EnvRL: Learn from Environment Dynamics in Agentic Reinforcement Learning
Pith reviewed 2026-06-27 01:23 UTC · model grok-4.3
The pith
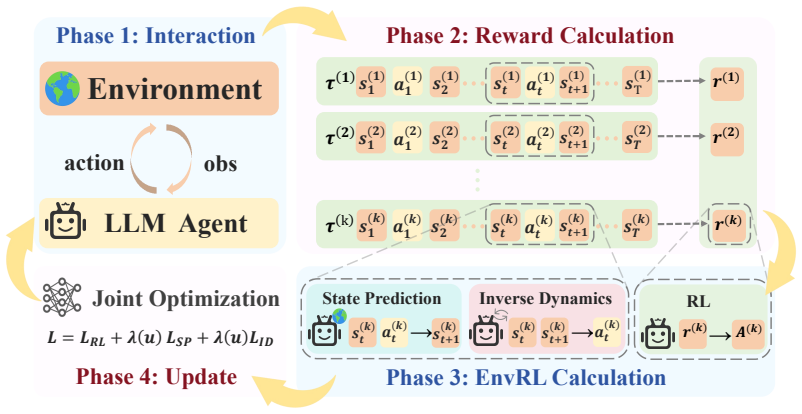
EnvRL adds state prediction and inverse dynamics objectives to agentic RL so agents internalize environment transitions from their own interaction trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that interaction experience inherently reveals the underlying transition mechanisms of the environment. By jointly optimizing state-prediction and inverse-dynamics objectives with the primary RL objective, the agent constructs a more accurate internal model of the environment from its own rollout data, which improves policy learning and produces higher success rates on long-horizon agentic tasks.
What carries the argument
Two auxiliary objectives—state prediction (forecasting future states from history) and inverse dynamics (recovering actions from observed state transitions)—optimized jointly with the RL loss to drive internalization of environment dynamics.
If this is right
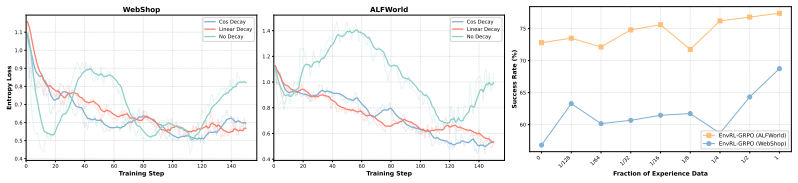
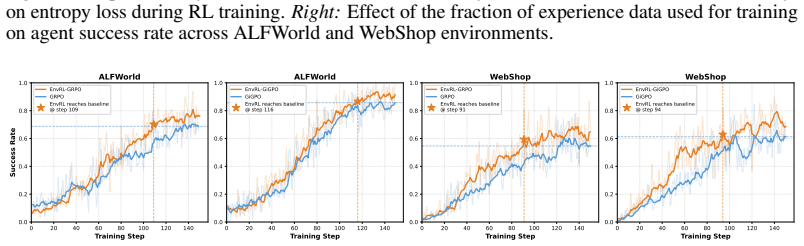
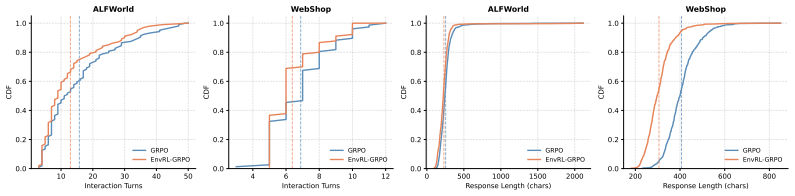
- When combined with GRPO, EnvRL raises Qwen-2.5-1.5B-Instruct success from 72.8% to 77.4% on ALFWorld.
- The same training raises success from 56.8% to 67.0% on WebShop.
- The approach applies to any RL method for agentic tasks that can access full interaction trajectories.
Where Pith is reading between the lines
- Similar auxiliary objectives could be added to other model-free RL setups to extract more signal per rollout without requiring extra environment steps.
- The method offers a lightweight bridge toward model-based ideas by shaping the policy's internal representations rather than training a separate dynamics model.
- One could measure whether the quality of the learned state predictions correlates with downstream planning or generalization behavior in the agent.
Load-bearing premise
The observed success-rate gains are produced by the agent learning accurate environment transition models rather than by the extra loss terms acting as generic regularizers or optimization aids.
What would settle it
Train identical models with the auxiliary objectives but replace the true next-state and inverse-action targets with randomly shuffled or noise targets; if the success-rate improvements over RL-only baselines disappear, the central claim is supported.
Figures

read the original abstract
Reinforcement learning (RL) has emerged as a powerful paradigm for training Large Language Models (LLMs) as agents. However, conventional RL methods for long-horizon agentic tasks often struggle with sparse outcome rewards. Intuitively, this overlooks the rich environment dynamics information contained in rollout interaction trajectories. We argue that the interaction experience inherently serves as an implicit supervision signal, reveals the underlying transition mechanisms of the environment, and enables the agent to construct a more accurate internal model of the environment.. Therefore, in this work, we investigate how to leverage this additional signal to improve policy learning. Specifically, we propose EnvRL, a framework that incorporates environment dynamics learning into agentic RL via two auxiliary objectives: state prediction and inverse dynamics. By jointly optimizing with the primary RL objective, we encourage the agent to internalize environment dynamics from its own interaction experience. Extensive experiments on two long-horizon agentic benchmarks demonstrate that EnvRL achieves significant improvements on success-rates over RL-only baselines, e.g., when trained with GRPO, lifting Qwen-2.5-1.5B-Instruct from 72.8% to 77.4% on ALFWorld, and from 56.8% to 67.0% on WebShop.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EnvRL, which augments agentic RL (e.g., GRPO) for LLMs with two auxiliary objectives—state prediction and inverse dynamics—derived from rollout trajectories. It argues that jointly optimizing these with the primary RL loss encourages internalization of environment dynamics, yielding higher success rates on long-horizon tasks. Experiments on ALFWorld and WebShop report gains such as lifting Qwen-2.5-1.5B-Instruct from 72.8% to 77.4% on ALFWorld and 56.8% to 67.0% on WebShop under GRPO.
Significance. If the gains are shown to arise specifically from improved dynamics modeling rather than generic auxiliary-loss effects, the framework would supply a lightweight, data-efficient way to exploit interaction trajectories in sparse-reward agentic settings. The concrete numerical improvements on two established benchmarks constitute a clear empirical contribution, though the causal mechanism requires further isolation to strengthen the central claim.
major comments (3)
- [Experiments] Experiments section: the reported success-rate lifts are shown only versus RL-only baselines; no ablation with non-dynamics auxiliary objectives (e.g., random-target prediction or unrelated heads) is presented to isolate whether gains stem from environment-dynamics internalization or from incidental regularization, gradient diversity, or multi-task effects.
- [§4] §4 (results tables): success rates are given as single point estimates (e.g., 72.8% → 77.4%, 56.8% → 67.0%) with no standard deviations, number of independent runs, or statistical significance tests, preventing assessment of whether the differences are reliable.
- [Method] Method section: the weighting coefficients λ_state and λ_inv between the RL loss and the two auxiliary losses are not specified, nor is any sensitivity analysis or hyper-parameter sweep reported, which bears directly on reproducibility of the joint-optimization claim.
minor comments (2)
- [Abstract] Abstract: the term 'significant improvements' is used without reference to the tables or statistical support; consider qualifying it as 'empirical' or citing the specific results.
- Notation: the precise formulation of the state-prediction and inverse-dynamics losses (e.g., whether they operate on token embeddings or full states) should be stated explicitly with equations for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each point below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the reported success-rate lifts are shown only versus RL-only baselines; no ablation with non-dynamics auxiliary objectives (e.g., random-target prediction or unrelated heads) is presented to isolate whether gains stem from environment-dynamics internalization or from incidental regularization, gradient diversity, or multi-task effects.
Authors: We agree that ablations with non-dynamics auxiliary objectives would provide stronger evidence for the specific benefit of dynamics learning. In the revised version, we will add experiments including a random prediction auxiliary task and an unrelated head to isolate the effect. revision: yes
-
Referee: [§4] §4 (results tables): success rates are given as single point estimates (e.g., 72.8% → 77.4%, 56.8% → 67.0%) with no standard deviations, number of independent runs, or statistical significance tests, preventing assessment of whether the differences are reliable.
Authors: We acknowledge the importance of reporting statistical reliability. We will conduct additional runs with different random seeds, report mean success rates with standard deviations, and include significance tests in the updated results section. revision: yes
-
Referee: [Method] Method section: the weighting coefficients λ_state and λ_inv between the RL loss and the two auxiliary losses are not specified, nor is any sensitivity analysis or hyper-parameter sweep reported, which bears directly on reproducibility of the joint-optimization claim.
Authors: The values of λ_state and λ_inv used in our experiments will be explicitly stated in the revised method section. Additionally, we will include a sensitivity analysis showing the impact of different weighting coefficients on performance. revision: yes
Circularity Check
No circularity; empirical framework with independent experimental claims
full rationale
The provided abstract and description contain no equations, fitted parameters presented as predictions, or self-citation chains. The method adds auxiliary state-prediction and inverse-dynamics losses to RL training and reports benchmark success-rate gains. These gains are not shown to reduce by construction to the inputs (no self-definitional re-use of the same quantities, no renaming of known results, no load-bearing uniqueness theorems). The derivation chain is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. 2024. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms
2024
-
[2]
David Brandfonbrener, Ofir Nachum, and Joan Bruna. 2023. Inverse dynamics pretraining learns good representations for multitask imitation. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA. Curran Associates Inc
2023
-
[3]
Xinning Chen, Xuan Liu, Yanwen Ba, Shigeng Zhang, Bo Ding, and Kenli Li. 2024. Selective learning for sample-efficient training in multi-agent sparse reward tasks. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, pages 8384–8388. International Joint Conferences on Artificial Intelligence Organization. ...
2024
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.Preprint, arXiv:2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. 2025. Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
David Ha and Jürgen Schmidhuber. 2018. World models
2018
-
[7]
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. 2019. Dream to control: Learning behaviors by latent imagination
2019
-
[8]
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. 2024. Mastering diverse domains through world models.Preprint, arXiv:2301.04104
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, Barcelona, Spain (Online). International Committee on Computational Linguistics
2020
-
[10]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
2025
-
[11]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, Vancouver, Canada. Association for Computational Linguistics
2017
-
[13]
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. 2024. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: A benchmark for question answering research.Tr...
2019
-
[15]
Yann LeCun and Courant. 2022. A path towards autonomous machine intelligence version 0.9.2, 2022-06-27
2022
- [16]
-
[17]
Continuous control with deep reinforcement learning
Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. 2019. Continuous control with deep reinforcement learning.Preprint, arXiv:1509.02971
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[18]
Minhua Lin, Zongyu Wu, Zhichao Xu, Hui Liu, Xianfeng Tang, Qi He, Charu Aggarwal, Hui Liu, Xiang Zhang, and Suhang Wang. 2025. A comprehensive survey on reinforcement learning-based agentic search: Foundations, roles, optimizations, evaluations, and applications
2025
-
[19]
Xiaoqian Liu, Ke Wang, Yuchuan Wu, Fei Huang, Yongbin Li, Junge Zhang, and Jianbin Jiao
- [20]
-
[21]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, Rongcheng Tu, Xiao Luo, Wei Ju, Zhiping Xiao, Yifan Wang, Meng Xiao, Chenwu Liu, Jingyang Yuan, Shichang Zhang, Yiqiao Jin, Fan Zhang, Xian Wu, Hanqing Zhao, Dacheng Tao, Philip S. Yu, and Ming Zhang. 2025. Large language model agent: A...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. 2023. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9802–9822, Toronto, Canada....
2023
-
[23]
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2023. Gaia: a benchmark for general ai assistants
2023
-
[24]
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin A. Riedmiller. 2013. Playing atari with deep reinforcement learning. CoRR, abs/1312.5602
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[25]
OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander M ˛ adry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, A...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Efros, and Trevor Darrell
Deepak Pathak, Pulkit Agrawal, Alexei A. Efros, and Trevor Darrell. 2017. Curiosity-driven exploration by self-supervised prediction. InProceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 2778–
2017
-
[27]
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah Smith, and Mike Lewis. 2023. Measuring and narrowing the compositionality gap in language models. InFindings of the Asso- ciation for Computational Linguistics: EMNLP 2023, pages 5687–5711, Singapore. Association for Computational Linguistics
2023
-
[28]
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. 2025. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lillicrap, and David Silver. 2019. Mastering atari, go, chess and shogi by planning with a learned model
2019
-
[30]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proxi- mal policy optimization algorithms.CoRR, abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Ramanan Sekar, Oleh Rybkin, Kostas Daniilidis, Pieter Abbeel, Danijar Hafner, and Deepak Pathak. 2020. Planning to explore via self-supervised world models
2020
-
[32]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models
2024
-
[33]
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. 2020. Alfworld: Aligning text and embodied environments for interactive learning
2020
-
[34]
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy P. Lillicrap, Karen Simonyan, and Demis Hassabis. 2017. Mastering chess and shogi by self-play with a general reinforcement learning algorithm.CoRR, abs/1712.01815
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexandra Barr, Alexandre Kirchmeyer, Ale...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
GLM Team, Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, Kedong Wang, Lucen Zhong, Mingdao Liu, Rui Lu, Shulin Cao, Xiaohan Zhang, Xuancheng Huang, Yao Wei, Yean Cheng, Yifan An, Yilin Niu, Yuanhao Wen, Yushi Bai, Zhengxiao Du, Zihan Wang, Zilin Zhu, Bohan Zhang, Bosi Wen, Bowen Wu, Bo...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. MuSiQue: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554
2022
-
[38]
Kangrui Wang, Pingyue Zhang, Zihan Wang, et al. 2025. Vagen: Reinforcing world model reasoning for multi-turn vlm agents
2025
-
[39]
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, Eli Gottlieb, Yiping Lu, Kyunghyun Cho, Jiajun Wu, Li Fei-Fei, Lijuan Wang, Yejin Choi, and Manling Li. 2025. Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning
2025
-
[40]
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. 2025. Browsecomp: A simple yet challenging benchmark for browsing agents.Preprint, arXiv:2504.12516
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. 2024. Osworld: Bench- marking multimodal agents for open-ended tasks in real computer environments.Preprint, arXiv:2404.07972
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Cohen, Ruslan Salakhutdi- nov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdi- nov, and Christopher D. Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InConference on Empirical Methods in Natural Language Processing (EMNLP)
2018
-
[44]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. 2022. Webshop: Towards scalable real-world web interaction with grounded language agents
2022
-
[45]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models
2022
-
[46]
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, Yifan Zhou, Yang Chen, Chen Zhang, Yutao Fan, Zihu Wang, Songtao Huang, Francisco Piedrahita-Velez, Yue Liao, Hongru Wang, Mengyue Yang, Heng Ji, Jun Wang, Shuicheng Yan, Philip Torr, and Lei Bai. 2025. The landscape of agentic r...
2025
-
[47]
Kai Zhang, Xiangchao Chen, Bo Liu, et al. 2025. Agent learning via early experience
2025
-
[48]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, et al. 2023. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854. 15 A Implementation Details This appendix provides the implementation details in ENVRL training. A.1 State Predictio...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.