Learning Dexterous Manipulation Using Contact Wrench Guidance From Human Demonstration
Pith reviewed 2026-07-02 21:21 UTC · model grok-4.3
The pith
Contact wrench guidance from human demonstrations scales reinforcement learning to 82 percent success on 1,831 dexterous manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
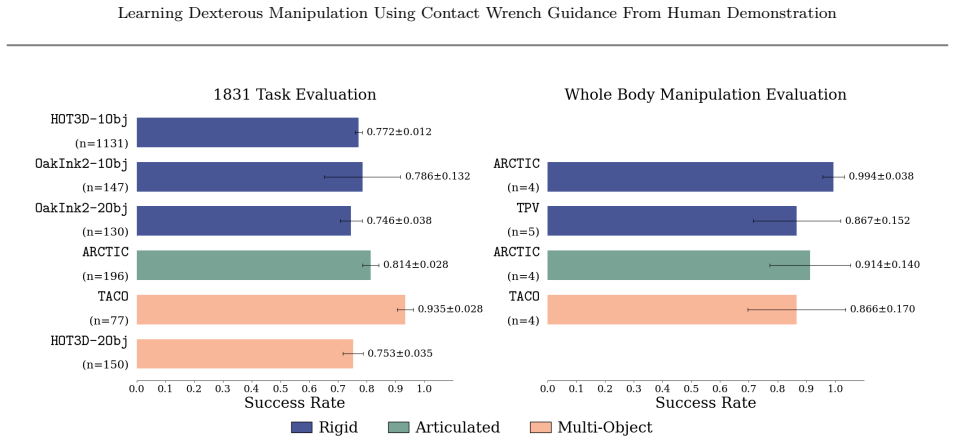
CHORD uses object-centric contact wrench space guidance from human demonstrations to direct reinforcement learning, representing motions by the forces and torques induced on the object so that similarity is measured by induced instantaneous motions; this yields an average 82.12 percent success rate across 1,831 benchmark tasks, 90.77 percent success when generalizing to whole-body manipulation from hand-only or third-person data, and successful open- and closed-loop transfer to real robots.
What carries the argument
Object-centric contact wrench space guidance, which represents human and robot motions by the forces and torques they induce on the manipulated object and quantifies similarity through the instantaneous motions those wrenches produce.
If this is right
- Reinforcement learning becomes feasible for contact-rich dexterous tasks spanning thousands of long-horizon scenarios.
- Policies learned from limited hand-only or third-person demonstrations can control whole-body robot actions.
- The same policies transfer from simulation to real robots without additional adaptation in both open-loop and closed-loop modes.
- A standardized benchmark of 4,739 tasks derived from motion capture and video reconstruction supports systematic evaluation.
Where Pith is reading between the lines
- The wrench representation may reduce sensitivity to kinematic differences between human and robot embodiments.
- Similar guidance could be tested on non-rigid or deformable objects where contact forces still dominate behavior.
- The method implies that reward shaping in manipulation can be partially replaced by demonstration-derived wrench targets.
Load-bearing premise
Representing human and robot motions by the forces and torques they induce on the object enables similarity measurement that effectively guides reinforcement learning for long-horizon tasks.
What would settle it
Running the same reinforcement learning agents on the 1,831 tasks with and without the wrench-based guidance term and finding no statistically significant difference in success rates would falsify the claim that this guidance improves scalability.
Figures

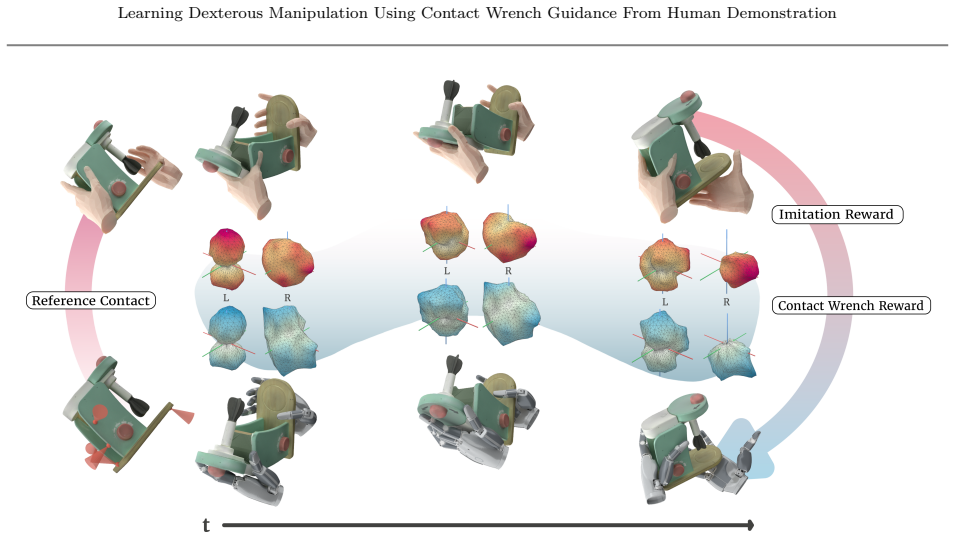


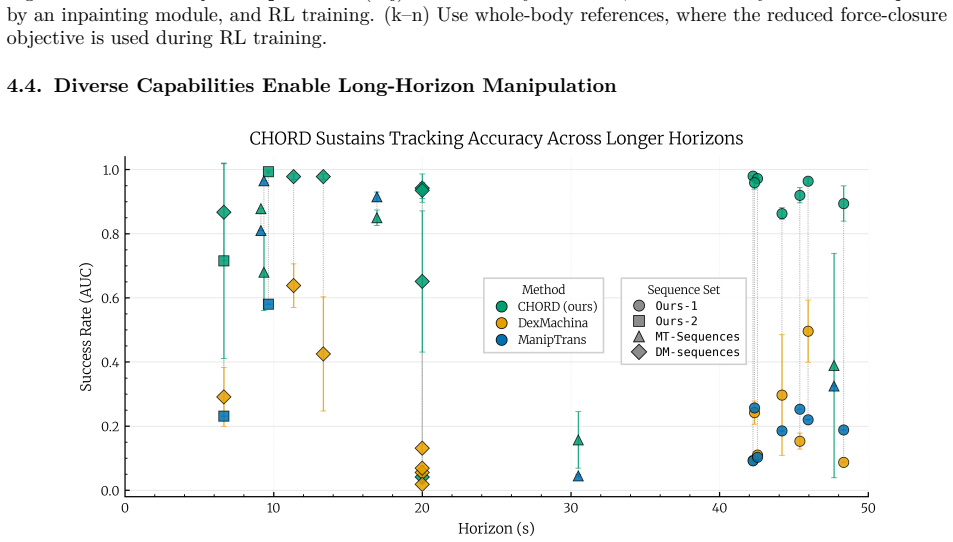

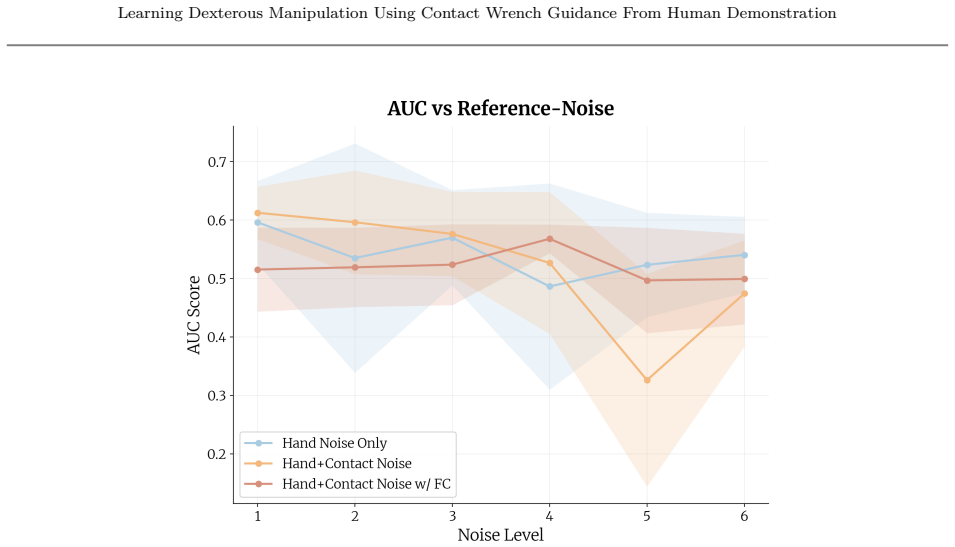



read the original abstract
Dexterous robot manipulation can benefit from the abundance of human demonstrations, but transferring such demonstrations to robot policies remains challenging. We present Contact Wrench Guidance from Human Demonstration in Robotic Dexterous Manipulation (CHORD), a framework for long-horizon manipulation of rigid and articulated objects with reinforcement learning. The key idea is object-centric contact wrench space guidance: we represent human and robot motions by the forces and torques they can induce on the object, enabling similarity to be measured by the induced instantaneous motions. This guidance makes reinforcement learning more scalable for contact-rich dexterous manipulation. We further introduce a large-scale simulation benchmark with 4,739 bimanual dexterous manipulation tasks, constructed from motion-capture datasets and reconstructed in-house videos. Evaluated on 1,831 benchmark tasks, CHORD achieves an average success rate of 82.12%, demonstrating strong scalability. CHORD also generalizes to whole-body manipulation from hand-only and third-person demonstrations, achieving a 90.77% success rate, and the learned policies transfer to the real world in both open-loop and closed-loop settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CHORD, a framework that represents human and robot motions via object-centric contact wrenches (forces and torques) to compute similarity through induced instantaneous motions, using this signal to guide reinforcement learning for long-horizon dexterous manipulation of rigid and articulated objects. It constructs a simulation benchmark of 4,739 bimanual tasks from motion-capture datasets and in-house videos, evaluates on 1,831 tasks reporting 82.12% average success, shows generalization to whole-body manipulation from hand-only/third-person demos at 90.77% success, and demonstrates open- and closed-loop real-world transfer.
Significance. If the wrench-space guidance proves robust and the benchmark construction is free of selection bias, the work offers a concrete mechanism for scaling RL on contact-rich tasks from abundant human data without requiring direct trajectory imitation. The scale of the benchmark (thousands of tasks) and reported real-world transfer are notable strengths that could influence subsequent research on demonstration-guided dexterous policies.
major comments (2)
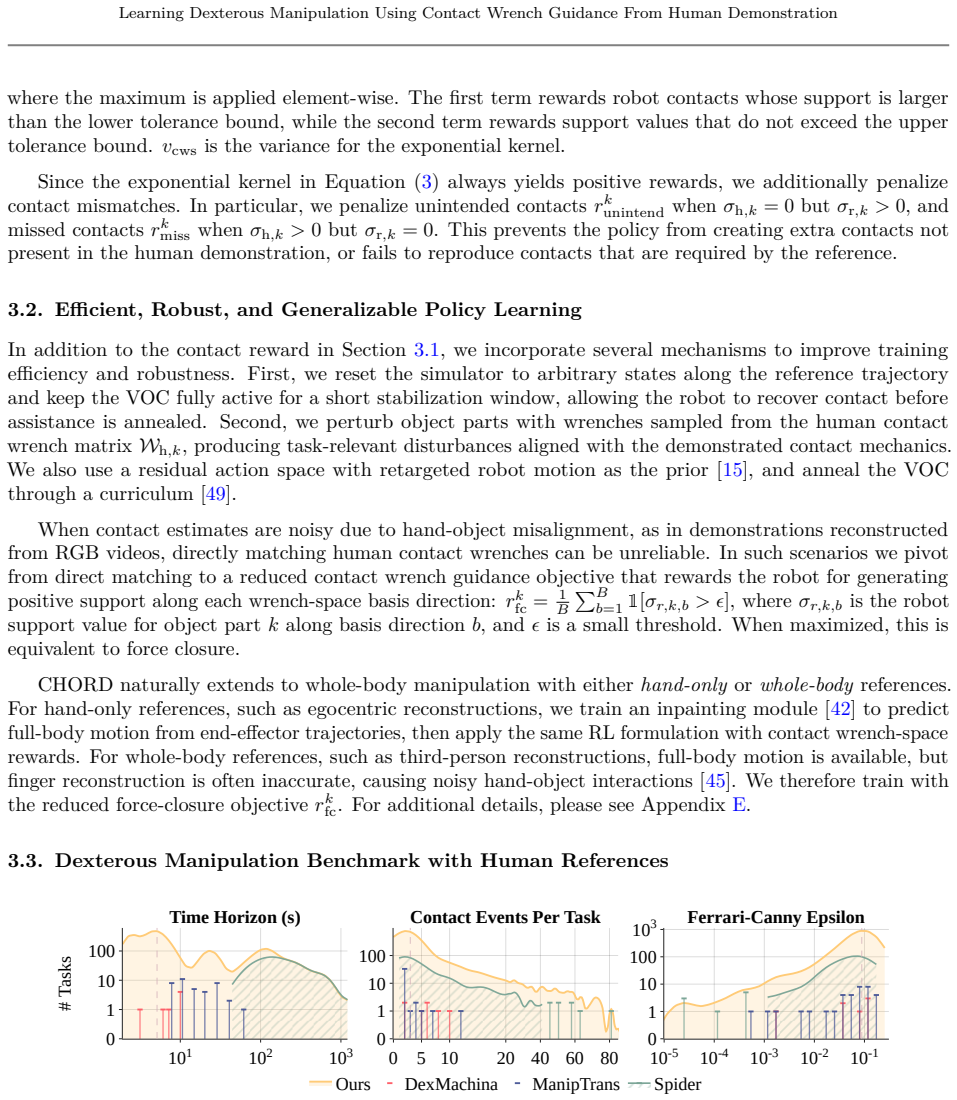
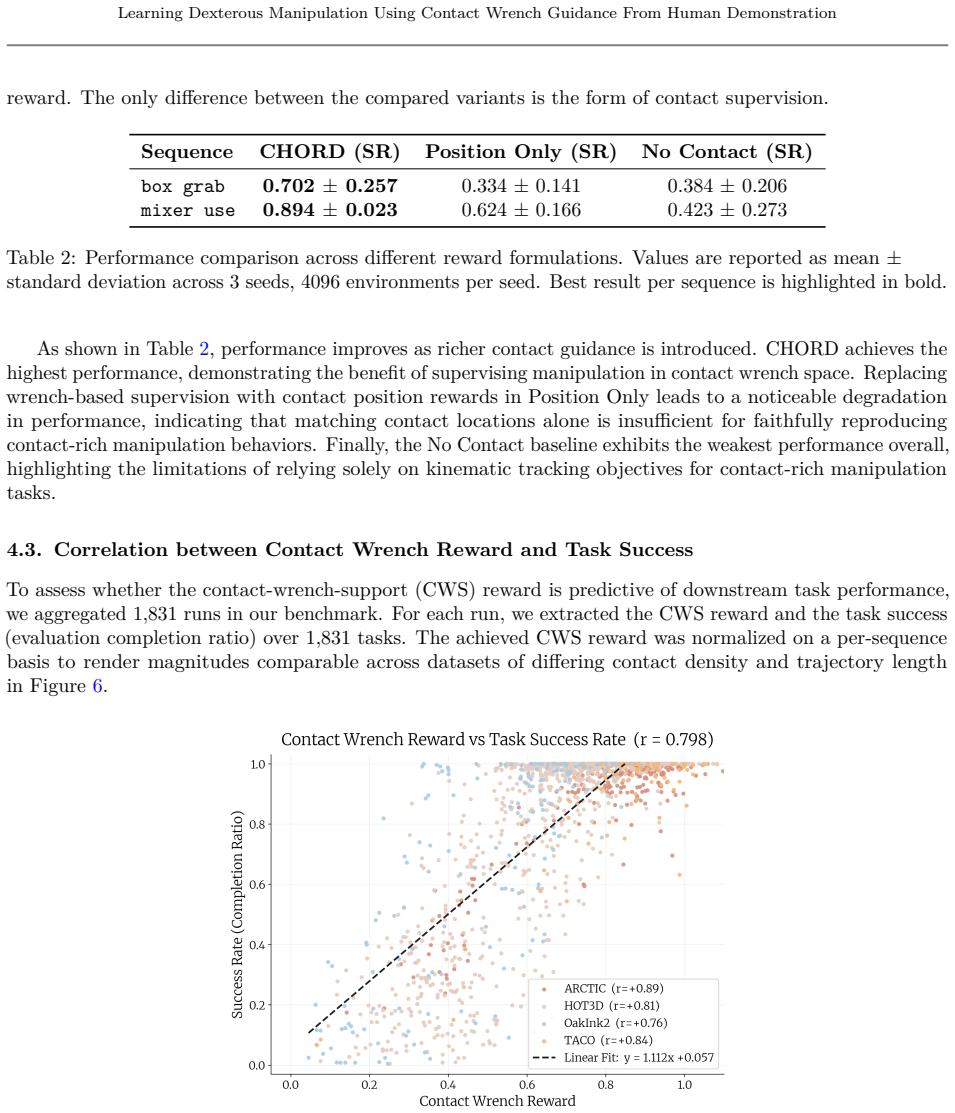
- [§4.3] §4.3 (Wrench Similarity Metric): The definition of similarity via induced instantaneous motions (Eq. 3) is load-bearing for the central claim that this guidance improves RL scalability, yet the manuscript does not report an ablation replacing it with a direct pose or velocity distance; without this, it remains unclear whether the wrench representation itself, rather than any dense reward, drives the 82.12% success rate.
- [§5.1] §5.1 (Benchmark Evaluation Protocol): The selection of the 1,831 evaluated tasks from the full 4,739 is not accompanied by a breakdown of task categories or difficulty stratification; if easier tasks are over-represented, the average success rate cannot be taken as evidence of strong scalability across the distribution.
minor comments (2)
- [Figure 3] Figure 3: The caption does not specify the number of random seeds used for the success-rate bars; adding this would allow readers to assess statistical reliability.
- [§6.2] §6.2: The real-world transfer experiments report qualitative success but omit quantitative metrics (e.g., success rate over N trials) comparable to the simulation numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive recommendation. We address each major point below and will incorporate clarifications and additional analysis in the revision.
read point-by-point responses
-
Referee: [§4.3] The definition of similarity via induced instantaneous motions (Eq. 3) is load-bearing for the central claim that this guidance improves RL scalability, yet the manuscript does not report an ablation replacing it with a direct pose or velocity distance; without this, it remains unclear whether the wrench representation itself, rather than any dense reward, drives the 82.12% success rate.
Authors: We agree that an explicit ablation against pose- or velocity-based dense rewards would strengthen the central claim. The wrench metric is designed to capture contact-induced dynamics that are invariant to absolute pose and better suited to articulated objects, but without the requested comparison the contribution of the representation versus the mere presence of a dense signal cannot be fully isolated. We will add this ablation (replacing Eq. 3 with Euclidean pose/velocity distances while keeping all other training details fixed) to the revised manuscript. revision: yes
-
Referee: [§5.1] The selection of the 1,831 evaluated tasks from the full 4,739 is not accompanied by a breakdown of task categories or difficulty stratification; if easier tasks are over-represented, the average success rate cannot be taken as evidence of strong scalability across the distribution.
Authors: The 1,831 tasks were those for which reliable object-centric wrench signals could be extracted from the source motion-capture and video data and that remained kinematically feasible after retargeting to the robot embodiment. We acknowledge that the current manuscript lacks an explicit stratification by object type (rigid vs. articulated), contact complexity, or estimated difficulty. We will add a supplementary table reporting the category distribution and success rates broken down by these factors for both the full 4,739 and the evaluated 1,831 subsets. revision: yes
Circularity Check
No significant circularity; empirical results on external benchmarks
full rationale
The abstract and available context present CHORD as a framework whose core contribution is an object-centric wrench-space similarity metric used to guide RL, with performance measured as empirical success rates (82.12% on 1,831 tasks, 90.77% on whole-body generalization) drawn from motion-capture datasets and reconstructed videos. No equations, fitted parameters renamed as predictions, self-citation load-bearing steps, or self-definitional reductions appear in the provided material. The benchmark construction and reported outcomes are externally sourced and falsifiable, rendering the derivation chain self-contained against external data rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Motions can be represented by the forces and torques they induce on the object to measure similarity
invented entities (1)
-
CHORD framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Rethinking optimization with differentiable simulation from a global perspective
Rika Antonova, Jingyun Yang, Krishna Murthy Jatavallabhula, and Jeannette Bohg. Rethinking optimization with differentiable simulation from a global perspective. In6th Annual Conference on Robot Learning, 2022
2022
-
[2]
Hot3d: Hand and object tracking in 3d from egocentric multi-view videos
Prithviraj Banerjee, Sindi Shkodrani, Pierre Moulon, Shreyas Hampali, Shangchen Han, Fan Zhang, Lin- guang Zhang, Jade Fountain, Edward Miller, Selen Basol, Richard Newcombe, Robert Wang, Jakob Julian Engel, and Tomas Hodan. Hot3d: Hand and object tracking in 3d from egocentric multi-view videos. In Proceedings of the IEEE/CVF Conference on Computer Visio...
2025
-
[3]
On the closure properties of robotic grasping.The International Journal of Robotics Research, 14(4):319–334, 1995
Antonio Bicchi. On the closure properties of robotic grasping.The International Journal of Robotics Research, 14(4):319–334, 1995
1995
-
[4]
Narang, Karl Van Wyk, Umar Iqbal, Stan Birchfield, Jan Kautz, and Dieter Fox
Yu-Wei Chao, Wei Yang, Yu Xiang, Pavlo Molchanov, Ankur Handa, Jonathan Tremblay, Yashraj S. Narang, Karl Van Wyk, Umar Iqbal, Stan Birchfield, Jan Kautz, and Dieter Fox. DexYCB: A benchmark for capturing hand grasping of objects. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[5]
Object-centric dexterous manipulation from human motion data.arXiv preprint arXiv:2411.04005, 2024
Yuanpei Chen, Chen Wang, Yaodong Yang, and C Karen Liu. Object-centric dexterous manipulation from human motion data.arXiv preprint arXiv:2411.04005, 2024
-
[6]
Black, and Otmar Hilliges
Zicong Fan, Omid Taheri, Dimitrios Tzionas, Muhammed Kocabas, Manuel Kaufmann, Michael J. Black, and Otmar Hilliges. ARCTIC: A dataset for dexterous bimanual hand-object manipulation. InProceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[7]
Planning optimal grasps
Carlo Ferrari and John Canny. Planning optimal grasps. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 2290–2295, 1992
1992
-
[8]
Learning prehensile dexterity by imitating and emulating state-only observations.IEEE Robotics and Automation Letters, 9(10):8266–8273, 2024
Yunhai Han, Zhenyang Chen, Kyle A Williams, and Harish Ravichandar. Learning prehensile dexterity by imitating and emulating state-only observations.IEEE Robotics and Automation Letters, 9(10):8266–8273, 2024
2024
-
[9]
Spot: Se (3) pose trajectory diffusion for object-centric manipulation
Cheng-Chun Hsu, Bowen Wen, Jie Xu, Yashraj Narang, Xiaolong Wang, Yuke Zhu, Joydeep Biswas, and Stan Birchfield. Spot: Se (3) pose trajectory diffusion for object-centric manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 4853–4860. IEEE, 2025
2025
-
[10]
ViPE: Video Pose Engine for 3D Geometric Perception
Jiahui Huang, Qunjie Zhou, Hesam Rabeti, Aleksandr Korovko, Huan Ling, Xuanchi Ren, Tianchang Shen, Jun Gao, Dmitry Slepichev, Chen-Hsuan Lin, Jiawei Ren, Kevin Xie, Joydeep Biswas, Laura Leal-Taixé, and Sanja Fidler. ViPE: Video pose engine for 3d geometric perception.arXiv preprint arXiv:2508.10934, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Egomimic: Scaling imitation learning via egocentric video
Simar Kareer, Dhruv Patel, Ryan Punamiya, Pranay Mathur, Shuo Cheng, Chen Wang, Judy Hoffman, and Danfei Xu. Egomimic: Scaling imitation learning via egocentric video. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 13226–13233, 2025
2025
-
[12]
3d Gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (TOG), 42(4), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d Gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (TOG), 42(4), 2023
2023
-
[13]
The role of tactile sensing in learning and deploying grasp refinement algorithms
Alexander Koenig, Zixi Liu, Lucas Janson, and Robert Howe. The role of tactile sensing in learning and deploying grasp refinement algorithms. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7766–7772. IEEE, 2022
2022
-
[14]
H2o: Two hands manipulating objects for first person interaction recognition
Taein Kwon, Bugra Tekin, Jan Stühmer, Federica Bogo, and Marc Pollefeys. H2o: Two hands manipulating objects for first person interaction recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10138–10148, October 2021
2021
-
[15]
Maniptrans: Efficient dexterous bimanual manipulation transfer via residual learning
Kailin Li, Puhao Li, Tengyu Liu, Yuyang Li, and Siyuan Huang. Maniptrans: Efficient dexterous bimanual manipulation transfer via residual learning. InProceedings of the Computer Vision and Pattern Recognition Conference, 2025. 12 Learning Dexterous Manipulation Using Contact Wrench Guidance From Human Demonstration
2025
-
[16]
Truong, Xiaoyu Huang, Yuman Gao, Guy Tevet, Koushil Sreenath, and C
Qiayuan Liao, Takara E. Truong, Xiaoyu Huang, Yuman Gao, Guy Tevet, Koushil Sreenath, and C. Karen Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion, 2025
2025
-
[17]
Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[18]
Dextrack: Towards generalizable neural tracking control for dexterous manipulation from human references
Xueyi Liu, Jianibieke Adalibieke, Qianwei Han, Yuzhe Qin, and Li Yi. Dextrack: Towards generalizable neural tracking control for dexterous manipulation from human references. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[19]
Parameterized quasi-physical simulators for dexterous manipulations transfer
Xueyi Liu, Kangbo Lyu, Jieqiong Zhang, Tao Du, and Li Yi. Parameterized quasi-physical simulators for dexterous manipulations transfer. In Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision – ECCV 2024, pages 164–182, Cham, 2025. Springer Nature Switzerland
2024
-
[20]
Taco: Benchmarking generalizable bimanual tool-action-object understanding
Yun Liu, Haolin Yang, Xu Si, Ling Liu, Zipeng Li, Yuxiang Zhang, Yebin Liu, and Li Yi. Taco: Benchmarking generalizable bimanual tool-action-object understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21740–21751, 2024
2024
-
[21]
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
Zhengyi Luo, Ye Yuan, Tingwu Wang, Chenran Li, Sirui Chen, Fernando Castañeda, Zi-Ang Cao, Jiefeng Li, David Minor, Qingwei Ben, Xingye Da, Runyu Ding, Cyrus Hogg, Lina Song, Edy Lim, Eugene Jeong, Tairan He, Haoru Xue, Wenli Xiao, Zi Wang, Simon Yuen, Jan Kautz, Yan Chang, Umar Iqbal, Linxi Fan, and Yuke Zhu. Sonic: Supersizing motion tracking for natura...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Andrew Melnik, Luka Lach, Matthias Plappert, Timo Korthals, Robert Haschke, and Helge Ritter. Using tactile sensing to improve the sample efficiency and performance of deep deterministic policy gradients for simulated in-hand manipulation tasks.Frontiers in Robotics and AI, 8:57, 2021
2021
-
[23]
Tactile sensing and deep reinforcement learning for in-hand manipulation tasks
Andrew Melnik, Luka Lach, Matthias Plappert, Timo Korthals, Robert prestige Haschke, and Helge Ritter. Tactile sensing and deep reinforcement learning for in-hand manipulation tasks. InIROS Workshop on Autonomous Object Manipulation, 2019
2019
-
[24]
Leveraging contact forces for learning to grasp
Haris Merzic, Miroslav Bogdanovic, Daniel Kappler, Ludovic Righetti, and Jeannette Bohg. Leveraging contact forces for learning to grasp. In2019 International Conference on Robotics and Automation (ICRA), pages 3615–3621. IEEE, 2019
2019
-
[25]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano- Muñoz, Xinjie Yao, René Zurbrügg, Nikita Rudin, Lukasz Wawrzyniak, Milad Rakhsha, Alain Denzler, Eric Heiden, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T. Carlson, Ji Yuan Feng, Animesh Garg, Renato Gasoto, Lionel Gulich, Yijie Guo, M. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
CRC press, 2017
Richard M Murray, Zexiang Li, and S Shankar Sastry.A mathematical introduction to robotic manipulation. CRC press, 2017. 13 Learning Dexterous Manipulation Using Contact Wrench Guidance From Human Demonstration
2017
-
[27]
R3M: A Universal Visual Representation for Robot Manipulation
Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. R3m: A universal visual representation for robot manipulation.arXiv preprint arXiv:2203.12601, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
An overview of dexterous manipulation
Allison M Okamura, Niels Smaby, and Mark R Cutkosky. An overview of dexterous manipulation. InProceedings 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No. 00CH37065), volume 1, pages 255–262. IEEE, 2000
2000
-
[29]
SPIDER: Scalable physics-informed dexterous retargeting.arXiv preprint arXiv:2511.09484, 2025
Chaoyi Pan, Changhao Wang, Haozhi Qi, Zixi Liu, Homanga Bharadhwaj, Akash Sharma, Tingfan Wu, Guanya Shi, Jitendra Malik, and Francois Robert Hogan. SPIDER: Scalable physics-informed dexterous retargeting.arXiv preprint arXiv:2511.09484, 2025
-
[30]
Tao Pang, H. J. Terry Suh, Lujie Yang, and Russ Tedrake. Global planning for contact-rich manipulation via local smoothing of quasi-dynamic contact models.IEEE Transactions on Robotics, 39(6):4691–4711, 2023
2023
-
[31]
Zhu, Simar Kareer, Judy Hoffman, and Danfei Xu
Ryan Punamiya, Dhruv Patel, Patcharapong Aphiwetsa, Pranav Kuppili, Lawrence Y. Zhu, Simar Kareer, Judy Hoffman, and Danfei Xu. Egobridge: Domain adaptation for generalizable imitation from egocentric human data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[32]
Dexmv: Imitation learning for dexterous manipulation from human videos, 2021
Yuzhe Qin, Yueh-Hua Wu, Shaowei Liu, Hanwen Jiang, Ruihan Yang, Yang Fu, and Xiaolong Wang. Dexmv: Imitation learning for dexterous manipulation from human videos, 2021
2021
-
[33]
SAM 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. SAM 2: Segment anything in images and videos. InInternational Conference o...
2025
-
[34]
Recent advances in robot learning from demonstration.Annual review of control, robotics, and autonomous systems, 3(1):297–330, 2020
Harish Ravichandar, Athanasios S Polydoros, Sonia Chernova, and Aude Billard. Recent advances in robot learning from demonstration.Annual review of control, robotics, and autonomous systems, 3(1):297–330, 2020
2020
-
[35]
Javier Romero, Dimitrios Tzionas, and Michael J. Black. Embodied hands: Modeling and capturing hands and bodies together.ACM Transactions on Graphics (TOG), 36(6), 2017
2017
-
[36]
SAM 3D: 3Dfy Anything in Images
SAM 3D Team. SAM 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
H. J. Terry Suh, Tao Pang, Tong Zhao, and Russ Tedrake. Dexterous contact-rich manipulation via the contact trust region.The International Journal of Robotics Research, 0(0), 2026
2026
-
[38]
Bundled gradients through contact via randomized smoothing.IEEE Robotics and Automation Letters, 7:1–1, 04 2022
Hyung Ju Suh, Tao Pang, and Russ Tedrake. Bundled gradients through contact via randomized smoothing.IEEE Robotics and Automation Letters, 7:1–1, 04 2022
2022
-
[39]
Black, and Dimitrios Tzionas
Omid Taheri, Nima Ghorbani, Michael J. Black, and Dimitrios Tzionas. GRAB: A dataset of whole-body human grasping of objects. InEuropean Conference on Computer Vision (ECCV), 2020
2020
-
[40]
DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras
Zachary Teed and Jia Deng. DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[41]
MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[42]
Motionbricks: Scalable real-time motions with modular latent generative model and smart primitives, 2026
Tingwu Wang, Olivier Dionne, Michael De Ruyter, David Minor, Davis Rempe, Kaifeng Zhao, Mathis Petrovich, Ye Yuan, Chenran Li, Zhengyi Luo, Brian Robison, Xavier Blackwell, Bernardo Antoniazzi, Xue Bin Peng, Yuke Zhu, and Simon Yuen. Motionbricks: Scalable real-time motions with modular latent generative model and smart primitives, 2026
2026
-
[43]
You only demonstrate once: Category-level manipulation from single visual demonstration.RSS, 2022
Bowen Wen, Wenzhao Lian, Kostas Bekris, and Stefan Schaal. You only demonstrate once: Category-level manipulation from single visual demonstration.RSS, 2022. 14 Learning Dexterous Manipulation Using Contact Wrench Guidance From Human Demonstration
2022
-
[44]
FoundationPose: Unified 6d pose estimation and tracking of novel objects
Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield. FoundationPose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[45]
Cari4d: Category agnostic 4d reconstruction of human-object interaction
Xianghui Xie, Bowen Wen, Yan Chang, Hesam Rabeti, Jiefeng Li, Ye Yuan, Gerard Pons-Moll, and Stan Birchfield. Cari4d: Category agnostic 4d reconstruction of human-object interaction. InConference on Computer Vision and Pattern Recognition (CVPR), June 2026
2026
-
[46]
DynHAMR: Recovering 4d interacting hand motion from a dynamic camera
Zhengdi Yu, Stefanos Zafeiriou, and Tolga Birdal. DynHAMR: Recovering 4d interacting hand motion from a dynamic camera. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27716–27726, 2025
2025
- [47]
-
[48]
Oakink2: A dataset of bimanual hands-object manipulation in complex task completion
Xinyu Zhan, Lixin Yang, Yifei Zhao, Kangrui Mao, Hanlin Xu, Zenan Lin, Kailin Li, and Cewu Lu. Oakink2: A dataset of bimanual hands-object manipulation in complex task completion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 445–456, June 2024
2024
-
[49]
Dexmachina: Functional retargeting for bimanual dexterous manipulation
Mandi Zhao, Yifan Hou, Dieter Fox, Yashraj Narang, Ajay Mandlekar, and Shuran Song. Dexmachina: Functional retargeting for bimanual dexterous manipulation. InProceedings of the Forty-Third Interna- tional Conference on Machine Learning, 2026
2026
-
[50]
Dexh2r: Task-oriented dexterous manipulation from human to robots.IEEE/ASME Transactions on Mechatronics, pages 1–12, 2025
Shuqi Zhao, Xinghao Zhu, Yuxin Chen, Chenran Li, Yichen Xie, Xiang Zhang, Mingyu Ding, and Masayoshi Tomizuka. Dexh2r: Task-oriented dexterous manipulation from human to robots.IEEE/ASME Transactions on Mechatronics, pages 1–12, 2025
2025
-
[51]
Egoscale: Scaling dexterous manipulation with diverse egocentric human data, 2026
Ruijie Zheng, Dantong Niu, Yuqi Xie, Jing Wang, Mengda Xu, Yunfan Jiang, Fernando Castañeda, Fengyuan Hu, You Liang Tan, Letian Fu, Trevor Darrell, Furong Huang, Yuke Zhu, Danfei Xu, and Linxi Fan. Egoscale: Scaling dexterous manipulation with diverse egocentric human data, 2026
2026
-
[52]
Diff-lfd: Contact-aware model-based learning from visual demonstration for robotic manipulation via differentiable physics-based simulation and rendering
Xinghao Zhu, Jinghan Ke, Zhixuan Xu, Zhixin Sun, Bizhe Bai, Jun Lv, Qingtao Liu, Yuwei Zeng, Qi Ye, Cewu Lu, Masayoshi Tomizuka, and Lin Shao. Diff-lfd: Contact-aware model-based learning from visual demonstration for robotic manipulation via differentiable physics-based simulation and rendering. In7th Annual Conference on Robot Learning, 2023. 15 Learnin...
2023
-
[53]
(ℱ1): predict the in-betweening frame count𝑇2 as described in [42], optimized with cross entropy loss on binned frame counts
-
[54]
(ℱ2): predict the global root trajectory conditioned on𝑇2, as described in [42], optimized with smooth-ℓ1loss on the ground truth root trajectory. 21 Learning Dexterous Manipulation Using Contact Wrench Guidance From Human Demonstration Pose Module Training.Given the keyframe constraints𝒯EE gt , we transform them to be root relative given the ground truth...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.