Recognition: unknown
ComSim: Building Scalable Real-World Robot Data Generation via Compositional Simulation
Pith reviewed 2026-05-10 16:07 UTC · model grok-4.3
The pith
Compositional Simulation generates large-scale realistic robot training data from limited real examples by combining classical simulation with a neural video transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
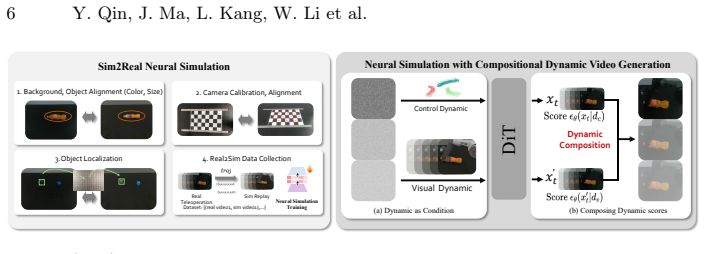
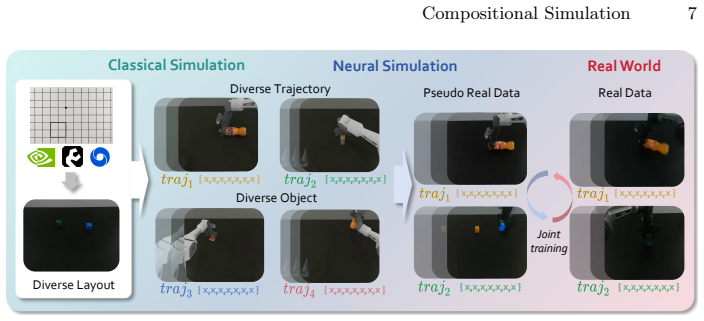
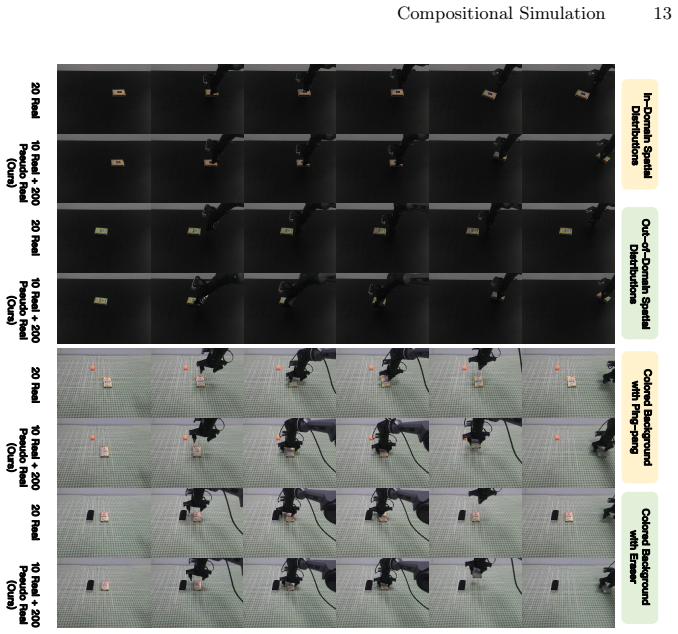
ComSim combines classical simulation for generating diverse action sequences with a neural simulator that converts those sequences into real-world visual representations. A closed-loop real-sim-real augmentation pipeline starts from a small real dataset, produces large quantities of consistent action-video pairs, and feeds them into policy training, yielding higher success rates for models operating in actual robot environments.
What carries the argument
The closed-loop real-sim-real data augmentation pipeline in which a neural simulator learns to render classical simulation videos as realistic footage while preserving action details.
If this is right
- Policies trained on the generated data achieve higher success rates when deployed on physical robots because the domain gap is reduced.
- The method produces training sets that cover more environmental variation than could be recorded directly from limited real-world effort.
- Data volume can grow through simulation without requiring matching increases in physical data collection time or cost.
- The same pipeline supports training of more capable robot policies for complex tasks that need broad scenario coverage.
Where Pith is reading between the lines
- The approach could extend to generating training data for multi-step manipulation tasks where scenario diversity is especially hard to capture in reality.
- If the neural conversion step generalizes across robot platforms, it might lower the amount of real data needed when switching to new hardware.
- The pipeline offers a route to improve world models for robotics by supplying them with larger volumes of consistent real-looking video.
Load-bearing premise
The neural simulator can convert classical simulation videos into real-world appearances without introducing visual artifacts or distorting the motion information required for policy learning.
What would settle it
Real-world robot experiments in which policies trained on the generated datasets show no improvement in task success rates compared with policies trained only on classical simulation or the original small real dataset.
Figures









read the original abstract
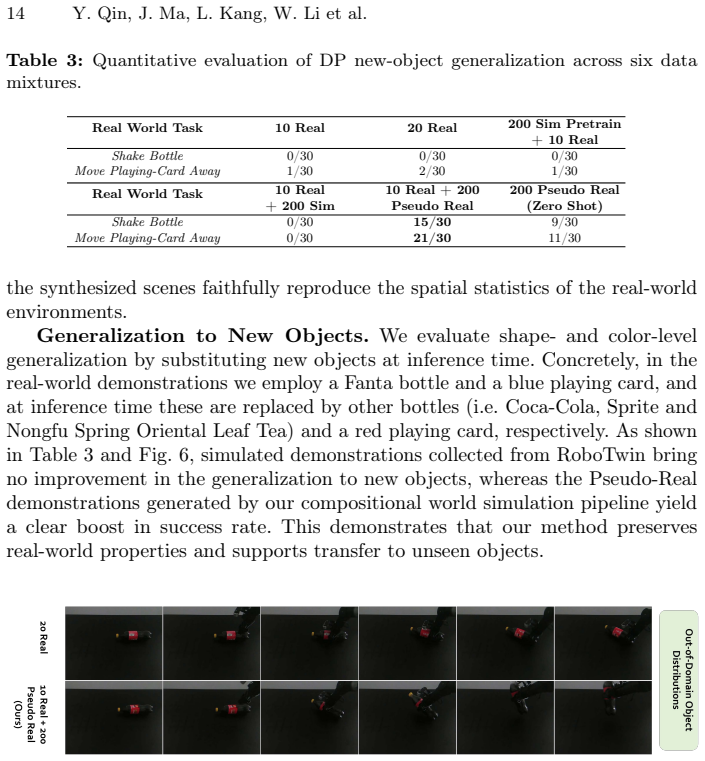
Recent advancements in foundational models, such as large language models and world models, have greatly enhanced the capabilities of robotics, enabling robots to autonomously perform complex tasks. However, acquiring large-scale, high-quality training data for robotics remains a challenge, as it often requires substantial manual effort and is limited in its coverage of diverse real-world environments. To address this, we propose a novel hybrid approach called Compositional Simulation, which combines classical simulation and neural simulation to generate accurate action-video pairs while maintaining real-world consistency. Our approach utilizes a closed-loop real-sim-real data augmentation pipeline, leveraging a small amount of real-world data to generate diverse, large-scale training datasets that cover a broader spectrum of real-world scenarios. We train a neural simulator to transform classical simulation videos into real-world representations, improving the accuracy of policy models trained in real-world environments. Through extensive experiments, we demonstrate that our method significantly reduces the sim2real domain gap, resulting in higher success rates in real-world policy model training. Our approach offers a scalable solution for generating robust training data and bridging the gap between simulated and real-world robotics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ComSim, a hybrid compositional simulation method that combines classical simulation with a neural simulator trained on a small amount of real-world data. It employs a closed-loop real-sim-real data augmentation pipeline to generate large-scale, diverse action-video pairs that aim to cover broader real-world scenarios, claiming this reduces the sim2real domain gap and yields higher success rates for real-world robot policy training based on extensive experiments.
Significance. If the neural simulator accurately transforms simulation videos while preserving action trajectories, physics, and semantics without artifacts, the approach could provide a practical, scalable route to augment limited real robot data and improve sim2real transfer. The closed-loop pipeline is a constructive element that could support iterative refinement.
major comments (2)
- [Abstract] Abstract: the central claims that the method 'significantly reduces the sim2real domain gap' and produces 'higher success rates in real-world policy model training' are asserted without any quantitative results, baselines, statistical tests, or error analysis, leaving the empirical contribution unsupported.
- [Method and Experiments] Method/Experiments: no implementation details, neural simulator architecture, training procedure, or fidelity metrics (e.g., action reconstruction error, optical-flow consistency, or policy-ablation deltas) are supplied to verify that the transformation preserves underlying action trajectories and dynamics, which is load-bearing for the claim that generated data improves rather than degrades downstream policies.
minor comments (1)
- [Abstract] The term 'Compositional Simulation' is used throughout but its precise compositional structure (how classical and neural components are combined at the data-generation level) is not formally defined or contrasted with prior hybrid simulation work.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We appreciate the constructive feedback and will revise the manuscript to address the concerns raised regarding the abstract and the method/experiments sections.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that the method 'significantly reduces the sim2real domain gap' and produces 'higher success rates in real-world policy model training' are asserted without any quantitative results, baselines, statistical tests, or error analysis, leaving the empirical contribution unsupported.
Authors: We agree with this observation. While the experiments section contains quantitative results supporting these claims, the abstract does not include specific numbers or references to baselines. In the revised manuscript, we will update the abstract to incorporate key quantitative findings, such as the percentage reduction in domain gap and success rate improvements with statistical details, to better support the empirical contributions. revision: yes
-
Referee: [Method and Experiments] Method/Experiments: no implementation details, neural simulator architecture, training procedure, or fidelity metrics (e.g., action reconstruction error, optical-flow consistency, or policy-ablation deltas) are supplied to verify that the transformation preserves underlying action trajectories and dynamics, which is load-bearing for the claim that generated data improves rather than degrades downstream policies.
Authors: We acknowledge that additional details are necessary to substantiate the claims. The current version provides an overview but lacks the requested specifics. We will revise the Method and Experiments sections to include the neural simulator's architecture, detailed training procedure, and fidelity metrics including action reconstruction error, optical-flow consistency checks, and policy ablation studies with performance deltas. This will demonstrate that the data generation preserves trajectories and dynamics and improves policy performance. revision: yes
Circularity Check
No circularity: high-level empirical pipeline with no derivations or self-referential fits
full rationale
The provided abstract and description contain no equations, parameter fits, uniqueness theorems, or derivation chains. The method is described as a closed-loop data augmentation pipeline trained on real data to generate simulated-to-real videos, with success claimed via downstream experiments. No load-bearing step reduces to its own inputs by construction, self-citation, or renaming. This matches the default case of a self-contained empirical claim whose validity rests on external validation rather than internal redefinition.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Compositional Simulation
no independent evidence
Reference graph
Works this paper leans on
-
[2]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y., Fox, D., Hu, F., Huang, S., et al.: Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734 (2025)
work page internal anchor Pith review arXiv 2025
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:pi_0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review arXiv 2023
-
[5]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Chen, X., Choromanski, K., Ding, T., Driess, D., Dubey, A., Finn, C., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818 (2023)
work page internal anchor Pith review arXiv 2023
-
[7]
RT-1: Robotics Transformer for Real-World Control at Scale
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakr- ishnan, K., Hausman, K., Herzog, A., Hsu, J., et al.: Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817 (2022)
work page internal anchor Pith review arXiv 2022
-
[8]
In: ICML (2024)
Bruce, J., Dennis, M.D., Edwards, A., Parker-Holder, J., Shi, Y., Hughes, E., Lai, M., Mavalankar, A., Steigerwald, R., Apps, C., et al.: Genie: Generative interactive environments. In: ICML (2024)
2024
-
[9]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Cheang, C.L., Chen, G., Jing, Y., Kong, T., Li, H., Li, Y., Liu, Y., Wu, H., Xu, J., Yang, Y., et al.: Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation. arXiv preprint arXiv:2410.06158 (2024)
work page internal anchor Pith review arXiv 2024
-
[10]
Chen, T., Chen, Z., Chen, B., Cai, Z., Liu, Y., Liang, Q., Li, Z., Lin, X., Ge, Y., Gu, Z., et al.: Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation. arXiv preprint arXiv:2506.18088 (2025)
work page internal anchor Pith review arXiv 2025
-
[11]
Urdformer: A pipeline for con- structing articulated simulation environments from real-world images,
Chen, Z., Walsman, A., Memmel, M., Mo, K., Fang, A., Vemuri, K., Wu, A., Fox, D., Gupta, A.: Urdformer: A pipeline for constructing articulated simulation environments from real-world images. arXiv preprint arXiv:2405.11656 (2024)
-
[12]
The International Journal of Robotics Research p
Chi, C., Xu, Z., Feng, S., Cousineau, E., Du, Y., Burchfiel, B., Tedrake, R., Song, S.: Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research p. 02783649241273668 (2023)
2023
-
[13]
arXiv preprint arXiv:2410.07408 (2024) 16 Y
Dai, T., Wong, J., Jiang, Y., Wang, C., Gokmen, C., Zhang, R., Wu, J., Fei-Fei, L.: Automated creation of digital cousins for robust policy learning. arXiv preprint arXiv:2410.07408 (2024) 16 Y. Qin, J. Ma, L. Kang, W. Li et al
-
[14]
Advances in neural information processing systems36, 9156–9172 (2023)
Du, Y., Yang, S., Dai, B., Dai, H., Nachum, O., Tenenbaum, J., Schuurmans, D., Abbeel, P.: Learning universal policies via text-guided video generation. Advances in neural information processing systems36, 9156–9172 (2023)
2023
-
[15]
In: The Eleventh International Conference on Learning Representations (2023)
Gu, J., Xiang, F., Li, X., Ling, Z., Liu, X., Mu, T., Tang, Y., Tao, S., Wei, X., Yao, Y., et al.: Maniskill2: A unified benchmark for generalizable manipulation skills. In: The Eleventh International Conference on Learning Representations (2023)
2023
-
[16]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Hessel, J., Holtzman, A., Forbes, M., Bras, R.L., Choi, Y.: Clipscore: A reference-free evaluation metric for image captioning. arXiv preprint arXiv:2104.08718 (2021)
work page internal anchor Pith review arXiv 2021
-
[17]
Advances in neural information processing systems30(2017)
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[18]
3d diffuser actor: Policy diffusion with 3d scene representations, 2024
Ke, T.W., Gkanatsios, N., Fragkiadaki, K.: 3d diffuser actor: Policy diffusion with 3d scene representations. arXiv preprint arXiv:2402.10885 (2024)
-
[19]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Kim, M.J., Finn, C., Liang, P.: Fine-tuning vision-language-action models: Opti- mizing speed and success. arXiv preprint arXiv:2502.19645 (2025)
work page internal anchor Pith review arXiv 2025
-
[20]
In: 8th Annual Conference on Robot Learning
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E.P., Sanketi, P.R., Vuong, Q., et al.: Openvla: An open-source vision- language-action model. In: 8th Annual Conference on Robot Learning
- [21]
-
[22]
arXiv (2017)
Kolve, E., Mottaghi, R., Han, W., VanderBilt, E., Weihs, L., Herrasti, A., Gordon, D., Zhu, Y., Gupta, A., Farhadi, A.: AI2-THOR: An Interactive 3D Environment for Visual AI. arXiv (2017)
2017
-
[23]
In: 6th Annual Conference on Robot Learning (2022), https://openreview.net/forum?id=_8DoIe8G3t
Li, C., Zhang, R., Wong, J., Gokmen, C., Srivastava, S., Martín-Martín, R., Wang, C., Levine, G., Lingelbach, M., Sun, J., Anvari, M., Hwang, M., Sharma, M., Aydin, A., Bansal, D., Hunter, S., Kim, K.Y., Lou, A., Matthews, C.R., Villa-Renteria, I., Tang, J.H., Tang, C., Xia, F., Savarese, S., Gweon, H., Liu, K., Wu, J., Fei-Fei, L.: BEHAVIOR-1k: A benchma...
2022
-
[24]
Li, Q., Liang, Y., Wang, Z., Luo, L., Chen, X., Liao, M., Wei, F., Deng, Y., Xu, S., Zhang, Y., et al.: Cogact: A foundational vision-language-action model for synergiz- ing cognition and action in robotic manipulation. arXiv preprint arXiv:2411.19650 (2024)
work page Pith review arXiv 2024
-
[25]
In: International Conference on Machine Learning
Liang, Z., Mu, Y., Ding, M., Ni, F., Tomizuka, M., Luo, P.: Adaptdiffuser: Diffusion models as adaptive self-evolving planners. In: International Conference on Machine Learning. pp. 20725–20745. PMLR (2023)
2023
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liang, Z., Mu, Y., Ma, H., Tomizuka, M., Ding, M., Luo, P.: Skilldiffuser: Inter- pretable hierarchical planning via skill abstractions in diffusion-based task execution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16467–16476 (2024)
2024
-
[27]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liang, Z., Mu, Y., Wang, Y., Chen, T., Shao, W., Zhan, W., Tomizuka, M., Luo, P., Ding, M.: Dexhanddiff: Interaction-aware diffusion planning for adaptive dexterous manipulation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1745–1755 (2025)
2025
-
[28]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Liu, S., Wu, L., Li, B., Tan, H., Chen, H., Wang, Z., Xu, K., Su, H., Zhu, J.: Rdt-1b: a diffusion foundation model for bimanual manipulation. arXiv preprint arXiv:2410.07864 (2024) Compositional Simulation 17
work page internal anchor Pith review arXiv 2024
-
[29]
IEEE Robotics and Automation Letters (2023)
Lynch, C., Wahid, A., Tompson, J., Ding, T., Betker, J., Baruch, R., Armstrong, T., Florence, P.: Interactive language: Talking to robots in real time. IEEE Robotics and Automation Letters (2023)
2023
-
[30]
In: Vanschoren, J., Yeung, S
Makoviychuk, V., Wawrzyniak, L., Guo, Y., Lu, M., Storey, K., Macklin, M., Hoeller, D., Rudin, N., Allshire, A., Handa, A., State, G.: Isaac gym: High performance GPU based physics simulation for robot learning. In: Vanschoren, J., Yeung, S. (eds.) Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Dataset...
2021
-
[31]
In: 7th Annual Conference on Robot Learning (2023)
Mandlekar, A., Nasiriany, S., Wen, B., Akinola, I., Narang, Y., Fan, L., Zhu, Y., Fox, D.: Mimicgen: A data generation system for scalable robot learning using human demonstrations. In: 7th Annual Conference on Robot Learning (2023)
2023
-
[32]
RoboTwin: Dual-arm robot benchmark with generative digital twins.arXiv preprint arXiv:2409.02920,
Mu, Y., Chen, T., Peng, S., Chen, Z., Gao, Z., Zou, Y., Lin, L., Xie, Z., Luo, P.: Robotwin: Dual-arm robot benchmark with generative digital twins (early version). arXiv preprint arXiv:2409.02920 (2024)
-
[33]
In: Robotics: Science and Systems (RSS) (2024)
Nasiriany, S., Maddukuri, A., Zhang, L., Parikh, A., Lo, A., Joshi, A., Mandlekar, A., Zhu, Y.: Robocasa: Large-scale simulation of everyday tasks for generalist robots. In: Robotics: Science and Systems (RSS) (2024)
2024
-
[34]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA: Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575 (2025)
work page internal anchor Pith review arXiv 2025
-
[35]
In: Proceedings of Robotics: Science and Systems
Octo Model Team, Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Xu, C., Luo, J., Kreiman, T., Tan, Y., Chen, L.Y., Sanketi, P., Vuong, Q., Xiao, T., Sadigh, D., Finn, C., Levine, S.: Octo: An open-source generalist robot policy. In: Proceedings of Robotics: Science and Systems. Delft, Netherlands (2024)
2024
-
[36]
OpenAI: Creating video from text.https://openai.com/index/sora/(2024)
2024
-
[37]
OpenAI: Gpt-5 system card (updated august 13, 2025).https://cdn.openai.com/ pdf/8124a3ce- ab78- 4f06- 96eb- 49ea29ffb52f/gpt5- system- card- aug7.pdf (Aug 2025)
2025
-
[38]
arXiv preprint arXiv:2503.16408 (2025)
Qin, Y., Kang, L., Song, X., Yin, Z., Liu, X., Liu, X., Zhang, R., Bai, L.: Robofactory: Exploring embodied agent collaboration with compositional constraints. arXiv preprint arXiv:2503.16408 (2025)
-
[39]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[40]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. CoRRabs/1707.06347(2017), http://arxiv.org/abs/ 1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
In: Advances in Neural Information Processing Systems (NeurIPS) (2021)
Szot, A., Clegg, A., Undersander, E., Wijmans, E., Zhao, Y., Turner, J., Maestre, N., Mukadam, M., Chaplot, D., Maksymets, O., Gokaslan, A., Vondrus, V., Dharur, S., Meier, F., Galuba, W., Chang, A., Kira, Z., Koltun, V., Malik, J., Savva, M., Batra, D.: Habitat 2.0: Training home assistants to rearrange their habitat. In: Advances in Neural Information P...
2021
-
[42]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Wu, Y., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Todorov, E., Erez, T., Tassa, Y.: Mujoco: A physics engine for model-based control. In: 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. pp. 5026–5033. IEEE (2012).https://doi.org/10.1109/IROS.2012.6386109 18 Y. Qin, J. Ma, L. Kang, W. Li et al
-
[44]
Reconciling reality through simulation: A real- to-sim-to-real approach for robust manipulation,
Torne, M., Simeonov, A., Li, Z., Chan, A., Chen, T., Gupta, A., Agrawal, P.: Reconciling reality through simulation: A real-to-sim-to-real approach for robust manipulation. arXiv preprint arXiv:2403.03949 (2024)
-
[45]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717 (2018)
work page internal anchor Pith review arXiv 2018
-
[47]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
In: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Wang, C., Fang, H., Fang, H.S., Lu, C.: Rise: 3d perception makes real-world robot imitation simple and effective. In: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 2870–2877. IEEE (2024)
2024
-
[49]
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
Wen, J., Zhu, Y., Li, J., Tang, Z., Shen, C., Feng, F.: Dexvla: Vision-language model with plug-in diffusion expert for general robot control. arXiv preprint arXiv:2502.05855 (2025)
work page Pith review arXiv 2025
-
[50]
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
Wu, H., Jing, Y., Cheang, C., Chen, G., Xu, J., Li, X., Liu, M., Li, H., Kong, T.: Unleashing large-scale video generative pre-training for visual robot manipulation. arXiv preprint arXiv:2312.13139 (2023)
work page internal anchor Pith review arXiv 2023
-
[51]
In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
Xiang, F., Qin, Y., Mo, K., Xia, Y., Zhu, H., Liu, F., Liu, M., Jiang, H., Yuan, Y., Wang, H., Yi, L., Chang, A.X., Guibas, L.J., Su, H.: SAPIEN: A simulated part-based interactive environment. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
2020
-
[52]
Xue, Z., Deng, S., Chen, Z., Wang, Y., Yuan, Z., Xu, H.: Demogen: Synthetic demon- stration generation for data-efficient visuomotor policy learning. arXiv preprint arXiv:2502.16932 (2025)
-
[53]
Learning interactive real-world simulators.arXiv preprint arXiv:2310.06114, 2023
Yang, M., Du, Y., Ghasemipour, K., Tompson, J., Schuurmans, D., Abbeel, P.: Learning interactive real-world simulators. arXiv preprint arXiv:2310.06114 (2023)
-
[54]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, S., Zhou, Y., Liu, Z., Loy, C.C.: Fresco: Spatial-temporal correspondence for zero-shot video translation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8703–8712 (2024)
2024
-
[55]
In: CoRL 2024 Workshop on Whole-body Control and Bimanual Manipulation: Applications in Humanoids and Beyond
Ye, S., Jang, J., Jeon, B., Joo, S.J., Yang, J., Peng, B., Mandlekar, A., Tan, R., Chao, Y.W., Lin, B.Y., et al.: Latent action pretraining from videos. In: CoRL 2024 Workshop on Whole-body Control and Bimanual Manipulation: Applications in Humanoids and Beyond
2024
-
[56]
Yu, J., Qin, Y., Wang, X., Wan, P., Zhang, D., Liu, X.: Gamefactory: Creating new games with generative interactive videos (2025)
2025
-
[57]
Scaling robot learning with semantically imagined experience,
Yu, T., Xiao, T., Stone, A., Tompson, J., Brohan, A., Wang, S., Singh, J., Tan, C., Peralta, J., Ichter, B., et al.: Scaling robot learning with semantically imagined experience. arXiv preprint arXiv:2302.11550 (2023)
-
[58]
In: Proceedings of Robotics: Science and Systems (RSS) (2024)
Ze, Y., Zhang, G., Zhang, K., Hu, C., Wang, M., Xu, H.: 3d diffusion policy: Gen- eralizable visuomotor policy learning via simple 3d representations. In: Proceedings of Robotics: Science and Systems (RSS) (2024)
2024
-
[59]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[60]
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y., Li, T., You, Y.: Open-sora: Democratizing efficient video production for all (March 2024), https://github.com/hpcaitech/Open-Sora Compositional Simulation 19
2024
-
[61]
Zhou, S., Du, Y., Chen, J., Li, Y., Yeung, D.Y., Gan, C.: Robodreamer: Learning compositional world models for robot imagination. arXiv preprint arXiv:2404.12377 (2024)
-
[62]
Irasim: Learning interactive real-robot action simulators.arXiv preprint arXiv:2406.14540, 2024
Zhu, F., Wu, H., Guo, S., Liu, Y., Cheang, C., Kong, T.: Irasim: Learning interactive real-robot action simulators. arXiv preprint arXiv:2406.14540 (2024)
-
[63]
Change the image style from the image style of the simulated environment to the image style captured by a DSLR camera
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. In: Conference on Robot Learning. pp. 2165–2183. PMLR (2023) Appendix 6 Use of LLMs This paper was written by the authors without any generative contribution from larg...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.