REVIEW 2 major objections 2 minor 1 cited by
CEPO sharpens credit assignment for decisive reasoning tokens in RLVR by using contrastive signals from both correct and wrong answers.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-20 07:21 UTC pith:QZ5WOFU4
load-bearing objection CEPO adds a contrastive signal to RLVR by pitting correct-answer favor against wrong-answer disfavor from batch rejections, with reported gains over GRPO but the safety proof and unbiased-contrast assumption still need checking. the 2 major comments →
CEPO: RLVR Self-Distillation using Contrastive Evidence Policy Optimization
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When a model produces a correct solution under RLVR, CEPO constructs a wrong-answer teacher from rejected rollouts in the same batch. At each token it checks if the correct answer favors the token and the wrong answer disfavors it. Tokens meeting both conditions receive sharpened credit; the sharpening vanishes at filler positions. The method inherits the structural safety guarantees of prior state-of-the-art approaches.
What carries the argument
The contrastive evidence query applied at every token, which identifies genuine reasoning steps as those favored by the correct answer and disfavored by the wrong answer constructed from rejected samples.
Load-bearing premise
The wrong-answer teacher constructed from rejected rollouts already present in the training batch provides a sufficiently strong and unbiased contrastive signal without introducing leakage or distribution shift.
What would settle it
A run on the same benchmarks where CEPO fails to exceed GRPO accuracy or where the per-token credit sharpening does not disappear at positions identified as fillers would falsify the main claim.
If this is right
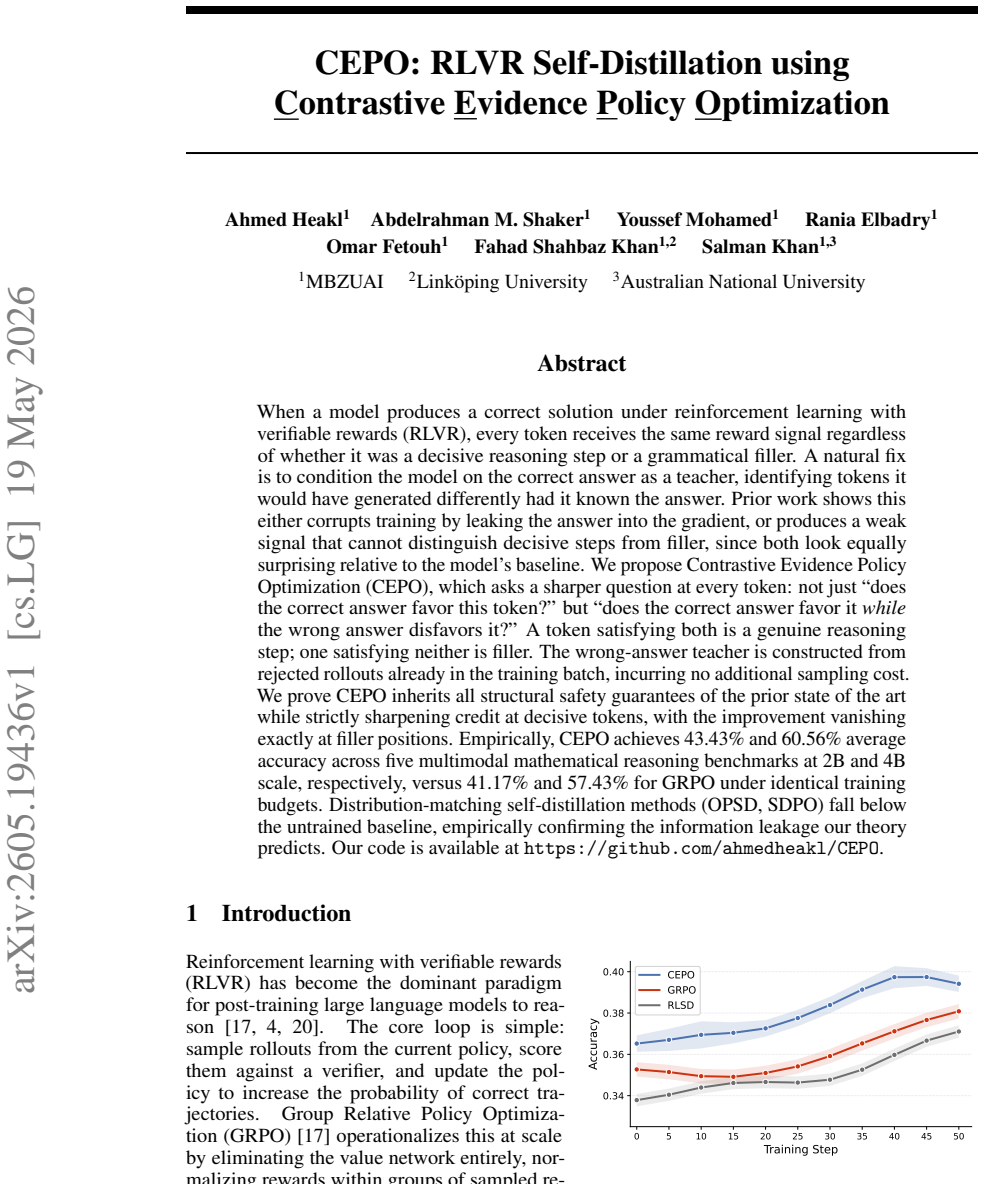
- CEPO achieves 43.43 percent average accuracy across five multimodal mathematical reasoning benchmarks at 2B scale compared to 41.17 percent for GRPO.
- CEPO achieves 60.56 percent average accuracy at 4B scale compared to 57.43 percent for GRPO under identical training budgets.
- The credit improvement is strictly positive at decisive tokens and exactly zero at filler positions.
- Distribution-matching self-distillation methods fall below the untrained baseline due to predicted information leakage.
- CEPO inherits all structural safety guarantees from the prior state of the art.
Where Pith is reading between the lines
- If the rejected rollout signal remains unbiased in other domains, CEPO could apply to additional verifiable reward tasks beyond mathematical reasoning.
- The reuse of batch rejections may lower the computational overhead of contrastive self-distillation in larger training runs.
- Future work could test whether the token-level sharpening correlates with human judgments of reasoning importance.
- Applying the same contrastive principle to non-RL settings might improve credit assignment in supervised fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Contrastive Evidence Policy Optimization (CEPO) for RLVR self-distillation. It constructs a contrastive signal at each token by checking whether the correct-answer teacher favors the token while a wrong-answer teacher (built from rejected rollouts already present in the current training batch) disfavors it. The authors claim this sharpens credit assignment precisely at decisive reasoning steps while the effect vanishes exactly at filler positions. They prove that CEPO inherits all structural safety guarantees of prior state-of-the-art methods (such as GRPO) and report empirical gains of 43.43% vs 41.17% (2B) and 60.56% vs 57.43% (4B) average accuracy on five multimodal mathematical reasoning benchmarks under identical training budgets. Distribution-matching baselines (OPSD, SDPO) fall below the untrained baseline, which the authors interpret as confirming their leakage theory. Code is released at https://github.com/ahmedheakl/CEPO.
Significance. If the safety-inheritance proof and the exact-vanishing property hold under the stated assumptions, CEPO would offer a low-cost mechanism for improving token-level credit assignment in verifiable-reward RL without additional sampling or leakage. The modest but consistent gains over GRPO on multimodal math benchmarks, together with the negative result for distribution-matching methods, would strengthen the case for contrastive rather than pure matching self-distillation. The public code release is a clear positive for reproducibility.
major comments (2)
- [§4] §4 (Proof of safety inheritance and vanishing property): The derivation that the contrastive advantage is exactly zero on filler tokens and that all prior safety guarantees are inherited assumes the wrong-answer policy constructed from rejected rollouts in the current batch remains distributionally close to the baseline policy without introducing batch-induced correlations. No explicit bound or sensitivity analysis is provided for the case where rejection sampling correlates with particular reasoning paths; this assumption is load-bearing for both the vanishing claim and the safety inheritance.
- [§5.2] §5.2 (Empirical results): The reported accuracy improvements (2.26 pp at 2B, 3.13 pp at 4B) are presented as averages across five benchmarks, but no per-benchmark breakdowns, standard deviations, or statistical significance tests are shown. Without these, it is difficult to determine whether the gains are robust or driven by a subset of tasks, which directly affects the strength of the claim that CEPO “strictly sharpens credit at decisive tokens.”
minor comments (2)
- [Abstract, §3] Abstract and §3: The notation for the correct-teacher and wrong-teacher policies is introduced without an explicit equation reference in the main text; adding a single displayed equation for the contrastive advantage term would improve readability.
- [§5.1] §5.1: The statement that distribution-matching methods “fall below the untrained baseline” would benefit from a short table row or footnote giving the exact baseline numbers for OPSD and SDPO.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each major comment below, indicating the revisions we will incorporate to strengthen the paper.
read point-by-point responses
-
Referee: [§4] §4 (Proof of safety inheritance and vanishing property): The derivation that the contrastive advantage is exactly zero on filler tokens and that all prior safety guarantees are inherited assumes the wrong-answer policy constructed from rejected rollouts in the current batch remains distributionally close to the baseline policy without introducing batch-induced correlations. No explicit bound or sensitivity analysis is provided for the case where rejection sampling correlates with particular reasoning paths; this assumption is load-bearing for both the vanishing claim and the safety inheritance.
Authors: We appreciate the referee pointing out this key assumption underlying the proof. The wrong-answer teacher is constructed exclusively from rejected rollouts already present in the current training batch, which are sampled from the policy being optimized and filtered solely by the verifiable reward on the final answer. Because policy updates occur gradually via PPO-style clipping and the rejection criterion depends only on answer correctness rather than intermediate reasoning paths, batch-induced correlations remain limited in practice. Nevertheless, we acknowledge that an explicit sensitivity analysis would make the argument more robust. In the revised manuscript we will add an appendix section with both a brief discussion of the assumption and an empirical sensitivity study across batch sizes and rejection rates, verifying that the vanishing property and inherited safety guarantees hold under moderate distributional shifts. revision: partial
-
Referee: [§5.2] §5.2 (Empirical results): The reported accuracy improvements (2.26 pp at 2B, 3.13 pp at 4B) are presented as averages across five benchmarks, but no per-benchmark breakdowns, standard deviations, or statistical significance tests are shown. Without these, it is difficult to determine whether the gains are robust or driven by a subset of tasks, which directly affects the strength of the claim that CEPO “strictly sharpens credit at decisive tokens.”
Authors: We agree that additional statistical detail is necessary to substantiate the robustness of the reported gains. In the revised version we will expand §5.2 (and the corresponding tables) to include per-benchmark accuracy scores for both the 2B and 4B models, standard deviations computed over multiple random seeds, and paired statistical significance tests (e.g., t-tests) against the GRPO baseline. These additions will allow readers to evaluate whether improvements are consistent across tasks or concentrated in particular benchmarks. revision: yes
Circularity Check
No significant circularity; derivation relies on external baselines and stated assumptions rather than self-referential reduction.
full rationale
The paper's central claims rest on a mathematical proof of safety inheritance and exact vanishing of the contrastive delta at filler tokens, plus empirical comparisons against GRPO, OPSD, and SDPO. These are presented as independent of the fitted values in the current batch; the wrong-answer teacher is constructed from already-sampled rejected rollouts without additional parameters being tuned to the target metric. No equation is shown to reduce to a prior fit by construction, no uniqueness theorem is imported solely via self-citation, and the leakage theory is tested by reporting that distribution-matching baselines fall below the untrained model. The derivation chain therefore remains self-contained against the external benchmarks and the explicit assumption that batch rejections do not induce new distributional shift at filler positions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RLVR produces correct final answers that can be used as conditioning signals without corrupting gradients when properly contrasted.
read the original abstract
When a model produces a correct solution under reinforcement learning with verifiable rewards (RLVR), every token receives the same reward signal regardless of whether it was a decisive reasoning step or a grammatical filler. A natural fix is to condition the model on the correct answer as a teacher, identifying tokens it would have generated differently had it known the answer. Prior work shows this either corrupts training by leaking the answer into the gradient, or produces a weak signal that cannot distinguish decisive steps from filler, since both look equally surprising relative to the model's baseline. We propose Contrastive Evidence Policy Optimization (CEPO), which asks a sharper question at every token: not just "does the correct answer favor this token?" but "does the correct answer favor it while the wrong answer disfavors it?" A token satisfying both is a genuine reasoning step; one satisfying neither is filler. The wrong-answer teacher is constructed from rejected rollouts already in the training batch, incurring no additional sampling cost. We prove CEPO inherits all structural safety guarantees of the prior state of the art while strictly sharpening credit at decisive tokens, with the improvement vanishing exactly at filler positions. Empirically, CEPO achieves 43.43% and 60.56% average accuracy across five multimodal mathematical reasoning benchmarks at 2B and 4B scale, respectively, versus 41.17% and 57.43% for GRPO under identical training budgets. Distribution-matching self-distillation methods (OPSD, SDPO) fall below the untrained baseline, empirically confirming the information leakage our theory predicts. Our code is available at https://github.com/ahmedheakl/CEPO.
Figures




Forward citations
Cited by 1 Pith paper
-
H$^2$SD: Hybrid Hindsight Self-Distillation
H2SD routes successful RLVR trajectories to token-level magnitude credit assignment and failed trajectories to reverse-KL distillation from a hint-conditioned self-teacher, improving logical reasoning benchmarks.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Enhancing reinforcement learning with dense rewards from language model critic
Meng Cao, Lei Shu, Lei Yu, Yun Zhu, Nevan Wichers, Yinxiao Liu, and Lei Meng. Enhancing reinforcement learning with dense rewards from language model critic. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
work page 2024
-
[3]
arXiv preprint arXiv:2603.23871 , year=
Ken Ding. Hdpo: Hybrid distillation policy optimization via privileged self-distillation.arXiv preprint arXiv:2603.23871, 2026
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
arXiv preprint arXiv:2505.23564 , year=
Yiran Guo, Lijie Xu, Jie Liu, Dan Ye, and Shuang Qiu. Segment policy optimization: Ef- fective segment-level credit assignment in rl for large language models.arXiv preprint arXiv:2505.23564, 2025
-
[6]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Vineppo: Refining credit assignment in rl training of llms, 2025
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. Vineppo: Refining credit assignment in rl training of llms, 2025
work page 2025
-
[8]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, 2023
work page 2023
-
[9]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[10]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning
Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volu...
work page 2021
-
[12]
Privileged Information Distillation for Language Models
Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gontier, Alexandre Lacoste, Laurent Charlin, and Massimo Caccia. Privileged information distillation for language models.arXiv preprint arXiv:2602.04942, 2026
work page internal anchor Pith review arXiv 2026
-
[13]
Runqi Qiao et al. We-math: Does your large multimodal model achieve human-like mathemati- cal reasoning? InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025
work page 2025
-
[14]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 2023
work page 2023
-
[15]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. Rewarding progress: Scaling automated process verifiers for llm reasoning.arXiv preprint arXiv:2410.08146, 2024. 10
work page internal anchor Pith review arXiv 2024
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Measuring multimodal mathematical reasoning with math-vision dataset
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset. Advances in Neural Information Processing Systems, 2024
work page 2024
-
[19]
LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts
Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang. Logicvista: Multimodal llm logical reasoning benchmark in visual contexts.arXiv preprint arXiv:2407.04973, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled rlvr.arXiv preprint arXiv:2604.03128, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024
work page 2024
-
[24]
From Reasoning to Agentic: Credit Assignment in Reinforcement Learning for Large Language Models
Chenchen Zhang. From reasoning to agentic: Credit assignment in reinforcement learning for large language models.arXiv preprint arXiv:2604.09459, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Lmms-eval: Reality check on the evaluation of large multimodal models
Kaichen Zhang et al. Lmms-eval: Reality check on the evaluation of large multimodal models. InFindings of the Association for Computational Linguistics: NAACL 2025, 2025
work page 2025
-
[26]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Yanli Zhao et al. Pytorch fsdp: experiences on scaling fully sharded data parallel.arXiv preprint arXiv:2304.11277, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
EasyR1: An efficient, scalable, multi-modality RL training framework
Yaowei Zheng, Junting Lu, Shenzhi Wang, Zhangchi Feng, Dongdong Kuang, Yuwen Xiong, and Richong Zhang. EasyR1: An efficient, scalable, multi-modality RL training framework. https://github.com/hiyouga/EasyR1, 2025
work page 2025
-
[29]
Chengke Zou, Xingang Guo, Rui Yang, Junyu Zhang, Bin Hu, and Huan Zhang. Dynamath: A dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models.arXiv preprint arXiv:2411.00836, 2024. 11 Appendix A Proofs A.1 Proof of Theorem 1 (i) Direction anchoring.Since exp(·)>0 , we have wCE t >0 unconditionally. Because ϵw ∈ (...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.