DPPE: Rethinking Camera-Based Positional Encoding for Scaling Multi-View Transformers
Pith reviewed 2026-07-01 05:37 UTC · model grok-4.3
The pith
Decoupling rotation and translation in camera positional encodings resolves indeterminacy that stalls late-stage training in multi-view transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
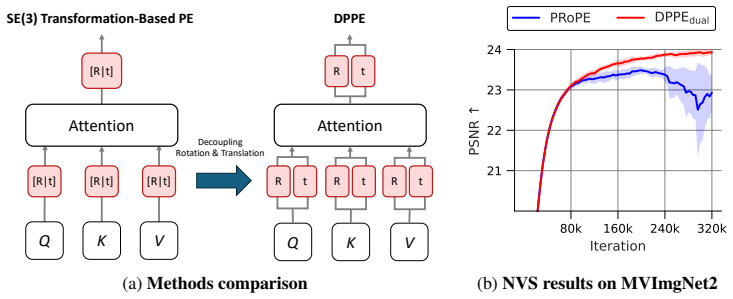
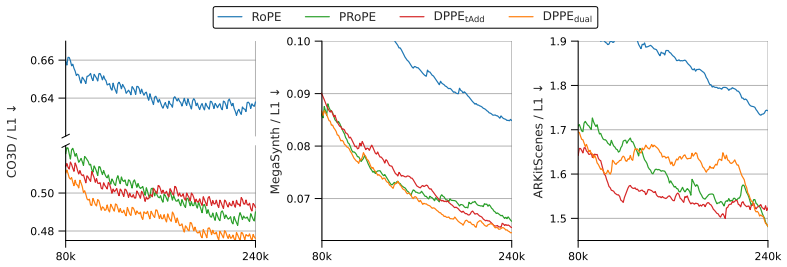
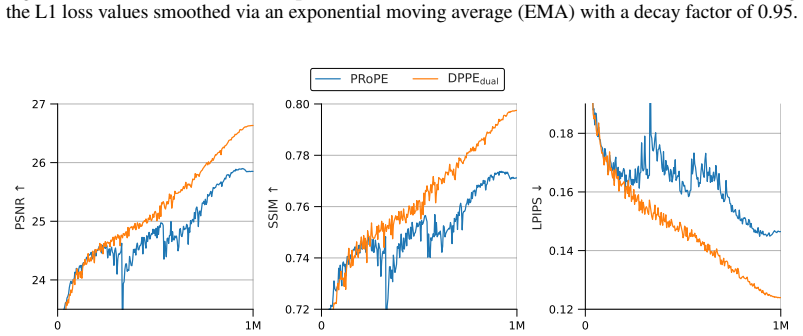
Storing rotation and translation given by the positional encoding in the same dimensions of the value vector causes indeterminacy in their independent identification, hindering training scalability. DPPE explicitly decouples rotation and translation to enable stable long-term training.
What carries the argument
Decoupled Pose Positional Encoding (DPPE), which splits rotation and translation from camera extrinsics into separate channels before insertion into query, key, and value vectors.
If this is right
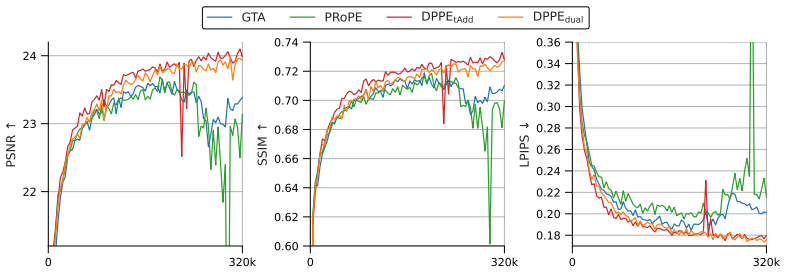
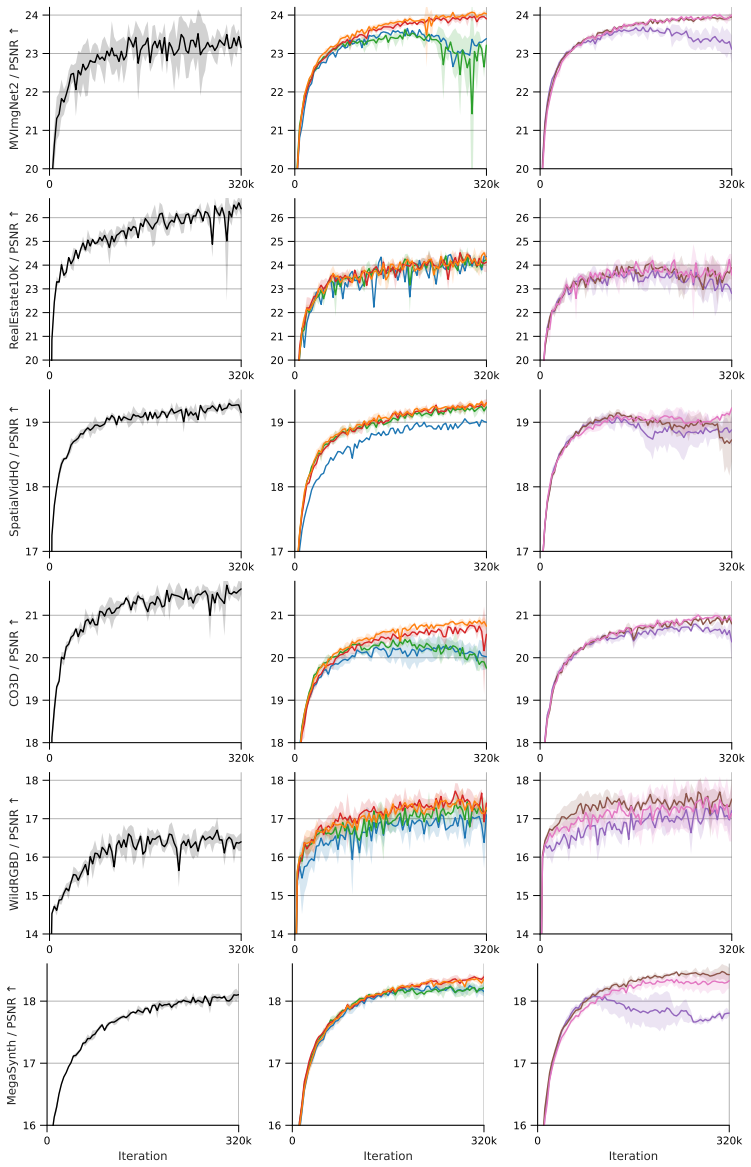
- Scaled-up NVS training proceeds without performance stagnation once rotation and translation are decoupled.
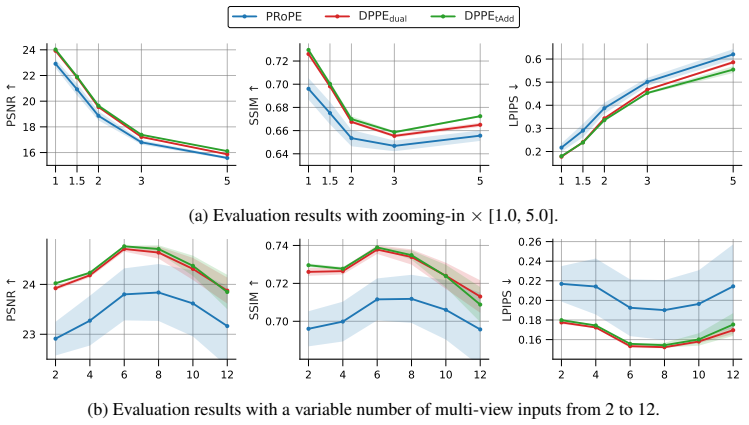
- The model generalizes better when the number of input viewpoints increases beyond the training distribution.
- Performance improves in zoom-in extrapolation scenarios that change the camera intrinsics relative to training.
- The original practice of injecting camera parameters as relative positional encoding is retained, only the mixing inside the value vector is removed.
Where Pith is reading between the lines
- The same indeterminacy may appear in any transformer that injects rigid-body pose into shared embedding dimensions, suggesting the fix could transfer to other 3D geometry tasks.
- If the decoupling is the dominant factor, further scaling laws for multi-view models should now be re-measured under the new encoding.
- Alternative ways to separate the two degrees of freedom (for example, separate attention heads) could be compared directly against DPPE.
Load-bearing premise
The late-training stagnation is caused specifically by rotation and translation sharing value-vector dimensions rather than by optimization, data, or capacity limits.
What would settle it
A controlled experiment that scales the same NVS model with and without the shared-dimension setup and finds no difference in late-stage plateauing would falsify the causal claim.
Figures



read the original abstract
The remarkable scalability of Transformers has expanded their application to 3D computer vision, where camera-aware positional encoding is crucial for providing spatial cues in multi-view geometry. Recent advancements have established the practice of using camera parameters -- such as extrinsics or projection matrices -- as relative positional encoding into the query, key, and value vectors of the attention mechanism. However, when scaling up the training recipe of novel view synthesis (NVS) models with the camera-based positional encoding, we observe a significant issue: model performance stagnates in the late stages of training. In this paper, we investigate the cause of the performance bottleneck when scaling up and demonstrate that storing rotation and translation given by the positional encoding in the same dimensions of the value vector causes indeterminacy in their independent identification, hindering training scalability. To address this, we propose Decoupled Pose Positional Encoding (DPPE), a novel camera-based positional encoding that explicitly decouples rotation and translation. Extensive evaluations on NVS tasks demonstrate that DPPE enables stable long-term training even in scaled-up training setup. Furthermore, it exhibits superior generalization performance in extrapolation settings, such as handling an increased number of viewpoints and zoom-in scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that camera-based positional encodings in multi-view transformers for novel view synthesis suffer from performance stagnation during scaled training because rotation and translation parameters are stored in shared dimensions of the value vectors, leading to indeterminacy in their identification. To address this, the authors propose Decoupled Pose Positional Encoding (DPPE) that explicitly separates rotation and translation, demonstrating through evaluations that it enables stable long-term training and improved generalization in extrapolation scenarios such as increased viewpoints and zoom-in.
Significance. If the causal diagnosis is correct and the empirical results hold, DPPE could represent a meaningful advance in scaling camera-aware transformers for 3D vision tasks. The structural decoupling addresses a potential source of training instability without introducing additional parameters, which is a strength. This could facilitate larger-scale training of NVS models and better handling of varying camera configurations.
major comments (1)
- [Investigation of cause (abstract and corresponding experimental section)] The central claim that shared dimensions for rotation and translation in the value vector cause indeterminacy (and thus stagnation) is load-bearing for the motivation and design of DPPE. The abstract states that the authors 'investigate the cause' and 'demonstrate' this mechanism, but provides no description of the controls, ablations, or measurements (e.g., holding optimization dynamics, data distribution, and model capacity fixed while varying only the shared vs. decoupled dimensions) used to establish the specific causal attribution over other scaling factors. If the relevant investigation section does not contain such isolating experiments, the weakest assumption identified in the stress-test remains unaddressed.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive critique. The concern about the strength of the causal evidence for the shared-dimension indeterminacy mechanism is well-taken; we address it point-by-point below and indicate where clarification or additional detail will be added.
read point-by-point responses
-
Referee: [Investigation of cause (abstract and corresponding experimental section)] The central claim that shared dimensions for rotation and translation in the value vector cause indeterminacy (and thus stagnation) is load-bearing for the motivation and design of DPPE. The abstract states that the authors 'investigate the cause' and 'demonstrate' this mechanism, but provides no description of the controls, ablations, or measurements (e.g., holding optimization dynamics, data distribution, and model capacity fixed while varying only the shared vs. decoupled dimensions) used to establish the specific causal attribution over other scaling factors. If the relevant investigation section does not contain such isolating experiments, the weakest assumption identified in the stress-test remains unaddressed.
Authors: We agree that a precise description of the experimental controls is necessary to support the causal claim. Section 4.1 presents training curves and attention-map analyses comparing otherwise identical models (same architecture, dataset, optimizer schedule, and random seeds) that differ only in whether rotation and translation parameters share value-vector dimensions. The shared-dimension variant exhibits the reported late-stage stagnation while the decoupled variant does not; additional controls vary only the number of shared dimensions while keeping total model capacity fixed. Nevertheless, the current text does not explicitly enumerate every held-constant factor in a single paragraph. We will revise Section 4.1 (and the abstract) to include a dedicated “controlled comparison” subsection that lists the fixed variables and the single manipulated variable, thereby making the isolating nature of the experiments explicit. revision: partial
Circularity Check
No circularity: empirical attribution and structural fix remain independent of inputs
full rationale
The paper's chain begins with an observed empirical stagnation during scaled NVS training, followed by an attribution to shared rot/trans dimensions in value vectors, and a proposed structural decoupling via DPPE. No equations, self-citations, or fitted parameters are shown reducing the central claim to a tautology or renaming of the input data. The demonstration is presented as experimental (performance recovery after decoupling), not derived by construction from the stagnation observation itself. This is the normal non-circular case for an empirical diagnosis plus architectural change.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[2]
Lvsm: A large view synthesis model with minimal 3d inductive bias
Haian Jin, Hanwen Jiang, Hao Tan, Kai Zhang, Sai Bi, Tianyuan Zhang, Fujun Luan, Noah Snavely, and Zexiang Xu. Lvsm: A large view synthesis model with minimal 3d inductive bias. arXiv preprint arXiv:2410.17242, 2024
-
[3]
arXiv preprint arXiv:2507.10496 (2025)
Ruilong Li, Brent Yi, Junchen Liu, Hang Gao, Yi Ma, and Angjoo Kanazawa. Cameras as relative positional encoding.arXiv preprint arXiv:2507.10496, 2025
-
[4]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[5]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, et al. Mapanything: Universal feed-forward metric 3d reconstruction.arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Self-attention with relative position rep- resentations
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position rep- resentations. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 464–468, 2018
2018
-
[8]
Conditional positional encodings for vision transformers.arXiv preprint arXiv:2102.10882, 2021
Xiangxiang Chu, Zhi Tian, Bo Zhang, Xinlong Wang, and Chunhua Shen. Conditional positional encodings for vision transformers.arXiv preprint arXiv:2102.10882, 2021
-
[9]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Ofir Press, Noah A Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation.arXiv preprint arXiv:2108.12409, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[11]
Rotary position embedding for vision transformer
Byeongho Heo, Song Park, Dongyoon Han, and Sangdoo Yun. Rotary position embedding for vision transformer. InEuropean Conference on Computer Vision, pages 289–305. Springer, 2024
2024
-
[12]
Circle-RoPE: Cone-like Decoupled Rotary Positional Embedding for Large Vision-Language Models
Chengcheng Wang, Jianyuan Guo, Hongguang Li, Yuchuan Tian, Ying Nie, Chang Xu, and Kai Han. Circle-rope: Cone-like decoupled rotary positional embedding for large vision-language models.arXiv preprint arXiv:2505.16416, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Positional encoding as spatial inductive bias in gans
Rui Xu, Xintao Wang, Kai Chen, Bolei Zhou, and Chen Change Loy. Positional encoding as spatial inductive bias in gans. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13569–13578, 2021
2021
-
[14]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
2020
-
[15]
Rethinking positional encoding in language pre-training
Guolin Ke, Di He, and Tie-Yan Liu. Rethinking positional encoding in language pre-training. arXiv preprint arXiv:2006.15595, 2020
-
[16]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. Deberta: Decoding-enhanced bert with disentangled attention.arXiv preprint arXiv:2006.03654, 2020. 10
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[17]
Haoyu Liu, Sucheng Ren, Tingyu Zhu, Peng Wang, Cihang Xie, Alan Yuille, Zeyu Zheng, and Feng Wang. Spiral rope: Rotate your rotary positional embeddings in the 2d plane.arXiv preprint arXiv:2602.03227, 2026
-
[18]
Yoav Gelberg, Koshi Eguchi, Takuya Akiba, and Edoardo Cetin. Extending the context of pretrained llms by dropping their positional embeddings.arXiv preprint arXiv:2512.12167, 2025
-
[19]
Eschernet: A generative model for scalable view synthesis
Xin Kong, Shikun Liu, Xiaoyang Lyu, Marwan Taher, Xiaojuan Qi, and Andrew J Davison. Eschernet: A generative model for scalable view synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9503–9513, 2024
2024
- [20]
-
[21]
Yu Wu, Minsik Jeon, Jen-Hao Rick Chang, Oncel Tuzel, and Shubham Tulsiani. Rayrope: Projective ray positional encoding for multi-view attention.arXiv preprint arXiv:2601.15275, 2026
- [22]
-
[23]
URoPE: Universal Relative Position Embedding across Geometric Spaces
Yichen Xie, Depu Meng, Chensheng Peng, Yihan Hu, Quentin Herau, Masayoshi Tomizuka, and Wei Zhan. Urope: Universal relative position embedding across geometric spaces.arXiv preprint arXiv:2604.18747, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Byeongjun Park, Byung-Hoon Kim, Hyungjin Chung, and Jong Chul Ye. Redirector: Creating any-length video retakes with rotary camera encoding.arXiv preprint arXiv:2511.19827, 2025
-
[25]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. Lgm: Large multi-view gaussian model for high-resolution 3d content creation. InEuropean Conference on Computer Vision, pages 1–18. Springer, 2024
2024
-
[26]
Gs-lrm: Large reconstruction model for 3d gaussian splatting
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, and Zexiang Xu. Gs-lrm: Large reconstruction model for 3d gaussian splatting. InEuropean Conference on Computer Vision, pages 1–19. Springer, 2024
2024
-
[27]
Grm: Large gaussian reconstruction model for efficient 3d reconstruction and generation
Yinghao Xu, Zifan Shi, Wang Yifan, Hansheng Chen, Ceyuan Yang, Sida Peng, Yujun Shen, and Gordon Wetzstein. Grm: Large gaussian reconstruction model for efficient 3d reconstruction and generation. InEuropean Conference on Computer Vision, pages 1–20. Springer, 2024
2024
-
[28]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025
2025
-
[29]
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T Barron, and Ben Poole. Cat3d: Create anything in 3d with multi-view diffusion models.arXiv preprint arXiv:2405.10314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [30]
-
[31]
Stereo Magnification: Learning View Synthesis using Multiplane Images
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnifi- cation: Learning view synthesis using multiplane images.arXiv preprint arXiv:1805.09817, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Jiahao Wang, Yufeng Yuan, Rujie Zheng, Youtian Lin, Jian Gao, Lin-Zhuo Chen, Yajie Bao, Yi Zhang, Chang Zeng, Yanxi Zhou, et al. Spatialvid: A large-scale video dataset with spatial annotations.arXiv preprint arXiv:2509.09676, 2025
-
[33]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4): 600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4): 600–612, 2004. 11
2004
-
[34]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[35]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[36]
Cambridge university press, 2003
Richard Hartley and Andrew Zisserman.Multiple view geometry in computer vision. Cambridge university press, 2003
2003
-
[37]
Scaling laws and compute-optimal training beyond fixed training durations.Advances in Neural Information Processing Systems, 37:76232–76264, 2024
Alexander Hägele, Elie Bakouch, Atli Kosson, Loubna B Allal, Leandro V on Werra, and Martin Jaggi. Scaling laws and compute-optimal training beyond fixed training durations.Advances in Neural Information Processing Systems, 37:76232–76264, 2024
2024
-
[38]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, et al. Minicpm: Unveiling the potential of small language models with scalable training strategies.arXiv preprint arXiv:2404.06395, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Smollm3: smol, multilingual, long-context reasoner.Hugging Face Blog, 2025
Elie Bakouch, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Lewis Tunstall, Car- los Miguel Patino, Edward Beeching, Aymeric Roucher, Aksel Joonas Reedi, Quentin Gal- louédec, et al. Smollm3: smol, multilingual, long-context reasoner.Hugging Face Blog, 2025
2025
-
[44]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. Llada2. 0: Scaling up diffusion language models to 100b.arXiv preprint arXiv:2512.15745, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. InProceedings of the IEEE/CVF international conference on computer vision, pages 10901–10911, 2021
2021
-
[46]
Rgbd objects in the wild: Scaling real-world 3d object learning from rgb-d videos
Hongchi Xia, Yang Fu, Sifei Liu, and Xiaolong Wang. Rgbd objects in the wild: Scaling real-world 3d object learning from rgb-d videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22378–22389, 2024
2024
-
[47]
Megasynth: Scaling up 3d scene reconstruction with synthesized data
Hanwen Jiang, Zexiang Xu, Desai Xie, Ziwen Chen, Haian Jin, Fujun Luan, Zhixin Shu, Kai Zhang, Sai Bi, Xin Sun, et al. Megasynth: Scaling up 3d scene reconstruction with synthesized data. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16441–16452, 2025
2025
-
[48]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
ARKitScenes: A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, et al. Arkitscenes: A diverse real- world dataset for 3d indoor scene understanding using mobile rgb-d data.arXiv preprint arXiv:2111.08897, 2021. 12 A Formulation of Self-Attention with DPPE tAdd We provide the explici...
work page internal anchor Pith review Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.