EvolveNav: Proactive Preflection and Self-Evolving Memory for Zero-Shot Object Goal Navigation
Pith reviewed 2026-06-27 00:31 UTC · model grok-4.3
The pith
A memory of rules extracted from an agent's own trajectories enables continuous improvement in zero-shot object goal navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
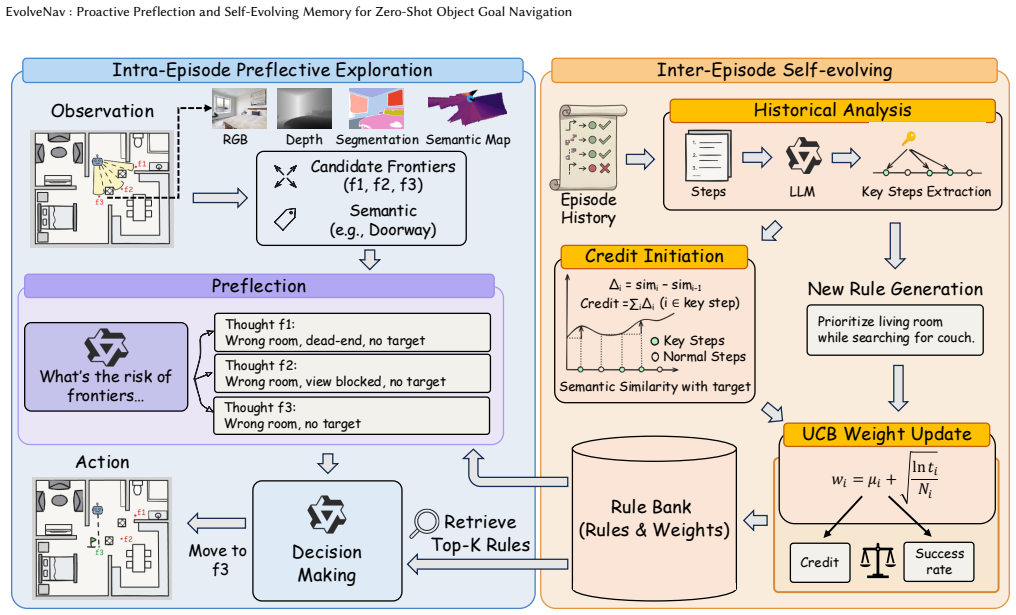
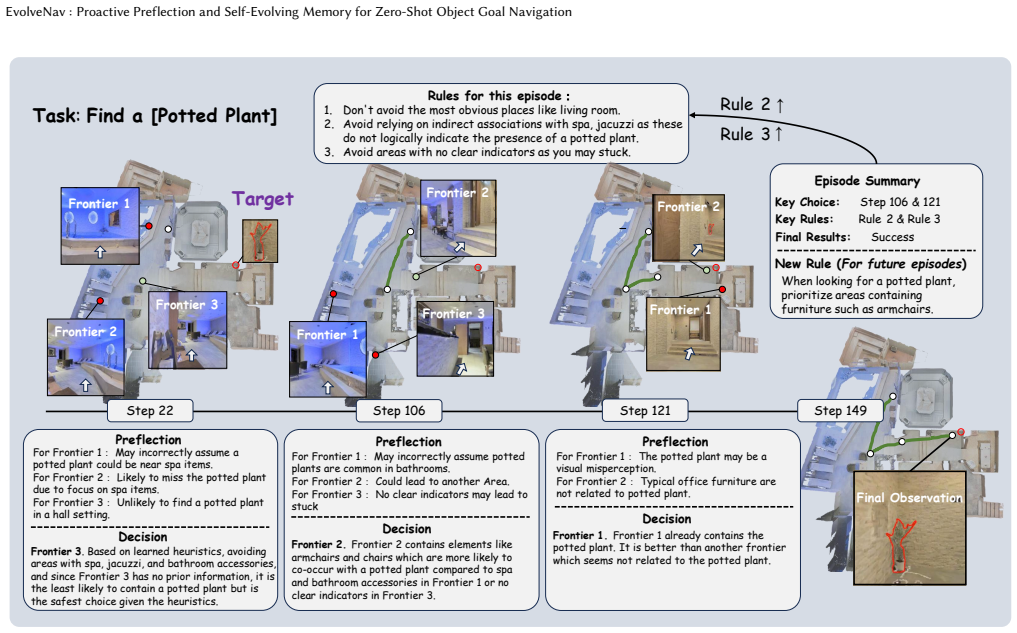
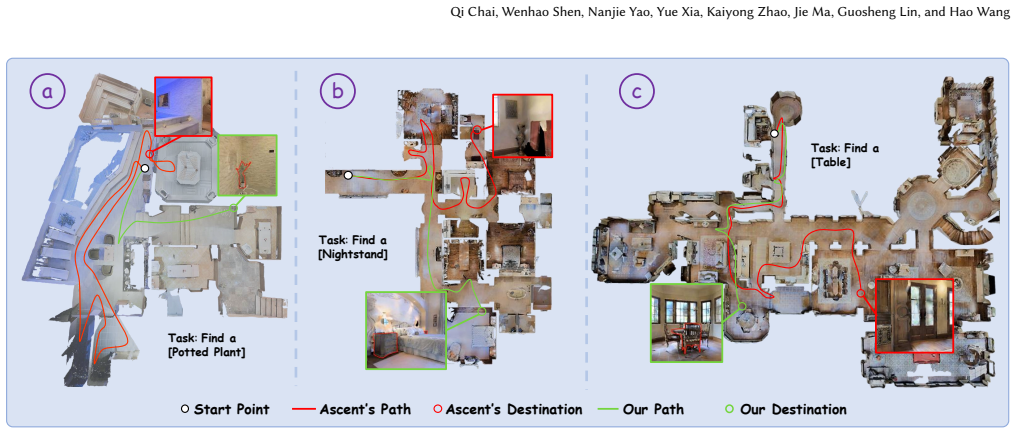
The central claim is that building an agentic rule memory from past trajectories, retrieving rules via upper confidence bound selection, and using memory-guided preflection to anticipate results before action produces continuous test-time improvement for zero-shot object-goal navigation and yields a 10.1 percent gain in success rate over static baselines.
What carries the argument
The agentic rule memory extracted from trajectories together with UCB-based retrieval and the memory-guided preflection module that forecasts potential outcomes before each action.
If this is right
- The agent reaches target objects with a 10.1 percent higher success rate than existing zero-shot baselines.
- Exploration requires fewer unnecessary steps because repeated errors are reduced.
- The system accumulates and reuses experience across episodes without any separate training phase.
- Foundation-model priors are supplemented by experience-derived rules that adapt during deployment.
Where Pith is reading between the lines
- If the rule memory proves robust, the same extraction-plus-retrieval pattern could be applied to other embodied tasks such as manipulation or multi-room planning.
- Over many episodes the memory could produce environment-specific navigation habits that emerge without hand-designed rewards.
- Retrieval that only weakly penalizes low-success rules risks the agent reinforcing early mistakes when environments change.
Load-bearing premise
Rules extracted from earlier trajectories will generalize usefully to new environments and the combination of UCB retrieval with preflection will reliably cut inefficient exploration.
What would settle it
An experiment in a sequence of previously unseen environments in which success rate stays the same or drops and step count rises when the rule memory and preflection modules are active compared with a version that disables them.
Figures

read the original abstract
Zero-Shot Object-Goal Navigation (ZS-OGN) requires embodied agents to explore and locate target objects without any prior training. To this end, recent methods leverage foundation models. But they typically rely on static priors and lack adaptation, which leads to repeated errors and costly trial and error. In this paper, we propose a self-evolving ZS-OGN framework that enables continuous test-time improvement. Specifically, we build an agentic rule memory by extracting actionable knowledge from past trajectories. Then, we propose a retrieval strategy based on upper confidence bound, selecting effective rules by balancing semantic relevance and historical success. In addition, we introduce a memory-guided preflection module that forecasts potential outcomes before action, reducing inefficient exploration. Extensive experiments show that our method outperforms existing zero-shot baselines, achieving a 10.1\% improvement in success rate with fewer unnecessary steps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EvolveNav, a self-evolving zero-shot object-goal navigation framework. It constructs an agentic rule memory by distilling actionable knowledge from past trajectories, retrieves rules via an upper-confidence-bound strategy that balances semantic relevance and historical success, and introduces a memory-guided preflection module that forecasts action outcomes to reduce inefficient exploration. The central empirical claim is a 10.1% success-rate improvement over existing zero-shot baselines together with fewer unnecessary steps.
Significance. If the reported gains prove robust under standard embodied-AI evaluation protocols, the work would usefully demonstrate that test-time rule memory and preflection can mitigate the trial-and-error cost of static foundation-model priors. The UCB retrieval mechanism is a principled choice for balancing exploration and exploitation in rule selection.
major comments (2)
- [§3.2] §3.2 (Rule Extraction): The process for distilling rules from trajectories is described at a high level, yet no quantitative metric (e.g., rule reuse rate across episodes or environments, or an ablation that removes the memory component) is supplied to test whether the extracted rules remain useful rather than scene-specific when applied to novel scenes; this assumption is load-bearing for the claimed reduction in unnecessary steps.
- [§4] §4 (Experiments): The headline 10.1% success-rate improvement is stated without accompanying protocol details—number of environments, number of episodes per environment, baseline implementations, error bars, or statistical tests—making it impossible to assess whether the result supports the generalizability claim.
minor comments (1)
- [Abstract] Abstract: The neologism 'preflection' is used without a one-sentence gloss, which reduces immediate readability for readers outside the immediate sub-area.
Simulated Author's Rebuttal
Thank you for the constructive comments. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Rule Extraction): The process for distilling rules from trajectories is described at a high level, yet no quantitative metric (e.g., rule reuse rate across episodes or environments, or an ablation that removes the memory component) is supplied to test whether the extracted rules remain useful rather than scene-specific when applied to novel scenes; this assumption is load-bearing for the claimed reduction in unnecessary steps.
Authors: We agree that quantitative support for rule generalization is needed. In revision we will add an ablation removing the memory component and report rule reuse rates across episodes and environments to show the rules are not merely scene-specific. revision: yes
-
Referee: [§4] §4 (Experiments): The headline 10.1% success-rate improvement is stated without accompanying protocol details—number of environments, number of episodes per environment, baseline implementations, error bars, or statistical tests—making it impossible to assess whether the result supports the generalizability claim.
Authors: We will expand §4 to include the full evaluation protocol: number of environments and episodes, baseline implementation details, error bars, and statistical tests supporting the reported gains. revision: yes
Circularity Check
No circularity: empirical method with no derivations or self-referential fits
full rationale
The paper describes an empirical framework for ZS-OGN involving rule extraction from trajectories, UCB-based retrieval, and a preflection module. No equations, parameter fits, or mathematical derivations appear in the abstract or summary. Performance claims (e.g., 10.1% SR gain) are presented as experimental outcomes rather than derived results. No self-citations, ansatzes, or uniqueness theorems are invoked in the provided text. The central claims rest on external validation through experiments, making the approach self-contained without reduction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Foundation models provide useful static priors that can be augmented by test-time memory extraction.
invented entities (2)
-
agentic rule memory
no independent evidence
-
memory-guided preflection module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [3]
-
[4]
Wenzhe Cai, Siyuan Huang, Guangran Cheng, Yuxing Long, Peng Gao, Changyin Sun, and Hao Dong. 2024. Bridging zero-shot object navigation and founda- tion models through pixel-guided navigation skill. In2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 5228–5234
2024
-
[5]
Qi Chai, Zhang Zheng, Junlong Ren, Deheng Ye, Zichuan Lin, and Hao Wang
- [6]
-
[7]
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. 2017. Matterport3d: Learning from rgb-d data in indoor environments.arXiv preprint arXiv:1709.06158 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
Devendra Singh Chaplot, Dhiraj Prakashchand Gandhi, Abhinav Gupta, and Russ R Salakhutdinov. 2020. Object goal navigation using goal-oriented semantic exploration.Advances in Neural Information Processing Systems33 (2020), 4247– 4258
2020
-
[9]
Nuo Chen, Hongguang Li, Jianhui Chang, Juhua Huang, Baoyuan Wang, and Jia Li. 2025. Compress to impress: Unleashing the potential of compressive memory in real-world long-term conversations. InProceedings of the 31st International Conference on Computational Linguistics. 755–773
2025
-
[10]
Shizhe Chen, Thomas Chabal, Ivan Laptev, and Cordelia Schmid. 2023. Object goal navigation with recursive implicit maps. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 7089–7096
2023
-
[11]
Shizhe Chen, Pierre-Louis Guhur, Makarand Tapaswi, Cordelia Schmid, and Ivan Laptev. 2022. Think global, act local: Dual-scale graph transformer for vision-and-language navigation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 16537–16547
2022
-
[12]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Ya- dav. 2025. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Ronghao Dang, Liuyi Wang, Zongtao He, Shuai Su, Jiagui Tang, Chengju Liu, and Qijun Chen. 2023. Search for or navigate to? dual adaptive thinking for object navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 8250–8259
2023
-
[14]
Honghao Fu, Junlong Ren, Qi Chai, Deheng Ye, Yujun Cai, and Hao Wang. 2025. Vistawise: Building cost-effective agent with cross-modal knowledge graph for minecraft. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 21895–21909
2025
-
[15]
Samir Yitzhak Gadre, Mitchell Wortsman, Gabriel Ilharco, Ludwig Schmidt, and Shuran Song. 2023. Cows on pasture: Baselines and benchmarks for language- driven zero-shot object navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 23171–23181
2023
-
[16]
Zeying Gong, Rong Li, Tianshuai Hu, Ronghe Qiu, Lingdong Kong, Lingfeng Zhang, Guoyang Zhao, Yiyi Ding, and Junwei Liang. 2026. Stairway to Success: An Online Floor-Aware Zero-Shot Object-Goal Navigation Framework via LLM- Driven Coarse-to-Fine Exploration.IEEE Robotics and Automation Letters(2026)
2026
-
[17]
Yu Guo, Jinsheng Sun, Ruiheng Zhang, Zhiqi Jiang, Zhenqiang Mi, Chao Yao, Xiaojuan Ban, and Mohammad S Obaidat. 2024. An object-driven navigation strategy based on active perception and semantic association.IEEE Robotics and Automation Letters9, 8 (2024), 7110–7117
2024
-
[18]
Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs.Advances in neural information processing systems30 (2017)
2017
- [19]
-
[20]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Jinyeon Kim, Cheolhong Min, Byeonghwi Kim, and Jonghyun Choi. 2024. Pre- emptive Action Revision by Environmental Feedback for Embodied Instruction Following Agents. InCoRL
2024
- [22]
-
[23]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
2023
-
[24]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[26]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[27]
Yuxing Long, Wenzhe Cai, Hongcheng Wang, Guanqi Zhan, and Hao Dong. 2024. InstructNav: Zero-shot System for Generic Instruction Navigation in Unexplored Environment. InConference on Robot Learning
2024
-
[28]
Jie Ma, Zhitao Gao, Qi Chai, Wangchun Sun, Pinghui Wang, Hongbin Pei, Jing Tao, Lingyun Song, Jun Liu, Chen Zhang, et al. 2025. Debate on graph: a flexible and reliable reasoning framework for large language models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 24768–24776
2025
-
[29]
Arjun Majumdar, Gunjan Aggarwal, Bhavika Devnani, Judy Hoffman, and Dhruv Batra. 2022. Zson: Zero-shot object-goal navigation using multimodal goal embeddings.Advances in Neural Information Processing Systems35 (2022), 32340– 32352
2022
-
[30]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[31]
In International Conference on Machine Learning
Learning transferable visual models from natural language supervision. In International Conference on Machine Learning. PmLR, 8748–8763
-
[32]
Santhosh K Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alex Clegg, John Turner, Eric Undersander, Wojciech Galuba, An- drew Westbury, Angel X Chang, et al. 2021. Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai.arXiv preprint arXiv:2109.08238 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
Ram Ramrakhya, Dhruv Batra, Erik Wijmans, and Abhishek Das. 2023. Pirlnav: Pretraining with imitation and rl finetuning for objectnav. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 17896–17906
2023
-
[34]
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. 2019. Habitat: A platform for embodied ai research. InProceedings of the IEEE/CVF international conference on computer vision. 9339–9347
2019
-
[35]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learn- ing.Advances in neural information processing systems36 (2023), 8634–8652
2023
-
[36]
Aaditya Singh and Adam Fry et al. 2025. OpenAI GPT-5 System Card. arXiv:2601.03267 [cs.CL] https://arxiv.org/abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Fuchun Sun, Runfa Chen, Tianying Ji, Yu Luo, Huaidong Zhou, and Huaping Liu. 2024. A comprehensive survey on embodied intelligence: Advancements, challenges, and future perspectives. (2024)
2024
-
[38]
Weihao Tan, Wentao Zhang, Shanqi Liu, Longtao Zheng, Xinrun Wang, and Bo An. [n. d.]. True Knowledge Comes from Practice: Aligning Large Language Models with Embodied Environments via Reinforcement Learning. InThe Twelfth International Conference on Learning Representations
-
[39]
Hanlin Wang, Chak Tou Leong, Jian Wang, and Wenjie Li. 2024. E 2CL: Exploration-based Error Correction Learning for Embodied Agents. InFindings of Qi Chai, Wenhao Shen, Nanjie Yao, Yue Xia, Kaiyong Zhao, Jie Ma, Guosheng Lin, and Hao Wang the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mo- hit Bansal, and Yun-Nung Chen (Eds.)....
- [40]
-
[41]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. 2024. Agent workflow memory.arXiv preprint arXiv:2409.07429(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Justin Wasserman, Girish Chowdhary, Abhinav Gupta, and Unnat Jain. 2024. Exploitation-guided exploration for semantic embodied navigation. In2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2901–2908
2024
- [43]
-
[44]
Yurong Wu, Yan Gao, Bin Benjamin Zhu, Zineng Zhou, Xiaodi Sun, Sheng Yang, Jian-Guang Lou, Zhiming Ding, and Linjun Yang. 2024. Strago: Harnessing strategic guidance for prompt optimization. InFindings of the Association for Computational Linguistics: EMNLP 2024. 10043–10061
2024
- [45]
-
[46]
Yutao Xie, Nathaniel Thomas, Nicklas Hansen, Yang Fu, Li Erran Li, and Xiao- long Wang. [n. d.]. TIPS: Turn-level Information-Potential Reward Shaping for Search-Augmented LLMs. InThe Fourteenth International Conference on Learning Representations
-
[47]
Karmesh Yadav, Ram Ramrakhya, Santhosh Kumar Ramakrishnan, Theo Gervet, John Turner, Aaron Gokaslan, Noah Maestre, Angel Xuan Chang, Dhruv Batra, Manolis Savva, et al . 2023. Habitat-matterport 3d semantics dataset. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4927–4936
2023
-
[48]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Cheng- peng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. 2024. Qwen2 Technical Report.eprint arXiv: 2407.10671(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al . 2024. Qwen2. 5 Technical Report.arXiv preprint arXiv:2412.15115(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. 2023. Large language models as optimizers. InThe Twelfth International Conference on Learning Representations
2023
-
[52]
Zebin Yang, Sunjian Zheng, Tong Xie, Tianshi Xu, Bo Yu, Fan Wang, Jie Tang, Shaoshan Liu, and Meng Li. [n. d.]. EfficientNav: Towards On-Device Object-Goal Navigation with Navigation Map Caching and Retrieval. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[53]
Weiran Yao, Shelby Heinecke, Juan Carlos Niebles, Zhiwei Liu, Yihao Feng, Le Xue, Rithesh Murthy, Zeyuan Chen, Jianguo Zhang, Devansh Arpit, et al
- [54]
-
[55]
Xin Ye and Yezhou Yang. 2021. Efficient robotic object search via hiem: Hier- archical policy learning with intrinsic-extrinsic modeling.IEEE robotics and automation letters6, 3 (2021), 4425–4432
2021
-
[56]
Hang Yin, Xiuwei Xu, Zhenyu Wu, Jie Zhou, and Jiwen Lu. 2024. SG-Nav: Online 3D Scene Graph Prompting for LLM-based Zero-shot Object Navigation. Advances in Neural Information Processing Systems37 (2024), 5285–5307
2024
-
[57]
Naoki Yokoyama, Sehoon Ha, Dhruv Batra, Jiuguang Wang, and Bernadette Bucher. 2024. Vlfm: Vision-language frontier maps for zero-shot semantic navi- gation. In2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 42–48
2024
-
[58]
Hwiyeon Yoo, Yunho Choi, Jeongho Park, and Songhwai Oh. 2024. Commonsense-aware object value graph for object goal navigation.IEEE Robotics and Automation Letters9, 5 (2024), 4423–4430
2024
-
[59]
Bangguo Yu, Hamidreza Kasaei, and Ming Cao. 2023. L3mvn: Leveraging large language models for visual target navigation. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 3554–3560
2023
- [60]
-
[61]
Mingjie Zhang, Yuheng Du, Chengkai Wu, Jinni Zhou, Zhenchao Qi, Jun Ma, and Boyu Zhou. 2025. Apexnav: An adaptive exploration strategy for zero-shot object navigation with target-centric semantic fusion.IEEE Robotics and Automation Letters(2025)
2025
-
[62]
Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, and Yu Qiao. 2023. Llama-adapter: Effi- cient fine-tuning of language models with zero-init attention.arXiv preprint arXiv:2303.16199(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Zheng Zhang, Yihuai Lan, Yangsen Chen, Lei Wang, Xiang Wang, and Hao Wang
-
[64]
InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Dvm: Towards controllable llm agents in social deduction games. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
-
[65]
Zheng Zhang, Nuoqian Xiao, Qi Chai, Deheng Ye, and Hao Wang. 2025. Mul- timind: Enhancing werewolf agents with multimodal reasoning and theory of mind. InProceedings of the 33rd ACM International Conference on Multimedia. 5824–5833
2025
- [66]
-
[67]
Xiaoming Zhao, Harsh Agrawal, Dhruv Batra, and Alexander Schwing. 2021. The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation. InProc. ICCV
2021
-
[68]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. Memo- rybank: Enhancing large language models with long-term memory. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 19724–19731
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.