Toward Self-Evolution-Ready Workflow Harnesses: A Reversible Migration Path and Convertibility Taxonomy for Expert LLM Pipelines
Pith reviewed 2026-06-27 03:36 UTC · model grok-4.3
The pith
A three-tier convertibility taxonomy routes legacy LLM workflows into reversible, composable stages for self-evolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
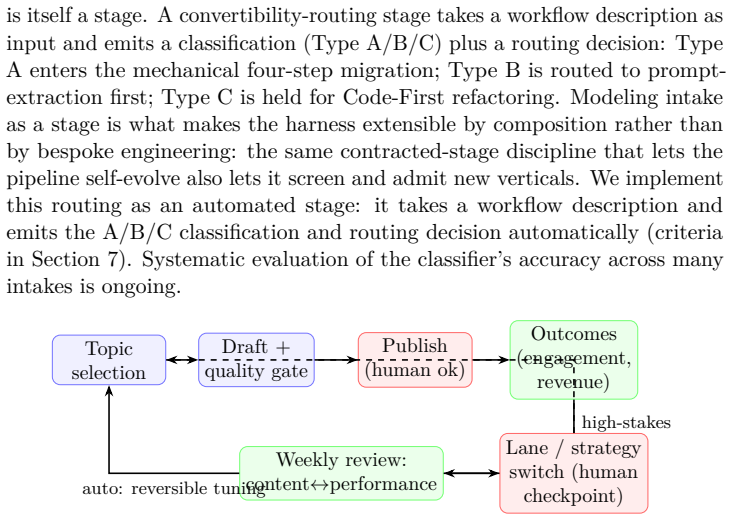
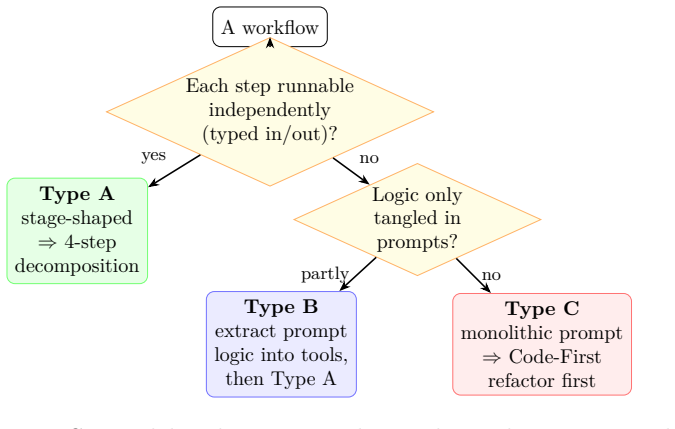
We present a reversible, Strangler-Fig migration path that refactors legacy workflows into composable, typed, and auditable stages. Central to this framework is a three-tier convertibility taxonomy (A/B/C), implemented as a routing stage within the system harness, which diagnoses a workflow's readiness and routes it accordingly.
What carries the argument
The three-tier convertibility taxonomy (A/B/C) implemented as a routing stage that diagnoses workflow readiness and selects the migration path.
If this is right
- Existing expert workflows gain a path to become feedback-responsive without full replacement.
- Stages in the migrated workflow become individually typed, composable, and auditable.
- Migration decisions are made by an internal routing stage rather than manual overhaul.
- The taxonomy classifies workflows into A, B, or C tiers to determine the appropriate conversion strategy.
Where Pith is reading between the lines
- If the taxonomy proves stable across domains, it could serve as a general diagnostic for any script-based pipeline moving toward agentic behavior.
- The reversible nature implies that teams could test evolutionary features on a subset of stages and roll back if needed.
- This framing shifts focus from building agents from scratch to incrementally upgrading production systems that already embed expert knowledge.
Load-bearing premise
The three-tier convertibility taxonomy can be implemented as an effective routing stage that accurately diagnoses readiness for migration without additional empirical validation or domain-specific tuning.
What would settle it
A test set of expert LLM workflows where the taxonomy assigns incorrect tiers or requires per-domain tuning data to achieve accurate routing would falsify the central claim.
Figures
read the original abstract
While expert-validated "LLM + script" workflows deliver significant value, they remain static: they encode hard-won domain knowledge yet fail to adapt execution based on feedback. Existing agent research predominantly targets greenfield agents and synthetic benchmarks, leaving the migration of active legacy workflows unresolved. To bridge this gap, we present a reversible, Strangler-Fig migration path that refactors legacy workflows into composable, typed, and auditable stages. Central to this framework is a three-tier convertibility taxonomy (A/B/C), implemented as a routing stage within the system harness, which diagnoses a workflow's readiness and routes it accordingly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a reversible Strangler-Fig migration path for refactoring legacy 'LLM + script' workflows into composable, typed, and auditable stages. Central to the framework is a three-tier convertibility taxonomy (A/B/C) that is implemented as a routing stage within the system harness to diagnose a workflow's readiness and route it accordingly.
Significance. If the taxonomy were equipped with explicit decision criteria and empirical validation, the proposal could address a genuine gap between static expert-validated workflows and adaptive agent systems by offering a concrete migration strategy. The conceptual framing correctly identifies that most agent research targets greenfield cases rather than legacy refactoring, but the current lack of mechanism details prevents assessment of whether the approach would deliver the claimed diagnostic and routing capability.
major comments (2)
- [Abstract] Abstract: the claim that the three-tier convertibility taxonomy (A/B/C) is 'implemented as a routing stage within the system harness, which diagnoses a workflow's readiness and routes it accordingly' is the load-bearing mechanism, yet the manuscript supplies no decision criteria, feature set, scoring function, or threshold logic for assigning tiers.
- [Abstract] Abstract: no experiments, datasets, or error analysis are provided to test whether the asserted routing stage would correctly classify workflows or generalize beyond the authors' examples, leaving the diagnostic effectiveness unverified.
minor comments (1)
- The abstract is dense; a short sentence outlining the subsequent sections would improve readability for readers encountering the taxonomy for the first time.
Simulated Author's Rebuttal
We thank the referee for highlighting the load-bearing claims in the abstract. The manuscript is a conceptual framework paper focused on the migration path and taxonomy structure; we address both comments by clarifying scope and committing to targeted revisions without misrepresenting the current content.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the three-tier convertibility taxonomy (A/B/C) is 'implemented as a routing stage within the system harness, which diagnoses a workflow's readiness and routes it accordingly' is the load-bearing mechanism, yet the manuscript supplies no decision criteria, feature set, scoring function, or threshold logic for assigning tiers.
Authors: We agree the abstract phrasing 'implemented as' implies operational detail that is not present. The body defines the A/B/C categories and their high-level properties (see Sections 3–4), but supplies no explicit decision criteria, features, scoring function, or thresholds. This reflects the paper's focus on establishing the taxonomy and reversible migration path rather than a concrete router implementation. We will revise the abstract to 'proposed as a routing stage' and add a short subsection with illustrative criteria and an example scoring sketch for future operationalization. revision: yes
-
Referee: [Abstract] Abstract: no experiments, datasets, or error analysis are provided to test whether the asserted routing stage would correctly classify workflows or generalize beyond the authors' examples, leaving the diagnostic effectiveness unverified.
Authors: Correct: the manuscript contains no experiments, datasets, or error analysis. As a framework proposal, its contribution is the migration strategy and taxonomy rather than empirical validation of a router. We will insert a dedicated 'Limitations and Future Evaluation' paragraph that outlines candidate datasets, classification metrics, and generalization tests, while explicitly stating that diagnostic effectiveness remains unverified in the present work. revision: partial
Circularity Check
Conceptual proposal with no derivations, equations, or self-referential reductions
full rationale
The manuscript is a design proposal for a migration path and three-tier taxonomy. It contains no equations, fitted parameters, predictions, or derivations. The taxonomy is introduced as a new construct within the harness rather than derived from or reduced to prior inputs, self-citations, or data. No load-bearing step reduces to its own definition or to a self-citation chain. The work is self-contained as a conceptual framework.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Gopichand Bandarupalli. Code reborn: AI-driven legacy systems mod- ernization from COBOL to Java.arXiv preprint arXiv:2504.11335, 2025
-
[3]
Manish Bhattarai and Minh Vu. Trustworthy agentic AI requires de- terministic architectural boundaries.arXiv preprint arXiv:2602.09947, 2026
-
[4]
Uwe M. Borghoff et al. Beyond prompt chaining: The TB-CSPN architecture for agentic AI. Preprints 202507.1294, 2025
-
[5]
Shielding agents via verifiable safety policy reasoning.arXiv preprint arXiv:2503.22738, 2025
Zhaorun Chen, Mintong Kang, and Bo Li. Shielding agents via verifiable safety policy reasoning.arXiv preprint arXiv:2503.22738, 2025
-
[6]
A Decoupled Human-in-the-Loop System for Controlled Autonomy in Agentic Workflows
Edward Cheng and Jeshua Cheng. A decoupled human-in-the-loop system for controlled autonomy in agentic workflows.arXiv preprint arXiv:2604.23049, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Kexin Chu. A systematic survey of security threats and defenses in LLM-based AI agents: A layered attack surface framework.arXiv preprint arXiv:2604.23338, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks
Lutfi Eren Erdogan, Nicholas Lee, Sehoon Kim, Suhong Moon, Hiroki Furuta, Gopala Anumanchipalli, Kurt Keutzer, and Amir Gholami. Plan- and-act: Improving planning of agents for long-horizon tasks.arXiv preprint arXiv:2503.09572, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Bypassing Prompt Guards in Production with Controlled-Release Prompting
Jaiden Fairoze, Sanjam Garg, Keewoo Lee, and Mingyuan Wang. By- passing prompt guards in production with controlled-release prompting. arXiv preprint arXiv:2510.01529, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Strangler fig application.https://martinfowler.com/ bliki/StranglerFigApplication.html, 2004
Martin Fowler. Strangler fig application.https://martinfowler.com/ bliki/StranglerFigApplication.html, 2004
2004
-
[11]
Aayush Gupta. Evaluating LLM agent reliability under production-like stress conditions.arXiv preprint arXiv:2601.06112, 2026
-
[12]
William Hackett, Lewis Birch, Stefan Trawicki, Neeraj Suri, and Peter Garraghan. Bypassing prompt injection and jailbreak detection in LLM guardrails.arXiv preprint arXiv:2504.11168, 2025
-
[13]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can lan- guage models resolve real-world GitHub issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
Tula Masterman, Sandi Besen, Mason Sawtell, and Alex Chao. The landscape of emerging AI agent architectures for reasoning, planning, and tool calling.arXiv preprint arXiv:2404.11584, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Mohan Rajagopalan and Vinay Rao. Protecting context and prompts: Deterministic security for non-deterministic AI.arXiv preprint arXiv:2602.10481, 2026
-
[16]
Autonomy and Agency in Agentic AI: Architectural Tactics for Regulated Contexts
Damir Safin and Dian Balta. Autonomy and agency in agentic AI: Archi- tectural tactics for regulated contexts.arXiv preprint arXiv:2605.12105, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.arXiv preprint arXiv:2302.04761, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.arXiv preprint arXiv:2303.11366, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Human-in-the-loop software develop- ment agents.arXiv preprint arXiv:2411.12924, 2024
Wannita Takerngsaksiri, Jirat Pasuksmit, Patanamon Thongtanunam, Chakkrit Tantithamthavorn, Ruixiong Zhang, Fan Jiang, Jing Li, Evan Cook, Kun Chen, and Ming Wu. Human-in-the-loop software develop- ment agents.arXiv preprint arXiv:2411.12924, 2024
-
[20]
Zhi Rui Tam, Cheng-Kuang Wu, Yi-Lin Tsai, Chieh-Yen Lin, Hung-yi Lee, and Yun-Nung Chen. Let me speak freely? a study of the impact 13 of format restrictions on performance of large language models.arXiv preprint arXiv:2408.02442, 2024
-
[21]
Uchi Uchibeke. Before the tool call: Deterministic pre-action autho- rization for autonomous AI agents.arXiv preprint arXiv:2603.20953, 2026
-
[22]
AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents
Haoyu Wang, Christopher M. Poskitt, and Jun Sun. Customizable runtime enforcement for safe and reliable LLM agents.arXiv preprint arXiv:2503.18666, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
A Survey on Large Language Model based Autonomous Agents
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.arXiv preprint arXiv:2308.11432, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Rongzhe Wei, Peizhi Niu, Xinjie Shen, Tony Tu, Yifan Li, Ruihan Wu, Eli Chien, Pin-Yu Chen, Olgica Milenkovic, and Pan Li. The trojan knowledge: Bypassing commercial LLM guardrails via harmless prompt weaving and adaptive tree search.arXiv preprint arXiv:2512.01353, 2025
-
[25]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. Auto- Gen: Enabling next-gen LLM applications via multi-agent conversation framework.arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Sikuan Yan et al. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Survey on Evaluation of LLM-based Agents
Asaf Yehudai, Lilach Eden, Alan Li, Guy Uziel, Yilun Zhao, Roy Bar- Haim, Arman Cohan, and Michal Shmueli-Scheuer. A survey on evalua- tion of LLM-based agents.arXiv preprint arXiv:2503.16416, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Jiaqi Feng, Yaliang Li, and Libing Wu. Agentic memory: Learning unified long-term and short-term memory management for large language model agents.arXiv preprint arXiv:2601.01885, 2026. 14
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.