Ink3D: Sculpting 3D Assets with Extremely Complex Textures via Video Generative Models
Pith reviewed 2026-07-02 13:14 UTC · model grok-4.3
The pith
Ink3D decouples geometry from texture to use video models for complex 3D appearances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
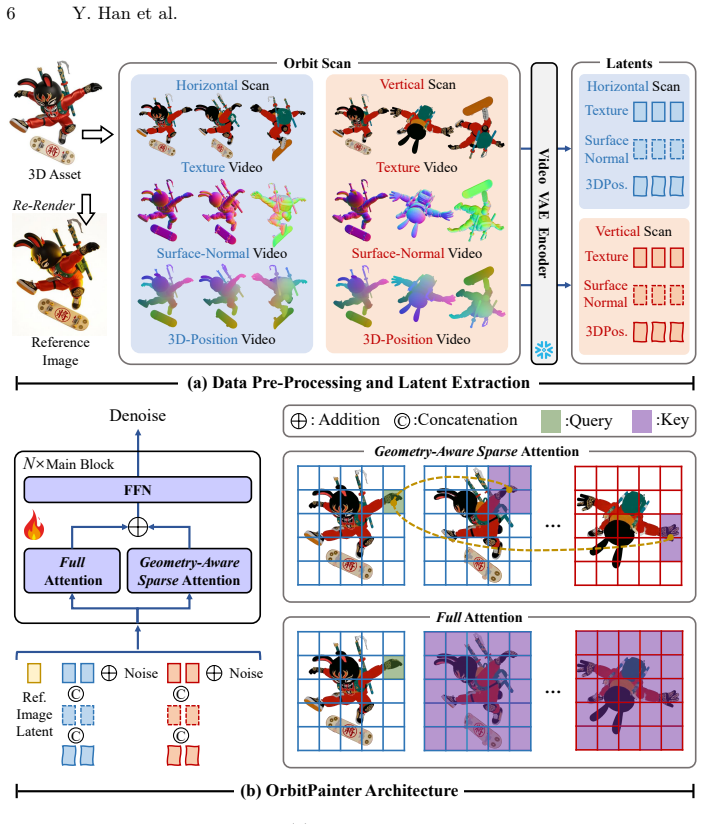
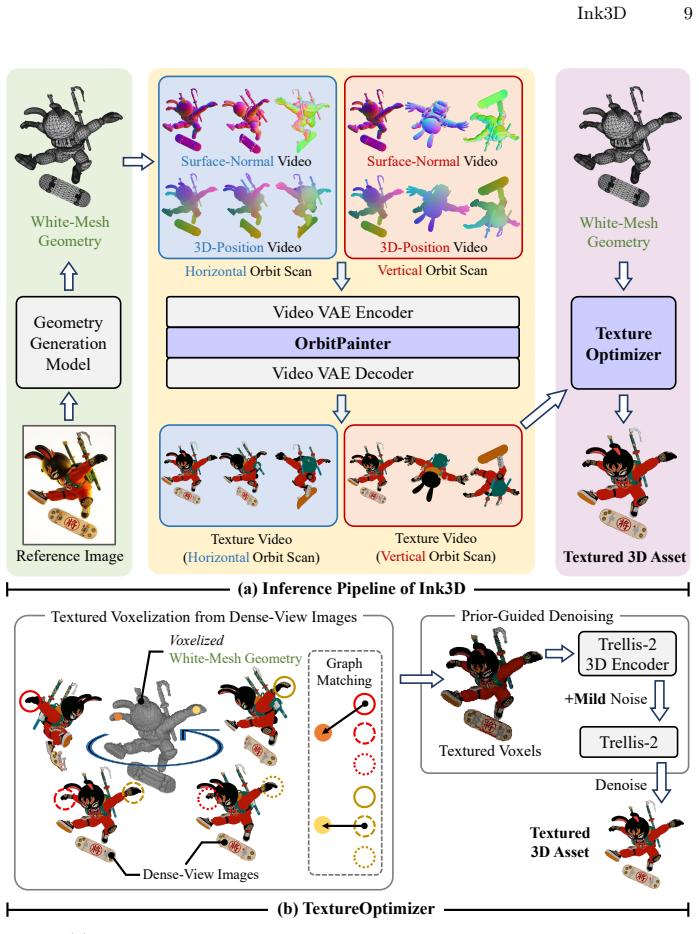
By first reconstructing a white-mesh geometry with an off-the-shelf 3D model, then generating dense orbit-scan videos with OrbitPainter to capture appearance across viewpoints, and integrating them with TextureOptimizer to handle inconsistencies, Ink3D bridges 3D generation with large-scale video priors for complex texture synthesis.
What carries the argument
OrbitPainter for producing multi-view video observations and TextureOptimizer for baking them into coherent textures on a decoupled geometry.
If this is right
- Produces significantly richer textures than prior 3D generative approaches.
- Enables more faithful texture generation from reference images.
- Leverages abundant video training data to overcome scarcity of detailed 3D data.
- Allows high-quality 3D assets with complex surface patterns like fine engravings or fabrics.
Where Pith is reading between the lines
- Future improvements in video models could directly enhance 3D texture quality without changes to the geometry pipeline.
- Similar decoupling might apply to other modalities where one data type is abundant and another is scarce.
- The method could support interactive editing if the video generation allows conditioning on user inputs.
Load-bearing premise
The multi-view videos from the conditional video model are consistent enough to be integrated into a single texture despite geometry inconsistencies introduced by the generation process.
What would settle it
Running the system on reference images with very fine, non-periodic details and checking if the output textures show blurring, seams, or loss of detail compared to the input.
Figures

read the original abstract
Recent 3D generative models can synthesize high-quality geometry but often struggle to reproduce intricate textures from reference images, largely due to the scarcity of large-scale 3D training data with rich surface appearance. In contrast, visual generative models are trained on datasets several orders of magnitude larger and excel at modeling complex visual patterns. Motivated by this gap, we introduce Ink3D, a framework that bridges 3D generation with large-scale video generative models to synthesize extremely complex textures. Ink3D first reconstructs a white-mesh geometry using an off-the-shelf 3D generation model. It then employs OrbitPainter, a conditional video generative model, to produce dense orbit-scan videos capturing object appearance across viewpoints. To convert these views into coherent textures, we introduce TextureOptimizer, a neural baking module that integrates dense multi-view observations while mitigating geometry inconsistencies arising from video generation. By decoupling geometry and texture synthesis and leveraging large-scale pretrained video priors, Ink3D enables significantly richer and more faithful texture generation than prior approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Ink3D, a framework for generating 3D assets with extremely complex textures. It reconstructs a white-mesh geometry using an off-the-shelf 3D model, employs OrbitPainter (a conditional video generative model) to synthesize dense orbit-scan videos capturing appearance across viewpoints, and uses TextureOptimizer (a neural baking module) to integrate the multi-view observations into coherent textures while mitigating geometry inconsistencies from the video generation process. The central claim is that decoupling geometry and texture synthesis and leveraging large-scale pretrained video priors enables significantly richer and more faithful texture generation than prior 3D approaches.
Significance. If the result holds, the work would be significant because it directly addresses the data scarcity issue in 3D texture modeling by transferring priors from much larger video datasets. The decoupling strategy and use of orbit videos represent a practical bridge between modalities, and the approach could enable new applications in asset creation where intricate surface details are required.
major comments (1)
- [§3 (TextureOptimizer)] §3 (TextureOptimizer): The claim that TextureOptimizer 'mitigates geometry inconsistencies arising from video generation' is load-bearing for the central claim of faithful textures, yet the manuscript provides no derivation, objective-function analysis, or bound demonstrating that the neural baking remains well-posed when viewpoint-dependent shape deviations exceed the optimizer's regularization; without this, residual view conflicts could produce seams or blurring rather than faithful appearance.
minor comments (2)
- [Abstract and §3] The abstract and method overview would benefit from a high-level equation or pseudocode sketch of the TextureOptimizer objective to clarify how multi-view fusion is formulated.
- [Experiments] Quantitative metrics (e.g., perceptual texture fidelity scores, user studies) and ablations on geometry-drift magnitude are referenced only at a high level; explicit tables comparing against baselines would strengthen the 'significantly richer' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the role of TextureOptimizer. We respond to the single major comment below.
read point-by-point responses
-
Referee: [§3 (TextureOptimizer)] §3 (TextureOptimizer): The claim that TextureOptimizer 'mitigates geometry inconsistencies arising from video generation' is load-bearing for the central claim of faithful textures, yet the manuscript provides no derivation, objective-function analysis, or bound demonstrating that the neural baking remains well-posed when viewpoint-dependent shape deviations exceed the optimizer's regularization; without this, residual view conflicts could produce seams or blurring rather than faithful appearance.
Authors: We acknowledge that the manuscript does not contain a formal derivation, objective-function analysis, or theoretical bound establishing well-posedness of the neural baking under large viewpoint-dependent geometry deviations. The TextureOptimizer is presented as a practical neural-field optimization that combines dense photometric and perceptual losses with view-consistency regularizers; the design relies on the high density of orbit views to average out inconsistencies rather than on a proven tolerance bound. Because the central claim of faithful texture transfer rests on this mitigation step, the absence of such analysis is a substantive gap. We will add, in the revised manuscript, an explicit statement of the composite objective, a short discussion of its conditioning under geometry perturbations, and supporting ablation results on controlled synthetic deviations. revision: yes
Circularity Check
No circularity: framework relies on external pretrained models without self-referential reductions
full rationale
The provided abstract and description contain no equations, fitted parameters, or derivation steps that reduce claims to inputs by construction. Ink3D is described as using off-the-shelf 3D models and large-scale pretrained video generative models (external to the paper), with TextureOptimizer introduced as a new module to integrate observations. No self-citations, ansatzes smuggled via prior work, or renaming of known results appear in the load-bearing claims. The central premise of decoupling geometry and texture synthesis is presented as building on independent external priors rather than being defined in terms of its own outputs. This is the common case of a self-contained engineering framework without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Agarwal, N., Ali, A., Bala, M., Balaji, Y., Barker, E., Cai, T., Chattopadhyay, P., Chen, Y., Cui, Y., Ding, Y., et al.: Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Advances in Neural Information Processing Systems37, 58757–58791 (2024)
Alonso,E.,Jelley,A.,Micheli,V.,Kanervisto,A.,Storkey,A.J.,Pearce,T.,Fleuret, F.: Diffusion for world modeling: Visual details matter in atari. Advances in Neural Information Processing Systems37, 58757–58791 (2024)
2024
-
[3]
Bai,J., Xia, M., Fu, X.,Wang, X.,Mu, L., Cao, J.,Liu, Z., Hu, H.,Bai, X., Wan, P., et al.: Recammaster: Camera-controlled generative rendering from a single video. arXiv preprint arXiv:2503.11647 (2025)
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023) Ink3D 23
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
IEEE transactions on pattern analysis and machine intelligence23(11), 1222–1239 (2001)
Boykov, Y., Veksler, O., Zabih, R.: Fast approximate energy minimization via graph cuts. IEEE transactions on pattern analysis and machine intelligence23(11), 1222–1239 (2001)
2001
-
[6]
In: Forty-first International Conference on Machine Learning (2024)
Bruce, J., Dennis, M.D., Edwards, A., Parker-Holder, J., Shi, Y., Hughes, E., Lai, M., Mavalankar, A., Steigerwald, R., Apps, C., et al.: Genie: Generative interactive environments. In: Forty-first International Conference on Machine Learning (2024)
2024
-
[7]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Cai, H., Cao, S., Du, R., Gao, P., Hoi, S., Hou, Z., Huang, S., Jiang, D., Jin, X., Li, L., et al.: Z-image: An efficient image generation foundation model with single-stream diffusion transformer. arXiv preprint arXiv:2511.22699 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
In: ICCV (2023)
Chen, D.Z., Siddiqui, Y., Lee, H.Y., Tulyakov, S., Nießner, M.: Text2tex: Text- driven high-quality 3d scene texturing via 2d diffusion. In: ICCV (2023)
2023
-
[9]
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Chen, H., Xia, M., He, Y., Zhang, Y., Cun, X., Yang, S., Xing, J., Liu, Y., Chen, Q., Wang, X., et al.: Videocrafter1: Open diffusion models for high-quality video generation. arXiv preprint arXiv:2310.19512 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, H., Zhang, Y., Cun, X., Xia, M., Wang, X., Weng, C., Shan, Y.: Videocrafter2: Overcoming data limitations for high-quality video diffusion mod- els. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7310–7320 (2024)
2024
-
[11]
arXiv preprint arXiv:2509.17627 (2025)
Chen, J., Li, X., Bai, X., Ma, T., Zhang, P., Chen, Z., Li, G., Liu, L., Zhao, S., Li, B., et al.: Omniinsert: Mask-free video insertion of any reference via diffusion transformer models. arXiv preprint arXiv:2509.17627 (2025)
-
[12]
In: ICCV (2023)
Chen, R., Chen, Y., Jiao, N., Kui, J.: Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: ICCV (2023)
2023
-
[13]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, R., Zhang, J., Liang, Y., Luo, G., Li, W., Liu, J., Li, X., Long, X., Feng, J., Tan, P.: Dora: Sampling and benchmarking for 3d shape variational auto-encoders. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16251–16261 (2025)
2025
-
[14]
arXiv preprint arXiv:2409.12957 (2024)
Chen, Z., Tang, J., Dong, Y., Cao, Z., Hong, F., Lan, Y., Wang, T., Xie, H., Wu, T., Saito, S., et al.: 3dtopia-xl: Scaling high-quality 3d asset generation via primitive diffusion. arXiv preprint arXiv:2409.12957 (2024)
-
[15]
Objaverse-XL: A Universe of 10M+ 3D Objects
Deitke, M., Liu, R., Wallingell, M., Ngo, H., Michel, O., et al.: Objaverse-xl: A universe of 10m+ 3d objects. arXiv preprint arXiv:2307.05663 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
In: CVPR (2023)
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., et al.: Objaverse: A universe of annotated 3d objects. In: CVPR (2023)
2023
-
[17]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[18]
arXiv preprint arXiv:2412.03568 (2024)
Feng, R., Zhang, H., Yang, Z., Xiao, J., Shu, Z., Liu, Z., Zheng, A., Huang, Y., Liu, Y., Zhang, H.: The matrix: Infinite-horizon world generation with real-time moving control. arXiv preprint arXiv:2412.03568 (2024)
-
[19]
arXiv preprint arXiv:2506.18866 (2025)
Gan, Q., Yang, R., Zhu, J., Xue, S., Hoi, S.: Omniavatar: Efficient audio- driven avatar video generation with adaptive body animation. arXiv preprint arXiv:2506.18866 (2025)
-
[20]
arXiv preprint arXiv:2508.18621 (2025)
Gao, X., Hu, L., Hu, S., Huang, M., Ji, C., Meng, D., Qi, J., Qiao, P., Shen, Z., Song, Y., et al.: Wan-s2v: Audio-driven cinematic video generation. arXiv preprint arXiv:2508.18621 (2025)
-
[21]
Google: Veo.https://deepmind.google/models/veo/(2024)
2024
-
[22]
arXiv preprint arXiv:2503.21732 (2025) 24 Y
He, X., Zou, Z.X., Chen, C.H., Guo, Y.C., Liang, D., Yuan, C.Y., Ouyang, W., Cao, Y.P., Li, Y.: Sparseflex: High-resolution and arbitrary-topology 3d shape modeling. arXiv preprint arXiv:2503.21732 (2025) 24 Y. Han et al
-
[23]
arXiv preprint arXiv:2505.04512 (2025)
Hu, T., Yu, Z., Zhou, Z., Liang, S., Zhou, Y., Lin, Q., Lu, Q.: Hunyuancustom: A multimodal-driven architecture for customized video generation. arXiv preprint arXiv:2505.04512 (2025)
-
[24]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Huang, Z., Guo, Y.C., Wang, H., Yi, R., Ma, L., Cao, Y.P., Sheng, L.: Mv- adapter: Multi-view consistent image generation made easy. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 16377–16387 (2025)
2025
-
[25]
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Hunyuan3D, T., Yang, S., Yang, M., Feng, Y., Huang, X., Zhang, S., He, Z., Luo, D., Liu, H., Zhao, Y., et al.: Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material. arXiv preprint arXiv:2506.15442 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Kuaishou: Kling.https://klingai.com(2024)
2024
-
[28]
Li, J., Tang, J., Xu, Z., Wu, L., Zhou, Y., Shao, S., Yu, T., Cao, Z., Lu, Q.: Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition. arXiv preprint arXiv:2506.172012(3), 6 (2025)
-
[29]
arXiv preprint arXiv:2505.07747 (2025) 2, 3, 4, 6, 8, 21, 30
Li, W., Zhang, X., Sun, Z., Qi, D., Li, H., Cheng, W., Cai, W., Wu, S., Liu, J., Wang, Z., et al.: Step1x-3d: Towards high-fidelity and controllable generation of textured 3d assets. arXiv preprint arXiv:2505.07747 (2025)
-
[30]
TripoSG: High-Fidelity 3D Shape Synthesis using Large-Scale Rectified Flow Models
Li, Y., Zou, Z.X., Liu, Z., Wang, D., Liang, Y., Yu, Z., Liu, X., Guo, Y.C., Liang, D., Ouyang, W., et al.: Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models. arXiv preprint arXiv:2502.06608 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
arXiv preprint arXiv:2505.23253 (2025)
Liang, Y., Luo, K., Chen, X., Chen, R., Yan, H., Li, W., Liu, J., Tan, P.: Uni- tex: Universal high fidelity generative texturing for 3d shapes. arXiv preprint arXiv:2505.23253 (2025)
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lin, C.H., Gao, J., Tang, L., Takikawa, T., Zeng, X., Huang, X., Kreis, K., Fidler, S., Liu, M.Y., Lin, T.Y.: Magic3d: High-resolution text-to-3d content creation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 300–309 (2023)
2023
-
[33]
In: The Twelfth International Conference on Learning Representations (2024)
Liu, Y., Lin, C., Zeng, Z., Long, X., Liu, L., Komura, T., Wang, W.: Syncdreamer: Generating multiview-consistent images from a single-view image. In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[34]
In: ICLR (2024)
Liu, Y., et al.: Syncmvd: Generating image-conditioned multiview consistent im- ages. In: ICLR (2024)
2024
-
[35]
In: International Conference on Learning Representations (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2019)
2019
-
[36]
arXiv preprint arXiv:2506.03140 (2025)
Luo, Y., Bai, J., Shi, X., Xia, M., Wang, X., Wan, P., Zhang, D., Gai, K., Xue, T.: Camclonemaster: Enabling reference-based camera control for video generation. arXiv preprint arXiv:2506.03140 (2025)
-
[37]
Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model
Ma, G., Huang, H., Yan, K., Chen, L., Duan, N., Yin, S., Wan, C., Ming, R., Song, X., Chen, X., et al.: Step-video-t2v technical report: The practice, challenges, and future of video foundation model. arXiv preprint arXiv:2502.10248 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
OpenAI: Sora.https://openai.com/sora/(2024)
2024
-
[39]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[40]
In: The Eleventh International Conference on Learning Representations (2023) Ink3D 25
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. In: The Eleventh International Conference on Learning Representations (2023) Ink3D 25
2023
-
[41]
ACM Transactions on Graphics (TOG)42(4), 1–11 (2023)
Richardson, E., Metzer, G., Alaluf, Y., Giryes, R., Cohen-Or, D.: Texture: Text- guided texturing of 3d shapes. ACM Transactions on Graphics (TOG)42(4), 1–11 (2023)
2023
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[43]
arXiv preprint arXiv:2402.10014 (2024)
Shaikh, K., et al.: Paint-it: Text-to-texture synthesis via deep image-space prior. arXiv preprint arXiv:2402.10014 (2024)
- [44]
-
[45]
Sketchfab: Sketchfab - The best 3D viewer on the web.https://sketchfab.com/ (2025)
2025
-
[46]
In: NeurIPS (2023)
Tang, S., Zhang, F., Chen, J., Wang, P., Furukawa, Y.: Mvdiffusion: Enabling holistic multi-view image generation with latent diffusion. In: NeurIPS (2023)
2023
-
[47]
Longcat-video technical report.arXiv preprint arXiv:2510.22200,
Team, M.L., Cai, X., Huang, Q., Kang, Z., Li, H., Liang, S., Ma, L., Ren, S., Wei, X., Xie, R., et al.: Longcat-video technical report. arXiv preprint arXiv:2510.22200 (2025)
-
[48]
arXiv preprint arXiv:2508.08248 (2025)
Tu, S., Pan, Y., Huang, Y., Han, X., Xing, Z., Dai, Q., Luo, C., Wu, Z., Jiang, Y.G.: Stableavatar: Infinite-length audio-driven avatar video generation. arXiv preprint arXiv:2508.08248 (2025)
-
[49]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
CustomX: Unified Character, Action, and Scene Customization in Video World Models
Wang, Y., Wei, F., Zhang, H., Dai, B., Lu, Y.: Animate any character in any world. arXiv preprint arXiv:2512.17796 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
In: NeurIPS (2024)
Wang, Z., Lu, C., Wang, Y., Bao, F., Li, C., Su, H., Zhu, J.: Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. In: NeurIPS (2024)
2024
-
[52]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
arXiv preprint arXiv:2505.17412 (2025)
Wu, S., Lin, Y., Zhang, F., Zeng, Y., Yang, Y., Bao, Y., Qian, J., Zhu, S., Cao, X., Torr, P., et al.: Direct3d-s2: Gigascale 3d generation made easy with spatial sparse attention. arXiv preprint arXiv:2505.17412 (2025)
-
[54]
Native and Compact Structured Latents for 3D Generation
Xiang, J., Chen, X., Xu, S., Wang, R., Lv, Z., Deng, Y., Zhu, H., Dong, Y., Zhao, H., Yuan, N.J., et al.: Native and compact structured latents for 3d generation. arXiv preprint arXiv:2512.14692 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21469–21480 (2025)
2025
-
[56]
arXiv preprint arXiv:2502.14247 (2025) 26 Y
Yang, J., Shang, T., Sun, W., Song, X., Cheng, Z., Wang, S., Chen, S., Liu, W., Li, H., Ji, P.: Pandora3d: A comprehensive framework for high-quality 3d shape and texture generation. arXiv preprint arXiv:2502.14247 (2025) 26 Y. Han et al
-
[57]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Advances in neural information processing systems37, 47455–47487 (2024)
Yin, T., Gharbi, M., Park, T., Zhang, R., Shechtman, E., Durand, F., Freeman, B.: Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems37, 47455–47487 (2024)
2024
-
[59]
ACM Transactions on Graphics (TOG)43(6), 1–14 (2024)
Yu, X., Yuan, Z., Guo, Y.C., Liu, Y.T., Liu, J., Li, Y., Cao, Y.P., Liang, D., Qi, X.: Texgen: a generative diffusion model for mesh textures. ACM Transactions on Graphics (TOG)43(6), 1–14 (2024)
2024
-
[60]
arXiv preprint arXiv:2507.04285 (2025)
Yuan, Z., Yu, X., Sun, Y.T., Guo, Y.C., Cao, Y.P., Liang, D., Qi, X.: Seqtex: Generate mesh textures in video sequence. arXiv preprint arXiv:2507.04285 (2025)
-
[61]
In: CVPR (2024)
Zeng, X., Peng, C., Wang, J., et al.: Paint3d: Paint anything 3d with lighting-less texture diffusion models. In: CVPR (2024)
2024
-
[62]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zeng, Y., Wei, G., Zheng, J., Zou, J., Wei, Y., Zhang, Y., Li, H.: Make pixels dance: High-dynamic video generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8850–8860 (2024)
2024
-
[63]
arXiv preprint arXiv:2502.09268 (2025)
Zhang, H., Ding, P., Lyu, S., Peng, Y., Wang, D.: Gevrm: Goal-expressive video generation model for robust visual manipulation. arXiv preprint arXiv:2502.09268 (2025)
-
[64]
ACM Transactions on Graphics (TOG)43(4), 1–20 (2024)
Zhang, L., Wang, Z., Zhang, Q., Qiu, Q., Pang, A., Jiang, H., Yang, W., Xu, L., Yu, J.: Clay: A controllable large-scale generative model for creating high-quality 3d assets. ACM Transactions on Graphics (TOG)43(4), 1–20 (2024)
2024
-
[65]
arXiv preprint arXiv:2508.10868 (2025)
Zhang, Y., Zhang, L., Ma, R., Cao, N.: Texverse: A universe of 3d objects with high-resolution textures. arXiv preprint arXiv:2508.10868 (2025)
-
[66]
arXiv preprint arXiv:2512.15716 (2025)
Zhao, J., Wei, F., Liu, Z., Zhang, H., Xu, C., Lu, Y.: Spatia: Video generation with updatable spatial memory. arXiv preprint arXiv:2512.15716 (2025)
-
[67]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zhao, Z., Lai, Z., Lin, Q., Zhao, Y., Liu, H., Yang, S., Feng, Y., Yang, M., et al.: Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation. arXiv preprint arXiv:2501.12202 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
RoboDreamer: Learning Compositional World Models for Robot Imagination
Zhou, S., Du, Y., Chen, J., Li, Y., Yeung, D.Y., Gan, C.: Robodreamer: Learning compositional world models for robot imagination. arXiv preprint arXiv:2404.12377 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.