Maestro: Reinforcement Learning to Orchestrate Hierarchical Model-Skill Ensembles
Pith reviewed 2026-05-22 07:47 UTC · model grok-4.3
The pith
A 4B reinforcement learning policy learns to orchestrate frozen expert models and skills to outperform larger monolithic systems on multimodal tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Maestro trains a lightweight policy via outcome-based RL to treat multimodal reasoning as sequential decisions over a hierarchical model-skill registry, choosing at each step whether to call an external expert, which frozen model-skill pair to use, and when to terminate, thereby composing ensembles that achieve 70.1 percent average accuracy across ten benchmarks while generalizing to out-of-domain additions without retraining.
What carries the argument
The outcome-based RL policy that selects and sequences frozen expert models from a two-tier skill library in a hierarchical registry.
If this is right
- The learned coordination policy generalizes to unseen models and skills without any retraining.
- Adding out-of-domain experts to the registry raises average performance on four hard benchmarks above all closed-source baselines.
- The approach keeps latency low because only the small policy runs continuously while large models are called selectively.
Where Pith is reading between the lines
- Coordination and knowledge storage can be decoupled, allowing the same policy to serve many different expert pools over time.
- Similar lightweight RL orchestration could be tested on non-language domains such as tool use in robotics or scientific simulation pipelines.
- If the policy discovers reusable selection patterns, future registries might be built by adding specialists rather than scaling single models.
Load-bearing premise
That a policy trained only on outcome rewards from the given benchmarks will reliably identify and combine complementary strengths across arbitrary new models and skills.
What would settle it
Run the trained policy on a fresh multimodal benchmark whose required capabilities have no overlapping strengths with the training registry and observe whether accuracy falls below the best single model in the registry.
Figures









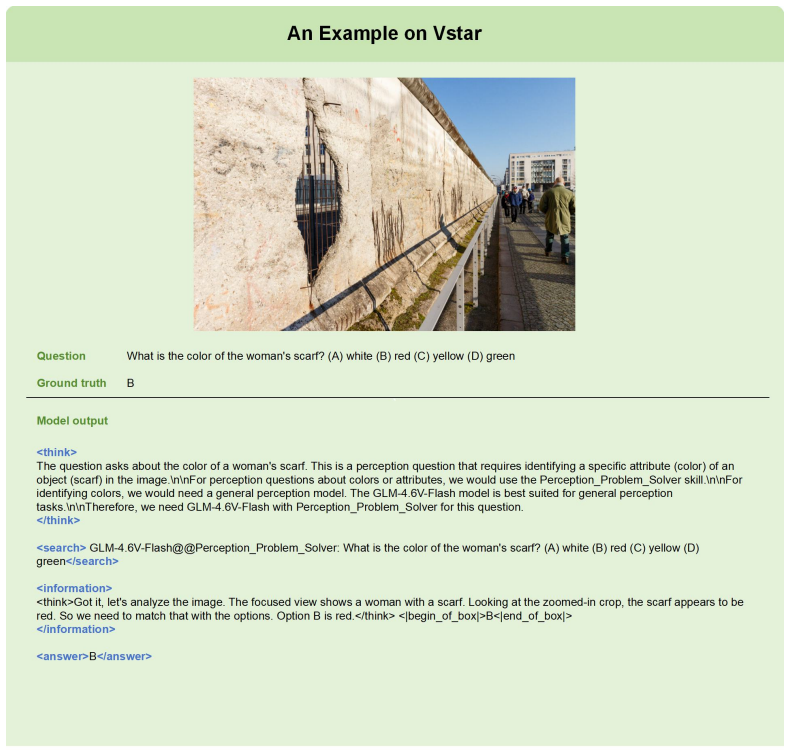













read the original abstract
The proliferation of large language models (LLMs) and modular skills has endowed autonomous agents with increasingly powerful capabilities. Existing frameworks typically rely on monolithic LLMs and fixed logic to interface with these skills. This gives rise to a critical bottleneck: different LLMs offer distinct advantages across diverse domains, yet current frameworks fail to exploit the complementary strengths of models and skills, thereby limiting their performance on downstream tasks. In this paper, we present Maestro (Multimodal Agent for Expert-Skill Targeted Reinforced Orchestration), a Reinforcement Learning (RL)-driven orchestration framework that reframes heterogeneous multimodal tasks as a sequential decision-making process over a hierarchical model-skill registry. Rather than consolidating all knowledge into a single model, Maestro trains a lightweight policy to dynamically compose ensembles of frozen expert models and a two-tier skill library, deciding at each step whether to invoke an external expert, which model-skill pair to select, and when to terminate. The policy is optimized via outcome-based RL, requiring no step-level supervision. We evaluate Maestro across ten representative multimodal benchmarks spanning mathematical reasoning, chart understanding, high-resolution perception, and domain-specific analysis. With only a 4B orchestrator, Maestro achieves an average accuracy of 70.1%, surpassing both GPT-5 (69.3%) and Gemini-2.5-Pro (68.7%). Crucially, the learned coordination policy generalizes to unseen models and skills without retraining: augmenting the registry with out-of-domain experts yields a 59.5% average on four challenging benchmarks, outperforming all closed-source baselines. Maestro further maintains high computational efficiency with low latency. The source code is available at https://github.com/jinyangwu/Maestro.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Maestro, a reinforcement learning framework that uses a lightweight 4B policy to orchestrate ensembles of frozen expert models and a hierarchical skill library for multimodal tasks. It reframes tasks as sequential decision processes, optimizing the policy with outcome-based RL without step-level supervision. The central empirical claims are an average accuracy of 70.1% on ten multimodal benchmarks, outperforming GPT-5 and Gemini-2.5-Pro, and successful generalization to unseen models and skills yielding 59.5% on four new benchmarks.
Significance. If the experimental results are robustly supported, this work highlights the potential of small learned orchestrators to exploit complementary strengths across heterogeneous frozen models and skills, offering an efficient alternative to monolithic large models for agentic systems. The availability of source code strengthens the contribution by enabling reproducibility.
major comments (2)
- [Abstract] Abstract: The performance claims (70.1% average accuracy surpassing GPT-5 at 69.3% and Gemini-2.5-Pro at 68.7%) are central to the paper's contribution, but the abstract supplies no details on benchmark construction, statistical tests, baseline implementations, or ablation controls. A full methods section is required to assess whether these numbers support the claim of effective orchestration.
- [Generalization results] Generalization results: The claim that the learned coordination policy generalizes to unseen models and skills without retraining (59.5% on four challenging benchmarks) is load-bearing for the argument that the RL policy discovers transferable coordination rather than benchmark-specific heuristics. However, insufficient details are provided on the augmentation of the registry, the characteristics of the new benchmarks, and controls for overfitting to the training task distribution, raising concerns about credit assignment in the long-horizon RL setup.
minor comments (1)
- [Abstract] The term 'two-tier skill library' is introduced without a clear definition or diagram, which could be clarified for readers unfamiliar with the hierarchical structure.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We have addressed each major comment below and will revise the manuscript accordingly to improve clarity and provide additional supporting details where needed.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance claims (70.1% average accuracy surpassing GPT-5 at 69.3% and Gemini-2.5-Pro at 68.7%) are central to the paper's contribution, but the abstract supplies no details on benchmark construction, statistical tests, baseline implementations, or ablation controls. A full methods section is required to assess whether these numbers support the claim of effective orchestration.
Authors: We agree that the abstract is necessarily concise and therefore omits granular experimental details. The full manuscript contains a dedicated Methods section (Section 3) that specifies benchmark construction for the ten multimodal tasks, implementation details for all baselines including GPT-5 and Gemini-2.5-Pro, ablation studies isolating the contribution of the hierarchical orchestration, and statistical reporting with standard deviations computed over multiple random seeds. To address the referee's point directly, we will revise the abstract to include a brief reference to the evaluation protocol and the presence of ablations and statistical controls in the main text. revision: yes
-
Referee: [Generalization results] Generalization results: The claim that the learned coordination policy generalizes to unseen models and skills without retraining (59.5% on four challenging benchmarks) is load-bearing for the argument that the RL policy discovers transferable coordination rather than benchmark-specific heuristics. However, insufficient details are provided on the augmentation of the registry, the characteristics of the new benchmarks, and controls for overfitting to the training task distribution, raising concerns about credit assignment in the long-horizon RL setup.
Authors: We appreciate the referee's emphasis on the generalization experiments. Section 4.3 of the manuscript describes the registry augmentation process, including the specific out-of-domain models and skills added. The four new benchmarks and their distinguishing characteristics are detailed in Section 5.3 and Appendix B. To further mitigate concerns about overfitting, we will add a new paragraph in the revised version reporting performance on an explicitly held-out task distribution and include policy trajectory visualizations demonstrating transferable coordination patterns. On credit assignment, the outcome-based RL formulation optimizes directly for final task success; we will expand the discussion in Section 6 to clarify how this objective encourages general strategies rather than task-specific heuristics. revision: yes
Circularity Check
No significant circularity: empirical RL results on external benchmarks
full rationale
The paper describes an RL-based orchestration framework evaluated empirically on ten multimodal benchmarks, with a 4B policy trained via outcome-based rewards and tested for generalization on augmented registries. No equations, derivations, or parameter-fitting steps are presented that reduce claims to self-referential inputs. Performance numbers (70.1% average, 59.5% on new benchmarks) are reported as measured outcomes against external baselines rather than quantities defined in terms of the same fitted data or self-citations. The derivation chain is therefore self-contained as standard experimental reporting.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL reward scaling and termination thresholds
axioms (1)
- domain assumption Heterogeneous frozen models and skills exhibit complementary strengths that can be exploited by dynamic selection.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize model-skill coordination as a finite-horizon POMDP and train the orchestration policy via outcome-based RL, requiring no step-level supervision of routing decisions.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The reward function R(τ) = r_ans + r_fmt ... outcome reward r_ans ... format reward r_fmt
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Tallyqa: Answering complex counting questions
Manoj Acharya, Kushal Kafle, and Christopher Kanan. Tallyqa: Answering complex counting questions. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 8076–8084, 2019
work page 2019
-
[2]
Claude code overview.https://code.claude.com/docs, 2025
Anthropic. Claude code overview.https://code.claude.com/docs, 2025
work page 2025
-
[3]
Intern-s1: A scientific multimodal foundation model.arXiv preprint arXiv:2508.15763, 2025
Lei Bai, Zhongrui Cai, Yuhang Cao, Maosong Cao, Weihan Cao, Chiyu Chen, Haojiong Chen, Kai Chen, Pengcheng Chen, Ying Chen, et al. Intern-s1: A scientific multimodal foundation model.arXiv preprint arXiv:2508.15763, 2025
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Multi-step visual reasoning with visual tokens scaling and verification
Tianyi Bai, Zengjie Hu, Fupeng Sun, Jiantao Qiu, Yizhen Jiang, Guangxin He, Bohan Zeng, Conghui He, Binhang Yuan, and Wentao Zhang. Multi-step visual reasoning with visual tokens scaling and verification. arXiv preprint arXiv:2506.07235, 2025
-
[6]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-bench: Evaluating conversational agents in a dual-control environment.arXiv preprint arXiv:2506.07982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Microvqa: A multi- modal reasoning benchmark for microscopy-based scientific research
James Burgess, Jeffrey J Nirschl, Laura Bravo-Sánchez, Alejandro Lozano, Sanket Rajan Gupte, Jesus G Galaz-Montoya, Yuhui Zhang, Yuchang Su, Disha Bhowmik, Zachary Coman, et al. Microvqa: A multi- modal reasoning benchmark for microscopy-based scientific research. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1...
work page 2025
-
[8]
Lei Chen, Xuanle Zhao, Zhixiong Zeng, Jing Huang, Yufeng Zhong, and Lin Ma. Chart-r1: Chain-of- thought supervision and reinforcement for advanced chart reasoner.arXiv preprint arXiv:2507.15509, 2025
-
[9]
Zixu Cheng, Jian Hu, Ziquan Liu, Chenyang Si, Wei Li, and Shaogang Gong. V-star: Benchmarking video-llms on video spatio-temporal reasoning.arXiv preprint arXiv:2503.11495, 2025
-
[10]
Yu Du, Fangyun Wei, and Hongyang Zhang. Anytool: Self-reflective, hierarchical agents for large-scale api calls.arXiv preprint arXiv:2402.04253, 2024
-
[11]
Group-in-group policy optimization for LLM agent training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for LLM agent training. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[12]
Lang Feng, Fuchao Yang, Feng Chen, Xin Cheng, Haiyang Xu, Zhenglin Wan, Ming Yan, and Bo An. Agentocr: Reimagining agent history via optical self-compression.arXiv preprint arXiv:2601.04786, 2026
-
[13]
DeepEyesV2: Toward Agentic Multimodal Model
Jack Hong, Chenxiao Zhao, ChengLin Zhu, Weiheng Lu, Guohai Xu, and Xing Yu. Deepeyesv2: Toward agentic multimodal model.arXiv preprint arXiv:2511.05271, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Step3-vl-10b technical report.arXiv preprint arXiv:2601.09668, 2026
Ailin Huang, Chengyuan Yao, Chunrui Han, Fanqi Wan, Hangyu Guo, Haoran Lv, Hongyu Zhou, Jia Wang, Jian Zhou, Jianjian Sun, et al. Step3-vl-10b technical report.arXiv preprint arXiv:2601.09668, 2026
-
[15]
Yue Huang, Jiawen Shi, Yuan Li, Chenrui Fan, Siyuan Wu, Qihui Zhang, Yixin Liu, Pan Zhou, Yao Wan, Neil Zhenqiang Gong, et al. Metatool benchmark for large language models: Deciding whether to use tools and which to use.arXiv preprint arXiv:2310.03128, 2023
-
[16]
Chengyou Jia, Minnan Luo, Zhuohang Dang, Qiushi Sun, Fangzhi Xu, Junlin Hu, Tianbao Xie, and Zhiyong Wu. Agentstore: Scalable integration of heterogeneous agents as specialized generalist computer assistant. InFindings of the Association for Computational Linguistics: ACL 2025, pages 8908–8934, 2025. 10
work page 2025
-
[17]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Erqa: Edge- restoration quality assessment for video super-resolution
Anastasia Kirillova., Eugene Lyapustin., Anastasia Antsiferova., and Dmitry Vatolin. Erqa: Edge- restoration quality assessment for video super-resolution. InProceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications - Volume 4: VISAPP ,, pages 315–322. INSTICC, SciTePress, 2022
work page 2022
-
[19]
Johnson, editors.Breakthroughs in Statistics: Methodology and Distribution
Samuel Kotz and Norman L. Johnson, editors.Breakthroughs in Statistics: Methodology and Distribution. Springer New York, New York, NY , 1992
work page 1992
-
[20]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, et al. Skillsbench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Appagent v2: Advanced agent for flexible mobile interactions.arXiv preprint arXiv:2408.11824, 2024
Yanda Li, Chi Zhang, Wenjia Jiang, Wanqi Yang, Bin Fu, Pei Cheng, Xin Chen, Ling Chen, and Yunchao Wei. Appagent v2: Advanced agent for flexible mobile interactions.arXiv preprint arXiv:2408.11824, 2024
-
[22]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[23]
Slake: A semantically-labeled knowledge-enhanced dataset for medical visual question answering
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. Slake: A semantically-labeled knowledge-enhanced dataset for medical visual question answering. In2021 IEEE 18th international symposium on biomedical imaging (ISBI), pages 1650–1654. IEEE, 2021
work page 2021
-
[24]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[25]
Ocrbench: on the hidden mystery of ocr in large multimodal models
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences, 67(12), December 2024. ISSN 1869-1919
work page 2024
-
[26]
Yuqi Liu, Tianyuan Qu, Zhisheng Zhong, Bohao Peng, Shu Liu, Bei Yu, and Jiaya Jia. Visionreasoner: Unified visual perception and reasoning via reinforcement learning.arXiv e-prints, pages arXiv–2505, 2025
work page 2025
-
[27]
Visual agentic reinforcement fine-tuning.arXiv preprint arXiv:2505.14246, 2025
Ziyu Liu, Yuhang Zang, Yushan Zou, Zijian Liang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual agentic reinforcement fine-tuning.arXiv preprint arXiv:2505.14246, 2025
-
[28]
Inter- gps: Interpretable geometry problem solving with formal language and symbolic reasoning
Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter- gps: Interpretable geometry problem solving with formal language and symbolic reasoning. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Vol...
work page 2021
-
[29]
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
Zhengxi Lu, Zhiyuan Yao, Jinyang Wu, Chengcheng Han, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. Skill0: In-context agentic reinforcement learning for skill internalization.arXiv preprint arXiv:2604.02268, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Automated creation of reusable and diverse toolsets for enhancing llm reasoning
Zhiyuan Ma, Zhenya Huang, Jiayu Liu, Minmao Wang, Hongke Zhao, and Xin Li. Automated creation of reusable and diverse toolsets for enhancing llm reasoning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24821–24830, 2025
work page 2025
-
[31]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. Advances in neural information processing systems, 36:46534–46594, 2023
work page 2023
-
[32]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022, pages 2263–2279, 2022
work page 2022
-
[33]
Codex — ai coding partner from openai.https://openai.com/codex/, 2025
OpenAI. Codex — ai coding partner from openai.https://openai.com/codex/, 2025
work page 2025
-
[34]
Skills - openclaw.https://docs.openclaw.ai/tools/skills, 2026
OpenClaw. Skills - openclaw.https://docs.openclaw.ai/tools/skills, 2026
work page 2026
-
[35]
Automind: Adaptive knowledgeable agent for automated data science
Yixin Ou, Yujie Luo, Jingsheng Zheng, Lanning Wei, Zhuoyun Yu, Shuofei Qiao, Jintian Zhang, Da Zheng, Yuren Mao, Yunjun Gao, et al. Automind: Adaptive knowledgeable agent for automated data science. arXiv preprint arXiv:2506.10974, 2025. 11
-
[36]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[37]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
work page 2023
-
[38]
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems, 37:126544–126565, 2024
work page 2024
-
[39]
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[40]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https://qwen.ai/ blog?id=qwen3.5
work page 2026
-
[42]
Vision language models are blind
Pooyan Rahmanzadehgervi, Logan Bolton, Mohammad Reza Taesiri, and Anh Totti Nguyen. Vision language models are blind. InProceedings of the Asian Conference on Computer Vision, pages 18–34, 2024
work page 2024
-
[43]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539–68551, 2023
work page 2023
-
[44]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
Andrew Sellergren, Chufan Gao, Fereshteh Mahvar, Timo Kohlberger, Fayaz Jamil, Madeleine Traverse, Alberto Tono, Bashir Sadjad, Lin Yang, Charles Lau, et al. Medgemma 1.5 technical report.arXiv preprint arXiv:2604.05081, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36:38154–38180, 2023
work page 2023
-
[47]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[48]
Vipergpt: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning. InProceedings of the IEEE/CVF international conference on computer vision, pages 11888– 11898, 2023
work page 2023
-
[49]
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases
Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun. Toolalpaca: Generalized tool learning for language models with 3000 simulated cases.arXiv preprint arXiv:2306.05301, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
SkillX: Automatically Constructing Skill Knowledge Bases for Agents
Chenxi Wang, Zhuoyun Yu, Xin Xie, Wuguannan Yao, Runnan Fang, Shuofei Qiao, Kexin Cao, Guozhou Zheng, Xiang Qi, Peng Zhang, et al. Skillx: Automatically constructing skill knowledge bases for agents. arXiv preprint arXiv:2604.04804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Skillorchestra: Learning to route agents via skill transfer.arXiv preprint arXiv:2602.19672, 2026
Jiayu Wang, Yifei Ming, Zixuan Ke, Shafiq Joty, Aws Albarghouthi, and Frederic Sala. Skillorchestra: Learning to route agents via skill transfer.arXiv preprint arXiv:2602.19672, 2026
-
[52]
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hong- sheng Li. Measuring multimodal mathematical reasoning with math-vision dataset.Advances in Neural Information Processing Systems, 37:95095–95169, 2024
work page 2024
-
[53]
Mathcoder-vl: Bridging vision and code for enhanced multimodal mathematical reasoning
Ke Wang, Junting Pan, Linda Wei, Aojun Zhou, Weikang Shi, Zimu Lu, Han Xiao, Yunqiao Yang, Houxing Ren, Mingjie Zhan, et al. Mathcoder-vl: Bridging vision and code for enhanced multimodal mathematical reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 2505–2534, 2025. 12
work page 2025
-
[54]
Wenbin Wang, Liang Ding, Minyan Zeng, Xiabin Zhou, Li Shen, Yong Luo, Wei Yu, and Dacheng Tao. Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7907–7915, 2025
work page 2025
-
[55]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[56]
Internvideo2: Scaling foundation models for multimodal video understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, et al. Internvideo2: Scaling foundation models for multimodal video understanding. InEuropean conference on computer vision, pages 396–416. Springer, 2024
work page 2024
-
[57]
Inducing programmatic skills for agentic tasks.arXiv preprint arXiv:2504.06821, 2025
Zora Zhiruo Wang, Apurva Gandhi, Graham Neubig, and Daniel Fried. Inducing programmatic skills for agentic tasks.arXiv preprint arXiv:2504.06821, 2025
-
[58]
Lai Wei, Liangbo He, Jun Lan, Lingzhong Dong, Yutong Cai, Siyuan Li, Huijia Zhu, Weiqiang Wang, Linghe Kong, Yue Wang, et al. Zooming without zooming: Region-to-image distillation for fine-grained multimodal perception.arXiv preprint arXiv:2602.11858, 2026
-
[59]
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Visual chatgpt: Talking, drawing and editing with visual foundation models.arXiv preprint arXiv:2303.04671, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
InThe 2023 Conference on Empirical Methods in Natural Language Processing
Jinyang Wu, Mingkuan Feng, Shuai Zhang, Feihu Che, Zengqi Wen, Chonghua Liao, and Jianhua Tao. Beyond examples: High-level automated reasoning paradigm in in-context learning via mcts.arXiv preprint arXiv:2411.18478, 2024
-
[61]
Jinyang Wu, Shuo Yang, Changpeng Yang, Yuhao Shen, Shuai Zhang, Zhengqi Wen, and Jianhua Tao. Spark: Strategic policy-aware exploration via dynamic branching for long-horizon agentic learning.arXiv preprint arXiv:2601.20209, 2026
-
[62]
Atlas: Orchestrating heterogeneous models and tools for multi-domain complex reasoning
Jinyang Wu, Guocheng Zhai, Ruihan Jin, Jiahao Yuan, Yuhao Shen, Shuai Zhang, Zhengqi Wen, and Jianhua Tao. Atlas: Orchestrating heterogeneous models and tools for multi-domain complex reasoning. arXiv preprint arXiv:2601.03872, 2026
-
[63]
Mingyuan Wu, Jingcheng Yang, Jize Jiang, Meitang Li, Kaizhuo Yan, Hanchao Yu, Minjia Zhang, Chengxiang Zhai, and Klara Nahrstedt. Vtool-r1: Vlms learn to think with images via reinforcement learning on multimodal tool use.arXiv preprint arXiv:2505.19255, 2025
-
[64]
Menglin Xia, Xuchao Zhang, Shantanu Dixit, Paramaguru Harimurugan, Rujia Wang, Victor Ruhle, Robert Sim, Chetan Bansal, and Saravan Rajmohan. Memora: A harmonic memory representation balancing abstraction and specificity.arXiv preprint arXiv:2602.03315, 2026
-
[65]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[66]
Yutao Yang, Junsong Li, Qianjun Pan, Bihao Zhan, Yuxuan Cai, Lin Du, Jie Zhou, Kai Chen, Qin Chen, Xin Li, et al. Autoskill: Experience-driven lifelong learning via skill self-evolution.arXiv preprint arXiv:2603.01145, 2026
-
[67]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[68]
Woongyeong Yeo, Kangsan Kim, Jaehong Yoon, and Sung Ju Hwang. Worldmm: Dynamic multimodal memory agent for long video reasoning.arXiv preprint arXiv:2512.02425, 2025
-
[69]
Craft: Customizing llms by creating and retrieving from specialized toolsets,
Lifan Yuan, Yangyi Chen, Xingyao Wang, Yi R Fung, Hao Peng, and Heng Ji. Craft: Customizing llms by creating and retrieving from specialized toolsets.arXiv preprint arXiv:2309.17428, 2023
-
[70]
Easytool: Enhancing llm-based agents with concise tool instruction
Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Yongliang Shen, Kan Ren, Dongsheng Li, and Deqing Yang. Easytool: Enhancing llm-based agents with concise tool instruction. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 9...
work page 2025
-
[71]
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. 13
work page 2026
-
[72]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
Humaneval-v: benchmarking high-level visual reasoning with complex diagrams in coding tasks
Fengji Zhang, Linquan Wu, Huiyu Bai, Guancheng Lin, Xiao Li, Xiao Yu, Yue Wang, Bei Chen, and Jacky Keung. Humaneval-v: benchmarking high-level visual reasoning with complex diagrams in coding tasks. arXiv preprint arXiv:2410.12381, 2024
-
[74]
Adaptive Chain-of-Focus Reasoning via Dynamic Visual Search and Zooming for Efficient VLMs
Xintong Zhang, Zhi Gao, Bofei Zhang, Pengxiang Li, Xiaowen Zhang, Yang Liu, Tao Yuan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, et al. Adaptive chain-of-focus reasoning via dynamic visual search and zooming for efficient vlms.arXiv preprint arXiv:2505.15436, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Yi-Fan Zhang, Xingyu Lu, Shukang Yin, Chaoyou Fu, Wei Chen, Xiao Hu, Bin Wen, Kaiyu Jiang, Changyi Liu, Tianke Zhang, et al. Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
RLVMR: Reinforcement learning with verifiable meta-reasoning rewards for robust long-horizon agents
Zijing Zhang, Ziyang Chen, Mingxiao Li, Zhaopeng Tu, and Xiaolong Li. RLVMR: Reinforcement learning with verifiable meta-reasoning rewards for robust long-horizon agents. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[77]
MSEarth: A Multimodal Benchmark for Earth Science Phenomenon Discovery with MLLMs
Xiangyu Zhao, Wanghan Xu, Bo Liu, Yuhao Zhou, Fenghua Ling, Ben Fei, Xiaoyu Yue, Lei Bai, Wenlong Zhang, and Xiao-Ming Wu. Msearth: A multimodal scientific dataset and benchmark for phenomena uncovering in earth science.arXiv preprint arXiv:2505.20740, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Skillrouter: Skill routing for llm agents at scale.arXiv e-prints, pages arXiv–2603, 2026
YanZhao Zheng, ZhenTao Zhang, Chao Ma, YuanQiang Yu, JiHuai Zhu, Yong Wu, Tianze Xu, Baohua Dong, Hangcheng Zhu, Ruohui Huang, et al. Skillrouter: Skill routing for llm agents at scale.arXiv e-prints, pages arXiv–2603, 2026
work page 2026
-
[79]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362, 2025. 14 Contents A Theoretical Analysis 16 A.1 Problem Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 A.2 Hierarchic...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
Geometric_Problem_Solver: Use for geometry diagrams, figures, angles, lengths, areas
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.