Variance Reduction for Expectations with Diffusion Teachers
Pith reviewed 2026-05-21 04:48 UTC · model grok-4.3
The pith
A hierarchical Monte Carlo estimator amortizes costly upstream work over multiple cheap diffusion noise samples to cut gradient variance in teacher-based pipelines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
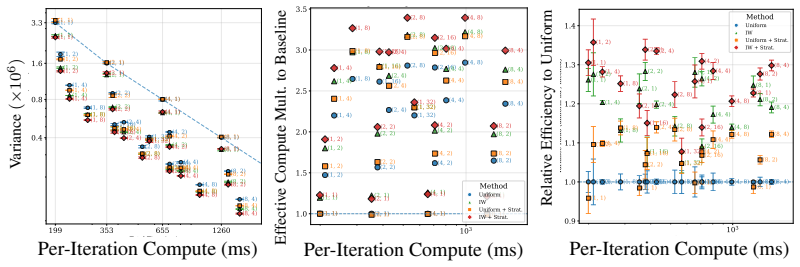
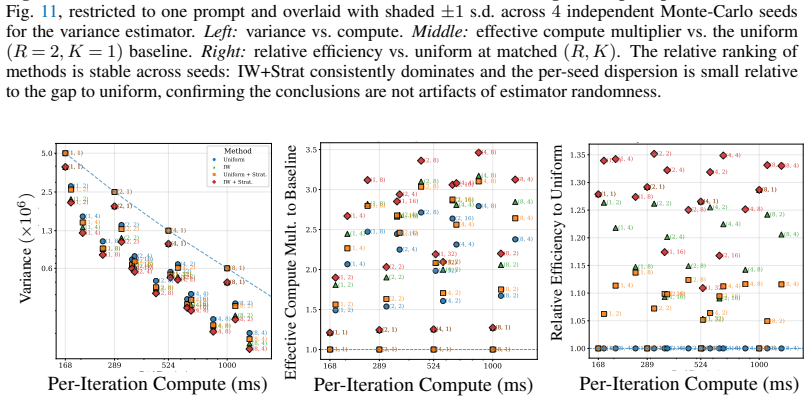
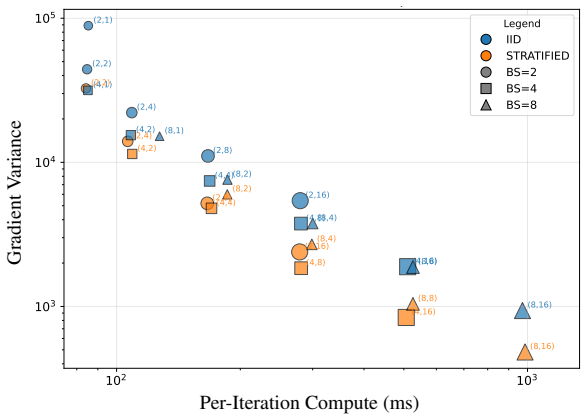
CARV is a compute-aware variance-accounting framework that motivates a hierarchical MC estimator: amortize the expensive upstream computation over cheap diffusion-noise resamples, sharpened by timestep importance sampling and a stratified-inverse-CDF construction. In text-to-3D distillation and attribution experiments this yields 2-3x effective compute multipliers, most of the gain coming from amortized reuse and roughly 25 percent additional gain from the sampling refinements, all without altering the objective.
What carries the argument
CARV hierarchical Monte Carlo estimator that reuses a single expensive upstream computation across multiple cheap diffusion noise resamples, refined by timestep importance sampling and stratified inverse-CDF sampling.
If this is right
- Text-to-3D distillation and attribution pipelines obtain 2-3x effective compute multipliers.
- Single-step distillation sees gradient variance reduced by roughly an order of magnitude.
- The majority of the gain comes from amortizing upstream costs; importance sampling plus stratification supplies an additional 25 percent improvement.
- Downstream FID remains unchanged once variance falls below a certain threshold, showing variance is no longer the limiting factor.
Where Pith is reading between the lines
- The same amortization pattern could be tested in other teacher-student loops that combine diffusion models with expensive forward simulations.
- Adding control variates or learned proposal distributions on top of the existing hierarchy might produce further variance reduction without extra upstream cost.
- When Monte Carlo variance ceases to dominate, optimization effort should shift toward model capacity or training dynamics rather than sampling refinements.
Load-bearing premise
The expensive upstream computation can be performed once and reused across multiple independent diffusion noise samples while preserving unbiasedness of the overall estimator.
What would settle it
A controlled run of the text-to-3D distillation pipeline that measures gradient variance and effective compute multiplier both with and without the stratified-inverse-CDF step, checking whether the reported variance reduction and 2-3x multiplier disappear.
Figures

























read the original abstract
Pretrained diffusion models serve as frozen teachers feeding downstream pipelines such as text-to-3D, single-step distillation, and data attribution. The teacher gradients these pipelines consume are Monte Carlo (MC) expectations over noise levels and Gaussian noise samples; their estimator variance dominates compute cost because each draw requires expensive upstream work (rendering, simulation, encoding). We introduce CARV, a compute-aware variance-accounting framework that motivates a hierarchical MC estimator: amortize the expensive upstream computation over cheap diffusion-noise resamples, sharpened by timestep importance sampling and a stratified-inverse-CDF construction. In our text-to-3D distillation and attribution experiments, CARV delivers 2-3x effective compute multipliers (most from amortized reuse; ~25% additional from IS+stratification) without changing the objective; in single-step distillation, the same techniques cut gradient variance by an order of magnitude but do not improve downstream FID, marking the regime where MC variance is no longer the bottleneck.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CARV, a compute-aware variance-accounting framework for Monte Carlo expectations in downstream tasks that use pretrained diffusion models as frozen teachers. It proposes a hierarchical MC estimator that amortizes expensive upstream computations (rendering, simulation, encoding) over multiple cheap diffusion-noise resamples, sharpened by timestep importance sampling and a stratified inverse-CDF construction. Experiments on text-to-3D distillation and data attribution report 2-3x effective compute multipliers (mostly from amortization, ~25% from IS+stratification) without altering the objective; single-step distillation shows order-of-magnitude variance reduction but no FID improvement.
Significance. If the unbiasedness of the amortized hierarchical estimator holds and the reported speed-ups are reproducible with proper statistical controls, the work addresses a practical bottleneck in diffusion-based pipelines and could yield meaningful efficiency gains. The empirical demonstration of compute multipliers in concrete applications (text-to-3D, attribution) is a positive contribution, though the lack of error bars and baseline details limits immediate impact.
major comments (2)
- [Method (hierarchical MC estimator construction)] The central claim that the hierarchical estimator remains unbiased when amortizing upstream computation over multiple noise resamples requires an explicit derivation. The conditioning, independence assumptions between the expensive upstream function and the diffusion noise, and the precise measure-theoretic construction that guarantees E[CARV estimator] equals the original MC expectation are not sufficiently detailed; without this, the assertion that the objective is unchanged cannot be verified.
- [Experiments section] Table or figure reporting the 2-3x multipliers (and the breakdown into amortized reuse vs. IS+stratification) lacks error bars, description of baseline estimators, and definition of 'effective compute.' These omissions make it impossible to assess whether the claimed gains are statistically reliable or how they were measured.
minor comments (2)
- [Method] Notation for the stratified-inverse-CDF sampling and the importance weights should be introduced with a short equation or pseudocode to improve readability.
- [Abstract and §1] The abstract and introduction could briefly state the key independence assumption that enables amortization while preserving unbiasedness.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestions. We address each of the major comments below and will revise the manuscript to incorporate the requested clarifications and improvements.
read point-by-point responses
-
Referee: [Method (hierarchical MC estimator construction)] The central claim that the hierarchical estimator remains unbiased when amortizing upstream computation over multiple noise resamples requires an explicit derivation. The conditioning, independence assumptions between the expensive upstream function and the diffusion noise, and the precise measure-theoretic construction that guarantees E[CARV estimator] equals the original MC expectation are not sufficiently detailed; without this, the assertion that the objective is unchanged cannot be verified.
Authors: We agree with the referee that a more explicit derivation is needed to rigorously establish the unbiasedness of the hierarchical estimator. In the revised manuscript, we will include a detailed appendix providing the measure-theoretic construction. This will explicitly state the independence assumptions (that the upstream computation is independent of the diffusion noise samples) and the conditioning on the amortized computations, proving that the expectation of the CARV estimator matches the original Monte Carlo expectation. This ensures the objective remains unchanged. revision: yes
-
Referee: [Experiments section] Table or figure reporting the 2-3x multipliers (and the breakdown into amortized reuse vs. IS+stratification) lacks error bars, description of baseline estimators, and definition of 'effective compute.' These omissions make it impossible to assess whether the claimed gains are statistically reliable or how they were measured.
Authors: We acknowledge the importance of statistical controls and clear definitions in the experimental section. In the revision, we will add error bars to the reported multipliers, obtained from multiple independent runs with different random seeds. We will also provide a precise definition of 'effective compute' as the factor by which the compute budget can be reduced while achieving the same variance level as the baseline. Additionally, we will describe the baseline estimators in detail and include the breakdown of gains attributable to amortized reuse versus the contributions from importance sampling and stratification. revision: yes
Circularity Check
No significant circularity; estimator construction is self-contained
full rationale
The paper presents CARV as a hierarchical Monte Carlo estimator that amortizes expensive upstream computations (rendering/encoding) over multiple cheap diffusion noise resamples, augmented by timestep importance sampling and stratified-inverse-CDF sampling. The abstract asserts that this preserves the original objective and yields unbiased estimates, with reported gains (2-3x multipliers) treated as empirical outcomes rather than derived from fitted parameters or self-referential definitions. No equations, self-citations, or ansatzes are visible in the provided text that reduce the central claim to its own inputs by construction. The derivation appears independent and externally falsifiable via the unbiasedness property of the MC construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Monte Carlo estimator remains unbiased when expensive upstream computations are reused across multiple independent noise samples at the same timestep.
- standard math A timestep importance distribution and stratified inverse-CDF sampler can be constructed without introducing bias.
Reference graph
Works this paper leans on
-
[1]
Training data attribution via approximate unrolled differentiation
Juhan Bae, Wu Lin, Jonathan Lorraine, and Roger Grosse. Training data attribution via approximate unrolled differentiation. InAdvances in Neural Information Processing Systems, volume 37, 2024. URLhttps://arxiv.org/abs/2405.12186. 44
-
[2]
Sherwin Bahmani, Ivan Skorokhodov, Victor Rong, Gordon Wetzstein, Leonidas Guibas, Peter Wonka, Sergey Tulyakov, Jeong Joon Park, Andrea Tagliasacchi, and David B. Lindell. 4D-fy: Text-to-4d generation using hybrid score distillation sampling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7996–8006,
-
[3]
Benedikt Bitterli, Chris Wyman, Matt Pharr, Peter Shirley, Aaron Lefohn, and Wojciech Jarosz. Spatiotemporal reservoir resampling for real-time ray tracing with dynamic direct lighting.ACM Transactions on Graphics (Proc. SIGGRAPH), 39(4):148:1–148:16, 2020. doi: 10.1145/3386569.3392481. 46
-
[4]
Montrage: Monitoring training for attribution of generative diffusion models
Jonathan Brokman, Omer Hofman, Roman Vainshtein, Amit Giloni, Toshiya Shimizu, Inder- jeet Singh, Oren Rachmil, Alon Zolfi, Asaf Shabtai, Yuki Unno, et al. Montrage: Monitoring training for attribution of generative diffusion models. InEuropean Conference on Computer Vision, pages 1–17. Springer, 2024. 44
work page 2024
-
[5]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. OpenAI technical report.https://openai. com/research/video-generation-models-as-world-simulators, 2024. 43
work page 2024
-
[6]
Fantasia3D: Disentangling geometry and appearance for high-quality text-to-3d content creation
Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. Fantasia3D: Disentangling geometry and appearance for high-quality text-to-3d content creation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22246–22256, 2023. 43
work page 2023
-
[7]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025. 44
work page 2025
-
[8]
Perception prioritized training of diffusion models
Jooyoung Choi, Jungbeom Lee, Chaehun Shin, Sungwon Kim, Hyunwoo Kim, and Sungroh Yoon. Perception prioritized training of diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022. URLhttps://arxiv.org/ abs/2204.00227. 43
-
[9]
Sinkhorn distances: Lightspeed computation of optimal transport
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. InAdvances in Neural Information Processing Systems, volume 26, pages 2292–2300, 2013. 33
work page 2013
-
[10]
FlashTex: Fast relightable mesh texturing with LightCon- trolNet
Kangle Deng, Timothy Omernick, Alexander Weiss, Deva Ramanan, Jun-Yan Zhu, Tinghui Zhou, and Maneesh Agrawala. FlashTex: Fast relightable mesh texturing with LightCon- trolNet. InEuropean Conference on Computer Vision, pages 90–107. Springer, 2024. 3, 44
work page 2024
-
[11]
Parker, CJ Carr, Zack Zukowski, Josiah Taylor, and Jordi Pons
Zach Evans, Julian D. Parker, CJ Carr, Zack Zukowski, Josiah Taylor, and Jordi Pons. Stable audio open. InICASSP 2025 – 2025 IEEE International Conference on Acoustics, Speech and Signal Processing, pages 1–5. IEEE, 2025. 42
work page 2025
-
[12]
Kristian Georgiev, Joshua Vendrow, Hadi Salman, Sung Min Park, and Aleksander Madry. The journey, not the destination: How data guides diffusion models.arXiv preprint arXiv:2312.06205, 2023. 44
-
[13]
Yuan-Chen Guo, Ying-Tian Liu, Ruizhi Shao, Christian Laforte, Vikram V oleti, Guan Luo, Chia-Hao Chen, Zi-Xin Zou, Chen Wang, Yan-Pei Cao, and Song-Hai Zhang. threestudio: A unified framework for 3D content generation.https://github.com/ threestudio-project/threestudio, 2023. 7, 17, 26, 47 10
work page 2023
-
[14]
Efficient diffusion training via Min-SNR weighting strategy
Tiankai Hang, Shuyang Gu, Chen Li, Jianmin Bao, Dong Chen, Han Hu, Xin Geng, and Baining Guo. Efficient diffusion training via Min-SNR weighting strategy. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7441–7451, 2023. 43, 46
work page 2023
-
[15]
CLIPScore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. CLIPScore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7514–7528, 2021. 7
work page 2021
-
[16]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020. 2, 42, 43
work page 2020
-
[17]
simple diffusion: End-to-end diffu- sion for high resolution images
Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. simple diffusion: End-to-end diffu- sion for high resolution images. InInternational Conference on Machine Learning, volume 202, pages 13213–13232. PMLR, 2023. 43
work page 2023
-
[18]
JacNet: Learning functions with structured jacobian
Safwan Hossain and Jonathan Lorraine. JacNet: Learning functions with structured jacobian. InFirst Workshop on Invertible Neural Nets and Normalizing Flows (INNF), ICML, 2019. 47
work page 2019
-
[19]
Planning with Diffusion for Flexible Behavior Synthesis
Michael Janner, Yilun Du, Joshua B. Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. InInternational Conference on Machine Learning, volume 162, pages 9902–9915. PMLR, 2022. URLhttps://arxiv.org/abs/2205.09991. 44
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Systems, volume 35, pages 26565–26577, 2022. 43
work page 2022
-
[21]
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. URLhttps: //arxiv.org/abs/2312.02696. 43
-
[22]
Denoising diffusion restora- tion models
Bahjat Kawar, Michael Elad, Stefano Ermon, and Jiaming Song. Denoising diffusion restora- tion models. InAdvances in Neural Information Processing Systems, volume 35, pages 23593–23606, 2022. 44
work page 2022
-
[23]
Dongjun Kim, Seungjae Shin, Kyungwoo Song, Wanmo Kang, and Il-Chul Moon. Soft truncation: A universal training technique of score-based diffusion model for high precision score estimation. InInternational Conference on Machine Learning, volume 162, pages 11201–11228. PMLR, 2022. URLhttps://arxiv.org/abs/2106.05527. 43
-
[24]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInter- national Conference on Learning Representations, 2015. 26
work page 2015
-
[25]
Kingma, Tim Salimans, Ben Poole, and Jonathan Ho
Diederik P. Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. Variational diffusion models. InAdvances in Neural Information Processing Systems, volume 34, 2021. URL https://arxiv.org/abs/2107.00630. 2, 3, 19, 43, 46
-
[26]
Understanding black-box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. InInternational conference on machine learning, pages 1885–1894. PMLR, 2017. 4, 22, 44
work page 2017
-
[27]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C.J. Burges, L. Bottou, and K.Q. Weinberger, editors,Advances in Neural Information Processing Systems, volume 25, pages 1097–1105. Curran Associates, Inc., 2012. URLhttps://proceedings.neurips.cc/paper_files/ paper/2012...
work page 2012
-
[28]
DataInf: Efficiently estimating data in- fluence in LoRA-tuned LLMs and diffusion models
Yongchan Kwon, Eric Wu, Kevin Wu, and James Zou. DataInf: Efficiently estimating data in- fluence in LoRA-tuned LLMs and diffusion models. InInternational Conference on Learning Representations, 2024. URLhttps://arxiv.org/abs/2310.00902. 44 11
-
[29]
Magic3D: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3D: High-resolution text-to-3d content creation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 300–309, 2023. 7, 43
work page 2023
-
[30]
Daqi Lin, Markus Kettunen, Benedikt Bitterli, Jacopo Pantaleoni, Cem Yuksel, and Chris Wyman. Generalized resampled importance sampling: Foundations of ReSTIR.ACM Trans- actions on Graphics (Proc. SIGGRAPH), 41(4):75:1–75:23, 2022. doi: 10.1145/3528223. 3530158. 46
-
[31]
Diffusion attribution score: Evalu- ating training data influence in diffusion models
Jinxu Lin, Linwei Tao, Minjing Dong, and Chang Xu. Diffusion attribution score: Evalu- ating training data influence in diffusion models. InInternational Conference on Learning Representations, 2025. URLhttps://arxiv.org/abs/2410.18639. 44
-
[32]
Align your Gaussians: Text-to-4d with dynamic 3D Gaussians and composed diffusion models
Huan Ling, Seung Wook Kim, Antonio Torralba, Sanja Fidler, and Karsten Kreis. Align your Gaussians: Text-to-4d with dynamic 3D Gaussians and composed diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8576–8588, 2024. 44
work page 2024
-
[33]
Fangfu Liu, Hanyang Wang, Shunyu Yao, Shengjun Zhang, Jie Zhou, and Yueqi Duan. Physics3D: Learning physical properties of 3D gaussians via video diffusion.arXiv preprint arXiv:2406.04338, 2024. 3, 44
-
[34]
DARTS: Differentiable architecture search
Hanxiao Liu, Karen Simonyan, and Yiming Yang. DARTS: Differentiable architecture search. InInternational Conference on Learning Representations, 2019. URLhttps: //openreview.net/forum?id=S1eYHoC5FX. 47
work page 2019
-
[35]
PhD thesis, University of Toronto, 2024
Jonathan Lorraine.Scalable Nested Optimization for Deep Learning. PhD thesis, University of Toronto, 2024. 44, 47
work page 2024
-
[36]
Task selection for automl system evaluation.arXiv preprint arXiv:2208.12754,
Jonathan Lorraine, Nihesh Anderson, Chansoo Lee, Quentin De Laroussilhe, and Mehadi Hassen. Task selection for automl system evaluation.arXiv preprint arXiv:2208.12754,
-
[37]
Lyapunov exponents for diversity in differentiable games
Jonathan Lorraine, Paul Vicol, Jack Parker-Holder, Tal Kachman, Luke Metz, and Jakob Fo- erster. Lyapunov exponents for diversity in differentiable games. InInternational Conference on Autonomous Agents and Multiagent Systems, pages 842–852, 2022. 47
work page 2022
-
[38]
ATT3D: Amortized text-to-3d object synthesis
Jonathan Lorraine, Kevin Xie, Xiaohui Zeng, Chen-Hsuan Lin, Towaki Takikawa, Nicholas Sharp, Tsung-Yi Lin, Ming-Yu Liu, Sanja Fidler, and James Lucas. ATT3D: Amortized text-to-3d object synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17946–17956, 2023. 44, 45, 46, 47
work page 2023
-
[39]
Lorraine, David Acuna, Paul Vicol, and David Duvenaud
Jonathan P. Lorraine, David Acuna, Paul Vicol, and David Duvenaud. Complex momentum for optimization in games. InInternational Conference on Artificial Intelligence and Statis- tics, volume 151, pages 7742–7765. PMLR, 2022. 47
work page 2022
-
[40]
RePaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. RePaint: Inpainting using denoising diffusion probabilistic models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11461– 11471, 2022. 44
work page 2022
-
[41]
Artem Lukoianov, Haitz S ´aez de Oc´ariz Borde, Kristjan Greenewald, Vitor Guizilini, Timur Bagautdinov, Vincent Sitzmann, and Justin M. Solomon. Score distillation via reparametrized DDIM. InAdvances in Neural Information Processing Systems, volume 37, pages 26011– 26044, 2024. 43, 45, 46
work page 2024
-
[42]
Diff-Instruct: A universal approach for transferring knowledge from pre-trained diffusion models
Weijian Luo, Tianyang Hu, Shifeng Zhang, Jiacheng Sun, Zhenguo Li, and Zhihua Zhang. Diff-Instruct: A universal approach for transferring knowledge from pre-trained diffusion models. InAdvances in Neural Information Processing Systems, volume 36, 2023. 44
work page 2023
-
[43]
Scale- Dreamer: Scalable text-to-3d synthesis with asynchronous score distillation
Zhiyuan Ma, Yuxiang Wei, Yabin Zhang, Xiangyu Zhu, Zhen Lei, and Lei Zhang. Scale- Dreamer: Scalable text-to-3d synthesis with asynchronous score distillation. InEuropean Conference on Computer Vision, pages 1–19. Springer, 2024. 43 12
work page 2024
-
[44]
Gradient-based hyperparameter op- timization through reversible learning
Dougal Maclaurin, David Duvenaud, and Ryan Adams. Gradient-based hyperparameter op- timization through reversible learning. InInternational Conference on Machine Learning, volume 37, pages 2113–2122. PMLR, 2015. 44, 47
work page 2015
-
[45]
David McAllister, Songwei Ge, Jia-Bin Huang, David W. Jacobs, Alexei A. Efros, Aleksander Holynski, and Angjoo Kanazawa. Rethinking score distillation as a bridge between image distributions. InAdvances in Neural Information Processing Systems, volume 37, 2024. URL https://arxiv.org/abs/2406.09417. 43
-
[46]
Improving hyperparameter optimization with checkpointed model weights
Nikhil Mehta, Jonathan Lorraine, Steve Masson, Ramanathan Arunachalam, Zaid Pervaiz Bhat, James Lucas, and Arun George Zachariah. Improving hyperparameter optimization with checkpointed model weights. InEuropean Conference on Computer Vision Workshop on Efficient Deep Learning for Foundation Models (EFM), pages 75–96, 2024. doi: 10.1007/ 978-3-031-91979-4 8. 47
work page 2024
-
[47]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equations. In International Conference on Learning Representations, 2022. URLhttps://arxiv.org/ abs/2108.01073. 44
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
Influence functions for scalable data attribution in diffu- sion models
Bruno Kacper Mlodozeniec, Runa Eschenhagen, Juhan Bae, Alexander Immer, David Krueger, and Richard E Turner. Influence functions for scalable data attribution in diffu- sion models. InThe Thirteenth International Conference on Learning Representations, 2025. 44
work page 2025
-
[49]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2I-Adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InProceedings of the AAAI Conference on Artificial Intelligence, pages 4296–4304, 2024. 44
work page 2024
-
[50]
Instant neural graphics primitives with a multiresolution hash encoding.ACM Trans
Thomas M ¨uller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graph- ics primitives with a multiresolution hash encoding.ACM Transactions on Graphics (Proc. SIGGRAPH), 41(4):102:1–102:15, 2022. doi: 10.1145/3528223.3530127. 26, 45, 47
-
[51]
SwiftBrush: One-step text-to-image diffusion model with variational score distillation
Thuan Hoang Nguyen and Anh Tran. SwiftBrush: One-step text-to-image diffusion model with variational score distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7807–7816, 2024. 44
work page 2024
-
[52]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. InInternational Conference on Machine Learning, volume 139, pages 8162–8171. PMLR, 2021. 2, 18, 43
work page 2021
-
[53]
NVIDIA FastGen: Fast generation from diffusion models.https://github.com/NVlabs/FastGen, 2026
Weili Nie, Julius Berner, Chao Liu, and Arash Vahdat. NVIDIA FastGen: Fast generation from diffusion models.https://github.com/NVlabs/FastGen, 2026. 8, 17
work page 2026
-
[54]
Art B. Owen. Monte carlo theory, methods and examples.https://artowen.su.domains/ mc/, 2013. 31, 43
work page 2013
-
[55]
Trak: Attributing model behavior at scale
Sung Min Park, Kristian Georgiev, Andrew Ilyas, Guillaume Leclerc, and Aleksander Madry. Trak: Attributing model behavior at scale. InInternational Conference on Machine Learning, pages 27074–27113. PMLR, 2023. 4, 23, 41, 44
work page 2023
-
[56]
Hyperparameter optimization with approximate gradient
Fabian Pedregosa. Hyperparameter optimization with approximate gradient. InInternational Conference on Machine Learning, volume 48, pages 737–746. PMLR, 2016. 44, 47
work page 2016
-
[57]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceed- ings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023. 8, 37, 43, 50
work page 2023
-
[58]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. DreamFusion: Text-to-3d using 2D diffusion. InInternational Conference on Learning Representations, 2023. URL https://arxiv.org/abs/2209.14988. 3, 7, 43 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Estimating training data influence by tracing gradient descent
Garima Pruthi, Frederick Liu, Satyen Kale, and Mukund Sundararajan. Estimating training data influence by tracing gradient descent. InAdvances in Neural Information Processing Systems, volume 33, pages 19920–19930, 2020. 4, 23, 44
work page 2020
-
[60]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInter- national Conference on Machine Learning, pages 8748–8763. PMLR, 2021. 27
work page 2021
-
[61]
Dreamgaussian4d: Genera- tive 4d gaussian splatting.arXiv preprint arXiv:2312.17142,
Jiawei Ren, Liang Pan, Jiaxiang Tang, Chi Zhang, Ang Cao, Gang Zeng, and Ziwei Liu. DreamGaussian4D: Generative 4D gaussian splatting.arXiv preprint arXiv:2312.17142,
-
[62]
Input convex gradient net- works
Jack Richter-Powell, Jonathan Lorraine, and Brandon Amos. Input convex gradient net- works. InAdvances in Neural Information Processing Systems Optimal Transport and Ma- chine Learning Workshop, 2021. 47
work page 2021
-
[63]
Score distillation sampling for audio: Source separation, synthesis, and beyond
Jessie Richter-Powell, Antonio Torralba, and Jonathan Lorraine. Score distillation sampling for audio: Source separation, synthesis, and beyond. arXiv preprint arXiv:2505.04621, 2025. Presented at the ICML 2025 AI Heard That! Workshop on Machine Learning for Audio. 3, 44, 47
-
[64]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Om- mer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695,
-
[65]
Reuven Y . Rubinstein and Dirk P. Kroese.Simulation and the Monte Carlo Method. John Wiley & Sons, 3 edition, 2016. 2, 18, 43
work page 2016
-
[66]
Align your flow: Scaling continuous-time flow map distillation.arXiv preprint arXiv:2506.14603, 2025
Amirmojtaba Sabour, Sanja Fidler, and Karsten Kreis. Align your flow: Scaling continuous- time flow map distillation. InAdvances in Neural Information Processing Systems, 2025. URLhttps://arxiv.org/abs/2506.14603. 44
-
[67]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InInternational Conference on Learning Representations, 2022. URLhttps://arxiv. org/abs/2202.00512. 43
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[68]
Multistep distilla- tion of diffusion models via moment matching
Tim Salimans, Thomas Mensink, Jonathan Heek, and Emiel Hoogeboom. Multistep distilla- tion of diffusion models via moment matching. InAdvances in Neural Information Processing Systems, volume 37, 2024. URLhttps://arxiv.org/abs/2406.04103. 43, 44
-
[69]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InEuropean Conference on Computer Vision. Springer, 2024. URLhttps: //arxiv.org/abs/2311.17042. 44
-
[70]
MVDream: Multi-view Diffusion for 3D Generation
Yichun Shi, Peng Wang, Jianglong Ye, Long Mai, Kejie Li, and Xiao Yang. MVDream: Multi-view diffusion for 3D generation. InInternational Conference on Learning Represen- tations, 2024. URLhttps://arxiv.org/abs/2308.16512. 43, 47
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Deep un- supervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep un- supervised learning using nonequilibrium thermodynamics. InInternational Conference on Machine Learning, volume 37, pages 2256–2265. PMLR, 2015. 42
work page 2015
-
[72]
Improved Techniques for Training Consistency Models
Yang Song and Prafulla Dhariwal. Improved techniques for training consistency models. In International Conference on Learning Representations, 2024. URLhttps://arxiv.org/ abs/2310.14189. 44
work page internal anchor Pith review arXiv 2024
-
[73]
Generative modeling by estimating gradients of the data dis- tribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data dis- tribution. InAdvances in Neural Information Processing Systems, volume 32, pages 11918– 11930, 2019. 42 14
work page 2019
-
[74]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations, 2021. URLhttps://arxiv. org/abs/2011.13456. 42
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[75]
arXiv preprint arXiv:2111.08005 , year=
Yang Song, Liyue Shen, Lei Xing, and Stefano Ermon. Solving inverse problems in med- ical imaging with score-based generative models. InInternational Conference on Learning Representations, 2022. URLhttps://arxiv.org/abs/2111.08005. 44
-
[76]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. In International Conference on Machine Learning, volume 202, pages 32211–32252. PMLR,
-
[77]
URLhttps://arxiv.org/abs/2303.01469. 44
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
Yanke Song, Jonathan Lorraine, Weili Nie, Karsten Kreis, and James Lucas. Multi-student diffusion distillation for better one-step generators.arXiv preprint arXiv:2410.23274, 2024. 44, 46, 47
-
[79]
VidGen-1M: A large-scale dataset for text-to-video generation
Zhiyu Tan, Xiaomeng Yang, Luozheng Qin, and Hao Li. VidGen-1M: A large-scale dataset for text-to-video generation. arXiv preprint arXiv:2408.02629, 2024. 8, 41, 43
-
[80]
Mean-shift distillation for diffusion mode seeking
Vikas Thamizharasan, Nikitas Chatzis, Iliyan Georgiev, Matthew Fisher, Difan Liu, Nanxuan Zhao, Evangelos Kalogerakis, and Michal Luk ´aˇc. Mean-shift distillation for diffusion mode seeking. InInternational Conference on Machine Learning (ICML), 2025. 46
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.