VGenST-Bench: A Benchmark for Spatio-Temporal Reasoning via Active Video Synthesis
Pith reviewed 2026-05-22 07:08 UTC · model grok-4.3
The pith
VGenST-Bench actively synthesizes controlled videos to diagnose fine-grained spatio-temporal reasoning in multimodal language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By replacing passive curation of real videos with active synthesis from generative models, VGenST-Bench produces videos whose spatio-temporal properties are known and adjustable in advance. The resulting dataset and task hierarchy let researchers isolate whether an MLLM fails at basic perception, at integrating motion across frames, or at higher-order spatial-temporal inference. This controlled construction directly supports fine-grained diagnosis of model capabilities.
What carries the argument
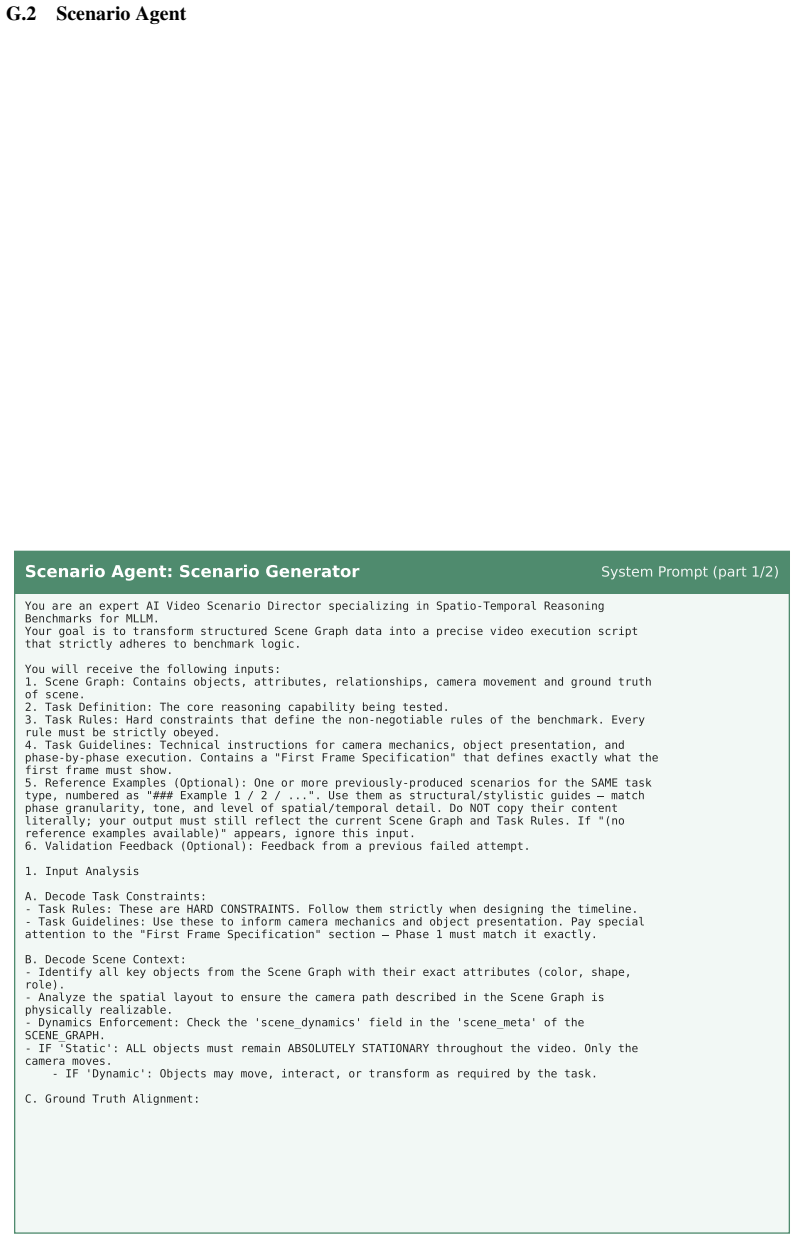
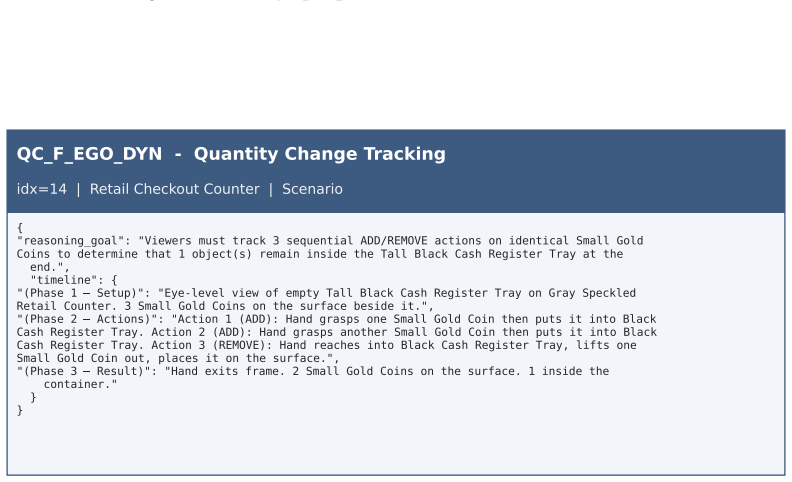
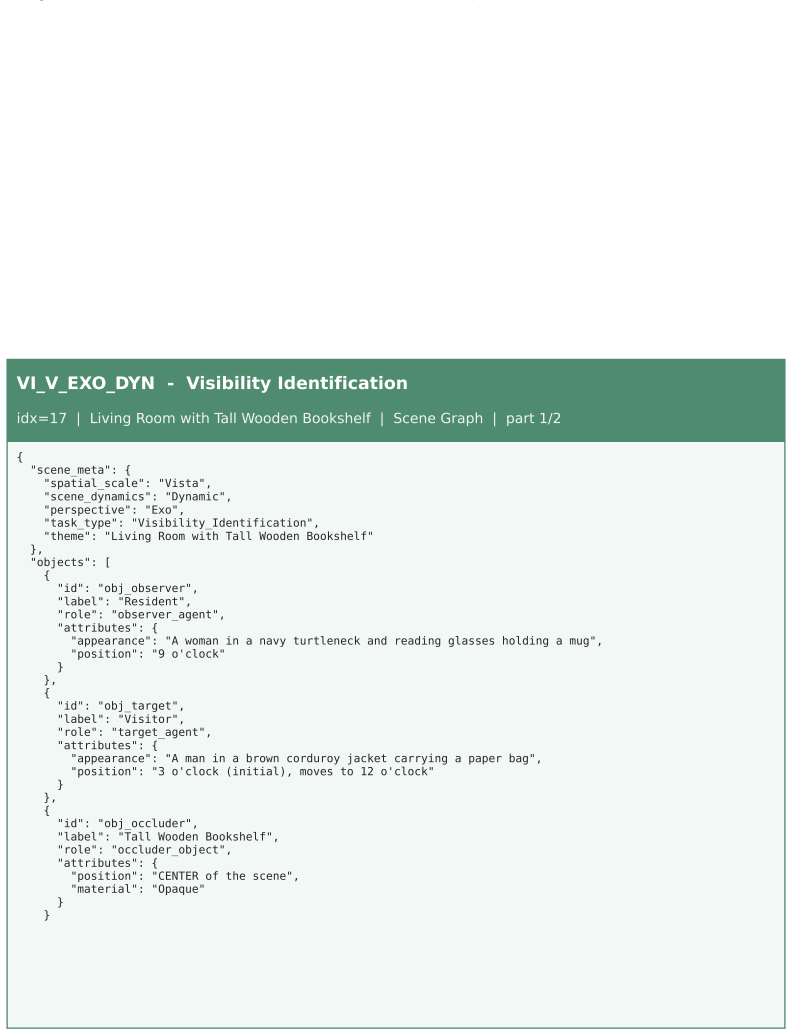
The multi-agent pipeline that combines generative video models with human quality control to produce videos and QA pairs under an explicit 3x2x2 taxonomy of spatial scale, perspective, and scene dynamics.
If this is right
- Existing MLLMs can be tested on decoupled perception versus reasoning subtasks to locate exact failure modes.
- New models can be trained or fine-tuned against the controlled variations in spatial scale, viewpoint, and dynamics.
- Benchmark scores become comparable across models because every video property is known and documented.
- The taxonomy supports systematic expansion by adding new dimensions while keeping the synthesis pipeline fixed.
Where Pith is reading between the lines
- If the synthesis method scales reliably, future benchmarks in other domains such as causal or social reasoning could adopt active generation instead of scraping existing media.
- The separation of perception and reasoning tasks suggests a template for auditing other multimodal capabilities where low-level feature extraction might mask higher-level deficits.
Load-bearing premise
The videos generated by the pipeline match real-world spatio-temporal properties closely enough that any model errors can be attributed to reasoning deficits rather than artifacts of the synthesis process.
What would settle it
Run the same MLLM suite on VGenST-Bench videos and on matched real-world videos that contain identical spatial-temporal events; if error patterns differ systematically, the synthesis artifacts explain the benchmark results.
Figures
























































































read the original abstract
Spatio-temporal reasoning is a core capability for Multimodal Large Language Models (MLLMs) operating in the real world. As such, evaluating it precisely has become an essential challenge. However, existing spatio-temporal reasoning benchmark datasets primarily rely on static image sets or passively curated video data, which limits the evaluation of fine-grained reasoning capabilities. In this paper, we introduce VGenST-Bench, a video benchmark that employs generative models to actively synthesize highly controlled and diverse evaluation scenarios. To construct VGenST-Bench, we propose a multi-agent pipeline incorporating a human quality control stage, ensuring the quality of all generated videos and QA pairs. We establish a comprehensive 3x2x2 video taxonomy, encompassing Spatial Scale, Perspective, and Scene Dynamics to span diverse scenarios. Furthermore, we design a hierarchical task suite that decouples low-level visual perception from high-level spatio-temporal reasoning. By shifting the paradigm from passive curation to active synthesis, VGenST-Bench enables fine-grained diagnosis of spatio-temporal understanding in MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VGenST-Bench, a video benchmark for spatio-temporal reasoning in MLLMs that shifts from passive curation to active synthesis via generative models and a multi-agent pipeline with human QC. It defines a 3x2x2 taxonomy (Spatial Scale, Perspective, Scene Dynamics) and a hierarchical task suite decoupling low-level perception from high-level reasoning, claiming this enables fine-grained diagnosis of model capabilities.
Significance. If the synthesized videos prove free of systematic artifacts that confound reasoning evaluation, the active-synthesis paradigm could meaningfully improve diagnostic granularity over existing passive video benchmarks. The taxonomy and task hierarchy are well-motivated design choices that directly target the stated limitations of prior datasets.
major comments (1)
- [Abstract and §3] Abstract and construction pipeline (described in §3): the claim that VGenST-Bench supports fine-grained diagnosis presupposes that generative artifacts do not systematically bias performance across taxonomy cells. No quantitative checks—optical-flow statistics, depth-consistency metrics, motion-continuity scores, or side-by-side realism ratings versus real videos—are reported to verify that the synthesized distribution matches real-world spatio-temporal statistics closely enough for the diagnostic claim to hold.
minor comments (2)
- [§3] The manuscript should clarify the exact generative models and prompting strategies used in the multi-agent pipeline, including any failure modes observed during video synthesis.
- [Figures 2–4] Figure captions and taxonomy diagrams would benefit from explicit mapping to the hierarchical task levels to improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the evidentiary requirements for our diagnostic claims. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and construction pipeline (described in §3): the claim that VGenST-Bench supports fine-grained diagnosis presupposes that generative artifacts do not systematically bias performance across taxonomy cells. No quantitative checks—optical-flow statistics, depth-consistency metrics, motion-continuity scores, or side-by-side realism ratings versus real videos—are reported to verify that the synthesized distribution matches real-world spatio-temporal statistics closely enough for the diagnostic claim to hold.
Authors: We agree that the current manuscript lacks the quantitative distributional checks the referee identifies. The multi-agent pipeline and human QC stage are designed to minimize obvious artifacts, but these do not substitute for explicit statistical validation. In the revised manuscript we will add to §3 the suggested analyses: optical-flow statistics, depth-consistency metrics, motion-continuity scores, and side-by-side human realism ratings comparing synthesized videos to real-world counterparts. These additions will directly support the fine-grained diagnosis claim by demonstrating that the synthesized distribution does not systematically deviate from real spatio-temporal statistics across taxonomy cells. revision: yes
Circularity Check
No significant circularity; benchmark construction is self-contained
full rationale
The paper presents a descriptive construction of VGenST-Bench via a multi-agent generative pipeline, 3x2x2 taxonomy, and hierarchical task suite without equations, fitted parameters, predictions, or derivations. The central claim that active synthesis enables fine-grained diagnosis follows directly from the stated design choices (controlled scenarios, decoupling perception from reasoning, human QC) and does not reduce to any prior inputs or self-citations by construction. No load-bearing step equates to its own inputs; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Generative models combined with multi-agent pipelines and human review can create videos whose spatio-temporal properties are suitable for fine-grained reasoning evaluation
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce VGenST-Bench, a video benchmark that employs generative models to actively synthesize highly controlled and diverse evaluation scenarios... multi-agent pipeline... 3×2×2 video taxonomy, encompassing Spatial Scale, Perspective, and Scene Dynamics... hierarchical task suite that decouples low-level visual perception from high-level spatio-temporal reasoning.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By shifting the paradigm from passive curation to active synthesis, VGenST-Bench enables fine-grained diagnosis of spatio-temporal understanding in MLLMs.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anthropic. Claude sonnet 4.6, 2025. URL https://www.anthropic.com/claude/sonnet. Accessed: 2026-05
work page 2025
-
[2]
Vqa: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. InProceedings of the IEEE international conference on computer vision, pages 2425–2433, 2015
work page 2015
-
[3]
ARKitScenes: A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, et al. Arkitscenes: A diverse real- world dataset for 3d indoor scene understanding using mobile rgb-d data.arXiv preprint arXiv:2111.08897, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Revisiting the" video" in video-language understanding
Shyamal Buch, Cristóbal Eyzaguirre, Adrien Gaidon, Jiajun Wu, Li Fei-Fei, and Juan Carlos Niebles. Revisiting the" video" in video-language understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2917–2927, 2022
work page 2022
-
[5]
Seedream: Bytedance image generation model
ByteDance Seed. Seedream: Bytedance image generation model. https://seed.bytedance. com/en/seedream5_0_lite, 2024. Accessed: 2026-05
work page 2024
-
[6]
Temporalbench: Towards fine-grained temporal understanding for multimodal video models
Mu Cai, Reuben Tan, Jianrui Zhang, Bocheng Zou, Kai Zhang, Feng Yao, Fangrui Zhu, Jing Gu, Yiwu Zhong, Yuzhang Shang, et al. Temporalbench: Towards fine-grained temporal understanding for multimodal video models. 2024
work page 2024
-
[7]
Has gpt-5 achieved spatial intelligence? an empirical study.arXiv preprint arXiv:2508.13142, 2025
Zhongang Cai, Yubo Wang, Qingping Sun, Ruisi Wang, Chenyang Gu, Wanqi Yin, Zhiqian Lin, Zhitao Yang, Chen Wei, Oscar Qian, et al. Holistic evaluation of multimodal llms on spatial intelligence.arXiv preprint arXiv:2508.13142, 2025
-
[8]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
work page 2024
-
[9]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision- language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
work page 2024
-
[10]
Zhenfang Chen, Shilong Dong, Kexin Yi, Yunzhu Li, Mingyu Ding, Antonio Torralba, Joshua B Tenenbaum, and Chuang Gan. Compositional physical reasoning of objects and events from videos.IEEE transactions on pattern analysis and machine intelligence, 2025
work page 2025
-
[11]
Spatialrgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. Advances in Neural Information Processing Systems, 37:135062–135093, 2024
work page 2024
-
[12]
Lost in time: A new temporal benchmark for videollms.arXiv preprint arXiv:2410.07752, 2024
Daniel Cores, Michael Dorkenwald, Manuel Mucientes, Cees GM Snoek, and Yuki M Asano. Lost in time: A new temporal benchmark for videollms.arXiv preprint arXiv:2410.07752, 2024
-
[13]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
work page 2017
-
[14]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
work page 2025
-
[17]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024
work page 2024
-
[18]
Learning human-perceived fakeness in ai-generated videos via multimodal llms, 2025
Xingyu Fu, Siyi Liu, Yinuo Xu, Pan Lu, Guangqiuse Hu, Tianbo Yang, Taran Anantasagar, Christopher Shen, Yikai Mao, Yuanzhe Liu, et al. Learning human-perceived fakeness in ai-generated videos via multimodal llms.arXiv preprint arXiv:2509.22646, 2025
-
[19]
Rohit Girdhar and Deva Ramanan. Cater: A diagnostic dataset for compositional actions and temporal reasoning.arXiv preprint arXiv:1910.04744, 2019
-
[20]
Ziyang Gong, Wenhao Li, Oliver Ma, Songyuan Li, Zhaokai Wang, Songyuan Li, Jiayi Ji, Xue Yang, Gen Luo, Junchi Yan, and Rongrong Ji. Space-10: A comprehensive benchmark for multimodal large language models in compositional spatial intelligence, 2025. URL https: //arxiv.org/abs/2506.07966
- [21]
-
[22]
Nano Banana: Gemini image generation model
Google DeepMind. Nano Banana: Gemini image generation model. https://deepmind. google/models/gemini/image/, 2025. Accessed: 2026-05
work page 2025
-
[23]
Google DeepMind. Gemini 3 Flash. https://deepmind.google/models/gemini/flash/,
-
[24]
Google DeepMind. Gemma 4. https://ai.google.dev/gemma/docs/core/model_ card_4/, 2026. Accessed: 2026-05
work page 2026
-
[25]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017
work page 2017
-
[26]
Egoexobench: A benchmark for first-and third-person view video understanding in mllms
Yuping He, Yifei Huang, Guo Chen, Baoqi Pei, Jilan Xu, Tong Lu, and Jiangmiao Pang. Egoexobench: A benchmark for first-and third-person view video understanding in mllms. arXiv preprint arXiv:2507.18342, 2025
-
[27]
Mary Hegarty, Daniel R Montello, Anthony E Richardson, Toru Ishikawa, and Kristin Lovelace. Spatial abilities at different scales: Individual differences in aptitude-test performance and spatial-layout learning.Intelligence, 34(2):151–176, 2006
work page 2006
-
[28]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019
work page 2019
-
[30]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al. π∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models.arXiv preprint arXiv:2506.03135, 2025
-
[32]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2901–2910, 2017. 11
work page 2017
-
[33]
What’s “up” with vision-language models? investigating their struggle with spatial reasoning
Amita Kamath, Jack Hessel, and Kai-Wei Chang. What’s “up” with vision-language models? investigating their struggle with spatial reasoning. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9161–9175, 2023
work page 2023
-
[34]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Allocentric and egocentric spatial representations: Definitions, distinctions, and interconnections
Roberta L Klatzky. Allocentric and egocentric spatial representations: Definitions, distinctions, and interconnections. InSpatial cognition: An interdisciplinary approach to representing and processing spatial knowledge, pages 1–17. Springer, 1998
work page 1998
-
[36]
Ku, M., Chong, T., Leung, J., Shah, K., Yu, A., and Chen, W
Benno Krojer, Mojtaba Komeili, Candace Ross, Quentin Garrido, Koustuv Sinha, Nicolas Ballas, and Mahmoud Assran. A shortcut-aware video-qa benchmark for physical understanding via minimal video pairs.arXiv preprint arXiv:2506.09987, 2025
-
[37]
Kling AI: Kuaishou video generation model
Kuaishou Technology. Kling AI: Kuaishou video generation model. https://klingai.com/,
-
[38]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[39]
Tvqa+: Spatio-temporal grounding for video question answering
Jie Lei, Licheng Yu, Tamara Berg, and Mohit Bansal. Tvqa+: Spatio-temporal grounding for video question answering. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 8211–8225, 2020
work page 2020
-
[40]
Revealing single frame bias for video-and-language learning
Jie Lei, Tamara Berg, and Mohit Bansal. Revealing single frame bias for video-and-language learning. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 487–507, 2023
work page 2023
-
[41]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed- bench: Benchmarking multimodal llms with generative comprehension.arXiv preprint arXiv:2307.16125, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Chenglin Li, Qianglong Chen, Zhi Li, Feng Tao, and Yin Zhang. Videocogqa: A control- lable benchmark for evaluating cognitive abilities in video-language models.arXiv preprint arXiv:2411.09105, 2024
-
[43]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
work page 2024
-
[44]
Unfolding spatial cognition: Evaluating multimodal models on visual simulations
Linjie Li, Mahtab Bigverdi, Jiawei Gu, Zixian Ma, Yinuo Yang, Ziang Li, Yejin Choi, and Ranjay Krishna. Unfolding spatial cognition: Evaluating multimodal models on visual simulations. arXiv preprint arXiv:2506.04633, 2025
-
[45]
Yun Li, Yiming Zhang, Tao Lin, XiangRui Liu, Wenxiao Cai, Zheng Liu, and Bo Zhao. Sti- bench: Are mllms ready for precise spatial-temporal world understanding? InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5622–5632, 2025
work page 2025
-
[46]
Super-clevr: A virtual benchmark to diagnose domain robustness in visual reasoning
Zhuowan Li, Xingrui Wang, Elias Stengel-Eskin, Adam Kortylewski, Wufei Ma, Benjamin Van Durme, and Alan L Yuille. Super-clevr: A virtual benchmark to diagnose domain robustness in visual reasoning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14963–14973, 2023
work page 2023
-
[47]
Zongxia Li, Xiyang Wu, Guangyao Shi, Yubin Qin, Hongyang Du, Fuxiao Liu, Tianyi Zhou, Dinesh Manocha, and Jordan Lee Boyd-Graber. Videohallu: Evaluating and mitigating multi- modal hallucinations on synthetic video understanding.arXiv preprint arXiv:2505.01481, 2025. 12
-
[48]
Jingli Lin, Runsen Xu, Shaohao Zhu, Sihan Yang, Peizhou Cao, Yunlong Ran, Miao Hu, Chenming Zhu, Yiman Xie, Yilin Long, et al. Mmsi-video-bench: A holistic benchmark for video-based spatial intelligence.arXiv preprint arXiv:2512.10863, 2025
-
[49]
Ost-bench: Evaluating the capabilities of mllms in online spatio-temporal scene understanding
Jingli Lin, Chenming Zhu, Runsen Xu, Xiaohan Mao, Xihui Liu, Tai Wang, and Jiangmiao Pang. Ost-bench: Evaluating the capabilities of mllms in online spatio-temporal scene understanding. arXiv preprint arXiv:2507.07984, 2025
-
[50]
Xiongkun Linghu, Jiangyong Huang, Xuesong Niu, Xiaojian Ma, Baoxiong Jia, and Siyuan Huang. Multi-modal situated reasoning in 3d scenes.Advances in Neural Information Process- ing Systems, 37:140903–140936, 2024
work page 2024
-
[51]
Fangyu Liu, Guy Emerson, and Nigel Collier. Visual spatial reasoning.Transactions of the Association for Computational Linguistics, 11:635–651, 2023
work page 2023
-
[52]
Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods
Weichen Liu, Qiyao Xue, Haoming Wang, Xiangyu Yin, Boyuan Yang, and Wei Gao. Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods. arXiv preprint arXiv:2511.15722, 2025
-
[53]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
work page 2024
-
[54]
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. Tempcompass: Do video llms really understand videos? InFindings of the Association for Computational Linguistics: ACL 2024, pages 8731–8772, 2024
work page 2024
-
[55]
3dsrbench: A comprehensive 3d spatial reasoning benchmark
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso de Melo, and Alan Yuille. 3dsrbench: A comprehensive 3d spatial reasoning benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6924–6934, 2025
work page 2025
-
[56]
Wan-Image: Pushing the Boundaries of Generative Visual Intelligence
Chaojie Mao, Chen-Wei Xie, Chongyang Zhong, Haoyou Deng, Jiaxing Zhao, Jie Xiao, Jinbo Xing, Jingfeng Zhang, Jingren Zhou, Jingyi Zhang, et al. Wan-image: Pushing the boundaries of generative visual intelligence.arXiv preprint arXiv:2604.19858, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
Scale and multiple psychologies of space
Daniel R Montello. Scale and multiple psychologies of space. InEuropean conference on spatial information theory, pages 312–321. Springer, 1993
work page 1993
- [58]
-
[59]
OpenAI. Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/ ,
-
[60]
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Recasens, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Mateusz Malinowski, Yi Yang, Carl Doersch, et al. Perception test: A diagnostic benchmark for multimodal video models.Advances in Neural Information Processing Systems, 36:42748–42761, 2023
work page 2023
-
[61]
Nlp evaluation in trouble: On the need to measure llm data contamination for each benchmark
Oscar Sainz, Jon Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. Nlp evaluation in trouble: On the need to measure llm data contamination for each benchmark. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10776–10787, 2023
work page 2023
-
[62]
Clevr-x: A visual reasoning dataset for natural language explanations
Leonard Salewski, A Sophia Koepke, Hendrik PA Lensch, and Zeynep Akata. Clevr-x: A visual reasoning dataset for natural language explanations. InInternational Workshop on Extending Explainable AI Beyond Deep Models and Classifiers, pages 69–88. Springer, 2020
work page 2020
-
[63]
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Team Seedance, Heyi Chen, Siyan Chen, Xin Chen, Yanfei Chen, Ying Chen, Zhuo Chen, Feng Cheng, Tianheng Cheng, Xinqi Cheng, et al. Seedance 1.5 pro: A native audio-visual joint generation foundation model.arXiv preprint arXiv:2512.13507, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Vidu: Ai video generation model
Shengshu Technology. Vidu: Ai video generation model. https://www.vidu.com/, 2024. Accessed: 2026-05. 13
work page 2024
-
[65]
Both text and images leaked! a systematic analysis of data contamination in multimodal llm
Dingjie Song, Sicheng Lai, Mingxuan Wang, Shunian Chen, Lichao Sun, and Benyou Wang. Both text and images leaked! a systematic analysis of data contamination in multimodal llm. arXiv preprint arXiv:2411.03823, 2024
-
[66]
Kexian Tang, Junyao Gao, Yanhong Zeng, Haodong Duan, Yanan Sun, Zhening Xing, Wenran Liu, Kaifeng Lyu, and Kai Chen. Lego-puzzles: How good are mllms at multi-step spatial reasoning?arXiv preprint arXiv:2503.19990, 2025
-
[67]
Qwen Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[68]
Seedance 2.0: Advancing Video Generation for World Complexity
Team Seedance. Seedance 2.0: Advancing video generation for world complexity.arXiv preprint arXiv:2604.14148, 2026. URL https://arxiv.org/abs/2604.14148. ByteDance Seed
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[69]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models.arXiv preprint arXiv:2402.12289, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9568–9578, 2024
work page 2024
-
[71]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Is a picture worth a thousand words? delving into spatial reasoning for vision language models
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Yixuan Li, and Neel Joshi. Is a picture worth a thousand words? delving into spatial reasoning for vision language models. Advances in Neural Information Processing Systems, 37:75392–75421, 2024
work page 2024
-
[73]
Siting Wang, Luoyang Sun, Cheng Deng, Kun Shao, Minnan Pei, Zheng Tian, Haifeng Zhang, and Jun Wang. Spatialviz-bench: Automatically generated spatial visualization reasoning tasks for mllms.arXiv e-prints, pages arXiv–2507, 2025
work page 2025
-
[74]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Xingrui Wang, Wufei Ma, Zhuowan Li, Adam Kortylewski, and Alan L Yuille. 3d-aware visual question answering about parts, poses and occlusions.Advances in Neural Information Processing Systems, 36:58717–58735, 2023
work page 2023
-
[76]
Xingrui Wang, Wufei Ma, Angtian Wang, Shuo Chen, Adam Kortylewski, and Alan Yuille. Compositional 4d dynamic scenes understanding with physics priors for video question answer- ing.arXiv preprint arXiv:2406.00622, 2024
-
[77]
Spatial457: A diagnostic benchmark for 6d spatial reasoning of large mutimodal models
Xingrui Wang, Wufei Ma, Tiezheng Zhang, Celso M de Melo, Jieneng Chen, and Alan Yuille. Spatial457: A diagnostic benchmark for 6d spatial reasoning of large mutimodal models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 24669–24679, 2025
work page 2025
-
[78]
Video models are zero-shot learners and reasoners
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners. arXiv preprint arXiv:2509.20328, 2025. 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
Next-qa: Next phase of question- answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question- answering to explaining temporal actions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9777–9786, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.