Recognition: no theorem link
Predictive but Not Plannable: RC-aux for Latent World Models
Pith reviewed 2026-05-11 02:08 UTC · model grok-4.3
The pith
Latent world models need explicit reachability supervision to support planning beyond accurate short-term prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RC-aux keeps the original world-model backbone unchanged and supplies two forms of planning-aligned supervision. Multi-horizon open-loop rollouts train consistency beyond one step. Budget-conditioned reachability targets, paired with hard negatives drawn from earlier time steps, push the latent space to separate states that are reachable within the current horizon from those that are not. The learned reachability score is then used by a modified planner that prefers trajectories that are both goal-directed and attainable under the action budget. On LeWorldModel backbones, both continuation training and matched-from-scratch runs across goal-conditioned pixel tasks and a LIBERO-Goal extension,
What carries the argument
The Reachability-Correction auxiliary objective (RC-aux), which injects budget-conditioned reachability supervision and temporal hard negatives to align latent geometry with finite-horizon reachability.
If this is right
- Planning success improves on goal-conditioned tasks even when short-horizon prediction error stays the same.
- The latent space geometry becomes more consistent with finite-horizon reachability constraints.
- A reachability-aware planner can use the auxiliary signal to prune or rank trajectories at test time.
- The same auxiliary objective works under both continued training and training from scratch on the same backbone.
- Representation quality for planning is shown to be separable from pure predictive accuracy.
Where Pith is reading between the lines
- The same mismatch between prediction and reachability may appear in other world-model families, suggesting RC-aux could be ported as a modular fix.
- In robotics domains where action budgets are strict, explicitly modeling reachability might reduce the number of unsafe or dead-end plans generated by latent search.
- Scaling the horizon length of the reachability labels could reveal whether the benefit saturates or continues to grow with longer planning horizons.
Load-bearing premise
That the added reachability labels and hard negatives will make latent distances correspond to true reachable sets under a fixed action budget instead of simply fitting the auxiliary task.
What would settle it
An experiment in which RC-aux is added, predictive accuracy remains unchanged, yet planning success rates on held-out goal-conditioned tasks do not increase or the predicted reachability scores fail to match actual reachable states measured by exhaustive search.
Figures



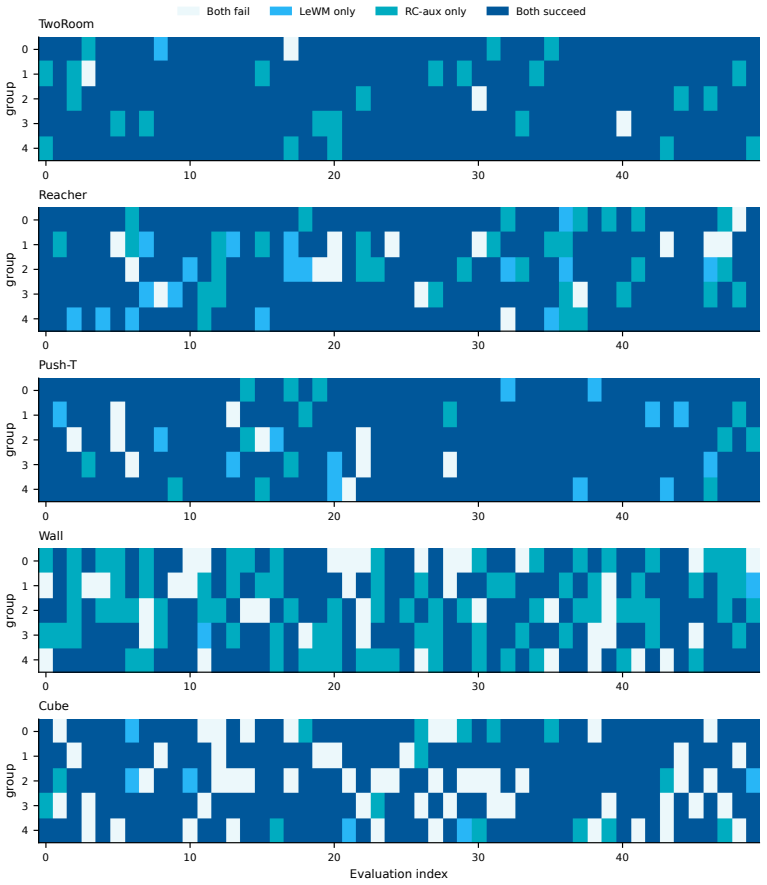










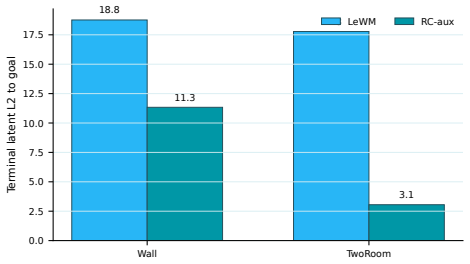

read the original abstract
A latent world model may achieve accurate short-horizon prediction while still inducing a latent space that is poorly aligned with planning. A key issue is spatiotemporal mismatch: these models are often trained with local predictive supervision, but deployed for long-horizon goal-directed search in latent spaces where Euclidean distance may not reflect what is reachable within a finite action budget. We present the Reachability-Correction auxiliary objective (RC-aux), a lightweight correction for this mismatch in reconstruction-free latent world models. RC-aux keeps the world-model backbone unchanged and adds planning-aligned supervision along two axes. Along the time axis, multi-horizon open-loop prediction trains the model beyond one-step consistency. Along the space axis, budget-conditioned reachability supervision, together with temporal hard negatives, encourages the latent space to distinguish states that are eventually reachable from those reachable within the current planning horizon. At test time, the learned reachability signal can also be used by a reachability-aware planner to favor trajectories that are both goal-directed and attainable under the available budget. We instantiate RC-aux on LeWorldModel and evaluate it under both continuation-training and matched-from-scratch settings. Across goal-conditioned pixel-control tasks and a LIBERO-Goal extension, RC-aux improves LeWM-style planning with modest additional cost. These results suggest that planning with latent world models depends not only on predictive accuracy, but also on whether the learned representation encodes the temporal and geometric structure required by downstream search. The code is available at https://github.com/Guang000/RC-aux.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RC-aux, a lightweight auxiliary objective added to reconstruction-free latent world models such as LeWorldModel. RC-aux combines multi-horizon open-loop prediction with budget-conditioned reachability supervision and temporal hard negatives to correct spatiotemporal mismatch between local predictive training and long-horizon goal-directed planning. The method is evaluated in continuation-training and matched-from-scratch regimes on goal-conditioned pixel-control tasks and a LIBERO-Goal extension, with the claim that the resulting latent space better encodes finite-horizon reachability, enabling improved planning (optionally using a reachability-aware planner at test time).
Significance. If the empirical gains are shown to arise from improved latent geometry rather than test-time use of the auxiliary head, the work would usefully separate predictive accuracy from plannability and provide a practical correction for existing world-model backbones in visual domains. The availability of code supports reproducibility.
major comments (2)
- [Experiments and Evaluation] The central claim that RC-aux aligns latent geometry with finite-horizon reachability (so that downstream search succeeds because of the representation) is load-bearing and requires an explicit ablation: replace the reachability-aware planner with standard latent-distance search using only the frozen encoder (no reachability head at test time). If the performance lift disappears in this setting, the results demonstrate utility of the auxiliary signal as a heuristic rather than a change in representation structure. This ablation is not described in the reported experiments.
- [Method] §3 (Method): the interaction between the budget-conditioned reachability head and the unchanged world-model backbone is not fully specified. It is unclear whether gradients from RC-aux flow into the backbone encoder or whether the auxiliary loss is strictly additive with frozen backbone parameters during the correction phase.
minor comments (2)
- [Abstract] The abstract would be strengthened by reporting at least one key quantitative result (e.g., success rate delta and baseline comparison) rather than stating only that improvements occur.
- [Method] Notation for the reachability head output and its integration into the planner should be defined more explicitly (e.g., how the budget-conditioned probability is combined with latent distance).
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major point below and will revise the manuscript to incorporate the suggested clarifications and additional experiments.
read point-by-point responses
-
Referee: [Experiments and Evaluation] The central claim that RC-aux aligns latent geometry with finite-horizon reachability (so that downstream search succeeds because of the representation) is load-bearing and requires an explicit ablation: replace the reachability-aware planner with standard latent-distance search using only the frozen encoder (no reachability head at test time). If the performance lift disappears in this setting, the results demonstrate utility of the auxiliary signal as a heuristic rather than a change in representation structure. This ablation is not described in the reported experiments.
Authors: We agree that this ablation is necessary to isolate whether the gains arise from improved latent geometry. The current evaluation focuses on the full RC-aux pipeline, which includes optional use of the reachability-aware planner at test time as described in the method. To directly address the concern, we will add this ablation in the revised version: we will report planning performance using only standard latent-distance search on the frozen encoder (without the reachability head) for both the baseline LeWorldModel and the RC-aux corrected model. This will clarify the contribution of the representation change independent of the test-time heuristic. revision: yes
-
Referee: [Method] §3 (Method): the interaction between the budget-conditioned reachability head and the unchanged world-model backbone is not fully specified. It is unclear whether gradients from RC-aux flow into the backbone encoder or whether the auxiliary loss is strictly additive with frozen backbone parameters during the correction phase.
Authors: We thank the referee for pointing out this ambiguity. As stated in the abstract ('RC-aux keeps the world-model backbone unchanged'), the backbone encoder and dynamics model remain frozen during the RC-aux correction phase. The auxiliary objectives (multi-horizon prediction and budget-conditioned reachability with temporal hard negatives) are implemented as separate heads whose parameters are trained on top of the fixed latent representations. Gradients from the RC-aux losses do not propagate into the backbone; the auxiliary loss is strictly additive. We will expand §3 with an explicit statement and diagram clarifying this frozen-backbone design to make the interaction unambiguous. revision: yes
Circularity Check
No circularity detected in RC-aux claims
full rationale
The paper introduces RC-aux as an auxiliary supervision signal added to an unchanged latent world model backbone, with claims of improved planning supported by empirical results on goal-conditioned tasks and LIBERO-Goal. No equations, self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations are present in the provided text that would make the planning gains equivalent to the auxiliary loss by construction. The method is framed as a lightweight correction for spatiotemporal mismatch, and results are reported as external improvements rather than tautological outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Latent world models trained with local predictive supervision can be deployed for long-horizon goal-directed search in their latent spaces.
invented entities (1)
-
Reachability-Correction auxiliary objective (RC-aux)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023
work page 2023
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Junik Bae, Kwanyoung Park, and Youngwoon Lee. Tldr: Unsupervised goal-conditioned rl via temporal distance-aware representations.arXiv preprint arXiv:2407.08464, 2024
-
[4]
Lejepa: Provable and scalable self-supervised learning without the heuristics, 2025
Randall Balestriero and Yann LeCun. Lejepa: Provable and scalable self-supervised learning without the heuristics.arXiv preprint arXiv:2511.08544, 2025
-
[5]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual repre- sentations from video.arXiv preprint arXiv:2404.08471, 2024
work page internal anchor Pith review arXiv 2024
-
[6]
Adrien Bardes, Jean Ponce, and Yann LeCun. Vicreg: Variance-invariance-covariance regular- ization for self-supervised learning.arXiv preprint arXiv:2105.04906, 2021
-
[7]
Maxime Burchi and Radu Timofte. Mudreamer: Learning predictive world models without reconstruction.arXiv preprint arXiv:2405.15083, 2024
-
[8]
Pablo Samuel Castro, Tyler Kastner, Prakash Panangaden, and Mark Rowland. Mico: Improved representations via sampling-based state similarity for markov decision processes.Advances in Neural Information Processing Systems, 34:30113–30126, 2021
work page 2021
-
[9]
Fei Deng, Ingook Jang, and Sungjin Ahn. Dreamerpro: Reconstruction-free model-based rein- forcement learning with prototypical representations. InInternational conference on machine learning, pages 4956–4975. PMLR, 2022
work page 2022
-
[10]
arXiv preprint arXiv:2601.00844 , year=
Matthieu Destrade, Oumayma Bounou, Quentin Le Lidec, Jean Ponce, and Yann LeCun. Value-guided action planning with jepa world models.arXiv preprint arXiv:2601.00844, 2025
-
[11]
Deep visual foresight for planning robot motion
Chelsea Finn and Sergey Levine. Deep visual foresight for planning robot motion. In2017 IEEE international conference on robotics and automation (ICRA), pages 2786–2793. IEEE, 2017
work page 2017
-
[12]
Deep- mdp: Learning continuous latent space models for representation learning
Carles Gelada, Saurabh Kumar, Jacob Buckman, Ofir Nachum, and Marc G Bellemare. Deep- mdp: Learning continuous latent space models for representation learning. InInternational conference on machine learning, pages 2170–2179. PMLR, 2019
work page 2019
-
[13]
Learning to reach goals via iterated supervised learning.arXiv preprint arXiv:1912.06088, 2019
Dibya Ghosh, Abhishek Gupta, Ashwin Reddy, Justin Fu, Coline Devin, Benjamin Eysenbach, and Sergey Levine. Learning to reach goals via iterated supervised learning.arXiv preprint arXiv:1912.06088, 2019. 10
-
[14]
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020
work page 2020
-
[15]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review arXiv 2018
-
[16]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review arXiv 1912
-
[17]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. InInternational conference on machine learning, pages 2555–2565. PMLR, 2019
work page 2019
-
[18]
Mastering Atari with Discrete World Models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models.arXiv preprint arXiv:2010.02193, 2020
work page internal anchor Pith review arXiv 2010
-
[19]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review arXiv 2023
-
[20]
TD-MPC2: Scalable, Robust World Models for Continuous Control
Nicklas Hansen, Hao Su, and Xiaolong Wang. Td-mpc2: Scalable, robust world models for continuous control.arXiv preprint arXiv:2310.16828, 2023
work page internal anchor Pith review arXiv 2023
-
[21]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review arXiv 2025
-
[22]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Offline Reinforcement Learning with Implicit Q-Learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning.arXiv preprint arXiv:2110.06169, 2021
work page internal anchor Pith review arXiv 2021
-
[24]
Pclast: Discovering plannable continuous latent states.arXiv preprint arXiv:2311.03534, 2023
Anurag Koul, Shivakanth Sujit, Shaoru Chen, Ben Evans, Lili Wu, Byron Xu, Rajan Chari, Riashat Islam, Raihan Seraj, Yonathan Efroni, et al. Pclast: Discovering plannable continuous latent states.arXiv preprint arXiv:2311.03534, 2023
-
[25]
Thanard Kurutach, Aviv Tamar, Ge Yang, Stuart J Russell, and Pieter Abbeel. Learning plannable representations with causal infogan.Advances in Neural Information Processing Systems, 31, 2018
work page 2018
-
[26]
Curl: Contrastive unsupervised repre- sentations for reinforcement learning
Michael Laskin, Aravind Srinivas, and Pieter Abbeel. Curl: Contrastive unsupervised repre- sentations for reinforcement learning. InInternational conference on machine learning, pages 5639–5650. PMLR, 2020
work page 2020
-
[27]
A path towards autonomous machine intelligence version 0.9
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review, 62(1):1–62, 2022
work page 2022
-
[28]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310, 2023
work page internal anchor Pith review arXiv 2023
-
[29]
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. Leworld- model: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026
work page internal anchor Pith review arXiv 2026
-
[30]
Temporal predictive coding for model-based planning in latent space
Tung D Nguyen, Rui Shu, Tuan Pham, Hung Bui, and Stefano Ermon. Temporal predictive coding for model-based planning in latent space. InInternational conference on machine learning, pages 8130–8139. PMLR, 2021
work page 2021
-
[31]
Dreamingv2: Reinforcement learning with discrete world models without reconstruction
Masashi Okada and Tadahiro Taniguchi. Dreamingv2: Reinforcement learning with discrete world models without reconstruction. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 985–991. IEEE, 2022. 11
work page 2022
-
[32]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Ogbench: Benchmarking offline goal-conditioned rl.arXiv preprint arXiv:2410.20092,
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. Ogbench: Benchmarking offline goal-conditioned rl.arXiv preprint arXiv:2410.20092, 2024
-
[34]
Zhifeng Qian, Mingyu You, Hongjun Zhou, Xuanhui Xu, and Bin He. Goal-conditioned reinforcement learning with disentanglement-based reachability planning.IEEE Robotics and Automation Letters, 8(8):4721–4728, 2023
work page 2023
-
[35]
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Si- mon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, et al. Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
work page 2020
-
[36]
Data-efficient reinforcement learning with self-predictive representations
Max Schwarzer, Ankesh Anand, Rishab Goel, R Devon Hjelm, Aaron Courville, and Philip Bachman. Data-efficient reinforcement learning with self-predictive representations.arXiv preprint arXiv:2007.05929, 2020
-
[37]
Planning to explore via self-supervised world models
Ramanan Sekar, Oleh Rybkin, Kostas Daniilidis, Pieter Abbeel, Danijar Hafner, and Deepak Pathak. Planning to explore via self-supervised world models. InInternational conference on machine learning, pages 8583–8592. PMLR, 2020
work page 2020
-
[38]
Vlad Sobal, Wancong Zhang, Kyunghyun Cho, Randall Balestriero, Tim GJ Rudner, and Yann LeCun. Stress-testing offline reward-free reinforcement learning: A case for planning with latent dynamics models. In7th Robot Learning Workshop: Towards Robots with Human-Level Abilities
-
[39]
Learning from reward-free offline data: A case for planning with latent dynamics models
Vlad Sobal, Wancong Zhang, Kyunghyun Cho, Randall Balestriero, Tim GJ Rudner, and Yann LeCun. Learning from reward-free offline data: A case for planning with latent dynamics models.arXiv preprint arXiv:2502.14819, 2025
-
[40]
Universal plan- ning networks: Learning generalizable representations for visuomotor control
Aravind Srinivas, Allan Jabri, Pieter Abbeel, Sergey Levine, and Chelsea Finn. Universal plan- ning networks: Learning generalizable representations for visuomotor control. InInternational conference on machine learning, pages 4732–4741. PMLR, 2018
work page 2018
-
[41]
State representation learning for goal-conditioned reinforcement learning
Lorenzo Steccanella and Anders Jonsson. State representation learning for goal-conditioned reinforcement learning. InJoint european conference on machine learning and knowledge discovery in databases, pages 84–99. Springer, 2022
work page 2022
-
[42]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite. arXiv preprint arXiv:1801.00690, 2018
work page internal anchor Pith review arXiv 2018
-
[43]
Optimal goal-reaching reinforcement learning via quasimetric learning
Tongzhou Wang, Antonio Torralba, Phillip Isola, and Amy Zhang. Optimal goal-reaching reinforcement learning via quasimetric learning. InInternational Conference on Machine Learning, pages 36411–36430. PMLR, 2023
work page 2023
-
[44]
Temporal straightening for latent planning.arXiv preprint arXiv:2603.12231, 2026
Ying Wang, Oumayma Bounou, Gaoyue Zhou, Randall Balestriero, Tim GJ Rudner, Yann LeCun, and Mengye Ren. Temporal straightening for latent planning.arXiv preprint arXiv:2603.12231, 2026
-
[45]
Manuel Watter, Jost Springenberg, Joschka Boedecker, and Martin Riedmiller. Embed to control: A locally linear latent dynamics model for control from raw images.Advances in neural information processing systems, 28, 2015
work page 2015
-
[46]
Amy Zhang, Rowan McAllister, Roberto Calandra, Yarin Gal, and Sergey Levine. Learning invariant representations for reinforcement learning without reconstruction.arXiv preprint arXiv:2006.10742, 2020
-
[47]
Gaoyue Zhou, Hengkai Pan, Yann LeCun, and Lerrel Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning.arXiv preprint arXiv:2411.04983, 2024. 12 A Extended Related Work Latent world models for control from pixels.World models learn compact predictive representa- tions that support decision-making by imagining the consequenc...
-
[48]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.