Probing into Camera Control of Video Models
Pith reviewed 2026-06-30 21:08 UTC · model grok-4.3
The pith
Video diffusion models gain camera control by resampling latent features with geometric displacement fields during denoising, without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Camera control need not be modeled as an implicit mapping problem but can instead be treated as a form of geometric guidance that induces displacements across frames. We reformulate camera control into a set of displacement fields and apply them via differentiable resampling of latent features during denoising. Our simple approach achieves effective camera control with minimal degradation across diverse quality metrics compared to fine-tuned baselines and serves as a probe to study the camera control capabilities of base models, identifying universal biases and benchmarking multi-view generation.
What carries the argument
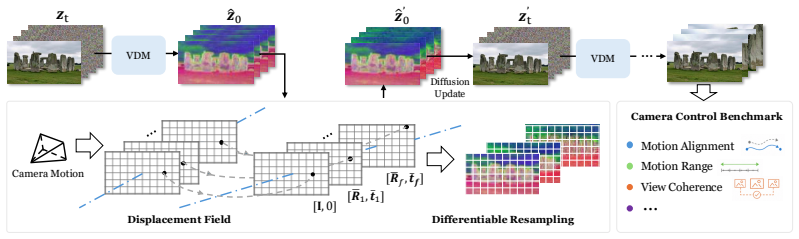
Differentiable resampling of latent features guided by camera-induced displacement fields computed from 3D geometry, inserted into the denoising loop of a pretrained video diffusion model.
If this is right
- Effective camera control is possible on most video diffusion models without any training or paired camera data.
- Quality degradation stays minimal across standard metrics relative to models that were fine-tuned for camera control.
- The same procedure reveals shared biases in how different base models respond to camera instructions.
- The method provides a direct benchmark for multi-view generation performance relevant to 3D and 4D tasks.
Where Pith is reading between the lines
- The resampling technique could be tested on other controllable signals such as object trajectories or lighting changes.
- Models that respond cleanly to this geometric probe may be preferable starting points for downstream 3D reconstruction pipelines.
- The approach supplies a lightweight way to diagnose and compare geometric consistency across families of video generators.
Load-bearing premise
Displacement fields derived from 3D camera geometry can be applied to the latent features of a pretrained diffusion model without breaking its generative prior or creating artifacts the base model cannot correct.
What would settle it
Run the resampling method on a base video model with a known camera trajectory and measure whether the output video exhibits the exact intended camera motion while its quality scores remain within a small margin of the uncontrolled model; failure would appear as mismatched motion or visible artifacts.
Figures



read the original abstract
Video is a rich and scalable source of 3D/4D visual observations, and camera control is a key capability for video generation models to produce geometrically meaningful content. Existing approaches typically learn a mapping from camera motion to video using additional camera modules and paired data. However, such datasets are often limited in scale, diversity, and scene dynamics, which can bias the model toward a narrow output distribution and compromise the strong prior learned by the base model. These limitations motivate a different perspective on camera control. In this paper, we show that camera control need not be modeled as an implicit mapping problem, but can instead be treated as a form of geometric guidance that induces displacements across frames. Specifically, we reformulate camera control into a set of displacement fields and apply them via differentiable resampling of latent features during denoising. Our simple approach achieves effective camera control with minimal degradation across diverse quality metrics compared to fine-tuned baselines. Since our method is applicable to most video diffusion models without training, it can also serve as a probe to study the camera control capabilities of base models. Using this probe, we identify universal biases shared by representative video models, as well as disparities in their responses to camera control. Finally, we benchmark their performance in multi-view generation, offering insights into their potential for 3D/4D tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that camera control in video diffusion models need not be learned as an implicit mapping but can instead be achieved training-free by reformulating camera motion as displacement fields derived from 3D geometry and applying them via differentiable resampling of latent features during each denoising step of a frozen model. This is reported to yield effective control with minimal degradation on quality metrics relative to fine-tuned baselines, while also serving as a probe to reveal universal biases and performance disparities across representative video models on multi-view generation tasks.
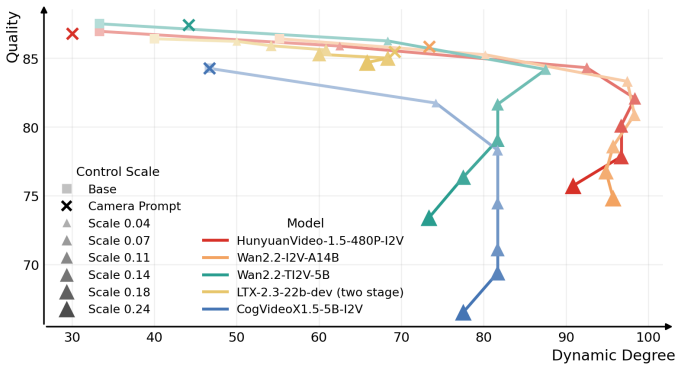
Significance. If the central mechanism holds, the work provides a simple, general, and data-efficient alternative to fine-tuning that preserves the base model's generative prior, which is a notable strength given the scarcity of diverse camera-paired video data. The probing experiments could offer diagnostic value for understanding limitations in current video diffusion models' 3D consistency, with potential implications for downstream 3D/4D applications.
major comments (2)
- [Method description (main text)] The load-bearing assumption that VAE latent features support geometric warps via differentiable resampling without breaking the generative prior or introducing uncorrectable artifacts (main method description) is not accompanied by analysis of how well the diffusion model compensates for non-equivariant encodings; the abstract provides no quantitative results on motion fidelity versus artifact levels across motion magnitudes or scene complexity, leaving attribution of 'minimal degradation' to the proposed geometric guidance unsupported.
- [Experiments section] The central claim of effective camera control via induced displacements (abstract and experiments) requires concrete details on the computation of displacement fields from 3D geometry and the exact resampling operation in latent space; without these, it remains unclear whether the reported results demonstrate geometric guidance or merely uncontrolled perturbations that the base model happens to accommodate.
minor comments (2)
- Notation for displacement fields and the resampling operator should be formalized with equations to improve reproducibility and clarity.
- Figure captions and axis labels in the probing experiments could be expanded to explicitly link observed biases to specific model architectures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying our approach and indicating revisions where appropriate to strengthen the presentation of the method and results.
read point-by-point responses
-
Referee: [Method description (main text)] The load-bearing assumption that VAE latent features support geometric warps via differentiable resampling without breaking the generative prior or introducing uncorrectable artifacts (main method description) is not accompanied by analysis of how well the diffusion model compensates for non-equivariant encodings; the abstract provides no quantitative results on motion fidelity versus artifact levels across motion magnitudes or scene complexity, leaving attribution of 'minimal degradation' to the proposed geometric guidance unsupported.
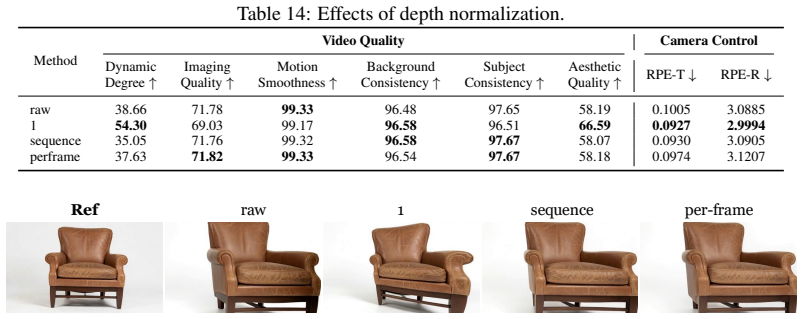
Authors: We agree that additional analysis of how the diffusion model compensates during denoising would strengthen the claims. Our experiments already report quality metrics close to fine-tuned baselines across multiple models and scenes, which indirectly supports that artifacts are mitigated, but we will add explicit quantification of motion fidelity (e.g., via optical flow consistency) versus artifact levels (e.g., FID/LPIPS breakdowns) stratified by motion magnitude and scene complexity to the method and experiments sections. The abstract will be updated to reference these supporting results. revision: yes
-
Referee: [Experiments section] The central claim of effective camera control via induced displacements (abstract and experiments) requires concrete details on the computation of displacement fields from 3D geometry and the exact resampling operation in latent space; without these, it remains unclear whether the reported results demonstrate geometric guidance or merely uncontrolled perturbations that the base model happens to accommodate.
Authors: The displacement fields are obtained by projecting 3D scene points (recovered via depth estimation) under the target camera poses using standard pinhole projection to derive per-pixel 2D flows between frames; the resampling applies differentiable bilinear grid sampling to the VAE latents at each denoising timestep, preserving differentiability for the frozen model. These steps are outlined in the method section, but we acknowledge the need for greater explicitness. We will revise the experiments section to include the full equations, a pseudocode listing of the resampling procedure, and an ablation confirming that random (non-geometric) perturbations yield substantially worse control, thereby demonstrating the geometric nature of the guidance. revision: yes
Circularity Check
No circularity; method is direct geometric application without reduction to inputs
full rationale
The paper presents camera control as geometric guidance via explicit displacement fields applied by differentiable resampling in latent space of a frozen pretrained model. No equations, fitted parameters, or self-citations are described that reduce the central claim to a definition or prior result by construction. The approach is framed as training-free and applicable to base models, with performance claims based on empirical comparison rather than self-referential derivation. This is a standard non-circular proposal of an inference-time technique.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Differentiable resampling of latent features during denoising can induce geometrically consistent frame displacements while preserving the base model's generative prior.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Ac3d: Analyzing and improving 3d camera control in video diffusion transformers
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Aliaksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B Lindell, and Sergey Tulyakov. Ac3d: Analyzing and improving 3d camera control in video diffusion transformers. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22875–22889, 2025
2025
-
[3]
Sherwin Bahmani, Ivan Skorokhodov, Aliaksandr Siarohin, Willi Menapace, Guocheng Qian, Michael Vasilkovsky, Hsin-Ying Lee, Chaoyang Wang, Jiaxu Zou, Andrea Tagliasacchi, et al. Vd3d: Taming large video diffusion transformers for 3d camera control.arXiv preprint arXiv:2407.12781, 2024
-
[4]
Recammaster: Camera-controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative rendering from a single video. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14834–14844, 2025
2025
-
[5]
Syncammaster: Synchronizing multi-camera video generation from diverse viewpoints
Jianhong Bai, Menghan Xia, Xintao Wang, Ziyang Yuan, Xiao Fu, Zuozhu Liu, Haoji Hu, Pengfei Wan, and Di Zhang. Syncammaster: Synchronizing multi-camera video generation from diverse viewpoints. arXiv preprint arXiv:2412.07760, 2024
-
[6]
Objaverse-xl: A universe of 10m+ 3d objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects. Advances in Neural Information Processing Systems, 36:35799–35813, 2023
2023
-
[7]
I2vcontrol-camera: Precise video camera control with adjustable motion strength
Wanquan Feng, Jiawei Liu, Pengqi Tu, Tianhao Qi, Mingzhen Sun, Tianxiang Ma, Songtao Zhao, Siyu Zhou, and Qian He. I2vcontrol-camera: Precise video camera control with adjustable motion strength. arXiv preprint arXiv:2411.06525, 2024
-
[8]
Kubric: A scalable dataset generator
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, et al. Kubric: A scalable dataset generator. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3749–3761, 2022
2022
-
[9]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Vfusion3d: Learning scalable 3d generative models from video diffusion models
Junlin Han, Filippos Kokkinos, and Philip Torr. Vfusion3d: Learning scalable 3d generative models from video diffusion models. InEuropean Conference on Computer Vision, pages 333–350. Springer, 2024
2024
-
[12]
Junlin Han, Jianyuan Wang, Andrea Vedaldi, Philip Torr, and Filippos Kokkinos. Flex3d: Feed-forward 3d generation with flexible reconstruction model and input view curation.arXiv preprint arXiv:2410.00890, 2024
-
[13]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Cameractrl ii: Dynamic scene exploration via camera-controlled video diffusion models
Hao He, Ceyuan Yang, Shanchuan Lin, Yinghao Xu, Meng Wei, Liangke Gui, Qi Zhao, Gordon Wetzstein, Lu Jiang, and Hongsheng Li. Cameractrl ii: Dynamic scene exploration via camera-controlled video diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13416–13426, 2025
2025
-
[15]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Training-free camera control for video generation.arXiv preprint arXiv:2406.10126, 2024
Chen Hou and Zhibo Chen. Training-free camera control for video generation.arXiv preprint arXiv:2406.10126, 2024. 10
-
[17]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[18]
Teng Hu, Jiangning Zhang, Ran Yi, Yating Wang, Hongrui Huang, Jieyu Weng, Yabiao Wang, and Lizhuang Ma. Motionmaster: Training-free camera motion transfer for video generation.arXiv preprint arXiv:2404.15789, 2024
-
[19]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[20]
Yanqin Jiang, Li Zhang, Jin Gao, Weimin Hu, and Yao Yao. Consistent4d: Consistent 360° dynamic object generation from monocular video.arXiv preprint arXiv:2311.02848, 2023
-
[21]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[22]
Collaborative video diffusion: Consistent multi-video generation with camera control.Advances in Neural Information Processing Systems, 37:16240–16271, 2024
Zhengfei Kuang, Shengqu Cai, Hao He, Yinghao Xu, Hongsheng Li, Leonidas J Guibas, and Gordon Wetzstein. Collaborative video diffusion: Consistent multi-video generation with camera control.Advances in Neural Information Processing Systems, 37:16240–16271, 2024
2024
-
[23]
Epipolar Geometry Improves Video Generation Models
Orest Kupyn, Fabian Manhardt, Federico Tombari, and Christian Rupprecht. Epipolar geometry improves video generation models.arXiv preprint arXiv:2510.21615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
2025
-
[25]
Vivid-zoo: Multi-view video generation with diffusion model.Advances in Neural Information Processing Systems, 37:62189–62222, 2024
Bing Li, Cheng Zheng, Wenxuan Zhu, Jinjie Mai, Biao Zhang, Peter Wonka, and Bernard Ghanem. Vivid-zoo: Multi-view video generation with diffusion model.Advances in Neural Information Processing Systems, 37:62189–62222, 2024
2024
-
[26]
Magic3d: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 300–309, 2023
2023
-
[27]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Towards understanding camera motions in any video.arXiv preprint arXiv:2504.15376, 2025
Zhiqiu Lin, Siyuan Cen, Daniel Jiang, Jay Karhade, Hewei Wang, Chancharik Mitra, Tiffany Ling, Yuhan Huang, Sifan Liu, Mingyu Chen, et al. Towards understanding camera motions in any video.arXiv preprint arXiv:2504.15376, 2025
-
[29]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024
2024
-
[30]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Zero- 1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl V ondrick. Zero- 1-to-3: Zero-shot one image to 3d object. InProceedings of the IEEE/CVF international conference on computer vision, pages 9298–9309, 2023
2023
-
[32]
Distinctive image features from scale-invariant keypoints.International journal of computer vision, 60(2):91–110, 2004
David G Lowe. Distinctive image features from scale-invariant keypoints.International journal of computer vision, 60(2):91–110, 2004
2004
-
[33]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhenheng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to-video generation.arXiv preprint arXiv:2407.02371, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 11
2021
-
[36]
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE transactions on pattern analysis and machine intelligence, 44(3):1623–1637, 2020
2020
-
[37]
Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. InProceedings of the IEEE/CVF international conference on computer vision, pages 10901–10911, 2021
2021
-
[38]
Gen3c: 3d-informed world-consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world-consistent video generation with precise camera control. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6121–6132, 2025
2025
-
[39]
Photorealistic text-to- image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to- image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
2022
-
[40]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020
2020
-
[41]
arXiv preprint arXiv:2411.04928 (2024)
Wenqiang Sun, Shuo Chen, Fangfu Liu, Zilong Chen, Yueqi Duan, Jun Zhang, and Yikai Wang. Dimen- sionx: Create any 3d and 4d scenes from a single image with controllable video diffusion.arXiv preprint arXiv:2411.04928, 2024
-
[42]
Hunyuanvideo 1.5 technical report, 2025
Tencent Hunyuan Foundation Model Team. Hunyuanvideo 1.5 technical report, 2025
2025
-
[43]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[44]
Sv3d: Novel multi-view synthesis and 3d generation from a single image using latent video diffusion
Vikram V oleti, Chun-Han Yao, Mark Boss, Adam Letts, David Pankratz, Dmitry Tochilkin, Christian Laforte, Robin Rombach, and Varun Jampani. Sv3d: Novel multi-view synthesis and 3d generation from a single image using latent video diffusion. InEuropean Conference on Computer Vision, pages 439–457. Springer, 2024
2024
-
[45]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[47]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
2024
-
[48]
Cat4d: Create anything in 4d with multi-view video diffusion models
Rundi Wu, Ruiqi Gao, Ben Poole, Alex Trevithick, Changxi Zheng, Jonathan T Barron, and Aleksander Holynski. Cat4d: Create anything in 4d with multi-view video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26057–26068, 2025
2025
-
[49]
Mingyang Xie, Numair Khan, Tianfu Wang, Naina Dhingra, Seonghyeon Nam, Haitao Yang, Zhuo Hui, Christopher Metzler, Andrea Vedaldi, Hamed Pirsiavash, et al. Lavr: Scene latent conditioned generative video trajectory re-rendering using large 4d reconstruction models.arXiv preprint arXiv:2601.14674, 2026
-
[50]
arXiv preprint arXiv:2407.17470 (2024)
Yiming Xie, Chun-Han Yao, Vikram V oleti, Huaizu Jiang, and Varun Jampani. Sv4d: Dynamic 3d content generation with multi-frame and multi-view consistency.arXiv preprint arXiv:2407.17470, 2024
-
[51]
Cavia: Camera-controllable multi-view video diffusion with view-integrated attention
Dejia Xu, Yifan Jiang, Chen Huang, Liangchen Song, Thorsten Gernoth, Liangliang Cao, Zhangyang Wang, and Hao Tang. Cavia: Camera-controllable multi-view video diffusion with view-integrated attention. arXiv preprint arXiv:2410.10774, 2024
-
[52]
CamCo: Camera-Controllable 3D-Consistent Image-to-Video Generation
Dejia Xu, Weili Nie, Chao Liu, Sifei Liu, Jan Kautz, Zhangyang Wang, and Arash Vahdat. Camco: Camera-controllable 3d-consistent image-to-video generation.arXiv preprint arXiv:2406.02509, 2024. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Meng You, Zhiyu Zhu, Hui Liu, and Junhui Hou. Nvs-solver: Video diffusion model as zero-shot novel view synthesizer.arXiv preprint arXiv:2405.15364, 2024
-
[55]
Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models
Mark Yu, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 100–111, 2025
2025
-
[56]
Motiondirector: Motion customization of text-to-video diffusion models
Rui Zhao, Yuchao Gu, Jay Zhangjie Wu, David Junhao Zhang, Jia-Wei Liu, Weijia Wu, Jussi Keppo, and Mike Zheng Shou. Motiondirector: Motion customization of text-to-video diffusion models. InEuropean Conference on Computer Vision, pages 273–290. Springer, 2024
2024
-
[57]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, et al. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Stereo Magnification: Learning View Synthesis using Multiplane Images
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images.arXiv preprint arXiv:1805.09817, 2018. 13 Appendix A Model configurations Table 6 summarizes the model configurations. Unlike prior works that rely on large-scale fine-tuning on curated datasets, our method is tra...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[59]
As a result, the ˆz0 signal in zt can become overly static, limiting the intrinsic dynamics synthesized by the pretrained model
CamTrol constructs warped frames from a single input image, such that subsequent frames are largely propagated from the first frame. As a result, the ˆz0 signal in zt can become overly static, limiting the intrinsic dynamics synthesized by the pretrained model. Instead, our method applies each displacement field independently to its corresponding frame. T...
-
[60]
More importantly, CamTrol relies on explicit point cloud reconstruction and inpainting pipelines to guide latent layout change. While such a formulation demonstrates that camera control can be induced through layout manipulation, the control signal itself is analytically constructed and tightly coupled with the external rendering pipeline, making direct e...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.