OASIS: Observation-Action Space Alignment via SE(3) Trajectory Prediction for Robotic Manipulation
Pith reviewed 2026-06-29 21:25 UTC · model grok-4.3
The pith
OASIS aligns observation and action spaces in robotic manipulation by conditioning the action decoder on hidden states from an SE(3) end-effector trajectory predictor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
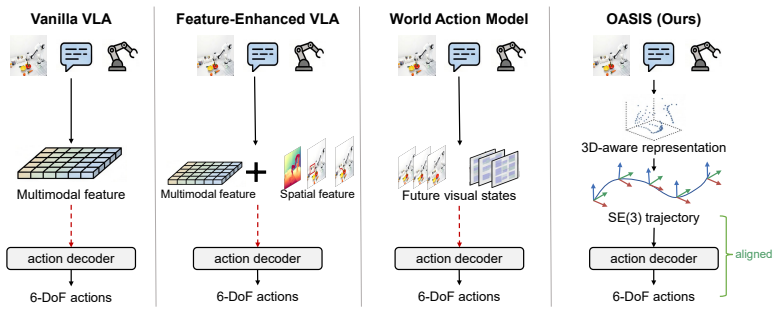
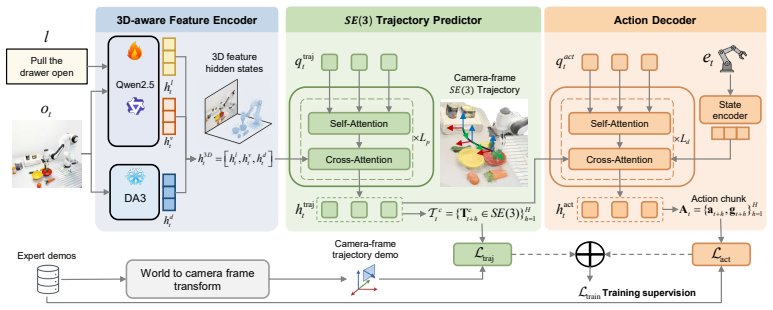
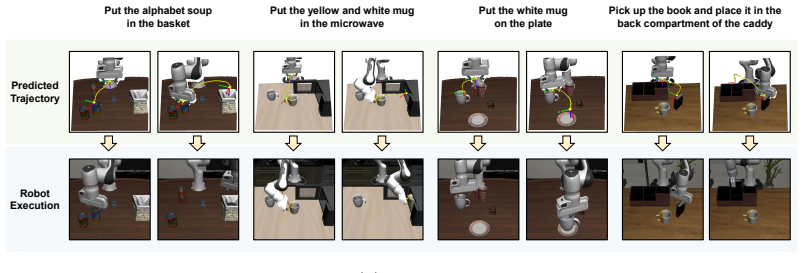
OASIS couples a 3D-aware feature encoder that fuses vision-language and metric-depth features with an SE(3) trajectory predictor that produces a camera-frame end-effector trajectory. Conditioned on the predictor's pose-supervised hidden states, the action decoder generates action chunks consistent with rigid-body motion. Across simulation and real-world experiments, OASIS outperforms VLA and WAM baselines in success rate and out-of-distribution generalization.
What carries the argument
The SE(3) trajectory predictor whose pose-supervised hidden states are used to condition the action decoder, thereby aligning intermediate representations with the rigid-body geometry of the action space.
If this is right
- Action chunks are generated already consistent with SE(3) rigid-body motion rather than requiring the decoder to recover that geometry implicitly.
- The policy achieves higher task success rates than VLA and WAM baselines on both simulated and real-world manipulation.
- Out-of-distribution generalization improves because the intermediate representation now shares the geometric structure of the action space.
- No additional geometric loss terms are required beyond the pose supervision on the trajectory predictor.
Where Pith is reading between the lines
- The same conditioning trick could be tested on tasks that require precise 3D reasoning such as insertion or stacking under partial occlusion.
- If the trajectory predictor is made differentiable end-to-end with the policy, future work might remove the separate pose-supervision stage entirely.
- The approach suggests a general pattern for other control domains where observation and action spaces obey different geometric groups.
Load-bearing premise
Conditioning the action decoder solely on the hidden states of a pose-supervised SE(3) trajectory predictor is enough to make generated action chunks obey rigid-body geometry without extra loss terms or constraints.
What would settle it
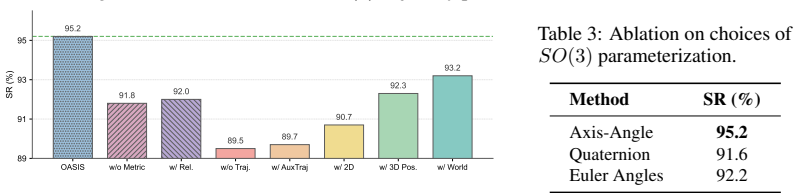
An ablation that removes the conditioning on the SE(3) predictor's hidden states while keeping the rest of the architecture identical and measures whether success rate and out-of-distribution generalization drop to baseline levels.
Figures






read the original abstract
Recent vision-language-action (VLA) models and world action models (WAMs) advance robotic manipulation by enriching intermediate representations with auxiliary spatial features or future visual-state prediction. However, these representations largely remain within the observation space and do not share the rigid-body geometry of the action space, forcing the action decoder to implicitly recover this geometry. We propose OASIS, a visuomotor policy that aligns the intermediate representation with the action space via $SE(3)$ end-effector trajectory prediction. OASIS couples a 3D-aware feature encoder that fuses vision-language and metric-depth features with an $SE(3)$ trajectory predictor that produces a camera-frame end-effector trajectory. Conditioned on the predictor's pose-supervised hidden states, the action decoder generates action chunks consistent with rigid-body motion. Across simulation and real-world experiments, OASIS outperforms VLA and WAM baselines in success rate and out-of-distribution generalization. Our project page is available at https://npuhandsome.github.io/OASIS_web.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes OASIS, a visuomotor policy for robotic manipulation that aligns the observation space with the action space via SE(3) end-effector trajectory prediction. It couples a 3D-aware feature encoder (fusing vision-language and metric-depth features) with an SE(3) trajectory predictor whose pose-supervised hidden states condition the action decoder to produce action chunks consistent with rigid-body motion. The paper claims that this alignment yields higher success rates and better out-of-distribution generalization than VLA and WAM baselines across simulation and real-world experiments.
Significance. If the central mechanism holds, the work could meaningfully advance VLA-style policies by explicitly bridging the geometric mismatch between observation and action spaces rather than relying on implicit recovery by the decoder. The use of an auxiliary SE(3) prediction task with pose supervision to shape the conditioning signal is a concrete, testable idea that could improve generalization in manipulation without requiring entirely new architectures.
major comments (1)
- [Method description of conditioning (SE(3) predictor to action decoder)] The core claim that conditioning the action decoder solely on the pose-supervised hidden states of the SE(3) trajectory predictor enforces rigid-body geometry in the output action chunks lacks an explicit supporting mechanism. If the conditioning operator is a simple concatenation or attention layer (as implied by the abstract) without an auxiliary loss penalizing non-rigid deviations in the action sequence itself, the geometric transfer is not guaranteed and performance gains may instead derive from the 3D encoder or the auxiliary prediction task alone.
minor comments (2)
- [Abstract] The abstract asserts outperformance but supplies no quantitative success rates, baseline names with exact metrics, statistical tests, or ablation results; these details should be added to the abstract or a results summary table for immediate evaluability.
- [Method] Notation for the SE(3) trajectory (camera-frame end-effector poses) and the precise form of the hidden-state conditioning should be formalized with an equation or diagram to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The major comment raises an important point about the explicitness of the geometric transfer mechanism, which we address below by clarifying the role of pose supervision and committing to revisions that strengthen the exposition.
read point-by-point responses
-
Referee: [Method description of conditioning (SE(3) predictor to action decoder)] The core claim that conditioning the action decoder solely on the pose-supervised hidden states of the SE(3) trajectory predictor enforces rigid-body geometry in the output action chunks lacks an explicit supporting mechanism. If the conditioning operator is a simple concatenation or attention layer (as implied by the abstract) without an auxiliary loss penalizing non-rigid deviations in the action sequence itself, the geometric transfer is not guaranteed and performance gains may instead derive from the 3D encoder or the auxiliary prediction task alone.
Authors: We appreciate this observation. The SE(3) trajectory predictor is trained end-to-end with direct supervision on the predicted camera-frame end-effector poses (i.e., the SE(3) trajectory itself), which forces its hidden states to encode representations that are consistent with rigid-body motion. These pose-supervised hidden states are then provided as conditioning input to the action decoder (via concatenation followed by cross-attention layers, as detailed in Section 3.3 of the manuscript). Because the conditioning signal is shaped by explicit SE(3) pose loss, the decoder is biased toward producing action chunks whose implied end-effector motion respects the same rigid geometry; no separate auxiliary loss on the action chunks is required for this transfer. That said, the referee is correct that the current manuscript does not provide a formal proof or additional ablation isolating the conditioning operator from the 3D encoder. We will revise Section 3 to explicitly describe the conditioning operator, add a paragraph explaining the geometric transfer argument, and include an ablation that compares (i) full OASIS, (ii) OASIS without pose supervision on the predictor, and (iii) the 3D encoder alone. These changes will make the mechanism clearer and address the possibility that gains arise elsewhere. revision: yes
Circularity Check
No circularity: derivation chain not reducible to inputs by construction
full rationale
The provided abstract and description contain no equations, fitting procedures, or derivation steps that reduce the central claim (conditioning on pose-supervised hidden states enforces rigid-body geometry) to a self-definition, fitted input renamed as prediction, or self-citation chain. The alignment mechanism is asserted via architectural description without visible reduction to its own inputs. No load-bearing uniqueness theorems or ansatzes from prior self-work are quoted. This matches the default case of a self-contained architectural proposal whose performance claims rest on external benchmarks rather than internal redefinition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Zero-Shot Robotic Manipulation with Pretrained Image-Editing Diffusion Models
Kevin Black, Mitsuhiko Nakamoto, Pranav Atreya, Homer Walke, Chelsea Finn, Aviral Kumar, and Sergey Levine. Zero-shot robotic manipulation with pretrained image-editing diffusion models.arXiv preprint arXiv:2310.10639, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, brian ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren,...
2025
-
[6]
π0: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, Laura Smith, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Z...
2025
-
[7]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Qingwen Bu, Hongyang Li, Li Chen, Jisong Cai, Jia Zeng, Heming Cui, Maoqing Yao, and Yu Qiao. Towards synergistic, generalized, and efficient dual-system for robotic manipulation. arXiv preprint arXiv:2410.08001, 2024
-
[9]
Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Learning to Act Anywhere with Task-centric Latent Actions. InProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025
2025
-
[10]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[13]
Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023. 10
2023
- [14]
-
[15]
arXiv preprint arXiv:2406.08545 (2024)
Ankit Goyal, Valts Blukis, Jie Xu, Yijie Guo, Yu-Wei Chao, and Dieter Fox. Rvt-2: Learning precise manipulation from few demonstrations.arXiv preprint arXiv:2406.08545, 2024
-
[16]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[17]
Video prediction policy: A generalist robot policy with predictive visual representations
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations. InForty-second International Conference on Machine Learning, 2025
2025
-
[18]
Thinkact: Vision-language-action reasoning via reinforced visual latent planning
Chi-Pin Huang, Yueh-Hua Wu, Min-Hung Chen, Yu-Chiang Frank Wang, and Fu-En Yang. Thinkact: Vision-language-action reasoning via reinforced visual latent planning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[19]
arXiv preprint arXiv:2411.18623 (2024)
Yueru Jia, Jiaming Liu, Sixiang Chen, Chenyang Gu, Zhilue Wang, Longzan Luo, Lily Lee, Pengwei Wang, Zhongyuan Wang, Renrui Zhang, et al. Lift3d foundation policy: Lift- ing 2d large-scale pretrained models for robust 3d robotic manipulation.arXiv preprint arXiv:2411.18623, 2024
-
[20]
Prismatic vlms: Investigating the design space of visually-conditioned language models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models. InForty-first International Conference on Machine Learning, 2024
2024
-
[21]
3D Diffuser Actor: Policy Diffusion with 3D Scene Representations
Tsung-Wei Ke, Nikolaos Gkanatsios, and Katerina Fragkiadaki. 3d diffuser actor: Policy diffusion with 3d scene representations.arXiv preprint arXiv:2402.10885, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
MolmoAct: Action Reasoning Models that can Reason in Space
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, et al. Molmoact: Action reasoning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Chengmeng Li, Junjie Wen, Yan Peng, Yaxin Peng, Feifei Feng, and Yichen Zhu. Pointvla: Injecting the 3d world into vision-language-action models.arXiv preprint arXiv:2503.07511, 2025
-
[25]
BridgeVLA: Input-output alignment for efficient 3d manipulation learning with vision-language models
Peiyan Li, Yixiang Chen, Hongtao Wu, Xiao Ma, Xiangnan Wu, Yan Huang, Liang Wang, Tao Kong, and Tieniu Tan. BridgeVLA: Input-output alignment for efficient 3d manipulation learning with vision-language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[26]
What Matters in Building Vision-Language-Action Models for Generalist Robots
Xinghang Li, Peiyan Li, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Tao Kong, Hanbo Zhang, and Huaping Liu. Towards generalist robot policies: What matters in building vision-language-action models.arXiv preprint arXiv:2412.14058, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Vision-language foundation models as effective robot imitators
Xinghang Li, Minghuan Liu, Hanbo Zhang, Cunjun Yu, Jie Xu, Hongtao Wu, Chilam Cheang, Ya Jing, Weinan Zhang, Huaping Liu, Hang Li, and Tao Kong. Vision-language foundation models as effective robot imitators. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[28]
QDepth-VLA: Quantized Depth Prediction as Auxiliary Supervision for Vision-Language-Action Models
Yixuan Li, Yuhui Chen, Mingcai Zhou, Haoran Li, Zhengtao Zhang, and Dongbin Zhao. Qdepth- vla: quantized depth prediction as auxiliary supervision for vision-language-action models. arXiv preprint arXiv:2510.14836, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Data scaling laws in imitation learning for robotic manipulation
Fanqi Lin, Yingdong Hu, Pingyue Sheng, Chuan Wen, Jiacheng You, and Yang Gao. Data scaling laws in imitation learning for robotic manipulation. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[30]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[32]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[33]
Efficient robotic policy learning via latent space backward planning
Dongxiu Liu, Haoyi Niu, Zhihao Wang, Jinliang Zheng, Yinan Zheng, Zhonghong Ou, Jianming HU, Jianxiong Li, and Xianyuan Zhan. Efficient robotic policy learning via latent space backward planning. InForty-second International Conference on Machine Learning, 2025
2025
-
[34]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[35]
RDT-1b: a diffusion foundation model for bimanual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. RDT-1b: a diffusion foundation model for bimanual manipulation. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[36]
Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[37]
Octo: An open-source generalist robot policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Charles Xu, Jianlan Luo, Tobias Kreiman, You Liang Tan, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and Systems, Delft, Netherl...
2024
-
[38]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick L...
2024
-
[39]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[40]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Pixel motion as universal representation for robot control.arXiv preprint arXiv:2505.07817, 2025
Kanchana Ranasinghe, Xiang Li, E-Ro Nguyen, Cristina Mata, Jongwoo Park, and Michael S Ryoo. Pixel motion as universal representation for robot control.arXiv preprint arXiv:2505.07817, 2025
-
[42]
Multimodal Diffusion Transformer: Learning Versatile Behavior from Multimodal Goals
Moritz Reuss, Ömer Erdinç Ya ˘gmurlu, Fabian Wenzel, and Rudolf Lioutikov. Multimodal Diffusion Transformer: Learning Versatile Behavior from Multimodal Goals. InProceedings of Robotics: Science and Systems, Delft, Netherlands, July 2024. 12
2024
-
[43]
Efficient diffusion trans- former policies with mixture of expert denoisers for multitask learning
Moritz Reuss, Jyothish Pari, Pulkit Agrawal, and Rudolf Lioutikov. Efficient diffusion trans- former policies with mixture of expert denoisers for multitask learning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[44]
Perceiver-actor: A multi-task transformer for robotic manipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InConference on Robot Learning, pages 785–799. PMLR, 2023
2023
-
[45]
Reconvla: Reconstructive vision- language-action model as effective robot perceiver
Wenxuan Song, Ziyang Zhou, Han Zhao, Jiayi Chen, Pengxiang Ding, Haodong Yan, Yuxin Huang, Feilong Tang, Donglin Wang, and Haoang Li. Reconvla: Reconstructive vision- language-action model as effective robot perceiver. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18549–18557, 2026
2026
-
[46]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[47]
SMART: Self-supervised multi-task pretraining with control transformers
Yanchao Sun, Shuang Ma, Ratnesh Madaan, Rogerio Bonatti, Furong Huang, and Ashish Kapoor. SMART: Self-supervised multi-task pretraining with control transformers. InInterna- tional Conference on Learning Representations, 2023
2023
-
[48]
Predictive inverse dynamics models are scalable learners for robotic manipulation
Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, and Jiangmiao Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[49]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[51]
The colosseum: A benchmark for evaluating generalization for robotic manipulation
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xin- long Wang, and Zhaoxiang Zhang. Unified vision-language-action model.arXiv preprint arXiv:2506.19850, 2025
-
[52]
Any-point Trajectory Modeling for Policy Learning
Chuan Wen, Xingyu Lin, John So, Kai Chen, Qi Dou, Yang Gao, and Pieter Abbeel. Any-point trajectory modeling for policy learning.arXiv preprint arXiv:2401.00025, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
Gaoyue Zhou, Hengkai Pan, Yann LeCun, and Lerrel Pinto
Amber Xie, Oleh Rybkin, Dorsa Sadigh, and Chelsea Finn. Latent diffusion planning for imitation learning.arXiv preprint arXiv:2504.16925, 2025
-
[54]
Depth anything v2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[55]
Deer-VLA: Dynamic inference of multimodal large language models for efficient robot execution
Yang Yue, Yulin Wang, Bingyi Kang, Yizeng Han, Shenzhi Wang, Shiji Song, Jiashi Feng, and Gao Huang. Deer-VLA: Dynamic inference of multimodal large language models for efficient robot execution. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[56]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. In Proceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[57]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[58]
UP- VLA: A unified understanding and prediction model for embodied agent
Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xiang Zhu, and Jianyu Chen. UP- VLA: A unified understanding and prediction model for embodied agent. InForty-second International Conference on Machine Learning, 2025
2025
-
[59]
Pivot-r: Primitive-driven waypoint-aware world model for robotic manipulation
Kaidong Zhang, Pengzhen Ren, Bingqian Lin, Junfan Lin, Shikui Ma, Hang Xu, and Xiao- dan Liang. Pivot-r: Primitive-driven waypoint-aware world model for robotic manipulation. Advances in Neural Information Processing Systems, 37:54105–54136, 2024. 13
2024
-
[60]
DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge
Wenyao Zhang, Hongsi Liu, Zekun Qi, Yunnan Wang, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, Fan Lu, He Wang, et al. Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge.arXiv preprint arXiv:2507.04447, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
One-shot imitation learning with invariance matching for robotic manipulation
Xinyu Zhang and Abdeslam Boularias. One-shot imitation learning with invariance matching for robotic manipulation. InProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[62]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
-
[63]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
3D-VLA: A 3D Vision-Language-Action Generative World Model
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3d-vla: A 3d vision-language-action generative world model.arXiv preprint arXiv:2403.09631, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
TraceVLA: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daumé III, Andrey Kolobov, Furong Huang, and Jianwei Yang. TraceVLA: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[66]
Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets. InProceedings of Robotics: Science and Systems (RSS), 2025
2025
-
[67]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 14 A Implementation details A.1 OASIS architecture Given the real-time constraints of ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.