DreamPolicy: A Unified World-model Policy for Scalable Humanoid Locomotion
Pith reviewed 2026-05-19 12:46 UTC · model grok-4.3
The pith
A single humanoid policy guided by an autoregressive diffusion world model can generalize to unseen composite terrains without distillation or manual rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
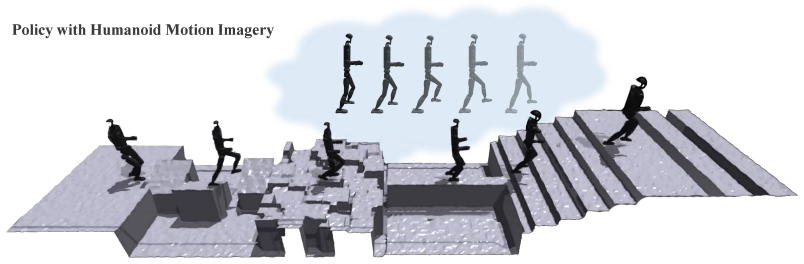
The central claim is that an autoregressive diffusion world model trained on aggregated rollouts from specialized policies can synthesize physically plausible future trajectories that serve as effective dynamic objectives for a single conditioned policy, thereby enabling robust zero-shot transfer to unseen composite terrains while naturally scaling with additional offline data.
What carries the argument
Terrain-aware autoregressive diffusion world model that generates future trajectories used as dynamic objectives for the conditioned policy.
If this is right
- A single policy can master both previously trained and entirely novel terrain combinations without explicit skill composition.
- Reward engineering is bypassed because the world model supplies the objectives directly from data.
- Performance continues to rise as the offline dataset grows because the diffusion model acquires richer locomotion patterns.
- The framework unifies world-model planning and policy learning in one loop, removing the one-task-one-policy pattern.
Where Pith is reading between the lines
- The same world-model-plus-conditioned-policy structure could be tested on manipulation or navigation tasks where composite environments also appear.
- If the diffusion model can be fine-tuned online from real-robot failures, the zero-shot transfer gap might shrink further without new simulation data.
- The approach suggests that learning a generative model of future states may be more data-efficient than distilling explicit teacher policies for high-dimensional control.
Load-bearing premise
The diffusion model trained only on rollouts from existing specialized policies will still produce trajectories that remain physically valid and useful when the policy is deployed on terrain combinations never encountered during data collection.
What would settle it
Run the trained policy on a composite terrain whose height map and friction values were withheld from both the specialized policies and the world-model training set, then measure whether the generated trajectories diverge from actual robot dynamics enough to cause frequent falls or stuck states.
Figures



read the original abstract
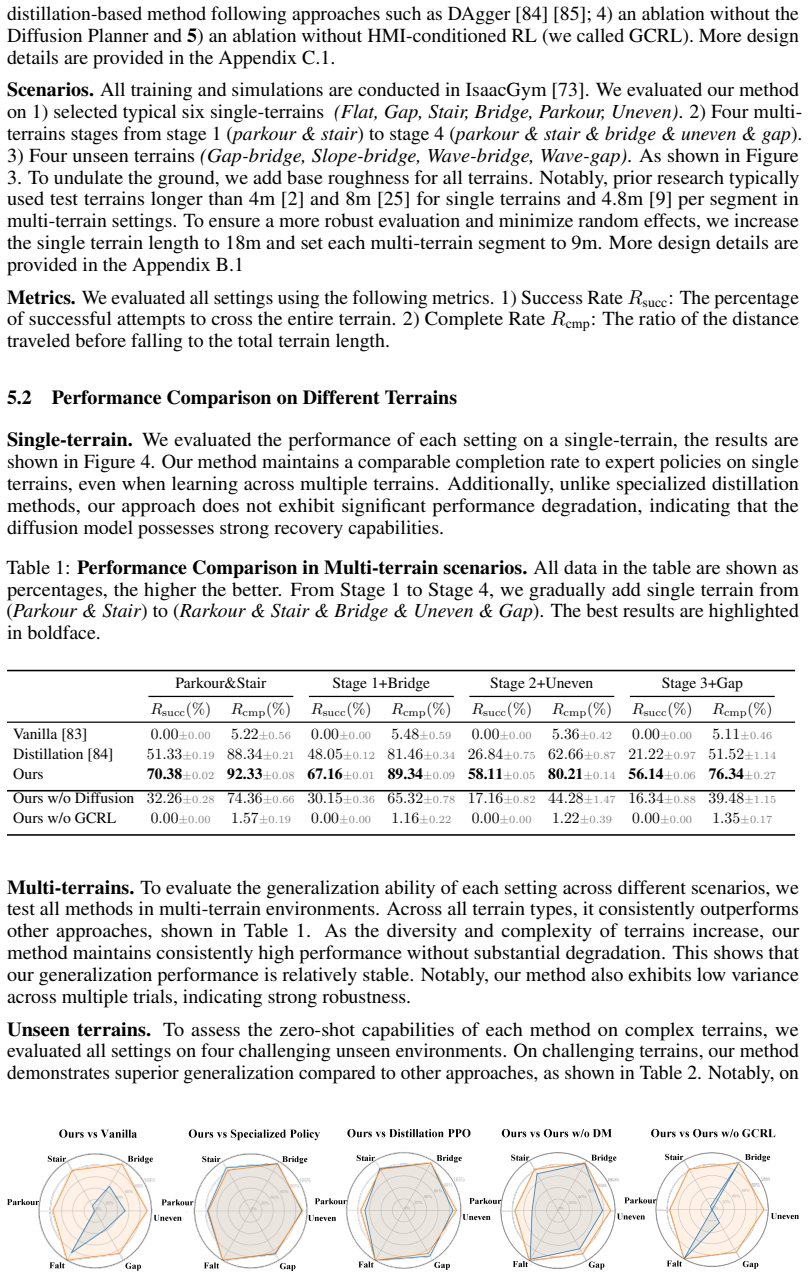
Achieving versatile humanoid locomotion with a single policy presents a critical scalability challenge. Prevailing methods often rely on distilling multiple terrain-specific teacher policies into a unified student policy. However, while such distillation captures basic locomotion primitives, it struggles to organically compose these skills to adapt to complex environments, resulting in poor generalization to novel composite terrains unseen during training. To overcome this, we present DreamPolicy, a unified framework that integrates offline data with a diffusion-based world model, enabling a single policy to master both known and unseen terrains. Central to our approach is a terrain-aware world model, driven by an autoregressive diffusion world model trained on aggregated rollouts from specialized policies. This model synthesizes physically plausible future trajectories, which serve as dynamic objectives for a conditioned policy, thereby bypassing manual reward engineering. Unlike distillation, our world model captures generalizable locomotion skills, allowing for robust zero-shot transfer to unseen composite terrains. DreamPolicy naturally scales with data availability. As the offline dataset expands, the diffusion world model continuously acquires richer skills. Experiments demonstrate that DreamPolicy outperforms the strongest baseline by up to 27\% on unseen terrains and 38\% on combined terrains. By unifying world model-based planning and policy learning, DreamPolicy breaks the "one task, one policy" bottleneck and establishes a scalable, data-driven paradigm for generalist humanoid control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents DreamPolicy, a unified framework for humanoid locomotion control that integrates offline rollouts with a terrain-aware autoregressive diffusion world model. The world model is trained on aggregated data from specialized single-terrain policies and generates future trajectories that serve as dynamic objectives for a conditioned policy, with the goal of achieving better composition of locomotion skills and robust zero-shot transfer to unseen composite terrains than distillation-based baselines. The abstract reports performance gains of up to 27% on unseen terrains and 38% on combined terrains.
Significance. If the generalization claims are substantiated, the approach could meaningfully advance scalable humanoid control by replacing per-task distillation with a data-driven world-model-plus-policy pipeline that improves with additional offline data and avoids manual reward engineering.
major comments (2)
- [Abstract] Abstract: the reported 27% and 38% gains are presented without any description of experimental protocols, baseline implementations, number of evaluation episodes, statistical significance testing, or terrain-generation procedures, preventing verification that the numbers support the central zero-shot transfer claim.
- [Method] Method section describing the diffusion world model: training occurs exclusively on aggregated rollouts from single-terrain specialized policies, yet no explicit mechanism (terrain embedding details, physics-informed loss terms, or training data containing terrain transitions) is provided to guarantee that synthesized trajectories remain physically plausible at boundaries of composite terrains.
minor comments (1)
- [Experiments] Figure captions and axis labels in the results section could be expanded to include the exact terrain parameters used for the composite test cases.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of clarity and substantiation. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 27% and 38% gains are presented without any description of experimental protocols, baseline implementations, number of evaluation episodes, statistical significance testing, or terrain-generation procedures, preventing verification that the numbers support the central zero-shot transfer claim.
Authors: We agree that the abstract would benefit from additional context to support the reported gains. Due to length constraints, we will revise the abstract to include a concise mention of the evaluation protocol (e.g., number of episodes per terrain, baseline comparisons, and terrain generation approach) while directing readers to the Experiments section for full protocols, statistical testing, and implementation details. This change will better substantiate the zero-shot transfer claims without altering the core results. revision: partial
-
Referee: [Method] Method section describing the diffusion world model: training occurs exclusively on aggregated rollouts from single-terrain specialized policies, yet no explicit mechanism (terrain embedding details, physics-informed loss terms, or training data containing terrain transitions) is provided to guarantee that synthesized trajectories remain physically plausible at boundaries of composite terrains.
Authors: The terrain-aware property is achieved by conditioning the autoregressive diffusion process on terrain embeddings derived from visual and proprioceptive observations, allowing the model to adapt predictions to upcoming terrain features. The aggregated training data includes sequences that implicitly capture transitions between terrain types encountered during single-terrain rollouts. We acknowledge that explicit discussion of boundary handling, embedding architecture, and any physics-informed regularizations was insufficient. We will expand the Method section with these details, including diagrams of the conditioning mechanism and clarification on how autoregressive generation promotes plausible transitions at composite boundaries. revision: yes
Circularity Check
No circularity: pipeline uses external offline rollouts and empirical training without definitional reduction
full rationale
The paper's core pipeline trains an autoregressive diffusion world model on aggregated rollouts collected from separate specialized policies, then conditions a policy on trajectories synthesized by that model. This structure depends on external data generation and standard supervised training rather than defining the target generalization performance in terms of the model's own fitted parameters or prior self-citations. No equation or claim reduces the zero-shot transfer result to a quantity that is true by construction; the reported gains on unseen terrains are presented as measured outcomes.
Axiom & Free-Parameter Ledger
free parameters (1)
- diffusion model training hyperparameters
axioms (1)
- domain assumption Aggregated rollouts from specialized policies contain sufficient information to train a generalizable world model for locomotion skills.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
terrain-aware autoregressive diffusion planner... synthesizes physically plausible future trajectories... HMI-conditioned policy
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DreamPolicy... scales seamlessly with more offline data... 75 million samples... six single-terrain environments
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
On the stability of anthropomorphic systems
Miomir Vukobratovi´c and Juri Stepanenko. On the stability of anthropomorphic systems. Mathematical biosciences, 15(1-2):1–37, 1972
work page 1972
-
[2]
Humanoid whole-body locomotion on narrow terrain via dynamic balance and reinforcement learning
Weiji Xie, Chenjia Bai, Jiyuan Shi, Junkai Yang, Yunfei Ge, Weinan Zhang, and Xuelong Li. Humanoid whole-body locomotion on narrow terrain via dynamic balance and reinforcement learning. arXiv preprint arXiv:2502.17219, 2025
-
[3]
Extreme parkour with legged robots
Xuxin Cheng, Kexin Shi, Ananye Agarwal, and Deepak Pathak. Extreme parkour with legged robots. In 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages 11443–11450. IEEE, 2024
work page 2024
-
[4]
Ziwen Zhuang, Zipeng Fu, Jianren Wang, Christopher Atkeson, Soeren Schwertfeger, Chelsea Finn, and Hang Zhao. Robot parkour learning. arXiv preprint arXiv:2309.05665, 2023
-
[5]
Fatemeh Zargarbashi, Jin Cheng, Dongho Kang, Robert Sumner, and Stelian Coros. Robotkeyframing: Learning locomotion with high-level objectives via mixture of dense and sparse rewards. arXiv preprint arXiv:2407.11562, 2024
-
[6]
Minimizing energy consumption leads to the emergence of gaits in legged robots
Zipeng Fu, Ashish Kumar, Jitendra Malik, and Deepak Pathak. Minimizing energy consumption leads to the emergence of gaits in legged robots. In Conference on Robot Learning (CoRL), 2021
work page 2021
-
[7]
Deep whole-body control: Learning a unified policy for manipulation and locomotion
Zipeng Fu, Xuxin Cheng, and Deepak Pathak. Deep whole-body control: Learning a unified policy for manipulation and locomotion. In Conference on Robot Learning (CoRL), 2022
work page 2022
-
[8]
Visual whole-body control for legged loco-manipulation
Minghuan Liu, Zixuan Chen, Xuxin Cheng, Yandong Ji, Rizhao Qiu, Ruihan Yang, and Xiaolong Wang. Visual whole-body control for legged loco-manipulation. The 8th Conference on Robot Learning, 2024. 10
work page 2024
-
[9]
Ziwen Zhuang, Shenzhe Yao, and Hang Zhao. Humanoid parkour learning. In 8th An- nual Conference on Robot Learning , 2024. URL https://openreview.net/forum?id= fs7ia3FqUM
work page 2024
-
[10]
Learning humanoid locomotion over challenging terrain
Ilija Radosavovic, Sarthak Kamat, Trevor Darrell, and Jitendra Malik. Learning humanoid locomotion over challenging terrain. arXiv preprint arXiv:2410.03654, 2024
-
[11]
Humanoid locomotion as next token prediction
Ilija Radosavovic, Bike Zhang, Baifeng Shi, Jathushan Rajasegaran, Sarthak Kamat, Trevor Darrell, Koushil Sreenath, and Jitendra Malik. Humanoid locomotion as next token prediction. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[12]
Rhino: Learning real-time humanoid-human- object interaction from human demonstrations
Jingxiao Chen, Xinyao Li, Jiahang Cao, Zhengbang Zhu, Wentao Dong, Minghuan Liu, Ying Wen, Yong Yu, Liqing Zhang, and Weinan Zhang. Rhino: Learning real-time humanoid-human- object interaction from human demonstrations. arXiv preprint arXiv:2502.13134, 2025
-
[13]
Zhaoyuan Gu, Junheng Li, Wenlan Shen, Wenhao Yu, Zhaoming Xie, Stephen McCrory, Xianyi Cheng, Abdulaziz Shamsah, Robert Griffin, C Karen Liu, et al. Humanoid locomotion and manipulation: Current progress and challenges in control, planning, and learning. arXiv preprint arXiv:2501.02116, 2025
-
[14]
Open-television: Teleop- eration with immersive active visual feedback
Xuxin Cheng, Jialong Li, Shiqi Yang, Ge Yang, and Xiaolong Wang. Open-television: Teleop- eration with immersive active visual feedback. arXiv preprint arXiv:2407.01512, 2024
-
[15]
Expres- sive whole-body control for humanoid robots
Xuxin Cheng, Yandong Ji, Junming Chen, Ruihan Yang, Ge Yang, and Xiaolong Wang. Expres- sive whole-body control for humanoid robots. arXiv preprint arXiv:2402.16796, 2024
-
[16]
Humanplus: Humanoid shadowing and imitation from humans
Zipeng Fu, Qingqing Zhao, Qi Wu, Gordon Wetzstein, and Chelsea Finn. Humanplus: Hu- manoid shadowing and imitation from humans. arXiv preprint arXiv:2406.10454, 2024
-
[17]
Hover: Versatile neural whole-body controller for humanoid robots,
Tairan He, Wenli Xiao, Toru Lin, Zhengyi Luo, Zhenjia Xu, Zhenyu Jiang, Changliu Liu, Guanya Shi, Xiaolong Wang, Linxi Fan, and Yuke Zhu. Hover: Versatile neural whole-body controller for humanoid robots. arXiv preprint arXiv:2410.21229, 2024
-
[18]
A unified and general humanoid whole-body controller for fine-grained locomotion
Yufei Xue, Wentao Dong, Minghuan Liu, Weinan Zhang, and Jiangmiao Pang. A unified and general humanoid whole-body controller for fine-grained locomotion. In Robotics: Science and Systems (RSS), 2025
work page 2025
-
[19]
Flam: Foundation model-based body stabilization for humanoid locomotion and manipulation
Xianqi Zhang, Hongliang Wei, Wenrui Wang, Xingtao Wang, Xiaopeng Fan, and Debin Zhao. Flam: Foundation model-based body stabilization for humanoid locomotion and manipulation. arXiv preprint arXiv:2503.22249, 2025
-
[20]
Nil: No-data imitation learning by leveraging pre-trained video diffusion models
Mert Albaba, Chenhao Li, Markos Diomataris, Omid Taheri, Andreas Krause, and Michael Black. Nil: No-data imitation learning by leveraging pre-trained video diffusion models. arXiv preprint arXiv:2503.10626, 2025
-
[21]
Whole-body humanoid robot locomotion with human reference
Qiang Zhang, Peter Cui, David Yan, Jingkai Sun, Yiqun Duan, Gang Han, Wen Zhao, Weining Zhang, Yijie Guo, Arthur Zhang, et al. Whole-body humanoid robot locomotion with human reference. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11225–11231. IEEE, 2024
work page 2024
-
[22]
Learning human-to-humanoid real-time whole-body teleoperation
Tairan He, Zhengyi Luo, Wenli Xiao, Chong Zhang, Kris Kitani, Changliu Liu, and Guanya Shi. Learning human-to-humanoid real-time whole-body teleoperation. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8944–8951. IEEE, 2024
work page 2024
-
[23]
Harmon: Whole- body motion generation of humanoid robots from language descriptions
Zhenyu Jiang, Yuqi Xie, Jinhan Li, Ye Yuan, Yifeng Zhu, and Yuke Zhu. Harmon: Whole- body motion generation of humanoid robots from language descriptions. arXiv preprint arXiv:2410.12773, 2024
-
[24]
Dynamic locomotion on slippery ground
Fabian Jenelten, Jemin Hwangbo, Fabian Tresoldi, C Dario Bellicoso, and Marco Hutter. Dynamic locomotion on slippery ground. IEEE Robotics and Automation Letters, 4(4):4170– 4176, 2019. 11
work page 2019
-
[25]
BeamDojo: Learning agile humanoid locomotion on sparse footholds
Huayi Wang, Zirui Wang, Junli Ren, Qingwei Ben, Tao Huang, Weinan Zhang, and Jiangmiao Pang. BeamDojo: Learning agile humanoid locomotion on sparse footholds. In Robotics: Science and Systems (RSS), 2025
work page 2025
-
[26]
Vb-com: Learning vision-blind composite humanoid locomotion against deficient perception
Junli Ren, Tao Huang, Huayi Wang, Zirui Wang, Qingwei Ben, Jiangmiao Pang, and Ping Luo. Vb-com: Learning vision-blind composite humanoid locomotion against deficient perception. arXiv preprint arXiv:2502.14814, 2025
-
[27]
Advancing humanoid locomotion: Mastering challenging terrains with denoising world model learning
Xinyang Gu, Yen-Jen Wang, Xiang Zhu, Chengming Shi, Yanjiang Guo, Yichen Liu, and Jianyu Chen. Advancing humanoid locomotion: Mastering challenging terrains with denoising world model learning. arXiv preprint arXiv:2408.14472, 2024
-
[28]
Learning humanoid locomotion with perceptive internal model, 2024
Junfeng Long, Junli Ren, Moji Shi, Zirui Wang, Tao Huang, Ping Luo, and Jiangmiao Pang. Learning humanoid locomotion with perceptive internal model, 2024. URL https://arxiv. org/abs/2411.14386
-
[29]
Qiang Zhang, Gang Han, Jingkai Sun, Wen Zhao, Chenghao Sun, Jiahang Cao, Jiaxu Wang, Yijie Guo, and Renjing Xu. Distillation-ppo: A novel two-stage reinforcement learning framework for humanoid robot perceptive locomotion. arXiv preprint arXiv:2503.08299, 2025
-
[30]
Learning perceptive humanoid locomotion over challenging terrain
Wandong Sun, Baoshi Cao, Long Chen, Yongbo Su, Yang Liu, Zongwu Xie, and Hong Liu. Learning perceptive humanoid locomotion over challenging terrain. arXiv preprint arXiv:2503.00692, 2025
-
[31]
Teacher motion priors: Enhancing robot locomotion over challenging terrain
Fangcheng Jin, Yuqi Wang, Peixin Ma, Guodong Yang, Pan Zhao, En Li, and Zhengtao Zhang. Teacher motion priors: Enhancing robot locomotion over challenging terrain. arXiv preprint arXiv:2504.10390, 2025
-
[32]
Omnih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning
Tairan He, Zhengyi Luo, Xialin He, Wenli Xiao, Chong Zhang, Weinan Zhang, Kris Kitani, Changliu Liu, and Guanya Shi. Omnih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning. arXiv preprint arXiv:2406.08858, 2024
-
[33]
Amass: Archive of motion capture as surface shapes
Naureen Mahmood, Nima Ghorbani, Nikolaus F Troje, Gerard Pons-Moll, and Michael J Black. Amass: Archive of motion capture as surface shapes. In Proceedings of the IEEE/CVF international conference on computer vision, pages 5442–5451, 2019
work page 2019
-
[34]
Deep reinforcement learning for bipedal locomotion: A brief survey
Lingfan Bao, Joseph Humphreys, Tianhu Peng, and Chengxu Zhou. Deep reinforcement learning for bipedal locomotion: A brief survey. arXiv preprint arXiv:2404.17070, 2024
-
[35]
Scaling cross- embodied learning: One policy for manipulation, navigation, locomotion and aviation
Ria Doshi, Homer Walke, Oier Mees, Sudeep Dasari, and Sergey Levine. Scaling cross- embodied learning: One policy for manipulation, navigation, locomotion and aviation. arXiv preprint arXiv:2408.11812, 2024
-
[36]
Skill transfer in deep reinforcement learning under morpho- logical heterogeneity
Yang Hu and Giovanni Montana. Skill transfer in deep reinforcement learning under morpho- logical heterogeneity. arXiv preprint arXiv:1908.05265, 2019
-
[37]
Transfer deep reinforcement learning in 3d environments: An empirical study
Devendra Singh Chaplot, Guillaume Lample, Kanthashree Mysore Sathyendra, and Ruslan Salakhutdinov. Transfer deep reinforcement learning in 3d environments: An empirical study. In NIPS deep reinforcemente leaning workshop, volume 138, 2016
work page 2016
-
[38]
One policy to control them all: Shared modular policies for agent-agnostic control
Wenlong Huang, Igor Mordatch, and Deepak Pathak. One policy to control them all: Shared modular policies for agent-agnostic control. In International Conference on Machine Learning, pages 4455–4464. PMLR, 2020
work page 2020
-
[39]
Bo Ai, Liu Dai, Nico Bohlinger, Dichen Li, Tongzhou Mu, Zhanxin Wu, K. Fay, Henrik I. Christensen, Jan Peters, and Hao Su. Towards embodiment scaling laws in robot locomotion,
- [40]
-
[41]
One policy to run them all: an end-to-end learning approach to multi-embodiment locomotion
Nico Bohlinger, Grzegorz Czechmanowski, Maciej Krupka, Piotr Kicki, Krzysztof Walas, Jan Peters, and Davide Tateo. One policy to run them all: an end-to-end learning approach to multi-embodiment locomotion. arXiv preprint arXiv:2409.06366, 2024
-
[42]
Get-zero: Graph embodiment transformer for zero-shot embodi- ment generalization
Austin Patel and Shuran Song. Get-zero: Graph embodiment transformer for zero-shot embodi- ment generalization. arXiv preprint arXiv:2407.15002, 2024. 12
-
[43]
Genloco: Generalized locomotion controllers for quadrupedal robots
Gilbert Feng, Hongbo Zhang, Zhongyu Li, Xue Bin Peng, Bhuvan Basireddy, Linzhu Yue, Zhitao Song, Lizhi Yang, Yunhui Liu, Koushil Sreenath, et al. Genloco: Generalized locomotion controllers for quadrupedal robots. In Conference on Robot Learning, pages 1893–1903. PMLR, 2023
work page 1903
-
[44]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy. arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[47]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choro- manski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-language- action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[49]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[50]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021
work page 2021
-
[51]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. Advances in Neural Information Processing Systems, 35:8633–8646, 2022
work page 2022
-
[52]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22563–22575, 2023
work page 2023
-
[53]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, page 02783649241273668, 2023
work page 2023
-
[54]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. In Proceedings of Robotics: Science and Systems (RSS), 2024
work page 2024
-
[55]
Planning with diffusion for flexible behavior synthesis
Michael Janner, Yilun Du, Joshua Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. In International Conference on Machine Learning , pages 9902–9915. PMLR, 2022
work page 2022
-
[56]
AffordDP: Generalizable diffusion policy with transferable affordance
Shijie Wu, Yihang Zhu, Yunao Huang, Kaizhen Zhu, Jiayuan Gu, Jingyi Yu, Ye Shi, and Jingya Wang. AffordDP: Generalizable diffusion policy with transferable affordance. arXiv preprint arXiv:2412.03142, 2024
-
[57]
Diffusion policies as an expressive policy class for offline reinforcement learning
Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[58]
Efficient diffusion policies for offline reinforcement learning
Bingyi Kang, Xiao Ma, Chao Du, Tianyu Pang, and Shuicheng Yan. Efficient diffusion policies for offline reinforcement learning. Advances in Neural Information Processing Systems, 36: 67195–67212, 2023. 13
work page 2023
-
[59]
Diffusion-dice: In-sample diffusion guidance for offline reinforcement learning
Liyuan Mao, Haoran Xu, Xianyuan Zhan, Weinan Zhang, and Amy Zhang. Diffusion-dice: In-sample diffusion guidance for offline reinforcement learning. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[60]
Policy representation via diffusion probability model for reinforcement learning
Long Yang, Zhixiong Huang, Fenghao Lei, Yucun Zhong, Yiming Yang, Cong Fang, Shiting Wen, Binbin Zhou, and Zhouchen Lin. Policy representation via diffusion probability model for reinforcement learning. arXiv preprint arXiv:2305.13122, 2023
-
[61]
Learning a diffusion model policy from rewards via q-score matching
Michael Psenka, Alejandro Escontrela, Pieter Abbeel, and Yi Ma. Learning a diffusion model policy from rewards via q-score matching. In International Conference on Machine Learning, pages 41163–41182. PMLR, 2024
work page 2024
-
[62]
Diffusion-based reinforcement learning via q-weighted variational policy optimization
Shutong Ding, Ke Hu, Zhenhao Zhang, Kan Ren, Weinan Zhang, Jingyi Yu, Jingya Wang, and Ye Shi. Diffusion-based reinforcement learning via q-weighted variational policy optimization. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[63]
Diffusion-vla: Scaling robot foundation models via unified diffusion and autoregression
Junjie Wen, Minjie Zhu, Yichen Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Chengmeng Li, Xiaoyu Liu, Yaxin Peng, Chaomin Shen, et al. Diffusion-vla: Scaling robot foundation models via unified diffusion and autoregression. arXiv preprint arXiv:2412.03293, 2024
-
[64]
Boosting continuous control with consistency policy
Yuhui Chen, Haoran Li, and Dongbin Zhao. Boosting continuous control with consistency policy. In Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, pages 335–344, 2024
work page 2024
-
[65]
HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, et al. Hybridvla: Collaborative diffusion and autoregression in a unified vision-language-action model. arXiv preprint arXiv:2503.10631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
CLoSD: Closing the loop between simulation and diffusion for multi-task character control
Guy Tevet, Sigal Raab, Setareh Cohan, Daniele Reda, Zhengyi Luo, Xue Bin Peng, Amit H Bermano, and Michiel van de Panne. CLoSD: Closing the loop between simulation and diffusion for multi-task character control. arXiv preprint arXiv:2410.03441, 2024
-
[67]
Dartcontrol: A diffusion-based autoregressive motion model for real-time text-driven motion control
Kaifeng Zhao, Gen Li, and Siyu Tang. Dartcontrol: A diffusion-based autoregressive motion model for real-time text-driven motion control. In The Thirteenth International Conference on Learning Representations, 2024
work page 2024
-
[68]
Motion planning diffusion: Learning and planning of robot motions with diffusion models
Joao Carvalho, An T Le, Mark Baierl, Dorothea Koert, and Jan Peters. Motion planning diffusion: Learning and planning of robot motions with diffusion models. In 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1916–1923. IEEE, 2023
work page 2023
-
[69]
Dipper: Diffusion-based 2d path planner applied on legged robots
Jianwei Liu, Maria Stamatopoulou, and Dimitrios Kanoulas. Dipper: Diffusion-based 2d path planner applied on legged robots. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 9264–9270. IEEE, 2024
work page 2024
-
[70]
DiffuseLoco: Real-time legged locomotion control with diffusion from offline datasets
Xiaoyu Huang, Yufeng Chi, Ruofeng Wang, Zhongyu Li, Xue Bin Peng, Sophia Shao, Borivoje Nikolic, and Koushil Sreenath. DiffuseLoco: Real-time legged locomotion control with diffusion from offline datasets. In 8th Annual Conference on Robot Learning, 2024
work page 2024
-
[71]
Birodiff: Diffusion policies for bipedal robot locomotion on unseen terrains
GVS Mothish, Manan Tayal, and Shishir Kolathaya. Birodiff: Diffusion policies for bipedal robot locomotion on unseen terrains. arXiv preprint arXiv:2407.05424, 2024
-
[72]
Discovery of skill switching criteria for learning agile quadruped locomotion
Wanming Yu, Fernando Acero, Vassil Atanassov, Chuanyu Yang, Ioannis Havoutis, Dimitrios Kanoulas, and Zhibin Li. Discovery of skill switching criteria for learning agile quadruped locomotion. arXiv preprint arXiv:2502.06676, 2025
-
[73]
Preference aligned diffusion planner for quadrupedal locomotion control
Xinyi Yuan, Zhiwei Shang, Zifan Wang, Chenkai Wang, Zhao Shan, Meixin Zhu, Chenjia Bai, Xuelong Li, Weiwei Wan, and Kensuke Harada. Preference aligned diffusion planner for quadrupedal locomotion control. arXiv preprint arXiv:2410.13586, 2024
-
[74]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning. arXiv preprint arXiv:2108.10470, 2021. 14
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[75]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[76]
Amp: Adversarial motion priors for stylized physics-based character control
Xue Bin Peng, Ze Ma, Pieter Abbeel, Sergey Levine, and Angjoo Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control. ACM Transactions on Graphics (ToG), 40(4):1–20, 2021
work page 2021
-
[77]
Is Conditional Generative Modeling all you need for Decision-Making?
Anurag Ajay, Yilun Du, Abhi Gupta, Joshua Tenenbaum, Tommi Jaakkola, and Pulkit Agrawal. Is conditional generative modeling all you need for decision-making? arXiv preprint arXiv:2211.15657, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[78]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021
work page 2021
-
[79]
Scheduled sampling for sequence prediction with recurrent neural networks
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks. Advances in neural information processing systems, 28, 2015
work page 2015
-
[80]
Learning physically simulated tennis skills from broadcast videos
Ye Yuan, Viktor Makoviychuk, Y Guo, S Fidler, XB Peng, and K Fatahalian. Learning physically simulated tennis skills from broadcast videos. ACM Trans. Graph, 42(4), 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.