REVIEW 2 major objections 2 cited by
Schedule-free spectral optimization matches tuned AdamW on 125M and 772M parameter models using one hyperparameter configuration across 1-8x Chinchilla horizons.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-25 05:36 UTC pith:CH6ZJZ5U
load-bearing objection SF-NorMuon delivers schedule-free training that matches tuned AdamW across horizons on 125M and 772M models with one fixed hyperparameter set. the 2 major comments →
Anytime Training with Schedule-Free Spectral Optimization
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SF-NorMuon is a schedule-free spectral optimizer that, with a single hyperparameter configuration, matches or exceeds tuned AdamW on 125M and 772M parameter language models across 1 to 8 times Chinchilla horizons. The work proves a stationarity guarantee for schedule-free spectral dynamics and shows that weight decay applied at the fast iterate is essential for long-horizon stability. This removes the need to commit to a training horizon upfront while preserving competitive performance.
What carries the argument
SF-NorMuon, a schedule-free spectral optimizer that applies weight decay at the fast iterate within schedule-free spectral dynamics.
Load-bearing premise
Weight decay applied at the fast iterate is essential for maintaining long-horizon stability in schedule-free spectral dynamics.
What would settle it
Training runs of SF-NorMuon on 772M parameter models over 8x Chinchilla horizons that exhibit instability or performance drops when weight decay is removed from the fast iterate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SF-NorMuon, a schedule-free spectral optimizer, claiming that a single hyperparameter configuration matches or exceeds per-horizon-tuned AdamW on 125M and 772M parameter language models across 1--8× Chinchilla horizons. It further states a stationarity guarantee for schedule-free spectral dynamics and identifies weight decay applied at the fast iterate as essential for long-horizon stability, enabling horizon-independent high-quality checkpoints.
Significance. If the empirical matching holds with the reported single-configuration robustness and the stationarity result is non-vacuous, the work would meaningfully advance practical anytime optimization by reducing horizon-dependent retuning costs and supporting continual learning. The theoretical identification of the weight-decay placement provides a concrete design principle that could guide further schedule-free methods.
major comments (2)
- [Abstract] Abstract: the central empirical claim (SF-NorMuon matches or exceeds tuned AdamW with one fixed hyperparameter set across two model sizes and multiple horizons) is stated without reference to any table, figure, ablation, or error analysis, preventing assessment of effect size, variance, or whether the result is load-bearing for the 'closes this gap' conclusion.
- [Abstract] Abstract (theoretical analysis section): the stationarity guarantee and the claim that weight decay at the fast iterate is 'essential for long-horizon stability' are asserted without any displayed equations, assumptions, or derivation outline, so it is impossible to verify whether the condition is derived or imposed by construction.
Simulated Author's Rebuttal
We thank the referee for their comments on the abstract. We respond to each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (SF-NorMuon matches or exceeds tuned AdamW with one fixed hyperparameter set across two model sizes and multiple horizons) is stated without reference to any table, figure, ablation, or error analysis, preventing assessment of effect size, variance, or whether the result is load-bearing for the 'closes this gap' conclusion.
Authors: We agree the abstract would be clearer with explicit pointers to the supporting evidence. The performance comparisons (including means and standard deviations over three random seeds) appear in Section 4, Tables 1–2 and Figures 2–4; hyperparameter robustness and weight-decay ablations are in Section 5. In the revision we will add concise parenthetical citations to these results within the abstract. revision: yes
-
Referee: [Abstract] Abstract (theoretical analysis section): the stationarity guarantee and the claim that weight decay at the fast iterate is 'essential for long-horizon stability' are asserted without any displayed equations, assumptions, or derivation outline, so it is impossible to verify whether the condition is derived or imposed by construction.
Authors: The stationarity guarantee is stated and proved as Theorem 3.1 (with the key assumption of weight decay applied to the fast iterate). The necessity of this placement is shown by a counter-example in Appendix B when weight decay is instead applied to the slow iterate. The abstract summarizes the result at high level; we will add a reference to Theorem 3.1 in the revised abstract. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's primary result is the empirical observation that a single fixed hyperparameter configuration of SF-NorMuon matches or exceeds per-horizon-tuned AdamW on 125M and 772M models across 1-8× Chinchilla horizons. The mentioned stationarity proof and weight-decay-at-fast-iterate condition are presented as supporting theoretical analysis, not as the load-bearing premise whose equations reduce to the performance numbers by construction. No self-definitional steps, fitted-input-called-prediction patterns, or load-bearing self-citation chains appear in the abstract or described material that would equate any claimed prediction to its own inputs. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
read the original abstract
Standard neural network training relies on learning-rate schedules tied to a fixed horizon, leading to strong path dependence and costly re-tuning as data availability changes. Schedule-Free (SF) methods address this by removing explicit schedules, yet SF-AdamW, the current state-of-the-art anytime optimizer, consistently underperforms well-tuned AdamW baselines. We propose SF-NorMuon, a schedule-free spectral optimizer that closes this gap: with a single hyperparameter configuration, SF-NorMuon matches or exceeds tuned AdamW on 125M and 772M parameter language models across $1$--$8\times$ Chinchilla horizons. On the theoretical side, we prove a stationarity guarantee for schedule-free spectral dynamics and identify weight decay at the fast iterate as essential for long-horizon stability. SF-NorMuon enables practitioners to obtain high-quality checkpoints at any point during training without committing to a horizon in advance. By closing the performance gap with tuned baselines, SF-NorMuon makes horizon-free optimization more practical, taking a step towards truly open-ended, continual learning.
Figures





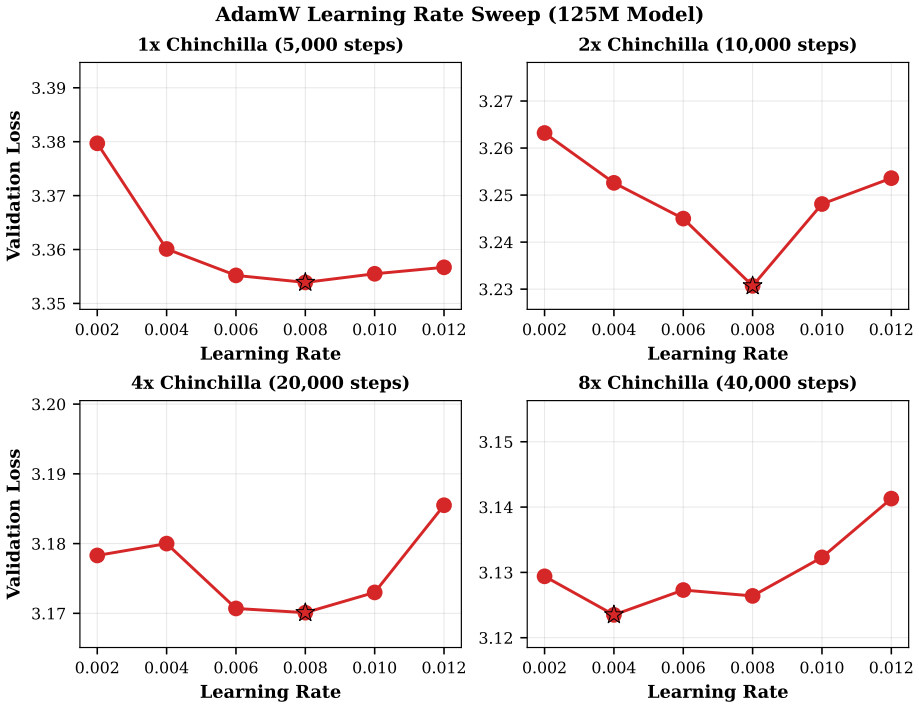

Forward citations
Cited by 2 Pith papers
-
WSqD: A Horizon-Free Learning Rate Schedule for Large Model Training
WSqD uses a horizon-independent shifted inverse-square-root base plus linear cooldown to get optimal last-iterate rates in convex stochastic optimization and match or beat tuned WSD on LLM pretraining with one reused ...
-
Scale Weight Decay and Train Better
Muon with weight decay scaled by η/η_max reaches the same MoE validation loss ~30% faster than constant-decay Muon while preserving asymptotic stationarity of the unregularized objective.
Reference graph
Works this paper leans on
-
[1]
Trevor Hastie, Robert Tibshirani, and Jerome Friedman.The Elements of Statistical Learning. Springer New York, 2009.isbn: 9780387848587.doi: 10.1007/978-0-387-84858-7.url: http://dx.doi.org/ 10.1007/978-0-387-84858-7
-
[2]
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning.http://www.deeplearningbook. org. MIT Press, 2016
work page 2016
-
[3]
Christopher M. Bishop and Hugh Bishop.Deep Learning: Foundations and Concepts. Springer In- ternational Publishing, 2024.isbn: 9783031454684.doi: 10.1007/978-3-031-45468-4 .url: http: //dx.doi.org/10.1007/978-3-031-45468-4
-
[4]
Language models are few-shot learners
Tom Brown et al. “Language models are few-shot learners”. In:Advances in neural information processing systems33 (2020), pp. 1877–1901
work page 2020
-
[5]
Hugo Touvron et al.LLaMA: Open and Efficient Foundation Language Models. 2023. arXiv:2302.13971 [cs.CL].url:https://arxiv.org/abs/2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Wayne Xin Zhao et al.A Survey of Large Language Models. 2023. eprint:arXiv:2303.18223
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Shervin Minaee et al.Large Language Models: A Survey. 2024. eprint:arXiv:2402.06196
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Anthony Brohan et al.RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. 2023. eprint:arXiv:2307.15818
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Yueen Ma et al.A Survey on Vision-Language-Action Models for Embodied AI. 2024. eprint:arXiv: 2405.14093
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Moo Jin Kim et al.OpenVLA: An Open-Source Vision-Language-Action Model. 2024. eprint:arXiv: 2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Continual lifelong learning with neural networks: A review,
German I. Parisi et al. “Continual lifelong learning with neural networks: A review”. In:Neural Networks113 (May 2019), pp. 54–71.issn: 0893-6080.doi: 10.1016/j.neunet.2019.01.012 .url: http://dx.doi.org/10.1016/j.neunet.2019.01.012
-
[12]
Liyuan Wang et al.A Comprehensive Survey of Continual Learning: Theory, Method and Application
- [13]
-
[14]
James Kirkpatrick et al. “Overcoming catastrophic forgetting in neural networks”. In:Proceedings of the National Academy of Sciences114.13 (Mar. 2017), pp. 3521–3526.issn: 1091-6490.doi:10.1073/pnas. 1611835114.url:http://dx.doi.org/10.1073/pnas.1611835114
-
[15]
A continual learning survey: Defying forgetting in classification tasks,
Matthias Delange et al. “A continual learning survey: Defying forgetting in classification tasks”. In: IEEE Transactions on Pattern Analysis and Machine Intelligence(2021).issn: 1939-3539.doi: 10. 1109/tpami.2021.3057446.url:http://dx.doi.org/10.1109/TPAMI.2021.3057446
-
[16]
Step-size Optimization for Continual Learning.arXiv preprint 2401.17401,
Thomas Degris et al. “Step-size optimization for continual learning”. In:arXiv preprint arXiv:2401.17401 (2024)
-
[17]
Anytime Pretraining: Horizon-Free Learning-Rate Schedules with Weight Averaging
Alexandru Meterez et al. “Anytime Pretraining: Horizon-Free Learning-Rate Schedules with Weight Averaging”. In:arXiv preprint arXiv:2602.03702(2026)
-
[18]
Aaron Defazio et al. “The road less scheduled”. In:Advances in Neural Information Processing Systems 37 (2024), pp. 9974–10007
work page 2024
-
[19]
How far away are truly hyperparameter-free learning algorithms?
Priya Kasimbeg et al. “How far away are truly hyperparameter-free learning algorithms?” In:arXiv preprint arXiv:2505.24005(2025)
-
[20]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. “SGDR: Stochastic Gradient Descent with Warm Restarts”. In: International Conference on Learning Representations. 2017.url:https://openreview.net/forum? id=Skq89Scxx
work page 2017
-
[21]
Jordan Hoffmann et al.Training Compute-Optimal Large Language Models. 2022. arXiv:2203.15556 [cs.CL].url:https://arxiv.org/abs/2203.15556
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Shengding Hu et al.MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies. 2024. arXiv:2404.06395 [cs.CL].url:https://arxiv.org/abs/2404.06395. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
A method for solving the convex programming problem with convergence rate O (1/k2)
Yurii Nesterov. “A method for solving the convex programming problem with convergence rate O (1/k2)”. In:Dokl akad nauk Sssr. Vol. 269. 1983, p. 543
work page 1983
-
[24]
An optimal method for stochastic composite optimization
Guanghui Lan. “An optimal method for stochastic composite optimization”. In:Mathematical Program- ming133.1 (2012), pp. 365–397
work page 2012
-
[25]
Alexander Hägele et al.Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations
- [26]
- [27]
-
[28]
Averaging Weights Leads to Wider Optima and Better Generalization
Pavel Izmailov et al. “Averaging weights leads to wider optima and better generalization”. In:arXiv preprint arXiv:1803.05407(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
Accelerating neural network training: An analysis of the AlgoPerf competition
Priya Kasimbeg et al. “Accelerating neural network training: An analysis of the AlgoPerf competition”. In: The Thirteenth International Conference on Learning Representations. 2025.url:https://openreview. net/forum?id=CtM5xjRSfm
work page 2025
-
[30]
Scaling laws and compute-optimal training beyond fixed training durations
Alexander Hägele et al. “Scaling laws and compute-optimal training beyond fixed training durations”. In:Advances in Neural Information Processing Systems37 (2024), pp. 76232–76264
work page 2024
-
[31]
Through the River: Understanding the Benefit of Schedule-Free Methods for Language Model Training
Minhak Song et al. “Through the River: Understanding the Benefit of Schedule-Free Methods for Language Model Training”. In:High-dimensional Learning Dynamics 2025. 2025.url: https : / / openreview.net/forum?id=b5HYeRzG9M
work page 2025
-
[32]
2026.url:https://openreview.net/forum?id=Jw7khYzYzl
Andrei Semenov, Matteo Pagliardini, and Martin Jaggi.Benchmarking Optimizers for Large Language Model Pretraining. 2026.url:https://openreview.net/forum?id=Jw7khYzYzl
work page 2026
-
[33]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. “Adam: A Method for Stochastic Optimization”. In:International Conference on Learning Representations (ICLR). 2015.url:https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[34]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. “Decoupled Weight Decay Regularization”. In:International Confer- ence on Learning Representations. 2019.url:https://openreview.net/forum?id=Bkg6RiCqY7
work page 2019
-
[35]
Keller Jordan et al.Muon: An optimizer for hidden layers in neural networks.https://kellerjordan. github.io/posts/muon/. Accessed: 2026-01-25. 2024
work page 2026
-
[36]
GitHub repository, master branch
Keller Jordan et al.Muon (GitHub repository): An optimizer for hidden layers in neural networks. GitHub repository, master branch. 2024.url:https://github.com/KellerJordan/Muon (visited on 01/25/2026)
work page 2024
- [37]
- [38]
-
[39]
Dion: Distributed orthonormalized updates.arXiv preprint arXiv:2504.05295, 2025.https://arxiv
Kwangjun Ahn et al. “Dion: Distributed Orthonormalized Updates”. In:arXiv preprint: 2504.05295 (2025)
-
[40]
Kwangjun Ahn, Noah Amsel, and John Langford.Dion2: A Simple Method to Shrink Matrix in Muon
- [41]
- [42]
-
[43]
Liliang Ren et al.Rethinking Language Model Scaling under Transferable Hypersphere Optimization
-
[44]
arXiv:2603.28743 [cs.LG].url:https://arxiv.org/abs/2603.28743
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Noah Amsel et al.The Polar Express: Optimal Matrix Sign Methods and Their Application to the Muon Algorithm. 2026. arXiv:2505.16932 [cs.LG].url:https://arxiv.org/abs/2505.16932
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
Ziyue Liu et al.Muon2: Boosting Muon via Adaptive Second-Moment Preconditioning. 2026. arXiv: 2604.09967 [cs.LG].url:https://arxiv.org/abs/2604.09967
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [47]
-
[48]
Alexey Kravatskiy et al.The Ky Fan Norms and Beyond: Dual Norms and Combinations for Matrix Optimization. 2025. arXiv:2512.09678 [math.OC].url:https://arxiv.org/abs/2512.09678
work page internal anchor Pith review arXiv 2025
-
[49]
Jingyuan Liu et al.Muon is Scalable for LLM Training. 2025. arXiv:2502 . 16982 [cs.LG].url: https://arxiv.org/abs/2502.16982
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Kimi Team.Kimi K2.5: Visual Agentic Intelligence. 2026. arXiv:2602.02276 [cs.CL].url: https: //arxiv.org/abs/2602.02276
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
GLM-5-Team.GLM-5: from Vibe Coding to Agentic Engineering. 2026. arXiv:2602.15763 [cs.LG]. url:https://arxiv.org/abs/2602.15763
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [52]
-
[53]
Levent Sagun et al.Empirical Analysis of the Hessian of Over-Parametrized Neural Networks. 2017. eprint:arXiv:1706.04454
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[54]
An Investigation into Neural Net Optimization via Hessian Eigenvalue Density
Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. “An Investigation into Neural Net Optimization via Hessian Eigenvalue Density”. In:Proceedings of the 36th International Conference on Machine Learning. Ed. by Kamalika Chaudhuri and Ruslan Salakhutdinov. Vol. 97. Proceedings of Machine Learning Research. PMLR, 2019, pp. 2232–2241.url: https : / / proceed...
work page 2019
-
[55]
arXiv preprint arXiv:2512.04299 , year=
Damek Davis and Dmitriy Drusvyatskiy.When do spectral gradient updates help in deep learning?2026. arXiv:2512.04299 [cs.LG].url:https://arxiv.org/abs/2512.04299
-
[56]
Fabian Schaipp et al. “The surprising agreement between convex optimization theory and learning-rate scheduling for large model training”. In:arXiv preprint arXiv:2501.18965(2025)
-
[57]
A simple weight decay can improve generalization
Anders Krogh and John A. Hertz. “A simple weight decay can improve generalization”. In:Proceedings of the 5th International Conference on Neural Information Processing Systems. NIPS’91. Denver, Colorado: Morgan Kaufmann Publishers Inc., 1991, pp. 950–957.isbn: 1558602224
work page 1991
-
[58]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Francesco D’Angelo et al.Why Do We Need Weight Decay in Modern Deep Learning?2024. arXiv: 2310.04415 [cs.LG].url:https://arxiv.org/abs/2310.04415
- [59]
-
[60]
Da Chang, Yongxiang Liu, and Ganzhao Yuan.On the Convergence of Muon and Beyond. 2026. arXiv: 2509.15816 [cs.LG].url:https://arxiv.org/abs/2509.15816
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
Wei Shen et al.On the Convergence Analysis of Muon. 2026. arXiv:2505.23737 [stat.ML] .url: https://arxiv.org/abs/2505.23737
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[62]
Naoki Sato, Hiroki Naganuma, and Hideaki Iiduka.Convergence Bound and Critical Batch Size of Muon Optimizer. 2025. arXiv:2507.01598 [cs.LG].url:https://arxiv.org/abs/2507.01598
work page internal anchor Pith review arXiv 2025
- [63]
-
[64]
Jeremy Bernstein and Laker Newhouse.Old Optimizer, New Norm: An Anthology. 2024. arXiv:2409. 20325 [cs.LG].url:https://arxiv.org/abs/2409.20325
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Thomas Pethick et al.Training Deep Learning Models with Norm-Constrained LMOs. 2025. arXiv: 2502.07529 [cs.LG].url:https://arxiv.org/abs/2502.07529
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Symbolic discovery of optimization algorithms
Xiangning Chen et al. “Symbolic discovery of optimization algorithms”. In:Advances in neural informa- tion processing systems36 (2023), pp. 49205–49233
work page 2023
-
[67]
Vineet Gupta, Tomer Koren, and Yoram Singer.Shampoo: Preconditioned Stochastic Tensor Optimiza- tion. 2018. arXiv:1802.09568 [cs.LG].url:https://arxiv.org/abs/1802.09568
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[68]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Priya Goyal et al. “Accurate, large minibatch sgd: Training imagenet in 1 hour”. In:arXiv preprint arXiv:1706.02677(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[69]
Why warmup the learning rate? underlying mechanisms and improvements
Dayal Singh Kalra and Maissam Barkeshli. “Why warmup the learning rate? underlying mechanisms and improvements”. In:Advances in Neural Information Processing Systems37 (2024), pp. 111760–111801. 14
work page 2024
-
[70]
Learning-rate-free learning by d-adaptation
Aaron Defazio and Konstantin Mishchenko. “Learning-rate-free learning by d-adaptation”. In:Interna- tional Conference on Machine Learning. PMLR. 2023, pp. 7449–7479
work page 2023
-
[71]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
Noam Shazeer et al. “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer”. In:International Conference on Learning Representations. 2017
work page 2017
-
[72]
GShard: Scaling giant models with conditional computation and automatic sharding
Dmitry Lepikhin et al. “GShard: Scaling giant models with conditional computation and automatic sharding”. In:International Conference on Learning Representations. 2021
work page 2021
-
[73]
Switch Transformers: scaling to trillion parameter models with simple and efficient sparsity
William Fedus, Barret Zoph, and Noam Shazeer. “Switch Transformers: scaling to trillion parameter models with simple and efficient sparsity”. In:Journal of Machine Learning Research23.120 (2022), pp. 1–39
work page 2022
-
[74]
Twan van Laarhoven.L2 Regularization versus Batch and Weight Normalization. 2017. arXiv:1706. 05350 [cs.LG].url:https://arxiv.org/abs/1706.05350
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [75]
-
[76]
Hugo Touvron et al.Llama 2: Open Foundation and Fine-Tuned Chat Models. 2023. arXiv:2307.09288 [cs.CL].url:https://arxiv.org/abs/2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[77]
Jianlin Su et al.RoFormer: Enhanced Transformer with Rotary Position Embedding. 2023. arXiv: 2104.09864 [cs.CL].url:https://arxiv.org/abs/2104.09864
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[78]
Biao Zhang and Rico Sennrich.Root Mean Square Layer Normalization. 2019. arXiv:1910.07467 [cs.LG].url:https://arxiv.org/abs/1910.07467
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [79]
-
[80]
Andrej Karpathy.NanoGPT.https://github.com/karpathy/nanoGPT. 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.