CLOVER: Closed-Loop Value Estimation and Ranking for End-to-End Autonomous Driving Planning
Pith reviewed 2026-05-20 20:52 UTC · model grok-4.3
The pith
A generator-scorer loop with pseudo-expert trajectories and conservative self-distillation closes the training-evaluation gap in end-to-end driving planners.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CLOVER follows a lightweight generator-scorer formulation: a generator produces diverse candidate trajectories, and a scorer predicts planning-metric sub-scores to rank them at inference time. To expand proposal support beyond single-trajectory imitation, CLOVER constructs evaluator-filtered pseudo-expert trajectories and trains the generator with set-level coverage supervision. It then performs conservative closed-loop self-distillation: the scorer is fitted to true evaluator sub-scores on generated proposals, while the generator is refined toward teacher-selected top-k and vector-Pareto targets with stability regularization. Analysis shows that an imperfect scorer can still improve the the
What carries the argument
Generator-scorer formulation with evaluator-filtered pseudo-expert trajectories and conservative closed-loop self-distillation that lets the scorer's ranking guide generator updates.
If this is right
- The generator covers more valid trajectories than pure imitation learning.
- Scorer-based ranking selects plans that better satisfy safety and comfort metrics at test time.
- Performance gains appear on both standard and harder NavHard splits.
- Open-loop metrics such as L2 error and collision rate also improve on nuScenes.
Where Pith is reading between the lines
- The conservative update rule could limit error propagation from noisy scorers in other imitation settings outside driving.
- The same generator-scorer structure might transfer to robotic motion planning where evaluation metrics also differ from demonstration data.
- Vector-Pareto selection inside the loop offers a route to explicit multi-objective trade-offs without extra human labels.
Load-bearing premise
Evaluator-filtered pseudo-expert trajectories add useful coverage beyond single-trajectory imitation, and scorer-guided refinements stay reliable when kept conservative.
What would settle it
Removing the set-level supervision on pseudo-expert trajectories and measuring whether PDMS and EPDMS on NAVSIM drop below the reported state-of-the-art values.
Figures



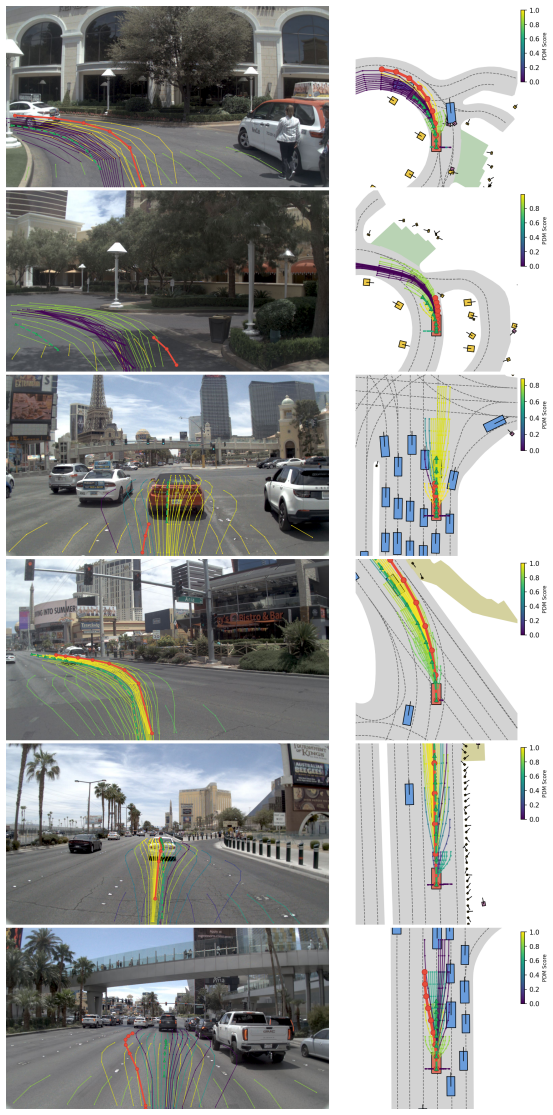

read the original abstract
End-to-end autonomous driving planners are commonly trained by imitating a single logged trajectory, yet evaluated by rule-based planning metrics that measure safety, feasibility, progress, and comfort. This creates a training--evaluation mismatch: trajectories close to the logged path may violate planning rules, while alternatives farther from the demonstration can remain valid and high-scoring. The mismatch is especially limiting for proposal-selection planners, whose performance depends on candidate-set coverage and scorer ranking quality. We propose CLOVER, a Closed-LOop Value Estimation and Ranking framework for end-to-end autonomous driving planning. CLOVER follows a lightweight generator--scorer formulation: a generator produces diverse candidate trajectories, and a scorer predicts planning-metric sub-scores to rank them at inference time. To expand proposal support beyond single-trajectory imitation, CLOVER constructs evaluator-filtered pseudo-expert trajectories and trains the generator with set-level coverage supervision. It then performs conservative closed-loop self-distillation: the scorer is fitted to true evaluator sub-scores on generated proposals, while the generator is refined toward teacher-selected top-$k$ and vector-Pareto targets with stability regularization. We analyze when an imperfect scorer can improve the generator, showing that scorer-mediated refinement is reliable when scorer-selected targets are enriched under the true evaluator and updates remain conservative. On NAVSIM, CLOVER achieves 94.5 PDMS and 90.4 EPDMS, establishing a new state of the art. On the more challenging NavHard split, it obtains 48.3 EPDMS, matching the strongest reported result. On supplementary nuScenes open-loop evaluation, CLOVER achieves the lowest L2 error and collision rate among compared methods. Code data will be released at https://github.com/WilliamXuanYu/CLOVER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CLOVER, a Closed-Loop Value Estimation and Ranking framework for end-to-end autonomous driving planning. It uses a generator to produce diverse candidate trajectories and a scorer to predict planning metric sub-scores for ranking. To address the training-evaluation mismatch, it constructs evaluator-filtered pseudo-expert trajectories for set-level coverage supervision and performs conservative closed-loop self-distillation, fitting the scorer to true evaluator sub-scores and refining the generator toward scorer-selected top-k and vector-Pareto targets. The method achieves state-of-the-art results on NAVSIM with 94.5 PDMS and 90.4 EPDMS, and 48.3 EPDMS on NavHard, with additional strong performance on nuScenes open-loop evaluation.
Significance. If the results are robust, this framework could have significant impact by better aligning training with evaluation metrics in autonomous driving, potentially leading to safer and more effective planners. The theoretical analysis on the conditions for successful scorer-mediated refinement adds value, and the commitment to releasing code supports reproducibility in the field.
major comments (2)
- The SOTA claims on NAVSIM (94.5 PDMS, 90.4 EPDMS) and NavHard (48.3 EPDMS) are presented without detailed ablation studies or error analysis isolating the closed-loop refinement from the pseudo-expert coverage. This is critical because the central claim relies on the reliability of scorer-mediated updates, yet no quantitative assessment of scorer error on generated proposals is provided.
- The analysis shows that refinement is reliable under conservative updates and enriched targets, but lacks a bound on scorer prediction error for proposals from the generator's distribution, which may differ from the training pseudo-experts. This is load-bearing for the NavHard results where distribution shift could be pronounced.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We appreciate the acknowledgment of the framework's potential impact and the value of the theoretical analysis. We address the major comments below by clarifying existing elements of the work and committing to targeted revisions that strengthen the empirical support for our claims without altering the core contributions.
read point-by-point responses
-
Referee: The SOTA claims on NAVSIM (94.5 PDMS, 90.4 EPDMS) and NavHard (48.3 EPDMS) are presented without detailed ablation studies or error analysis isolating the closed-loop refinement from the pseudo-expert coverage. This is critical because the central claim relies on the reliability of scorer-mediated updates, yet no quantitative assessment of scorer error on generated proposals is provided.
Authors: We agree that stronger isolation of components would improve clarity. The manuscript already contains ablations on set-level coverage and self-distillation, but we will expand these in the revision to explicitly separate the contributions of pseudo-expert trajectories from the closed-loop scorer-mediated updates. We will also add quantitative evaluation of scorer prediction error (e.g., MAE and ranking accuracy) specifically on proposals sampled from the generator, both before and after refinement, to directly address reliability of the scorer-mediated step. revision: yes
-
Referee: The analysis shows that refinement is reliable under conservative updates and enriched targets, but lacks a bound on scorer prediction error for proposals from the generator's distribution, which may differ from the training pseudo-experts. This is load-bearing for the NavHard results where distribution shift could be pronounced.
Authors: The theoretical section derives conditions for successful refinement that explicitly tolerate imperfect scorers, relying on conservative updates and target enrichment rather than requiring zero error. A general, assumption-free bound on scorer error under generator-induced distribution shift is not provided because it would require strong additional assumptions on the scorer architecture and data that are not realistic for this setting. In revision we will add empirical quantification of scorer error on generator proposals, including a direct comparison between pseudo-expert and generator distributions, and a focused discussion of observed shift on the NavHard split to substantiate the reported results. revision: partial
Circularity Check
No significant circularity: CLOVER refinement uses external evaluator for scorer fitting and conservative updates
full rationale
The derivation chain begins with single-trajectory imitation, expands via evaluator-filtered pseudo-experts for generator coverage, fits scorer to true evaluator sub-scores on proposals, and refines generator toward scorer-selected top-k and Pareto targets under stability regularization. This does not reduce to the original inputs by construction, as the pseudo-expert enrichment and closed-loop selection introduce non-tautological steps. The reliability analysis conditions the improvement on scorer enrichment under the true evaluator and conservative updates, which are external to the fitted parameters. No self-definitional, fitted-input-renamed-as-prediction, or self-citation load-bearing steps appear. The SOTA metrics are reported as empirical results on NAVSIM and NavHard, not derived algebraically from the training inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Evaluator sub-scores provide reliable ground truth for training the scorer.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We analyze when an imperfect scorer can improve the generator, showing that scorer-mediated refinement is reliable when scorer-selected targets are statistically enriched under the true evaluator and updates remain conservative.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Selected-set enrichment improves high-score support)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InCVPR, 2020
work page 2020
-
[2]
Pseudo-simulation for autonomous driving
Wei Cao, Marcel Hallgarten, Tianyu Li, Daniel Dauner, Xunjiang Gu, Caojun Wang, Yakov Miron, Marco Aiello, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, Andreas Geiger, and Kashyap Chitta. Pseudo-simulation for autonomous driving. InCoRL, 2025
work page 2025
-
[3]
Devil is in narrow policy: Unleashing exploration in driving vla models, 2026
Canyu Chen, Yuguang Yang, Zhewen Tan, Yizhi Wang, Ruiyi Zhan, Haiyan Liu, Xuanyao Mao, Jason Bao, Xinyue Tang, Linlin Yang, Bingchuan Sun, Yan Wang, and Baochang Zhang. Devil is in narrow policy: Unleashing exploration in driving vla models, 2026. URL https: //arxiv.org/abs/2603.06049
-
[4]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning.arXiv preprint arXiv:2402.13243, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Yuntao Chen, Yuqi Wang, and Zhaoxiang Zhang. Drivinggpt: Unifying driving world modeling and planning with multi-modal autoregressive transformers.arXiv preprint arXiv:2412.18607, 2024. 12 Table 8:Ablation of teacher-set construction in Stage 2.Scalar real-PDMS top- k targets tend to concentrate proposals around a narrow high-score mode. Distance suppress...
- [6]
-
[7]
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(11):12878–12895, 2022
work page 2022
-
[8]
Parting with miscon- ceptions about learning-based vehicle motion planning
Daniel Dauner, Marcel Hallgarten, Andreas Geiger, and Kashyap Chitta. Parting with miscon- ceptions about learning-based vehicle motion planning. InCoRL, 2023
work page 2023
-
[9]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, et al. Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking. InNeurIPS, 2024
work page 2024
-
[10]
Rap: 3d rasterization augmented end-to-end planning.arXiv preprint arXiv:2510.04333, 2025
Lan Feng, Yang Gao, Eloi Zablocki, Quanyi Li, Wuyang Li, Sichao Liu, Matthieu Cord, and Alexandre Alahi. Rap: 3d rasterization augmented end-to-end planning.arXiv preprint arXiv:2510.04333, 2025
-
[11]
Renju Feng, Ning Xi, Duanfeng Chu, Rukang Wang, Zejian Deng, Anzheng Wang, Liping Lu, Jinxiang Wang, and Yanjun Huang. Artemis: Autoregressive end-to-end trajectory planning with mixture of experts for autonomous driving.arXiv preprint arXiv:2504.19580, 2025
-
[12]
ipad: Iterative proposal-centric end-to-end autonomous driving.arXiv preprint arXiv:2505.15111, 2025
Ke Guo, Haochen Liu, Xiaojun Wu, Jia Pan, and Chen Lv. ipad: Iterative proposal-centric end-to-end autonomous driving.arXiv preprint arXiv:2505.15111, 2025
-
[13]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. InICLR, 2022
work page 2022
-
[14]
St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning
Shengchao Hu, Li Chen, Penghao Wu, Hongyang Li, Junchi Yan, and Dacheng Tao. St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. InEuropean Conference on Computer Vision, pages 533–549. Springer, 2022
work page 2022
-
[15]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, Lewei Lu, Xiaosong Jia, Qiang Liu, Jifeng Dai, Yu Qiao, and Hongyang Li. Planning-oriented autonomous driving. InCVPR, 2023
work page 2023
-
[16]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InCVPR, pages 17853–17862, 2023. 13
work page 2023
-
[17]
EMMA: End-to-End Multimodal Model for Autonomous Driving
Jyh-Jing Hwang, Runsheng Xu, Hubert Lin, Wei-Chih Hung, Jingwei Ji, Kristy Choi, Di Huang, Tong He, Paul Covington, Benjamin Sapp, et al. Emma: End-to-end multimodal model for autonomous driving.arXiv preprint arXiv:2410.23262, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Vad: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. InICCV, 2023
work page 2023
-
[19]
Siwen Jiao, Kangan Qian, Hao Ye, Yang Zhong, Ziang Luo, Sicong Jiang, Zilin Huang, Yangyi Fang, Jinyu Miao, Zheng Fu, et al. Evadrive: Evolutionary adversarial policy optimization for end-to-end autonomous driving.arXiv preprint arXiv:2508.09158, 2025
-
[20]
Driving on registers.arXiv preprint arXiv:2601.05083, 2026
Ellington Kirby, Alexandre Boulch, Yihong Xu, Yuan Yin, Gilles Puy, Éloi Zablocki, Andrei Bursuc, Spyros Gidaris, Renaud Marlet, Florent Bartoccioni, et al. Driving on registers.arXiv preprint arXiv:2601.05083, 2026
-
[21]
Kailin Li, Zhenxin Li, Shiyi Lan, Yuan Xie, Zhizhong Zhang, Jiayi Liu, Zuxuan Wu, Zhiding Yu, and Jose M Alvarez. Hydra-mdp++: Advancing end-to-end driving via expert-guided hydra-distillation.arXiv e-prints, pages arXiv–2503, 2025
work page 2025
-
[22]
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Yingyan Li, Shuyao Shang, Weisong Liu, Bing Zhan, Haochen Wang, Yuqi Wang, Yuntao Chen, Xiaoman Wang, Yasong An, Chufeng Tang, et al. Drivevla-w0: World models amplify data scaling law in autonomous driving.arXiv preprint arXiv:2510.12796, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing Wang, et al. Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving.arXiv preprint arXiv:2506.08052, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, et al. Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation.arXiv preprint arXiv:2406.06978, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Zhenxin Li, Wenhao Yao, Zi Wang, Xinglong Sun, Joshua Chen, Nadine Chang, Maying Shen, Zuxuan Wu, Shiyi Lan, and Jose M Alvarez. Generalized trajectory scoring for end-to-end multimodal planning.arXiv preprint arXiv:2506.06664, 2025
-
[26]
Zhiqi Li, Zhiding Yu, Shiyi Lan, Jiahan Li, Jan Kautz, Tong Lu, and Jose M Alvarez. Is ego status all you need for open-loop end-to-end autonomous driving? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14864–14873, 2024
work page 2024
-
[27]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InCVPR, pages 12037–12047, 2025
work page 2025
-
[28]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jégou, Julien Mairal, Patrick L...
work page 2024
-
[29]
Drivex: Omni scene modeling for learning generalizable world knowledge in autonomous driving
Chen Shi, Shaoshuai Shi, Kehua Sheng, Bo Zhang, and Li Jiang. Drivex: Omni scene modeling for learning generalizable world knowledge in autonomous driving. InICCV, 2025
work page 2025
-
[30]
Centaur: Robust end-to-end autonomous driving with test-time training
Chonghao Sima, Kashyap Chitta, Zhiding Yu, Shiyi Lan, Ping Luo, Andreas Geiger, Hongyang Li, and Jose M Alvarez. Centaur: Robust end-to-end autonomous driving with test-time training. arXiv preprint arXiv:2503.11650, 2025
-
[31]
DIVER: Reinforced Diffusion Breaks Imitation Bottlenecks in End-to-End Autonomous Driving
Ziying Song, Lin Liu, Hongyu Pan, Bencheng Liao, Mingzhe Guo, Lei Yang, Yongchang Zhang, Shaoqing Xu, Caiyan Jia, and Yadan Luo. Breaking imitation bottlenecks: Reinforced diffusion powers diverse trajectory generation.arXiv preprint arXiv:2507.04049, 2025. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Wenchao Sun, Xuewu Lin, Keyu Chen, Zixiang Pei, Xiang Li, Yining Shi, and Sifa Zheng. Sparsedrivev2: Scoring is all you need for end-to-end autonomous driving, 2026. URL https: //arxiv.org/abs/2603.29163
-
[33]
Unified vision-language-action model.arXiv preprint arXiv:2506.19850, 2025
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xin- long Wang, and Zhaoxiang Zhang. Unified vision-language-action model.arXiv preprint arXiv:2506.19850, 2025
-
[34]
Para-drive: Paral- lelized architecture for real-time autonomous driving
Xinshuo Weng, Boris Ivanovic, Yan Wang, Yue Wang, and Marco Pavone. Para-drive: Paral- lelized architecture for real-time autonomous driving. InCVPR, 2024
work page 2024
-
[35]
PRIX: Learning to Plan from Raw Pixels for End-to-End Autonomous Driving
Maciej K Wozniak, Lianhang Liu, Yixi Cai, and Patric Jensfelt. Prix: Learning to plan from raw pixels for end-to-end autonomous driving.arXiv preprint arXiv:2507.17596, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Openemma: Open-source multimodal model for end-to-end autonomous driving
Shuo Xing, Chengyuan Qian, Yuping Wang, Hongyuan Hua, Kexin Tian, Yang Zhou, and Zhengzhong Tu. Openemma: Open-source multimodal model for end-to-end autonomous driving. InProceedings of the Winter Conference on Applications of Computer Vision, pages 1001–1009, 2025
work page 2025
-
[37]
Zebin Xing, Xingyu Zhang, Yang Hu, Bo Jiang, Tong He, Qian Zhang, Xiaoxiao Long, and Wei Yin. Goalflow: Goal-driven flow matching for multimodal trajectories generation in end-to-end autonomous driving. InCVPR, 2025
work page 2025
-
[38]
Wenhao Yao, Zhenxin Li, Shiyi Lan, Zi Wang, Xinglong Sun, Jose M Alvarez, and Zuxuan Wu. Drivesuprim: Towards precise trajectory selection for end-to-end planning.arXiv preprint arXiv:2506.06659, 2025
-
[39]
Chengran Yuan, Zhanqi Zhang, Jiawei Sun, Shuo Sun, Zefan Huang, Christina Dao Wen Lee, Dongen Li, Yuhang Han, Anthony Wong, Keng Peng Tee, et al. Drama: An efficient end-to-end motion planner for autonomous driving with mamba.arXiv preprint arXiv:2408.03601, 2024
-
[40]
World4drive: End-to-end autonomous driving via intention-aware physical latent world model
Yupeng Zheng, Pengxuan Yang, Zebin Xing, Qichao Zhang, Yuhang Zheng, Yinfeng Gao, Pengfei Li, Teng Zhang, Zhongpu Xia, Peng Jia, et al. World4drive: End-to-end autonomous driving via intention-aware physical latent world model. InICCV, 2025
work page 2025
-
[41]
Open- drivevla: Towards end-to-end autonomous driving with large vision language action model
Xingcheng Zhou, Xuyuan Han, Feng Yang, Yunpu Ma, V olker Tresp, and Alois Knoll. Open- drivevla: Towards end-to-end autonomous driving with large vision language action model. arXiv preprint arXiv:2503.23463, 2025
-
[42]
Zewei Zhou, Tianhui Cai, Seth Z Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning.arXiv preprint arXiv:2506.13757, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
re- gions important for driving
Jialv Zou, Shaoyu Chen, Bencheng Liao, Zhiyu Zheng, Yuehao Song, Lefei Zhang, Qian Zhang, Wenyu Liu, and Xinggang Wang. Diffusiondrivev2: Reinforcement learning-constrained trun- cated diffusion modeling in end-to-end autonomous driving.arXiv preprint arXiv:2512.07745, 2025. 15 A Pseudo-Expert Trajectory Generation CLOVER uses pseudo-expert trajectories t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.