OmniView-Space: Reinforcing Spatial Reasoning via Multi-Perspective Spatial Mapping
Pith reviewed 2026-07-02 14:14 UTC · model grok-4.3
The pith
OmniView-Space re-anchors reconstructed geometry into query-aligned visual cognitive maps and textual spatial graphs to support multi-step spatial reasoning in multimodal models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OmniView-Space maintains spatial consistency through multimodal egocentric evidence by re-anchoring reconstructed geometry into a query-aligned visual cognitive map and a textual spatial graph, using tool-guided egocentric reasoning to select the required ego anchor, and applying cognitive-map distillation from MPSM trajectories and ego-frame rewards so the model can reason with self-generated maps.
What carries the argument
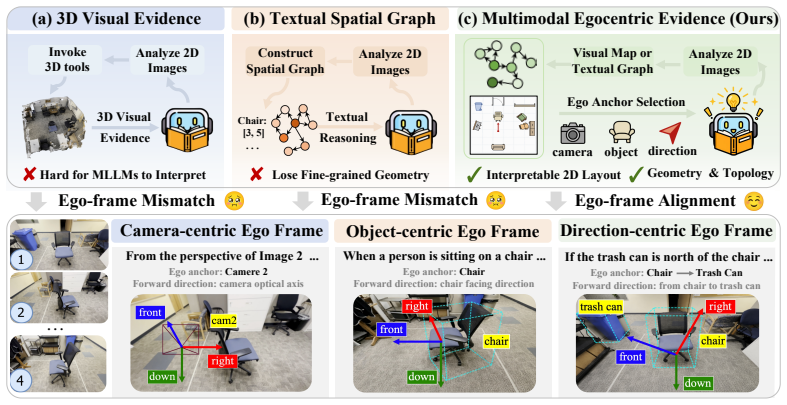
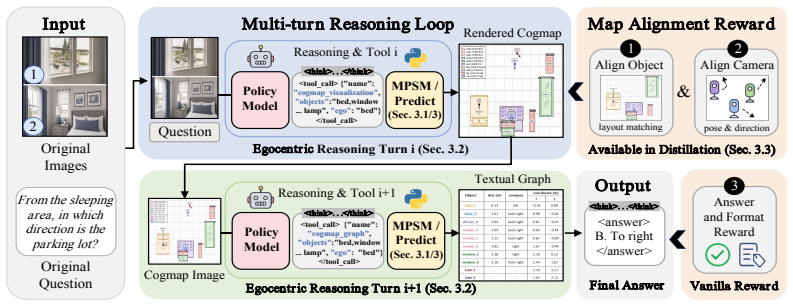
Multi-Perspective Spatial Mapping (MPSM), which re-anchors reconstructed geometry into a query-aligned visual cognitive map and a textual spatial graph.
If this is right
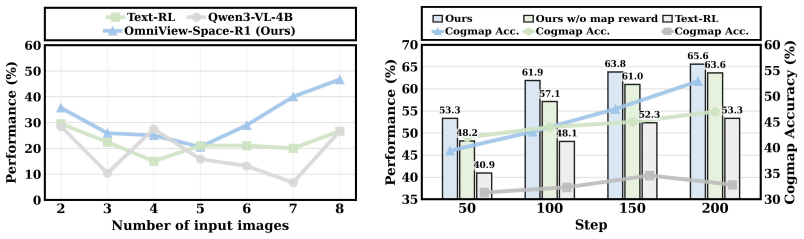
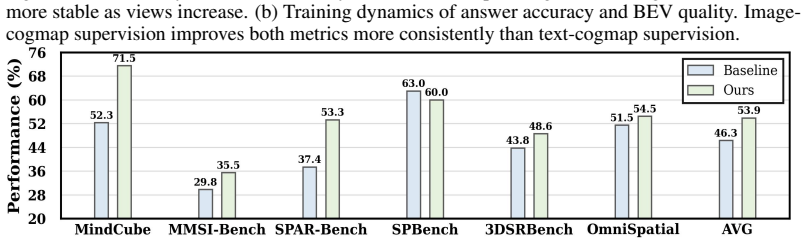
- Models achieve state-of-the-art performance on single- and multi-image spatial reasoning benchmarks.
- The distilled model sustains benchmark performance while lowering dependence on external geometry pipelines.
- An interleaved policy lets the model actively choose the ego anchor demanded by each query and request the matching MPSM evidence.
- Training on MPSM-generated trajectories and ego-frame rewards enables reasoning with self-generated cognitive maps.
Where Pith is reading between the lines
- The same re-anchoring step could be applied to navigation or robotic manipulation tasks that also require switching reference frames mid-sequence.
- Distillation might reduce error accumulation over longer chains of spatial questions by internalizing the mapping process.
- The approach points to a general pattern in which explicit external mapping tools are used only during training and then replaced by model-internal equivalents.
Load-bearing premise
Multi-Perspective Spatial Mapping can reliably re-anchor reconstructed geometry into query-aligned visual cognitive maps and textual spatial graphs that support complex multi-step reasoning across varying reference frames.
What would settle it
A controlled test on multi-step spatial queries with changing reference frames in which OmniView-Space and its distilled version show no accuracy gain over baselines that use only textual reasoning or standard 3D reconstruction would falsify the central claim.
Figures


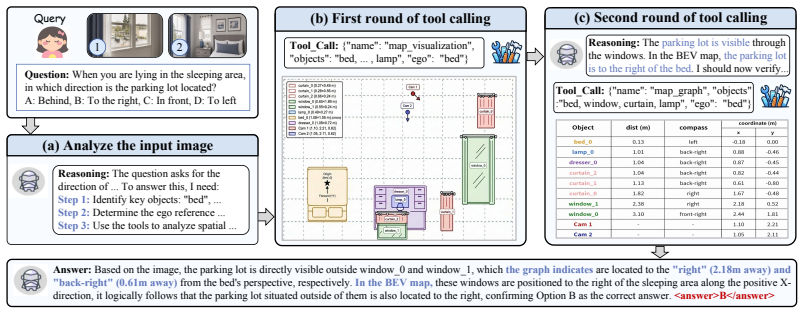

read the original abstract
Spatial intelligence remains a persistent challenge for Multimodal Large Language Models (MLLMs), as it requires coherent spatial scene representations beyond basic object recognition. Existing methods typically build such representations through textual reasoning or 3D reconstruction. However, they often falter during multi-step reasoning, particularly when required to dynamically re-anchor evidence to the specific camera-, object-, or direction-centric reference frames demanded by complex queries. To address this, we propose OmniView-Space, a framework designed to maintain spatial consistency through multimodal egocentric evidence. Our approach consists of three core components: (1) Multi-Perspective Spatial Mapping (MPSM), which re-anchors reconstructed geometry into a query-aligned visual cognitive map and a textual spatial graph; (2) Tool-Guided Egocentric Reasoning, an interleaved policy trained to actively select the ego anchor required by the query and request the corresponding MPSM evidence; and (3) Cognitive-Map Distillation, which uses MPSM-generated trajectories and ego-frame rewards to train the model to reason with self-generated cognitive maps. Experiments on single- and multi-image spatial reasoning benchmarks show that OmniView-Space achieves state-of-the-art performance. Furthermore, the distilled model maintains this performance while reducing reliance on external geometry pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OmniView-Space, a framework to improve spatial reasoning in MLLMs via three components: (1) Multi-Perspective Spatial Mapping (MPSM) that re-anchors reconstructed geometry into query-aligned visual cognitive maps and textual spatial graphs, (2) Tool-Guided Egocentric Reasoning, an interleaved policy that selects the required ego anchor and requests corresponding MPSM evidence, and (3) Cognitive-Map Distillation that trains the model on MPSM-generated trajectories and ego-frame rewards. Experiments are reported to achieve SOTA on single- and multi-image spatial reasoning benchmarks, with the distilled model preserving performance while reducing dependence on external geometry pipelines.
Significance. If the central claims hold after proper validation of the re-anchoring step, the work would be significant for multimodal spatial intelligence: it targets the specific failure mode of reference-frame inconsistency in multi-step queries and offers a path toward self-contained reasoning that does not require persistent external geometry modules. The distillation result, if reproducible, would be a practical contribution.
major comments (2)
- [Abstract / §3.1] Abstract (and §3.1, assuming standard section numbering for MPSM): the description of MPSM states that it 're-anchors reconstructed geometry into a query-aligned visual cognitive map and a textual spatial graph' that supports 'complex multi-step reasoning across varying reference frames,' yet supplies no algorithm, loss, alignment metric, or error-propagation analysis for frame consistency (camera-, object-, direction-centric). This component is load-bearing for both the SOTA claim and the distilled-model result; without isolated validation, downstream gains cannot be attributed to MPSM correctness versus the external geometry pipeline that is later removed.
- [Experiments / ablation tables] Experiments section (and any ablation tables): no metric or ablation isolates MPSM alignment fidelity or multi-step reference-frame error independently of the full pipeline and Tool-Guided policy. The headline SOTA and distillation results therefore rest on an untested assumption that the re-anchoring step preserves consistency; an explicit test (e.g., frame-alignment accuracy on held-out multi-step chains) is required to support the central claim.
minor comments (3)
- [§3] Notation for the three reference-frame types (camera-, object-, direction-centric) should be defined once with consistent symbols rather than repeated prose descriptions.
- [Abstract] The abstract claims 'state-of-the-art performance' without naming the exact benchmarks, prior SOTA numbers, or statistical significance; these details belong in the abstract or a summary table.
- [Figures] Figure captions for any cognitive-map visualizations should explicitly label the reference frame of each panel and the query that produced it.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for more explicit validation of the MPSM re-anchoring mechanism. We address each major comment below and will incorporate the requested details and experiments in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / §3.1] Abstract (and §3.1, assuming standard section numbering for MPSM): the description of MPSM states that it 're-anchors reconstructed geometry into a query-aligned visual cognitive map and a textual spatial graph' that supports 'complex multi-step reasoning across varying reference frames,' yet supplies no algorithm, loss, alignment metric, or error-propagation analysis for frame consistency (camera-, object-, direction-centric). This component is load-bearing for both the SOTA claim and the distilled-model result; without isolated validation, downstream gains cannot be attributed to MPSM correctness versus the external geometry pipeline that is later removed.
Authors: We agree that the current description of MPSM in the abstract and §3.1 is high-level and lacks the requested algorithmic details. The manuscript presents the re-anchoring conceptually but does not include an explicit algorithm, loss formulation, alignment metric, or error-propagation analysis for maintaining consistency across camera-, object-, and direction-centric frames. We will revise §3.1 to add a formal algorithmic description of the re-anchoring procedure, the specific alignment metric employed, and a dedicated error-propagation analysis. This addition will clarify how frame consistency is enforced and support attribution of downstream gains to MPSM. revision: yes
-
Referee: [Experiments / ablation tables] Experiments section (and any ablation tables): no metric or ablation isolates MPSM alignment fidelity or multi-step reference-frame error independently of the full pipeline and Tool-Guided policy. The headline SOTA and distillation results therefore rest on an untested assumption that the re-anchoring step preserves consistency; an explicit test (e.g., frame-alignment accuracy on held-out multi-step chains) is required to support the central claim.
Authors: We acknowledge that the existing ablations evaluate the full pipeline and Tool-Guided policy but do not isolate MPSM alignment fidelity or multi-step reference-frame error. To address this, we will add a new experiment reporting frame-alignment accuracy on held-out multi-step reasoning chains, using a metric that evaluates consistency independently of the external geometry pipeline and policy. This will be included in the Experiments section and ablation tables to directly test the re-anchoring assumption. revision: yes
Circularity Check
No circularity: claims rest on external benchmarks
full rationale
The paper introduces MPSM re-anchoring, Tool-Guided Egocentric Reasoning, and Cognitive-Map Distillation as a proposed framework, then reports SOTA results on single- and multi-image spatial reasoning benchmarks plus a distillation outcome. No equations, self-citations, or internal definitions are shown that would make any claimed prediction equivalent to its inputs by construction. The evaluation chain is therefore independent of the method's own definitions and relies on external test sets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.arXiv preprint arXiv:2304.08485, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Zhang, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Zhe Chen, Wenhai Wang, Yue Cao, et al. Internvl2: Scaling up vision foundation models and aligning for generic visual-linguistic tasks.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025
2025
-
[7]
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, et al. Mmsi-bench: A benchmark for multi-image spatial intelligence.arXiv preprint arXiv:2505.23764, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
arXiv preprint arXiv:2503.22976 (2025)
Jiahui Zhang, Yurui Chen, Yanpeng Zhou, Yueming Xu, Ze Huang, Jilin Mei, Junhui Chen, Yu- Jie Yuan, Xinyue Cai, Guowei Huang, et al. From flatland to space: Teaching vision-language models to perceive and reason in 3d.arXiv preprint arXiv:2503.22976, 2025
-
[9]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
SpaceR: Reinforcing MLLMs in Video Spatial Reasoning
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. Spacer: Reinforcing mllms in video spatial reasoning.arXiv preprint arXiv:2504.01805, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Scaling spatial intelligence with multimodal foundation models.arXiv preprint arXiv:2511.13719, 2025
Zhongang Cai, Ruisi Wang, Chenyang Gu, Fanyi Pu, Junxiang Xu, Yubo Wang, Wanqi Yin, Zhitao Yang, Chen Wei, Qingping Sun, et al. Scaling spatial intelligence with multimodal foundation models.arXiv preprint arXiv:2511.13719, 2025
-
[12]
Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025
Rui Yang, Ziyu Zhu, Yanwei Li, Jingjia Huang, Shen Yan, Siyuan Zhou, Zhe Liu, Xiangtai Li, Shuangye Li, Wenqian Wang, et al. Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025
-
[13]
Zhanpeng Luo, Ce Zhang, Silong Yong, Cunxi Dai, Qianwei Wang, Haoxi Ran, Guanya Shi, Katia Sycara, and Yaqi Xie. pyspatial: Generating 3d visual programs for zero-shot spatial reasoning.arXiv preprint arXiv:2603.00905, 2026
-
[14]
Think3d: Thinking with space for spatial reasoning.arXiv preprint arXiv:2601.13029, 2026
Zaibin Zhang, Yuhan Wu, Lianjie Jia, Yifan Wang, Zhongbo Zhang, Yijiang Li, Binghao Ran, Fuxi Zhang, Zhuohan Sun, Zhenfei Yin, Lijun Wang, and Huchuan Lu. Think3d: Thinking with space for spatial reasoning.arXiv preprint arXiv:2601.13029, 2026
-
[15]
Yibin Huang, Wang Xu, Wanyue Zhang, Helu Zhi, Jingjing Huang, Yangbin Xu, Yangang Sun, Conghui Zhu, and Tiejun Zhao. Video2layout: Recall and reconstruct metric-grounded cognitive map for spatial reasoning.arXiv preprint arXiv:2511.16160, 2025
-
[16]
Spatial mental modeling from limited views
Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, et al. Spatial mental modeling from limited views. InStructural Priors for Vision Workshop at ICCV’25, 2025. 10
2025
-
[17]
3dsrbench: A comprehensive 3d spatial reasoning benchmark
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso de Melo, and Alan Yuille. 3dsrbench: A comprehensive 3d spatial reasoning benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6924–6934, 2025
2025
-
[18]
Zheyuan Zhang, Fengyuan Hu, Jayjun Lee, Freda Shi, Parisa Kordjamshidi, Joyce Chai, and Ziqiao Ma. Do vision-language models represent space and how? evaluating spatial frame of reference under ambiguities.arXiv preprint arXiv:2410.17385, 2024
-
[19]
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models.arXiv preprint arXiv:2506.03135, 2025
-
[20]
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Guizilini, and Yue Wang. Physbench: Benchmarking and enhancing vision-language models for physical world understanding.arXiv preprint arXiv:2501.16411, 2025
-
[21]
Bydeway: Boost your multimodal llm with depth prompting in a training-free way
Rajarshi Roy, Devleena Das, Ankesh Banerjee, Arjya Bhattacharjee, Kousik Dasgupta, and Subarna Tripathi. Bydeway: Boost your multimodal llm with depth prompting in a training-free way. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6058–6064, 2025
2025
-
[22]
Synthetic vision: Training vision-language models to understand physics
Vahid Balazadeh, Mohammadmehdi Ataei, Hyunmin Cheong, Amir Hosein Khasahmadi, and Rahul G Krishnan. Synthetic vision: Training vision-language models to understand physics. arXiv e-prints, pages arXiv–2412, 2024
2024
-
[23]
Haoyu Zhang, Meng Liu, Zaijing Li, Haokun Wen, Weili Guan, Yaowei Wang, and Liqiang Nie. Spatial understanding from videos: Structured prompts meet simulation data.arXiv preprint arXiv:2506.03642, 2025
-
[24]
Perspective-aware reasoning in vision-language models via mental imagery simulation
Phillip Y Lee, Jihyeon Je, Chanho Park, Mikaela Angelina Uy, Leonidas Guibas, and Minhyuk Sung. Perspective-aware reasoning in vision-language models via mental imagery simulation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9241–9251, 2025
2025
-
[25]
Coarse correspondences boost spatial-temporal reasoning in multimodal language model
Benlin Liu, Yuhao Dong, Yiqin Wang, Zixian Ma, Yansong Tang, Luming Tang, Yongming Rao, Wei-Chiu Ma, and Ranjay Krishna. Coarse correspondences boost spatial-temporal reasoning in multimodal language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3783–3792, 2025
2025
-
[26]
Visual agentic ai for spatial reasoning with a dynamic api
Damiano Marsili, Rohun Agrawal, Yisong Yue, and Georgia Gkioxari. Visual agentic ai for spatial reasoning with a dynamic api. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19446–19455, 2025
2025
-
[27]
Shun Taguchi, Hideki Deguchi, Takumi Hamazaki, and Hiroyuki Sakai. Spatialprompting: Keyframe-driven zero-shot spatial reasoning with off-the-shelf multimodal large language models.arXiv preprint arXiv:2505.04911, 2025
-
[28]
Zhangquan Chen, Manyuan Zhang, Xinlei Yu, Xufang Luo, Mingze Sun, Zihao Pan, Xiang An, Yan Feng, Peng Pei, Xunliang Cai, et al. Think with 3d: Geometric imagination grounded spatial reasoning from limited views.arXiv preprint arXiv:2510.18632, 2025
-
[29]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. InEuropean conference on computer vision, pages 71–91. Springer, 2024
2024
-
[30]
GRIT: Teaching MLLMs to Think with Images
Yue Fan, Xuehai He, Diji Yang, Kaizhi Zheng, Ching-Chen Kuo, Yuting Zheng, Sravana Jyothi Narayanaraju, Xinze Guan, and Xin Eric Wang. Grit: Teaching mllms to think with images. arXiv preprint arXiv:2505.15879, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Advancing multi-modal language models with a comprehen- sive dataset and benchmark for chain-of-thought reasoning.Advances in Neural Information Processing Systems, 37:8612–8642, 2024. 11
2024
-
[32]
Visuothink: Empowering lvlm reasoning with multimodal tree search
Yikun Wang, Siyin Wang, Qinyuan Cheng, Zhaoye Fei, Liang Ding, Qipeng Guo, Dacheng Tao, and Xipeng Qiu. Visuothink: Empowering lvlm reasoning with multimodal tree search. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 21707–21719, 2025
2025
-
[33]
Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing
Junfei Wu, Jian Guan, Kaituo Feng, Qiang Liu, Shu Wu, Liang Wang, Wei Wu, and Tieniu Tan. Reinforcing spatial reasoning in vision-language models with interwoven thinking and visual drawing.arXiv preprint arXiv:2506.09965, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Mm-spatial: Exploring 3d spatial understanding in multimodal llms
Erik Daxberger, Nina Wenzel, David Griffiths, Haiming Gang, Justin Lazarow, Gefen Kohavi, Kai Kang, Marcin Eichner, Yinfei Yang, Afshin Dehghan, et al. Mm-spatial: Exploring 3d spatial understanding in multimodal llms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7395–7408, 2025
2025
-
[35]
Fuhao Chang, Shuxin Li, Yabei Li, and Lei He. Vlm-3d: end-to-end vision-language models for open-world 3d perception.arXiv preprint arXiv:2508.09061, 2025
-
[36]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence.arXiv preprint arXiv:2505.23747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Multi-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models
Runsen Xu, Weiyao Wang, Hao Tang, Xingyu Chen, Xiaodong Wang, Fu-Jen Chu, Dahua Lin, Matt Feiszli, and Kevin J Liang. Multi-spatialmllm: Multi-frame spatial understanding with multi-modal large language models.arXiv preprint arXiv:2505.17015, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Embodied-r: Collaborative framework for activating embodied spatial reasoning in foundation models via reinforcement learning
Baining Zhao, Ziyou Wang, Jianjie Fang, Chen Gao, Fanhang Man, Jinqiang Cui, Xin Wang, Xinlei Chen, Yong Li, and Wenwu Zhu. Embodied-r: Collaborative framework for activating embodied spatial reasoning in foundation models via reinforcement learning. InProceedings of the 33rd ACM International Conference on Multimedia, pages 11071–11080, 2025
2025
-
[39]
arXiv preprint arXiv:2505.24625 (2025)
Duo Zheng, Shijia Huang, Yanyang Li, and Liwei Wang. Learning from videos for 3d world: Enhancing mllms with 3d vision geometry priors.arXiv preprint arXiv:2505.24625, 2025
-
[40]
Geometrically-constrained agent for spatial reasoning.arXiv preprint arXiv:2511.22659, 2025
Zeren Chen, Xiaoya Lu, Zhijie Zheng, Pengrui Li, Lehan He, Yijin Zhou, Jing Shao, Bohan Zhuang, and Lu Sheng. Geometrically-constrained agent for spatial reasoning.arXiv preprint arXiv:2511.22659, 2025
-
[41]
Yi Han, Enshen Zhou, Shanyu Rong, Jingkun An, Pengwei Wang, Zhongyuan Wang, Cheng Chi, Lu Sheng, and Shanghang Zhang. Tiger: Tool-integrated geometric reasoning in vision-language models for robotics.arXiv preprint arXiv:2510.07181, 2025
-
[42]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[45]
arXiv preprint arXiv:2511.23075 (2025)
Ruosen Zhao, Zhikang Zhang, Jialei Xu, Jiahao Chang, Dong Chen, Lingyun Li, Weijian Sun, and Zizhuang Wei. Spacemind: Camera-guided modality fusion for spatial reasoning in vision-language models.arXiv preprint arXiv:2511.23075, 2025
-
[46]
Site: towards spatial intelligence thorough evaluation
Wenqi Wang, Reuben Tan, Pengyue Zhu, Jianwei Yang, Zhengyuan Yang, Lijuan Wang, Andrey Kolobov, Jianfeng Gao, and Boqing Gong. Site: towards spatial intelligence thorough evaluation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9058–9069, 2025
2025
-
[47]
Defining and evaluating visual language models’ basic spatial abilities: A perspective from psychometrics
Wenrui Xu, Dalin Lyu, Weihang Wang, Jie Feng, Chen Gao, and Yong Li. Defining and evaluating visual language models’ basic spatial abilities: A perspective from psychometrics. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11571–11590, 2025. 12
2025
-
[48]
Jirong Zha, Yuxuan Fan, Xiao Yang, Chen Gao, and Xinlei Chen. How to enable llm with 3d capacity? a survey of spatial reasoning in llm.arXiv preprint arXiv:2504.05786, 2025
-
[49]
Mental models in cognitive science.Cognitive science, 4(1):71–115, 1980
Philip N Johnson-Laird. Mental models in cognitive science.Cognitive science, 4(1):71–115, 1980
1980
-
[50]
Number 6
Philip Nicholas Johnson-Laird.Mental models: Towards a cognitive science of language, inference, and consciousness. Number 6. Harvard University Press, 1983
1983
-
[51]
Spatialbot: Precise spatial understanding with vision language models
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision language models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9490–9498. IEEE, 2025
2025
-
[52]
Yuecheng Liu, Dafeng Chi, Shiguang Wu, Zhanguang Zhang, Yaochen Hu, Lingfeng Zhang, Yingxue Zhang, Shuang Wu, Tongtong Cao, Guowei Huang, et al. Spatialcot: Advancing spatial reasoning through coordinate alignment and chain-of-thought for embodied task planning.arXiv preprint arXiv:2501.10074, 2025
-
[53]
Wufei Ma, Yu-Cheng Chou, Qihao Liu, Xingrui Wang, Celso de Melo, Jianwen Xie, and Alan Yuille. Spatialreasoner: Towards explicit and generalizable 3d spatial reasoning.arXiv preprint arXiv:2504.20024, 2025
-
[54]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
2024
-
[55]
Spatialrgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. Advances in Neural Information Processing Systems, 37:135062–135093, 2024
2024
-
[56]
Zhenyu Pan and Han Liu. Metaspatial: Reinforcing 3d spatial reasoning in vlms for the metaverse.arXiv preprint arXiv:2503.18470, 2025
-
[57]
EgoMind: Activating Spatial Cognition through Linguistic Reasoning in MLLMs
Zhenghao Chen, Huiqun Wang, and Di Huang. Egomind: Activating spatial cognition through linguistic reasoning in mllms.arXiv preprint arXiv:2604.03318, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
Hunar Batra, Haoqin Tu, Hardy Chen, Yuanze Lin, Cihang Xie, and Ronald Clark. Spatial- thinker: Reinforcing 3d reasoning in multimodal llms via spatial rewards.arXiv preprint arXiv:2511.07403, 2025
-
[59]
Hengyi Wang, Ruiqiang Zhang, Chang Liu, Guanjie Wang, Zehua Ma, Han Fang, and Weiming Zhang. Allocentric perceiver: Disentangling allocentric reasoning from egocentric visual priors via frame instantiation.arXiv preprint arXiv:2602.05789, 2026
-
[60]
Zehan Wang, Ziang Zhang, Jiayang Xu, Jialei Wang, Tianyu Pang, Chao Du, Hengshuang Zhao, and Zhou Zhao. Orient anything v2: Unifying orientation and rotation understanding.arXiv preprint arXiv:2601.05573, 2026
-
[61]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Spatialladder: Progressive training for spatial reasoning in vision-language models,
Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Spatialladder: Progressive training for spatial reasoning in vision-language models.arXiv preprint arXiv:2510.08531, 2025
-
[63]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
A new era of intelligence with gemini 3.Google
Sundar Pichai, Demis Hassabis, and Koray Kavukcuoglu. A new era of intelligence with gemini 3.Google. URL: https://blog.google/products-and-platforms/products/gemini/gemini-3/ (accessed: 2026-01-16), 2025
2026
-
[66]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Cambrian-s: Towards spatial supersensing in video
Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis L Brown II, Zihao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, et al. Cambrian-s: Towards spatial supersensing in video. InThe Fourteenth International Conference on Learning Representations, 2025
2025
-
[68]
Robobrain 2.0 technical report.arXiv preprint arXiv:2507.02029, 2025
BAAI RoboBrain Team, Mingyu Cao, Huajie Tan, Yuheng Ji, Xiansheng Chen, Minglan Lin, Zhiyu Li, Zhou Cao, Pengwei Wang, Enshen Zhou, et al. Robobrain 2.0 technical report.arXiv preprint arXiv:2507.02029, 2025
-
[69]
Yuhong Liu, Beichen Zhang, Yuhang Zang, Yuhang Cao, Long Xing, Xiaoyi Dong, Haodong Duan, Dahua Lin, and Jiaqi Wang. Spatial-ssrl: Enhancing spatial understanding via self- supervised reinforcement learning.arXiv preprint arXiv:2510.27606, 2025
-
[70]
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Alisson Azzolini, Junjie Bai, Hannah Brandon, Jiaxin Cao, Prithvijit Chattopadhyay, Huayu Chen, Jinju Chu, Yin Cui, Jenna Diamond, Yifan Ding, et al. Cosmos-reason1: From physical common sense to embodied reasoning.arXiv preprint arXiv:2503.15558, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Reinforced visual perception with tools.arXiv preprint arXiv:2509.01656, 2025
Zetong Zhou, Dongping Chen, Zixian Ma, Zhihan Hu, Mingyang Fu, Sinan Wang, Yao Wan, Zhou Zhao, and Ranjay Krishna. Reinforced visual perception with tools.arXiv preprint arXiv:2509.01656, 2025
-
[72]
Wentao Yuan, Jiafei Duan, Valts Blukis, Wilbert Pumacay, Ranjay Krishna, Adithyavairavan Murali, Arsalan Mousavian, and Dieter Fox. Robopoint: A vision-language model for spatial affordance prediction for robotics.arXiv preprint arXiv:2406.10721, 2024. 14 A Appendix Overview This appendix provides supplementary implementation details to support the main p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.