One Forward Beats Two: InnerZoom for Accurate and Efficient GUI Grounding
Pith reviewed 2026-06-30 06:55 UTC · model grok-4.3
The pith
InnerZoom bridges target evidence across decoder layers in one forward pass to improve GUI coordinate prediction without a second run.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
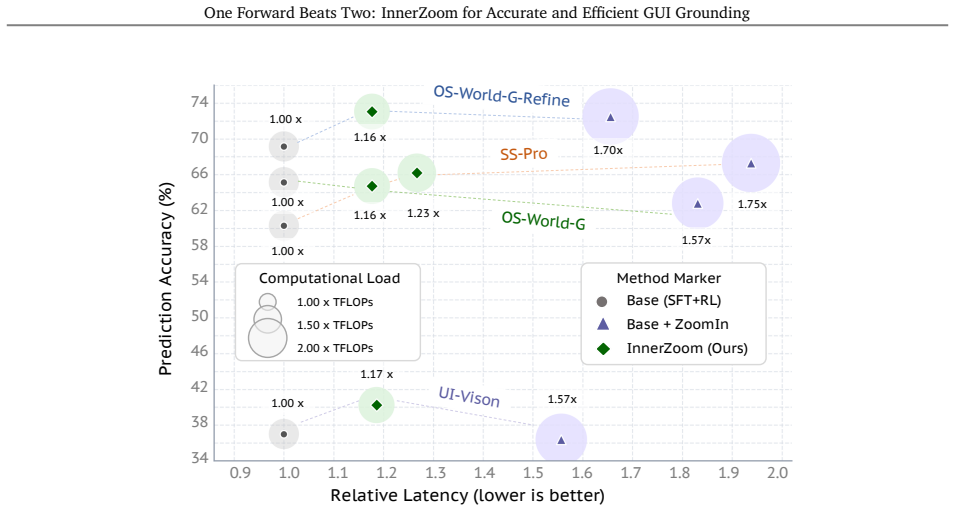
InnerZoom transforms target-related cues from the original forward pass into a compact cross-layer evidence state, then preserves, refines, and reinjects this state throughout later decoding layers to guide coordinate prediction. Under a controlled 4B setting it improves the SFT+RL baseline by 5.3 points on average, outperforms two-pass ZoomIn by 1.3 points on average, and delivers state-of-the-art scores of 64.7 on OSWorld-G, 40.2 on UI-Vision, 73.1 on OSWorld-GR, and 87.6 on MMBench-GUI while cutting end-to-end latency by up to 31.8 percent and TFLOPs by about 29 percent.
What carries the argument
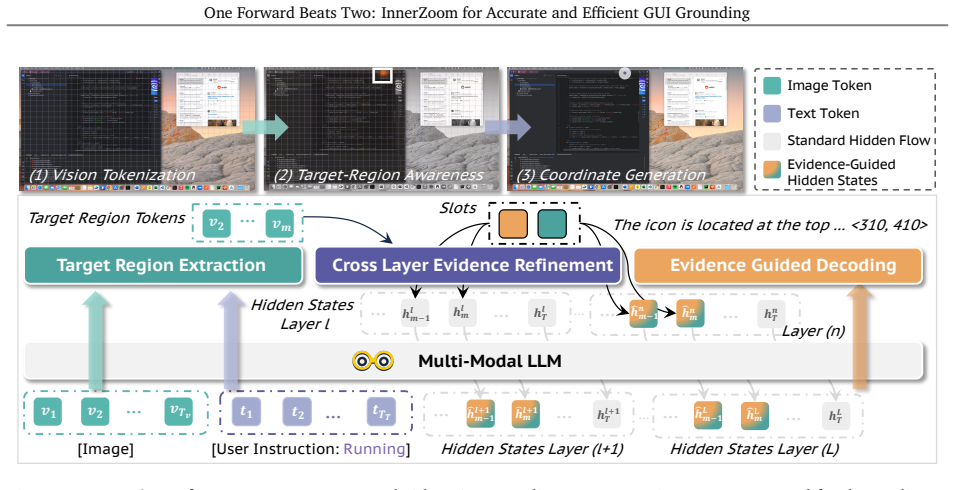
InnerZoom, a single-forward cross-layer evidence bridging mechanism that extracts target-region awareness from intermediate decoder layers into a compact state for later reinjection.
Load-bearing premise
Target-region awareness that emerges in intermediate decoder layers can be extracted into a compact state and reinjected into later layers without information loss to reliably improve final coordinate accuracy.
What would settle it
Run the model with the cross-layer evidence state ablated or replaced by random values and measure whether coordinate prediction accuracy falls back to the level of the plain SFT+RL baseline.
Figures



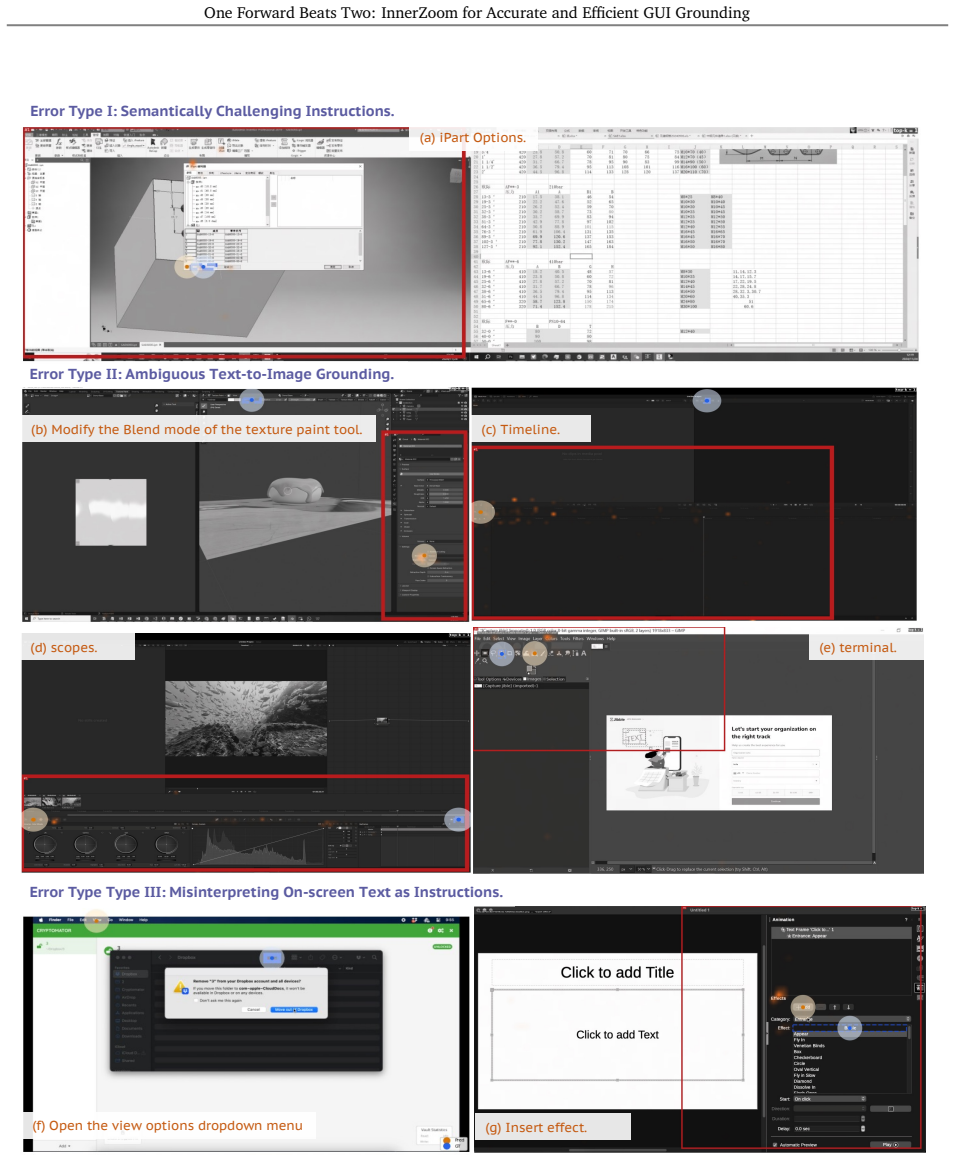
read the original abstract
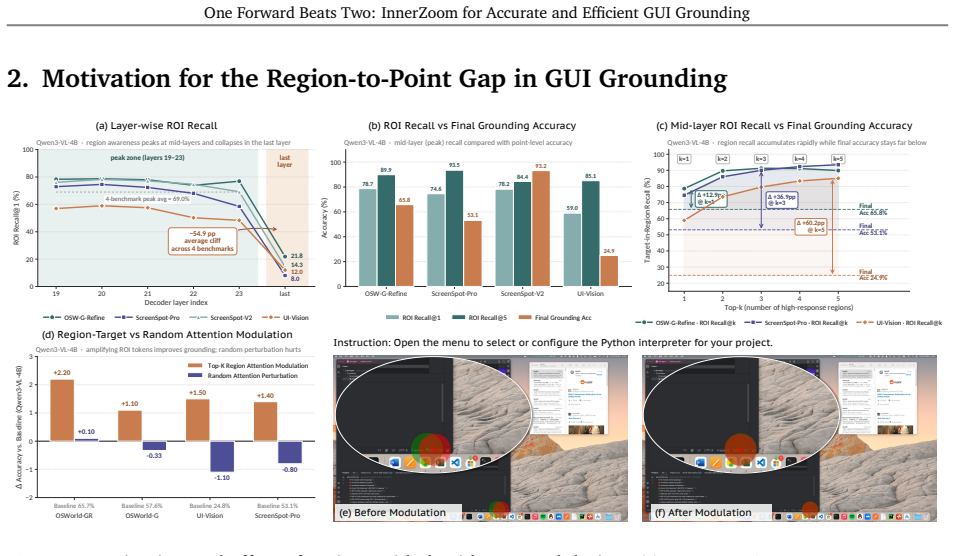
MLLM-based GUI grounding methods commonly formulate target localization as autoregressive coordinate generation, enabling models to leverage the strong instruction-following and semantic understanding capabilities of MLLMs. However, this formulation requires the model to retain region-level target evidence while decoding coordinate tokens with the spatial precision demanded by GUI clicking. Our diagnostic analysis reveals that target-region awareness emerges in intermediate decoder layers but is neither retained nor translated into the final coordinate prediction. Existing ZoomIn-style methods address this issue through an external crop-and-rerun pass, which improves localization but increases end-to-end latency and computational cost. To retain the accuracy benefits of two-pass zooming without this extra cost, we propose InnerZoom, a single-forward framework for cross-layer evidence bridging. InnerZoom transforms target-related cues from the original forward pass into a compact cross-layer evidence state, then preserves, refines, and reinjects this state throughout later decoding layers to guide coordinate prediction. Extensive experimental results suggest that InnerZoom-4B achieves state-of-the-art performance on all six GUI grounding benchmarks, obtaining 64.7 on OSWorld-G, 40.2 on UI-Vision, 73.1 on OSWorld-GR, and 87.6 on MMBench-GUI, surpassing the previous best results by 4.1, 3.2, 2.9, and 2.3 points, respectively. Under a controlled 4B setting, InnerZoom improves the same SFT+RL baseline by 5.3 points on average and outperforms two-pass ZoomIn by 1.3 points on average, while reducing end-to-end latency by up to 31.8% and TFLOPs by about 29%. Code and models will be publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InnerZoom, a single-forward-pass framework for MLLM-based GUI grounding that extracts target-region awareness from intermediate decoder layers into a compact cross-layer evidence state, then preserves, refines, and reinjects this state into later layers to guide autoregressive coordinate token prediction. This is positioned as retaining the accuracy benefits of two-pass ZoomIn-style external cropping without the added latency. The manuscript reports SOTA results across six benchmarks (e.g., 64.7 on OSWorld-G, 40.2 on UI-Vision), with a 5.3-point average gain over a controlled 4B SFT+RL baseline and 1.3-point gain over ZoomIn, plus up to 31.8% latency and 29% TFLOPs reductions.
Significance. If the cross-layer bridging mechanism can be shown to preserve the spatial precision required for coordinate prediction without information loss, the result would be significant for efficient GUI agent systems, as it offers a way to improve localization accuracy in autoregressive MLLMs while cutting the computational cost of multi-pass inference. Public release of code and models would strengthen reproducibility.
major comments (3)
- [Diagnostic analysis] Diagnostic analysis section: The observation that target-region awareness emerges in intermediate layers but is lost before final coordinate prediction is central to motivating InnerZoom, yet no quantitative evidence (e.g., layer-wise attention or feature similarity metrics) is provided to measure how much spatial detail is retained versus discarded when forming the compact evidence state; without this, the 5.3-point gain cannot be confidently attributed to the reinjection mechanism rather than other training factors.
- [Method] Method description of the evidence state transformation: The claim that the compact cross-layer evidence state can be preserved, refined, and reinjected without loss of fine-grained spatial cues (necessary for pixel-accurate clicking) is load-bearing for both the accuracy and single-forward efficiency claims, but the manuscript provides no ablation on state dimensionality, no visualization of reinjected features, and no comparison of boundary precision before/after compaction; this directly tests the skeptic concern that compaction may discard the cues that external cropping would otherwise supply.
- [Experiments] Experimental results, controlled 4B setting: The reported 1.3-point average improvement over two-pass ZoomIn and 29% TFLOPs reduction are presented without a breakdown of the bridging module's own compute overhead or confirmation that the baseline and ZoomIn comparisons use identical training data, hyperparameters, and evaluation protocols; this is required to establish that the single-forward gains follow from the proposed bridging rather than implementation differences.
minor comments (2)
- The abstract and results tables would benefit from explicit citation of the exact benchmark versions and evaluation protocols used for the six GUI grounding tasks to allow direct replication.
- Notation for the cross-layer evidence state (e.g., how it is concatenated or attended with decoder hidden states) should be formalized with an equation or pseudocode for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the diagnostic analysis, method validation, and experimental details.
read point-by-point responses
-
Referee: [Diagnostic analysis] Diagnostic analysis section: The observation that target-region awareness emerges in intermediate layers but is lost before final coordinate prediction is central to motivating InnerZoom, yet no quantitative evidence (e.g., layer-wise attention or feature similarity metrics) is provided to measure how much spatial detail is retained versus discarded when forming the compact evidence state; without this, the 5.3-point gain cannot be confidently attributed to the reinjection mechanism rather than other training factors.
Authors: We agree that quantitative support would strengthen attribution of the gains. In revision we will add layer-wise analyses including cosine similarity between intermediate decoder features and target-region embeddings, plus attention map comparisons, to quantify retention versus loss of spatial detail across layers. revision: yes
-
Referee: [Method] Method description of the evidence state transformation: The claim that the compact cross-layer evidence state can be preserved, refined, and reinjected without loss of fine-grained spatial cues (necessary for pixel-accurate clicking) is load-bearing for both the accuracy and single-forward efficiency claims, but the manuscript provides no ablation on state dimensionality, no visualization of reinjected features, and no comparison of boundary precision before/after compaction; this directly tests the skeptic concern that compaction may discard the cues that external cropping would otherwise supply.
Authors: We will add the requested validation: ablations on evidence-state dimensionality, visualizations of reinjected features at selected layers, and boundary-precision metrics (e.g., click success at sub-pixel thresholds) comparing pre- and post-compaction states to confirm preservation of fine-grained cues. revision: yes
-
Referee: [Experiments] Experimental results, controlled 4B setting: The reported 1.3-point average improvement over two-pass ZoomIn and 29% TFLOPs reduction are presented without a breakdown of the bridging module's own compute overhead or confirmation that the baseline and ZoomIn comparisons use identical training data, hyperparameters, and evaluation protocols; this is required to establish that the single-forward gains follow from the proposed bridging rather than implementation differences.
Authors: The controlled 4B experiments used identical training data, hyperparameters, and evaluation protocols across the SFT+RL baseline, ZoomIn, and InnerZoom; we will state this explicitly. We will also add a breakdown of the bridging module's overhead (which is small because it reuses existing activations within the single forward pass) to isolate its contribution to the reported latency and TFLOPs savings. revision: yes
Circularity Check
No significant circularity; architectural proposal validated on external benchmarks
full rationale
The paper describes an architectural change (InnerZoom) that extracts and reinjects cross-layer evidence in a single forward pass. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text that would reduce the claimed accuracy or efficiency gains to a definitional equivalence. Performance numbers are reported against independent benchmarks and controlled baselines (SFT+RL, ZoomIn), making the derivation self-contained rather than circular. Minor self-citation is possible in a full manuscript but is not load-bearing here.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[6]
Seeclick: Harnessing gui grounding for advanced visual gui agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Li YanTao, Jianbing Zhang, and Zhiyong Wu. Seeclick: Harnessing gui grounding for advanced visual gui agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9313--9332, 2024
2024
-
[7]
Flashattention: Fast and memory-efficient exact attention with io-awareness
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher R \'e . Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in neural information processing systems, 35: 0 16344--16359, 2022
2022
-
[8]
Test-time reinforcement learning for gui grounding via region consistency
Yong Du, Yuchen Yan, Fei Tang, Zhengxi Lu, Chang Zong, Weiming Lu, Shengpei Jiang, and Yongliang Shen. Test-time reinforcement learning for gui grounding via region consistency. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 30593--30601, 2026
2026
-
[9]
Navigating the digital world as humans do: Universal visual grounding for GUI agents
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. Navigating the digital world as humans do: Universal visual grounding for GUI agents. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=kxnoqaisCT
2025
-
[12]
Zonui-3b: Competitive gui grounding with a 3b vlm trained on a single consumer gpu
ZongHan Hsieh, ShengJing Yang, and Tzer-Jen Wei. Zonui-3b: Competitive gui grounding with a 3b vlm trained on a single consumer gpu. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 959--966, 2026
2026
-
[15]
Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web, 2024
Raghav Kapoor, Yash Parag Butala, Melisa Russak, Jing Yu Koh, Kiran Kamble, Waseem Alshikh, and Ruslan Salakhutdinov. Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web, 2024
2024
-
[17]
Gui-spotlight: Adaptive iterative focus refinement for enhanced gui visual grounding
Bin Lei, Nuo Xu, Ali Payani, Mingyi Hong, Chunhua Liao, Yu Cao, and Caiwen Ding. Gui-spotlight: Adaptive iterative focus refinement for enhanced gui visual grounding. 2025
2025
-
[19]
Screenspot-pro: GUI grounding for professional high-resolution computer use
Kaixin Li, Meng Ziyang, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. Screenspot-pro: GUI grounding for professional high-resolution computer use. In Workshop on Reasoning and Planning for Large Language Models, 2025 b . URL https://openreview.net/forum?id=XaKNDIAHas
2025
-
[20]
On the effects of data scale on ui control agents, 2024
Wei Li, William Bishop, Alice Li, Chris Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. On the effects of data scale on ui control agents, 2024. URL https://arxiv.org/abs/2406.03679
-
[22]
Showui: One vision-language-action model for gui visual agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Stan Weixian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for gui visual agent. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19498--19508, 2025 a
2025
-
[23]
Boosting multimodal large language models with visual tokens withdrawal for rapid inference
Zhihang Lin, Mingbao Lin, Luxi Lin, and Rongrong Ji. Boosting multimodal large language models with visual tokens withdrawal for rapid inference. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 5334--5342, 2025 b
2025
-
[25]
Infigui-g1: Advancing gui grounding with adaptive exploration policy optimization
Yuhang Liu, Zeyu Liu, Shuanghe Zhu, Pengxiang Li, Congkai Xie, Jiasheng Wang, Xueyu Hu, Xiaotian Han, Jianbo Yuan, Xinyao Wang, et al. Infigui-g1: Advancing gui grounding with adaptive exploration policy optimization. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32267--32275, 2026 a
2026
-
[27]
Visual test-time scaling for gui agent grounding
Tiange Luo, Lajanugen Logeswaran, Justin Johnson, and Honglak Lee. Visual test-time scaling for gui agent grounding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 19989--19998, 2025
2025
-
[28]
Ray: A distributed framework for emerging \ AI \ applications
Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I Jordan, et al. Ray: A distributed framework for emerging \ AI \ applications. In 13th USENIX symposium on operating systems design and implementation (OSDI 18), pages 561--577, 2018
2018
-
[29]
Rodriguez, Montek Kalsi, Rabiul Awal, Nicolas Chapados, M
Shravan Nayak, Xiangru Jian, Kevin Qinghong Lin, Juan A. Rodriguez, Montek Kalsi, Rabiul Awal, Nicolas Chapados, M. Tamer Özsu, Aishwarya Agrawal, David Vazquez, Christopher Pal, Perouz Taslakian, Spandana Gella, and Sai Rajeswar. Ui-vision: A desktop-centric gui benchmark for visual perception and interaction, 2025. URL https://arxiv.org/abs/2503.15661
-
[31]
Gui agents: A survey
Dang Nguyen, Jian Chen, Yu Wang, Gang Wu, Namyong Park, Zhengmian Hu, Hanjia Lyu, Junda Wu, Ryan Aponte, Yu Xia, et al. Gui agents: A survey. In Findings of the Association for Computational Linguistics: ACL 2025, pages 22522--22538, 2025
2025
-
[37]
Zero: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. In SC20: international conference for high performance computing, networking, storage and analysis, pages 1--16. IEEE, 2020
2020
-
[39]
Ui-tars-1.5
ByteDance Seed. Ui-tars-1.5. https://seed-tars.com/1.5, 2025
2025
-
[41]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Gui-g ^2 : Gaussian reward modeling for gui grounding
Fei Tang, Zhangxuan Gu, Zhengxi Lu, Xuyang Liu, Shuheng Shen, Changhua Meng, Wen Wang, Wenqi Zhang, Yongliang Shen, Weiming Lu, et al. Gui-g ^2 : Gaussian reward modeling for gui grounding. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33214--33222, 2026 b
2026
-
[47]
Charles, Zhilin Yang, and Tao Yu
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Henry Wu, Zhennan Shen, Zhuokai Li, Ryan Li, Xiaochuan Li, Junda Chen, Boyuan Zheng, Peihang Li, Fangyu Lei, Ruisheng Cao, Yeqiao Fu, Dongchan Shin, Martin Shin, Jiarui Hu, Yuyan Wang, Jixuan Chen, Yuxiao Ye, Danyang Zhang, Dikang Du, Hao Hu,...
-
[48]
Opencua: Open foundations for computer-use agents
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Wu, et al. Opencua: Open foundations for computer-use agents. Advances in Neural Information Processing Systems, 38: 0 139756--139806, 2026
2026
-
[50]
Dimo-gui: Advancing test-time scaling in gui grounding via modality-aware visual reasoning
Hang Wu, Hongkai Chen, Yujun Cai, Chang Liu, Qingwen Ye, Ming-Hsuan Yang, and Yiwei Wang. Dimo-gui: Advancing test-time scaling in gui grounding via modality-aware visual reasoning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 26257--26267, 2025 a
2025
-
[51]
Gui-actor: Coordinate-free visual grounding for gui agents
Qianhui Wu, Kanzhi Cheng, Rui Yang, Chaoyun Zhang, Jianwei Yang, Huiqiang Jiang, Jian Mu, Baolin Peng, Bo Qiao, Reuben Tan, et al. Gui-actor: Coordinate-free visual grounding for gui agents. Advances in Neural Information Processing Systems, 38: 0 15101--15128, 2026
2026
-
[53]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, and Yu Qiao. Os-atlas: A foundation action model for generalist gui agents, 2024 b . URL https://arxiv.org/abs/2410.23218
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Os-atlas: Foundation action model for generalist gui agents
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. Os-atlas: Foundation action model for generalist gui agents. In International Conference on Learning Representations, volume 2025, pages 5090--5108, 2025 b
2025
-
[55]
Scaling computer-use grounding via user interface decomposition and synthesis, 2025
Tianbao Xie, Jiaqi Deng, Xiaochuan Li, Junlin Yang, Haoyuan Wu, Jixuan Chen, Wenjing Hu, Xinyuan Wang, Yuhui Xu, Zekun Wang, Yiheng Xu, Junli Wang, Doyen Sahoo, Tao Yu, and Caiming Xiong. Scaling computer-use grounding via user interface decomposition and synthesis, 2025. URL https://arxiv.org/abs/2505.13227
-
[56]
Scaling computer-use grounding via user interface decomposition and synthesis
Tianbao Xie, Jiaqi Deng, Xiaochuan Li, Junlin Yang, Haoyuan Wu, Jixuan Chen, Wenjing Hu, Xinyuan Wang, Yuhui Xu, Zekun Wang, et al. Scaling computer-use grounding via user interface decomposition and synthesis. Advances in Neural Information Processing Systems, 38, 2026
2026
-
[61]
GTA1: GUI Test-time Scaling Agent
Yan Yang, Dongxu Li, Yutong Dai, Yuhao Yang, Ziyang Luo, Zirui Zhao, Zhiyuan Hu, Junzhe Huang, Amrita Saha, Zeyuan Chen, Ran Xu, Liyuan Pan, Caiming Xiong, and Junnan Li. Gta1: Gui test-time scaling agent, 2025 a . URL https://arxiv.org/abs/2507.05791
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems
Yingxuan Yang, Huacan Chai, Shuai Shao, Yuanyi Song, Siyuan Qi, Renting Rui, and Weinan Zhang. Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems. Advances in Neural Information Processing Systems, 38: 0 107309--107336, 2026
2026
-
[63]
Aria-ui: Visual grounding for gui instructions
Yuhao Yang, Yue Wang, Dongxu Li, Ziyang Luo, Bei Chen, Chao Huang, and Junnan Li. Aria-ui: Visual grounding for gui instructions. In Findings of the Association for Computational Linguistics: ACL 2025, pages 22418--22433, 2025 b
2025
-
[66]
Se-gui: Enhancing visual grounding for gui agents via self-evolutionary reinforcement learning
Xinbin Yuan, Jian Zhang, Kaixin Li, Zhuoxuan Cai, Lujian Yao, Jie Chen, Enguang Wang, Qibin Hou, Jinwei Chen, Peng-Tao Jiang, et al. Se-gui: Enhancing visual grounding for gui agents via self-evolutionary reinforcement learning. Advances in Neural Information Processing Systems, 38: 0 127658--127679, 2026
2026
-
[67]
Manicog: Training-free improvement for gui grounding via manipulation chains
Borui Zhang, Bo Zhang, Bo Wang, Wenzhao Zheng, Yuhao Cheng, Liang Tang, Yiqiang Yan, Jie Zhou, and Jiwen Lu. Manicog: Training-free improvement for gui grounding via manipulation chains
-
[74]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
ZonUI-3B: Competitive GUI Grounding with a 3B VLM Trained on a Single Consumer GPU , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[75]
arXiv preprint arXiv:2602.06391 , year=
POINTS-GUI-G: GUI-Grounding Journey , author=. arXiv preprint arXiv:2602.06391 , year=
-
[76]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Seeclick: Harnessing gui grounding for advanced visual gui agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[77]
UGround: Towards Unified Visual Grounding with Unrolled Transformers
Uground: Towards unified visual grounding with unrolled transformers , author=. arXiv preprint arXiv:2510.03853 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
International Conference on Learning Representations , volume=
OS-ATLAS: Foundation action model for generalist GUI agents , author=. International Conference on Learning Representations , volume=
-
[79]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Showui: One vision-language-action model for gui visual agent , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[80]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Ui-tars: Pioneering automated gui interaction with native agents , author=. arXiv preprint arXiv:2501.12326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[81]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning , author=. arXiv preprint arXiv:2509.02544 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[82]
arXiv preprint arXiv:2510.20286 , year=
UI-Ins: Enhancing GUI Grounding with Multi-Perspective Instruction-as-Reasoning , author=. arXiv preprint arXiv:2510.20286 , year=
-
[83]
arXiv preprint arXiv:2512.22047 , year=
MAI-UI Technical Report: Real-World Centric Foundation GUI Agents , author=. arXiv preprint arXiv:2512.22047 , year=
-
[84]
5: Multi-platform fundamental gui agents , author=
Mobile-agent-v3. 5: Multi-platform fundamental gui agents , author=. arXiv preprint arXiv:2602.16855 , year=
-
[85]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Aria-ui: Visual grounding for gui instructions , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[86]
arXiv preprint arXiv:2406.13719 , year=
GUI Action Narrator: Where and When Did That Action Take Place? , author=. arXiv preprint arXiv:2406.13719 , year=
-
[87]
Advances in Neural Information Processing Systems , volume=
Se-gui: Enhancing visual grounding for gui agents via self-evolutionary reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[88]
Advances in Neural Information Processing Systems , volume=
Gui-actor: Coordinate-free visual grounding for gui agents , author=. Advances in Neural Information Processing Systems , volume=
-
[89]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
GUI-G ^2 : Gaussian Reward Modeling for GUI Grounding , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[90]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Test-time reinforcement learning for gui grounding via region consistency , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[91]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Gui-r1: A generalist r1-style vision-language action model for gui agents , author=. arXiv preprint arXiv:2504.10458 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[92]
Advances in Neural Information Processing Systems , volume=
Opencua: Open foundations for computer-use agents , author=. Advances in Neural Information Processing Systems , volume=
-
[93]
arXiv preprint arXiv:2508.10833 , year=
Ui-venus technical report: Building high-performance ui agents with rft , author=. arXiv preprint arXiv:2508.10833 , year=
-
[94]
arXiv preprint arXiv:2602.09082 , year=
Ui-venus-1.5 technical report , author=. arXiv preprint arXiv:2602.09082 , year=
-
[95]
arXiv preprint arXiv:2601.15876 , year=
Evocua: Evolving computer use agents via learning from scalable synthetic experience , author=. arXiv preprint arXiv:2601.15876 , year=
-
[96]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Cogagent: A visual language model for gui agents , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[97]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Infigui-g1: Advancing gui grounding with adaptive exploration policy optimization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[98]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Visual test-time scaling for gui agent grounding , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[99]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Dimo-gui: Advancing test-time scaling in gui grounding via modality-aware visual reasoning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[100]
arXiv preprint arXiv:2512.05941 , year=
Zoom in, Click out: Unlocking and Evaluating the Potential of Zooming for GUI Grounding , author=. arXiv preprint arXiv:2512.05941 , year=
-
[101]
UI-Zoomer: Uncertainty-Driven Adaptive Zoom-In for GUI Grounding
UI-Zoomer: Uncertainty-Driven Adaptive Zoom-In for GUI Grounding , author=. arXiv preprint arXiv:2604.14113 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[102]
arXiv preprint arXiv:2512.08529 , year=
MVP: Multiple View Prediction Improves GUI Grounding , author=. arXiv preprint arXiv:2512.08529 , year=
-
[103]
What Happens Before Decoding? Prefill Determines GUI Grounding in VLMs
What Happens Before Decoding? Prefill Determines GUI Grounding in VLMs , author=. arXiv preprint arXiv:2605.12549 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[104]
arXiv preprint arXiv:2512.01979 , year=
Chain-of-Ground: Improving GUI Grounding via Iterative Reasoning and Reference Feedback , author=. arXiv preprint arXiv:2512.01979 , year=
-
[105]
GUI-Spotlight: Adaptive Iterative Focus Refinement for Enhanced GUI Visual Grounding , author=
-
[106]
arXiv preprint arXiv:2505.15259 , year=
ReGUIDE: Data Efficient GUI Grounding via Spatial Reasoning and Search , author=. arXiv preprint arXiv:2505.15259 , year=
-
[107]
AutoFocus: Uncertainty-Aware Active Visual Search for GUI Grounding
AutoFocus: Uncertainty-Aware Active Visual Search for GUI Grounding , author=. arXiv preprint arXiv:2605.02630 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[108]
arXiv preprint arXiv:2411.13591 , year=
Improved gui grounding via iterative narrowing , author=. arXiv preprint arXiv:2411.13591 , year=
-
[109]
arXiv preprint arXiv:2601.09770 , year=
GUI-Eyes: Tool-Augmented Perception for Visual Grounding in GUI Agents , author=. arXiv preprint arXiv:2601.09770 , year=
-
[110]
arXiv preprint arXiv:2511.00810 , year=
Gui-aima: Aligning intrinsic multimodal attention with a context anchor for gui grounding , author=. arXiv preprint arXiv:2511.00810 , year=
-
[111]
arXiv preprint arXiv:2601.06899 , year=
V2P: Visual Attention Calibration for GUI Grounding via Background Suppression and Center Peaking , author=. arXiv preprint arXiv:2601.06899 , year=
-
[112]
ManiCoG: Training-Free Improvement for GUI Grounding via Manipulation Chains , author=
-
[113]
arXiv preprint arXiv:2603.17441 , year=
Adazoom-gui: Adaptive zoom-based gui grounding with instruction refinement , author=. arXiv preprint arXiv:2603.17441 , year=
-
[114]
arXiv preprint arXiv:2603.14448 , year=
Zoom to Essence: Trainless GUI Grounding by Inferring upon Interface Elements , author=. arXiv preprint arXiv:2603.14448 , year=
-
[115]
BAMI: Training-Free Bias Mitigation in GUI Grounding
BAMI: Training-Free Bias Mitigation in GUI Grounding , author=. arXiv preprint arXiv:2605.06664 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[116]
arXiv preprint arXiv:2510.03230 , year=
Improving GUI Grounding with Explicit Position-to-Coordinate Mapping , author=. arXiv preprint arXiv:2510.03230 , year=
-
[117]
Qwen3-VL Technical Report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[118]
2025 , eprint=
Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis , author=. 2025 , eprint=
2025
-
[119]
2025 , eprint=
UI-Vision: A Desktop-centric GUI Benchmark for Visual Perception and Interaction , author=. 2025 , eprint=
2025
-
[120]
ScreenSpot-Pro:
Kaixin Li and Meng Ziyang and Hongzhan Lin and Ziyang Luo and Yuchen Tian and Jing Ma and Zhiyong Huang and Tat-Seng Chua , booktitle=. ScreenSpot-Pro:. 2025 , url=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.