Structured Labeling Enables Faster Vision-Language Models for End-to-End Autonomous Driving
Pith reviewed 2026-05-22 00:11 UTC · model grok-4.3
The pith
Structured concise labels let a 0.9B VLM match larger models on driving decisions with over 10x speedup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
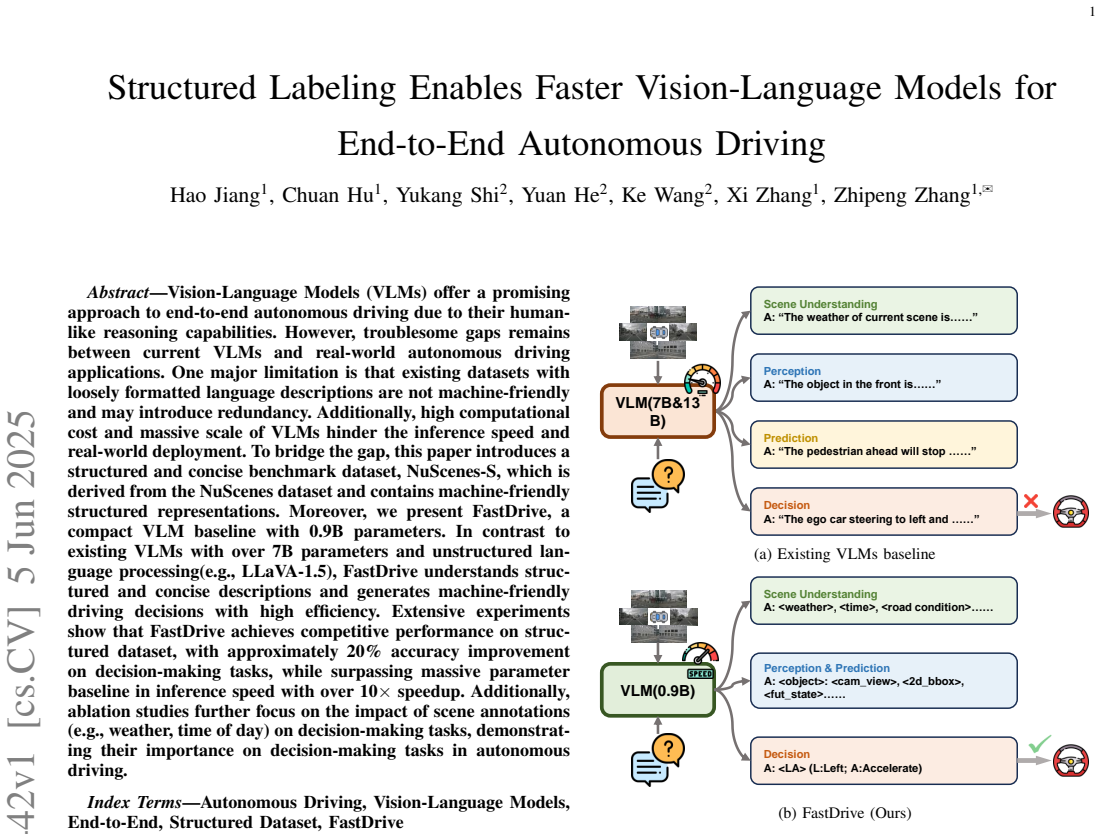
FastDrive, a 0.9B-parameter vision-language model, processes structured concise descriptions from the NuScenes-S dataset to generate machine-friendly driving decisions. It delivers competitive performance with approximately 20% accuracy gains on decision-making tasks and over 10x inference speedup relative to larger VLMs exceeding 7B parameters that handle unstructured language.
What carries the argument
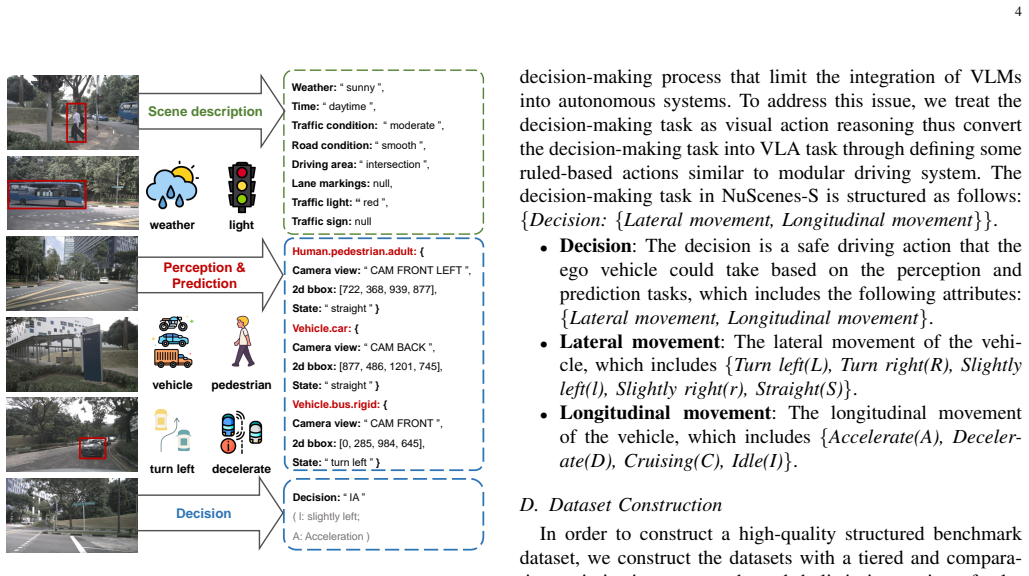
NuScenes-S structured dataset, which converts loose NuScenes descriptions into concise, machine-friendly representations that allow compact VLMs like FastDrive to understand scenes and produce decisions efficiently.
If this is right
- Compact VLMs become practical for real-time end-to-end autonomous driving on edge hardware.
- Including scene annotations such as weather and time of day measurably improves decision accuracy.
- Reducing language redundancy through structured labeling can outweigh gains from simply scaling model size.
- Inference speed improvements of 10x or more make deployment in production vehicles more feasible.
Where Pith is reading between the lines
- The same structured-labeling tactic could accelerate VLMs in other real-time control domains such as robotics or drone navigation.
- Lower parameter counts might reduce training energy and data-center costs for autonomous systems.
- Machine-friendly outputs could simplify integration between perception modules and downstream planners.
Load-bearing premise
Converting original NuScenes language descriptions into structured concise labels preserves every detail required for safe and accurate driving decisions.
What would settle it
Real-vehicle tests in which FastDrive produces more unsafe maneuvers or collisions than a larger unstructured VLM baseline would disprove the performance and safety claims.
Figures



read the original abstract
Vision-Language Models (VLMs) offer a promising approach to end-to-end autonomous driving due to their human-like reasoning capabilities. However, troublesome gaps remains between current VLMs and real-world autonomous driving applications. One major limitation is that existing datasets with loosely formatted language descriptions are not machine-friendly and may introduce redundancy. Additionally, high computational cost and massive scale of VLMs hinder the inference speed and real-world deployment. To bridge the gap, this paper introduces a structured and concise benchmark dataset, NuScenes-S, which is derived from the NuScenes dataset and contains machine-friendly structured representations. Moreover, we present FastDrive, a compact VLM baseline with 0.9B parameters. In contrast to existing VLMs with over 7B parameters and unstructured language processing(e.g., LLaVA-1.5), FastDrive understands structured and concise descriptions and generates machine-friendly driving decisions with high efficiency. Extensive experiments show that FastDrive achieves competitive performance on structured dataset, with approximately 20% accuracy improvement on decision-making tasks, while surpassing massive parameter baseline in inference speed with over 10x speedup. Additionally, ablation studies further focus on the impact of scene annotations (e.g., weather, time of day) on decision-making tasks, demonstrating their importance on decision-making tasks in autonomous driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NuScenes-S, a structured and concise benchmark dataset derived from NuScenes with machine-friendly representations (e.g., weather, time, object lists), and proposes FastDrive, a compact 0.9B-parameter VLM that processes these structured inputs to generate driving decisions. It claims competitive performance with approximately 20% accuracy improvement on decision-making tasks and over 10x inference speedup relative to larger unstructured VLMs such as LLaVA-1.5, supported by ablations on scene annotations.
Significance. If the empirical results hold with proper validation, the work could meaningfully advance practical VLM deployment in autonomous driving by showing that structured labeling enables much smaller and faster models. This addresses key barriers of computational cost and input redundancy, with potential for more efficient end-to-end systems.
major comments (3)
- [Abstract] Abstract: The central claims of ~20% accuracy improvement on decision-making tasks and >10x speedup are presented without any experimental protocol, baseline details, dataset statistics, error bars, or evaluation metrics, preventing verification of the results.
- [§3] Dataset construction: Converting NuScenes free-form descriptions to structured concise labels lacks any quantitative fidelity metric, human validation study, or analysis of retained safety-critical information (e.g., pedestrian intent or multi-agent interactions), so reported gains may partly reflect task simplification.
- [§5] §5 (Experiments): Ablation studies on scene annotations (weather, time of day) are described as demonstrating importance but provide no specific quantitative results, tables, or controls, undermining assessment of their contribution to the decision-making claims.
minor comments (2)
- [Abstract] Abstract: Grammatical issue - 'troublesome gaps remains' should read 'troublesome gaps remain'.
- [Abstract] Abstract: The phrase 'massive parameter baseline' is imprecise; explicitly name the compared models and their parameter counts.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, clarifying existing content where appropriate and outlining specific revisions to improve transparency and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of ~20% accuracy improvement on decision-making tasks and >10x speedup are presented without any experimental protocol, baseline details, dataset statistics, error bars, or evaluation metrics, preventing verification of the results.
Authors: We agree that the abstract should better contextualize the claims for readers. The full experimental protocol, baselines (including LLaVA-1.5), dataset statistics from NuScenes-S, decision accuracy as the primary metric, and results with standard deviations are detailed in Sections 4 and 5. In the revised version we will expand the abstract to briefly note the evaluation metric, key baselines, and that results are averaged over multiple runs, while retaining conciseness. revision: yes
-
Referee: [§3] Dataset construction: Converting NuScenes free-form descriptions to structured concise labels lacks any quantitative fidelity metric, human validation study, or analysis of retained safety-critical information (e.g., pedestrian intent or multi-agent interactions), so reported gains may partly reflect task simplification.
Authors: We acknowledge that the current Section 3 describes the conversion process and provides examples but does not include quantitative fidelity metrics or human validation. We will add an analysis comparing information retention (with emphasis on safety-critical elements such as pedestrian intent and multi-agent interactions) and report results from a small-scale human validation study in the revised manuscript to address potential concerns about task simplification. revision: yes
-
Referee: [§5] §5 (Experiments): Ablation studies on scene annotations (weather, time of day) are described as demonstrating importance but provide no specific quantitative results, tables, or controls, undermining assessment of their contribution to the decision-making claims.
Authors: The ablation results are presented in Section 5 with tables showing accuracy changes when removing individual annotations (weather, time of day) relative to the full structured input. We will revise the text to explicitly reference these quantitative values, clarify the control conditions, and discuss the magnitude of each annotation's contribution to decision accuracy. revision: yes
Circularity Check
No significant circularity; empirical claims rest on new dataset and model evaluations
full rationale
The paper introduces NuScenes-S as a structured reformatting of NuScenes descriptions and presents FastDrive as a compact VLM trained and evaluated on it. No equations, derivations, or first-principles predictions appear in the provided text. Performance claims (accuracy gains, speedups) are presented as direct experimental outcomes against baselines rather than quantities forced by fitting or self-definition. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked to justify core results. The work is self-contained as standard empirical ML research: new data representation plus model training, with results measured on held-out tasks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Structured and concise scene annotations preserve all information needed for accurate driving decisions
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NuScenes-S extract and summarize key elements … into clear and concise phrases, and organize them into structured dictionary format … {Weather, Traffic condition, … Decision: {Lateral movement, Longitudinal movement}}
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FastDrive … 0.9B parameters … over 10× speedup … structured and concise descriptions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scenario understanding of traffic scenes through large visual language models,
R. Esteban, L. Jannik, N. Uhlemann, and M. Lienkamp, “Scenario understanding of traffic scenes through large visual language models,”
-
[2]
Available: https://arxiv.org/abs/2501.17131
[Online]. Available: https://arxiv.org/abs/2501.17131
-
[3]
X. Zhou, M. Liu, E. Yurtsever, B. L. Zagar, W. Zimmer, H. Cao, and A. C. Knoll, “Vision language models in autonomous driving: A survey and outlook,” 2024. [Online]. Available: https://arxiv.org/abs/2310.14414
-
[5]
Drivelm: Driving with graph visual question answering.arXiv preprint arXiv:2312.14150,
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, and H. Li, “Drivelm: Driving with graph visual question answering,” 2025. [Online]. Available: https://arxiv.org/abs/2312.14150
-
[6]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
X. Tian, J. Gu, B. Li, Y . Liu, Y . Wang, Z. Zhao, K. Zhan, P. Jia, X. Lang, and H. Zhao, “Drivevlm: The convergence of autonomous driving and large vision-language models,” 2024. [Online]. Available: https://arxiv.org/abs/2402.12289
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
M. Abdin, J. Aneja, H. Awadalla, and A. Awadallah, “Phi-3 technical report: A highly capable language model locally on your phone,” 2024. [Online]. Available: https://arxiv.org/abs/2404.14219
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, and X. Deng, “Qwen technical report,” 2023. [Online]. Available: https://arxiv.org/abs/2309.16609
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” 2023. [Online]. Available: https://arxiv.org/abs/2304.08485
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Improved Baselines with Visual Instruction Tuning
H. Liu, C. Li, Y . Li, and Y . J. Lee, “Improved baselines with visual instruction tuning,” 2024. [Online]. Available: https: //arxiv.org/abs/2310.03744
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, B. Li, P. Luo, T. Lu, Y . Qiao, and J. Dai, “Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,” 2024. [Online]. Available: https://arxiv.org/abs/2312.14238
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “Minigpt-4: Enhancing vision-language understanding with advanced large language models,” 2023. [Online]. Available: https://arxiv.org/abs/2304.10592
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” 2021. [Online]. Available: https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Holistic autonomous driving understanding by bird’s-eye-view injected multi- modal large models,
X. Ding, J. Han, H. Xu, X. Liang, W. Zhang, and X. Li, “Holistic autonomous driving understanding by bird’s-eye-view injected multi- modal large models,” 2024. [Online]. Available: https://arxiv.org/abs/ 2401.00988
-
[20]
Visual chatgpt: Talking, drawing and editing with visual foundation models,
C. Wu, S. Yin, W. Qi, X. Wang, Z. Tang, and N. Duan, “Visual chatgpt: Talking, drawing and editing with visual foundation models,”
-
[21]
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
[Online]. Available: https://arxiv.org/abs/2303.04671
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
B. Lin, Z. Tang, Y . Ye, J. Huang, J. Zhang, Y . Pang, P. Jin, M. Ning, J. Luo, and L. Yuan, “Moe-llava: Mixture of experts for large vision-language models,” 2024. [Online]. Available: https: //arxiv.org/abs/2401.15947
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Y . Zhang, J. Lu, and N. Jaitly, “The entity-deduction arena: A playground for probing the conversational reasoning and planning capabilities of LLMs,” 2024. [Online]. Available: https://openreview. net/forum?id=PfrpYGKGPL
work page 2024
-
[24]
An in-depth look at gemini’s language abilities,
S. N. Akter, Z. Yu, A. Muhamed, T. Ou, A. B ¨auerle, ´Angel Alexander Cabrera, K. Dholakia, C. Xiong, and G. Neubig, “An in-depth look at gemini’s language abilities,” 2023. [Online]. Available: https://arxiv.org/abs/2312.11444
-
[25]
Llm4drive: A survey of large language models for autonomous driving.ArXiv, abs/2311.01043, 2023
Z. Yang, X. Jia, H. Li, and J. Yan, “Llm4drive: A survey of large language models for autonomous driving,” 2024. [Online]. Available: https://arxiv.org/abs/2311.01043
-
[26]
Dilu: A knowledge-driven approach to au- tonomous driving with large language models
L. Wen, D. Fu, X. Li, X. Cai, T. Ma, P. Cai, M. Dou, B. Shi, L. He, and Y . Qiao, “Dilu: A knowledge-driven approach to autonomous driving with large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2309.16292
-
[27]
Drive like a human: Rethinking autonomous driving with large language models,
D. Fu, X. Li, L. Wen, M. Dou, P. Cai, B. Shi, and Y . Qiao, “Drive like a human: Rethinking autonomous driving with large language models,”
-
[28]
Drive like a human: Rethink- ing autonomous driving with large language models
[Online]. Available: https://arxiv.org/abs/2307.07162
-
[30]
Lmdrive: Closed-loop end-to-end driving with large language models,
H. Shao, Y . Hu, L. Wang, S. L. Waslander, Y . Liu, and H. Li, “Lmdrive: Closed-loop end-to-end driving with large language models,”
-
[31]
Available: https://arxiv.org/abs/2312.07488
[Online]. Available: https://arxiv.org/abs/2312.07488
-
[32]
W. Wang, J. Xie, C. Hu, H. Zou, J. Fan, W. Tong, Y . Wen, S. Wu, H. Deng, Z. Li, H. Tian, L. Lu, X. Zhu, X. Wang, Y . Qiao, and J. Dai, “Drivemlm: Aligning multi-modal large language models with behavioral planning states for autonomous driving,” 2023. [Online]. Available: https://arxiv.org/abs/2312.09245
-
[33]
Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving
B. Jiang, S. Chen, B. Liao, X. Zhang, W. Yin, Q. Zhang, C. Huang, W. Liu, and X. Wang, “Senna: Bridging large vision-language models and end-to-end autonomous driving,” 2024. [Online]. Available: https://arxiv.org/abs/2410.22313
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Continuously learning, adapting, and improving: A dual-process approach to autonomous driving,
J. Mei, Y . Ma, X. Yang, L. Wen, X. Cai, X. Li, D. Fu, B. Zhang, P. Cai, M. Dou, B. Shi, L. He, Y . Liu, and Y . Qiao, “Continuously learning, adapting, and improving: A dual-process approach to autonomous driving,” 2024. [Online]. Available: https://arxiv.org/abs/2405.15324
-
[35]
Vision meets robotics: The KITTI dataset,
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The kitti dataset,” The International Journal of Robotics Research, vol. 32, no. 11, pp. 1231–1237, 2013. [Online]. Available: https://doi.org/10.1177/0278364913491297
-
[36]
Scalability in perception for autonomous driving: Waymo open dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, and V . Patnaik, “Scalability in perception for autonomous driving: Waymo open dataset,” 2020. [Online]. Available: https://arxiv.org/abs/1912.04838
-
[37]
nuScenes: A multimodal dataset for autonomous driving
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” 2020. [Online]. Available: https://arxiv.org/abs/1903.11027
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[38]
Talk2car: Taking control of your self-driving car,
T. Deruyttere, S. Vandenhende, D. Grujicic, L. Van Gool, and M.-F. Moens, “Talk2car: Taking control of your self-driving car,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) . 9 Association for Computational Linguistics, 2019...
-
[39]
Language prompt for autonomous driving,
D. Wu, W. Han, T. Wang, Y . Liu, X. Zhang, and J. Shen, “Language prompt for autonomous driving,” 2023. [Online]. Available: https://arxiv.org/abs/2309.04379
-
[40]
Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario,
T. Qian, J. Chen, L. Zhuo, Y . Jiao, and Y .-G. Jiang, “Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario,” 2024. [Online]. Available: https://arxiv.org/abs/2305. 14836
work page 2024
-
[41]
Textual Explanations for Self-Driving Vehicles
J. Kim, A. Rohrbach, T. Darrell, J. Canny, and Z. Akata, “Textual explanations for self-driving vehicles,” 2018. [Online]. Available: https://arxiv.org/abs/1807.11546
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
Explainable object-induced action decision for autonomous vehicles,
Y . Xu, X. Yang, L. Gong, H.-C. Lin, T.-Y . Wu, Y . Li, and N. Vasconcelos, “Explainable object-induced action decision for autonomous vehicles,” 2020. [Online]. Available: https://arxiv.org/abs/ 2003.09405
-
[43]
Drama: Joint risk localization and captioning in driving,
S. Malla, C. Choi, I. Dwivedi, J. H. Choi, and J. Li, “Drama: Joint risk localization and captioning in driving,” 2022. [Online]. Available: https://arxiv.org/abs/2209.10767
-
[44]
Rank2tell: A multimodal driving dataset for joint importance ranking and reasoning,
E. Sachdeva, N. Agarwal, S. Chundi, S. Roelofs, J. Li, M. Kochenderfer, C. Choi, and B. Dariush, “Rank2tell: A multimodal driving dataset for joint importance ranking and reasoning,” 2023. [Online]. Available: https://arxiv.org/abs/2309.06597
-
[45]
S. Xie, L. Kong, Y . Dong, C. Sima, W. Zhang, Q. A. Chen, Z. Liu, and L. Pan, “Are vlms ready for autonomous driving? an empirical study from the reliability, data, and metric perspectives,” 2025. [Online]. Available: https://arxiv.org/abs/2501.04003
-
[46]
Z. Chen, W. Wang, Y . Cao, Y . Liu, Z. Gao, E. Cui, J. Zhu, S. Ye, H. Tian, Z. Liu, L. Gu, X. Wang, Q. Li, Y . Ren, Z. Chen, J. Luo, J. Wang, T. Jiang, B. Wang, C. He, B. Shi, X. Zhang, H. Lv, Y . Wang, W. Shao, P. Chu, Z. Tu, T. He, Z. Wu, H. Deng, J. Ge, K. Chen, K. Zhang, L. Wang, M. Dou, L. Lu, X. Zhu, T. Lu, D. Lin, Y . Qiao, J. Dai, and W. Wang, “Ex...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, and B. Zheng, “Qwen2.5 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2412. 15115
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.