Recognition: no theorem link
Boosting Omni-Modal Language Models: Staged Post-Training with Visually Debiased Evaluation
Pith reviewed 2026-05-15 06:02 UTC · model grok-4.3
The pith
A three-stage post-training recipe enables a 3B omni-modal model to match or slightly surpass a 30B model on benchmarks that filter out visual shortcuts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that after the final stage of supervised fine-tuning on self-distilled data within the OmniBoost pipeline, the 3B model attains performance levels that are comparable to, and in aggregate slightly above, those of the 30B model on OmniClean without employing a stronger omni-modal teacher.
What carries the argument
OmniBoost, the three-stage post-training recipe of mixed bi-modal SFT, mixed-modality RLVR, and SFT on self-distilled data, evaluated under the OmniClean benchmark created by removing visually solvable queries via visual-only probing.
Load-bearing premise
That filtering via visual-only probing removes only shortcut queries while keeping those that truly need audio-visual-language integration, and that self-distilled data offers useful supervision free of new biases or circularity.
What would settle it
The 3B model failing to reach comparable performance to the 30B model on OmniClean after completing the self-distillation stage, or the self-distilled data leading to degraded results on original unfiltered queries due to introduced biases.
Figures










read the original abstract
Omni-modal language models are intended to jointly understand audio, visual inputs, and language, but benchmark gains can be inflated when visual evidence alone is enough to answer a query. We study whether current omni-modal benchmarks separate visual shortcuts from genuine audio-visual-language evidence integration, and how post-training behaves under a visually debiased evaluation setting. We audit nine omni-modal benchmarks with visual-only probing, remove visually solvable queries, and retain full subsets when filtering is undefined or would make comparisons unstable. This yields OmniClean, a cleaned evaluation view with 8,551 retained queries from 16,968 audited queries. On OmniClean, we evaluate OmniBoost, a three-stage post-training recipe based on Qwen2.5-Omni-3B: mixed bi-modal SFT, mixed-modality RLVR, and SFT on self-distilled data. Balanced bi-modal SFT gives limited and uneven gains, RLVR provides the first broad improvement, and self-distillation reshapes the benchmark profile. After SFT on self-distilled data, the 3B model reaches performance comparable to, and in aggregate slightly above, Qwen3-Omni-30B-A3B-Instruct without using a stronger omni-modal teacher. These results show that omni-modal progress is easier to interpret when evaluation controls visual leakage, and that small omni-modal models can benefit from staged post-training with self-distilled omni-query supervision. Project page: https://cheliu-computation.github.io/omni/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that auditing nine omni-modal benchmarks via visual-only probing yields OmniClean (8,551 retained queries from 16,968), a visually debiased evaluation set. It then presents OmniBoost, a three-stage post-training pipeline on Qwen2.5-Omni-3B (mixed bi-modal SFT, mixed-modality RLVR, and final SFT on self-distilled data) that enables the 3B model to reach aggregate performance comparable to or slightly above Qwen3-Omni-30B-A3B-Instruct on OmniClean without a stronger teacher.
Significance. If the results hold, the work is significant for establishing a practical method to control visual leakage in omni-modal benchmarks and for showing that staged post-training with self-distillation can let small models match much larger ones. The creation of OmniClean itself supplies a reusable, audited resource that could improve interpretability of future omni-modal progress.
major comments (2)
- [Abstract and §3] Abstract and §3 (OmniBoost pipeline): The decisive performance lift is attributed to the final self-distillation SFT stage, yet the protocol is underspecified—no details appear on query selection from the bi-modal/RLVR checkpoints, response generation parameters (temperature, top-p, or sampling), or filtering to ensure queries genuinely require audio-visual integration. This is load-bearing for the central claim that gains reflect new cross-modal reasoning rather than distribution alignment with OmniClean.
- [§4] §4 (Experiments): The abstract states that the 3B model reaches performance comparable to the 30B model in aggregate after self-distillation, but reports no per-stage ablations, error bars, exact retained query counts per original benchmark, or statistical significance tests. Without these, the moderate soundness of the headline result cannot be fully evaluated.
minor comments (2)
- [Abstract] The abstract introduces 'OmniClean' and 'OmniBoost' without a one-sentence parenthetical definition; adding this would improve immediate readability for readers scanning the paper.
- [§2 or §4] Table or figure captions for the OmniClean statistics (8,551/16,968) should explicitly list the nine source benchmarks and the fraction removed per benchmark to allow direct replication of the filtering step.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We appreciate the emphasis on clarifying the self-distillation protocol and enhancing the experimental reporting. Below, we provide point-by-point responses to the major comments and describe the revisions we will make to address them.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (OmniBoost pipeline): The decisive performance lift is attributed to the final self-distillation SFT stage, yet the protocol is underspecified—no details appear on query selection from the bi-modal/RLVR checkpoints, response generation parameters (temperature, top-p, or sampling), or filtering to ensure queries genuinely require audio-visual integration. This is load-bearing for the central claim that gains reflect new cross-modal reasoning rather than distribution alignment with OmniClean.
Authors: We thank the referee for pointing this out. The self-distillation protocol was described at a high level in the original submission, but we recognize the need for greater specificity. In the revised manuscript, we will expand §3 to include full details on query selection criteria from the bi-modal and RLVR checkpoints, the exact generation parameters (including temperature, top-p, and sampling strategy), and the filtering mechanism used to ensure queries require audio-visual integration. This will strengthen the evidence that the performance gains reflect genuine improvements in cross-modal reasoning. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract states that the 3B model reaches performance comparable to the 30B model in aggregate after self-distillation, but reports no per-stage ablations, error bars, exact retained query counts per original benchmark, or statistical significance tests. Without these, the moderate soundness of the headline result cannot be fully evaluated.
Authors: We agree that additional analyses are warranted. In the revision, we will add per-stage ablation results, report error bars from multiple runs, include exact retained query counts per benchmark in a supplementary table, and perform statistical significance tests to support the headline comparisons. These changes will be incorporated into §4 and the appendix. revision: yes
Circularity Check
No significant circularity; staged post-training evaluated on independent OmniClean benchmark
full rationale
The paper's central claims rest on empirical results from a three-stage pipeline (bi-modal SFT, RLVR, then SFT on self-distilled data) measured against the externally constructed OmniClean subset, which is obtained by visual-only probing of nine existing benchmarks followed by filtering. No equations, parameter fits, or self-citations are shown that reduce the reported performance gains (including the 3B model matching or exceeding the 30B baseline) to tautological redefinitions or inputs defined by the same data. Self-distillation generates supervision from the model's own outputs, but the evaluation set remains an audited external hold-out whose construction does not incorporate the training queries or responses, preserving independence. This matches the default expectation that most papers exhibit no circularity when the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, et al. Qwen2.5-omni technical report, 2025. URLhttps://arxiv.org/abs/2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, et al. Qwen3-omni technical report, 2025. URLhttps://arxiv.org/abs/2509.17765
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Humanomniv2: From understanding to omni-modal reasoning with context, 2025
Qize Yang, Shimin Yao, Weixuan Chen, Shenghao Fu, Detao Bai, Jiaxing Zhao, Boyuan Sun, Bowen Yin, Xihan Wei, and Jingren Zhou. Humanomniv2: From understanding to omni-modal reasoning with context, 2025. URL https://arxiv.org/ abs/2506.21277
-
[4]
Nexus-o: An omni-perceptive and -interactive model for language, audio, and vision
Che Liu, Yingji Zhang, Dong Zhang, Weijie Zhang, Chenggong Gong, Yu Lu, Shilin Zhou, Ziliang Gan, Ziao Wang, Haipang Wu, Ji Liu, Andre Freitas, Qifan Wang, Zenglin Xu, Rongjunchen Zhang, and Yong Dai. Nexus-o: An omni-perceptive and -interactive model for language, audio, and vision. InProceedings of the 33rd ACM International Conference on Multimedia, pa...
-
[5]
Don’t just assume; look and answer: Overcoming priors for visual question answering
Aishwarya Agrawal, Dhruv Batra, Devi Parikh, and Aniruddha Kembhavi. Don’t just assume; look and answer: Overcoming priors for visual question answering. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4971–4980, 2018
work page 2018
-
[6]
Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities, 2025
Ziwei Zhou, Rui Wang, Zuxuan Wu, and Yu-Gang Jiang. Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities, 2025. URLhttps://arxiv.org/abs/2505.17862. 15 StepFun-Audio Team
-
[7]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback....
work page 2022
-
[8]
Self-Instruct: Aligning Language Models with Self-Generated Instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self- instruct: Aligning language models with self-generated instructions, 2022. URLhttps://arxiv.org/abs/2212.10560
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InProceedings of Conference on Neural Information Processing Systems, 2023
work page 2023
-
[10]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, et al. Dapo: An open-source llm reinforcement learning system at scale, 2025. URLhttps://arxiv.org/abs/2503.14476
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[14]
Sdrt: Enhance vision- language models by self-distillation with diverse reasoning traces, 2025
Guande Wu, Huan Song, Yawei Wang, Qiaojing Yan, Yijun Tian, Lin Lee Cheong, and Panpan Xu. Sdrt: Enhance vision- language models by self-distillation with diverse reasoning traces, 2025. URLhttps://arxiv.org/abs/2503.01754
-
[15]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava-video: Video instruction tuning with synthetic data, 2025. URLhttps://arxiv.org/abs/2410.02713
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Step-audio-r1 technical report, 2025
Fei Tian, Xiangyu Tony Zhang, Yuxin Zhang, Haoyang Zhang, Yuxin Li, Daijiao Liu, Yayue Deng, Donghang Wu, Jun Chen, Liang Zhao, Chengyuan Yao, Hexin Liu, Eng Siong Chng, Xuerui Yang, Xiangyu Zhang, Daxin Jiang, and Gang Yu. Step-audio-r1 technical report, 2025. URLhttps://arxiv.org/abs/2511.15848
-
[17]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b & gpt-oss-20b model card, 2025. URLhttps://arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Nemotron 3 nano omni: Efficient and open multimodal intelligence,
Amala Sanjay Deshmukh, Kateryna Chumachenko, Tuomas Rintamaki, Matthieu Le, Tyler Poon, Danial Mohseni Taheri, Ilia Karmanov, Guilin Liu, Jarno Seppanen, Arushi Goel, et al. Nemotron 3 nano omni: Efficient and open multimodal intelligence,
-
[20]
URLhttps://arxiv.org/abs/2604.24954
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency, 2025. URL https://arxiv.org/abs/2508.18265
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, et al. Molmo2: Open weights and data for vision-language models with video understanding and grounding, 2026. URLhttps://arxiv.org/abs/2601.10611
-
[23]
Step-audio: Unified understanding and generation in intelligent speech interaction, 2025
Ailin Huang, Boyong Wu, Bruce Wang, Chao Yan, Chen Hu, Chengli Feng, Fei Tian, Feiyu Shen, Jingbei Li, Mingrui Chen, et al. Step-audio: Unified understanding and generation in intelligent speech interaction, 2025. URL https://arxiv.org/ abs/2502.11946
-
[24]
Step-audio 2 technical report, 2025
Boyong Wu, Chao Yan, Chen Hu, Cheng Yi, Chengli Feng, Fei Tian, Feiyu Shen, Gang Yu, Haoyang Zhang, Jingbei Li, et al. Step-audio 2 technical report, 2025. URLhttps://arxiv.org/abs/2507.16632
-
[25]
Step-Audio-R1.5 Technical Report
Yuxin Zhang, Xiangyu Tony Zhang, Daijiao Liu, Fei Tian, Yayue Deng, Jun Chen, Qingjian Lin, Haoyang Zhang, Yuxin Li, Jinglan Gong, et al. Step-audio-r1.5 technical report, 2026. URLhttps://arxiv.org/abs/2604.25719
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
arXiv preprint arXiv:2502.04326 (2025)
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluating real-world omnimodal understanding for multimodal llms, 2025. URLhttps://arxiv.org/abs/2502.04326. 16 StepFun-Audio Team
-
[27]
Omnibench: Towards the future of universal omni-language models, 2025
Yizhi Li, Yinghao Ma, Ge Zhang, Ruibin Yuan, Kang Zhu, Hangyu Guo, Yiming Liang, Jiaheng Liu, Zekun Wang, Jian Yang, Siwei Wu, Xingwei Qu, Jinjie Shi, Xinyue Zhang, Zhenzhu Yang, Yidan Wen, Yanghai Wang, Shihao Li, Zhaoxiang Zhang, Zachary Liu, Emmanouil Benetos, Wenhao Huang, and Chenghua Lin. Omnibench: Towards the future of universal omni-language mode...
-
[28]
Av-odyssey bench: Can your multimodal llms really understand audio-visual information?,
Kaixiong Gong, Kaituo Feng, Bohao Li, Yibing Wang, Mofan Cheng, Shijia Yang, Jiaming Han, Benyou Wang, Yutong Bai, Zhuoran Yang, and Xiangyu Yue. Av-odyssey bench: Can your multimodal llms really understand audio-visual information?,
- [29]
-
[30]
Video-holmes: Can MLLM think like holmes for complex video reasoning?CoRR, abs/2505.21374, 2025
Junhao Cheng, Yuying Ge, Teng Wang, Yixiao Ge, Jing Liao, and Ying Shan. Video-holmes: Can mllm think like holmes for complex video reasoning?, 2025. URLhttps://arxiv.org/abs/2505.21374
-
[31]
Chen Chen, ZeYang Hu, Fengjiao Chen, Liya Ma, Jiaxing Liu, Xiaoyu Li, Ziwen Wang, Xuezhi Cao, and Xunliang Cai. Uno-bench: A unified benchmark for exploring the compositional law between uni-modal and omni-modal in omni models,
- [32]
-
[33]
Av-reasoner: Improving and benchmarking clue-grounded audio-visual counting for mllms, 2025
Lidong Lu, Guo Chen, Zhiqi Li, Yicheng Liu, and Tong Lu. Av-reasoner: Improving and benchmarking clue-grounded audio-visual counting for mllms, 2025. URLhttps://arxiv.org/abs/2506.05328
-
[34]
Omnivideobench: Towards audio-visual understanding evaluation for omni mllms, 2025
Caorui Li, Yu Chen, Yiyan Ji, Jin Xu, Zhenyu Cui, Shihao Li, Yuanxing Zhang, Wentao Wang, Zhenghao Song, Dingling Zhang, Ying He, Haoxiang Liu, Yuxuan Wang, Qiufeng Wang, Jiafu Tang, Zhenhe Wu, Jiehui Luo, Zhiyu Pan, Weihao Xie, Chenchen Zhang, Zhaohui Wang, Jiayi Tian, Yanghai Wang, Zhe Cao, Minxin Dai, Ke Wang, Runzhe Wen, Yinghao Ma, Yaning Pan, Sungky...
-
[35]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl-rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning.arXiv preprint arXiv:2504.08837, 2025
work page internal anchor Pith review arXiv 2025
-
[38]
Zhongwei Wan, Zhihao Dou, Che Liu, Yu Zhang, Dongfei Cui, Qinjian Zhao, Hui Shen, Jing Xiong, Yi Xin, Yifan Jiang, et al. Srpo: Enhancing multimodal llm reasoning via reflection-aware reinforcement learning.arXiv preprint arXiv:2506.01713, 2025
-
[39]
Jiaqi Wang, Kevin Qinghong Lin, James Cheng, and Mike Zheng Shou. Think or not? selective reasoning via reinforcement learning for vision-language models.arXiv preprint arXiv:2505.16854, 2025
-
[40]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms, 2025. URLhttps://arxiv.org/abs/2503.21776
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Videoauto-r1: Video auto reasoning via thinking once, answering twice, 2026
Shuming Liu, Mingchen Zhuge, Changsheng Zhao, Jun Chen, Lemeng Wu, Zechun Liu, Chenchen Zhu, Zhipeng Cai, Chong Zhou, Haozhe Liu, Ernie Chang, Saksham Suri, Hongyu Xu, Qi Qian, Wei Wen, Balakrishnan Varadarajan, Zhuang Liu, Hu Xu, Florian Bordes, Raghuraman Krishnamoorthi, Bernard Ghanem, Vikas Chandra, and Yunyang Xiong. Videoauto-r1: Video auto reasonin...
-
[42]
Sharegpt4video: Improving video understanding and generation with better captions, 2024
Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Bin Lin, Zhenyu Tang, Li Yuan, Yu Qiao, Dahua Lin, Feng Zhao, and Jiaqi Wang. Sharegpt4video: Improving video understanding and generation with better captions, 2024. URLhttps://arxiv.org/abs/2406.04325
-
[43]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi, 2024. URL https://arxiv. org/abs/2311.16502
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, and Graham Neubig. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark, 2024. URLhttps://arxiv.org/abs/2409.02813
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts, 2023. URL https://arxiv.org/abs/2310.02255
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Measuring multimodal mathematical reasoning with MATH-Vision dataset, 2024
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with MATH-Vision dataset, 2024. URLhttps://arxiv.org/abs/2402.14804
-
[48]
A Diagram Is Worth A Dozen Images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images, 2016. URLhttps://arxiv.org/abs/1603.07396
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[49]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning, 2022
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning, 2022. URLhttps://arxiv.org/abs/2203.10244. 17 StepFun-Audio Team
-
[50]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, and Feng Zhao. Are we on the right way for evaluating large vision-language models?, 2024. URL https://arxiv.org/ abs/2403.20330
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Pravesh Agrawal, Szymon Antoniak, Emma Bou Hanna, Baptiste Bout, Devendra Chaplot, Jessica Chudnovsky, Diogo Costa, Baudouin De Monicault, Saurabh Garg, Theophile Gervet, Soham Ghosh, Amelie Heliou, Paul Jacob, Albert Q. Jiang, Kartik Khandelwal, Timothee Lacroix, Guillaume Lample, Diego Las Casas, Thibaut Lavril, Teven Le Scao, Andy Lo, William Marshall,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, Ran He, and Xing Sun. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis, 202...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Sd-qa: Spoken dialectal question answering for the real world
Fahim Faisal, Sharlina Keshava, Md Mahfuz ibn Alam, and Antonios Anastasopoulos. Sd-qa: Spoken dialectal question answering for the real world. InFindings of the Association for Computational Linguistics: EMNLP 2021, pages 3296–3315,
work page 2021
-
[54]
URLhttps://aclanthology.org/2021.findings-emnlp.281/
work page 2021
-
[55]
Towards understanding chain-of-thought prompting: An empirical study of what matters
Dingdong Wang, Junan Li, Jincenzi Wu, Dongchao Yang, Xueyuan Chen, Tianhua Zhang, and Helen Meng. Mmsu: A massive multi-task spoken language understanding and reasoning benchmark, 2025. URLhttps://arxiv.org/abs/2506.04779
-
[56]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering, 2018. URLhttps://arxiv.org/abs/1809.02789
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[57]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction- following evaluation for large language models, 2023. URLhttps://arxiv.org/abs/2311.07911
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models, 2023. URLhttps://arxiv.org/abs/2307.15043
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
H., Pasad, A., Casanova, E., Wang, W., Fu, S.-W., Li, J., Chen, Z., Balam, J., et al
Yiming Chen, Xianghu Yue, Chen Zhang, Xiaoxue Gao, Robby T. Tan, and Haizhou Li. V oicebench: Benchmarking llm-based voice assistants, 2024. URLhttps://arxiv.org/abs/2410.17196
-
[60]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
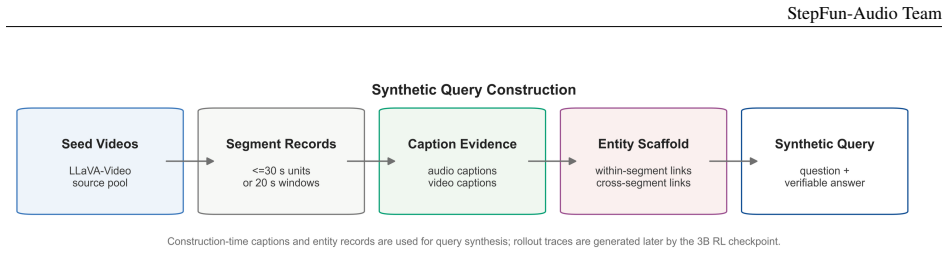
S Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. Mmau: A massive multi-task audio understanding and reasoning benchmark, 2024. URL https://arxiv.org/abs/2410.19168. A Detailed Synthetic Query Graphic Description B Full Section 3 Regression Plots (a) Daily-Omni: Vi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.