Recognition: unknown
HalluClear: Diagnosing, Evaluating and Mitigating Hallucinations in GUI Agents
Pith reviewed 2026-05-10 06:23 UTC · model grok-4.3
The pith
A 9K-sample post-training suite cuts hallucinations and improves action accuracy in GUI agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HalluClear supplies a GUI-specific hallucination taxonomy, a calibrated three-stage evaluation workflow that improves VLM-as-a-judge reliability through expert-annotated benchmarking and ensemble credibility estimation, and a mitigation scheme based on closed-loop structured reasoning that supports cold-start continual post-training. When agents are post-trained on only 9K samples drawn from the suite, hallucinations decline and both grounding accuracy and action fidelity rise on representative benchmarks, with the gains appearing for generalist models as well as GUI-specialist agents.
What carries the argument
The closed-loop structured reasoning mitigation scheme, which structures the agent's internal reasoning to detect and correct hallucinations before final action selection.
If this is right
- Post-training on the 9K-sample suite produces measurable drops in hallucination rates for tested agents.
- Grounding precision and action fidelity both increase on public GUI benchmarks.
- The same training procedure works for generalist vision-language models and for agents already specialized for GUI tasks.
- The approach functions as a lightweight complement to large-scale pre-training for improving agent reliability.
Where Pith is reading between the lines
- The taxonomy and evaluation workflow could be adapted to diagnose hallucinations in other multimodal agent settings beyond desktop interfaces.
- If the structured-reasoning loop proves stable in live deployment, it could support real-time self-correction during extended GUI sessions.
- Wider use of small, targeted post-training sets might lower the data and compute barriers to deploying trustworthy automation agents.
- Similar closed-loop correction patterns might connect to existing techniques for reducing ungrounded outputs in other reasoning systems.
Load-bearing premise
The three-stage evaluation workflow accurately tracks genuine hallucination reduction and the mitigation transfers to new agents without creating additional failure modes.
What would settle it
Running the post-training procedure on the 9K samples and then measuring hallucination rates on the same public benchmarks; if rates stay the same or rise, the mitigation claim is falsified.
Figures






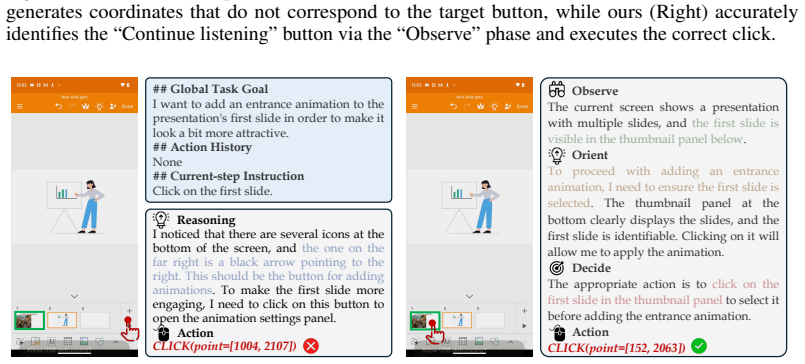


















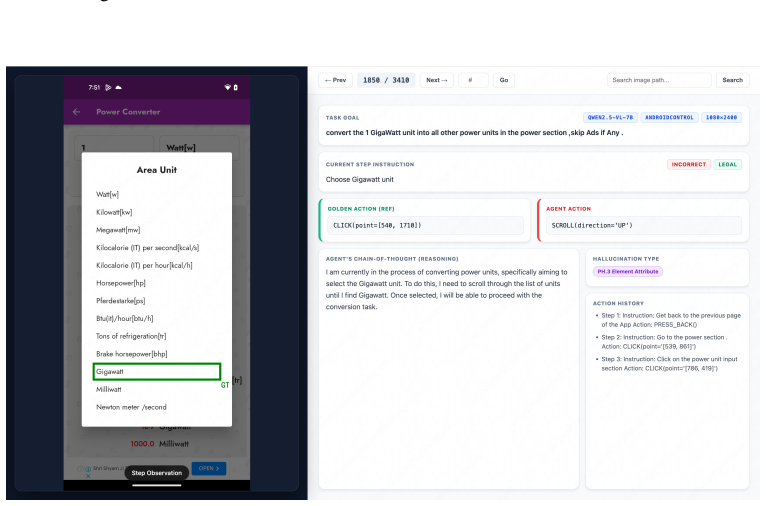
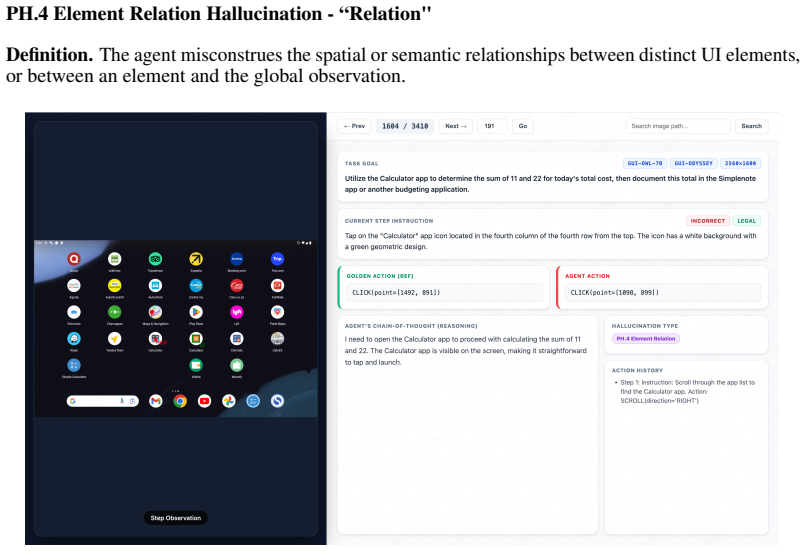














read the original abstract
While progress in GUI agents has been largely driven by industrial-scale training, ungrounded hallucinations often trigger cascading failures in real-world deployments.Unlike general VLM domains, the GUI agent field lacks a hallucination-focused suite for fine-grained diagnosis, reliable evaluation, and targeted mitigation.To bridge this gap, we introduce HalluClear, a comprehensive suite for hallucination mitigation in GUI agents as a complement to computation-intensive scaling. HalluClear comprises: (1) a GUI-specific hallucination taxonomy derived from empirical failure analysis; (2) a calibrated three-stage evaluation workflow which enhances VLM-as-a-judge reliability via expert-annotated benchmarking and ensemble credibility estimation; and (3) a mitigation scheme based on closed-loop structured reasoning, enabling lightweight continual post-training with cold-start initialization for both generalist and GUI-specialist agents. Experiments across representative agents and public benchmarks demonstrate that post-training on only 9K samples within our suite can significantly reduce hallucinations, thereby improving grounding and action fidelity, offering a compute-efficient pathway to robust GUI automation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HalluClear, a suite for hallucination diagnosis, evaluation, and mitigation in GUI agents. It defines a GUI-specific taxonomy from failure analysis, proposes a three-stage VLM-as-a-judge workflow (expert-annotated benchmarking plus ensemble credibility estimation) to improve evaluation reliability, and presents a closed-loop structured reasoning mitigation method for lightweight post-training (cold-start initialization). Experiments on representative generalist and GUI-specialist agents across public benchmarks claim that fine-tuning on only 9K samples from the suite significantly reduces hallucinations while improving grounding and action fidelity.
Significance. If the evaluation workflow proves reliable and the reported reductions hold under human-validated metrics, the work offers a practical, compute-efficient complement to industrial-scale training for robust GUI agents. The taxonomy and mitigation approach address a real deployment failure mode (ungrounded hallucinations) with a lightweight continual-learning pathway that applies to both generalist and specialist models.
major comments (3)
- [§3] §3 (Evaluation Workflow): The three-stage VLM-as-a-judge pipeline is presented as enhancing reliability via expert benchmarking and ensemble estimation, yet the manuscript does not report end-to-end human agreement metrics (e.g., F1, Cohen’s kappa, or correlation) between the judge and human annotators on the actual post-training agent outputs used for the main results. Without this, the claimed hallucination reductions risk being artifacts of VLM bias rather than genuine agent improvement.
- [§4] §4 (Experiments): The central claim that post-training on 9K samples “significantly reduce[s] hallucinations” and improves grounding/action fidelity is stated without quantitative metrics, error bars, baseline comparisons, or details on how the 9K samples were sampled/constructed or how hallucinations were scored in the reported tables. This makes it impossible to assess effect size or reproducibility from the provided evidence.
- [§4.2] §4.2 (Transfer to generalist vs. GUI-specialist agents): The claim that the closed-loop mitigation transfers without introducing new failure modes is not supported by ablation or failure-mode analysis on the post-mitigation outputs; only aggregate improvements are shown, leaving open whether the method trades one hallucination type for another.
minor comments (2)
- [Abstract] The abstract and §1 would benefit from a single sentence summarizing the quantitative gains (e.g., “X% relative reduction in hallucination rate on benchmark Y”) rather than the qualitative “significantly reduce.”
- [§3.1] Notation for the three-stage workflow (e.g., credibility estimation formula) should be defined explicitly in §3.1 before use in later sections.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications from the manuscript and outlining planned revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3] §3 (Evaluation Workflow): The three-stage VLM-as-a-judge pipeline is presented as enhancing reliability via expert benchmarking and ensemble estimation, yet the manuscript does not report end-to-end human agreement metrics (e.g., F1, Cohen’s kappa, or correlation) between the judge and human annotators on the actual post-training agent outputs used for the main results. Without this, the claimed hallucination reductions risk being artifacts of VLM bias rather than genuine agent improvement.
Authors: We appreciate the referee’s emphasis on rigorous validation of the VLM-as-a-judge workflow. The expert-annotated benchmarking described in §3 was performed on a diverse held-out set of GUI agent trajectories that explicitly includes outputs from both base and post-trained models to calibrate the ensemble credibility estimation. However, we acknowledge that aggregate agreement statistics (such as Cohen’s kappa and Pearson correlation) were not broken out specifically for the post-mitigation outputs appearing in the main experimental tables. In the revised manuscript we will add these end-to-end human agreement metrics computed on a random sample of post-training outputs, together with the corresponding F1 scores, to directly address the concern about potential VLM bias. revision: yes
-
Referee: [§4] §4 (Experiments): The central claim that post-training on 9K samples “significantly reduce[s] hallucinations” and improves grounding/action fidelity is stated without quantitative metrics, error bars, baseline comparisons, or details on how the 9K samples were sampled/constructed or how hallucinations were scored in the reported tables. This makes it impossible to assess effect size or reproducibility from the provided evidence.
Authors: We regret that the experimental reporting in §4 was insufficiently detailed. The 9K samples were constructed by stratified sampling from the HalluClear suite according to the taxonomy categories (ensuring balanced coverage of hallucination types), with the exact construction procedure and scoring protocol (via the calibrated three-stage workflow) described in §4.1 and §3 respectively. The tables already contain quantitative pre/post comparisons and baseline results against other mitigation approaches. Nevertheless, we agree that error bars from multiple random seeds and more explicit reproducibility details are necessary. In the revision we will (i) add standard-error bars, (ii) expand the sampling and scoring methodology subsection, and (iii) include the precise dataset-construction code and prompts as supplementary material. revision: yes
-
Referee: [§4.2] §4.2 (Transfer to generalist vs. GUI-specialist agents): The claim that the closed-loop mitigation transfers without introducing new failure modes is not supported by ablation or failure-mode analysis on the post-mitigation outputs; only aggregate improvements are shown, leaving open whether the method trades one hallucination type for another.
Authors: We thank the referee for raising the possibility of hidden trade-offs. Section 4.2 already reports per-category hallucination rates (using the taxonomy) for both generalist and GUI-specialist agents, showing consistent reductions across all categories with no category exhibiting an increase. To strengthen this evidence, the revised manuscript will include an explicit ablation study that isolates the contribution of each component of the closed-loop structured-reasoning mitigation, together with a fine-grained failure-mode analysis of a random sample of post-mitigation trajectories. This will demonstrate that the method does not trade one hallucination type for another. revision: yes
Circularity Check
No significant circularity; empirical claims are self-contained
full rationale
The paper's core contribution is an empirical suite (taxonomy from failure analysis, three-stage VLM-as-a-judge workflow with expert benchmarking, and closed-loop post-training on 9K samples) whose results are presented as experimental outcomes on public benchmarks rather than derived via equations or self-referential definitions. No load-bearing mathematical steps, fitted parameters renamed as predictions, or self-citation chains that reduce the central claim to its inputs appear in the abstract or described workflow. The mitigation and evaluation are framed as independent empirical procedures with external grounding in expert annotations and benchmark transfers, making the derivation self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen Team. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Qwen Team. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
OpenAI. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Model evaluation – approach, methodology & results: Gemini 3 flash, December 2025
Google DeepMind. Model evaluation – approach, methodology & results: Gemini 3 flash, December 2025. Model id: gemini-3-flash-preview
2025
-
[5]
Os-atlas: Foundation action model for generalist gui agents
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. Os-atlas: Foundation action model for generalist gui agents. InICLR, 2025
2025
-
[6]
Opencua: Open foundations for computer-use agents
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Henry Wu, et al. Opencua: Open foundations for computer-use agents. InNeurIPS, 2025
2025
-
[7]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[8]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326, 2025
work page Pith review arXiv 2025
-
[9]
Mobile-agent-v3: Fundamental agents for gui automation.arXiv preprint arXiv:2508.15144, 2025
Jiabo Ye, Xi Zhang, Haiyang Xu, Haowei Liu, Junyang Wang, Zhaoqing Zhu, Ziwei Zheng, Feiyu Gao, Junjie Cao, Zhengxi Lu, et al. Mobile-agent-v3: Fundamental agents for gui automation.arXiv preprint arXiv:2508.15144, 2025
-
[10]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InEMNLP, pages 292–305, 2023
2023
-
[14]
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InCVPR, pages 14375–14385, 2024
2024
-
[15]
doi:10.48550/arXiv.2504.17550 , abstract =
Yejin Bang, Ziwei Ji, Alan Schelten, Anthony Hartshorn, Tara Fowler, Cheng Zhang, Nicola Cancedda, and Pascale Fung. Hallulens: Llm hallucination benchmark.arXiv preprint arXiv:2504.17550, 2025
-
[16]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
2025
-
[17]
James Johnson. Automating the OODA loop in the age of intelligent machines: reaffirming the role of humans in command-and-control decision-making in the digital age.Defence Studies, 23(1):43–67, 2022
2022
-
[18]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InICLR, 2022. 11
2022
-
[19]
Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134, 1998
Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134, 1998
1998
-
[20]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InCVPR, pages 24185–24198, 2024
2024
-
[21]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen Team. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. In NeurIPS, volume 35, pages 24824–24837, 2022
2022
-
[23]
Aguvis: Unified pure vision agents for autonomous gui interaction
Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. Aguvis: Unified pure vision agents for autonomous gui interaction. ICML, 2025
2025
-
[24]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxi- ang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning.arXiv preprint arXiv:2509.02544, 2025
work page internal anchor Pith review arXiv 2025
-
[25]
Why Language Models Hallucinate
Adam Tauman Kalai, Ofir Nachum, Santosh S Vempala, and Edwin Zhang. Why language models hallucinate.arXiv preprint arXiv:2509.04664, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
On the effects of data scale on ui control agents
Wei Li, William E Bishop, Alice Li, Christopher Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. On the effects of data scale on ui control agents. InNeurIPS, volume 37, pages 92130–92154, 2024
2024
-
[27]
Guiodyssey: A comprehensive dataset for cross-app gui navigation on mobile devices
Quanfeng Lu, Wenqi Shao, Zitao Liu, Lingxiao Du, Fanqing Meng, Boxuan Li, Botong Chen, Siyuan Huang, Kaipeng Zhang, and Ping Luo. Guiodyssey: A comprehensive dataset for cross-app gui navigation on mobile devices. InICCV, pages 22404–22414, 2025
2025
-
[28]
G-eval: NLG evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: NLG evaluation using gpt-4 with better human alignment. InEMNLP, pages 2511–2522, 2023
2023
-
[29]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. InACL, pages 3214–3252, 2022
2022
-
[30]
Halueval: A large-scale hallucination evaluation benchmark for large language models
Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. Halueval: A large-scale hallucination evaluation benchmark for large language models. InEMNLP, 2023
2023
-
[31]
Showui: One vision-language-action model for gui visual agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Stan Weix- ian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for gui visual agent. InCVPR, pages 19498–19508, 2025
2025
-
[32]
Visual-RFT: Visual Reinforcement Fine-Tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-rft: Visual reinforcement fine-tuning.arXiv preprint arXiv:2503.01785, 2025
work page internal anchor Pith review arXiv 2025
-
[33]
Screenspot-pro: Gui grounding for professional high-resolution computer use
Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. Screenspot-pro: Gui grounding for professional high-resolution computer use. InACM MM, pages 8778–8786, 2025
2025
-
[34]
Cogagent: A visual language model for gui agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. InCVPR, pages 14281–14290, 2024
2024
-
[35]
Mobileflow: A multimodal llm for mobile gui agent.arXiv preprint arXiv:2407.04346, 2024
Songqin Nong, Jiali Zhu, Rui Wu, Jiongchao Jin, Shuo Shan, Xiutian Huang, and Wenhao Xu. Mobileflow: A multimodal llm for mobile gui agent.arXiv preprint arXiv:2407.04346, 2024
-
[36]
Visiontasker: Mobile task automation using vision based ui understanding and llm task planning
Yunpeng Song, Yiheng Bian, Yongtao Tang, Guiyu Ma, and Zhongmin Cai. Visiontasker: Mobile task automation using vision based ui understanding and llm task planning. InACM UIST, pages 1–17, 2024. 12
2024
-
[37]
Navigating the digital world as humans do: Universal visual grounding for gui agents
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. Navigating the digital world as humans do: Universal visual grounding for gui agents. InICLR, 2025
2025
-
[38]
Seeclick: Harnessing gui grounding for advanced visual gui agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Li YanTao, Jianbing Zhang, and Zhiyong Wu. Seeclick: Harnessing gui grounding for advanced visual gui agents. InACL, pages 9313–9332, 2024
2024
-
[39]
Guicourse: From general vision language model to versatile gui agent
Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, et al. Guicourse: From general vision language model to versatile gui agent. InACL, pages 21936–21959, 2025
2025
-
[40]
Os-genesis: Automating gui agent trajectory construction via reverse task synthesis
Qiushi Sun, Kanzhi Cheng, Zichen Ding, Chuanyang Jin, Yian Wang, Fangzhi Xu, Zhenyu Wu, Chengyou Jia, Liheng Chen, Zhoumianze Liu, et al. Os-genesis: Automating gui agent trajectory construction via reverse task synthesis. InACL, pages 5555–5579, 2025
2025
-
[41]
Gui-xplore: Empowering generalizable gui agents with one exploration
Yuchen Sun, Shanhui Zhao, Tao Yu, Hao Wen, Samith Va, Mengwei Xu, Yuanchun Li, and Chongyang Zhang. Gui-xplore: Empowering generalizable gui agents with one exploration. In CVPR, pages 19477–19486, 2025
2025
-
[42]
Ui-r1: Enhancing action prediction of gui agents by reinforcement learning
Zhengxi Lu, Yuxiang Chai, Yaxuan Guo, Xi Yin, Liang Liu, Hao Wang, Han Xiao, Shuai Ren, Guanjing Xiong, and Hongsheng Li. Ui-r1: Enhancing efficient action prediction of gui agents by reinforcement learning.arXiv preprint arXiv:2503.21620, 2025
-
[43]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Run Luo, Lu Wang, Wanwei He, Longze Chen, Jiaming Li, and Xiaobo Xia. Gui-r1: A generalist r1-style vision-language action model for gui agents.arXiv preprint arXiv:2504.10458, 2025
work page internal anchor Pith review arXiv 2025
-
[44]
History-aware reasoning for gui agents.arXiv preprint arXiv:2511.09127, 2025
Ziwei Wang, Leyang Yang, Xiaoxuan Tang, Sheng Zhou, Dajun Chen, Wei Jiang, and Yong Li. History-aware reasoning for gui agents.arXiv preprint arXiv:2511.09127, 2025
-
[45]
Yan Yang, Dongxu Li, Yutong Dai, Yuhao Yang, Ziyang Luo, Zirui Zhao, Zhiyuan Hu, Junzhe Huang, Amrita Saha, Zeyuan Chen, et al. Gta1: Gui test-time scaling agent.arXiv preprint arXiv:2507.05791, 2025
-
[46]
Factuality of large language models in the year 2024.CoRR, 2024
Yuxia Wang, Minghan Wang, Muhammad Arslan Manzoor, Fei Liu, Georgi Georgiev, Rock- tim Jyoti Das, and Preslav Nakov. Factuality of large language models in the year 2024.CoRR, 2024
2024
-
[47]
The troubling emergence of hallucination in large language models-an extensive definition, quantification, and prescriptive remediations
Vipula Rawte, Swagata Chakraborty, Agnibh Pathak, Anubhav Sarkar, SM Towhidul Islam Ton- moy, Aman Chadha, Amit Sheth, and Amitava Das. The troubling emergence of hallucination in large language models-an extensive definition, quantification, and prescriptive remediations. InEMNLP, pages 2541–2573, 2023
2023
-
[48]
Evaluating the factual consistency of large language models through news summarization
Derek Tam, Anisha Mascarenhas, Shiyue Zhang, Sarah Kwan, Mohit Bansal, and Colin Raffel. Evaluating the factual consistency of large language models through news summarization. In ACL, 2023
2023
-
[49]
Alignscore: Evaluating factual consis- tency with a unified alignment function
Yuheng Zha, Yichi Yang, Ruichen Li, and Zhiting Hu. Alignscore: Evaluating factual consis- tency with a unified alignment function. InACL, pages 11328–11348, 2023
2023
-
[50]
arXiv preprint arXiv:2307.13528 , year =
I Chern, Steffi Chern, Shiqi Chen, Weizhe Yuan, Kehua Feng, Chunting Zhou, Junxian He, Gra- ham Neubig, Pengfei Liu, et al. Factool: Factuality detection in generative ai–a tool augmented framework for multi-task and multi-domain scenarios.arXiv preprint arXiv:2307.13528, 2023
-
[51]
Niels Mündler, Jingxuan He, Slobodan Jenko, and Martin Vechev. Self-contradictory hal- lucinations of large language models: Evaluation, detection and mitigation.arXiv preprint arXiv:2305.15852, 2023
-
[52]
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. InEMNLP, pages 9004–9017, 2023
2023
-
[53]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InICLR. 13
-
[54]
Measuring multimodal mathematical reasoning with math-vision dataset
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset. In NeurIPS, volume 37, pages 95095–95169, 2024
2024
-
[55]
Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InECCV, pages 169–186
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InECCV, pages 169–186. Springer, 2024
2024
-
[56]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed- bench: Benchmarking multimodal llms with generative comprehension.arXiv preprint arXiv:2307.16125, 2023
work page internal anchor Pith review arXiv 2023
-
[57]
Mme: A comprehensive evaluation benchmark for multimodal large language models, 2025
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, Rongrong Ji, Caifeng Shan, and Ran He. Mme: A comprehensive evaluation benchmark for multimodal large language models, 2025
2025
-
[58]
Xingjian Tao, Yiwei Wang, Yujun Cai, Zhicheng Yang, and Jing Tang. Understanding gui agent localization biases through logit sharpness.arXiv preprint arXiv:2506.15425, 2025
-
[59]
Lingzhong Dong, Ziqi Zhou, Shuaibo Yang, Haiyue Sheng, Pengzhou Cheng, Zongru Wu, Zheng Wu, Gongshen Liu, and Zhuosheng Zhang. Say one thing, do another? diagnosing reasoning-execution gaps in vlm-powered mobile-use agents.arXiv preprint arXiv:2510.02204, 2025
-
[60]
Swift:a scalable lightweight infrastructure for fine-tuning
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. Swift:a scalable lightweight infrastructure for fine-tuning. InAAAI, 2025
2025
-
[61]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In EuroSys, 2024
2024
-
[62]
Seed1.8 model card: Towards generalized real-world agency, 2025
Bytedance Seed. Seed1.8 model card: Towards generalized real-world agency, 2025
2025
-
[63]
Google DeepMind. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Doubao-seed-1.6-vision, 2025
Bytedance Seed. Doubao-seed-1.6-vision, 2025
2025
-
[65]
Glm-4.6v: Open source multimodal models with native tool use, 2025
Z.ai. Glm-4.6v: Open source multimodal models with native tool use, 2025
2025
-
[66]
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zhang Zheng, and Mike Zheng Shou. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930, 2024. 14 A Related Work A.1 GUI Agents The integration of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) has revolutionized GUI automation. Ear...
work page internal anchor Pith review arXiv 2024
-
[67]
Step 1: Observe
<thinking>thinking</thinking>: Present your complete logical chain of problem-solving. It follows a clear and concise three-step logical reasoning process, i.e., Step 1: Observe; Step 2: Orient; Step 3: Decide. - Step 1: Observe: Describe in detail the layout, state, and key elements of the current-step screenshot. - Step 2: Orient: Infer what you should ...
-
[69]
<conclusion>conclusion</conclusion>: Summarize the action taken in the current step. Respond according to the user’s input, supplying the requested sections of the problem-solving process, i.e., <thinking>thinking</thinking> <an- swer>answer</answer><reflection>reflection</reflection><conclusion> conclusion</conclusion>. Solve the problem in accordance wi...
-
[70]
Step 1: Observe
<thinking>thinking</thinking>: Present your complete logical chain of problem-solving. It follows a clear and concise three-step logical reasoning process, i.e., Step 1: Observe; Step 2: Orient; Step 3: Decide. - Step 1: Observe: Describe in detail the layout, state, and key elements of the current-step screenshot. - Step 2: Orient: Infer what you should ...
-
[71]
Task Failed
<answer>answer</answer>: Provide the action to be executed in the specified format of the Action Space defined above. If you conclude that the task cannot be completed, output exactly: "Task Failed"
-
[72]
Verification Failed
<reflection>reflection</reflection>: Review the accuracy of the reasoning process within <thinking> and then verify the consistency between the reasoning process within <thinking> and the result within <answer>. If any error or inconsistency exists, end with: "Verification Failed"; otherwise, end with: "Verification Succeeded"
-
[73]
and": hallucination A occurs in one part, while hallucination B occurs elsewhere; or • “or
<conclusion>conclusion</conclusion>: Summarize the action taken in the current step. Respond according to the user’s input, supplying the requested sections of the problem- solving process, i.e., <thinking>thinking</thinking><answer>answer</answer> <reflection>reflection</reflection><conclusion>conclusion</conclusion>. Solve the problem in accordance with...
-
[74]
This reflects a failure in global scene understanding that transcends the perception of specific UI elements
**Screenshot State Hallucination**: The agent misinterprets the holistic state of the current screen- shot. This reflects a failure in global scene understanding that transcends the perception of specific UI elements
-
[75]
**Element Existence Hallucination**: The agent erroneously identifies or fabricates non-existent elements that do not appear in the screenshot
-
[76]
**Element Attribute Hallucination**: The agent misinterprets the intrinsic attributes of UI elements, specifically regarding their visual appearance, intended function, and operational affordances
-
[77]
Instances where grounding coordinates fall outside the screenshot boundaries are categorized here
**Element Relation Hallucination**: The agent misunderstands the relationships between UI ele- ments, or between elements and the overall screen, primarily concerning spatial arrangements. Instances where grounding coordinates fall outside the screenshot boundaries are categorized here
-
[78]
The primary focus is whether the reasoning steps within <thinking>demonstrate a clear intent to follow current-step instruction
**Instruction Hallucination**: The agent fails to adhere to or explicitly disregards low-level step instructions provided within the query. The primary focus is whether the reasoning steps within <thinking>demonstrate a clear intent to follow current-step instruction
-
[79]
**Context Hallucination**: The agent demonstrates inconsistencies within the context, specifically regarding discrepancies between the query and reasoning steps, or between the reasoning steps and the predicted answer. Typical examples of the former include invoking illegal actions (the predicted answer within <answer> does not follow the action space def...
-
[80]
This focuses on flawed causal transitions rather than simple correspondence errors
**Logical Hallucination**: The agent exhibits manifest logical errors or discontinuities within its reasoning steps. This focuses on flawed causal transitions rather than simple correspondence errors
-
[81]
**Factuality Hallucination**: The agent lacks relevant external knowledge, leading to overconfident fabrication of information or incorrect factual assertions
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.