Recognition: no theorem link
CA2: Code-Aware Agent for Automated Game Testing
Pith reviewed 2026-05-15 05:49 UTC · model grok-4.3
The pith
Reinforcement learning agents that observe call stack traces test games more effectively than agents limited to game state alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
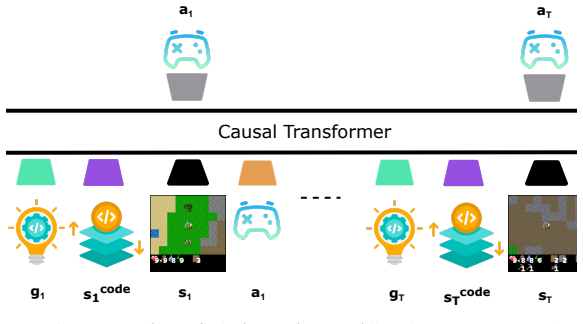
CA2 receives the current function call trace along with the game state and learns to reach specific target functions. In instrumented state-based and image-based environments, this code-aware agent achieves consistent improvement over non-code-aware baselines that do not leverage call stack information.
What carries the argument
The call stack trace supplied as an additional observation signal that lets the reinforcement learning policy learn targeted paths to specific code functions.
Load-bearing premise
That supplying the call stack produces a genuine improvement in the learned testing policy rather than an artifact of the chosen games or reward design.
What would settle it
Reproducing the experiments in additional game environments where adding the call stack trace produces no measurable increase in the rate at which target functions are reached or in code coverage achieved.
Figures

read the original abstract
Automated game testing is important for verifying game functionality, but it remains a costly and time-consuming process. Manual testing often misses edge cases, and current automated methods struggle to provide full code coverage. Prior work has explored reinforcement learning (RL) for game testing, but without leveraging internal code signals such as the call stack. We present Code Aware Agent (CA2), which uses call stack information to learn effective testing strategies. The agent receives the current function call trace along with the game state and learns to reach specific target functions. We instrument two types of environments, 1) State-based and 2) Image-based, with support for efficient call stack extraction. Through experimental evaluation, we find that CA2 achieves consistent improvement over the non-code aware baselines, which does not leverage call stack information. Our results show that incorporating code signals like the call stack enables more effective and targeted game testing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CA2, a reinforcement learning agent for automated game testing that augments the observation space with call-stack traces extracted from instrumented game code. The agent is trained to reach specific target functions in two environment types (state-based and image-based) and is reported to achieve consistent improvement over non-code-aware baselines that lack access to call-stack signals.
Significance. If the experimental claims are substantiated with quantitative metrics and controls, the work would demonstrate a practical way to inject internal program state into RL-based testing agents, potentially raising code coverage and reducing manual effort in game verification pipelines.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experimental Evaluation): the claim of 'consistent improvement' is stated without any numerical metrics, confidence intervals, statistical tests, or environment specifications (e.g., number of games, episodes, or coverage percentages), rendering the central empirical claim unverifiable from the provided text.
- [§3 and §4] §3 (Method) and §4: no ablation is described that removes the call-stack channel while holding reward function, instrumentation, and observation dimensionality constant; without this control it is impossible to rule out that measured gains arise from reward shaping or instrumentation artifacts rather than genuine policy conditioning on call-stack features.
- [§3.2] §3.2 (Environment Instrumentation): the paper asserts 'efficient call stack extraction' but supplies no runtime overhead measurements, extraction latency figures, or scaling behavior with call depth, leaving the practicality claim unsupported.
minor comments (2)
- [§3.1] Notation for the call-trace representation (e.g., whether it is a sequence, set, or embedding) is introduced without a formal definition or example in §3.1.
- [Abstract] The abstract and introduction use 'consistent improvement' without defining the metric (coverage, time-to-target, or reward) against which improvement is measured.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the opportunity to clarify and strengthen our manuscript. We address each major point below and will incorporate revisions to improve verifiability and rigor.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Evaluation): the claim of 'consistent improvement' is stated without any numerical metrics, confidence intervals, statistical tests, or environment specifications (e.g., number of games, episodes, or coverage percentages), rendering the central empirical claim unverifiable from the provided text.
Authors: We agree that the abstract and §4 would benefit from explicit quantitative details to make the central claims verifiable. The experiments in §4 were conducted on two environment types with multiple target functions, reporting coverage percentages, success rates, and episode counts for CA2 versus baselines. In the revision we will update the abstract to include specific metrics (e.g., average coverage improvement and standard deviation across runs) and add confidence intervals plus statistical tests (paired t-tests) to the results tables and text in §4. revision: yes
-
Referee: [§3 and §4] §3 (Method) and §4: no ablation is described that removes the call-stack channel while holding reward function, instrumentation, and observation dimensionality constant; without this control it is impossible to rule out that measured gains arise from reward shaping or instrumentation artifacts rather than genuine policy conditioning on call-stack features.
Authors: The non-code-aware baselines already share the identical reward function and instrumentation; they differ solely by the absence of the call-stack input. To additionally control for observation dimensionality, we will add an explicit ablation in the revised §4 in which the call-stack channel is replaced by a dummy vector of identical dimension (zero-filled or random noise) while keeping all other components fixed. This will isolate the contribution of the actual call-stack features. revision: yes
-
Referee: [§3.2] §3.2 (Environment Instrumentation): the paper asserts 'efficient call stack extraction' but supplies no runtime overhead measurements, extraction latency figures, or scaling behavior with call depth, leaving the practicality claim unsupported.
Authors: We acknowledge that no quantitative overhead figures were supplied. During our experiments we recorded extraction latencies; in the revision we will add a short analysis (new paragraph or table in §3.2) reporting average per-step extraction time, overhead as a percentage of simulation time, and scaling across call depths up to the maximum observed in the test games. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical RL agent (CA2) that augments game-state observations with call-stack traces and compares performance against non-code-aware baselines across instrumented environments. No equations, parameter-fitting steps, or derivation chains are described that would reduce any claimed result to its inputs by construction. The central claim rests on reported experimental improvements rather than any self-definitional, fitted-input, or self-citation reduction; the evaluation is therefore self-contained against external benchmarks and receives a score of 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C. Politowski, F. Petrillo, and Y.-G. Guéhéneuc.A Survey of Video Game Testing. 2021. arXiv:2103.06431 [cs.SE].url:https://arxiv.org/abs/2103.06431
-
[2]
Technical Challenges of Deploying Reinforcement Learning Agents for Game Testing in AAA Games
J. Gillberg, J. Bergdahl, A. Sestini, A. Eakins, and L. Gisslén. “Technical Challenges of Deploying Reinforcement Learning Agents for Game Testing in AAA Games”. In:2023 IEEE Conference on Games (CoG). 2023.doi:10.1109/CoG57401.2023.10333194
-
[3]
Playing Atari with Deep Reinforcement Learning
V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Ried- miller. “Playing atari with deep reinforcement learning”. In:arXiv preprint arXiv:1312.5602 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[4]
Mastering Diverse Domains through World Models
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap.Mastering Diverse Domains through World Models. 2024. arXiv:2301.04104 [cs.AI].url:https://arxiv.org/abs/2301.04104
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
C. Gordillo, J. Bergdahl, K. Tollmar, and L. Gisslén.Improving Playtesting Coverage via Curiosity Driven Reinforcement Learning Agents. 2021. arXiv:2103 . 13798 [cs.LG].url: https://arxiv.org/abs/2103.13798
-
[6]
Automated Game- play Testing and Validation With Curiosity-Conditioned Proximal Trajectories
A. Sestini, L. Gisslén, J. Bergdahl, K. Tollmar, and A. D. Bagdanov. “Automated Game- play Testing and Validation With Curiosity-Conditioned Proximal Trajectories”. In:IEEE Transactions on Games16.1 (2024), pp. 113–126.doi:10.1109/TG.2022.3226910
- [7]
-
[8]
G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba. “Openai gym”. In:arXiv preprint arXiv:1606.01540(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[9]
E. Beeching, J. Debangoye, O. Simonin, and C. Wolf.Godot Reinforcement Learning Agents
- [10]
-
[11]
Hafner.Benchmarking the Spectrum of Agent Capabilities
D. Hafner.Benchmarking the Spectrum of Agent Capabilities. 2022. arXiv:2109 . 06780 [cs.AI].url:https://arxiv.org/abs/2109.06780
-
[12]
GLIB: towards automated test oracle for graphically-rich applications
K. Chen, Y. Li, Y. Chen, C. Fan, Z. Hu, and W. Yang. “GLIB: towards automated test oracle for graphically-rich applications”. In:Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. ESEC/FSE ’21. ACM, Aug. 2021, 1093–1104.doi:10.1145/3468264.3468586. url:http://dx.d...
-
[13]
Grandmaster level in StarCraft II using multi-agent reinforcement learning
O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. H. Choi, R. Powell, T. Ewalds, P. Georgiev, et al. “Grandmaster level in StarCraft II using multi-agent reinforcement learning”. In:nature575.7782 (2019), pp. 350–354
work page 2019
-
[14]
S. Lifshitz, K. Paster, H. Chan, J. Ba, and S. McIlraith.STEVE-1: A Generative Model for Text-to-Behavior in Minecraft. 2024. arXiv:2306.00937 [cs.AI].url:https://arxiv.org/ abs/2306.00937
-
[15]
S. Qi, S. Chen, Y. Li, X. Kong, J. Wang, B. Yang, P. Wong, Y. Zhong, X. Zhang, Z. Zhang, N. Liu, W. Wang, Y. Yang, and S.-C. Zhu.CivRealm: A Learning and Reasoning Odyssey in Civilization for Decision-Making Agents. 2024. arXiv:2401.10568 [cs.AI].url:https: //arxiv.org/abs/2401.10568
- [16]
-
[17]
Team et al.Scaling Instructable Agents Across Many Simulated Worlds
S. Team et al.Scaling Instructable Agents Across Many Simulated Worlds. 2024. arXiv:2404. 10179 [cs.RO].url:https://arxiv.org/abs/2404.10179
-
[18]
G. Wang, Y. Xie, Y. Jiang, A. Mandlekar, C. Xiao, Y. Zhu, L. Fan, and A. Anandkumar. Voyager: An Open-Ended Embodied Agent with Large Language Models. 2023. arXiv:2305. 16291 [cs.AI].url:https://arxiv.org/abs/2305.16291
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein.Generative Agents: Interactive Simulacra of Human Behavior. 2023. arXiv:2304.03442 [cs.HC].url: https://arxiv.org/abs/2304.03442
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
LeveragingLLMAgentsforAutomated Video Game Testing
C.Wang,L.Tang,M.Yuan,J.Yu,X.Xie,andJ.Bu.“LeveragingLLMAgentsforAutomated Video Game Testing”. In:arXiv preprint arXiv:2509.22170(2025)
-
[21]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Y. Qin et al.UI-TARS: Pioneering Automated GUI Interaction with Native Agents. 2025. arXiv:2501.12326 [cs.AI].url:https://arxiv.org/abs/2501.12326
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Wuji: Automatic Online Combat Game Testing Using Evolutionary Deep Reinforcement Learning
Y. Zheng, X. Xie, T. Su, L. Ma, J. Hao, Z. Meng, Y. Liu, R. Shen, Y. Chen, and C. Fan. “Wuji: Automatic Online Combat Game Testing Using Evolutionary Deep Reinforcement Learning”. In:2019 34th IEEE/ACM International Conference on Automated Software En- gineering (ASE). 2019, pp. 772–784.doi:10.1109/ASE.2019.00077
-
[23]
Visualizing AI Playtesting Data of 2D Side-scrolling Games
S. Agarwal, C. Herrmann, G. Wallner, and F. Beck. “Visualizing AI Playtesting Data of 2D Side-scrolling Games”. In:2020 IEEE Conference on Games (CoG). 2020, pp. 572–575.doi: 10.1109/CoG47356.2020.9231915
-
[24]
J. Bergdahl, C. Gordillo, K. Tollmar, and L. Gisslén.Augmenting Automated Game Testing with Deep Reinforcement Learning. 2021. arXiv:2103.15819 [cs.LG].url:https://arxiv. org/abs/2103.15819
-
[25]
Automated Play-Testing through RL Based Human-Like Play-Styles Generation
P. Le Pelletier de Woillemont, R. Labory, and V. Corruble. “Automated Play-Testing through RL Based Human-Like Play-Styles Generation”. In:Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment18.1 (Oct. 2022), 146–154.issn: 2326-909X.doi:10.1609/aiide.v18i1.21958.url:http://dx.doi.org/10.1609/aiide. v18i1.21958
work page doi:10.1609/aiide.v18i1.21958.url:http://dx.doi.org/10.1609/aiide 2022
- [26]
- [27]
-
[28]
I.Kostrikov,A.Nair,andS.Levine.Offline Reinforcement Learning with Implicit Q-Learning
-
[29]
arXiv:2110.06169 [cs.LG].url:https://arxiv.org/abs/2110.06169
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
S. Fujimoto and S. S. Gu.A Minimalist Approach to Offline Reinforcement Learning. 2021. arXiv:2106.06860 [cs.LG].url:https://arxiv.org/abs/2106.06860
-
[31]
Decision transformer: Reinforcement learning via sequence modeling
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch. “Decision transformer: Reinforcement learning via sequence modeling”. In:Ad- vances in neural information processing systems34 (2021), pp. 15084–15097
work page 2021
-
[32]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin.Attention Is All You Need. 2023. arXiv:1706.03762 [cs.CL].url:https: //arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
J. L. Ba, J. R. Kiros, and G. E. Hinton.Layer Normalization. 2016. arXiv:1607 . 06450 [stat.ML].url:https://arxiv.org/abs/1607.06450. AppendixA.CA2 ADDITIONAL DETAILS A.1.HYPERP ARAMETERS We present the hyperparameters (Table 5) used for training our Decision Transformer with Code-Aware Agent (GC-DT-CA2) agent. This configuration reflects design choices t...
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.