Native3D: End-to-End 3D Scene Generation via Unified Mesh-Texture Modeling and Semantic Alignment
Pith reviewed 2026-06-27 22:16 UTC · model grok-4.3
The pith
Native3D generates 3D scenes end-to-end by modeling mesh and texture jointly without 2D intermediates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
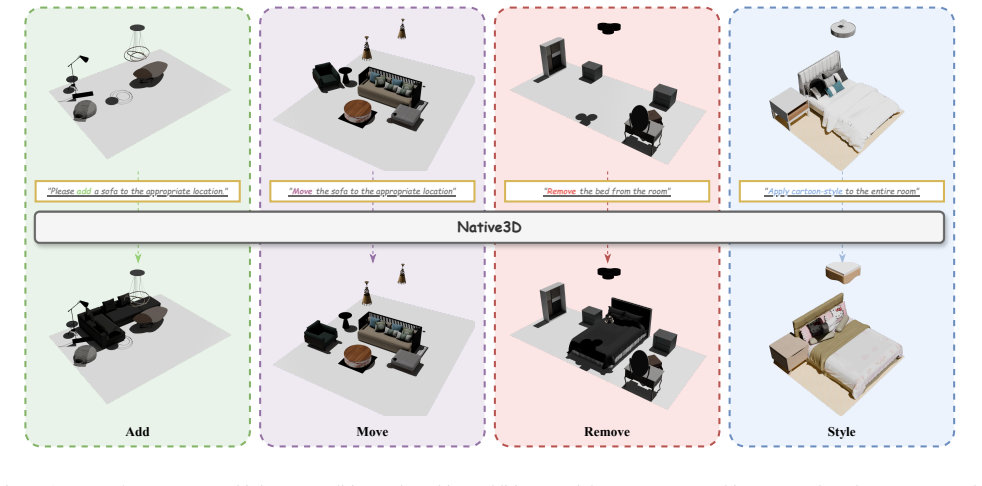
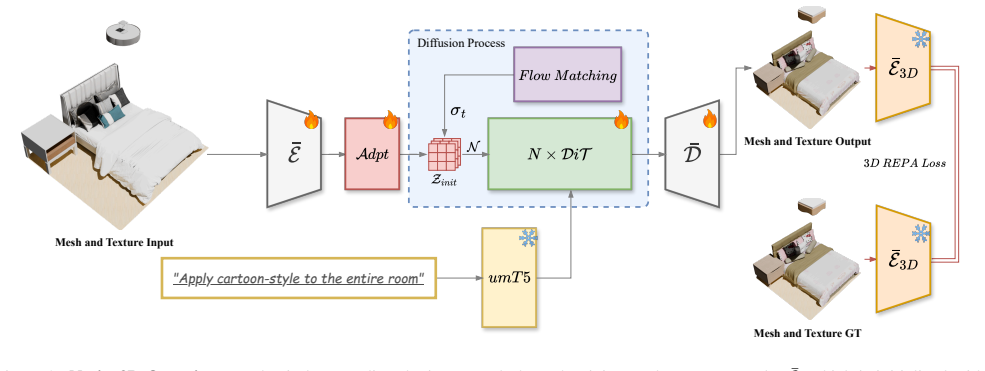
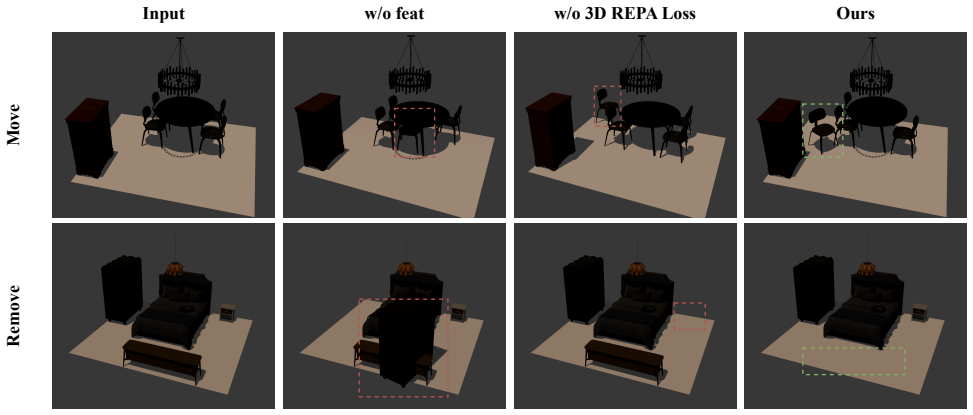
Native3D is the first end-to-end 3D scene generation framework that completely bypasses 2D intermediate representations. It designs a unified mesh-texture joint representation that models geometric structures and texture features simultaneously through a Transformer-based scene encoder, maintaining spatial relationships and visual consistency. It further proposes the 3D Representation Alignment Loss which uses contrastive learning to align multi-level semantic representations in latent space, enhancing geometric and textural fidelity.
What carries the argument
Unified mesh-texture joint representation processed by Transformer-based scene encoder, combined with 3D Representation Alignment Loss for semantic alignment in latent space.
If this is right
- Outperforms existing methods that rely on 2D adaptations in generation quality.
- Provides greater editing flexibility for 3D scenes.
- Maintains spatial relationships and visual consistency among objects in generated scenes.
- Enhances geometric and textural fidelity through multi-level semantic alignment.
Where Pith is reading between the lines
- Direct 3D modeling could reduce errors in applications like virtual reality where accurate geometry matters.
- Similar unified representations might apply to other generative tasks involving 3D data.
- The approach suggests potential for fully native 3D diffusion models without hybrid pipelines.
Load-bearing premise
Adapting 3D representations to the 2D domain inevitably introduces geometric structural distortion and texture detail degradation that cannot be adequately mitigated by existing adaptation techniques.
What would settle it
Running Native3D and a 2D-adapted baseline on identical scene prompts and measuring if Native3D shows measurably less distortion in 3D metrics like surface accuracy and texture sharpness.
Figures

read the original abstract
This paper presents Native3D, the first end-to-end 3D scene generation framework that completely bypasses 2D intermediate representations. Traditional approaches typically require adapting 3D representations to the 2D domain to leverage pre-trained diffusion models, which inevitably introduces domain adaptation issues including geometric structural distortion and texture detail degradation. To address these limitations, we design a unified mesh-texture joint representation that simultaneously models both geometric structures and texture features through a Transformer-based scene encoder, effectively maintaining spatial relationships and visual consistency among objects within scenes. We further propose the 3D Representation Alignment Loss (3D REPA Loss), which employs an improved contrastive learning mechanism to align multi-level semantic representations in the latent space, significantly enhancing geometric and textural fidelity. Experimental results demonstrate that Native3D outperforms existing methods in both generation quality and editing flexibility, providing a novel solution for 3D scene editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Native3D as the first end-to-end 3D scene generation framework that bypasses 2D intermediate representations. It introduces a unified mesh-texture joint representation modeled via a Transformer-based scene encoder to maintain spatial and visual consistency, along with a 3D Representation Alignment Loss (3D REPA Loss) that uses contrastive learning to align multi-level semantic features in latent space. The work claims superior generation quality and editing flexibility over prior methods based on experimental results.
Significance. If the central claims are substantiated with rigorous experiments, the approach could meaningfully advance 3D scene generation by avoiding domain-shift artifacts from 2D adaptation pipelines. The unified 3D-native representation and semantic alignment loss represent a direct attempt to operate entirely in 3D, which aligns with ongoing efforts to reduce geometric and textural degradation in scene-level synthesis.
minor comments (2)
- The abstract states that 'experimental results demonstrate' outperformance but provides no information on datasets, evaluation metrics, baselines, or statistical significance; the full manuscript should include these details with error bars and ablation studies to support the quality and flexibility claims.
- The novelty claim of being 'the first' end-to-end 3D framework requires explicit differentiation from prior 3D-native or hybrid methods in the related-work section.
Simulated Author's Rebuttal
We thank the referee for their careful reading and positive evaluation of Native3D. The summary accurately captures our core contributions: the first end-to-end 3D scene generation framework that avoids 2D intermediates, the unified mesh-texture representation, and the 3D REPA Loss. We note that the recommendation is listed as uncertain despite the absence of any specific major comments or identified flaws in the provided report. We address this overall assessment below.
Circularity Check
No significant circularity identified
full rationale
The abstract and provided text contain no equations, derivations, predictions, or self-citations. The central claim is a high-level architectural description of a new end-to-end framework motivated by standard domain-adaptation issues in the field. No load-bearing step reduces to its inputs by construction, and no formal result is advanced that could be assessed for circularity. This is the expected outcome for a paper whose text offers no mathematical chain to inspect.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A Transformer-based scene encoder can maintain spatial relationships and visual consistency among objects in 3D scenes
invented entities (1)
-
3D REPA Loss
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL Technical Report,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Emerging Properties in Self-Supervised Vision Transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing Properties in Self-Supervised Vision Transformers, 2021. arXiv:2104.14294 [cs]. 1
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
SceneTex: High-Quality Texture Synthesis for Indoor Scenes via Diffusion Priors,
Dave Zhenyu Chen, Haoxuan Li, Hsin-Ying Lee, Sergey Tulyakov, and Matthias Nießner. SceneTex: High-Quality Texture Synthesis for Indoor Scenes via Diffusion Priors,
- [4]
-
[5]
Text2tex: Text-driven tex- ture synthesis via diffusion models
Dave Zhenyu Chen, Yawar Siddiqui, Hsin-Ying Lee, Sergey Tulyakov, and Matthias Nießner. Text2tex: Text-driven tex- ture synthesis via diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18558–18568, 2023. 1, 2, 3, 4, 6, 8, 12. 6
2023
-
[6]
Text2Shape: Generating Shapes from Natural Language by Learning Joint Embeddings
Kevin Chen, Christopher B. Choy, Manolis Savva, An- gel X. Chang, Thomas Funkhouser, and Silvio Savarese. Text2Shape: Generating Shapes from Natural Lan- guage by Learning Joint Embeddings, 2018. eprint: arXiv:1803.08495. 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
No-reference color image quality assessment: From entropy to perceptual quality, 2018
Xiaoqiao Chen, Qingyi Zhang, Manhui Lin, Guangyi Yang, and Chu He. No-reference color image quality assessment: From entropy to perceptual quality, 2018. 6
2018
-
[8]
Ctrl-Room: Controllable Text-to-3D Room Meshes Generation with Layout Con- straints, 2025
Chuan Fang, Yuan Dong, Kunming Luo, Xiaotao Hu, Rakesh Shrestha, and Ping Tan. Ctrl-Room: Controllable Text-to-3D Room Meshes Generation with Layout Con- straints, 2025. arXiv:2310.03602 [cs]. 1
-
[9]
3D-FRONT: 3D Furnished Rooms with layOuts and semaNTics, 2021
Huan Fu, Bowen Cai, Lin Gao, Lingxiao Zhang, Ji- aming Wang Cao Li, Zengqi Xun, Chengyue Sun, Rongfei Jia, Binqiang Zhao, and Hao Zhang. 3D-FRONT: 3D Furnished Rooms with layOuts and semaNTics, 2021. arXiv:2011.09127 [cs]. 6
-
[10]
Efros, Alek- sander Holynski, and Angjoo Kanazawa
Ayaan Haque, Matthew Tancik, Alexei A. Efros, Alek- sander Holynski, and Angjoo Kanazawa. Instruct- NeRF2NeRF: Editing 3D Scenes with Instructions, 2023. arXiv:2303.12789 [cs]. 1
-
[11]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aber- man, Yael Pritch, and Daniel Cohen-Or. Prompt-to- Prompt Image Editing with Cross Attention Control, 2022. arXiv:2208.01626 [cs]. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. CLIPScore: A Reference-free Evaluation Metric for Image Captioning, 2022. arXiv:2104.08718 [cs]. 6
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium, 2018. arXiv:1706.08500 [cs]. 6
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
RoomPainter: View-Integrated Diffusion for Consis- tent Indoor Scene Texturing, 2025
Zhipeng Huang, Wangbo Yu, Xinhua Cheng, ChengShu Zhao, Yunyang Ge, Mingyi Guo, Li Yuan, and Yonghong Tian. RoomPainter: View-Integrated Diffusion for Consis- tent Indoor Scene Texturing, 2025. arXiv:2412.16778 [cs]. 1, 3, 6
-
[15]
Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material, 2025
Team Hunyuan3D, Shuhui Yang, Mingxin Yang, Yifei Feng, Xin Huang, Sheng Zhang, Zebin He, Di Luo, Haolin Liu, Yunfei Zhao, Qingxiang Lin, Zeqiang Lai, Xianghui Yang, Huiwen Shi, Zibo Zhao, Bowen Zhang, Hongyu Yan, Lifu Wang, Sicong Liu, Jihong Zhang, Meng Chen, Liang Dong, Yiwen Jia, Yulin Cai, Jiaao Yu, Yixuan Tang, Dongyuan Guo, Junlin Yu, Hao Zhang, Zhe...
2025
-
[16]
Text2Room: Extracting Tex- tured 3D Meshes from 2D Text-to-Image Models, 2023
Lukas H ¨ollein, Ang Cao, Andrew Owens, Justin John- son, and Matthias Nießner. Text2Room: Extracting Tex- tured 3D Meshes from 2D Text-to-Image Models, 2023. arXiv:2303.11989 [cs]. 3
-
[17]
Shap-E: Generating Conditional 3D Implicit Functions
Heewoo Jun and Alex Nichol. Shap-E: Generat- ing Conditional 3D Implicit Functions, 2023. eprint: arXiv:2305.02463. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
InstructScene: Instruction- Driven 3D Indoor Scene Synthesis with Semantic Graph Prior, 2024
Chenguo Lin and Yadong Mu. InstructScene: Instruction- Driven 3D Indoor Scene Synthesis with Semantic Graph Prior, 2024. arXiv:2402.04717 [cs]. 6
-
[19]
COCO- GAN: Generation by Parts via Conditional Coordinating,
Chieh Hubert Lin, Chia-Che Chang, Yu-Sheng Chen, Da- Cheng Juan, Wei Wei, and Hwann-Tzong Chen. COCO- GAN: Generation by Parts via Conditional Coordinating,
- [20]
-
[21]
InfinityGAN: Towards Infinite-Pixel Image Synthesis, 2022
Chieh Hubert Lin, Hsin-Ying Lee, Yen-Chi Cheng, Sergey Tulyakov, and Ming-Hsuan Yang. InfinityGAN: Towards Infinite-Pixel Image Synthesis, 2022. arXiv:2104.03963 [cs]. 3
-
[22]
Magic3D: High-Resolution Text-to-3D Content Creation, 2023
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3D: High-Resolution Text-to-3D Content Creation, 2023. arXiv:2211.10440 [cs]. 3
-
[23]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling.arXiv preprint arXiv:2210.02747, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Marching cubes: A high resolution 3d surface construction algorithm
William E Lorensen and Harvey E Cline. Marching cubes: A high resolution 3d surface construction algorithm. InSem- inal graphics: pioneering efforts that shaped the field, pages 347–353. 1998. 4
1998
-
[25]
Point-E: A System for Generating 3D Point Clouds from Complex Prompts
Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, and Mark Chen. Point-E: A System for Gen- erating 3D Point Clouds from Complex Prompts, 2022. arXiv:2212.08751 [cs]. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Represen- tation Learning with Contrastive Predictive Coding, 2019. arXiv:1807.03748 [cs]. 8
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[27]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e Je- gou, Julien Mairal, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Text2Immersion: Generative Immersive Scene with 3D Gaussians, 2023
Hao Ouyang, Kathryn Heal, Stephen Lombardi, and Tiancheng Sun. Text2Immersion: Generative Immersive Scene with 3D Gaussians, 2023. arXiv:2312.09242 [cs]. 3
-
[29]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Milden- hall. DreamFusion: Text-to-3D using 2D Diffusion, 2022. eprint: arXiv:2209.14988. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Vi- sual Models From Natural Language Supervision, 2021. arXiv:2103.00020 [cs]. 1
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents.arXiv preprint arXiv:2204.06125, 1 (2):3, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models, 2022. arXiv:2112.10752 [cs]. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. LAION- 400M: Open Dataset of CLIP-Filtered 400 Million Image- Text Pairs, 2021. arXiv:2111.02114 [cs]. 6
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
Improved Adversarial Systems for 3D Object Generation and Reconstruction
Edward Smith and David Meger. Improved Adversarial Sys- tems for 3D Object Generation and Reconstruction, 2017. arXiv:1707.09557 [cs]. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
Shitao Tang, Fuyang Zhang, Jiacheng Chen, Peng Wang, and Yasutaka Furukawa. MVDiffusion: Enabling Holistic Multi- view Image Generation with Correspondence-Aware Diffu- sion, 2023. arXiv:2307.01097 [cs]. 1, 3
-
[36]
Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation, 2022
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation, 2022. arXiv:2211.12572 [cs]. 3
-
[37]
RoomTex: Tex- turing Compositional Indoor Scenes via Iterative Inpainting,
Qi Wang, Ruijie Lu, Xudong Xu, Jingbo Wang, Michael Yu Wang, Bo Dai, Gang Zeng, and Dan Xu. RoomTex: Tex- turing Compositional Indoor Scenes via Iterative Inpainting,
- [38]
-
[39]
Diffuse and Disperse: Im- age Generation with Representation Regularization, 2025
Runqian Wang and Kaiming He. Diffuse and Disperse: Im- age Generation with Representation Regularization, 2025. arXiv:2506.09027 [cs]. 5
-
[40]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation, 2023. arXiv:2305.16213 [cs]. 3
-
[41]
Direct3D: Scal- able Image-to-3D Generation via 3D Latent Diffusion Trans- former, 2024
Shuang Wu, Youtian Lin, Feihu Zhang, Yifei Zeng, Jingxi Xu, Philip Torr, Xun Cao, and Yao Yao. Direct3D: Scal- able Image-to-3D Generation via 3D Latent Diffusion Trans- former, 2024. arXiv:2405.14832 [cs]. 2, 6, 8
-
[42]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. ImgEdit: A Unified Image Editing Dataset and Benchmark, 2025. arXiv:2505.20275 [cs]. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation Alignment for Generation: Training Dif- fusion Transformers Is Easier Than You Think, 2025. arXiv:2410.06940 [cs]. 3, 5, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. ViewCrafter: Taming Video Diffu- sion Models for High-fidelity Novel View Synthesis, 2024. arXiv:2409.02048 [cs]. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
3DShape2VecSet: A 3D Shape Representation for Neural Fields and Generative Diffusion Models, 2023
Biao Zhang, Jiapeng Tang, Matthias Niessner, and Peter Wonka. 3DShape2VecSet: A 3D Shape Representation for Neural Fields and Generative Diffusion Models, 2023. arXiv:2301.11445 [cs]. 8
-
[46]
Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields, 2024
Jingbo Zhang, Xiaoyu Li, Ziyu Wan, Can Wang, and Jing Liao. Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields, 2024. arXiv:2305.11588 [cs]. 3
-
[47]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zibo Zhao, Zeqiang Lai, Qingxiang Lin, Yunfei Zhao, Haolin Liu, Shuhui Yang, Yifei Feng, Mingxin Yang, Sheng Zhang, Xianghui Yang, Huiwen Shi, Sicong Liu, Junta Wu, Yihang Lian, Fan Yang, Ruining Tang, Zebin He, Xinzhou Wang, Jian Liu, Xuhui Zuo, Zhuo Chen, Biwen Lei, Hao- han Weng, Jing Xu, Yiling Zhu, Xinhai Liu, Lixin Xu, Changrong Hu, Shaoxiong Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
ReStyle3D: Scene- Level Appearance Transfer with Semantic Correspondences,
Liyuan Zhu, Shengqu Cai, Shengyu Huang, Gordon Wet- zstein, Naji Khosravan, and Iro Armeni. ReStyle3D: Scene- Level Appearance Transfer with Semantic Correspondences,
- [49]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.