Sentinel: Embodied Cooperative Spatial Reasoning and Planning
Pith reviewed 2026-06-29 22:56 UTC · model grok-4.3
The pith
Decentralized agents gather faster and safer in city scenes by sharing language updates and replanning paths together.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
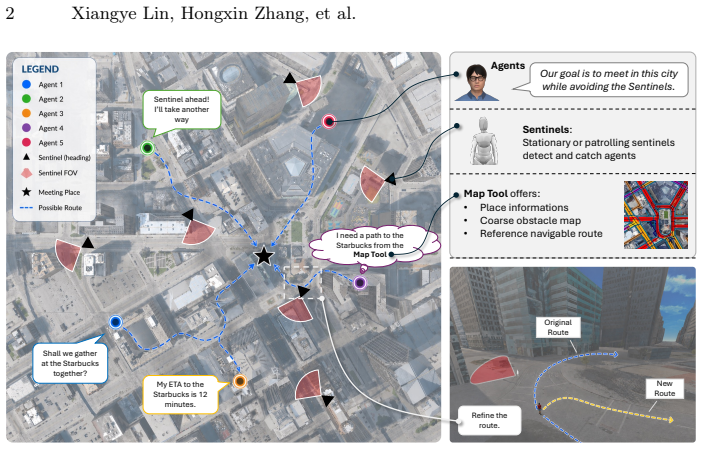
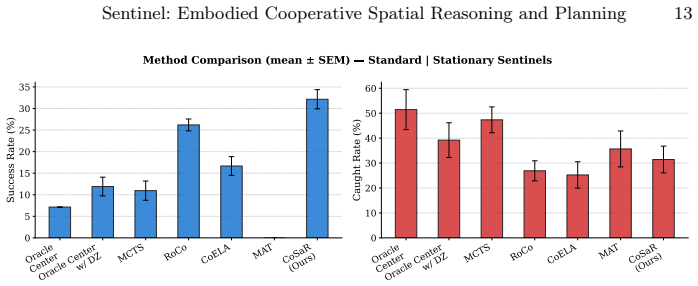
CoSaR enables agents to exchange situational updates, reason over evolving spatial constraints, and collaboratively replan trajectories, consistently leading to faster gathering, shorter path lengths, and improved safety when evaluated across 14 city-level scenes with 3-5 agents.
What carries the argument
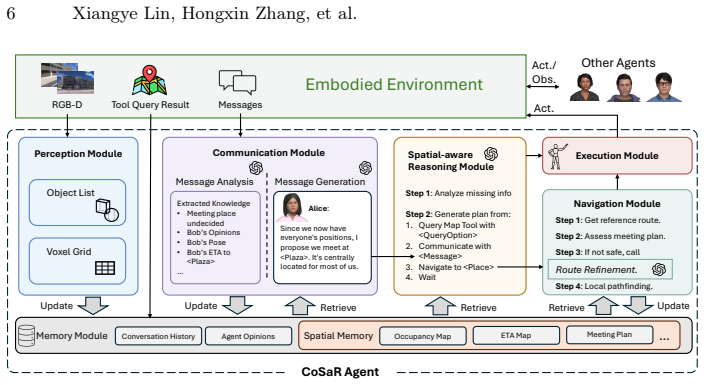
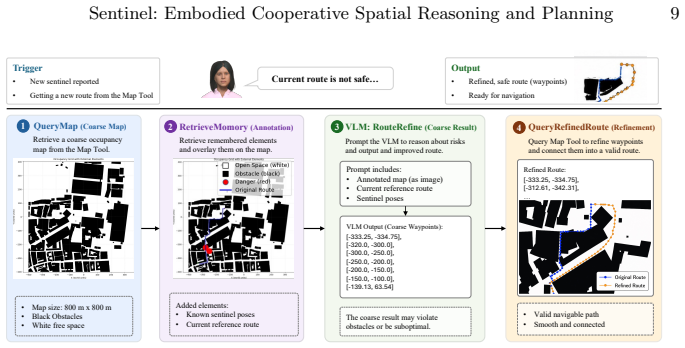
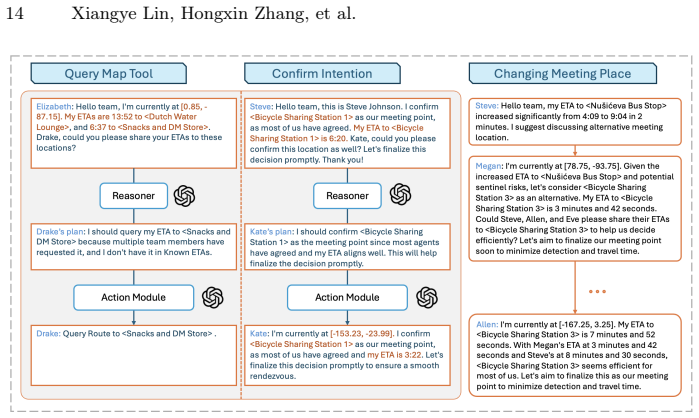
CoSaR (Cooperative Spatial Reasoning and Planning) framework, which bridges high-level communication and planning of foundation models with classical spatial navigation algorithms.
If this is right
- Agents reach safe meeting points through language exchanges alone even when maps are incomplete.
- Collaborative replanning reduces exposure to dynamic obstacles such as patrolling sentinels.
- The same integration of communication and navigation scales to groups of three to five agents in varied city layouts.
- Classical navigation algorithms supply the precision that pure language planning lacks in physical movement.
Where Pith is reading between the lines
- The benchmark could serve as a testbed for comparing different foundation models on spatial coordination tasks.
- Similar language-plus-navigation loops might support robot teams in search-and-rescue operations inside buildings.
- Removing the coarse spatial tool entirely would clarify how much the method depends on that specific input.
- Extending the sentinels to actively pursue agents would test whether the replanning step remains robust.
Load-bearing premise
Coarse spatial information and natural language communication supply enough shared grounding for agents to agree on mutually safe meeting points without central coordination.
What would settle it
Remove all natural language communication or replace the coarse spatial tool with random data, then measure whether gathering times increase and collision rates rise in the same 14 scenes.
Figures
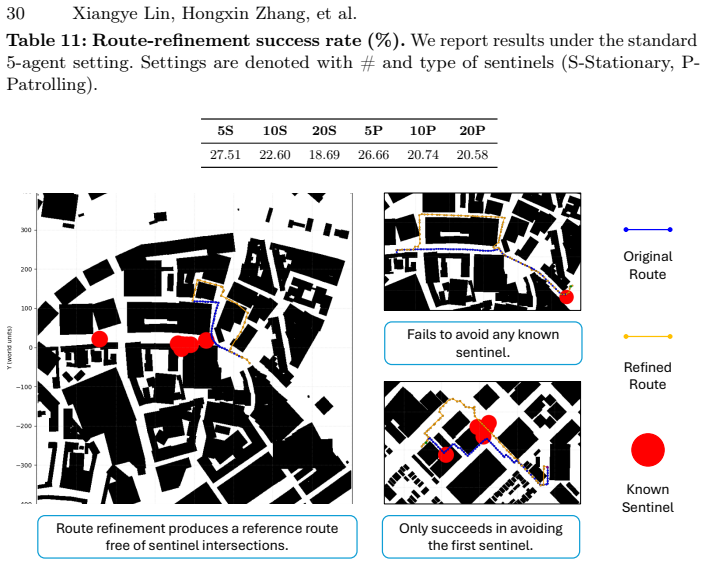
read the original abstract
In this work, we study Cooperative Spatial Intelligence, the ability of decentralized embodied agents to coordinate effectively under dynamic environmental constraints across city-scale outdoor domains. We introduce Sentinel Challenge, a benchmark where multiple decentralized embodied agents must communicate in natural language to agree on a mutually safe and convenient meeting point within large, city-scale outdoor environments. Each agent must then navigate safely while avoiding dynamic sentinels patrolling the area, using a tool that provides coarse spatial information. To address this, we propose CoSaR (Cooperative Spatial Reasoning and Planning), a framework that bridges the high-level communication and planning abilities of foundation models with the precision of classical spatial navigation algorithms. CoSaR enables agents to exchange situational updates, reason over evolving spatial constraints, and collaboratively replan trajectories. Evaluated across 14 city-level scenes with 3-5 agents, CoSaR consistently leads to faster gathering, shorter path lengths, and improved safety. Our results demonstrate that integrating dynamic communication with spatial reasoning is essential for robust multi-agent cooperation. By formalizing this new setting and providing a scalable benchmark, we aim to build a foundation for advancing cooperative spatial intelligence in embodied multi-agent systems. Code and challenge are available at https://github.com/UMass-Embodied-AGI/Sentinel.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Sentinel Challenge benchmark for cooperative spatial intelligence, where decentralized embodied agents in city-scale outdoor scenes must use natural language communication and a coarse spatial information tool to agree on safe meeting points while avoiding dynamic sentinels. It proposes the CoSaR framework, which combines foundation models for high-level reasoning and communication with classical spatial navigation algorithms for trajectory planning and replanning. Evaluation across 14 scenes with 3-5 agents reports that CoSaR yields faster gathering, shorter path lengths, and improved safety.
Significance. If the empirical results are robust, the work formalizes a new setting for multi-agent embodied cooperation and provides evidence that hybrid LLM-classical methods can address dynamic spatial constraints without central coordination. The public release of code and the benchmark supports reproducibility and is a clear strength.
major comments (1)
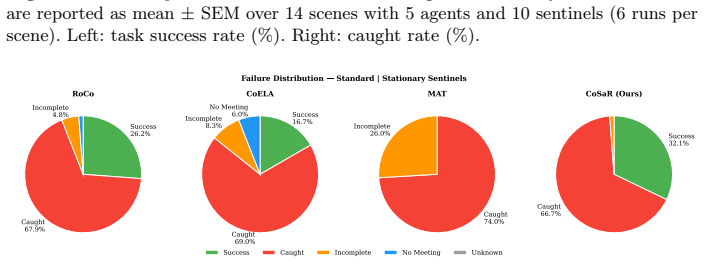
- [Evaluation] The central empirical claim (faster gathering, shorter paths, improved safety) is presented without details on the baselines, exact metrics, statistical significance tests, error bars, or ablation studies in the reported evaluation across 14 scenes. This information is load-bearing for assessing whether the gains are reliable and attributable to CoSaR.
minor comments (2)
- [Abstract] The abstract states that 'integrating dynamic communication with spatial reasoning is essential' but does not reference prior multi-agent navigation or LLM-planning literature that could contextualize this claim.
- The description of the coarse spatial information tool would benefit from a concrete example of the information it returns to clarify how it supports mutually safe meeting-point agreement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the novelty of the Sentinel Challenge benchmark, the CoSaR framework, and the value of the public code and benchmark release. We address the single major comment on evaluation details below.
read point-by-point responses
-
Referee: [Evaluation] The central empirical claim (faster gathering, shorter paths, improved safety) is presented without details on the baselines, exact metrics, statistical significance tests, error bars, or ablation studies in the reported evaluation across 14 scenes. This information is load-bearing for assessing whether the gains are reliable and attributable to CoSaR.
Authors: We agree that the current manuscript lacks sufficient detail on these aspects, which is necessary to substantiate the claims. In the revised manuscript we will add: (1) explicit descriptions of all baselines (including their implementation and any adaptations), (2) precise mathematical definitions of each metric together with how they are computed from raw trajectories, (3) results of statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests with reported p-values) across the 14 scenes, (4) error bars or standard deviations on all quantitative results, and (5) ablation studies that isolate the contribution of the natural-language communication module, the spatial-reasoning component, and the classical replanning algorithm. These additions will appear in an expanded Experiments section with new tables and figures. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical benchmark (Sentinel Challenge) and a framework (CoSaR) evaluated on 14 scenes with released code; the central claims concern measured improvements in gathering speed, path length, and safety under explicit design choices (coarse spatial tool + NL communication). No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. The work is self-contained against external benchmarks and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Ahn, M., Brohan, A., Brown, N., Chebotar, Y., Cortes, O., David, B., Finn, C., Gopalakrishnan, K., Hausman, K., Herzog, A., et al.: Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691 (2022) 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Journal of Artificial Intelligence Research 64, 817–859 (2019) 3
Amato, C., Konidaris, G., Kaelbling, L.P., How, J.P.: Modeling and planning with macro-actions in decentralized pomdps. Journal of Artificial Intelligence Research 64, 817–859 (2019) 3
2019
-
[3]
On Evaluation of Embodied Navigation Agents
Anderson, P., Chang, A., Chaplot, D.S., Dosovitskiy, A., Gupta, S., Koltun, V., Kosecka, J., Malik, J., Mottaghi, R., Savva, M., et al.: On evaluation of embodied navigation agents. arXiv preprint arXiv:1807.06757 (2018) 4
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
In: International Conference on LearningRepresentations(2020), https://openreview.net/forum?id=SkxpxJBKwS 3
Baker, B., Kanitscheider, I., Markov, T., Wu, Y., Powell, G., McGrew, B., Mordatch, I.: Emergent tool use from multi-agent autocurricula. In: International Conference on LearningRepresentations(2020), https://openreview.net/forum?id=SkxpxJBKwS 3
2020
-
[5]
Artificial Intelligence280, 103216 (2020) 3
Bard, N., Foerster, J.N., Chandar, S., Burch, N., Lanctot, M., Song, H.F., Parisotto, E., Dumoulin, V., Moitra, S., Hughes, E., et al.: The hanabi challenge: A new frontier for ai research. Artificial Intelligence280, 103216 (2020) 3
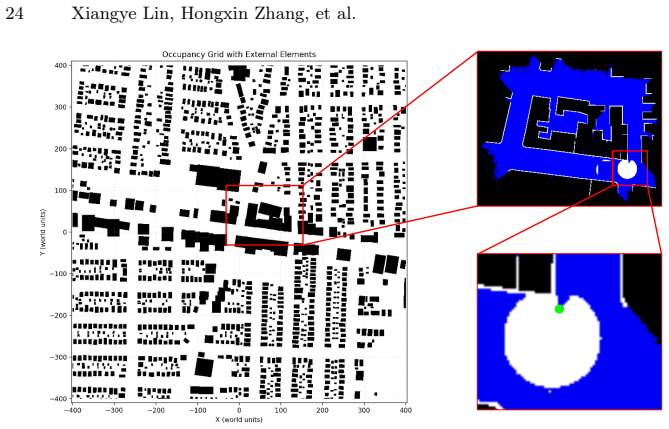
2020
-
[6]
Mathematics of operations research27(4), 819–840 (2002) 4
Bernstein, D.S., Givan, R., Immerman, N., Zilberstein, S.: The complexity of decentralized control of markov decision processes. Mathematics of operations research27(4), 819–840 (2002) 4
2002
-
[7]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Cai, W., Ponomarenko, I., Yuan, J., Li, X., Yang, W., Dong, H., Zhao, B.: Spa- tialbot: Precise spatial understanding with vision language models. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 9490–9498. IEEE (2025) 4
2025
-
[8]
Advances in neural information processing systems32(2019) 3
Carroll, M., Shah, R., Ho, M.K., Griffiths, T., Seshia, S., Abbeel, P., Dragan, A.: On the utility of learning about humans for human-ai coordination. Advances in neural information processing systems32(2019) 3
2019
-
[9]
Numerische Mathematik1(1), 269–271 (1959) 6, 10
Dijkstra, E.W.: A note on two problems in connexion with graphs. Numerische Mathematik1(1), 269–271 (1959) 6, 10
1959
-
[10]
arXiv preprint arXiv:2403.11401 (2024) 4
Fu, R., Liu, J., Chen, X., Nie, Y., Xiong, W.: Scene-llm: Extending language model for 3d visual understanding and reasoning. arXiv preprint arXiv:2403.11401 (2024) 4
-
[11]
arXiv preprint arXiv:2203.104213(4), 7 (2022) 4
Gadre, S.Y., Wortsman, M., Ilharco, G., Schmidt, L., Song, S.: Clip on wheels: Zero-shot object navigation as object localization and exploration. arXiv preprint arXiv:2203.104213(4), 7 (2022) 4
-
[12]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025) 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Advances in Neural Information Processing Systems36, 20482–20494 (2023) 4
Hong, Y., Zhen, H., Chen, P., Zheng, S., Du, Y., Chen, Z., Gan, C.: 3d-llm: Injecting the 3d world into large language models. Advances in Neural Information Processing Systems36, 20482–20494 (2023) 4
2023
-
[14]
arXiv preprint arXiv:2210.05714 (2022) 4 18 Xiangye Lin, Hongxin Zhang, et al
Huang, C., Mees, O., Zeng, A., Burgard, W.: Visual language maps for robot navigation. arXiv preprint arXiv:2210.05714 (2022) 4 18 Xiangye Lin, Hongxin Zhang, et al
-
[15]
Science364(6443), 859–865 (2019) 3
Jaderberg, M., Czarnecki, W.M., Dunning, I., Marris, L., Lever, G., Castaneda, A.G., Beattie, C., Rabinowitz, N.C., Morcos, A.S., Ruderman, A., et al.: Human- level performance in 3d multiplayer games with population-based reinforcement learning. Science364(6443), 859–865 (2019) 3
2019
-
[16]
In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V 16
Jain, U., Weihs, L., Kolve, E., Farhadi, A., Lazebnik, S., Kembhavi, A., Schwing, A.: A cordial sync: Going beyond marginal policies for multi-agent embodied tasks. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V 16. pp. 471–490. Springer (2020) 3
2020
-
[17]
In: Fortieth International Conference on Machine Learning (2023) 4
Jiang, Y., Gupta, A., Zhang, Z., Wang, G., Dou, Y., Chen, Y., Fei-Fei, L., Anand- kumar, A., Zhu, Y., Fan, L.: Vima: General robot manipulation with multimodal prompts. In: Fortieth International Conference on Machine Learning (2023) 4
2023
-
[18]
IEEE Robotics and Automation Letters6(2), 1312–1319 (2021) 4
Kahn, G., Abbeel, P., Levine, S.: Badgr: An autonomous self-supervised learning- based navigation system. IEEE Robotics and Automation Letters6(2), 1312–1319 (2021) 4
2021
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Khandelwal, A., Weihs, L., Mottaghi, R., Kembhavi, A.: Simple but effective: Clip embeddings for embodied ai. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14829–14838 (2022) 4
2022
-
[20]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language- action model. arXiv preprint arXiv:2406.09246 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
AI2-THOR: An Interactive 3D Environment for Visual AI
Kolve, E., Mottaghi, R., Han, W., VanderBilt, E., Weihs, L., Herrasti, A., Deitke, M., Ehsani, K., Gordon, D., Zhu, Y., et al.: Ai2-thor: An interactive 3d environment for visual ai. arXiv preprint arXiv:1712.05474 (2017) 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
In: 2013 IEEE Inter- national Conference on Robotics and Automation
Kümmerle, R., Ruhnke, M., Steder, B., Stachniss, C., Burgard, W.: A navigation system for robots operating in crowded urban environments. In: 2013 IEEE Inter- national Conference on Robotics and Automation. pp. 3225–3232. IEEE (2013) 4
2013
-
[23]
In: Conference on Robot Learning
Li, C., Zhang, R., Wong, J., Gokmen, C., Srivastava, S., Martín-Martín, R., Wang, C., Levine, G., Lingelbach, M., Sun, J., et al.: Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation. In: Conference on Robot Learning. pp. 80–93. PMLR (2023) 3
2023
-
[24]
arXiv preprint arXiv:2411.04679 (2024) 2, 3
Liu, J., Zhou, P., Du, Y., Tan, A.H., Snoek, C.G., Sonke, J.J., Gavves, E.: Capo: Cooperative plan optimization for efficient embodied multi-agent cooperation. arXiv preprint arXiv:2411.04679 (2024) 2, 3
-
[25]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499 (2023) 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, X., Li, J., Jiang, Y., Sujay, N., Yang, Z., Zhang, J., Abanes, J., Zhang, J., Feng, C.: Citywalker: Learning embodied urban navigation from web-scale videos. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6875–6885 (2025) 4
2025
-
[27]
Advances in neural informa- tion processing systems30(2017) 3
Lowe, R., Tamar, A., Harb, J., Pieter Abbeel, O., Mordatch, I.: Multi-agent actor- critic for mixed cooperative-competitive environments. Advances in neural informa- tion processing systems30(2017) 3
2017
-
[28]
Advances in Neural Information Processing Systems35, 32340–32352 (2022) 4
Majumdar, A., Aggarwal, G., Devnani, B., Hoffman, J., Batra, D.: Zson: Zero-shot object-goal navigation using multimodal goal embeddings. Advances in Neural Information Processing Systems35, 32340–32352 (2022) 4
2022
-
[29]
Mandi, Z., Jain, S., Song, S.: Roco: Dialectic multi-robot collaboration with large language models. arXiv preprint arXiv:2307.04738 (2023) 3, 11, 15 Sentinel: Embodied Cooperative Spatial Reasoning and Planning 19
-
[30]
Mapping Instructions to Actions in 3D Environments with Visual Goal Prediction
Misra, D., Bennett, A., Blukis, V., Niklasson, E., Shatkhin, M., Artzi, Y.: Mapping instructions to actions in 3d environments with visual goal prediction. arXiv preprint arXiv:1809.00786 (2018) 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Nature Machine Intelligence pp
Mon-Williams, R., Li, G., Long, R., Du, W., Lucas, C.G.: Embodied large language models enable robots to complete complex tasks in unpredictable environments. Nature Machine Intelligence pp. 1–10 (2025) 4
2025
-
[32]
Morales, Y., Carballo, A., Takeuchi, E., Aburadani, A., Tsubouchi, T.: Autonomous robotnavigationinoutdoorclutteredpedestrianwalkways.JournalofFieldRobotics 26(8), 609–635 (2009) 4
2009
-
[33]
OpenAI: Gpt-4 technical report (2023) 2
2023
-
[34]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Padmakumar, A., Thomason, J., Shrivastava, A., Lange, P., Narayan-Chen, A., Gella, S., Piramuthu, R., Tur, G., Hakkani-Tur, D.: Teach: Task-driven embodied agents that chat. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 36, pp. 2017–2025 (2022) 3
2017
-
[35]
Generative Agents: Interactive Simulacra of Human Behavior
Park, J.S., O’Brien, J.C., Cai, C.J., Morris, M.R., Liang, P., Bernstein, M.S.: Generative agents: Interactive simulacra of human behavior. arXiv preprint arXiv:2304.03442 (2023) 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
In: International Conference on Learning Representations (2021) 3
Puig, X., Shu, T., Li, S., Wang, Z., Liao, Y.H., Tenenbaum, J.B., Fidler, S., Torralba, A.: Watch-and-help: A challenge for social perception and human-ai collaboration. In: International Conference on Learning Representations (2021) 3
2021
-
[37]
arXiv preprint arXiv:2310.13724 (2023) 3
Puig, X., Undersander, E., Szot, A., Cote, M.D., Yang, T.Y., Partsey, R., Desai, R., Clegg, A.W., Hlavac, M., Min, S.Y., et al.: Habitat 3.0: A co-habitat for humans, avatars and robots. arXiv preprint arXiv:2310.13724 (2023) 3
-
[38]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 7
2021
-
[39]
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K.V., Carion, N., Wu, C.Y., Girshick, R., Dollár, P., Feichtenhofer, C.: Sam 2: Segment anything in images and videos (2024),https://arxiv.org/abs/2408.007147
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
In: Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems
Samvelyan, M., Rashid, T., Schroeder de Witt, C., Farquhar, G., Nardelli, N., Rudner, T.G., Hung, C.M., Torr, P.H., Foerster, J., Whiteson, S.: The starcraft multi-agent challenge. In: Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems. pp. 2186–2188 (2019) 3
2019
-
[41]
In: Proceedings of the IEEE/CVF international conference on computer vision
Savva, M., Kadian, A., Maksymets, O., Zhao, Y., Wijmans, E., Jain, B., Straub, J., Liu, J., Koltun, V., Malik, J., et al.: Habitat: A platform for embodied ai research. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9339–9347 (2019) 3
2019
-
[42]
In: 2021 IEEE International Conference on Robotics and Automation (ICRA)
Shah, D., Eysenbach, B., Kahn, G., Rhinehart, N., Levine, S.: Ving: Learning open-world navigation with visual goals. In: 2021 IEEE International Conference on Robotics and Automation (ICRA). pp. 13215–13222. IEEE (2021) 4
2021
-
[43]
In: Conference on robot learning
Shah, D., Osiński, B., Levine, S., et al.: Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action. In: Conference on robot learning. pp. 492–504. PMLR (2023) 4
2023
-
[44]
arXiv preprint arXiv:2306.14846 (2023) 4
Shah, D., Sridhar, A., Dashora, N., Stachowicz, K., Black, K., Hirose, N., Levine, S.: Vint: A foundation model for visual navigation. arXiv preprint arXiv:2306.14846 (2023) 4
-
[45]
arXiv preprint arXiv:2110.01517 (2021) 3 20 Xiangye Lin, Hongxin Zhang, et al
Sharma, P., Torralba, A., Andreas, J.: Skill induction and planning with latent language. arXiv preprint arXiv:2110.01517 (2021) 3 20 Xiangye Lin, Hongxin Zhang, et al
-
[46]
In: Proceedings of the IEEE/CVF international conference on computer vision
Song, C.H., Wu, J., Washington, C., Sadler, B.M., Chao, W.L., Su, Y.: Llm-planner: Few-shot grounded planning for embodied agents with large language models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2998–3009 (2023) 4
2023
-
[47]
In: Proceedings of the fifth international joint conference on Autonomous agents and multiagent systems
Spaan, M.T., Gordon, G.J., Vlassis, N.: Decentralized planning under uncertainty for teams of communicating agents. In: Proceedings of the fifth international joint conference on Autonomous agents and multiagent systems. pp. 249–256 (2006) 4
2006
-
[48]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Sridhar, A., Shah, D., Glossop, C., Levine, S.: Nomad: Goal masked diffusion policies for navigation and exploration. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 63–70. IEEE (2024) 4
2024
-
[49]
Autonomous Robots8, 345–383 (2000) 3
Stone, P., Veloso, M.: Multiagent systems: A survey from a machine learning perspective. Autonomous Robots8, 345–383 (2000) 3
2000
-
[50]
Neural MMO: A Massively Multiagent Game Environment for Training and Evaluating Intelligent Agents
Suarez, J., Du, Y., Isola, P., Mordatch, I.: Neural mmo: A massively multiagent game environment for training and evaluating intelligent agents. arXiv preprint arXiv:1903.00784 (2019) 3
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[51]
Cognitive Architectures for Language Agents
Sumers, T., Yao, S., Narasimhan, K., Griffiths, T.L.: Cognitive architectures for language agents. arXiv preprint arXiv:2309.02427 (2023) 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
In: International Conference on Machine Learning
Szot, A., Jain, U., Batra, D., Kira, Z., Desai, R., Rai, A.: Adaptive coordination in social embodied rearrangement. In: International Conference on Machine Learning. pp. 33365–33380. PMLR (2023) 3
2023
-
[53]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Wang, G., Xie, Y., Jiang, Y., Mandlekar, A., Xiao, C., Zhu, Y., Fan, L., Anandkumar, A.: Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291 (2023) 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
A Survey on Large Language Model based Autonomous Agents
Wang, L., Ma, C., Feng, X., Zhang, Z., Yang, H., Zhang, J., Chen, Z., Tang, J., Chen, X., Lin, Y., et al.: A survey on large language model based autonomous agents. arXiv preprint arXiv:2308.11432 (2023) 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, T., Mao, X., Zhu, C., Xu, R., Lyu, R., Li, P., Chen, X., Zhang, W., Chen, K., Xue, T., et al.: Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19757–19767 (2024) 4
2024
-
[56]
In: Thirty-seventh Conference on Neural Information Processing Systems (2023) 3
Wang, Z., Cai, S., Chen, G., Liu, A., Ma, X., Liang, Y.: Describe, explain, plan and select: interactive planning with llms enables open-world multi-task agents. In: Thirty-seventh Conference on Neural Information Processing Systems (2023) 3
2023
-
[57]
In: Second Agent Learning in Open-Endedness Workshop (2023),https://openreview.net/forum? id=xzPkZyHlOW4
Wang, Z., Cai, S., Liu, A., Ma, X., Liang, Y.: JARVIS-1: Open-world multi-task agents with memory-augmented multimodal language models. In: Second Agent Learning in Open-Endedness Workshop (2023),https://openreview.net/forum? id=xzPkZyHlOW4
2023
-
[58]
Advances in Neural Information Processing Systems35, 16509–16521 (2022) 3, 11
Wen, M., Kuba, J., Lin, R., Zhang, W., Wen, Y., Wang, J., Yang, Y.: Multi- agent reinforcement learning is a sequence modeling problem. Advances in Neural Information Processing Systems35, 16509–16521 (2022) 3, 11
2022
-
[59]
arXiv preprint arXiv:1911.00357 (2019) 4
Wijmans, E., Kadian, A., Morcos, A., Lee, S., Essa, I., Parikh, D., Savva, M., Batra, D.: Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames. arXiv preprint arXiv:1911.00357 (2019) 4
-
[60]
The Rise and Potential of Large Language Model Based Agents: A Survey
Xi, Z., Chen, W., Guo, X., He, W., Ding, Y., Hong, B., Zhang, M., Wang, J., Jin, S., Zhou, E., et al.: The rise and potential of large language model based agents: A survey. arXiv preprint arXiv:2309.07864 (2023) 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Xia, F., Zamir, A.R., He, Z., Sax, A., Malik, J., Savarese, S.: Gibson env: Real- world perception for embodied agents. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 9068–9079 (2018) 3 Sentinel: Embodied Cooperative Spatial Reasoning and Planning 21
2018
-
[62]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xiang, F., Qin, Y., Mo, K., Xia, Y., Zhu, H., Liu, F., Liu, M., Jiang, H., Yuan, Y., Wang, H., et al.: Sapien: A simulated part-based interactive environment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11097–11107 (2020) 3
2020
-
[63]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yang, J., Yang, S., Gupta, A.W., Han, R., Fei-Fei, L., Xie, S.: Thinking in space: How multimodal large language models see, remember, and recall spaces. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 10632–10643 (2025) 4
2025
-
[64]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yang, Y., Yang, H., Zhou, J., Chen, P., Zhang, H., Du, Y., Gan, C.: 3d-mem: 3d scene memory for embodied exploration and reasoning. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 17294–17303 (2025) 4
2025
-
[65]
Zhang, H., Du, W., Shan, J., Zhou, Q., Du, Y., Tenenbaum, J.B., Shu, T., Gan, C.: Building cooperative embodied agents modularly with large language models (2023) 2, 3, 4, 11, 15
2023
-
[66]
arXiv preprint arXiv:2404.10775 (2024) 4
Zhang, H., Wang, Z., Lyu, Q., Zhang, Z., Chen, S., Shu, T., Dariush, B., Lee, K., Du, Y., Gan, C.: Combo: compositional world models for embodied multi-agent cooperation. arXiv preprint arXiv:2404.10775 (2024) 4
-
[67]
arXiv preprint arXiv:2506.24019 (2025) 3
Zhang, H., Zhang, Z., Wang, Z., Zhang, Z., Fang, L., Zhou, Q., Gan, C.: Ella: Embodied social agents with lifelong memory. arXiv preprint arXiv:2506.24019 (2025) 3
-
[68]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zheng, D., Huang, S., Zhao, L., Zhong, Y., Wang, L.: Towards learning a generalist model for embodied navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13624–13634 (2024) 4
2024
-
[69]
Zhou, Q., Chen, S., Wang, Y., Xu, H., Du, W., Zhang, H., Du, Y., Tenenbaum, J.B., Gan, C.: Hazard challenge: Embodied decision making in dynamically changing environments (2024) 3
2024
-
[70]
arXiv preprint arXiv:2508.14893 (2025) 3, 10
Zhou, Q., Zhang, H., Lin, X., Zhang, Z., Chen, Y., Liu, W., Zhang, Z., Chen, S., Fang, L., Lyu, Q., et al.: Virtual community: An open world for humans, robots, and society. arXiv preprint arXiv:2508.14893 (2025) 3, 10
-
[71]
In: Conference on Robot Learning
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. In: Conference on Robot Learning. pp. 2165–2183. PMLR (2023) 4
2023
-
[72]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zu, L., Lin, L., Fu, S., Zhao, N., Zhou, P.: Collaborative tree search for enhancing embodied multi-agent collaboration. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29513–29522 (2025) 3 A Additional Details on the Sentinel Challenge The navigation component of theSentinelchallenge is fundamentally built upon the map tool...
2025
-
[73]
dangerous
Each RGB–D frame is accompanied by semantic labels. The agent keeps a set of “dangerous” labels corresponding to sentinel-related classes
-
[74]
For every pixel whose semantic label belongs to this dangerous set, its 3D location is reconstructed from the depth value and camera pose
-
[75]
Specifically, letps denote the reconstructed sentinel-related point
Around each reconstructed location, the occupancy map marks nearby cells within a fixed radius as dangerous. Specifically, letps denote the reconstructed sentinel-related point. All cellspsatisfying ∥p−p s∥ ≤r (1) are marked as dangerous, wherer is the danger-zone radius. In our experi- ments,ris set to10. 24 Xiangye Lin, Hongxin Zhang, et al. Fig.8: Coar...
-
[76]
Letpa denote the agent position
To prevent the agent from being enclosed by newly created danger zones- which may interfere with A* navigation-we restrict danger labeling using a distance-difference constraint relative to the agent position. Letpa denote the agent position. A cellpis marked as dangerous only if d(p,p s)−d(p,p a)< τ, (2) where d(·,· )denotes Euclidean distance and τ is a...
-
[77]
Danger zones are updated continuously. If a region previously marked as dangerous becomes visible again in a later frame and no dangerous labels are detected, the corresponding cells are cleared and restored to a safe state. Consequently, the map reflects currently observed threats and automatically removes outdated danger markings. B.2 Emergency avoidanc...
-
[78]
Emergency avoidance is triggered whenever: (a) the agent receives a warning signal from any sentinel, or (b) the agent visually detects a sentinel within a certain threshold
-
[79]
Once triggered, the agent performs anemergency avoidance target selection and moves toward the target for10consecutive steps, away from the nearest sentinels
-
[80]
If the area is clear, the agent resumes its original task
After completing these10steps, the agent scans its surroundings to confirm that no sentinel is still in close proximity. If the area is clear, the agent resumes its original task. Emergency Avoidance Target Selection.When an agent detects nearby sentinels, it performs an emergency avoidance procedure to select a temporary navigation target that moves it a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.