Pondering the Way: Spatial-perceiving World Action Model for Embodied Navigation
Pith reviewed 2026-06-30 05:53 UTC · model grok-4.3
The pith
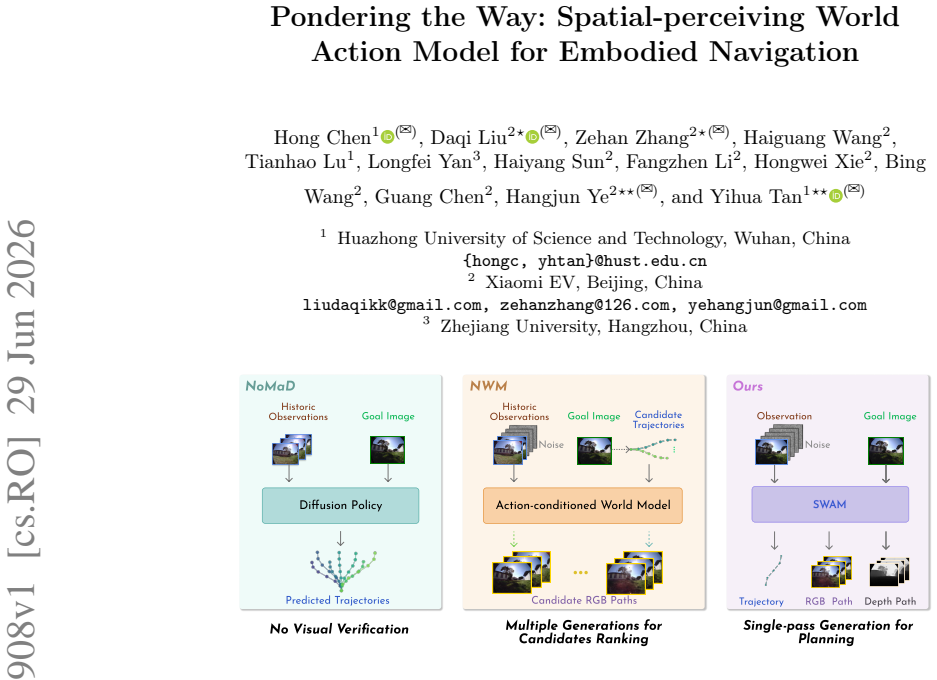
SWAM jointly generates RGB-D sequences and action trajectories from start and goal images in a single inference pass for embodied navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
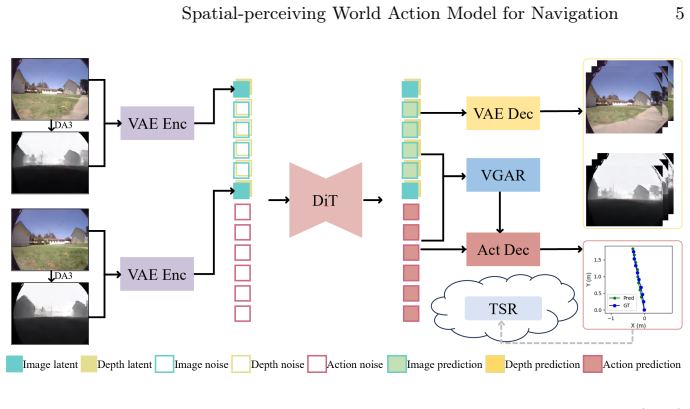
SWAM performs single-pass joint generation of intermediate RGB-D sequences and corresponding action trajectories given only start and goal RGB observations. This task-centric design replaces candidate sampling and verification loops with direct synthesis that enforces goal consistency and spatial feasibility. Depth pseudo-labels are used only during training; inference remains monocular. A visual-guided action refinement module together with trajectory-scale regularization further aligns motion predictions with visual cues and stabilizes outputs across distance scales.
What carries the argument
The Spatial-perceiving World Action Model (SWAM) that performs single-pass joint observation-action generation to enforce goal-consistent and spatially feasible trajectories.
If this is right
- Removes dependence on candidate sampling and separate verification steps, lowering computational cost.
- Produces trajectories whose visual predictions stay aligned with executed actions by construction.
- Internalizes spatial priors from depth labels so that monocular input suffices at inference.
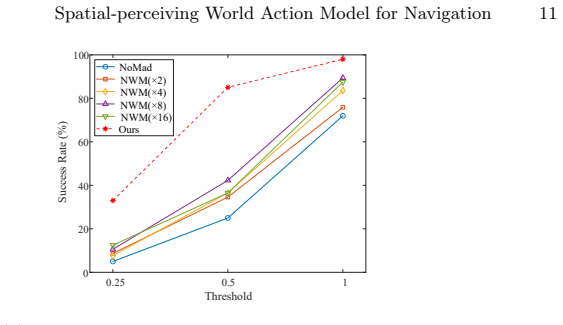
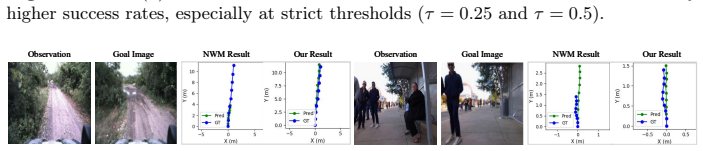
- Yields higher success rates and shorter accurate paths than two-stage planners.
- Maintains performance when transferred zero-shot to environments never seen in training.
Where Pith is reading between the lines
- The single-pass structure may limit error accumulation that occurs when planning and verification are chained across many steps.
- Monocular inference at test time could simplify hardware requirements for robots that lack depth sensors.
- The same joint-generation pattern could be tested on other control problems where visual prediction and action choice currently drift apart.
- If the regularization terms prove general, similar scale-aware losses might stabilize long-horizon predictions in related sequence models.
Load-bearing premise
Jointly predicting future RGB-D images and actions in one model will automatically keep the actions feasible inside the predicted visual space without introducing new mismatches.
What would settle it
Execute the generated action sequence in simulation while feeding the predicted RGB-D frames as observations; if the agent deviates from the intended goal or the observed depths contradict the predicted sequence, the joint-consistency claim fails.
Figures




read the original abstract
Existing world model-based planners for visual navigation typically follow a verification-centric paradigm, decoupling goal intent from trajectory synthesis. This approach suffers from candidate dependence, heavy computational overhead, and inconsistencies between sampled actions and predicted visuals. To address these issues, we propose SWAM (Spatial-perceiving World Action Model), a task-centric joint observation-action generation framework. Given start and goal RGB observations, SWAM performs single-pass inference to simultaneously generate intermediate RGB-D sequences and corresponding action trajectories, promoting goal-consistent trajectory generation and improved spatial feasibility. While SWAM leverages depth pseudo-labels during training to internalize spatial priors, it requires only monocular RGB input at inference time. We further introduce a visual-guided action refinement module and a trajectory-scale regularization loss to enforce fine-grained alignment between motion and visual cues while stabilizing predictions across varying distances. Extensive experiments show that SWAM significantly outperforms state-of-the-art two-stage planners in success rate, trajectory accuracy, and inference efficiency, while demonstrating robust zero-shot generalization to unseen environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SWAM (Spatial-perceiving World Action Model), a joint observation-action generation framework for embodied visual navigation. Unlike verification-centric two-stage planners that decouple goal intent from trajectory synthesis, SWAM performs single-pass inference to generate intermediate RGB-D sequences and corresponding action trajectories from start and goal RGB observations. Depth pseudo-labels are used only during training to internalize spatial priors, while inference uses monocular RGB. Additional components include a visual-guided action refinement module and a trajectory-scale regularization loss. The central claim is that this architecture yields higher success rates, better trajectory accuracy, improved inference efficiency, and stronger zero-shot generalization to unseen environments compared to prior two-stage methods.
Significance. If the performance claims hold under rigorous evaluation, the work could be significant for embodied navigation and world-model planning. The shift to single-pass joint generation directly targets documented inconsistencies between predicted visuals and executed actions, while the training-time use of depth pseudo-labels followed by RGB-only inference is a practical design that could reduce overhead. Demonstrating robust generalization without explicit depth at test time would be a useful contribution if supported by appropriate controls.
major comments (2)
- [Abstract] Abstract: The central claims of significant outperformance in success rate, trajectory accuracy, and inference efficiency, plus robust zero-shot generalization, are asserted without any quantitative results, baselines, error bars, dataset descriptions, or ablation evidence appearing in the provided manuscript text. This absence prevents evaluation of whether the joint-generation approach actually delivers the claimed consistency and efficiency gains.
- [Abstract] The manuscript text supplies no equations, architectural diagrams, loss formulations, or training details that would allow assessment of how the visual-guided refinement module and trajectory-scale regularization loss enforce alignment between motion and visual cues. Without these, it is impossible to verify that the single-pass design avoids introducing new mismatches between predicted visuals and actions.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comments point by point below and agree that revisions are needed to strengthen the abstract and ensure technical details are verifiable.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of significant outperformance in success rate, trajectory accuracy, and inference efficiency, plus robust zero-shot generalization, are asserted without any quantitative results, baselines, error bars, dataset descriptions, or ablation evidence appearing in the provided manuscript text. This absence prevents evaluation of whether the joint-generation approach actually delivers the claimed consistency and efficiency gains.
Authors: We agree that the abstract, as currently written, asserts performance claims without quantitative support or dataset details. The full manuscript contains these results in the Experiments section. We will revise the abstract to include key quantitative highlights (e.g., success rate deltas, inference speedups, and dataset names) to allow immediate evaluation of the claims. revision: yes
-
Referee: [Abstract] The manuscript text supplies no equations, architectural diagrams, loss formulations, or training details that would allow assessment of how the visual-guided refinement module and trajectory-scale regularization loss enforce alignment between motion and visual cues. Without these, it is impossible to verify that the single-pass design avoids introducing new mismatches between predicted visuals and actions.
Authors: We acknowledge that the provided manuscript text lacks equations, diagrams, loss formulations, and training details for the visual-guided action refinement module and trajectory-scale regularization loss. We will revise the manuscript to include these elements (equations for the losses, an architecture diagram, and explicit description of how they enforce visual-action alignment) so that the single-pass design can be properly assessed. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and description present SWAM as an empirical architecture: a single-pass joint RGB-D and action generator trained with depth pseudo-labels, refinement module, and regularization loss. No equations, parameter-fitting steps, uniqueness theorems, or self-citations are referenced that would reduce claimed performance gains to quantities defined by the inputs themselves. Experimental claims of improved success rate and zero-shot generalization rest on external benchmarks rather than any internal definitional loop, rendering the method self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Eighth international joint conference on Artificial intelligence-Volume 2
Allen, J.F., Koomen, J.A.: Planning using a temporal world model. In: Proceedings of the Eighth international joint conference on Artificial intelligence-Volume 2. pp. 741–747 (1983)
1983
-
[2]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Bar, A., Zhou, G., Tran, D., Darrell, T., LeCun, Y.: Navigation world models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15791–15801 (2025)
2025
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Journal of intelligent and robotic systems53(3), 263–296 (2008)
Bonin-Font, F., Ortiz, A., Oliver, G.: Visual navigation for mobile robots: A survey. Journal of intelligent and robotic systems53(3), 263–296 (2008)
2008
-
[5]
WorldVLA: Towards Autoregressive Action World Model
Cen, J., Yu, C., Yuan, H., Jiang, Y., Huang, S., Guo, J., Li, X., Song, Y., Luo, H., Wang, F., et al.: Worldvla: Towards autoregressive action world model. arXiv preprint arXiv:2506.21539 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
In: Robotics: Science and Systems (RSS) (2023)
Chi, C., Feng, S., Du, Y., Xu, Z., Cousineau, E., Burchfiel, B., Tedrake, R.: Diffu- sion policy: Visuomotor policy learning via action diffusion. In: Robotics: Science and Systems (RSS) (2023)
2023
-
[7]
Visual Foresight: Model-Based Deep Reinforcement Learning for Vision-Based Robotic Control
Ebert, F., Finn, C., Dasari, S., Xie, A., Lee, A., Levine, S.: Visual foresight: Model- based deep reinforcement learning for vision-based robotic control. arXiv preprint arXiv:1812.00568 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
In: 2017 IEEE international conference on robotics and automation (ICRA)
Finn, C., Levine, S.: Deep visual foresight for planning robot motion. In: 2017 IEEE international conference on robotics and automation (ICRA). pp. 2786–2793. IEEE (2017)
2017
-
[9]
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Gao,S.,Liang,W.,Zheng,K.,Malik,A.,Ye,S.,Yu,S.,Tseng,W.C.,Dong,Y.,Mo, K., Lin, C.H., et al.: Dreamdojo: A generalist robot world model from large-scale human videos. arXiv preprint arXiv:2602.06949 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Advances in Neural Information Processing Systems37, 112386–112410 (2024)
Guo, Y., Hu, Y., Zhang, J., Wang, Y.J., Chen, X., Lu, C., Chen, J.: Prediction with action: Visual policy learning via joint denoising process. Advances in Neural Information Processing Systems37, 112386–112410 (2024)
2024
-
[11]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Gupta, S., Davidson, J., Levine, S., Sukthankar, R., Malik, J.: Cognitive mapping and planning for visual navigation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2616–2625 (2017)
2017
-
[12]
Ha, D., Schmidhuber, J.: World models. arXiv preprint arXiv:1803.101222(3), 440 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
In: International Conference on Learning Representations (ICLR) (2020)
Hafner, D., Lillicrap, T., Ba, J., Norouzi, M.: Dream to control: Learning behaviors by latent imagination. In: International Conference on Learning Representations (ICLR) (2020)
2020
-
[14]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Hao, S., Gu, Y., Ma, H., Hong, J., Wang, Z., Wang, D., Hu, Z.: Reasoning with lan- guage model is planning with world model. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 8154–8173 (2023)
2023
-
[15]
IEEE Robotics and Automation Letters9(1), 49–56 (2023)
Hirose, N., Shah, D., Sridhar, A., Levine, S.: Sacson: Scalable autonomous control for social navigation. IEEE Robotics and Automation Letters9(1), 49–56 (2023)
2023
-
[16]
IEEE Robotics and Automation Letters4(4), 3184–3191 (2019)
Hirose, N., Xia, F., Martín-Martín, R., Sadeghian, A., Savarese, S.: Deep visual mpc-policy learning for navigation. IEEE Robotics and Automation Letters4(4), 3184–3191 (2019)
2019
-
[17]
Advances in neural information processing systems33, 6840–6851 (2020) Spatial-perceiving World Action Model for Navigation 17
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) Spatial-perceiving World Action Model for Navigation 17
2020
-
[18]
IEEE Robotics and Automation Letters 7(4), 11807–11814 (2022)
Karnan, H., Nair, A., Xiao, X., Warnell, G., Pirk, S., Toshev, A., Hart, J., Biswas, J., Stone, P.: Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation. IEEE Robotics and Automation Letters 7(4), 11807–11814 (2022)
2022
-
[19]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
A Comprehensive Survey on World Models for Embodied AI
Li, X., He, X., Zhang, L., Wu, M., Li, X., Liu, Y.: A comprehensive survey on world models for embodied ai. arXiv preprint arXiv:2510.16732 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
In: The Eleventh International Conference on Learning Rep- resentations
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: The Eleventh International Conference on Learning Rep- resentations
-
[23]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Liu, Y., Zhang, K., Li, Y., Yan, Z., Gao, C., Chen, R., Yuan, Z., Huang, Y., Sun, H., Gao, J., et al.: Sora: A review on background, technology, limitations, and opportunities of large vision models. arXiv preprint arXiv:2402.17177 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
In: International Conference on Learning Representations (2017)
Mirowski, P., Pascanu, R., Viola, F., Soyer, H., Ballard, A., Banino, A., Denil, M., Goroshin, R., Sifre, L., Kavukcuoglu, K., et al.: Learning to navigate in complex environments. In: International Conference on Learning Representations (2017)
2017
-
[25]
In: International Conference on Learning Representations (2018)
Parisotto, E., Salakhutdinov, R.: Neural map: Structured memory for deep re- inforcement learning. In: International Conference on Learning Representations (2018)
2018
-
[26]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[27]
In: International Conference on Learning Representations (2018)
Savinov, N., Dosovitskiy, A., Koltun, V.: Semi-parametric topological memory for navigation. In: International Conference on Learning Representations (2018)
2018
-
[28]
In: Confer- ence on Robot Learning
Shah, D., Equi, M.R., Osiński, B., Xia, F., Ichter, B., Levine, S.: Navigation with large language models: Semantic guesswork as a heuristic for planning. In: Confer- ence on Robot Learning. pp. 2683–2699. PMLR (2023)
2023
-
[29]
In: 2021 IEEE International Conference on Robotics and Automation (ICRA)
Shah, D., Eysenbach, B., Kahn, G., Rhinehart, N., Levine, S.: Ving: Learning open-world navigation with visual goals. In: 2021 IEEE International Conference on Robotics and Automation (ICRA). pp. 13215–13222. IEEE (2021)
2021
-
[30]
In: Conference on Robot Learning
Shah, D., Eysenbach, B., Rhinehart, N., Levine, S.: Rapid exploration for open- world navigation with latent goal models. In: Conference on Robot Learning. pp. 674–684. PMLR (2022)
2022
-
[31]
In: 2023 IEEE International Conference on Robotics and Automation (ICRA)
Shah, D., Sridhar, A., Bhorkar, A., Hirose, N., Levine, S.: Gnm: A general naviga- tion model to drive any robot. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). pp. 7226–7233. IEEE (2023)
2023
-
[32]
In: Conference on Robot Learning
Shah,D.,Sridhar,A.,Dashora,N.,Stachowicz,K.,Black,K.,Hirose,N.,Levine,S.: Vint: A foundation model for visual navigation. In: Conference on Robot Learning. pp. 711–733. PMLR (2023)
2023
-
[33]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems(NeurIPS2025) (2025)
Shen, Y., Wei, F., Du, Z., Liang, Y., Lu, Y., Yang, J., Zheng, N., Guo, B.: Videovla: Video generators can be generalizable robot manipulators. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems(NeurIPS2025) (2025)
2025
-
[34]
Song,J.,Meng,C.,Ermon,S.:Denoisingdiffusionimplicitmodels.In:International Conference on Learning Representations 18 Chen et al
-
[35]
In: Interna- tional Conference on Learning Representations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. In: Interna- tional Conference on Learning Representations
-
[36]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Sridhar, A., Shah, D., Glossop, C., Levine, S.: Nomad: Goal masked diffusion poli- cies for navigation and exploration. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 63–70. IEEE (2024)
2024
-
[37]
Octo: An Open-Source Generalist Robot Policy
Team, O.M., Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Kreiman, T., Xu, C., et al.: Octo: An open-source generalist robot policy. arXiv preprint arXiv:2405.12213 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
In: 2022 International Conference on Robotics and Automation (ICRA)
Triest, S., Sivaprakasam, M., Wang, S.J., Wang, W., Johnson, A.M., Scherer, S.: Tartandrive: A large-scale dataset for learning off-road dynamics models. In: 2022 International Conference on Robotics and Automation (ICRA). pp. 2546–2552. IEEE (2022)
2022
-
[39]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
arXiv preprint arXiv:2503.15875 (2025)
Wang, H., Liu, D., Xie, H., Liu, H., Ma, E., Yu, K., Wang, L., Wang, B.: Mila: Multi-view intensive-fidelity long-term video generation world model for au- tonomous driving. arXiv preprint arXiv:2503.15875 (2025)
-
[41]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wu, Y., Karunratanakul, K., Luo, Z., Tang, S.: Uniphys: Unified planner and con- troller with diffusion for flexible physics-based character control. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13214–13224 (2025)
2025
-
[42]
arXiv preprint arXiv:2601.04453 (2026)
Xiong, Z., Ye, X., Yaman, B., Cheng, S., Lu, Y., Luo, J., Jacobs, N., Ren, L.: UniDrive-WM: Unified understanding, planning and generation world model for autonomous driving. arXiv preprint arXiv:2601.04453 (2026)
-
[43]
In: Belgrave, D., Zhang, C., Lin, H., Pascanu, R., Koniusz, P., Ghassemi, M., Chen, N
Yang, J., Chitta, K., Gao, S., Chen, L., Shao, Y., Jia, X., Li, H., Geiger, A., Yue, X., Chen, L.: Resim: Reliable world simulation for autonomous driving. In: Belgrave, D., Zhang, C., Lin, H., Pascanu, R., Koniusz, P., Ghassemi, M., Chen, N. (eds.) Advances in Neural Information Processing Systems. vol. 38, pp. 167710–167741 (2025)
2025
-
[44]
arXiv preprint arXiv:2512.16023 (2025)
Yang, L., Bai, Y., Eskandar, G., Shen, F., Altillawi, M., Chen, D., Liu, Z., Valada, A.: Covar: Co-generation of video and action for robotic manipulation via multi- modal diffusion. arXiv preprint arXiv:2512.16023 (2025)
-
[45]
Yang,Y., Liu,J., Zhang,Z., Zhou, S.,Tan, R.,Yang,J., Du,Y., Gan,C.: Mindjour- ney:Test-timescalingwithworldmodelsforspatialreasoning.In:TheThirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[46]
In: The Thirteenth International Conference on Learning Represen- tations (2025)
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., Yin, D., Yuxuan.Zhang, Wang, W., Cheng, Y., Xu, B., Gu, X., Dong, Y., Tang, J.: Cogvideox: Text-to-video diffusion models with an expert transformer. In: The Thirteenth International Conference on Learning Represen- tations (2025)
2025
-
[47]
World Action Models are Zero-shot Policies
Ye, S., Ge, Y., Zheng, K., Gao, S., Yu, S., Kurian, G., Indupuru, S., Tan, Y.L., Zhu, C., Xiang, J., et al.: World action models are zero-shot policies. arXiv preprint arXiv:2602.15922 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
In: RSS 2025 Workshop: Mobile Manipulation: Emerging Opportunities&Con- temporary Challenges (2025) Spatial-perceiving World Action Model for Navigation 19
Yin, T., Mei, Z., Sun, T., Zha, L., Zhou, E., Bao, J., Yamane, M., Sho, O., Majum- dar, A.: Womap: World models for embodied open-vocabulary object localization. In: RSS 2025 Workshop: Mobile Manipulation: Emerging Opportunities&Con- temporary Challenges (2025) Spatial-perceiving World Action Model for Navigation 19
2025
-
[49]
World-in-world: World models in a closed-loop world.arXiv preprint arXiv:2510.18135, 2025
Zhang, J., Jiang, M., Dai, N., Lu, T., Uzunoglu, A., Zhang, S., Wei, Y., Wang, J., Patel, V.M., Liang, P.P., et al.: World-in-world: World models in a closed-loop world. arXiv preprint arXiv:2510.18135 (2025)
-
[50]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, K., Tang, Z., Hu, X., Pan, X., Guo, X., Liu, Y., Huang, J., Yuan, L., Zhang, Q., Long, X.X., et al.: Epona: Autoregressive diffusion world model for autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27220–27230 (2025)
2025
-
[51]
Engineering Applications of Artificial Intelligence114, 105036 (2022)
Zhang, T., Hu, X., Xiao, J., Zhang, G.: A survey of visual navigation: From geome- try to embodied ai. Engineering Applications of Artificial Intelligence114, 105036 (2022)
2022
-
[52]
Open-Sora: Democratizing Efficient Video Production for All
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y., Li, T., You, Y.: Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning
Zhou, G., Pan, H., LeCun, Y., Pinto, L.: Dino-wm: World models on pre-trained visual features enable zero-shot planning. arXiv preprint arXiv:2411.04983 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Zhou, S., Du, Y., Yang, Y., Han, L., Chen, P., Yeung, D.Y., Gan, C.: Learning 3d persistent embodied world models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[55]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhu, H., Wang, Y., Zhou, J., Chang, W., Zhou, Y., Li, Z., Chen, J., Shen, C., Pang, J., He, T.: Aether: Geometric-aware unified world modeling. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8535–8546 (2025)
2025
-
[56]
In: 2017 IEEE international conference on robotics and automation (ICRA)
Zhu, Y., Mottaghi, R., Kolve, E., Lim, J.J., Gupta, A., Fei-Fei, L., Farhadi, A.: Target-driven visual navigation in indoor scenes using deep reinforcement learning. In: 2017 IEEE international conference on robotics and automation (ICRA). pp. 3357–3364. IEEE (2017) Pondering the Way: Spatial-perceiving World Action Model for Embodied Navigation Supplemen...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.