DriveJudge: Rethinking Autonomous Driving Evaluation with Vision-Language Models
Pith reviewed 2026-06-27 02:59 UTC · model grok-4.3
The pith
DriveJudge uses a vision-language model to interpret driving context before selectively applying deterministic physical rules for evaluation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
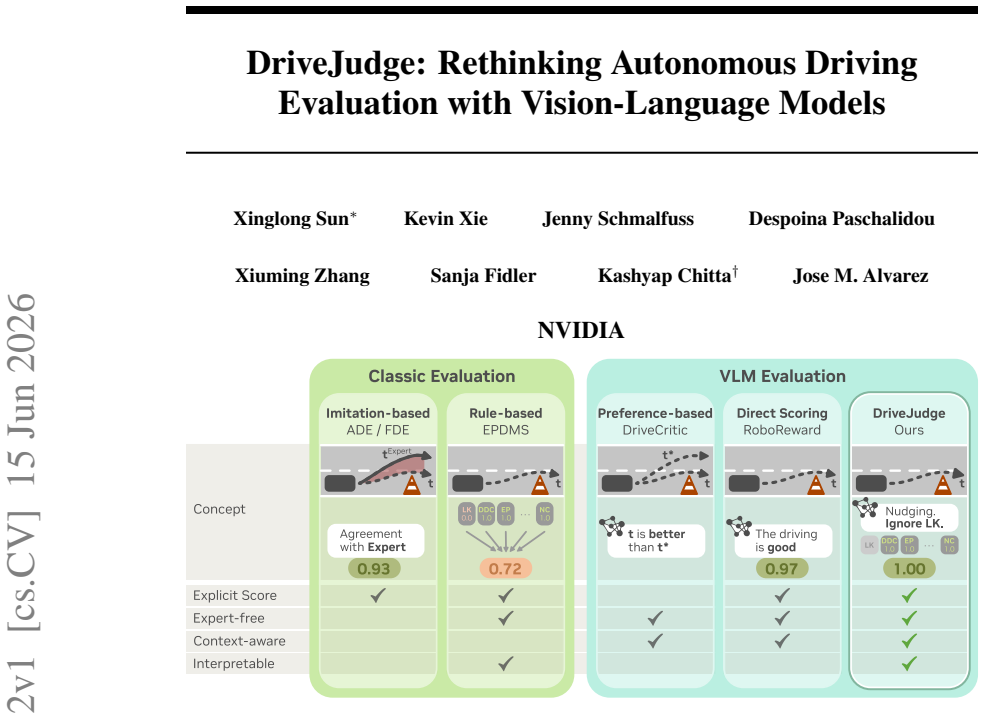
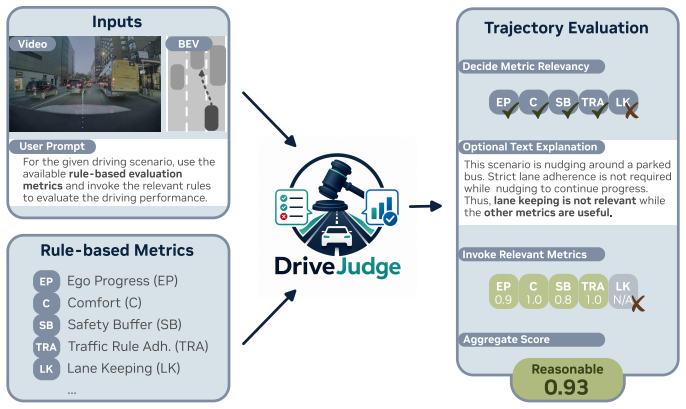
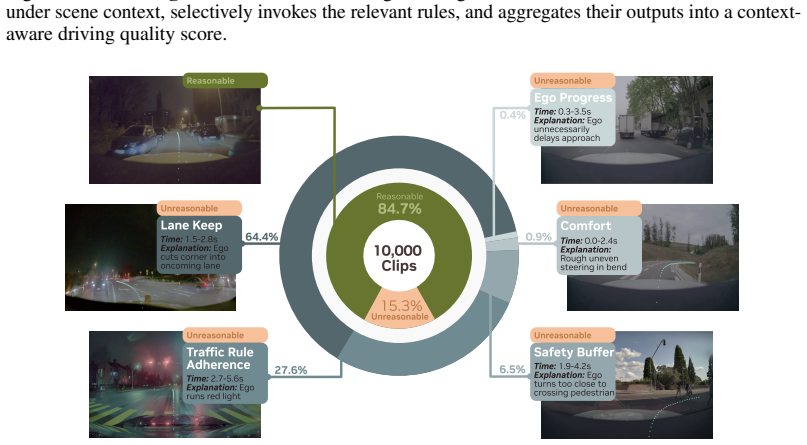
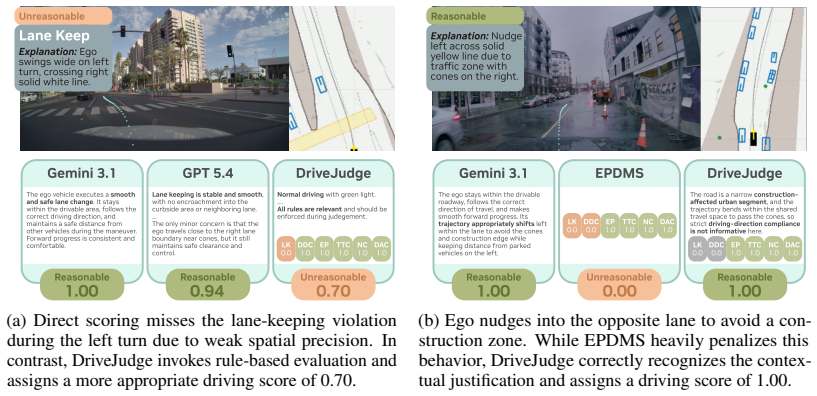
DriveJudge is a driving evaluation agent that combines rule-grounded evaluation with Vision-Language Model (VLM) reasoning and selectively invokes physically-grounded deterministic rule functions after interpreting the environmental context. Trained and tested on a curated dataset of 33,577 challenging driving samples with human annotations, it addresses driving metric evaluation through two tasks: Driving Quality Classification and Trajectory Preference Selection, where it outperforms EPDMS by 21.23 AUC and the recent VLM-based DriveCritic by 6.5%.
What carries the argument
DriveJudge, the agent that uses VLM reasoning to interpret context and then selectively calls deterministic rule functions for physically grounded scores.
If this is right
- Establishes two new human-aligned benchmark tasks for measuring driving evaluation quality.
- Demonstrates that hybrid VLM-plus-rule systems can exceed both pure rule-based and pure VLM-based methods on the same data.
- Provides an interpretable evaluation signal that could be used to train or fine-tune end-to-end driving policies.
- Shows that context interpretation followed by rule invocation improves both classification accuracy and preference ranking.
Where Pith is reading between the lines
- The same hybrid pattern could be tested on other embodied tasks where behavior must be judged against both context and hard constraints, such as robotic manipulation.
- If the rule set is expanded, DriveJudge might serve as an online monitor that flags unsafe actions in real vehicles before they occur.
- Future work could measure how much the performance gain depends on the particular VLM backbone versus the rule-invocation logic.
- The dataset itself could be used to study where human raters disagree, revealing ambiguous driving situations that current rules do not cover.
Load-bearing premise
Human annotations on the 33,577 samples give an accurate and unbiased ground truth for reasonable driving behavior, and the VLM can reliably read the context to pick the correct rules without adding new mistakes.
What would settle it
Collecting a fresh test set of driving scenarios and showing that a panel of new human raters agrees more with EPDMS or DriveCritic classifications than with DriveJudge.
Figures
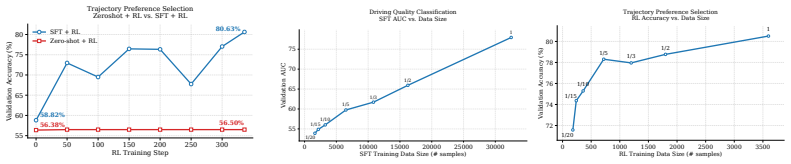



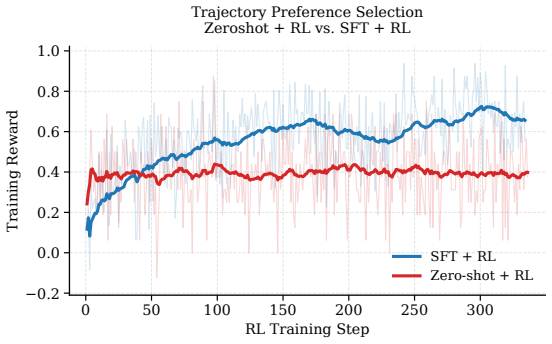
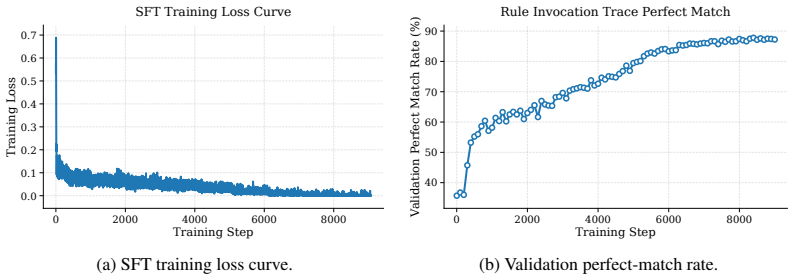
read the original abstract
Autonomous driving has shifted towards end-to-end policy learning, where reliable, interpretable policy evaluation is a fundamental challenge as driving quality is highly context-dependent. Commonly used rule-based driving metrics like EPDMS are interpretable but lack context-awareness, while recent VLMbased evaluations are context-aware but limited by ambiguous VLM outputs and weak physical grounding. To evaluate driving in a manner that is both interpretable and context-aware, we introduce DriveJudge. DriveJudge is a driving evaluation agent that combines rule-grounded evaluation with Vision-Language Model (VLM) reasoning and selectively invokes physically-grounded deterministic rule functions after interpreting the environmental context. To train and evaluate DriveJudge, we curate a large-scale dataset of 33,577 challenging driving samples with human annotations on whether the driving behavior is reasonable in the given scenario. With this dataset, we address the underexplored problem of driving metric evaluation, and introduce two human-aligned benchmark tasks: Driving Quality Classification and Trajectory Preference Selection. DriveJudge outperforms EPDMS for driving quality classification by 21.23 AUC, and the recent VLM-based DriveCritic for trajectory preference selection by 6.5%, setting a new standard for interpretable and precise driving evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DriveJudge, a VLM-based driving evaluation agent that interprets environmental context via vision-language reasoning and selectively invokes physically-grounded deterministic rule functions. It curates a dataset of 33,577 human-annotated samples for reasonableness of driving behavior and defines two benchmark tasks (driving quality classification and trajectory preference selection), reporting a 21.23 AUC improvement over EPDMS and a 6.5% gain over DriveCritic.
Significance. If the evaluation setup is robust, the work could advance interpretable, context-aware metrics for end-to-end autonomous driving policies by addressing the context-dependence limitation of pure rule-based metrics and the ambiguity of standalone VLM outputs. The human-aligned benchmarks represent a constructive contribution to the field.
major comments (3)
- [Dataset / Evaluation setup] Dataset construction (implied in abstract and methods): The central claims rest on human annotations of 33,577 samples serving as reliable ground truth for whether driving behavior is 'reasonable' in context. No inter-annotator agreement statistics, annotation guidelines, or validation against objective criteria are described; given the inherent subjectivity of reasonableness (e.g., aggressive yet safe maneuvers), this undermines assessment of whether the reported AUC and percentage gains reflect genuine improvement rather than annotation noise or bias.
- [Methods / DriveJudge description] Methods (abstract and § on DriveJudge architecture): The performance numbers are presented without any description of the VLM model, training procedure, prompting strategy for context interpretation, or the precise deterministic rule functions and invocation logic. These omissions make it impossible to determine whether the 21.23 AUC and 6.5% gains arise from the proposed hybrid approach or from unspecified implementation choices.
- [Results / Experiments] Results (abstract): The reported improvements lack any mention of statistical significance testing, confidence intervals, ablation studies, or error analysis. Without these, the robustness of the gains over EPDMS and DriveCritic cannot be evaluated, especially on a benchmark whose ground truth reliability is itself unquantified.
minor comments (1)
- [Abstract] Abstract contains minor typographical issues (e.g., 'VLMbased' should be 'VLM-based').
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive criticism. We address each of the major comments below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Dataset / Evaluation setup] Dataset construction (implied in abstract and methods): The central claims rest on human annotations of 33,577 samples serving as reliable ground truth for whether driving behavior is 'reasonable' in context. No inter-annotator agreement statistics, annotation guidelines, or validation against objective criteria are described; given the inherent subjectivity of reasonableness (e.g., aggressive yet safe maneuvers), this undermines assessment of whether the reported AUC and percentage gains reflect genuine improvement rather than annotation noise or bias.
Authors: We agree that details on the annotation process are essential for validating the ground truth. The current manuscript provides limited information on this. In the revision, we will include a dedicated subsection on dataset construction that details the annotation guidelines, the number of annotators per sample if multiple, inter-annotator agreement metrics (such as Cohen's kappa if computed), and any steps taken to mitigate subjectivity. If certain statistics were not collected during the original annotation, we will explicitly state this as a limitation and discuss its implications. revision: yes
-
Referee: [Methods / DriveJudge description] Methods (abstract and § on DriveJudge architecture): The performance numbers are presented without any description of the VLM model, training procedure, prompting strategy for context interpretation, or the precise deterministic rule functions and invocation logic. These omissions make it impossible to determine whether the 21.23 AUC and 6.5% gains arise from the proposed hybrid approach or from unspecified implementation choices.
Authors: We acknowledge the lack of implementation details in the submitted manuscript. We will revise the methods section to provide a comprehensive description of the VLM model employed (including version and parameters), the prompting strategies used for context interpretation, the training procedure if any fine-tuning was performed, and the exact deterministic rule functions along with the logic for their selective invocation. This will allow readers to better understand and potentially reproduce the hybrid approach. revision: yes
-
Referee: [Results / Experiments] Results (abstract): The reported improvements lack any mention of statistical significance testing, confidence intervals, ablation studies, or error analysis. Without these, the robustness of the gains over EPDMS and DriveCritic cannot be evaluated, especially on a benchmark whose ground truth reliability is itself unquantified.
Authors: We will enhance the results section by adding statistical significance testing (e.g., paired t-tests or McNemar's test where appropriate), confidence intervals for the reported metrics, ablation studies on the components of DriveJudge (such as the contribution of VLM reasoning versus rule functions), and an error analysis to identify cases where the model underperforms. These additions will help demonstrate the robustness of the improvements. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical ML system (DriveJudge) that combines VLM reasoning with deterministic rules, evaluated on a curated human-annotated dataset of 33,577 samples for two benchmark tasks. No equations, derivations, fitted parameters presented as predictions, or first-principles claims appear in the provided text. Performance numbers (21.23 AUC, 6.5%) are direct empirical comparisons against external baselines and human labels on held-out data. No self-citation chains, ansatzes, or renamings reduce any central result to its own inputs by construction. This is a standard empirical evaluation paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marius Zoellner
Ahmed Abouelazm, Jonas Michel, and J. Marius Zoellner. A review of reward functions for reinforcement learning in the context of autonomous driving, 2026
2026
-
[2]
Evaluating vision-language models as evaluators in path planning
Mohamed Aghzal, Xiang Yue, Erion Plaku, and Ziyu Yao. Evaluating vision-language models as evaluators in path planning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6886–6897, 2025
2025
-
[3]
Hassan Abu Alhaija, Jose Alvarez, Maciej Bala, Tiffany Cai, Tianshi Cao, Liz Cha, Joshua Chen, Mike Chen, Francesco Ferroni, Sanja Fidler, et al. Cosmos-transfer1: Conditional world generation with adaptive multimodal control.arXiv preprint arXiv:2503.14492, 2025
-
[4]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InCVPR, pages 11621–11631, 2020. 10
2020
-
[5]
Pseudo-simulation for autonomous driving
Wei Cao, Marcel Hallgarten, Tianyu Li, Daniel Dauner, Xunjiang Gu, Caojun Wang, Yakov Miron, Marco Aiello, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, Andreas Geiger, and Kashyap Chitta. Pseudo-simulation for autonomous driving. InConference on Robot Learning (CoRL), 2025
2025
-
[6]
Criteria: a new benchmarking paradigm for evaluating trajectory prediction models for autonomous driving
Changhe Chen, Mozhgan Pourkeshavarz, and Amir Rasouli. Criteria: a new benchmarking paradigm for evaluating trajectory prediction models for autonomous driving. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 8265–8271. IEEE, 2024
2024
-
[7]
Kai Chen, Ruiyuan Gao, Lanqing Hong, Hang Xu, Xu Jia, Holger Caesar, Dengxin Dai, Bingbing Liu, Dzmitry Tsishkou, Songcen Xu, et al. Eccv 2024 w-coda: 1st workshop on multimodal perception and comprehension of corner cases in autonomous driving.arXiv preprint arXiv:2507.01735, 2025
-
[8]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning.arXiv preprint arXiv:2402.13243, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Scaling instruction-finetuned language models
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1–53, 2024
2024
-
[10]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, Andreas Geiger, and Kashyap Chitta. Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking. InNeurIPS, volume 37, pages 28706–28719, 2024
2024
-
[12]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Carla: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. pages 1–16, 2017
2017
-
[14]
Lin Guan, Yifan Zhou, Denis Liu, Yantian Zha, Heni Ben Amor, and Subbarao Kambhampati. Task success is not enough: Investigating the use of video-language models as behavior critics for catching undesirable agent behaviors.arXiv preprint arXiv:2402.04210, 2024
-
[15]
Styledrive: Towards driving-style aware benchmarking of end-to-end autonomous driving
Ruiyang Hao, Bowen Jing, Haibao Yu, and Zaiqing Nie. Styledrive: Towards driving-style aware benchmarking of end-to-end autonomous driving. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 4627–4635, 2026. 11
2026
-
[16]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InCVPR, pages 17853–17862, 2023
2023
-
[17]
Ting Huang, Zeyu Zhang, and Hao Tang. 3d-r1: Enhancing reasoning in 3d vlms for unified scene understanding.arXiv preprint arXiv:2507.23478, 2025
-
[18]
Bench2drive: Towards multi- ability benchmarking of closed-loop end-to-end autonomous driving.NeurIPS, 37:819–844, 2024
Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive: Towards multi- ability benchmarking of closed-loop end-to-end autonomous driving.NeurIPS, 37:819–844, 2024
2024
-
[19]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[20]
Pierre Krack, Tobias Jülg, Wolfram Burgard, and Florian Walter. Rewarding dino: Predicting dense rewards with vision foundation models.arXiv preprint arXiv:2603.16978, 2026
-
[21]
Explaining human preferences via metrics for structured 3d reconstruction
Jack Langerman, Denys Rozumnyi, Yuzhong Huang, and Dmytro Mishkin. Explaining human preferences via metrics for structured 3d reconstruction. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 26944–26953, 2025
2025
-
[22]
Tony Lee, Andrew Wagenmaker, Karl Pertsch, Percy Liang, Sergey Levine, and Chelsea Finn. Roboreward: General-purpose vision-language reward models for robotics.arXiv preprint arXiv:2601.00675, 2026
-
[23]
Coda: A real-world road corner case dataset for object detection in autonomous driving
Kaican Li, Kai Chen, Haoyu Wang, Lanqing Hong, Chaoqiang Ye, Jianhua Han, Yukuai Chen, Wei Zhang, Chunjing Xu, Dit-Yan Yeung, et al. Coda: A real-world road corner case dataset for object detection in autonomous driving. InEuropean Conference on Computer Vision, pages 406–423. Springer, 2022
2022
-
[24]
Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking. 2026
2026
-
[25]
SpaceDrive: Infusing Spatial Awareness into VLM-based Autonomous Driving
Peizheng Li, Zhenghao Zhang, David Holtz, Hang Yu, Yutong Yang, Yuzhi Lai, Rui Song, Andreas Geiger, and Andreas Zell. Spacedrive: Infusing spatial awareness into vlm-based autonomous driving.arXiv preprint arXiv:2512.10719, 2, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning.IEEE transactions on pattern analysis and machine intelligence, 45(3):3461–3475, 2022
Quanyi Li, Zhenghao Peng, Lan Feng, Qihang Zhang, Zhenghai Xue, and Bolei Zhou. Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning.IEEE transactions on pattern analysis and machine intelligence, 45(3):3461–3475, 2022
2022
-
[27]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, et al. Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation.arXiv preprint arXiv:2406.06978, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Zhenxin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Zuxuan Wu, and Jose M. Alvarez. Hydra-next: Robust closed-loop driving with open-loop training. InICCV, pages 27305–27314, October 2025
2025
-
[29]
Zhenxin Li, Wenhao Yao, Zi Wang, Xinglong Sun, Jingde Chen, Nadine Chang, Maying Shen, Jingyu Song, Zuxuan Wu, Shiyi Lan, et al. Ztrs: Zero-imitation end-to-end autonomous driving with trajectory scoring.arXiv preprint arXiv:2510.24108, 2025
- [30]
-
[31]
Robometer: Scaling General-Purpose Robotic Reward Models via Trajectory Comparisons
Anthony Liang, Yigit Korkmaz, Jiahui Zhang, Minyoung Hwang, Abrar Anwar, Sidhant Kaushik, Aditya Shah, Alex S Huang, Luke Zettlemoyer, Dieter Fox, et al. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons.arXiv preprint arXiv:2603.02115, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, and Xinggang Wang. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InCVPR, June 2025
2025
-
[33]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[34]
Dapo: Improving multi-step reasoning abilities of large language models with direct advantage-based policy optimization
Jiacai Liu, Chaojie Wang, Chris Yuhao Liu, Liang Zeng, Rui Yan, Yiwen Sun, and Yang Liu. Dapo: Improving multi-step reasoning abilities of large language models with direct advantage-based policy optimization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 12
2025
-
[35]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, et al. Gdpo: Group reward-decoupled normalization policy optimization for multi-reward rl optimization.arXiv preprint arXiv:2601.05242, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Yuechen Luo, Fang Li, Shaoqing Xu, Yang Ji, Zehan Zhang, Bing Wang, Yuannan Shen, Jianwei Cui, Long Chen, Guang Chen, et al. Last-vla: Thinking in latent spatio-temporal space for vision-language-action in autonomous driving.arXiv preprint arXiv:2603.01928, 2026
-
[37]
Alpasim: A modular, lightweight, and data-driven research simulator for autonomous driving, October 2025
NVIDIA, Yulong Cao, Riccardo de Lutio, Sanja Fidler, Guillermo Garcia Cobo, Zan Gojcic, Maximilian Igl, Boris Ivanovic, Peter Karkus, Janick Martinez Esturo, Marco Pavone, Aaron Smith, Ellie Tanimura, Michal Tyszkiewicz, Michael Watson, Qi Wu, and Le Zhang. Alpasim: A modular, lightweight, and data-driven research simulator for autonomous driving, October 2025
2025
-
[38]
PhysicalAI-Autonomous-Vehicles, October 2025
NVIDIA Corporation. PhysicalAI-Autonomous-Vehicles, October 2025. Dataset hosted on Hugging Face. Accessed 2026-05-05
2025
-
[39]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[41]
Xuanchi Ren, Yifan Lu, Tianshi Cao, Ruiyuan Gao, Shengyu Huang, Amirmojtaba Sabour, Tianchang Shen, Tobias Pfaff, Jay Zhangjie Wu, Runjian Chen, et al. Cosmos-drive-dreams: Scalable synthetic driving data generation with world foundation models.arXiv preprint arXiv:2506.09042, 2025. 13
-
[42]
PARC: A quantitative framework uncovering the symmetries within vision language models
Jenny Schmalfuss, Nadine Chang, Vibashan VS, Maying Shen, Andres Bruhn, and Jose M Alvarez. PARC: A quantitative framework uncovering the symmetries within vision language models. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 25081–25091, 2025
2025
-
[43]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[44]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Drivecritic: Towards context-aware, human-aligned evaluation for autonomous driving with vision-language models.ICRA, 2026
Jingyu Song, Zhenxin Li, Shiyi Lan, Xinglong Sun, Nadine Chang, Maying Shen, Joshua Chen, Kather- ine A Skinner, and Jose M Alvarez. Drivecritic: Towards context-aware, human-aligned evaluation for autonomous driving with vision-language models.ICRA, 2026
2026
-
[46]
Jie Wang, Guang Li, Zhijian Huang, Chenxu Dang, Hangjun Ye, Yahong Han, and Long Chen. Vggdrive: Empowering vision-language models with cross-view geometric grounding for autonomous driving.arXiv preprint arXiv:2602.20794, 2026
-
[47]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners.arXiv preprint arXiv:2109.01652, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[48]
Yanru Wu, Weiduo Yuan, Ang Qi, Vitor Guizilini, Jiageng Mao, and Yue Wang. Large reward models: Gen- eralizable online robot reward generation with vision-language models.arXiv preprint arXiv:2603.16065, 2026
-
[49]
Tianbao Xie, Siheng Zhao, Chen Henry Wu, Yitao Liu, Qian Luo, Victor Zhong, Yanchao Yang, and Tao Yu. Text2reward: Reward shaping with language models for reinforcement learning.arXiv preprint arXiv:2309.11489, 2023
-
[50]
Phycritic: Multimodal critic models for physical ai.arXiv preprint arXiv:2602.11124, 2026
Tianyi Xiong, Shihao Wang, Guilin Liu, Yi Dong, Ming Li, Heng Huang, Jan Kautz, and Zhiding Yu. Phycritic: Multimodal critic models for physical ai.arXiv preprint arXiv:2602.11124, 2026
-
[51]
Runsheng Xu, Hubert Lin, Wonseok Jeon, Hao Feng, Yuliang Zou, Liting Sun, John Gorman, Ekaterina Tolstaya, Sarah Tang, Brandyn White, et al. Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios.arXiv preprint arXiv:2510.26125, 2025
-
[52]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Wenhao Yao, Zhenxin Li, Shiyi Lan, Zi Wang, Xinglong Sun, Jose M. Alvarez, and Zuxuan Wu. Drivesuprim: Towards precise trajectory selection for end-to-end planning.arXiv preprint arXiv:2506.06659, 2025
-
[54]
HAD: Combining Hierarchical Diffusion with Metric-Decoupled RL for End-to-End Driving
Wenhao Yao, Xinglong Sun, Zhenxin Li, Shiyi Lan, Zi Wang, Jose M Alvarez, and Zuxuan Wu. Had: Combining hierarchical diffusion with metric-decoupled rl for end-to-end driving.arXiv preprint arXiv:2604.03581, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Pengfei Yi, Yingjie Ma, Wenjiang Xu, Yanan Hao, Shuai Gan, Wanting Li, and Shanlin Zhong. Critic in the loop: A tri-system vla framework for robust long-horizon manipulation.arXiv preprint arXiv:2603.05185, 2026
-
[56]
Critic-v: Vlm critics help catch vlm errors in multimodal reasoning
Di Zhang, Jingdi Lei, Junxian Li, Xunzhi Wang, Yujie Liu, Zonglin Yang, Jiatong Li, Weida Wang, Suorong Yang, Jianbo Wu, et al. Critic-v: Vlm critics help catch vlm errors in multimodal reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9050–9061, 2025
2025
-
[57]
Vq-insight: Teaching vlms for ai-generated video quality understanding via progressive visual reinforcement learning
Xuanyu Zhang, Weiqi Li, Shijie Zhao, Junlin Li, Li Zhang, and Jian Zhang. Vq-insight: Teaching vlms for ai-generated video quality understanding via progressive visual reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 12870–12878, 2026. 14
2026
-
[58]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[59]
Jialv Zou, Shaoyu Chen, Bencheng Liao, Zhiyu Zheng, Yuehao Song, Lefei Zhang, Qian Zhang, Wenyu Liu, and Xinggang Wang. Diffusiondrivev2: Reinforcement learning-constrained truncated diffusion modeling in end-to-end autonomous driving.arXiv preprint arXiv:2512.07745, 2025. 15 A Model Details A.1 Prompts System : You are an expert AI driving i n s t r u c ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.