CoStream: Composing Simple Behaviors for Generalizable Complex Manipulation
Pith reviewed 2026-06-30 00:52 UTC · model grok-4.3
The pith
Complex manipulation emerges from composing three simple behaviors by right-multiplication on SE(3).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
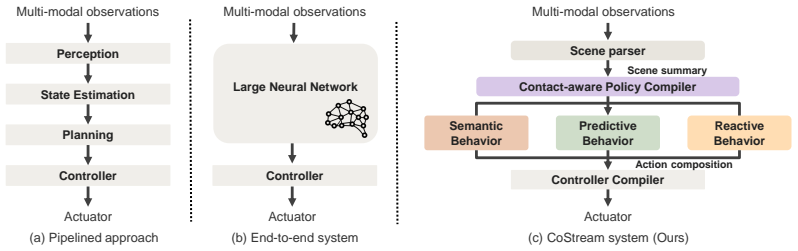
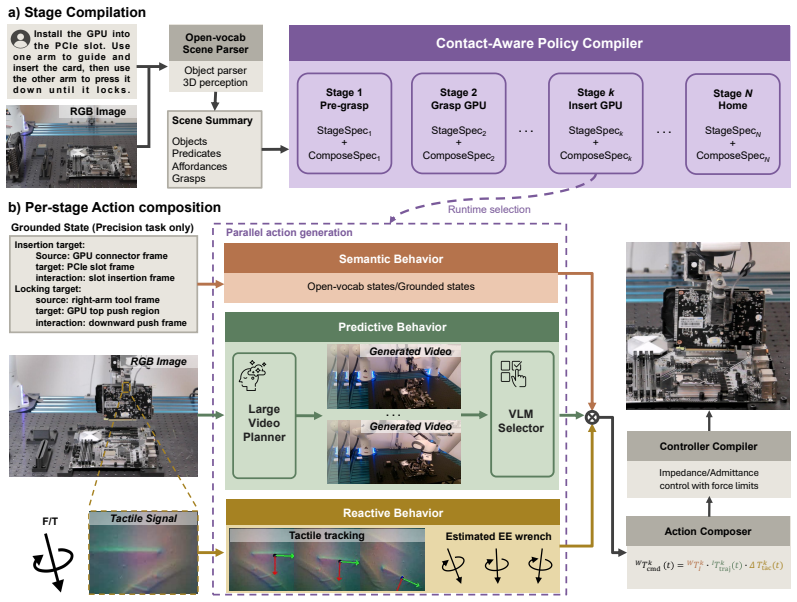
Complex manipulation capabilities can emerge naturally from the composition of simple, independent behaviors. Rather than deploying a monolithic policy or a rigid pipeline, CoStream orchestrates foundation models and diverse sensing modalities into a semantic behavior, a predictive behavior, and a reactive behavior whose outputs compose by right-multiplication into a single pose command at each control step, executed by a compliant controller.
What carries the argument
Right-multiplication on SE(3) of outputs from a semantic behavior, a predictive behavior, and a reactive behavior.
If this is right
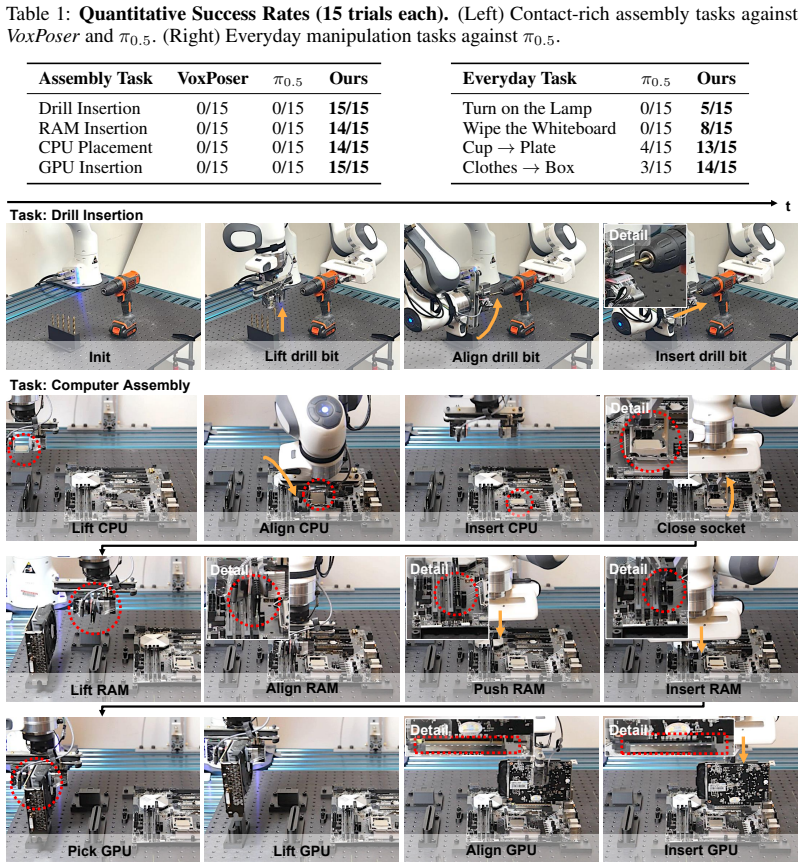
- The same three behaviors achieve millimeter precision on precision assembly without task-specific redesign.
- Generalization to new tasks occurs without collecting new demonstration data or rebuilding interfaces.
- Recovery from manual perturbations during execution is handled automatically by the reactive component.
- Strongest performance gains appear on contact-rich assembly and object transfer compared with monolithic baselines.
Where Pith is reading between the lines
- If the SE(3) multiplication rule holds across more tasks, the same composition pattern could be used to add navigation or grasping behaviors without redesigning the controller.
- The absence of arbitration logic may become a bottleneck only when behaviors produce directly opposing pose increments on the same axis.
- Replacing the foundation model inside the semantic behavior with a different vision-language model would provide a direct test of how much the overall success rate depends on the quality of the extracted constraints.
Load-bearing premise
The three behaviors produce outputs that remain compatible and non-conflicting when composed by right-multiplication on SE(3) at every time step.
What would settle it
A contact-rich insertion task in which the multiplied pose commands produce collisions or instability that any one of the three behaviors alone would have avoided.
Figures



read the original abstract
Long-horizon, contact-rich complex manipulation tasks, such as seating a GPU into a PCIe slot, demand both millimeter high precision and out-of-the-box generalization to new tasks. Existing paradigms struggle to satisfy both: classical pipelines use brittle, task-specific interfaces to achieve high-precision control but require costly pipeline redesigns to adapt to new tasks, whereas monolithic end-to-end policies provide better generalization but lack high precision on complex, out-of-distribution tasks unless retrained with new data. Both paradigms share an implicit assumption: once a manipulation capability is acquired, it must be deployed as a rigid pipeline or monolithic whole, rather than being freely decomposed and recomposed. In this paper, we show that complex manipulation capabilities can emerge naturally from the composition of simple, independent behaviors. Rather than deploying a monolithic policy or a rigid pipeline, we propose CoStream, a framework orchestrating foundation models and diverse sensing modalities into multiple composable core behaviors: a semantic behavior extracting spatial constraints via foundation models; a predictive behavior forecasting trajectories by tracking keypoints in imagined videos; and a reactive behavior providing high-frequency tactile and force corrections. On a shared $SE(3)$ interface, these outputs compose by right-multiplication into a single pose command at each control step, executed by a compliant controller. We demonstrate CoStream on 8 real-world tasks spanning everyday manipulation and precision assembly, with the strongest gains in contact-rich assembly and object transfer, and show robust recovery from manual perturbations during execution. Website: https://costream-simple.github.io
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that complex, long-horizon contact-rich manipulation (e.g., GPU seating) can emerge from composing three independent behaviors—semantic (foundation-model spatial constraints), predictive (keypoint trajectories from imagined videos), and reactive (tactile/force feedback)—via right-multiplication on SE(3) at each timestep to yield a single pose command executed by a compliant controller. It reports demonstration on eight real-world tasks with strongest gains in assembly and transfer, plus recovery from perturbations.
Significance. If the SE(3) composition is shown to produce feasible commands without hidden arbitration, the modular decomposition offers a concrete route to combine foundation-model generalization with high-precision reactive control, avoiding both brittle task-specific pipelines and data-hungry monolithic retraining.
major comments (2)
- [Abstract] Abstract: the central claim that semantic, predictive, and reactive outputs 'compose by right-multiplication into a single pose command' without additional arbitration or priority logic is load-bearing for the generalization argument, yet the manuscript supplies no derivation, compatibility condition, or empirical check for cases in which two behaviors prescribe opposing rotations/translations (common in contact-rich assembly).
- [Abstract] The reported gains on eight tasks rest on the assumption that the three behaviors remain non-conflicting under SE(3) multiplication at every timestep; without quantitative ablation on conflict frequency, controller compliance limits, or failure modes when the product becomes infeasible, it is impossible to assess whether the composition mechanism actually supports the 'naturally emerge' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional formalization and analysis will strengthen the manuscript. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that semantic, predictive, and reactive outputs 'compose by right-multiplication into a single pose command' without additional arbitration or priority logic is load-bearing for the generalization argument, yet the manuscript supplies no derivation, compatibility condition, or empirical check for cases in which two behaviors prescribe opposing rotations/translations (common in contact-rich assembly).
Authors: We agree that a formal derivation and explicit compatibility conditions are needed to support the load-bearing claim. The manuscript defines composition strictly as right-multiplication on SE(3) poses (a group operation that always yields a valid element of SE(3)), with the compliant controller responsible for physical execution. In the revised manuscript we will add a dedicated subsection in Methods that (i) derives the composition operator, (ii) states the algebraic compatibility condition (the product remains a feasible pose command), and (iii) explains how controller compliance resolves any residual physical conflict without additional arbitration logic. revision: yes
-
Referee: [Abstract] The reported gains on eight tasks rest on the assumption that the three behaviors remain non-conflicting under SE(3) multiplication at every timestep; without quantitative ablation on conflict frequency, controller compliance limits, or failure modes when the product becomes infeasible, it is impossible to assess whether the composition mechanism actually supports the 'naturally emerge' claim.
Authors: We acknowledge that the current manuscript lacks quantitative ablations on conflict frequency and controller limits. While the eight real-world tasks demonstrate successful execution without explicit arbitration, we did not report measurements of opposing prescriptions or infeasible-product cases. In the revision we will add an ablation subsection that (i) counts the frequency of conflicting rotation/translation prescriptions across all trials, (ii) characterizes the compliance limits of the low-level controller, and (iii) documents any observed failure modes when the composed command becomes physically unrealizable. revision: yes
Circularity Check
No circularity; empirical composition framework with no self-referential derivations or fitted predictions
full rationale
The paper presents CoStream as a framework that composes three independent behaviors (semantic, predictive, reactive) via SE(3) right-multiplication into a single pose command, validated empirically across 8 real-world tasks. No equations, parameter fitting, or derivations are described that reduce the central claim to inputs by construction. The compatibility of outputs under composition is an explicit modeling assumption tested through experiments rather than derived from prior self-citations or self-definitions. Self-citations, if present, are not load-bearing for the emergence claim, which rests on demonstration rather than mathematical reduction. This is a standard empirical systems contribution with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Outputs of semantic, predictive, and reactive behaviors remain compatible under SE(3) right-multiplication without additional conflict resolution
Reference graph
Works this paper leans on
-
[1]
H. Shi, H. Xu, Z. Huang, Y . Li, and J. Wu. Robocraft: Learning to see, simulate, and shape elasto-plastic objects with graph networks, 2022
2022
-
[2]
H. Shi, H. Xu, S. Clarke, Y . Li, and J. Wu. Robocook: Long-horizon elasto-plastic object manipulation with diverse tools. In7th Annual Conference on Robot Learning, 2023
2023
-
[3]
H. Chen, Y . Niu, K. Hong, S. Liu, Y . Wang, Y . Li, and K. R. Driggs-Campbell. Predicting object interactions with behavior primitives: An application in stowing tasks. In7th Annual Conference on Robot Learning, 2023
2023
-
[4]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y . Lu, H. Michalewski, I. Mordatch, K. Pe...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration, A. Padalkar, A. Pooley, A. Jain, A. Bewley, A. Herzog, A. Irpan, A. Khazatsky, A. Rai, A. Singh, A. Brohan, A. Raffin, A. Wahid, B. Burgess- Limerick, B. Kim, B. Sch ¨olkopf, B. Ichter, C. Lu, C. Xu, C. Finn, C. Xu, C. Chi, C. Huang, C. Chan, C. Pan, C. Fu, C. Devin, D. Driess, D. Pathak, D. Shah, D. B ¨uchler, D. Kalash- ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Huang, S
J. Huang, S. Yong, X. Ma, X. Linghu, P. Li, Y . Wang, Q. Li, S.-C. Zhu, B. Jia, and S. Huang. An embodied generalist agent in 3d world. InProceedings of the International Conference on Machine Learning (ICML), 2024
2024
-
[7]
D. A. Pomerleau. ALVINN: An autonomous land vehicle in a neural network.Advances in neural information processing systems, 1, 1988. 9
1988
-
[8]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[9]
Florence, C
P. Florence, C. Lynch, A. Zeng, O. A. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mor- datch, and J. Tompson. Implicit behavioral cloning. In5th Annual Conference on Robot Learning, 2021
2021
-
[10]
Ghosh, H
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y . Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[11]
K. Black, N. Brown, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, L. Smith, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A Vision-Language-Action Flow Model for General Robot Control. In Proceedings...
-
[12]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, b. ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Walke...
-
[13]
URLhttps://proceedings.mlr.press/v305/black25a
PMLR, 27–30 Sep 2025. URLhttps://proceedings.mlr.press/v305/black25a. html
2025
-
[14]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model. In P. Agrawal, O. Kroemer, and W. Burgard, editors,Proceedings of The 8th Conference on Robot Lea...
2025
-
[15]
M. J. Kim, C. Finn, and P. Liang. Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success. InProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025. doi:10.15607/RSS.2025.XXI.017
-
[16]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Yu, A. Zh...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
H. A. Simon.The Sciences of the Artificial. MIT Press, Cambridge, MA, 3 edition, Sept. 1996. ISBN 9780262264495
1996
-
[18]
R. Brooks. A robust layered control system for a mobile robot.IEEE Journal on Robotics and Automation, 2(1):14–23, 1986. doi:10.1109/JRA.1986.1087032
-
[19]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, A. Herzog, D. Ho, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, E. Jang, R. J. Ruano, K. Jeffrey, S. Jesmonth, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, K.-H. Lee, S. Levine, Y . Lu, L. Luu, C. Parada, P. Pastor, J. Quiambao, K. Rao, J. Rettingh...
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [20]
-
[21]
Y . Hong, H. Zhen, P. Chen, S. Zheng, Y . Du, Z. Chen, and C. Gan. 3d-llm: Injecting the 3d world into large language models. InAdvances in Neural Information Processing Systems, volume 36, pages 20482–20494, 2023
2023
- [22]
-
[23]
Liang, W
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. R. Florence, and A. Zeng. Code as policies: Language model programs for embodied control.2023 IEEE International Con- ference on Robotics and Automation (ICRA), pages 9493–9500, 2022
2023
-
[24]
Huang, C
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models. InConference on Robot Learning (CoRL), 2023
2023
-
[25]
Huang, C
W. Huang, C. Wang, Y . Li, R. Zhang, and L. Fei-Fei. Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation. In8th Annual Conference on Robot Learning, 2024
2024
-
[26]
K. Fang, F. Liu, P. Abbeel, and S. Levine. Moka: Open-world robotic manipulation through mark-based visual prompting.Robotics: Science and Systems (RSS), 2024
2024
- [27]
-
[28]
S. Nasiriany, F. Xia, W. Yu, T. Xiao, J. Liang, I. Dasgupta, A. Xie, D. Driess, A. Wahid, Z. Xu, et al. Pivot: Iterative visual prompting elicits actionable knowledge for vlms.arXiv preprint arXiv:2402.07872, 2024
-
[29]
H. Liu, S. Yao, H. Chen, J. Gao, J. Mao, J.-B. Huang, and Y . Du. Simpact: Simulation-enabled action planning using vision-language models, 2025
2025
-
[30]
Y . She, S. Wang, S. Dong, N. Sunil, A. Rodriguez, and E. Adelson. Cable manipulation with a tactile-reactive gripper.The International Journal of Robotics Research, 40(12-14):1385– 1401, 2021. doi:10.1177/02783649211027233
-
[31]
Y . Yuan, H. Che, Y . Qin, B. Huang, Z.-H. Yin, K.-W. Lee, Y . Wu, S.-C. Lim, and X. Wang. Robot synesthesia: In-hand manipulation with visuotactile sensing. In2024 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 6558–6565. IEEE, 2024
2024
-
[32]
Guzey, Y
I. Guzey, Y . Dai, B. Evans, S. Chintala, and L. Pinto. See to touch: Learning tactile dexterity through visual incentives. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 13825–13832. IEEE, 2024
2024
- [33]
- [34]
-
[35]
R. Ye, Y . Hu, Y . A. Bian, L. Kulm, and T. Bhattacharjee. Morpheus: a multimodal one- armed robot-assisted peeling system with human users in-the-loop. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 9540–9547. IEEE, 2024
2024
-
[36]
W. Hu, B. Huang, W. W. Lee, S. Yang, Y . Zheng, and Z. Li. Dexterous in-hand manipulation of slender cylindrical objects through deep reinforcement learning with tactile sensing, 2023
2023
-
[37]
Z. Yu, W. Xu, S. Yao, J. Ren, T. Tang, Y . Li, G. Gu, and C. Lu. Precise robotic needle-threading with tactile perception and reinforcement learning. InConference on Robot Learning, pages 3266–3276. PMLR, 2023
2023
- [38]
-
[39]
Huang, Y
B. Huang, Y . Wang, X. Yang, Y . Luo, and Y . Li. 3d vitac:learning fine-grained manipulation with visuo-tactile sensing. InProceedings of Robotics: Conference on Robot Learning(CoRL), 2024
2024
- [40]
-
[41]
K. Yu, Y . Han, Q. Wang, V . Saxena, D. Xu, and Y . Zhao. Mimictouch: Leveraging multi- modal human tactile demonstrations for contact-rich manipulation. In8th Annual Conference on Robot Learning, 2024
2024
-
[42]
H. Chen, J. Xu, H. Chen, K. Hong, B. Huang, C. Liu, J. Mao, Y . Li, Y . Du, and K. R. Driggs-Campbell. Multi-modal manipulation via multi-modal policy consensus.ArXiv, abs/2509.23468, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
S. Tian, F. Ebert, D. Jayaraman, M. Mudigonda, C. Finn, R. Calandra, and S. Levine. Manipulation by feel: Touch-based control with deep predictive models.arXiv preprint arXiv:1903.04128, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[44]
C. R. Garrett, R. Chitnis, R. Holladay, B. Kim, T. Silver, L. P. Kaelbling, and T. Lozano-P´erez. Integrated task and motion planning.Annual Review of Control, Robotics, and Autonomous Systems, 4(V olume 4, 2021):265–293, 2021. ISSN 2573-5144
2021
-
[45]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. RT-1: Robotics transformer for real-world control at scale. In Proceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[46]
H. Chen, J. Xu, L. Sheng, T. Ji, S. Liu, Y . Li, and K. Driggs-Campbell. Learning coordinated bimanual manipulation policies using state diffusion and inverse dynamics models. In2025 IEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[47]
H. Zhen, X. Qiu, P. Chen, J. Yang, X. Yan, Y . Du, Y . Hong, and C. Gan. 3d-vla: 3d vision- language-action generative world model.arXiv preprint arXiv:2403.09631, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
L. Wang, J. Zhao, Y . Du, E. H. Adelson, and R. Tedrake. Poco: Policy composition from and for heterogeneous robot learning, 2024
2024
-
[49]
C. Liu, H. Chen, S. H. Høeg, S. Yao, Y . Li, K. Hauser, and Y . Du. Flexible multitask learning with factorized diffusion policy, 2025
2025
-
[50]
A. Ajay, S. Han, Y . Du, S. Li, A. Gupta, T. Jaakkola, J. Tenenbaum, L. Kaelbling, A. Srivastava, and P. Agrawal. Compositional foundation models for hierarchical planning.Advances in Neural Information Processing Systems (NeurIPS), 2023. 12
2023
-
[51]
Y . Du, M. Yang, P. Florence, F. Xia, A. Wahid, B. Ichter, P. Sermanet, T. Yu, P. Abbeel, J. B. Tenenbaum, et al. Video language planning.International Conference on Learning Representations, 2024
2024
-
[52]
M. T. Mason. Compliance and force control for computer controlled manipulators.IEEE Transactions on Systems, Man, and Cybernetics, 11(6):418–432, 1981
1981
-
[53]
task frame formalism
H. Bruyninckx and J. De Schutter. Specification of force-controlled actions in the “task frame formalism”—a synthesis.IEEE Transactions on Robotics and Automation, 12(4):581–589, 1996
1996
-
[54]
Simeonov, Y
A. Simeonov, Y . Du, A. Tagliasacchi, J. B. Tenenbaum, A. Rodriguez, P. Agrawal, and V . Sitz- mann. Neural descriptor fields: SE(3)-equivariant object representations for manipulation. In IEEE International Conference on Robotics and Automation (ICRA), 2022
2022
-
[55]
B. Chen, T. Zhang, H. Geng, K. Song, C. Zhang, P. Li, W. T. Freeman, J. Malik, P. Abbeel, R. Tedrake, V . Sitzmann, and Y . Du. Large video planner enables generalizable robot control,
-
[56]
URLhttps://arxiv.org/abs/2512.15840
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Y . Xiao, J. Wang, N. Xue, N. Karaev, I. Makarov, B. Kang, X. Zhu, H. Bao, Y . Shen, and X. Zhou. Spatialtrackerv2: 3d point tracking made easy. InICCV, 2025
2025
-
[58]
H.-J. Huang, M. Kaess, and W. Yuan. Normalflow: Fast, robust, and accurate contact-based object 6dof pose tracking with vision-based tactile sensors.IEEE Robotics and Automation Letters, 10(1):452–459, Jan. 2025. ISSN 2377-3774. doi:10.1109/lra.2024.3505815. URL http://dx.doi.org/10.1109/LRA.2024.3505815
-
[59]
W.-H. Chen, J. Yang, L. Guo, and S. Li. Disturbance-observer-based control and related meth- ods – an overview.IEEE Transactions on Industrial Electronics, 63(2):1083–1095, 2016
2016
-
[60]
Berry, Physics of nonhermitian degeneracies, Czech
S. Baker and I. Matthews. Lucas-kanade 20 years on: A unifying framework.International Journal of Computer Vision, 56(3):221–255, feb 2004. ISSN 1573-1405. doi:10.1023/B: VISI.0000011205.11775.fd
work page doi:10.1023/b: 2004
-
[61]
W. Shen, N. Kumar, S. Chintalapudi, J. Wang, C. Watson, E. Hu, J. Cao, D. Jayaraman, L. P. Kaelbling, and T. Lozano-P ´erez. Tiptop: A modular open-vocabulary planning system for robotic manipulation, 2026
2026
-
[62]
B. Wen, M. Trepte, J. Aribido, J. Kautz, O. Gallo, and S. Birchfield. Foundationstereo: Zero- shot stereo matching, 2025
2025
-
[63]
W. Yuan, A. Murali, A. Mousavian, and D. Fox. M2t2: Multi-task masked transformer for object-centric pick and place. InConference on Robot Learning (CoRL), 2023
2023
-
[64]
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakr- ishna, R. Baruch, M. Bauza, M. Blokzijl, et al. Gemini robotics: Bringing AI into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Gemini robotics-er 1.6: Powering real-world robotics tasks through enhanced embodied reasoning.https://deepmind.google/blog/ gemini-robotics-er-1-6/, 2026
Google DeepMind. Gemini robotics-er 1.6: Powering real-world robotics tasks through enhanced embodied reasoning.https://deepmind.google/blog/ gemini-robotics-er-1-6/, 2026. Accessed: 2026-05-29
2026
-
[66]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, et al. SAM 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025. 13 6 Semantic behavior: grounding solver The semantic behavior grounds the task-frame anchor WT k I by minimizing a weighted sum ofM differentiable geometric resid...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.