Aerial Inspection Behaviors via RL-based Quadrotor Control for Under-canopy Forest Environments
Pith reviewed 2026-05-20 06:29 UTC · model grok-4.3
The pith
A reinforcement learning-based quadrotor controller with navigation planners enables aerial inspections in under-canopy forest environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
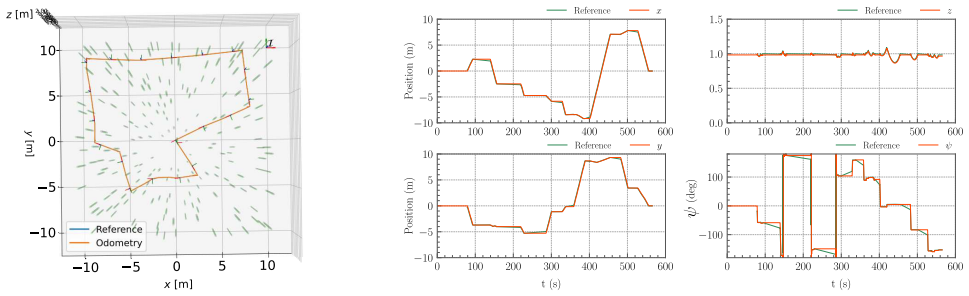
Through five target inspection scenarios, the work shows that an RL-based motor-level stabilizing controller, when supported by a navigation guidance layer with TSP and RRT* planners, can be used effectively as the low-level inspection execution module for under-canopy forest inspection missions.
What carries the argument
The end-to-end RL policy mapping states to RPMs for view-pose tracking, integrated with TSP for visit sequencing and RRT* for generating feasible collision-free paths.
If this is right
- The RL controller achieves reliable simultaneous position and yaw reference tracking for various inspection behaviors.
- Collision-free paths from the RRT* planner can be tracked by the RL policy without violating its limitations in forest environments.
- The TSP planner enables optimal ordering of inspection region visits for efficient long-range missions.
- This architecture supports both point-to-point navigation and target inspections over known forest maps.
Where Pith is reading between the lines
- This method could be adapted for environments with partial map knowledge by incorporating online planning updates.
- Extensions to real hardware would need to validate the sim-to-real transfer of the RL policy under wind and sensor variations.
- Similar layered control might improve drone performance in other cluttered settings like orchards or urban canyons.
- The approach opens possibilities for incorporating additional inspection criteria such as lighting conditions or multi-view requirements.
Load-bearing premise
The RRT* planner generates collision-free paths that the end-to-end RL policy can reliably track given its performance limits.
What would settle it
Observing the quadrotor failing to maintain the required view pose or colliding with trees while following an RRT*-generated path during one of the five inspection scenarios.
Figures







read the original abstract
This paper addresses the problem of using a deep Reinforcement Learning (RL)-based low-level Quadrotor controller within an autonomous Quadrotor navigation stack for aerial inspection missions in under-canopy forest environments. Specifically, the article presents an end-to-end (mapping states to RPMs) Quadrotor control policy that achieves inspection view-pose tracking (simultaneous position and yaw reference tracking), which is crucial for various target inspection behaviors and point-to-point navigation in forests. To ensure safe and reliable deployment of the end-to-end RL controller in long-range missions, this article utilizes a higher navigation guidance layer comprising of a Traveling Salesman Problem planner (TSP) and a Rapidly-exploring Random Tree Star (RRT*) planner. Over a known map of a forest and a set of user-specified inspection regions, the TSP planner finds the optimal visitation sequence. Between two target regions, collision-free paths that respect the tracking limitations of the lower end-to-end RL policy are generated by an RRT* planner. Through five target inspection scenarios, this article demonstrates that an RL-based motor-level stabilizing controller, supported by a navigation guidance layer, can be used effectively as the low-level inspection execution module for under-canopy forest inspection missions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This manuscript presents an end-to-end deep reinforcement learning (RL) policy for quadrotor control that maps states directly to rotor RPMs to achieve simultaneous position and yaw (view-pose) tracking for aerial inspection tasks. The low-level RL controller is embedded in a navigation stack that uses a Traveling Salesman Problem (TSP) planner to determine optimal visitation order over user-specified inspection regions and an RRT* planner to generate collision-free paths between regions; the paths are asserted to respect the RL policy's tracking limitations. Effectiveness is demonstrated empirically across five target inspection scenarios in under-canopy forest environments.
Significance. If the empirical demonstrations hold under rigorous validation, the work would offer a practical architecture for combining learned motor-level stabilization with classical sampling-based planning, potentially improving reliability of autonomous quadrotor inspection in cluttered natural settings where purely geometric planners or purely learned end-to-end policies have historically struggled.
major comments (2)
- [Abstract / Navigation Guidance Layer] Abstract and Navigation Guidance Layer description: The claim that RRT* produces 'collision-free paths that respect the tracking limitations of the lower end-to-end RL policy' is load-bearing for the reliability argument, yet the text provides no mechanism (velocity/acceleration bounds, curvature limits, back-propagation of policy constraints into the planner, or reward shaping) by which this respect is enforced or verified. Without such propagation, success in the five scenarios may be path-dependent rather than architecture-guaranteed.
- [Results / Evaluation] Results / Evaluation section (five scenarios): The central empirical claim rests on demonstration across five inspection scenarios, but the provided text supplies no training procedure, simulation fidelity details, quantitative success metrics, error bars, statistical significance, or real-world transfer results. This absence directly limits verifiable support for the assertion that the RL controller plus guidance layer is 'effective' for under-canopy missions.
minor comments (1)
- [Abstract] The abstract would be strengthened by a single sentence summarizing the key quantitative outcomes (e.g., success rate, tracking error) from the five scenarios.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important areas for improving clarity and rigor, particularly regarding the integration of the RL controller with the planning layer and the strength of the empirical evaluation. We address each major comment point-by-point below, indicating revisions where changes have been made to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Navigation Guidance Layer] Abstract and Navigation Guidance Layer description: The claim that RRT* produces 'collision-free paths that respect the tracking limitations of the lower end-to-end RL policy' is load-bearing for the reliability argument, yet the text provides no mechanism (velocity/acceleration bounds, curvature limits, back-propagation of policy constraints into the planner, or reward shaping) by which this respect is enforced or verified. Without such propagation, success in the five scenarios may be path-dependent rather than architecture-guaranteed.
Authors: We agree that the manuscript would be strengthened by an explicit description of how the RRT* planner respects the RL policy's tracking limitations. The original text assumed this would be inferred from the policy's demonstrated performance, but we acknowledge this was insufficient. In the revised manuscript, we have expanded the Navigation Guidance Layer section to detail the mechanism: velocity and acceleration bounds (along with maximum yaw rate) are extracted from successful RL policy rollouts in simulation and imposed as hard constraints during RRT* sampling and edge validation. This conservative bounding approach ensures generated paths remain within the policy's reliable tracking regime without requiring full constraint back-propagation, which we found computationally prohibitive for real-time replanning. We have also added a short justification for this design choice over reward shaping. revision: yes
-
Referee: [Results / Evaluation] Results / Evaluation section (five scenarios): The central empirical claim rests on demonstration across five inspection scenarios, but the provided text supplies no training procedure, simulation fidelity details, quantitative success metrics, error bars, statistical significance, or real-world transfer results. This absence directly limits verifiable support for the assertion that the RL controller plus guidance layer is 'effective' for under-canopy missions.
Authors: We accept that the initial submission's Results section was under-specified for rigorous verification. The revised manuscript now includes a dedicated subsection on the RL training procedure (network architecture, reward terms for position/yaw tracking and obstacle avoidance, PPO hyperparameters, and curriculum learning schedule), simulation fidelity details (Gazebo-based environment with realistic forest geometry, added Gaussian sensor noise, and variable wind disturbances), and quantitative metrics: success rates, mean position and yaw tracking errors with standard deviations over 50 independent trials per scenario, and error bars on all reported figures. We have also added pairwise statistical comparisons (t-tests) against a baseline geometric controller. Real-world transfer results are not available in this work, as the study is confined to high-fidelity simulation to isolate the controller-planning interaction; we have updated the Discussion to explicitly state this scope limitation and outline planned hardware experiments. revision: partial
- Real-world transfer results, as the current study is limited to simulation-based validation and no hardware experiments were performed.
Circularity Check
No circularity: empirical demonstration of modular RL+planner stack
full rationale
The paper presents an end-to-end RL controller (states to RPMs) and a separate higher-level navigation layer (TSP + RRT*) whose paths are stated to respect the RL policy's tracking limits. The central claim rests on empirical results from five inspection scenarios rather than any derivation, equation, or fitted parameter that reduces to its own inputs by construction. No self-citations, uniqueness theorems, ansatzes, or renamings of known results appear in the provided text to load-bear the architecture. The planner's respect for RL limits is an operating assumption, not a self-definitional loop or statistically forced prediction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
end-to-end (mapping states to RPMs) Quadrotor control policy that achieves inspection view-pose tracking
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RRT* planner generates collision-free paths that respect the tracking limitations of the lower end-to-end RL policy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
G. Nikolakopoulos, S. Mansouri, and C. Kanellakis, Aerial Robotic W orkers. Butterworth-Heinemann, 2023. ISBN: 9780128149096
work page 2023
-
[2]
Autonomous exploration under canop y for forest investigation using lidar and quadrotor,
H. Y ao and X. Liang, “Autonomous exploration under canop y for forest investigation using lidar and quadrotor,” IEEE Transactions on Geoscience and Remote Sensing , vol. 62, pp. 1–19, 2024
work page 2024
-
[3]
A multi-waypoint mot ion planning framework for quadrotor drones in cluttered envir onments,
D. Shi, J. Shen, M. Gao, and X. Y ang, “A multi-waypoint mot ion planning framework for quadrotor drones in cluttered envir onments,” Drones, vol. 8, no. 8, 2024
work page 2024
-
[4]
Pid contro l of quadrotor uavs: A survey,
I. Lopez-Sanchez and J. Moreno-V alenzuela, “Pid contro l of quadrotor uavs: A survey,” Annual Reviews in Control , vol. 56, p. 100900, 2023
work page 2023
-
[5]
K. Gamagedara and T. Lee, “Geometric adaptive controls o f a quadrotor unmanned aerial vehicle with decoupled attitude dynamics,” Journal of Dynamic Systems, Measurement, and Control , vol. 144, p. 031002, 11 2021
work page 2021
-
[6]
H. Gao, X. Hou, J. Xu, and B. Guan, “Quad-rotor unmanned ae rial vehicle path planning based on the target bias extension and dynamic step size rrt* algorithm,” W orld Electric V ehicle Journal, vol. 15, no. 1, 2024
work page 2024
-
[7]
Reaching the limit in autonomous racing: Optimal control v ersus reinforcement learning,
Y . Song, A. Romero, M. M¨ uller, V . Koltun, and D. Scaramuz za, “Reaching the limit in autonomous racing: Optimal control v ersus reinforcement learning,” Science Robotics, vol. 8, no. 82, p. eadg1462, 2023
work page 2023
-
[8]
Control of a Quadrotor with Reinforcement Learning
J. Hwangbo, I. Sa, R. Siegwart, and M. Hutter, “Control of a Quadrotor with Reinforcement Learning,” IEEE Robotics and Automation Letters, vol. 2, pp. 2096–2103, Oct. 2017. arXiv:1707.05110 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2096
-
[9]
J. Eschmann, D. Albani, and G. Loianno, “Learning to fly in seconds,” IEEE Robotics and Automation Letters , vol. 9, no. 7, pp. 6336–6343, 2024
work page 2024
-
[10]
Champion-level drone racing using deep rei nforce- ment learning,
E. Kaufmann, L. Bauersfeld, A. Loquercio, M. M¨ uller, V . Koltun, and D. Scaramuzza, “Champion-level drone racing using deep rei nforce- ment learning,” Nature, vol. 620, pp. 982–987, Aug. 2023
work page 2023
-
[11]
Multi-agent reinforcement learning f or the low- level control of a quadrotor uav,
B. Y u and T. Lee, “Multi-agent reinforcement learning f or the low- level control of a quadrotor uav,” in 2024 American Control Confer- ence (ACC) , pp. 1537–1542, 2024
work page 2024
-
[12]
Multi- task reinforcement learning for quadrotors,
J. Xing, I. Geles, Y . Song, E. Aljalbout, and D. Scaramuz za, “Multi- task reinforcement learning for quadrotors,” IEEE Robotics and Au- tomation Letters , vol. 10, no. 3, pp. 2112–2119, 2025
work page 2025
-
[13]
Learning speed adapt ation for flight in clutter,
G. Zhao, T. Wu, Y . Chen, and F. Gao, “Learning speed adapt ation for flight in clutter,” IEEE Robotics and Automation Letters , vol. 9, no. 8, pp. 7222–7229, 2024
work page 2024
-
[14]
Mavrl: Learn to fly in cluttered environments with varying speed,
H. Y u, C. Wagter, and G. C. H. E. de Croon, “Mavrl: Learn to fly in cluttered environments with varying speed,” IEEE Robotics and Automation Letters, vol. 10, no. 2, pp. 1441–1448, 2025
work page 2025
-
[15]
Semantically- driven deep reinforcement learning for inspection path planning,
G. Malczyk, M. Kulkarni, and K. Alexis, “Semantically- driven deep reinforcement learning for inspection path planning,” IEEE Robotics and Automation Letters , vol. 10, no. 7, pp. 7206–7213, 2025
work page 2025
-
[16]
Learning a single near-hover position controlle r for vastly different quadcopters,
D. Zhang, A. Loquercio, X. Wu, A. Kumar, J. Malik, and M. W . Mueller, “Learning a single near-hover position controlle r for vastly different quadcopters,” in 2023 IEEE International Conference on Robotics and Automation (ICRA) , pp. 1263–1269, 2023
work page 2023
-
[17]
J. Panerati, H. Zheng, S. Zhou, J. Xu, A. Prorok, and A. P . Schoellig, “Learning to fly—a gym environment with pybullet physics for reinforcement learning of multi-agent quadcopter control ,” in 2021 IEEE/RSJ International Conference on Intelligent Robots a nd Systems (IROS), pp. 7512–7519, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.