AnyBody: Free-Form Whole-Body Humanoid Control from Arbitrary Keypoint Guidance
Pith reviewed 2026-06-30 07:42 UTC · model grok-4.3
The pith
AnyBody learns one latent motion space that any keypoint subset can drive for whole-body humanoid control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
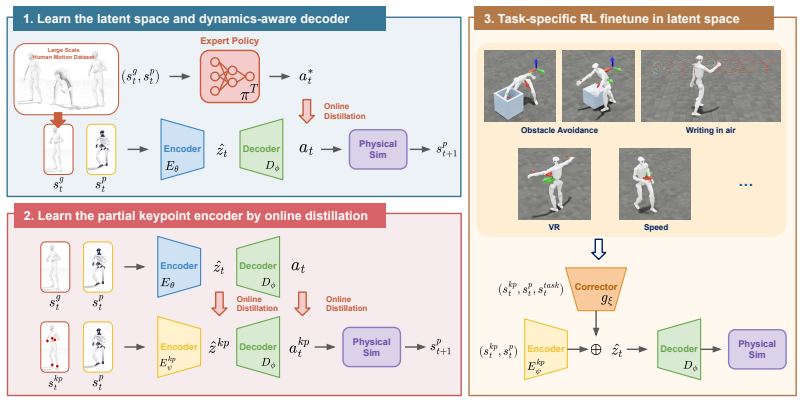
AnyBody closes the gap between full-motion-capture trackers and partial-keypoint control by learning a single latent motion representation on a unit sphere; a masked self-attention transformer aligns any keypoint subset to this representation, and the resulting latent commands a shared decoder that produces coordinated whole-body actions without hierarchical decomposition.
What carries the argument
Unit-sphere latent space from online distillation of a privileged teacher tracker, addressed by a masked self-attention transformer keypoint encoder.
If this is right
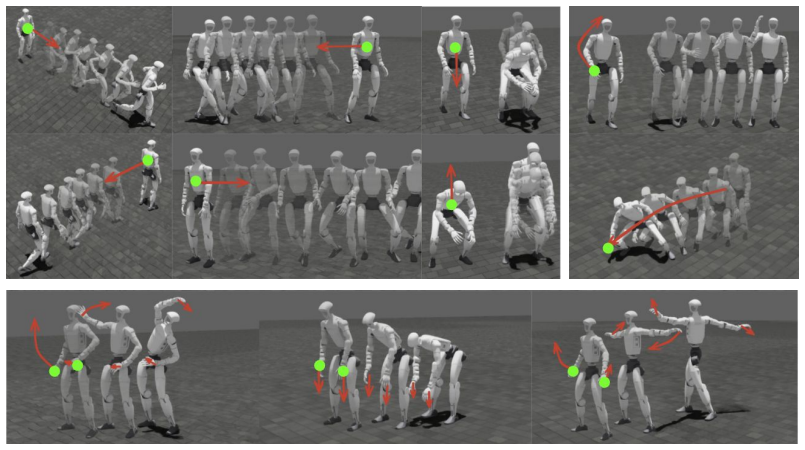
- Arbitrary keypoint subsets at deploy time produce coordinated whole-body humanoid motions.
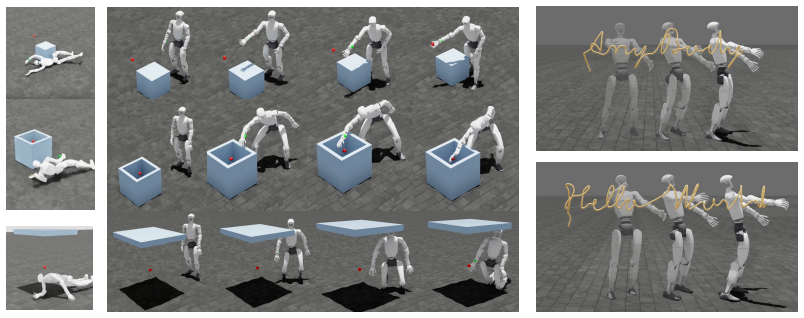
- Downstream tasks are learned by adding a lightweight residual corrector on top of the frozen decoder.
- Large-scale human motion tracking works from partial keypoint inputs without retargeting.
- Free-form control and teleoperation become possible with flexible keypoint choices.
Where Pith is reading between the lines
- Real-time camera-based keypoint detectors could replace mocap suits for robot training data.
- The same latent-space approach might transfer to non-humanoid robots if the motor prior generalizes.
- Task-specific correctors could be swapped at runtime to switch behaviors without retraining the core controller.
Load-bearing premise
The privileged teacher tracker trained on unstructured motion data can be distilled into a deterministic encoder-decoder whose unit-sphere latent space stays addressable by arbitrary masked keypoint subsets without loss of coordinated whole-body motion quality.
What would settle it
Running the same locomotion sequence with only upper-body keypoints and observing whether leg coordination degrades compared with full keypoints.
Figures
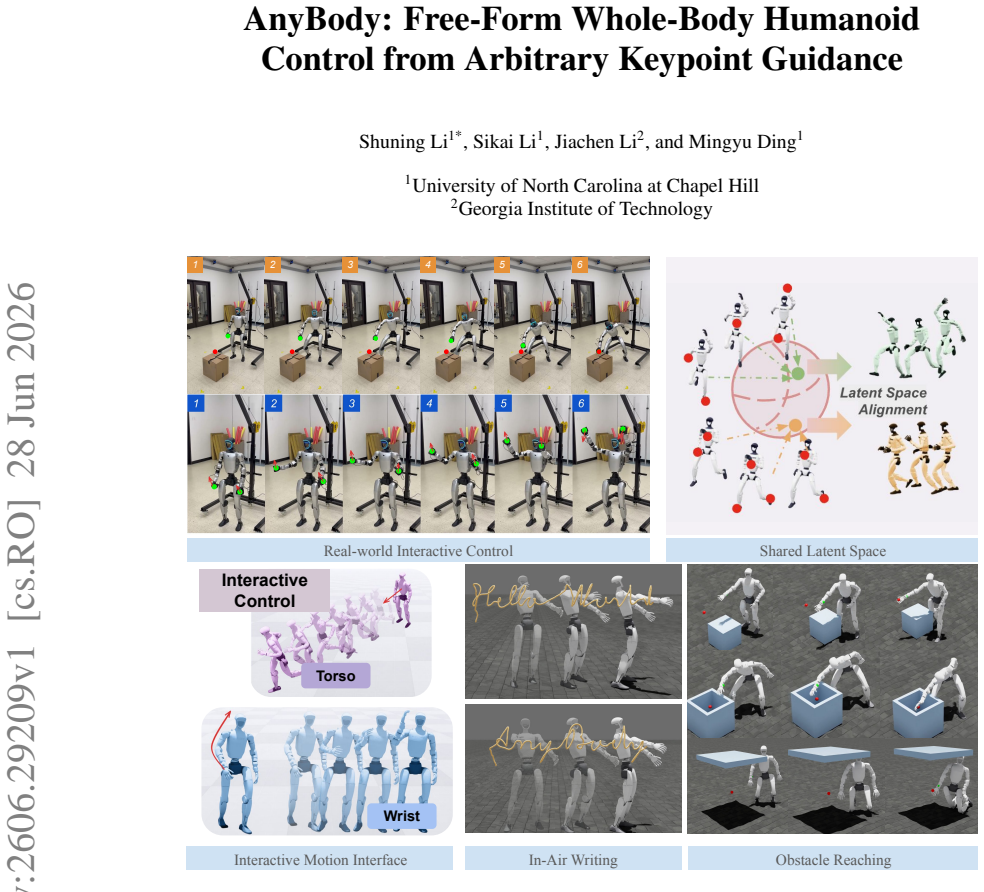





read the original abstract
We present AnyBody, a unified whole-body humanoid controller driven by an arbitrary subset of body keypoints chosen at deploy time. Prior physics-based trackers either rely on expensive full-body motion capture and error-prone trajectory retargeting, which bottleneck scalable data collection and policy learning, or decompose upper- and lower-body control into separate hierarchical representations, sacrificing the coordinated whole-body motions that loco-manipulation requires. We close this gap by learning a single latent motion representation that any keypoint subset can address. To achieve this, we first train a privileged teacher tracker on a large unstructured motion corpus and distill it online into a deterministic encoder-decoder student whose latent space is a unit sphere. We then train a transformer keypoint encoder that admits any subset of body keypoints through masked self-attention, aligning it to the privileged latent. Additionally, we treat the frozen decoder as a motor prior and specialize downstream tasks with a lightweight residual corrector in the latent space. We demonstrate the effectiveness of AnyBody by tracking large-scale human motions from arbitrary keypoint subsets, free-form control, flexibly teleoperating, and learning downstream behaviors including locomotion, in-air writing, and obstacle-reach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AnyBody, a unified whole-body humanoid controller driven by an arbitrary subset of body keypoints at deploy time. It trains a privileged teacher tracker on unstructured motion data, distills it online into a deterministic encoder-decoder student with unit-sphere latent space, trains a masked self-attention transformer keypoint encoder aligned to that latent, and uses the frozen decoder plus a lightweight residual corrector for downstream task specialization. Demonstrations include tracking large-scale human motions from arbitrary keypoints, free-form control, teleoperation, and learning behaviors such as locomotion, in-air writing, and obstacle reaching.
Significance. If the online distillation and keypoint-to-latent alignment succeed without degrading coordinated whole-body motion quality, the work would be significant for physics-based humanoid control. It directly addresses the scalability bottleneck of full-body mocap and the coordination loss of hierarchical upper/lower-body decompositions, enabling more flexible loco-manipulation policies from partial observations. The single latent representation addressable by arbitrary masked subsets is a coherent architectural choice that, if validated, advances deploy-time adaptability.
minor comments (1)
- The provided manuscript text consists only of the abstract; without access to sections, equations, training details, or quantitative results, it is not possible to assess whether the distillation and alignment steps empirically support the central claim of lossless addressability by arbitrary keypoint subsets.
Simulated Author's Rebuttal
We thank the referee for their summary of AnyBody and for noting its potential to address scalability and coordination issues in whole-body humanoid control. The recommendation of 'uncertain' is noted, but the report lists no specific major comments under the MAJOR COMMENTS section. We therefore have no individual points to rebut or revise at this stage and look forward to any additional detailed feedback.
Circularity Check
No significant circularity
full rationale
The provided abstract and description outline a standard privileged-teacher distillation pipeline: an external unstructured motion corpus trains the teacher, online distillation produces the student encoder-decoder with unit-sphere latent, a separate masked-self-attention transformer is trained to align arbitrary keypoint subsets to that latent, and a frozen decoder plus residual corrector handles downstream tasks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the text. The central claim (single latent addressable by arbitrary subsets) is presented as the outcome of this empirical alignment training rather than a mathematical identity or reduction to the inputs by construction. The pipeline is self-contained against external motion data and does not invoke uniqueness theorems or prior self-authored results as load-bearing premises.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv preprint arXiv:2508.08241, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [2]
- [3]
- [4]
-
[5]
D. Kalaria, S. S. Harithas, P. Katara, S. Kwak, S. Bhagat, S. Sastry, S. Sridhar, S. Vemprala, A. Kapoor, and J. C.-K. Huang. Dreamcontrol: Human-inspired whole-body humanoid control for scene interaction via guided diffusion.arXiv preprint arXiv:2509.14353, 2025
-
[6]
C. Lu, X. Cheng, J. Li, S. Yang, M. Ji, C. Yuan, G. Yang, S. Yi, and X. Wang. Mobile- television: Predictive motion priors for humanoid whole-body control. In2025 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 5364–5371. IEEE, 2025
2025
- [7]
-
[8]
J. Shi, X. Liu, D. Wang, S. Schwertfeger, C. Zhang, F. Sun, C. Bai, X. Li, et al. Adversarial lo- comotion and motion imitation for humanoid policy learning.Advances in Neural Information Processing Systems, 38:73918–73949, 2026
2026
-
[9]
Y . Li, Y . Zhang, W. Xiao, C. Pan, H. Weng, G. He, T. He, and G. Shi. Learning gentle humanoid locomotion and end-effector stabilization control.arXiv e-prints, pages arXiv–2505, 2025
2025
-
[10]
J. Li, X. Cheng, T. Huang, S. Yang, R.-Z. Qiu, and X. Wang. Amo: Adaptive motion opti- mization for hyper-dexterous humanoid whole-body control. InRobotics: Science and Systems (RSS), 2025. doi:10.15607/RSS.2025.XXI.061
-
[11]
Q. Ben, F. Jia, J. Zeng, J. Dong, D. Lin, and J. Pang. Homie: Humanoid loco-manipulation with isomorphic exoskeleton cockpit, 2025
2025
-
[12]
Xu and G
J. Xu and G. Durrett. Spherical latent spaces for stable variational autoencoders. InPro- ceedings of the 2018 conference on empirical methods in natural language processing, pages 4503–4513, 2018
2018
-
[13]
W. Fan, H. Huang, C. Liang, X. Liu, and S.-J. Peng. Unsupervised meta-learning via spherical latent representations and dual vae-gan: W. fan et al.Applied Intelligence, 53(19):22775– 22788, 2023
2023
-
[14]
Z. Luo, Y . Yuan, T. Wang, C. Li, F. Casta ˜neda, S. Chen, et al. Sonic: Supersizing motion tracking for natural humanoid whole-body control, 2025
2025
-
[15]
X. B. Peng, P. Abbeel, S. Levine, and M. van de Panne. Deepmimic: Example-guided deep re- inforcement learning of physics-based character skills.ACM Transactions on Graphics (TOG), 37(4):143:1–143:14, 2018. doi:10.1145/3197517.3201311. 16
-
[16]
Z. Luo, J. Cao, A. Winkler, K. Kitani, and W. Xu. Perpetual humanoid control for real-time simulated avatars. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 10861–10870, 2023. doi:10.1109/ICCV51070.2023.01000
-
[17]
Mahmood, N
N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black. Amass: Archive of motion capture as surface shapes. InProceedings of the IEEE/CVF international conference on computer vision, pages 5442–5451, 2019
2019
-
[18]
S. Li, S. Li, Z. Wei, Y . Yao, C. Li, and M. Ding. Coordex: Coordinating body and hand pri- ors for continuous dexterous humanoid loco-manipulation.arXiv preprint arXiv:2606.23680, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [20]
- [21]
- [22]
- [23]
-
[24]
Y . Wang, M. Yang, G. Ding, Y . Zhang, W. Zeng, X. Xu, H. Jiang, and Z. Lu. From experts to a generalist: Toward general whole-body control for humanoid robots.Advances in Neural Information Processing Systems, 38:147748–147772, 2026
2026
- [25]
-
[26]
Z. Fu, Q. Zhao, Q. Wu, G. Wetzstein, and C. Finn. Humanplus: Humanoid shadowing and imitation from humans. InConference on Robot Learning (CoRL), 2024
2024
-
[27]
T. He, Z. Luo, X. He, W. Xiao, C. Zhang, W. Zhang, K. Kitani, C. Liu, and G. Shi. Om- nih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning. InConference on Robot Learning (CoRL), 2024
2024
-
[28]
Y . Li, Y . Lin, J. Cui, T. Liu, W. Liang, Y . Zhu, and S. Huang. Clone: Closed-loop whole-body humanoid teleoperation for long-horizon tasks. InConference on Robot Learning (CoRL), pages 4493–4505, 2025
2025
-
[29]
Dugar, A
P. Dugar, A. Shrestha, F. Yu, B. van Marum, and A. Fern. Learning multi-modal whole- body control for real-world humanoid robots. InProceedings of the AAAI Symposium Series, volume 7, pages 650–657, 2025
2025
-
[30]
T. He, W. Xiao, T. Lin, Z. Luo, Z. Xu, Z. Jiang, J. Kautz, C. Liu, G. Shi, X. Wang, L. Fan, and Y . Zhu. Hover: Versatile neural whole-body controller for humanoid robots. InIEEE International Conference on Robotics and Automation (ICRA), pages 9989–9996, 2025. doi: 10.1109/ICRA55743.2025.11128549
- [31]
-
[32]
Yamada, M
J. Yamada, M. Rigter, J. Collins, and I. Posner. Twist: Teacher-student world model distillation for efficient sim-to-real transfer. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 9190–9196. IEEE, 2024
2024
-
[33]
Wang and K.-J
L. Wang and K.-J. Yoon. Knowledge distillation and student-teacher learning for visual in- telligence: A review and new outlooks.IEEE transactions on pattern analysis and machine intelligence, 44(6):3048–3068, 2021
2021
-
[34]
Zhang, G
Q. Zhang, G. Han, J. Sun, W. Zhao, C. Sun, J. Cao, J. Wang, Y . Guo, and R. Xu. Distillation- ppo: A novel two-stage reinforcement learning framework for humanoid robot perceptive lo- comotion. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2916–2922. IEEE, 2025
2025
-
[35]
C. Yang, X. Yu, H. Yang, Z. An, C. Yu, L. Huang, and Y . Xu. Multi-teacher knowledge distillation with reinforcement learning for visual recognition. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 9148–9156, 2025
2025
-
[36]
Behavioral Cloning from Observation
F. Torabi, G. Warnell, and P. Stone. Behavioral cloning from observation.arXiv preprint arXiv:1805.01954, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Z. Luo, J. Cao, J. Merel, A. Winkler, J. Huang, K. Kitani, and W. Xu. Universal humanoid motion representations for physics-based control. InInternational Conference on Learning Representations, volume 2024, pages 56766–56782, 2024
2024
-
[38]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
LoRA-FA: Efficient and Effective Low Rank Representation Fine-tuning
L. Zhang, L. Zhang, S. Shi, X. Chu, and B. Li. Lora-fa: Memory-efficient low-rank adaptation for large language models fine-tuning.arXiv preprint arXiv:2308.03303, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
T. Silver, K. Allen, J. Tenenbaum, and L. Kaelbling. Residual policy learning.arXiv preprint arXiv:1812.06298, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
Johannink, S
T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, and S. Levine. Residual reinforcement learning for robot control. In2019 international conference on robotics and automation (ICRA), pages 6023–6029. IEEE, 2019
2019
-
[42]
M. Alakuijala, G. Dulac-Arnold, J. Mairal, J. Ponce, and C. Schmid. Residual reinforcement learning from demonstrations.arXiv preprint arXiv:2106.08050, 2021
- [43]
-
[44]
BONES-SEED: Skeletal everyday embodiment dataset.https:// huggingface.co/datasets/bones-studio/seed, 2026
Bones Studio. BONES-SEED: Skeletal everyday embodiment dataset.https:// huggingface.co/datasets/bones-studio/seed, 2026. 142,220 annotated motion clips, ≈288 hours at 120 fps
2026
-
[45]
Unitree G1 Humanoid Robot.https://www.unitree.com/g1, 2024
Unitree Robotics. Unitree G1 Humanoid Robot.https://www.unitree.com/g1, 2024
2024
-
[46]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
NVIDIA, :, M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Mu ˜noz, X. Yao, R. Zurbr ¨ugg, N. Rudin, L. Wawrzyniak, M. Rakhsha, A. Denzler, E. Heiden, A. Borovicka, O. Ahmed, I. Akinola, A. Anwar, M. T. Carlson, J. Y . Feng, A. Garg, R. Gasoto, L. Gulich, Y . Guo, M. Gussert, A. Hansen, M. Kulkarni, C. Li, W. Liu, V . Makoviychuk, G....
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.