VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
Pith reviewed 2026-05-19 12:49 UTC · model grok-4.3
The pith
VLM-3R lets vision-language models reason in 3D from monocular video using implicit tokens
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
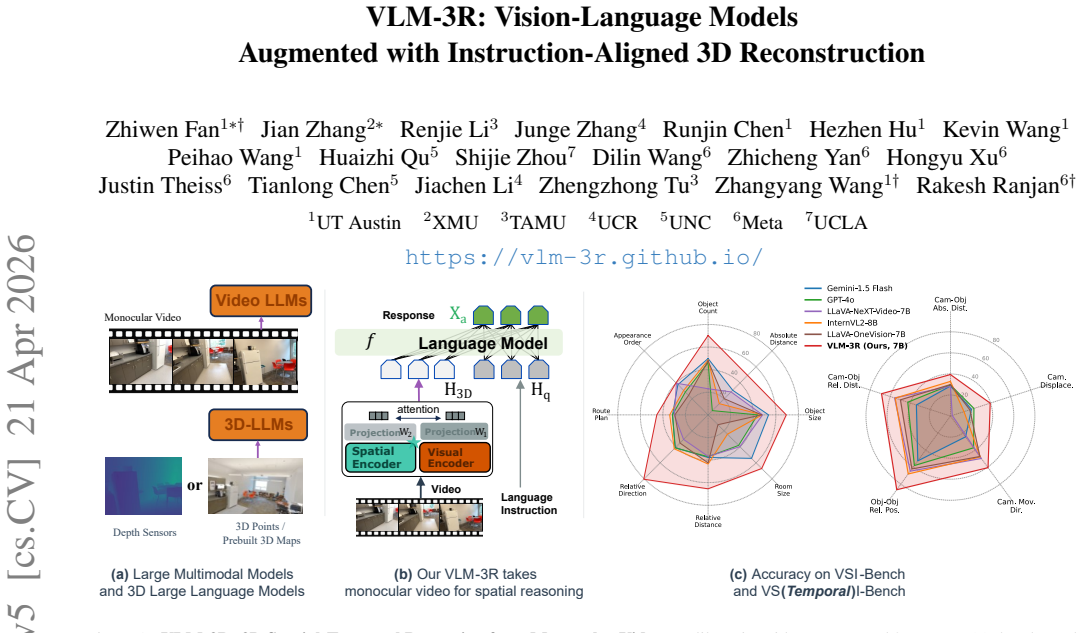
The central discovery is a framework called VLM-3R that augments vision-language models with 3D reconstructive instruction tuning. Monocular video frames are processed by a geometry encoder to produce implicit 3D tokens. Spatial-Visual-View Fusion combines these with visual and view data, and training on a large set of 3D reconstructive QA pairs aligns the spatial context to instructions. This setup supports monocular 3D spatial assistance and embodied reasoning while also handling evolving spatial relationships over time.
What carries the argument
geometry encoder deriving implicit 3D tokens that represent spatial understanding from monocular video frames
Load-bearing premise
The geometry encoder produces implicit 3D tokens whose spatial content is sufficiently accurate and complete for downstream language reasoning without any external depth sensor or pre-built 3D map.
What would settle it
Running the model on monocular video test cases requiring precise 3D spatial predictions and checking if accuracy drops significantly compared to systems using depth sensors would falsify the sufficiency of the implicit tokens.
Figures


read the original abstract
The rapid advancement of Large Multimodal Models (LMMs) for 2D images and videos has motivated extending these models to understand 3D scenes, aiming for human-like visual-spatial intelligence. Nevertheless, achieving deep spatial understanding comparable to human capabilities poses significant challenges in model encoding and data acquisition. Existing methods frequently depend on external depth sensors for geometry capture or utilize off-the-shelf algorithms for pre-constructing 3D maps, thereby limiting their scalability, especially with prevalent monocular video inputs and for time-sensitive applications. In this work, we introduce VLM-3R, a unified framework for Vision-Language Models (VLMs) that incorporates 3D Reconstructive instruction tuning. VLM-3R processes monocular video frames by employing a geometry encoder to derive implicit 3D tokens that represent spatial understanding. Leveraging our Spatial-Visual-View Fusion and over 200K curated 3D reconstructive instruction tuning question-answer (QA) pairs, VLM-3R effectively aligns real-world spatial context with language instructions. This enables monocular 3D spatial assistance and embodied reasoning. To facilitate the evaluation of temporal reasoning, we introduce the Vision-Spatial-Temporal Intelligence benchmark, featuring over 138.6K QA pairs across five distinct tasks focused on evolving spatial relationships. Extensive experiments demonstrate that our model, VLM-3R, not only facilitates robust visual-spatial reasoning but also enables the understanding of temporal 3D context changes, excelling in both accuracy and scalability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VLM-3R, a unified framework augmenting Vision-Language Models with 3D Reconstructive instruction tuning. Monocular video frames are processed by a geometry encoder to produce implicit 3D tokens; these are fused via a Spatial-Visual-View Fusion module and the model is trained on over 200K curated 3D reconstructive QA pairs. The authors also release the Vision-Spatial-Temporal Intelligence benchmark containing 138.6K QA pairs across five tasks targeting evolving spatial relationships. Experiments are reported to demonstrate improved visual-spatial and temporal 3D reasoning without external depth sensors or pre-built maps.
Significance. If the central claims are substantiated, the work offers a scalable route to monocular 3D spatial understanding in VLMs, removing reliance on depth sensors or offline 3D reconstruction pipelines. The scale of the instruction-tuning corpus and the new temporal benchmark constitute concrete contributions that could support future embodied-reasoning research. The approach is noteworthy for attempting to embed geometric structure directly into the token stream rather than post-hoc fusion.
major comments (2)
- [§3] §3 (Geometry Encoder and Implicit 3D Tokens): No quantitative evaluation of geometric fidelity is provided for the implicit 3D tokens themselves (e.g., depth estimation MAE, multi-view consistency error, or comparison against ground-truth 3D reconstructions). Because the central claim rests on these tokens supplying accurate spatial content for downstream reasoning, the absence of such metrics leaves open the possibility that performance gains derive from language-level pattern matching rather than metric 3D structure.
- [§4] §4 (Experiments and Ablations): The reported results do not include ablations that isolate the geometry encoder from the Spatial-Visual-View Fusion module or from the 200K QA supervision. Without these controls it is difficult to attribute gains specifically to the implicit 3D representation rather than to increased training data volume or architectural capacity.
minor comments (2)
- [§5] Benchmark construction (§5): Provide explicit details on how the 138.6K QA pairs were generated, filtered, and checked for overlap with the 200K training set to allow independent assessment of benchmark independence.
- [§3] Notation and architecture diagram: Clarify the precise dimensionality and injection point of the implicit 3D tokens into the VLM backbone; a small diagram would reduce ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and indicate the revisions planned for the next version to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [§3] §3 (Geometry Encoder and Implicit 3D Tokens): No quantitative evaluation of geometric fidelity is provided for the implicit 3D tokens themselves (e.g., depth estimation MAE, multi-view consistency error, or comparison against ground-truth 3D reconstructions). Because the central claim rests on these tokens supplying accurate spatial content for downstream reasoning, the absence of such metrics leaves open the possibility that performance gains derive from language-level pattern matching rather than metric 3D structure.
Authors: We agree that direct quantitative assessment of the geometric fidelity of the implicit 3D tokens would help rule out purely linguistic explanations for the observed gains. While the primary evaluation in the manuscript centers on end-to-end spatial and temporal reasoning performance, we acknowledge the value of additional proxy metrics. In the revised manuscript we will add a dedicated analysis that reports depth prediction accuracy against available ground-truth depth on suitable subsets of the data, together with multi-view consistency measures derived from the input video sequences. These results will be presented alongside the existing reasoning benchmarks to better attribute improvements to the geometry encoder. revision: yes
-
Referee: [§4] §4 (Experiments and Ablations): The reported results do not include ablations that isolate the geometry encoder from the Spatial-Visual-View Fusion module or from the 200K QA supervision. Without these controls it is difficult to attribute gains specifically to the implicit 3D representation rather than to increased training data volume or architectural capacity.
Authors: We concur that more granular ablations would clarify the individual contributions of the geometry encoder, the fusion module, and the scale of the 3D reconstructive QA data. The current experiments include comparisons against strong baselines and variants trained without full 3D supervision, yet we did not present a complete set of controlled ablations. In the revision we will incorporate additional ablation studies that systematically disable or replace the geometry encoder, vary the fusion strategy, and train on reduced subsets of the 200K QA pairs while keeping model capacity fixed. These controls will help isolate the role of the implicit 3D representation. revision: yes
Circularity Check
No significant circularity; derivation relies on external data curation and new benchmark
full rationale
The paper presents VLM-3R as a framework that augments VLMs with a geometry encoder producing implicit 3D tokens from monocular video, trained via Spatial-Visual-View Fusion on over 200K curated 3D reconstructive QA pairs and evaluated on a newly introduced 138.6K-pair Vision-Spatial-Temporal Intelligence benchmark. No equations, self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on the curation of external instruction-tuning data and the construction of an independent benchmark rather than reducing to the model's own outputs by construction. The derivation chain is therefore self-contained against the stated training and evaluation resources.
Axiom & Free-Parameter Ledger
free parameters (2)
- geometry encoder architecture and training hyperparameters
- Spatial-Visual-View Fusion module parameters
axioms (2)
- domain assumption Monocular video frames contain sufficient geometric information for a learned encoder to produce implicit 3D tokens usable for spatial reasoning
- domain assumption The curated 200K 3D reconstructive QA pairs and 138.6K benchmark pairs are representative and unbiased measures of real-world spatial-temporal understanding
invented entities (1)
-
implicit 3D tokens
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VLM-3R processes monocular video frames by employing a geometry encoder to derive implicit 3D tokens... Spatial-Visual-View Fusion... over 200K curated 3D reconstructive instruction tuning QA pairs
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
metric-scale multiview stereo model... globally aligned metric-scale 3D structures directly from monocular video
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 23 Pith papers
-
ViSRA: A Video-based Spatial Reasoning Agent for Multi-modal Large Language Models
ViSRA boosts MLLM 3D spatial reasoning performance by up to 28.9% on unseen tasks via a plug-and-play video-based agent that extracts explicit spatial cues from expert models without any post-training.
-
Any 3D Scene is Worth 1K Tokens: 3D-Grounded Representation for Scene Generation at Scale
A 3D-grounded autoencoder and diffusion transformer allow direct generation of 3D scenes in an implicit latent space using a fixed 1K-token representation for arbitrary views and resolutions.
-
EgoTL: Egocentric Think-Aloud Chains for Long-Horizon Tasks
EgoTL provides a new egocentric dataset with think-aloud chains and metric labels that benchmarks VLMs on long-horizon tasks and improves their planning, reasoning, and spatial grounding after finetuning.
-
Token Warping Helps MLLMs Look from Nearby Viewpoints
Backward token warping in ViT-based MLLMs enables reliable reasoning from nearby viewpoints by preserving semantic coherence better than pixel-wise warping or fine-tuning baselines.
-
Thinking with Geometry: Active Geometry Integration for Spatial Reasoning
GeoThinker enables active, task-conditioned geometry integration in MLLMs via spatial-grounded fusion and importance gating, reaching 72.6 on VSI-Bench.
-
SpatialMosaic: A Multiview VLM Dataset for Partial Visibility
SpatialMosaic introduces a 2M-pair multi-view QA dataset and 1M-pair benchmark for MLLMs on spatial reasoning under partial visibility, plus a hybrid baseline that integrates 3D reconstruction models as geometry encoders.
-
4D-RGPT: Toward Region-level 4D Understanding via Perceptual Distillation
4D-RGPT uses perceptual 4D distillation to boost region-level 4D perception in multimodal LLMs and reports gains on existing and new video QA benchmarks.
-
POMA-3D: The Point Map Way to 3D Scene Understanding
POMA-3D learns self-supervised 3D scene representations from point maps and improves performance on geometric 3D tasks including navigation and scene retrieval.
-
4DThinker: Thinking with 4D Imagery for Dynamic Spatial Understanding
4DThinker enables VLMs to perform dynamic spatial reasoning by internally simulating 4D imagery in latent space, outperforming prior text-based and modular approaches.
-
$M^2$-VLA: Boosting Vision-Language Models for Generalizable Manipulation via Layer Mixture and Meta-Skills
M²-VLA shows that generalized VLMs can serve as direct backbones for robotic manipulation by selectively extracting task-critical features via Mixture of Layers and adding Meta Skill Modules for efficient trajectory learning.
-
Text-Guided 6D Object Pose Rearrangement via Closed-Loop VLM Agents
Closed-loop VLM agents using multi-view reasoning, object-centered visualization, and single-axis rotation prediction achieve superior text-guided 6D pose rearrangement for target objects in scenes.
-
Let Geometry GUIDE: Layer-wise Unrolling of Geometric Priors in Multimodal LLMs
GUIDE unrolls multi-granularity geometric priors layer-wise into early MLLM layers with gating to improve spatial reasoning and perception.
-
Lifting Unlabeled Internet-level Data for 3D Scene Understanding
Unlabeled web videos processed by designed data engines generate effective training data that yields strong zero-shot and finetuned performance on 3D detection, segmentation, VQA, and navigation.
-
EgoMind: Activating Spatial Cognition through Linguistic Reasoning in MLLMs
EgoMind activates spatial cognition in MLLMs via linguistic Role-Play Caption and Progressive Spatial Analysis, reaching competitive results on VSI-Bench, SPAR-Bench, SITE-Bench and SPBench with only 5K SFT and 20K RL...
-
MiMo-Embodied: X-Embodied Foundation Model Technical Report
MiMo-Embodied is a single foundation model that achieves state-of-the-art results on 17 embodied AI benchmarks and 12 autonomous driving benchmarks through multi-stage learning, curated data, and CoT/RL fine-tuning th...
-
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
Geometry Forcing aligns video diffusion representations with geometric foundation model features via angular cosine and scale regression objectives to improve 3D consistency in generated videos.
-
Thinking with Novel Views: A Systematic Analysis of Generative-Augmented Spatial Intelligence
Integrating generative novel-view synthesis into LMM reasoning loops improves accuracy on spatial subtasks by 1.3 to 3.9 percentage points across multiple models and tasks.
-
From Where Things Are to What They Are For: Benchmarking Spatial-Functional Intelligence in Multimodal LLMs
SFI-Bench shows current multimodal LLMs struggle to integrate spatial memory with functional reasoning and external knowledge in video tasks.
-
SpatialImaginer: Towards Adaptive Visual Imagination for Spatial Reasoning
SpatialImaginer integrates visual imagination with textual chain-of-thought to improve spatial reasoning robustness in multimodal large language models.
-
FF3R: Feedforward Feature 3D Reconstruction from Unconstrained views
FF3R unifies geometric and semantic 3D reconstruction in a single annotation-free feed-forward network trained solely via RGB and feature rendering supervision.
-
MAG-3D: Multi-Agent Grounded Reasoning for 3D Understanding
MAG-3D is a training-free multi-agent framework that coordinates planning, grounding, and coding agents with off-the-shelf VLMs to achieve grounded 3D reasoning and state-of-the-art benchmark results.
-
OpenSpatial: A Principled Data Engine for Empowering Spatial Intelligence
OpenSpatial supplies a principled open-source data engine and 3-million-sample dataset that raises spatial-reasoning model performance by an average of 19 percent on benchmarks.
-
AVA-VLA: Improving Vision-Language-Action models with Active Visual Attention
AVA-VLA reformulates VLA learning as a POMDP using recurrent states and active visual attention to achieve state-of-the-art results on LIBERO, CALVIN, and real dual-arm tasks.
Reference graph
Works this paper leans on
-
[1]
Open-asset-importer-library (assimp).https : //github.com/assimp/assimp, 2024. 15
work page 2024
-
[2]
Karen E Adolph. Specificity of learning: Why infants fall over a veritable cliff.Psychological Science, 11(4):290–295,
-
[3]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. 2022. 2
work page 2022
-
[4]
Scanqa: 3d question answering for spatial scene understanding
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. Scanqa: 3d question answering for spatial scene understanding. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19129– 19139, 2022. 6, 7
work page 2022
-
[5]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.12966, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
ARKitScenes: A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, et al. Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data.arXiv preprint arXiv:2111.08897, 2021. 4, 14, 15
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Gašper Beguš, Maksymilian D ˛ abkowski, and Ryan Rhodes. Large linguistic models: Analyzing theoretical linguistic abilities of llms.arXiv preprint arXiv:2305.00948, 2023. 2
-
[10]
Language models are few-shot learners.NeurIPS, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, Sand- hini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, S...
work page 2020
-
[11]
Spatialvlm: Endow- ing vision-language models with spatial reasoning capabili- ties
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endow- ing vision-language models with spatial reasoning capabili- ties. InCVPR, pages 14455–14465, 2024. 2, 3
work page 2024
-
[12]
Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning
Sijin Chen, Xin Chen, Chi Zhang, Mingsheng Li, Gang Yu, Hao Fei, Hongyuan Zhu, Jiayuan Fan, and Tao Chen. Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26428–26438, 2024. 7
work page 2024
-
[13]
Longvila: Scaling long-context vi- sual language models for long videos.arXiv, 2024
Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, et al. Longvila: Scaling long-context vi- sual language models for long videos.arXiv, 2024. 3
work page 2024
-
[14]
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhang- wei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.Science China Information Sciences, 67(12):220101,
-
[15]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InCVPR,
-
[16]
Spatial- rgpt: Grounded spatial reasoning in vision language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Rui- han Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatial- rgpt: Grounded spatial reasoning in vision language models. arXiv, 2024. 2
work page 2024
-
[17]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 4, 14, 15
work page 2017
-
[18]
3d-llava: Towards generalist 3d lmms with omni superpoint transformer.arXiv, 2025
Jiajun Deng, Tianyu He, Li Jiang, Tianyu Wang, Feras Day- oub, and Ian Reid. 3d-llava: Towards generalist 3d lmms with omni superpoint transformer.arXiv, 2025. 2, 3, 7
work page 2025
-
[19]
Palm-e: An embodied multimodal language model.arxiv, 2023
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, et al. Palm-e: An embodied multimodal language model.arxiv, 2023. 2
work page 2023
-
[20]
Zhiwen Fan, Jian Zhang, Wenyan Cong, Peihao Wang, Renjie Li, Kairun Wen, Shijie Zhou, Achuta Kadambi, Zhangyang Wang, Danfei Xu, et al. Large spatial model: End-to-end unposed images to semantic 3d.Advances in neural information processing systems, 37:40212–40229,
-
[21]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis.arXiv preprint arXiv:2405.21075, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24108–24118, 2025. 6, 7
work page 2025
-
[23]
Howard E Gardner.Frames of mind: The theory of multiple intelligences. 2011. 3
work page 2011
-
[24]
Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Ba- tra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017. 6, 7
work page 2017
-
[25]
Cascade cost volume for high-resolution 9 multi-view stereo and stereo matching
Xiaodong Gu, Zhiwen Fan, Siyu Zhu, Zuozhuo Dai, Feitong Tan, and Ping Tan. Cascade cost volume for high-resolution 9 multi-view stereo and stereo matching. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2495–2504, 2020. 3
work page 2020
-
[26]
Richard Hartley and Andrew Zisserman.Multiple view ge- ometry in computer vision. Cambridge university press,
-
[27]
Mary Hegarty and D Waller. Individual differences in spatial abilities.The Cambridge handbook of visuospatial thinking, pages 121–169, 2005. 3
work page 2005
-
[28]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Mea- suring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020. 4
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[29]
3d-llm: Inject- ing the 3d world into large language models
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: Inject- ing the 3d world into large language models. InNeurIPS,
-
[30]
Multiply: A multisensory object- centric embodied large language model in 3d world
Yining Hong, Zishuo Zheng, Peihao Chen, Yian Wang, Jun- yan Li, and Chuang Gan. Multiply: A multisensory object- centric embodied large language model in 3d world. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26406–26416, 2024. 2
work page 2024
-
[31]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 6
work page 2022
-
[32]
Chat-scene: Bridging 3d scene and large language models with object identifiers
Haifeng Huang, Yilun Chen, Zehan Wang, Rongjie Huang, Runsen Xu, Tai Wang, Luping Liu, Xize Cheng, Yang Zhao, Jiangmiao Pang, et al. Chat-scene: Bridging 3d scene and large language models with object identifiers. Advances in Neural Information Processing Systems, 37: 113991–114017, 2024. 7
work page 2024
-
[33]
Yuzhi Huang, Kairun Wen, Rongxin Gao, Dongxuan Liu, Yibin Lou, Jie Wu, Jing Xu, Jian Zhang, Zheng Yang, Yun- long Lin, Chenxin Li, Panwang Pan, Junbin Lu, Jingyan Jiang, Xinghao Ding, Yue Huang, and Zhi Wang. Think- ing in dynamics: How multimodal large language models perceive, track, and reason dynamics in physical 4d world,
-
[34]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv, 2024. 3
work page 2024
-
[35]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InICML, 2021. 2
work page 2021
-
[37]
Language models with rationality
Nora Kassner, Oyvind Tafjord, Ashish Sabharwal, Kyle Richardson, Hinrich Schütze, and Peter Clark. Language models with rationality. InEMNLP, 2023. 2
work page 2023
-
[38]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Ground- ing image matching in 3d with mast3r. InEuropean Confer- ence on Computer Vision, pages 71–91. Springer, 2024. 3
work page 2024
-
[39]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Llava-onevision: Easy visual task transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv, 2024. 3
work page 2024
-
[41]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InICML, pages 19730–19742, 2023. 2
work page 2023
-
[42]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InICML,
-
[43]
Vila: On pre-training for visual language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Moham- mad Shoeybi, and Song Han. Vila: On pre-training for visual language models. InCVPR, pages 26689–26699, 2024. 3, 6
work page 2024
-
[44]
JingLi Lin, Chenming Zhu, Runsen Xu, Xiaohan Mao, Xihui Liu, Tai Wang, and Jiangmiao Pang. Ost-bench: Evaluating the capabilities of mllms in online spatio-temporal scene un- derstanding.arXiv preprint arXiv:2507.07984, 2025. 6
-
[45]
Visual instruction tuning.NeurIPS, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.NeurIPS, 2024. 2
work page 2024
-
[46]
Zuyan Liu, Yuhao Dong, Ziwei Liu, Winston Hu, Ji- wen Lu, and Yongming Rao. Oryx mllm: On-demand spatial-temporal understanding at arbitrary resolution.arXiv preprint arXiv:2409.12961, 2024. 7
-
[47]
Unified-io: A unified model for vision, language, and multi-modal tasks.arXiv,
Jiasen Lu, Christopher Clark, Rowan Zellers, Roozbeh Mot- taghi, and Aniruddha Kembhavi. Unified-io: A unified model for vision, language, and multi-modal tasks.arXiv,
-
[48]
Sqa3d: Situated question answering in 3d scenes.arXiv preprint arXiv:2210.07474, 2022
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yi- tao Liang, Song-Chun Zhu, and Siyuan Huang. Sqa3d: Situated question answering in 3d scenes.arXiv preprint arXiv:2210.07474, 2022. 6, 7
-
[49]
Openeqa: Embodied question answering in the era of foun- dation models
Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, et al. Openeqa: Embodied question answering in the era of foun- dation models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16488– 16498, 2024. 18
work page 2024
-
[50]
Spatiallm: Train- ing large language models for structured indoor modeling
Yongsen Mao, Junhao Zhong, Chuan Fang, Jia Zheng, Rui Tang, Hao Zhu, Ping Tan, and Zihan Zhou. Spatiallm: Train- ing large language models for structured indoor modeling. arXiv preprint arXiv:2506.07491, 2025. 2
-
[51]
Timothy P McNamara. How are the locations of objects in the environment represented in memory? InInternational conference on spatial cognition, pages 174–191, 2002. 3
work page 2002
-
[52]
Individual differences in navigation: an introductory overview.Prime archives in psychology, 2022
Chiara Meneghetti, Laura Miola, Tommaso Feraco, Veronica Muffato, and Tommaso Feraco Miola. Individual differences in navigation: an introductory overview.Prime archives in psychology, 2022. 3
work page 2022
-
[53]
Mast3r-slam: Real-time dense slam with 3d reconstruction 10 priors
Riku Murai, Eric Dexheimer, and Andrew J Davison. Mast3r-slam: Real-time dense slam with 3d reconstruction 10 priors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16695–16705, 2025. 2
work page 2025
-
[54]
A comprehensive overview of large language models.arXiv preprint arXiv:2307.06435,
Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, and Ajmal Mian. A comprehensive overview of large language models.arXiv preprint arXiv:2307.06435,
-
[55]
Kosmos-2: Grounding multimodal large language models to the world.arXiv, 2023
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world.arXiv, 2023. 2
work page 2023
-
[56]
Improving language understanding by gener- ative pre-training.OpenAI Blog, 2018
Alec Radford. Improving language understanding by gener- ative pre-training.OpenAI Blog, 2018. 2
work page 2018
-
[57]
Language models are unsu- pervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsu- pervised multitask learners.OpenAI blog, 1(8):9, 2019. 2
work page 2019
-
[58]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, 2021. 2
work page 2021
-
[59]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. InProceedings of the IEEE/CVF international conference on computer vision, pages 9339–9347, 2019. 4, 15
work page 2019
-
[60]
Structure- from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 4104–4113, 2016. 2, 3
work page 2016
-
[61]
Zhenggang Tang, Yuchen Fan, Dilin Wang, Hongyu Xu, Rakesh Ranjan, Alexander Schwing, and Zhicheng Yan. Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds.arXiv preprint arXiv:2412.06974, 2024. 3
-
[62]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of con- text.arXiv, 2024
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of con- text.arXiv, 2024. 2, 3, 6
work page 2024
-
[64]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[66]
David Ed Waller and Lynn Ed Nadel.Handbook of spatial cognition.American Psychological Association, 2013. 3
work page 2013
-
[67]
3D Reconstruction with Spatial Memory
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory.arXiv preprint arXiv:2408.16061, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
Haochen Wang, Yucheng Zhao, Tiancai Wang, Haoqiang Fan, Xiangyu Zhang, and Zhaoxiang Zhang. Ross3d: Recon- structive visual instruction tuning with 3d-awareness.arXiv preprint arXiv:2504.01901, 2025. 2
-
[69]
Vggt: Visual geometry grounded transformer.arXiv preprint arXiv:2503.11651, 2025
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer.arXiv preprint arXiv:2503.11651, 2025. 3, 5
-
[70]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based au- tonomous agents.Frontiers of Computer Science, 18(6): 186345, 2024. 2
work page 2024
-
[71]
Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. InICML, 2022. 2
work page 2022
-
[72]
Continuous 3d perception model with persistent state.arXiv preprint arXiv:2501.12387, 2025
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state.arXiv preprint arXiv:2501.12387, 2025. 2, 3, 5, 13, 18
-
[73]
Dust3r: Geometric 3d vi- sion made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vi- sion made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20697– 20709, 2024. 3, 5
work page 2024
-
[74]
Emergent abilities of large language models.TMLR, 2022
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models.TMLR, 2022. 2
work page 2022
-
[75]
Kairun Wen, Yuzhi Huang, Runyu Chen, Hui Zheng, Yun- long Lin, Panwang Pan, Chenxin Li, Wenyan Cong, Jian Zhang, Junbin Lu, et al. Dynamicverse: A physically- aware multimodal framework for 4d world modeling.arXiv preprint arXiv:2512.03000, 2025. 3
-
[76]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence.arXiv preprint arXiv:2505.23747, 2025. 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How mul- timodal large language models see, remember, and recall spaces.arXiv preprint arXiv:2412.14171, 2024. 3, 4, 6, 14
-
[78]
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass.arXiv preprint arXiv:2501.13928, 2025. 3
-
[79]
Mvsnet: Depth inference for unstructured multi-view stereo
Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan. Mvsnet: Depth inference for unstructured multi-view stereo. InProceedings of the European conference on computer vi- sion (ECCV), pages 767–783, 2018. 3
work page 2018
-
[80]
Scannet++: A high-fidelity dataset of 3d in- door scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high-fidelity dataset of 3d in- door scenes. InProceedings of the IEEE/CVF International 11 Conference on Computer Vision, pages 12–22, 2023. 4, 14, 15
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.