VISD: Enhancing Video Reasoning via Structured Self-Distillation
Pith reviewed 2026-05-25 06:05 UTC · model grok-4.3
The pith
VISD introduces structured self-distillation to supply diagnostically specific token-level supervision for VideoLLMs, stably combined with reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VISD is a structured self-distillation framework that uses a video-aware judge model to decompose reasoning quality into multiple dimensions including answer correctness, logical consistency, and spatio-temporal grounding. This structured feedback guides a teacher policy for token-level supervision. To integrate the dense signals stably with RL, the framework introduces a direction-magnitude decoupling mechanism where rollout-level advantages determine update direction and the privileged signals modulate token-level update magnitudes. Curriculum scheduling and EMA-based teacher stabilization further support robust optimization over long sequences.
What carries the argument
Direction-magnitude decoupling mechanism that uses rollout advantages to set policy update direction while structured judge signals control token-level update magnitudes.
If this is right
- VideoLLMs achieve higher answer accuracy on diverse reasoning benchmarks.
- Spatio-temporal grounding quality in generated responses improves.
- Training reaches target performance in nearly half the optimization steps.
- Credit assignment over long reasoning trajectories becomes finer-grained and more semantically aligned.
Where Pith is reading between the lines
- The decoupling approach could stabilize dense supervision in other long-sequence generative tasks outside video.
- Swapping in a stronger judge model might increase the performance gains without changing the rest of the training setup.
- Diagnostic decomposition of quality signals may prove useful for reducing instability when mixing dense and verifiable rewards in multimodal models.
Load-bearing premise
A video-aware judge model can reliably decompose reasoning quality into the dimensions of correctness, logical consistency, and spatio-temporal grounding to supply stable, non-biased privileged signals.
What would settle it
An ablation that removes the structured judge feedback and finds no remaining gains in answer accuracy, grounding quality, or convergence speed compared with standard RLVR would falsify the central claim.
Figures









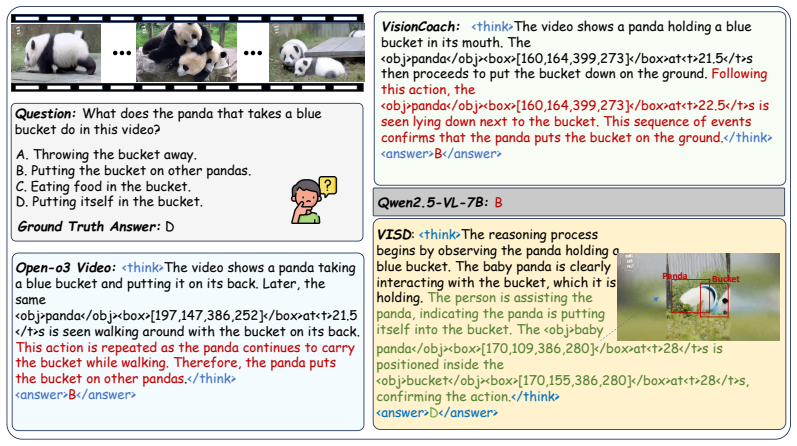


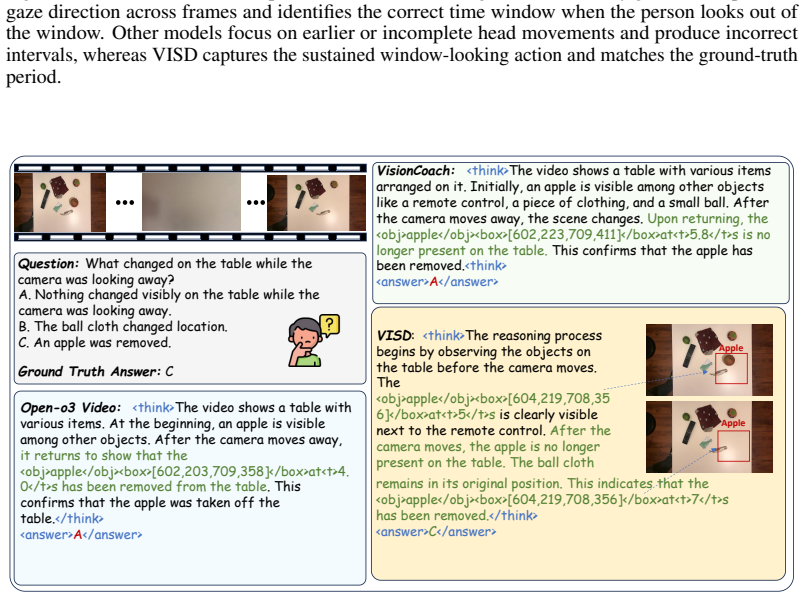




read the original abstract
Training VideoLLMs for complex reasoning remains challenging due to sparse sequence level rewards and the lack of fine grained credit assignment over long, temporally grounded reasoning trajectories. While reinforcement learning with verifiable rewards (RLVR) provides reliable supervision, it fails to capture token level contributions, leading to inefficient learning. Conversely, existing self distillation methods offer dense supervision but lack structure and diagnostic specificity, and often interact unstably with reinforcement learning. In this work, we propose VISD, a structured self distillation framework that introduces diagnostically meaningful privileged information for video reasoning. VISD employs a video aware judge model to decompose reasoning quality into multiple dimensions, including answer correctness, logical consistency, and spatio-temporal grounding, and uses this structured feedback to guide a teacher policy for token level supervision. To stably integrate dense supervision with RL, we introduce a direction magnitude decoupling mechanism, where rollout level advantages computed from rewards determine update direction, while structured privileged signals modulate token level update magnitudes. This design enables semantically aligned and fine grained credit assignment, improving both reasoning faithfulness and training efficiency. Additionally, VISD incorporates curriculum scheduling and EMA based teacher stabilization to support robust optimization over long video sequences. Experiments on diverse benchmarks show that VISD consistently outperforms strong baselines, improving answer accuracy and spatio temporal grounding quality. Notably, VISD reaches these gains with nearly 2x faster convergence in optimization steps, highlighting the effectiveness of structured self supervision in improving both performance and sample efficiency for VideoLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VISD, a structured self-distillation framework for VideoLLMs. It introduces a video-aware judge model that decomposes reasoning quality into dimensions including answer correctness, logical consistency, and spatio-temporal grounding to supply token-level privileged signals. These are integrated with RL via a direction-magnitude decoupling mechanism (rollout advantages set update direction; privileged signals modulate magnitudes), plus curriculum scheduling and EMA-based teacher stabilization. The central empirical claim is consistent outperformance over strong baselines on diverse benchmarks, with gains in answer accuracy and spatio-temporal grounding quality, achieved at nearly 2x faster convergence in optimization steps.
Significance. If the reported gains hold under rigorous verification, the work would demonstrate a practical way to combine dense structured supervision with verifiable RL rewards for long-horizon video reasoning, addressing sparse credit assignment while maintaining stability. The direction-magnitude decoupling and judge-based decomposition are concrete contributions that could generalize beyond the specific VideoLLM setting.
major comments (1)
- [Abstract / Experiments] Abstract and Experiments section: the central claim of 'consistent outperformance' and 'nearly 2x faster convergence' is stated without any reported benchmarks, baselines, metrics (e.g., accuracy, grounding scores), number of runs, variance, or statistical tests. This absence prevents assessment of whether the judge model and decoupling mechanism actually produce the claimed gains.
minor comments (2)
- [Method] The description of the judge model as 'video-aware' is introduced without a formal definition or architecture diagram; a concrete specification (e.g., input format, output tokenization) would clarify how the multi-dimensional signals are generated.
- [Method] Notation for the direction-magnitude decoupling (advantages vs. magnitudes) is described in prose but would benefit from an explicit equation or pseudocode block to show the precise update rule.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The single major comment highlights an important presentational issue regarding the reporting of empirical results. We address it directly below.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim of 'consistent outperformance' and 'nearly 2x faster convergence' is stated without any reported benchmarks, baselines, metrics (e.g., accuracy, grounding scores), number of runs, variance, or statistical tests. This absence prevents assessment of whether the judge model and decoupling mechanism actually produce the claimed gains.
Authors: We agree that the current abstract and experiments section do not provide the specific quantitative details needed for independent assessment. The manuscript text supplied to the review process contained only high-level claims without the supporting tables, exact benchmark names, baseline comparisons, metric values, run counts, standard deviations, or significance tests. In the revised version we will (1) revise the abstract to include the key numerical results (e.g., accuracy deltas and convergence-step ratios on each dataset), (2) expand the experiments section with full tables listing all baselines, metrics (answer accuracy, spatio-temporal grounding scores), number of random seeds, variance, and statistical tests, and (3) explicitly link the reported gains to the judge-model dimensions and direction-magnitude decoupling. These additions will make the empirical support verifiable. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via empirical procedure
full rationale
The paper introduces VISD as a training framework combining a video-aware judge for multi-dimensional feedback with a direction-magnitude decoupling mechanism for RL integration. No equations, fitted parameters, or self-citations are presented that would reduce any claimed prediction or result to an input quantity by construction. The abstract and described method rely on procedural definitions and benchmark experiments for validation, with no load-bearing self-referential steps or uniqueness theorems invoked. This is the standard case of an empirical method paper whose central claims remain independently testable.
Axiom & Free-Parameter Ledger
invented entities (1)
-
video-aware judge model
no independent evidence
Forward citations
Cited by 2 Pith papers
-
A Brief Overview: On-Policy Self-Distillation In Large Language Models
OPSD lets a single LLM distill its own reasoning by sampling trajectories from the student role while granting the teacher role privileged access to verified solutions, reducing memory needs versus separate-model dist...
-
A Brief Overview: On-Policy Self-Distillation In Large Language Models
This overview paper explains the conceptual foundations and design principles of On-Policy Self-Distillation for large language models from a beginner's perspective.
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe twelfth international conference on learning representations, 2024
work page 2024
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Datasets and recipes for video temporal grounding via reinforcement learning
Ruizhe Chen, Tianze Luo, Zhiting Fan, Heqing Zou, Zhaopeng Feng, Guiyang Xie, Hansheng Zhang, Zhuochen Wang, Zuozhu Liu, and Zhang Huaijian. Datasets and recipes for video temporal grounding via reinforcement learning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 983–992, 2025
work page 2025
-
[4]
Longvila: Scaling long-context visual language models for long videos
Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, et al. Longvila: Scaling long-context visual language models for long videos. InThe Thirteenth International Conference on Learning Representa- tions, 2024
work page 2024
-
[5]
Scaling rl to long videos.arXiv preprint arXiv:2507.07966, 2025
Yukang Chen, Wei Huang, Baifeng Shi, Qinghao Hu, Hanrong Ye, Ligeng Zhu, Zhijian Liu, Pavlo Molchanov, Jan Kautz, Xiaojuan Qi, et al. Scaling rl to long videos.arXiv preprint arXiv:2507.07966, 2025
-
[6]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shen- glong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Zixu Cheng, Jian Hu, Ziquan Liu, Chenyang Si, Wei Li, and Shaogang Gong. V-star: Bench- marking video-llms on video spatio-temporal reasoning.arXiv preprint arXiv:2503.11495, 2025
-
[8]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
Chaoyou Fu, Haozhi Yuan, Yuhao Dong, Yi-Fan Zhang, Yunhang Shen, Xiaoxing Hu, Xueying Li, Jinsen Su, Chengwu Long, Xiaoyao Xie, et al. Video-mme-v2: Towards the next stage in benchmarks for comprehensive video understanding.arXiv preprint arXiv:2604.05015, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Tommaso Furlanello, Zachary Lipton, Michael Tschannen, Laurent Itti, and Anima Anandkumar. Born again neural networks. InInternational conference on machine learning, pages 1607–1616. PMLR, 2018
work page 2018
-
[12]
Tall: Temporal activity localization via language query
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. Tall: Temporal activity localization via language query. InProceedings of the IEEE international conference on computer vision, pages 5267–5275, 2017
work page 2017
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Trace: Temporal grounding video llm via causal event modeling.arXiv preprint arXiv:2410.05643, 2024
Yongxin Guo, Jingyu Liu, Mingda Li, Qingbin Liu, Xi Chen, and Xiaoying Tang. Trace: Temporal grounding video llm via causal event modeling.arXiv preprint arXiv:2410.05643, 2024
-
[15]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. 2015
work page 2015
-
[16]
WorldSense: Evaluating Real-world Omnimodal Understanding for Multimodal LLMs
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluat- ing real-world omnimodal understanding for multimodal llms.arXiv preprint arXiv:2502.04326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Kairui Hu, Penghao Wu, Fanyi Pu, Wang Xiao, Yuanhan Zhang, Xiang Yue, Bo Li, and Ziwei Liu. Video-mmmu: Evaluating knowledge acquisition from multi-discipline professional videos. arXiv preprint arXiv:2501.13826, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Daeun Lee, Shoubin Yu, Yue Zhang, and Mohit Bansal. Visioncoach: Reinforcing grounded video reasoning via visual-perception prompting.arXiv preprint arXiv:2603.14659, 2026
-
[21]
Gengsheng Li, Tianyu Yang, Junfeng Fang, Mingyang Song, Mao Zheng, Haiyun Guo, Dan Zhang, Jinqiao Wang, and Tat-Seng Chua. Unifying group-relative and self-distillation policy optimization via sample routing.arXiv preprint arXiv:2604.02288, 2026
-
[22]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
work page 2024
-
[23]
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, and Limin Wang. Videochat-r1: Enhancing spatio-temporal perception via reinforce- ment fine-tuning.arXiv preprint arXiv:2504.06958, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Self-hinting language models enhance reinforcement learning.arXiv preprint arXiv:2602.03143, 2026
Baohao Liao, Hanze Dong, Xinxing Xu, Christof Monz, and Jiang Bian. Self-hinting language models enhance reinforcement learning.arXiv preprint arXiv:2602.03143, 2026
-
[26]
St-llm: Large language models are effective temporal learners
Ruyang Liu, Chen Li, Haoran Tang, Yixiao Ge, Ying Shan, and Ge Li. St-llm: Large language models are effective temporal learners. InEuropean Conference on Computer Vision, pages 1–18. Springer, 2024
work page 2024
-
[27]
Zuyan Liu, Yuhao Dong, Ziwei Liu, Winston Hu, Jiwen Lu, and Yongming Rao. Oryx mllm: On- demand spatial-temporal understanding at arbitrary resolution.arXiv preprint arXiv:2409.12961, 2024
-
[28]
Chiyu Ma, Shuo Yang, Kexin Huang, Jinda Lu, Haoming Meng, Shangshang Wang, Bolin Ding, Soroush V osoughi, Guoyin Wang, and Jingren Zhou. Fipo: Eliciting deep reasoning with future-kl influenced policy optimization.arXiv preprint arXiv:2603.19835, 2026
-
[29]
Video-chatgpt: Towards detailed video understanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12585–12602, 2024. 11
work page 2024
-
[30]
Jiahao Meng, Xiangtai Li, Haochen Wang, Yue Tan, Tao Zhang, Lingdong Kong, Yunhai Tong, Anran Wang, Zhiyang Teng, Yujing Wang, et al. Open-o3 video: Grounded video reasoning with explicit spatio-temporal evidence.arXiv preprint arXiv:2510.20579, 2025
-
[31]
SpaceR: Reinforcing MLLMs in Video Spatial Reasoning
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. Spacer: Reinforcing mllms in video spatial reasoning.arXiv preprint arXiv:2504.01805, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Simko: Simple pass@ k policy optimization.arXiv preprint arXiv:2510.14807, 2025
Ruotian Peng, Yi Ren, Zhouliang Yu, Weiyang Liu, and Yandong Wen. Simko: Simple pass@ k policy optimization.arXiv preprint arXiv:2510.14807, 2025
-
[33]
Andrei A Rusu, Sergio Gomez Colmenarejo, Caglar Gulcehre, Guillaume Desjardins, James Kirkpatrick, Razvan Pascanu, V olodymyr Mnih, Koray Kavukcuoglu, and Raia Hadsell. Policy distillation.arXiv preprint arXiv:1511.06295, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[34]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Video-xl: Extra-long vision language model for hour-scale video understanding
Yan Shu, Zheng Liu, Peitian Zhang, Minghao Qin, Junjie Zhou, Zhengyang Liang, Tiejun Huang, and Bo Zhao. Video-xl: Extra-long vision language model for hour-scale video understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26160–26169, 2025
work page 2025
-
[37]
PPLLaVA: Varied Video Sequence Understanding With Prompt Guidance
Shangkun Sun, Ruyang Liu, Haoran Tang, Yixiao Ge, Haibo Lu, Jiankun Yang, and Chen Li. Ppllava: Varied video sequence understanding with prompt guidance.arXiv preprint arXiv:2411.02327, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Xiaokun Sun, Zezhong Wu, Zewen Ding, and Linli Xu. Mvp: Enhancing video large language models via self-supervised masked video prediction.arXiv preprint arXiv:2601.03781, 2026
-
[39]
Haochen Wang, Xiangtai Li, Zilong Huang, Anran Wang, Jiacong Wang, Tao Zhang, Jiani Zheng, Sule Bai, Zijian Kang, Jiashi Feng, et al. Traceable evidence enhanced visual grounded reasoning: Evaluation and methodology.arXiv preprint arXiv:2507.07999, 2025
-
[40]
Qi Wang, Yanrui Yu, Ye Yuan, Rui Mao, and Tianfei Zhou. Videorft: Incentivizing video reasoning capability in mllms via reinforced fine-tuning.arXiv preprint arXiv:2505.12434, 2025
-
[41]
Time-R1: Post-Training Large Vision Language Model for Temporal Video Grounding
Ye Wang, Ziheng Wang, Boshen Xu, Yang Du, Kejun Lin, Zihan Xiao, Zihao Yue, Jianzhong Ju, Liang Zhang, Dingyi Yang, et al. Time-r1: Post-training large vision language model for temporal video grounding.arXiv preprint arXiv:2503.13377, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Yi Wang, Xinhao Li, Ziang Yan, Yinan He, Jiashuo Yu, Xiangyu Zeng, Chenting Wang, Changlian Ma, Haian Huang, Jianfei Gao, et al. Internvideo2. 5: Empowering video mllms with long and rich context modeling.arXiv preprint arXiv:2501.12386, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Ziyang Wang, Jaehong Yoon, Shoubin Yu, Md Mohaiminul Islam, Gedas Bertasius, and Mohit Bansal. Video-rts: Rethinking reinforcement learning and test-time scaling for efficient and enhanced video reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 28114–28128, 2025
work page 2025
-
[44]
Ziyue Wang, Sheng Jin, Zhongrong Zuo, Jiawei Wu, Han Qiu, Qi She, Hao Zhang, and Xudong Jiang. Video-ktr: Reinforcing video reasoning via key token attribution.arXiv preprint arXiv:2601.19686, 2026
-
[45]
Ziang Yan, Xinhao Li, Yinan He, Zhengrong Yue, Xiangyu Zeng, Yali Wang, Yu Qiao, Limin Wang, and Yi Wang. Videochat-r1. 5: Visual test-time scaling to reinforce multimodal reasoning by iterative perception.arXiv preprint arXiv:2509.21100, 2025. 12
-
[46]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled rlvr.arXiv preprint arXiv:2604.03128, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
LongVT: Incentivizing "Thinking with Long Videos" via Native Tool Calling
Zuhao Yang, Sudong Wang, Kaichen Zhang, Keming Wu, Sicong Leng, Yifan Zhang, Bo Li, Chengwei Qin, Shijian Lu, Xingxuan Li, et al. Longvt: Incentivizing" thinking with long videos" via native tool calling.arXiv preprint arXiv:2511.20785, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Video-o3: Native Interleaved Clue Seeking for Long Video Multi-Hop Reasoning
Xiangyu Zeng, Zhiqiu Zhang, Yuhan Zhu, Xinhao Li, Zikang Wang, Changlian Ma, Qingyu Zhang, Zizheng Huang, Kun Ouyang, Tianxiang Jiang, et al. Video-o3: Native interleaved clue seeking for long video multi-hop reasoning.arXiv preprint arXiv:2601.23224, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Video-llama: An instruction-tuned audio-visual language model for video understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. InProceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations, pages 543–553, 2023
work page 2023
-
[51]
Haoji Zhang, Xin Gu, Jiawen Li, Chixiang Ma, Sule Bai, Chubin Zhang, Bowen Zhang, Zhichao Zhou, Dongliang He, and Yansong Tang. Thinking with videos: Multimodal tool-augmented reinforcement learning for long video reasoning.arXiv preprint arXiv:2508.04416, 2025
-
[52]
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava- video: Video instruction tuning with synthetic data.Transactions on Machine Learning Research, 2025
work page 2025
-
[53]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. 13 Appendix Contents A Extended Related Work 15 B Limitations and Future Works 16 C Implementation and Evaluation Details 16 C.1 Algorithm Details . . . . . . ....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Say whether the student final answer is fully correct, partly correct, or wrong
Answer diagnosis. Say whether the student final answer is fully correct, partly correct, or wrong. Briefly name the problematic part. For natural-language answers, focus on semantic meaning rather than exact wording . For structured answers, say which part is wrong or missing
-
[56]
Judge whether the student’s reasoning broadly supports the final answer
Reasoning-versus-answer consistency. Judge whether the student’s reasoning broadly supports the final answer. If the reasoning points to one event, object, text clue, time range, or spatial reference but the final answer states another, say so. If the reasoning is too weak, too broad, or too incomplete to justify the final answer, say that clearly
-
[57]
High-level error cause. When the response is not fully correct, pick the single most likely high-level cause and mention it briefly. Prefer one of these categories: the reasoning focused on the wrong event, time span, or object; the reasoning was too broad or lacked enough evidence to support such a specific answer; the reasoning was mostly on the right t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.