Active-GRPO: Adaptive Imitation and Self-Improving Reasoning for Molecular Optimization
Pith reviewed 2026-07-02 16:05 UTC · model grok-4.3
The pith
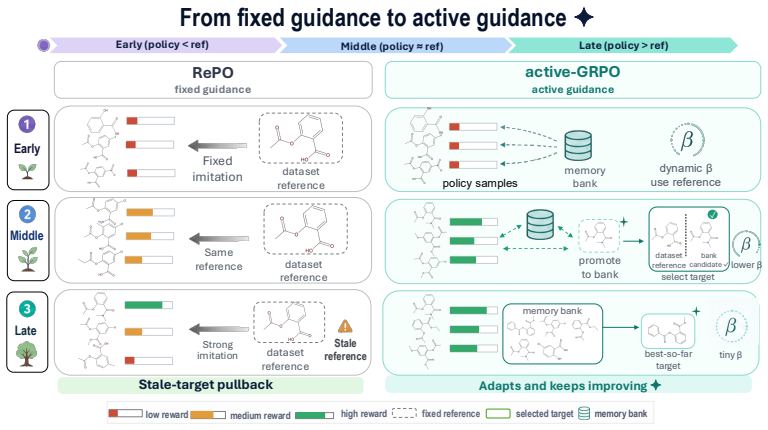
Active-GRPO lets the policy decide per instance whether to imitate a reference or reinforce its own superior molecules while continuously replacing the reference with better outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
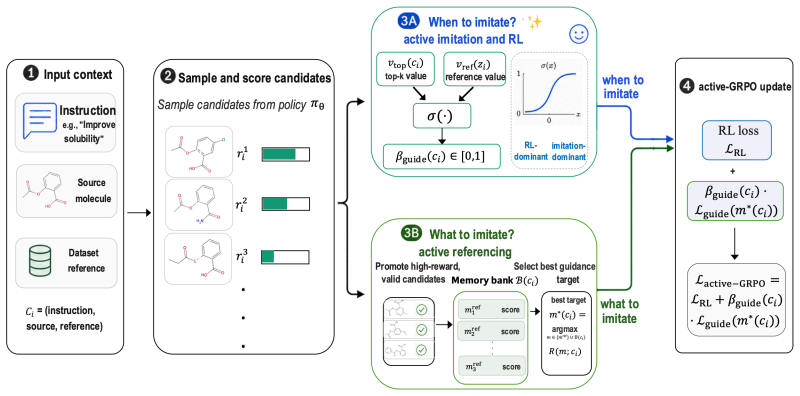
Active-GRPO performs imitation learning when the reference still outperforms the policy's own candidates and shifts to self-improvement via reinforcement learning once the policy has generated molecules that surpass the reference, while the active referencing mechanism continuously upgrades the reference itself by replacing it with the best policy-generated candidate discovered so far.
What carries the argument
active imitate-reinforce mechanism that switches training mode based on per-instance performance comparison between reference and policy candidates, coupled with active referencing that replaces the reference with superior policy outputs
Load-bearing premise
The policy can reliably generate candidates that surpass the current reference on a per-instance basis to trigger the shift from imitation to self-reinforcement, and that continuously replacing the reference with policy outputs keeps guidance informative without introducing instability or bias.
What would settle it
Run the method on the same benchmark starting from the initial references; if no policy-generated candidate ever exceeds its reference across all instances, the imitate-reinforce switch and reference upgrade never activate and performance remains identical to RePO.
Figures
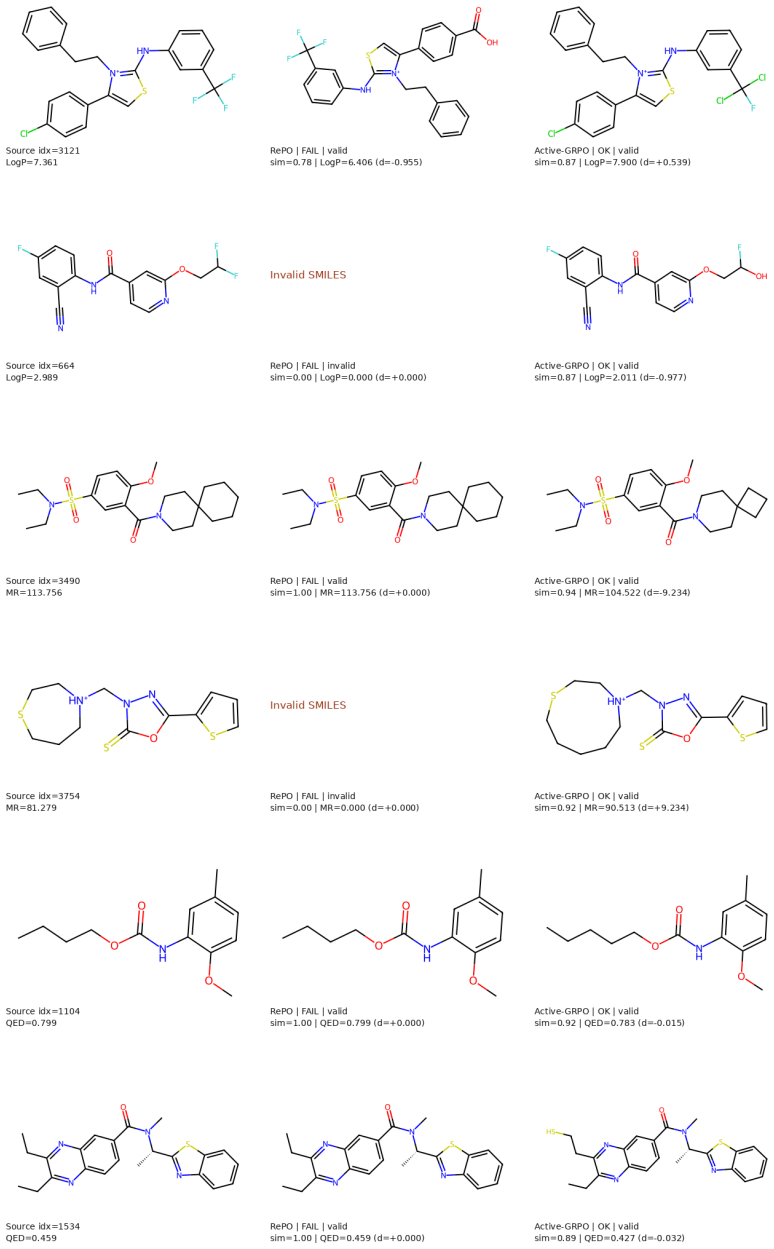
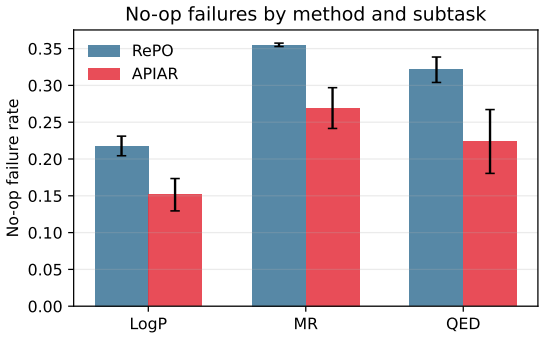
read the original abstract
Scientific reasoning is an increasingly important capability of large language models, yet improving the robustness and efficiency of training such reasoning remains a key open challenge. We study this problem in instruction-based molecular optimization, where answer-only supervised fine-tuning (SFT) collapses multi-step reasoning and reinforcement learning with verifiable rewards (RLVR) suffers from sparse feedback. Reference-guided Policy Optimization mitigates both by anchoring policy updates to dataset-provided references, but its effectiveness is tightly coupled to reference quality: weak or misaligned references impose a performance ceiling. To overcome this ceiling, we propose active reasoning, a paradigm in which the policy actively decides, on a per-instance basis, when to imitate a reference and when to reinforce its own discoveries, while continuously upgrading what it imitates. We instantiate this paradigm as Active Group Relative Policy Optimization (Active-GRPO), realized through two coupled mechanisms: active imitate-reinforce and active referencing. The former performs imitation learning when the reference still outperforms the policy's own candidates, and shifts to self-improvement via reinforcement learning once the policy has generated molecules that surpass the reference. The latter continuously upgrades the reference itself by replacing it with the best policy-generated candidate discovered so far, progressively raising the imitation target and ensuring that reference guidance remains informative-rather than restrictive-throughout training. Across TOMG-Bench MOLOPT, Active-GRPO improves average SRxSim from 0.0959 for GRPO and 0.1665 for RePO to 0.1773 under matched three-seed evaluation, with statistically significant gains on LogP, MR, and QED.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
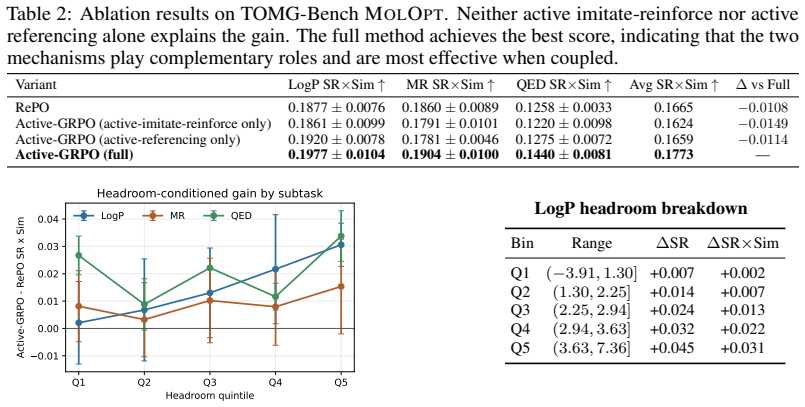
Summary. The paper proposes Active-GRPO, an extension of Group Relative Policy Optimization (GRPO) for instruction-based molecular optimization. It introduces two coupled mechanisms—active imitate-reinforce (switching from imitation to self-reinforcement once policy candidates surpass the reference) and active referencing (continuously replacing the reference with the best policy-generated molecule)—to overcome performance ceilings from fixed or weak references. The central empirical claim is that Active-GRPO achieves an average SRxSim of 0.1773 on TOMG-Bench MOLOPT, outperforming GRPO (0.0959) and RePO (0.1665) under matched three-seed evaluation, with statistically significant gains on LogP, MR, and QED tasks.
Significance. If the reported gains are robust and the active mechanisms demonstrably trigger and stabilize as described, the work would offer a concrete paradigm for enabling self-improving reasoning in reference-guided RL settings with sparse rewards, potentially applicable beyond molecular tasks to other scientific reasoning domains.
major comments (3)
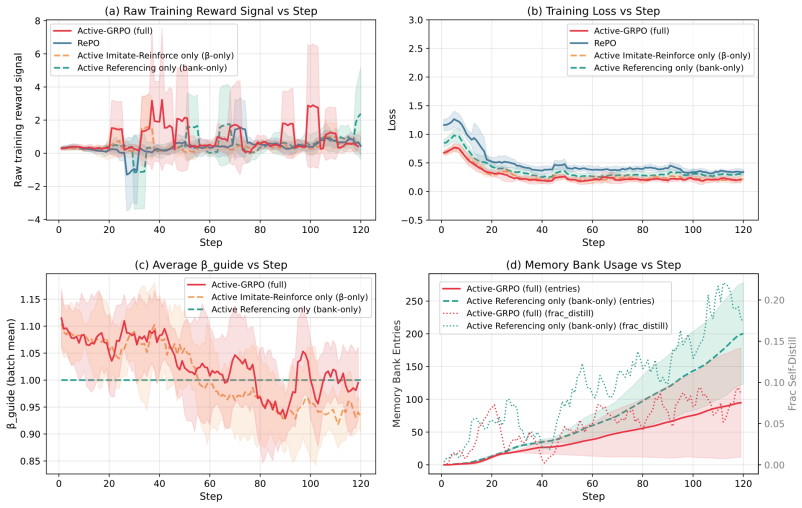
- [Abstract and Experiments section] The abstract and experimental results present performance gains as arising from the active imitate-reinforce switch and active referencing, yet provide no quantitative data (e.g., switch frequency per task, fraction of instances where policy surpasses reference, or reference-update counts) to confirm these mechanisms operate as claimed rather than defaulting to imitation mode.
- [Method description of active referencing] The active referencing mechanism (described as continuously upgrading the reference with policy outputs) lacks any reported analysis of stability, diversity, or bias amplification; in sparse-reward molecular optimization this risks the reference distribution collapsing toward early suboptimal discoveries without explicit regularization.
- [Abstract and Table reporting TOMG-Bench MOLOPT results] The claim of 'statistically significant gains' on LogP, MR, and QED is stated without accompanying details on the exact test, p-values, or per-seed variances, making it impossible to assess whether the three-seed evaluation supports the cross-method superiority asserted.
minor comments (1)
- [Abstract] Notation for SRxSim and other metrics should be defined on first use with a brief equation or reference to prior work.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that additional quantitative evidence for the active mechanisms and fuller statistical reporting would strengthen the manuscript. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract and Experiments section] The abstract and experimental results present performance gains as arising from the active imitate-reinforce switch and active referencing, yet provide no quantitative data (e.g., switch frequency per task, fraction of instances where policy surpasses reference, or reference-update counts) to confirm these mechanisms operate as claimed rather than defaulting to imitation mode.
Authors: We agree that the current version lacks these supporting metrics. In the revised manuscript we will add a dedicated subsection (and accompanying table) in the Experiments section that reports, for each task: (i) the fraction of training instances where the policy first surpasses the reference, (ii) the average number of imitate-to-reinforce switches per epoch, and (iii) the total number of reference updates performed. These statistics will be computed from the same three seeds used for the main results. revision: yes
-
Referee: [Method description of active referencing] The active referencing mechanism (described as continuously upgrading the reference with policy outputs) lacks any reported analysis of stability, diversity, or bias amplification; in sparse-reward molecular optimization this risks the reference distribution collapsing toward early suboptimal discoveries without explicit regularization.
Authors: We acknowledge the absence of such analysis. We will add a new paragraph in the Method section together with an appendix figure that tracks (a) reference-molecule diversity (Tanimoto distance to prior references), (b) reward trajectory of the reference itself, and (c) a simple entropy measure of the reference distribution over training. If the analysis reveals premature collapse on any task we will also report the effect of adding a diversity regularizer as an ablation. revision: yes
-
Referee: [Abstract and Table reporting TOMG-Bench MOLOPT results] The claim of 'statistically significant gains' on LogP, MR, and QED is stated without accompanying details on the exact test, p-values, or per-seed variances, making it impossible to assess whether the three-seed evaluation supports the cross-method superiority asserted.
Authors: We agree that the statistical details are missing. In the revised version we will replace the current statement with a footnote (and expanded table caption) that specifies: a paired t-test across the three seeds, the exact p-values for each task (LogP, MR, QED), and the per-seed SRxSim means and standard deviations for all three methods. The same information will be added to the main results table. revision: yes
Circularity Check
No circularity: empirical benchmark gains reported without self-referential reduction
full rationale
The provided abstract and context present Active-GRPO as an empirical method whose performance is measured on TOMG-Bench MOLOPT via matched three-seed evaluation, yielding concrete SRxSim improvements (0.1773 vs. 0.0959/0.1665). No equations, derivations, or first-principles claims are shown that reduce by construction to fitted parameters, self-citations, or renamed inputs. The imitate-reinforce switch and active referencing are described as algorithmic mechanisms, not as predictions derived from the benchmark results themselves. This is a standard non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Microsoft Research AI4Science and Microsoft Azure Quantum. The impact of large lan- guage models on scientific discovery: a preliminary study using gpt-4.arXiv preprint arXiv:2311.07361, 2023. 1, 16
-
[2]
Hindsight experience replay.Advances in neural information processing systems, 30, 2017
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, OpenAI Pieter Abbeel, and Wojciech Zaremba. Hindsight experience replay.Advances in neural information processing systems, 30, 2017. 2, 16
2017
-
[3]
Thinking fast and slow with deep learning and tree search.Advances in neural information processing systems, 30, 2017
Thomas Anthony, Zheng Tian, and David Barber. Thinking fast and slow with deep learning and tree search.Advances in neural information processing systems, 30, 2017. 17
2017
-
[4]
Why is tanimoto index an appropriate choice for fingerprint-based similarity calculations?Journal of cheminformatics, 7(1):20, 2015
Dávid Bajusz, Anita Rácz, and Károly Héberger. Why is tanimoto index an appropriate choice for fingerprint-based similarity calculations?Journal of cheminformatics, 7(1):20, 2015. 2
2015
-
[5]
Data quality in imitation learning.Advances in neural information processing systems, 36:80375–80395, 2023
Suneel Belkhale, Yuchen Cui, and Dorsa Sadigh. Data quality in imitation learning.Advances in neural information processing systems, 36:80375–80395, 2023. 2, 17
2023
-
[6]
The properties of known drugs
Guy W Bemis and Mark A Murcko. The properties of known drugs. 1. molecular frameworks. Journal of medicinal chemistry, 39(15):2887–2893, 1996. 2
1996
-
[7]
Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023
Daniil A Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023. 1, 2, 16
2023
-
[8]
Guacamol: bench- marking models for de novo molecular design.Journal of chemical information and modeling, 59(3):1096–1108, 2019
Nathan Brown, Marco Fiscato, Marwin HS Segler, and Alain C Vaucher. Guacamol: bench- marking models for de novo molecular design.Journal of chemical information and modeling, 59(3):1096–1108, 2019. 2, 16
2019
-
[9]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021. 1
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161, 2025. 2, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. 1 10
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Yannick Djoumbou-Feunang, Jeremy Wilmot, John Kinney, Pritam Chanda, Pulan Yu, Avery Sader, Max Sharifi, Scott Smith, Junjun Ou, Jie Hu, Elizabeth Shipp, Dirk Tomandl, and Siva P. Kumpatla. Cheminformatics and artificial intelligence for accelerating agrochemical discovery. Frontiers in Chemistry, 11:1292027, 2023. doi: 10.3389/fchem.2023.1292027. 2
-
[13]
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. Raft: Reward ranked finetuning for generative foundation model alignment.arXiv preprint arXiv:2304.06767, 2023. 17
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Translation between molecules and natural language
Carl Edwards, Tuan Lai, Kevin Ros, Garrett Honke, Kyunghyun Cho, and Heng Ji. Translation between molecules and natural language. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 375–413, 2022. 2, 16
2022
-
[15]
Sample efficiency matters: a benchmark for practical molecular optimization.Advances in neural information processing systems, 35:21342–21357, 2022
Wenhao Gao, Tianfan Fu, Jimeng Sun, and Connor Coley. Sample efficiency matters: a benchmark for practical molecular optimization.Advances in neural information processing systems, 35:21342–21357, 2022. 2, 16
2022
-
[16]
Yang Gao, Dana Alon, and Donald Metzler. Impact of preference noise on the alignment performance of generative language models.arXiv preprint arXiv:2404.09824, 2024. 2, 17
-
[17]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Reinforced Self-Training (ReST) for Language Modeling
Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, et al. Reinforced self-training (rest) for language modeling.arXiv preprint arXiv:2308.08998, 2023. 17
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 1, 2, 3, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021. 1
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Deep Q-learning from demonstrations
Todd Hester, Matej Vecerik, Olivier Pietquin, Marc Lanctot, Tom Schaul, Bilal Piot, Dan Horgan, John Quan, Andrew Sendonaris, Ian Osband, et al. Deep Q-learning from demonstrations. In Proceedings of the National Conference on Artificial Intelligence (AAAI), 2018. 2, 16
2018
-
[22]
Kexin Huang, Tianfan Fu, Wenhao Gao, Yue Zhao, Yusuf Roohani, Jure Leskovec, Connor W Coley, Cao Xiao, Jimeng Sun, and Marinka Zitnik. Therapeutics data commons: Machine learn- ing datasets and tasks for drug discovery and development.arXiv preprint arXiv:2102.09548,
-
[23]
Leverag- ing large language models for predictive chemistry.Nature Machine Intelligence, 6:161–169,
Kevin Maik Jablonka, Philippe Schwaller, Andres Ortega-Guerrero, and Berend Smit. Leverag- ing large language models for predictive chemistry.Nature Machine Intelligence, 6:161–169,
-
[24]
doi: 10.1038/s42256-023-00788-1. 1
-
[25]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Learning Multimodal Graph-to-Graph Translation for Molecular Optimization
Wengong Jin, Kevin Yang, Regina Barzilay, and Tommi Jaakkola. Learning multimodal graph- to-graph translation for molecular optimization.arXiv preprint arXiv:1812.01070, 2018. 2, 16
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Hierarchical generation of molecular graphs using structural motifs
Wengong Jin, Regina Barzilay, and Tommi Jaakkola. Hierarchical generation of molecular graphs using structural motifs. InInternational conference on machine learning, pages 4839–
-
[28]
Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022. 16 11
2022
-
[29]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024. 1, 2, 16
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Speak-to-Structure: Evaluating LLMs in Open-domain Natural Language-Driven Molecule Generation
Jiatong Li, Junxian Li, Yunqing Liu, Dongzhan Zhou, and Qing Li. Tomg-bench: Evaluating llms on text-based open molecule generation.arXiv preprint arXiv:2412.14642, 2024. 2, 6, 16
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Jiatong Li, Yunqing Liu, Wenqi Fan, Xiao-Yong Wei, Hui Liu, Jiliang Tang, and Qing Li. Empowering molecule discovery for molecule-caption translation with large language models: A chatgpt perspective.IEEE transactions on knowledge and data engineering, 36(11):6071– 6083, 2024. 2, 16
2024
-
[32]
Xuan Li, Zhanke Zhou, Zongze Li, Jiangchao Yao, Yu Rong, Lu Zhang, and Bo Han. Reference- guided policy optimization for molecular optimization via llm reasoning.arXiv preprint arXiv:2603.05900, 2026. 2
-
[33]
Repo: Reference-guided policy optimization for molecular optimization via llm reasoning
Xuan Li, Zhanke Zhou, Zongze Li, Jiangchao Yao, Yu Rong, Lu Zhang, and Bo Han. Repo: Reference-guided policy optimization for molecular optimization via llm reasoning. InInterna- tional Conference on Learning Representations (ICLR), 2026. 2, 4, 6, 7, 17
2026
-
[34]
Bill Yuchen Lin, Abhilasha Ravichander, Ximing Lu, Nouha Dziri, Melanie Sclar, Khyathi Chandu, Chandra Bhagavatula, and Yejin Choi. The unlocking spell on base llms: Rethinking alignment via in-context learning.arXiv preprint arXiv:2312.01552, 2023. 2, 16
-
[35]
Navigating chemical space for biology and medicine
Christopher Lipinski and Andrew Hopkins. Navigating chemical space for biology and medicine. Nature, 432(7019):855–861, 2004. 2
2004
-
[36]
Xuefeng Liu, Takuma Yoneda, Rick L Stevens, Matthew R Walter, and Yuxin Chen. Blend- ing imitation and reinforcement learning for robust policy improvement.arXiv preprint arXiv:2310.01737, 2023. 17
-
[37]
s1: Simple test-time scaling
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286–20332, 2025. 1, 16
2025
-
[38]
Overcoming exploration in reinforcement learning with demonstrations
Ashvin Nair, Bob McGrew, Marcin Andrychowicz, Wojciech Zaremba, and Pieter Abbeel. Overcoming exploration in reinforcement learning with demonstrations. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 6292–6299, 2018. 2, 17
2018
-
[39]
R OpenAI. Gpt-4 technical report. arxiv 2303.08774.View in Article, 2(5):1, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022. 2
2022
-
[41]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177, 2019. 2, 17
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[42]
Molecular sets (moses): a benchmarking platform for molecular generation models.Frontiers in pharmacology, 11:565644, 2020
Daniil Polykovskiy, Alexander Zhebrak, Benjamin Sanchez-Lengeling, Sergey Golovanov, Oktai Tatanov, Stanislav Belyaev, Rauf Kurbanov, Aleksey Artamonov, Vladimir Aladinskiy, Mark Veselov, et al. Molecular sets (moses): a benchmarking platform for molecular generation models.Frontiers in pharmacology, 11:565644, 2020. 2, 16
2020
-
[43]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations.arXiv preprint arXiv:1709.10087, 2017. 2, 16
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[44]
Learning by playing solving sparse reward tasks from scratch
Martin Riedmiller, Roland Hafner, Thomas Lampe, Michael Neunert, Jonas Degrave, Tom Wiele, Vlad Mnih, Nicolas Heess, and Jost Tobias Springenberg. Learning by playing solving sparse reward tasks from scratch. InInternational conference on machine learning, pages 4344–4353. PMLR, 2018. 2, 16 12
2018
-
[45]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635, 2011. 17
2011
-
[46]
Inverse molecular design using machine learning: Generative models for matter engineering.Science, 361(6400):360–365, 2018
Benjamin Sanchez-Lengeling and Alán Aspuru-Guzik. Inverse molecular design using machine learning: Generative models for matter engineering.Science, 361(6400):360–365, 2018. 2
2018
-
[47]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[48]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 3, 16
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Avi Singh, John D Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J Liu, James Harrison, Jaehoon Lee, Kelvin Xu, et al. Beyond human data: Scaling self-training for problem-solving with language models.arXiv preprint arXiv:2312.06585,
-
[50]
A deep learning approach to antibiotic discovery.Cell, 180(4):688–702, 2020
Jonathan M Stokes, Kevin Yang, Kyle Swanson, Wengong Jin, Andres Cubillos-Ruiz, Nina M Donghia, Craig R MacNair, Shawn French, Lindsey A Carfrae, Zohar Bloom-Ackermann, et al. A deep learning approach to antibiotic discovery.Cell, 180(4):688–702, 2020. 1, 2, 16
2020
-
[51]
Stanford alpaca: An instruction-following llama model,
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Stanford alpaca: An instruction-following llama model,
-
[52]
Galactica: A Large Language Model for Science
Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. Galactica: A large language model for science.arXiv preprint arXiv:2211.09085, 2022. 1, 16
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022. 1, 16
2022
-
[54]
Smiles, a chemical language and information system
David Weininger. Smiles, a chemical language and information system. 1. introduction to methodology and encoding rules.Journal of chemical information and computer sciences, 28 (1):31–36, 1988. 2, 3
1988
-
[55]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models.arXiv preprint arXiv:2309.12284, 2023. 16
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Self-Rewarding Language Models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models.arXiv preprint arXiv:2401.10020,
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
replace the fluorine atoms with chlo- rine atoms
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 35:15476–15488, 2022. 1, 16, 17 13 A Implementation and Reproducibility Details This appendix provides implementation details omitted from the main algorithmic presentation, including the precise RL objectiv...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.