Recognition: 2 theorem links
· Lean TheoremPhyGround: Benchmarking Physical Reasoning in Generative World Models
Pith reviewed 2026-05-12 05:13 UTC · model grok-4.3
The pith
PhyGround provides 250 prompts and 13 laws to diagnose specific physical violations in generated videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
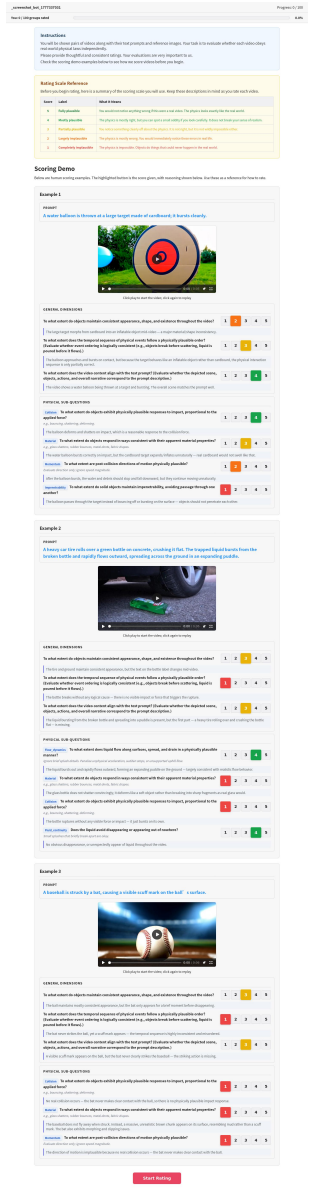
We introduce PhyGround, a criteria-grounded benchmark for evaluating physical reasoning in video generation. The benchmark contains 250 curated prompts, each augmented with an expected physical outcome, and a taxonomy of 13 physical laws across solid-body mechanics, fluid dynamics, and optics. Each law is operationalized through observable sub-questions to enable per-law diagnostics. We evaluate eight modern video generation models through a large-scale, quality-controlled human study.
What carries the argument
The taxonomy of 13 physical laws operationalized through observable sub-questions attached to 250 prompts that each carry a stated expected physical outcome.
If this is right
- Model developers can identify and correct failures on one law at a time instead of working from coarse overall scores.
- Comparisons among video generators become more repeatable because each prompt has a pre-specified physical outcome.
- An open physics-specialized VLM judge can be used for fast, auditable automated checks that reduce reliance on human annotators.
- Research on generative world models can prioritize training changes that improve performance on specific laws such as fluid dynamics or optics.
Where Pith is reading between the lines
- The human annotation protocol with split-half reliability checks could be adapted to create similar fine-grained benchmarks for other generative tasks.
- Consistent law-specific failures across models may point to architectural limits that current scaling alone will not overcome.
- Adding prompts that combine multiple laws could test whether models handle interacting physical rules rather than isolated ones.
Load-bearing premise
The taxonomy of 13 laws and their sub-questions covers the main physical reasoning failures that matter for video generation.
What would settle it
A video model that scores well on PhyGround but still produces clearly wrong physics in new test videos whose interactions fall outside the 13 laws.
Figures






































read the original abstract
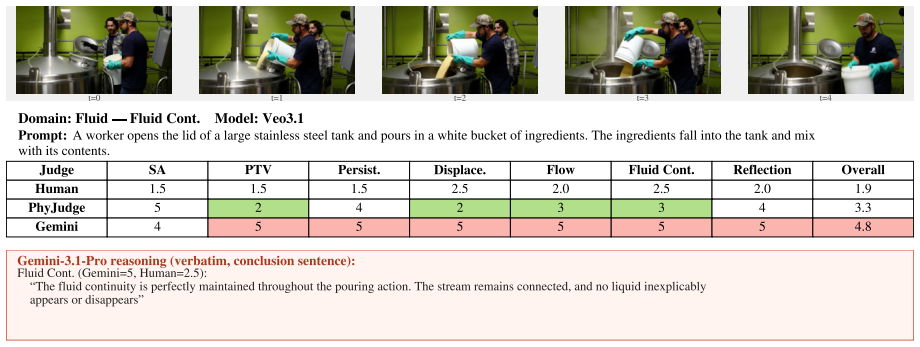
Generative world models are increasingly used for video generation, where learned simulators are expected to capture the physical rules that govern real-world dynamics. However, evaluating whether generated videos actually follow these rules remains challenging. Existing physics-focused video benchmarks have made important progress, but they still face three key challenges, including the coarse evaluation frameworks that hide law-specific failures, response biases and fatigue that undermine the validity of annotation judgments, and automated evaluators that are insufficiently physics-aware or difficult to audit. To address those challenges, we introduce PhyGround, a criteria-grounded benchmark for evaluating physical reasoning in video generation. The benchmark contains 250 curated prompts, each augmented with an expected physical outcome, and a taxonomy of 13 physical laws across solid-body mechanics, fluid dynamics, and optics. Each law is operationalized through observable sub-questions to enable per-law diagnostics. We evaluate eight modern video generation models through a large-scale, quality-controlled human study, grounded on social science lab experiment design. A total of 459 annotators provided 5,796 complete annotations and over 37.4K fine-grained labels; after quality control, the retained annotations exhibited high split-half model-ranking correlations (Spearman's rho > 0.90). To support reproducible automated evaluation, we release PhyJudge-9B, an open physics-specialized VLM judge. PhyJudge-9B achieves substantially lower aggregate relative bias than Gemini-3.1-Pro (3.3% vs. 16.6%). We release prompts, human annotations, model checkpoints, and evaluation code on the project page https://phyground.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PhyGround, a criteria-grounded benchmark for physical reasoning in generative video models. It consists of 250 curated prompts each paired with an expected physical outcome, a taxonomy of 13 physical laws (solid-body mechanics, fluid dynamics, optics) operationalized via observable sub-questions for per-law diagnostics, results from a large-scale quality-controlled human study (459 annotators, 5,796 annotations, >37.4K fine-grained labels) showing high split-half reliability (Spearman's rho > 0.90), and the release of an open physics-specialized VLM judge (PhyJudge-9B) that exhibits lower aggregate relative bias (3.3%) than Gemini-3.1-Pro (16.6%). The work evaluates eight modern video generation models and releases prompts, annotations, model checkpoints, and code.
Significance. If the reported reliability and bias metrics hold, this benchmark advances evaluation of physical reasoning in video generation by replacing coarse, non-diagnostic metrics with law-specific sub-questions and by grounding judgments in social-science-style quality controls rather than ad-hoc annotation. The explicit release of data, annotations, and an auditable open judge model directly addresses reproducibility and automation concerns in the field. The high split-half correlations and quantified bias comparison provide concrete evidence that the protocol mitigates common annotation pitfalls.
minor comments (3)
- [Abstract and §3] Abstract and §3 (prompt curation): the criteria used to select and balance the 250 prompts across the 13 laws are described at a high level but lack an explicit enumeration or decision tree; adding a supplementary table listing per-law prompt counts and exclusion reasons would improve auditability.
- [§4.2] §4.2 (human study design): while split-half Spearman correlations >0.90 are reported after quality control, the exact filtering thresholds (e.g., attention-check failure rate, minimum completion time) and how they were chosen are not stated; a short methods paragraph or appendix table would allow readers to replicate the retention process.
- [Results tables] Table 2 or equivalent results table: the per-law failure rates for the eight models are aggregated; reporting the number of annotations per law (or at least per category) would clarify whether low-sample laws drive any observed differences.
Simulated Author's Rebuttal
We sincerely thank the referee for their careful review and for recommending acceptance of the manuscript. We are encouraged by the positive evaluation of PhyGround's contributions to benchmarking physical reasoning in generative world models.
Circularity Check
No significant circularity; benchmark defined from external laws and independent annotations
full rationale
The paper introduces PhyGround as a new benchmark consisting of 250 prompts, a taxonomy of 13 physical laws drawn from standard mechanics/fluid/optics domains, observable sub-questions, and a large-scale human annotation study with quality controls. No derivation chain, prediction, or first-principles result is claimed that reduces to fitted parameters, self-citations, or the models under test. The taxonomy and expected outcomes are presented as externally grounded (standard physical laws plus human judgment), the human study is described as independent with split-half validation, and PhyJudge-9B is released as an auxiliary tool rather than a load-bearing premise. No self-definitional loops, fitted-input predictions, or uniqueness theorems imported from prior author work appear in the provided text. This is a standard benchmark-release contribution whose central claims rest on the curation process and empirical annotation consistency rather than any circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Physical laws in solid-body mechanics, fluid dynamics, and optics can be operationalized into observable sub-questions suitable for video evaluation.
invented entities (1)
-
PhyJudge-9B
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
taxonomy of 13 physical laws across solid-body mechanics, fluid dynamics, and optics... each law is operationalized through observable sub-questions
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
criteria-grounded benchmark... 250 curated prompts... PhyJudge-9B... lower aggregate relative bias
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Impossible videos.arXiv preprint arXiv:2503.14378, 2025
Zechen Bai, Hai Ci, and Mike Zheng Shou. Impossible videos.arXiv preprint arXiv:2503.14378, 2025
-
[3]
Videophy: Evaluating physical commonsense for video generation
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai-Wei Chang, and Aditya Grover. Videophy: Evaluating physical commonsense for video generation. arXiv preprint arXiv:2406.03520, 2024
-
[4]
Hritik Bansal, Clark Peng, Yonatan Bitton, Roman Goldenberg, Aditya Grover, and Kai-Wei Chang. Videophy- 2: A challenging action-centric physical commonsense evaluation in video generation.arXiv preprint arXiv:2503.06800, 2025
-
[5]
Donald T. Campbell and Julian C. Stanley.Experimental and Quasi-Experimental Designs for Research. Rand McNally, Chicago, IL, 1963
work page 1963
-
[6]
Physgame: Uncovering physical commonsense violations in gameplay videos
Meng Cao, Haoran Tang, Haoze Zhao, Hangyu Guo, Jiaheng Liu, Ge Zhang, Ruyang Liu, Qiang Sun, Ian Reid, and Xiaodan Liang. Physgame: Uncovering physical commonsense violations in gameplay videos. arXiv preprint arXiv:2412.01800, 2024
-
[7]
Jesse Chandler, Pam Mueller, and Gabriele Paolacci. Nonnaïveté among amazon mechanical turk workers: Consequences and solutions for behavioral researchers.Behavior research methods, 46(1):112–130, 2014
work page 2014
-
[8]
Jingtao Ding, Yunke Zhang, Yu Shang, Yuheng Zhang, Zefang Zong, Jie Feng, Yuan Yuan, Hongyuan Su, Nian Li, Nicholas Sukiennik, et al. Understanding world or predicting future? a comprehensive survey of world models.ACM Computing Surveys, 58(3):1–38, 2025. 9
work page 2025
-
[9]
Veo 3.https://deepmind.google/models/veo/, 2026
Google DeepMind. Veo 3.https://deepmind.google/models/veo/, 2026
work page 2026
-
[10]
InThe Thirteenth International Conference on Learning Representations
Jing Gu, Xian Liu, Yu Zeng, Ashwin Nagarajan, Fangrui Zhu, Daniel Hong, Yue Fan, Qianqi Yan, Kaiwen Zhou, Ming-Yu Liu, et al. " phyworldbench": A comprehensive evaluation of physical realism in text-to-video models.arXiv preprint arXiv:2507.13428, 2025
-
[11]
Cosmos world foundation models for physical ai
Jinwei Gu. Cosmos world foundation models for physical ai. InProceedings of the 3rd International Workshop on Rich Media With Generative AI, pages 39–39, 2025
work page 2025
-
[12]
Xuyang Guo, Jiayan Huo, Zhenmei Shi, Zhao Song, Jiahao Zhang, and Jiale Zhao. T2vphysbench: A first- principles benchmark for physical consistency in text-to-video generation.arXiv preprint arXiv:2505.00337, 2025
-
[13]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026
work page Pith review arXiv 2026
-
[14]
Video-bench: Human-aligned video generation benchmark
Hui Han, Siyuan Li, Jiaqi Chen, Yiwen Yuan, Yuling Wu, Yufan Deng, Chak Tou Leong, Hanwen Du, Junchen Fu, Youhua Li, et al. Video-bench: Human-aligned video generation benchmark. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18858–18868, 2025
work page 2025
-
[15]
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan
Xuan He, Dongfu Jiang, Ping Nie, Minghao Liu, Zhengxuan Jiang, Mingyi Su, Wentao Ma, Junru Lin, Chun Ye, Yi Lu, et al. Videoscore2: Think before you score in generative video evaluation.arXiv preprint arXiv:2509.22799, 2025
-
[16]
Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation
Xuan He, Dongfu Jiang, Ge Zhang, Max Ku, Achint Soni, Sherman Siu, Haonan Chen, Abhranil Chandra, Ziyan Jiang, Aaran Arulraj, et al. Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2105–2123, 2024
work page 2024
-
[17]
Image quality metrics: Psnr vs
Alain Hore and Djemel Ziou. Image quality metrics: Psnr vs. ssim. In2010 20th international conference on pattern recognition, pages 2366–2369. IEEE, 2010
work page 2010
-
[18]
Lanxiang Hu, Abhilash Shankarampeta, Yixin Huang, Zilin Dai, Haoyang Yu, Yujie Zhao, Haoqiang Kang, Daniel Zhao, Tajana Rosing, and Hao Zhang. Benchmarking scientific understanding and reasoning for video generation using videoscience-bench.arXiv preprint arXiv:2512.02942, 2025
-
[19]
Cosmos-eval: Towards explainable evaluation of physics and semantics in text-to-video models
Yujie Huang, Wenwu He, Congcong Liu, Dong Liang, and Zhuo-Xu Cui. Cosmos-eval: Towards explainable evaluation of physics and semantics in text-to-video models
-
[20]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
work page 2024
- [21]
-
[22]
arXiv preprint arXiv:2502.20694 (2025)
Dacheng Li, Yunhao Fang, Yukang Chen, Shuo Yang, Shiyi Cao, Justin Wong, Michael Luo, Xiaolong Wang, Hongxu Yin, Joseph E Gonzalez, et al. Worldmodelbench: Judging video generation models as world models. arXiv preprint arXiv:2502.20694, 2025
-
[23]
Improving Video Generation with Human Feedback
Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Menghan Xia, Xintao Wang, et al. Improving video generation with human feedback.arXiv preprint arXiv:2501.13918, 2025
work page internal anchor Pith review arXiv 2025
-
[24]
Xiao Liu and Jiawei Zhang. Aigve-macs: Unified multi-aspect commenting and scoring model for ai-generated video evaluation.arXiv preprint arXiv:2507.01255, 2025
-
[25]
Evalcrafter: Benchmarking and evaluating large video generation models
Yaofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Yong Zhang, Haoxin Chen, Yang Liu, Tieyong Zeng, Raymond Chan, and Ying Shan. Evalcrafter: Benchmarking and evaluating large video generation models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22139–22149, 2024. 10
work page 2024
-
[26]
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quanfeng Lu, Kaipeng Zhang, Yu Cheng, Dianqi Li, Yu Qiao, and Ping Luo. Towards world simulator: Crafting physical commonsense-based benchmark for video generation.arXiv preprint arXiv:2410.05363, 2024
-
[27]
Saman Motamed, Minghao Chen, Luc Van Gool, and Iro Laina. Travl: A recipe for making video-language models better judges of physics implausibility.arXiv preprint arXiv:2510.07550, 2025
-
[28]
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do generative video models understand physical principles? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 948–958, 2026
work page 2026
-
[29]
Martin T. Orne. On the social psychology of the psychological experiment: With particular reference to demand characteristics and their implications.American Psychologist, 17(11):776–783, 1962
work page 1962
-
[30]
Kaihang Pan, Qi Tian, Jianwei Zhang, Weijie Kong, Jiangfeng Xiong, Yanxin Long, Shixue Zhang, Haiyi Qiu, Tan Wang, Zheqi Lv, et al. Omniweaving: Towards unified video generation with free-form composition and reasoning.arXiv preprint arXiv:2603.24458, 2026
-
[31]
Running experiments on amazon mechanical turk.Judgment and Decision making, 5(5):411–419, 2010
Gabriele Paolacci, Jesse Chandler, and Panagiotis G Ipeirotis. Running experiments on amazon mechanical turk.Judgment and Decision making, 5(5):411–419, 2010
work page 2010
-
[32]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[33]
Harry T. Reis and Charles M. Judd, editors.Handbook of Research Methods in Social and Personality Psychology. Cambridge University Press, Cambridge, UK, 2000
work page 2000
-
[34]
Human Cognition in Machines: A Unified Perspective of World Models
Timothy Rupprecht, Pu Zhao, Amir Taherin, Arash Akbari, Arman Akbari, Yumei He, Sean Duffy, Juyi Lin, Yixiao Chen, Rahul Chowdhury, et al. Human cognition in machines: A unified perspective of world models. arXiv preprint arXiv:2604.16592, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
William R. Shadish, Thomas D. Cook, and Donald T. Campbell.Experimental and Quasi-Experimental Designs for Generalized Causal Inference. Houghton Mifflin, Boston, MA, 2002
work page 2002
-
[36]
Vf-eval: Evaluating multimodal llms for generating feedback on aigc videos
Tingyu Song, Tongyan Hu, Guo Gan, and Yilun Zhao. Vf-eval: Evaluating multimodal llms for generating feedback on aigc videos. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 21126–21146, 2025
work page 2025
-
[37]
Shangkun Sun, Xiaoyu Liang, Bowen Qu, and Wei Gao. Content-rich aigc video quality assessment via intricate text alignment and motion-aware consistency.arXiv preprint arXiv:2502.04076, 2025
-
[38]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Haibo Tong, Zhaoyang Wang, Zhaorun Chen, Haonian Ji, Shi Qiu, Siwei Han, Kexin Geng, Zhongkai Xue, Yiyang Zhou, Peng Xia, et al. Mj-video: Fine-grained benchmarking and rewarding video preferences in video generation.arXiv preprint arXiv:2502.01719, 2025
-
[40]
Fvd: A new metric for video generation
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. Fvd: A new metric for video generation. 2019
work page 2019
-
[41]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Jiarui Wang, Huiyu Duan, Ziheng Jia, Yu Zhao, Woo Yi Yang, Zicheng Zhang, Zijian Chen, Juntong Wang, Yuke Xing, Guangtao Zhai, et al. Love: Benchmarking and evaluating text-to-video generation and video-to- text interpretation.arXiv preprint arXiv:2505.12098, 2025
-
[43]
Jiarui Wang, Huiyu Duan, Guangtao Zhai, Juntong Wang, and Xiongkuo Min. Aigv-assessor: Benchmarking and evaluating the perceptual quality of text-to-video generation with lmm. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18869–18880, 2025. 11
work page 2025
-
[44]
A very big video reasoning suite
Maijunxian Wang, Ruisi Wang, Juyi Lin, Ran Ji, Thaddäus Wiedemer, Qingying Gao, Dezhi Luo, Yaoyao Qian, Lianyu Huang, Zelong Hong, et al. A very big video reasoning suite.arXiv preprint arXiv:2602.20159, 2026
-
[45]
Zeqing Wang, Keze Wang, and Lei Zhang. Phydetex: Detecting and explaining the physical plausibility of t2v models.arXiv preprint arXiv:2512.01843, 2025
-
[46]
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shurun Li, et al. Visionreward: Fine-grained multi-dimensional human preference learning for image and video generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 11269–11277, 2026
work page 2026
-
[47]
Chenyu Zhang, Daniil Cherniavskii, Antonios Tragoudaras, Antonios V ozikis, Thijmen Nijdam, Derck WE Prinzhorn, Mark Bodracska, Nicu Sebe, Andrii Zadaianchuk, and Efstratios Gavves. Morpheus: Bench- marking physical reasoning of video generative models with real physical experiments.arXiv preprint arXiv:2504.02918, 2025
-
[48]
Qin Zhang, Peiyu Jing, Hong-Xing Yu, Fangqiang Ding, Fan Nie, Weimin Wang, Yilun Du, James Zou, Jiajun Wu, and Bing Shuai. Physion-eval: Evaluating physical realism in generated video via human reasoning.arXiv preprint arXiv:2603.19607, 2026
-
[49]
Xuanyu Zhang, Weiqi Li, Shijie Zhao, Junlin Li, Li Zhang, and Jian Zhang. Vq-insight: Teaching vlms for ai-generated video quality understanding via progressive visual reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 12870–12878, 2026
work page 2026
-
[50]
Q-bench-video: Benchmark the video quality understanding of lmms
Zicheng Zhang, Ziheng Jia, Haoning Wu, Chunyi Li, Zijian Chen, Yingjie Zhou, Wei Sun, Xiaohong Liu, Xiongkuo Min, Weisi Lin, et al. Q-bench-video: Benchmark the video quality understanding of lmms. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 3229–3239, 2025
work page 2025
-
[51]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, et al. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness. arXiv preprint arXiv:2503.21755, 2025. A Prompt Suite and Physics Law Selection Rationale This appendix provides the full design rationale behind the ...
work page internal anchor Pith review arXiv 2025
-
[52]
Unique Physical Outcome.The expected outcome must be unambiguous, admitting only one physically plausible result. For example, “spaghetti breaks into pieces” is excluded because the number of pieces has no correct answer
-
[53]
Visual Verifiability.Whether the outcome occurred must be immediately apparent from the generated video, without domain expertise or frame-by-frame analysis
-
[54]
Concise Everyday Scenario.The prompt must describe a concrete situation in under 50 words, set in a familiar context. Prompts requiring specialized laboratory equipment or rare objects (e.g., “rotary filling machine,” “press brake”) are excluded because video models lack sufficient visual reference for these objects
-
[55]
Prompts that are only superficially associated through keywords are excluded
Domain Alignment.The core phenomenon must genuinely belong to the target physics domain. Prompts that are only superficially associated through keywords are excluded. For example, grinding should not be classified as collision when the underlying mechanism is friction, nor should a penguin entering water be classified as fluid dynamics when the scene prim...
-
[56]
Physics as Core Phenomenon.The scenario must be driven by a natural physical process. Machine and tool operations (hydraulic lifts, excavators, mechanical presses) are excluded because the physical outcome is incidental to the mechanical action. Active human or animal motion (jumping, throwing, running) is excluded because the initial conditions (applied ...
-
[57]
The presentation order of videos is randomized independently for each annotator
Random Assignment and Presentation Order.When a subject enters our self-developed annotation platform, they are randomly assigned a subset of videos from the full video pool. The presentation order of videos is randomized independently for each annotator. These procedures reduce assignment bias, ordering effects, and carryover effects. Random assignment p...
-
[58]
Consent, Task Framing, and Demographic Information.Participants first review the consent form, study overview, voluntary-participation statement, and other required information. The task is described without revealing our hypotheses, and model identities are hidden from annotators. This design reduces the possibility that annotators adjust their ratings b...
-
[59]
Training Module.Before entering the main evaluation task, annotators complete a short training module. The module presents example videos that illustrate different levels of physical realism and explains how to apply the five-point Likert scale. This step helps annotators understand the distinction between visual plausibility and physical correctness. It ...
-
[60]
Rating Procedure.Each video must be watched at least once before rating. Annotators evaluate three general dimensions, semantic alignment, physical temporal validity, and object persistence, as well as the applicable physical laws for that video. The rating design asks annotators to assess observable visual evidence rather than solve physics equations or ...
-
[61]
Score Constancy: The standard deviation of an annotator’s scores. std= 0 means assigning the same score to every dimension of every video and provides no discriminating information whatsoever; std<0.3 is treated as near-constant
-
[62]
Per-video Copy-paste Rate: Whether the annotator gives identical scores to all dimensions within each video. A 100% copy-paste rate means the annotator does not differentiate evaluation dimensions (e.g., gravity vs. collision), so the labels should be treated as invalid even when the annotator’s cross-video overall std is greater than zero. This signal is...
-
[63]
Peer MAE: The mean absolute deviation between an annotator’s scores and those of other annotators on the same video-dimension cells, averaged over all pairwise comparisons in which the annotator participated. On the 1–5 scale, peer MAE values above 1.8 are flagged as extreme, corresponding to disagreeing with peers by nearly two scale points on average; t...
-
[64]
Behavioral Signals: Two platform-side signals are recorded for every annotation submission.Page stay timeis the elapsed seconds between page load and rating submission; the median across an annotator’s submissions below 30 seconds is treated as short stay (the videos themselves are typically several seconds long, and rating 3 general dimensions plus 2–4 p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.