RoboWorld: Fast and Reliable Neural Simulators for Generalist Robot Policy Evaluation
Pith reviewed 2026-07-02 11:19 UTC · model grok-4.3
The pith
RoboWorld pairs a fast autoregressive video world model with Step Forcing and task-progress scoring to evaluate robot policies at 0.989 correlation with real-world results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
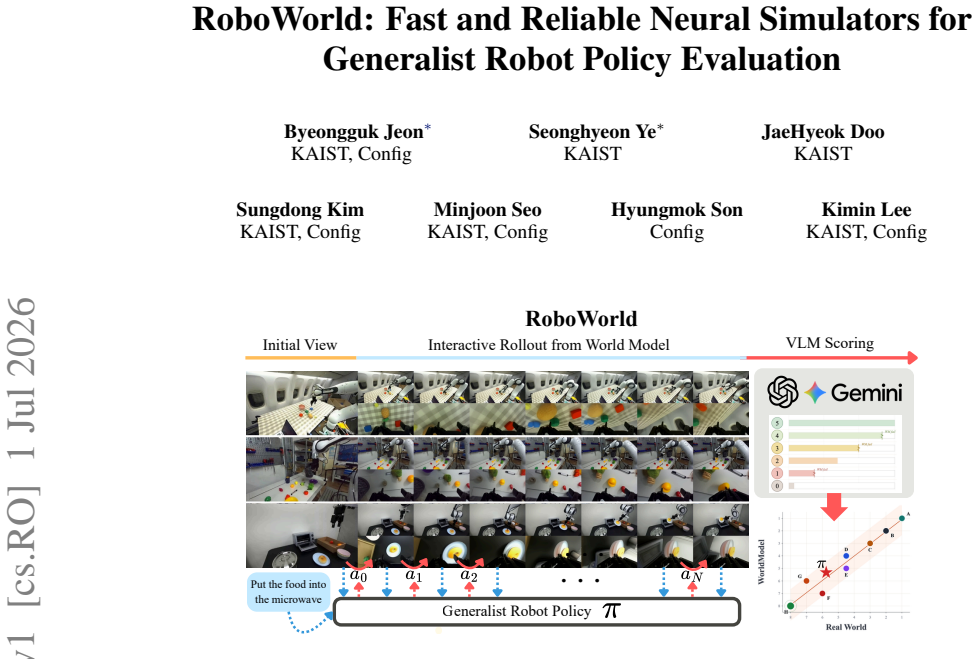
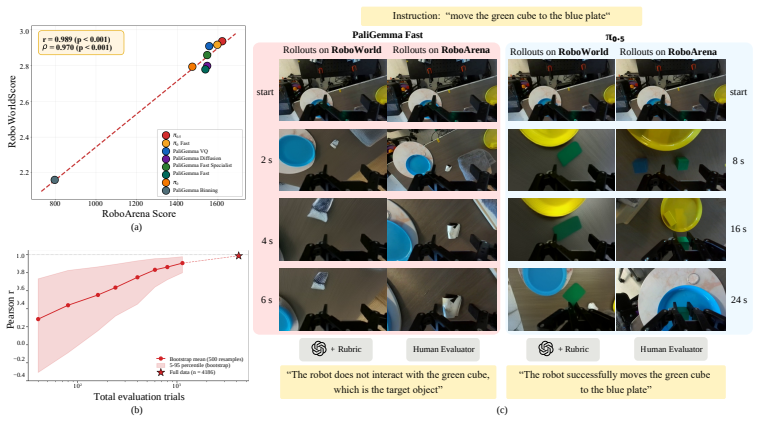
By pairing a fast autoregressive video world model with Step Forcing for reliable rollouts and task-progress-aware vision-language model scoring, RoboWorld achieves strong alignment with real-world robot evaluation, with Pearson's r = 0.989 and Spearman's ρ = 0.970 across tasks and environments.
What carries the argument
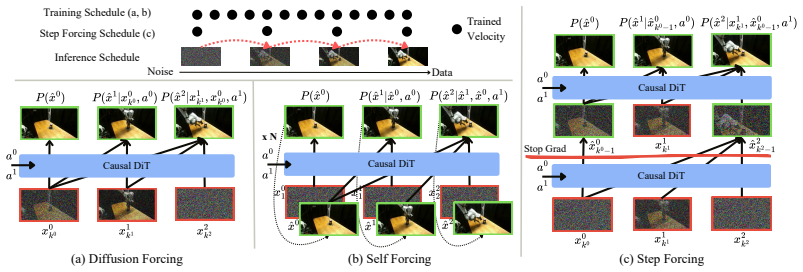
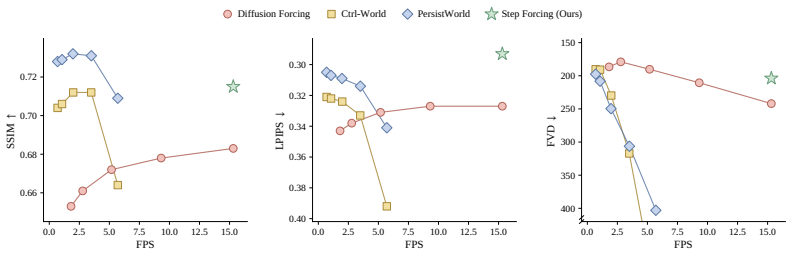
Step Forcing, which combines anchored and one-step self-forwarded contexts to reduce train-test mismatch in autoregressive world-model rollouts while preserving action-observation dynamics.
If this is right
- Robot policies can be evaluated at large scale without physical hardware or deployment constraints.
- Evaluation speed increases because the autoregressive model supports faster inference than real robots.
- The same pipeline supports consistent measurement across diverse tasks and environments.
- High correlation lets the system act as a direct proxy for real-world success rates.
Where Pith is reading between the lines
- The same combination of autoregressive rollout control and progress scoring might transfer to policy evaluation in other embodied domains such as navigation or manipulation in simulation.
- If the scoring component generalizes without per-task tuning, it could reduce reliance on human-defined success criteria in automated testing loops.
- Extending Step Forcing to multi-step or multi-agent rollouts could expose new limits on how far the current mismatch reduction works.
Load-bearing premise
The task-progress-aware vision-language model scoring accurately reflects true task success and does not require task-specific calibration or human oversight.
What would settle it
Running the pipeline on a fresh set of robot tasks and environments outside the original test distribution and finding Pearson correlation below 0.9 would show the alignment does not hold generally.
Figures


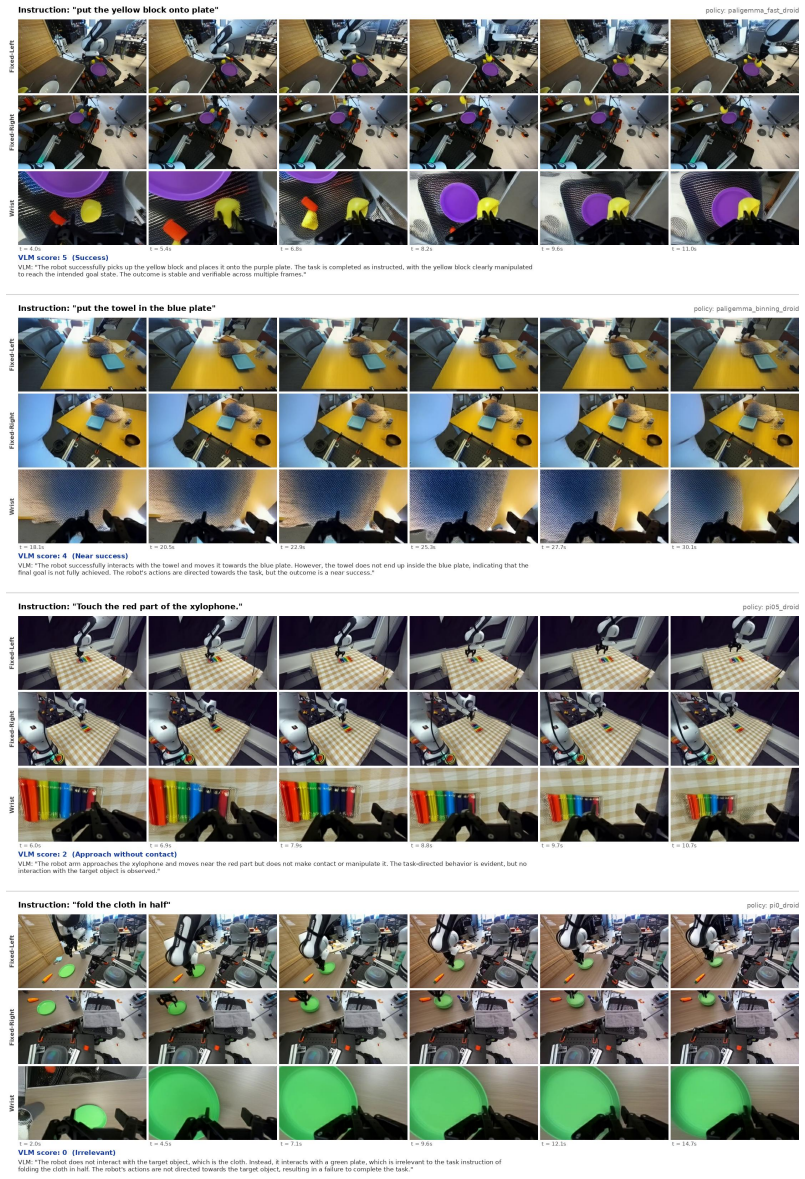
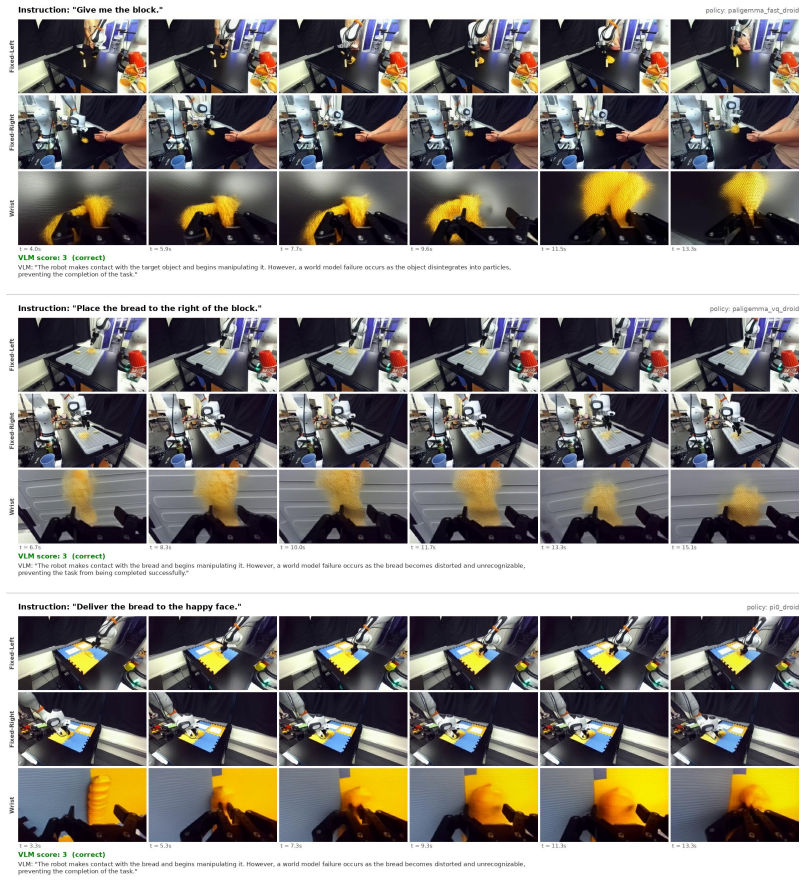

read the original abstract
Video world models are emerging as a scalable alternative for evaluating generalist robot policies, bypassing the physical constraints and engineering burdens of real-world deployment. However, evaluating policies with video world models remains challenging, as world-model errors can make generated rollouts unreliable and slow inference limits large-scale throughput. We introduce RoboWorld, an automated evaluation pipeline that pairs a fast autoregressive video world model with a task-progress-aware vision-language model scoring. To enable reliable long-horizon autoregressive world-model rollouts, we propose Step Forcing, which combines anchored and one-step self-forwarded contexts to reduce train--test mismatch while preserving action--observation dynamics. Together, these components enable RoboWorld to align strongly with real-world robot evaluation across tasks and environments, achieving Pearson's r = 0.989 and Spearman's \r{ho} = 0.970.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RoboWorld, an automated pipeline for evaluating generalist robot policies that pairs a fast autoregressive video world model (with a proposed Step Forcing technique for reliable long-horizon rollouts) and a task-progress-aware vision-language model (VLM) scorer. It claims that these components enable strong alignment with real-world robot evaluations across tasks and environments, with reported Pearson's r = 0.989 and Spearman's ρ = 0.970.
Significance. If the central alignment claim holds under proper validation, the work would provide a scalable, hardware-free method for policy evaluation that could substantially reduce the cost and engineering overhead of testing generalist robot policies in simulation.
major comments (1)
- [Abstract] Abstract: The headline correlations (Pearson's r = 0.989, Spearman's ρ = 0.970) are computed between RoboWorld outputs and real-world rollouts, but these outputs depend on the task-progress-aware VLM scorer. No quantitative validation of the VLM (e.g., inter-rater agreement with human ground truth, calibration curves, cross-task generalization, or error analysis on failure modes) is supplied, which is load-bearing for the claim that RoboWorld 'aligns strongly' at scale without per-task calibration or oversight.
Simulated Author's Rebuttal
We thank the referee for their detailed review and for highlighting this important aspect of our evaluation pipeline. We address the concern regarding validation of the task-progress-aware VLM scorer below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline correlations (Pearson's r = 0.989, Spearman's ρ = 0.970) are computed between RoboWorld outputs and real-world rollouts, but these outputs depend on the task-progress-aware VLM scorer. No quantitative validation of the VLM (e.g., inter-rater agreement with human ground truth, calibration curves, cross-task generalization, or error analysis on failure modes) is supplied, which is load-bearing for the claim that RoboWorld 'aligns strongly' at scale without per-task calibration or oversight.
Authors: We agree that the VLM scorer is a critical component and that the manuscript would benefit from explicit quantitative validation of its alignment with human judgments, separate from the end-to-end pipeline correlations. The reported Pearson's r and Spearman's ρ validate the full RoboWorld system (world model + VLM), but do not isolate VLM performance. In the revised version we will add an appendix containing: (1) inter-rater agreement (Cohen's κ and percentage agreement) between the VLM and multiple human raters on a held-out set of 200 rollouts across tasks; (2) calibration curves showing VLM score vs. human-assigned progress; (3) cross-task generalization results; and (4) error analysis on failure modes where the VLM diverges from humans. These additions will be supported by the existing human-labeled data collected during real-world experiments. revision: yes
Circularity Check
No circularity: correlations are direct empirical measurements against held-out real-world rollouts
full rationale
The paper's central claim is an empirical correlation (Pearson's r = 0.989, Spearman's ρ = 0.970) between RoboWorld-generated scores and independent real-world policy evaluations. The abstract and provided text give no equations, fitted parameters, or self-citations that define the reported alignment by construction. Step Forcing is presented as a training technique to reduce mismatch, not as a redefinition of the evaluation metric. The VLM scoring component is described as an automated proxy, but its outputs are compared externally rather than being tautological with the real-world ground truth. No load-bearing step reduces to a self-citation chain or renames a fitted input as a prediction. This is the common case of a self-contained empirical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick. Microsoft coco: Common objects in context. InEuropean Conference on Computer Vision, 2014
2014
-
[2]
Russakovsky, J
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge.Interna- tional journal of computer vision, 115(3):211–252, 2015
2015
-
[3]
Measuring Massive Multitask Language Understanding
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[4]
Chiang, L
W.-L. Chiang, L. Zheng, Y . Sheng, A. N. Angelopoulos, T. Li, D. Li, B. Zhu, H. Zhang, M. Jordan, J. E. Gonzalez, et al. Chatbot arena: An open platform for evaluating llms by human preference. InInternational Conference on Machine Learning, 2024
2024
-
[5]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, 2023
2023
-
[7]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x mod- els: Open x-embodiment collaboration 0. InIEEE International Conference on Robotics and Automation, 2024
2024
-
[8]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on Robot Learning, 2020
2020
-
[14]
James, Z
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
2020
-
[15]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523, 2024. 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Y . R. Wang, C. Ung, C. Tan, G. Tannert, J. Duan, J. Li, A. Le, R. Oswal, M. Grotz, W. Pumacay, et al. Roboeval: Where robotic manipulation meets structured and scalable evaluation.arXiv preprint arXiv:2507.00435, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Zhang, Z
S. Zhang, Z. Xu, P. Liu, X. Yu, Y . Li, Q. Gao, Z. Fei, Z. Yin, Z. Wu, Y .-G. Jiang, et al. Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks. InIEEE/CVF International Conference on Computer Vision, 2025
2025
- [18]
-
[19]
W. Zhao, J. P. Queralta, and T. Westerlund. Sim-to-real transfer in deep reinforcement learning for robotics: a survey. InIEEE symposium series on computational intelligence (SSCI), 2020
2020
-
[20]
Blanco-Mulero, O
D. Blanco-Mulero, O. Barbany, G. Alcan, A. Colom ´e, C. Torras, and V . Kyrki. Benchmarking the sim-to-real gap in cloth manipulation.IEEE Robotics and Automation Letters, 9(3):2981– 2988, 2024
2024
- [21]
- [22]
- [23]
-
[24]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y . Levi, Z. En- glish, V . V oleti, A. Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Brooks, B
T. Brooks, B. Peebles, C. Holmes, W. DePue, Y . Guo, L. Jing, D. Schnurr, J. Taylor, T. Luhman, E. Luhman, C. Ng, R. Wang, and A. Ramesh. Video generation models as world simulators. 2024
2024
-
[26]
W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, J. Xiong, X. Li, B. Wu, J. Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
H. Chen, Y . Zhang, X. Cun, M. Xia, X. Wang, C. Weng, and Y . Shan. Videocrafter2: Over- coming data limitations for high-quality video diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[28]
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y . Yang, W. Hong, X. Zhang, G. Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
A. Ali, J. Bai, M. Bala, Y . Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y .-W. Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Cosmos World Foundation Model Platform for Physical AI
N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y . Chen, Y . Cui, Y . Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Y . Guo, L. X. Shi, J. Chen, and C. Finn. Ctrl-world: A controllable generative world model for robot manipulation.arXiv preprint arXiv:2510.10125, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [33]
-
[34]
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y . Dong, K. Mo, C.-H. Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
X. W. M. Team. 1x world model: Evaluating bits, not atoms. Technical report, 1X Technolo- gies, 2025. Accessed: 2026-02-23
2025
- [36]
-
[37]
J. Yang, K. Lin, J. Li, W. Zhang, T. Lin, L. Wu, Z. Su, H. Zhao, Y .-Q. Zhang, L. Chen, et al. Rise: Self-improving robot policy with compositional world model.arXiv preprint arXiv:2602.11075, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [38]
-
[39]
J. Quevedo, A. K. Sharma, Y . Sun, V . Suryavanshi, P. Liang, and S. Yang. Worldgym: World model as an environment for policy evaluation.arXiv preprint arXiv:2506.00613, 2025
- [40]
-
[41]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [42]
-
[43]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, et al. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Tobin, R
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. InIEEE/RSJ International Conference on Intelligent Robots and Systems, 2017
2017
- [45]
-
[46]
J. Abou-Chakra, L. Sun, K. Rana, B. May, K. Schmeckpeper, N. Suenderhauf, M. V . Minniti, and L. Herlant. Real-is-sim: Bridging the sim-to-real gap with a dynamic digital twin.arXiv preprint arXiv:2504.03597, 2025. 11
-
[47]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, et al. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models. arXiv preprint arXiv:2505.12705, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Y . Liao, P. Zhou, S. Huang, D. Yang, S. Chen, Y . Jiang, Y . Hu, J. Cai, S. Liu, J. Luo, et al. Genie envisioner: A unified world foundation platform for robotic manipulation.arXiv preprint arXiv:2508.05635, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
S. Yang, Y . Du, K. Ghasemipour, J. Tompson, L. Kaelbling, D. Schuurmans, and P. Abbeel. Learning interactive real-world simulators.arXiv preprint arXiv:2310.06114, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
J. Wu, S. Yin, N. Feng, X. He, D. Li, J. Hao, and M. Long. ivideogpt: Interactive videogpts are scalable world models.Advances in Neural Information Processing Systems, 37:68082–68119, 2024
2024
- [54]
- [55]
- [56]
- [57]
-
[58]
Ebert, C
F. Ebert, C. Finn, A. X. Lee, and S. Levine. Self-supervised visual planning with temporal skip connections.CoRL, 12(16):23, 2017
2017
-
[59]
Bruce, M
J. Bruce, M. D. Dennis, A. Edwards, J. Parker-Holder, Y . Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Apps, et al. Genie: Generative interactive environments. In International Conference on Machine Learning, 2024
2024
- [60]
-
[61]
Matrix-game: Interactive world founda- tion model.arXiv preprint arXiv:2506.18701, 2025
Y . Zhang, C. Peng, B. Wang, P. Wang, Q. Zhu, F. Kang, B. Jiang, Z. Gao, E. Li, Y . Liu, et al. Matrix-game: Interactive world foundation model.arXiv preprint arXiv:2506.18701, 2025
-
[62]
X. He, C. Peng, Z. Liu, B. Wang, Y . Zhang, Q. Cui, F. Kang, B. Jiang, M. An, Y . Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Diffusion Models Are Real-Time Game Engines
D. Valevski, Y . Leviathan, M. Arar, and S. Fruchter. Diffusion models are real-time game engines.arXiv preprint arXiv:2408.14837, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
T. Yin, Q. Zhang, R. Zhang, W. T. Freeman, F. Durand, E. Shechtman, and X. Huang. From slow bidirectional to fast autoregressive video diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 12
2025
-
[65]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
X. Huang, Z. Li, G. He, M. Zhou, and E. Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Y . Guo, C. Yang, H. He, Y . Zhao, M. Wei, Z. Yang, W. Huang, and D. Lin. End-to-end training for autoregressive video diffusion via self-resampling.arXiv preprint arXiv:2512.15702, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[68]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[69]
B. Chen, D. Mart ´ı Mons´o, Y . Du, M. Simchowitz, R. Tedrake, and V . Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
2024
-
[70]
D. Zhou, Q. Sun, Y . Peng, K. Yan, R. Dong, D. Wang, Z. Ge, N. Duan, and X. Zhang. Taming teacher forcing for masked autoregressive video generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[71]
Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
2004
-
[72]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018
2018
- [73]
-
[74]
J. Cui, J. Wu, M. Li, T. Yang, X. Li, R. Wang, A. Bai, Y . Ban, and C.-J. Hsieh. Self-forcing++: Towards minute-scale high-quality video generation.arXiv preprint arXiv:2510.02283, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
S. Huang, J. Wu, Q. Zhou, S. Miao, and M. Long. Vid2world: Crafting video diffusion models to interactive world models.arXiv preprint arXiv:2505.14357, 2025
-
[76]
J. Bardhan, P. Drozdik, J. Sivic, and V . Petrik. Persistent robot world models: Stabilizing multi-step rollouts via reinforcement learning.arXiv preprint arXiv:2603.25685, 2026
-
[77]
Towards Accurate Generative Models of Video: A New Metric & Challenges
T. Unterthiner, S. Van Steenkiste, K. Kurach, R. Marinier, M. Michalski, and S. Gelly. To- wards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[78]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[79]
Fwd/step
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, page 127063, 2024. 13 Appendix A Implementation Details: Action-conditioned BAIR Dataset.We use the BAIR Robot Pushing dataset [58]:43,264training clips and256test clips of30frames each,64×64RGB pixels in[−1,1], accompanied by...
2024
-
[80]
Determine whether the robot interacts with the target object based on the fixed views
Use the fixed views (the two upper views) as the primary reference. Determine whether the robot interacts with the target object based on the fixed views
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.