DIM-WAM: World-Action Modeling with Diverse Historical Event Memory
Pith reviewed 2026-06-29 04:56 UTC · model grok-4.3
The pith
DiM-WAM raises long-horizon robot task success by merging multi-scale historical event memory and supervising global progress.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
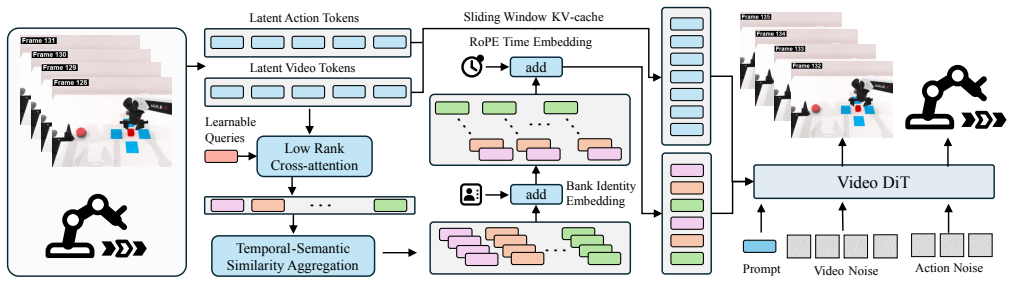
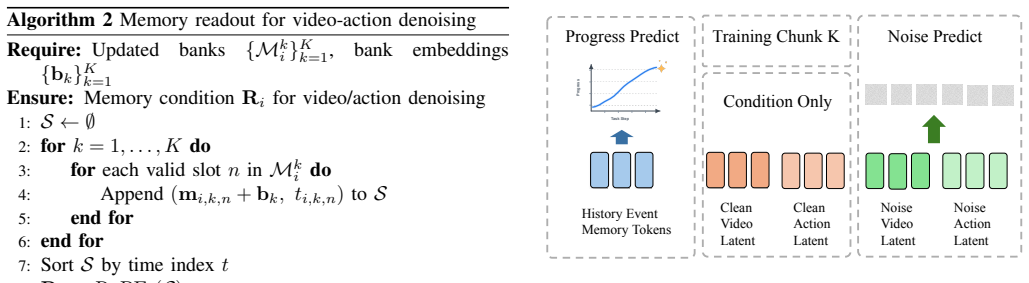
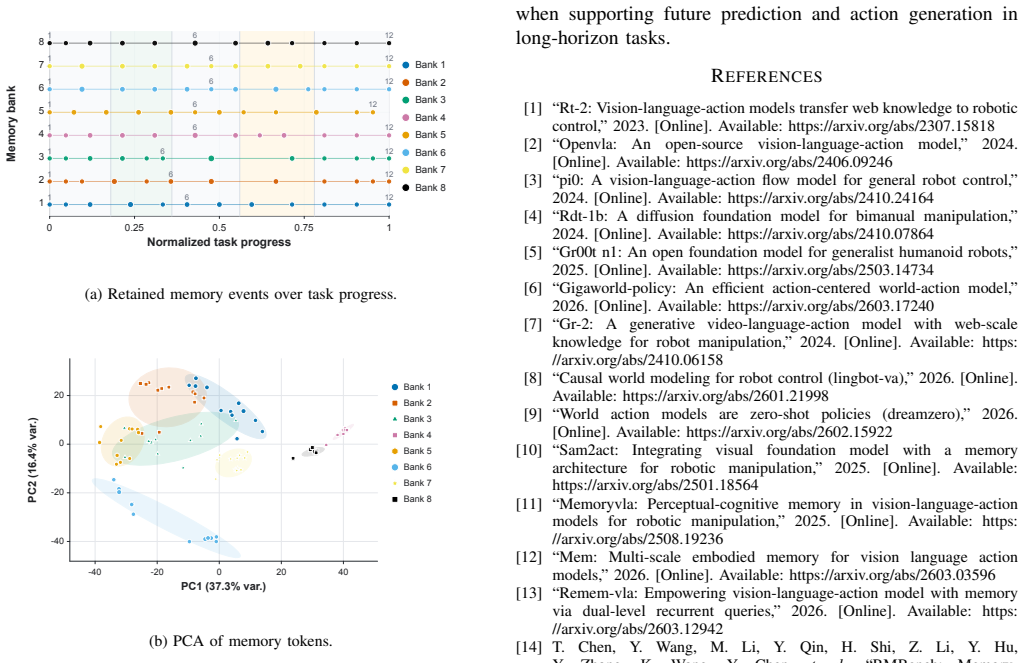
DiM-WAM extracts compact visual event information from observations, updates multiple independent memory banks through similarity-based merging, and reads bank-identity- and time-embedded long-term context to condition video and action denoising; a progress-supervision objective further trains memory tokens to represent both completed historical events and current task stage implications for the remaining work.
What carries the argument
Multi-bank memory with similarity-based merging plus progress-supervision objective that conditions denoising of future states and actions.
If this is right
- Long-horizon tasks become solvable at higher rates when predictions are conditioned on merged historical events and task progress.
- Memory tokens capture implications for unfinished work in addition to past observations.
- The same architecture produces gains on both simulated benchmarks and physical robot hardware.
- Independent bank merging preserves complementary temporal scales without explicit task labels.
Where Pith is reading between the lines
- The memory design could transfer to other sequential prediction settings that require awareness of distant past events.
- Increasing the number of banks might further separate distinct event types without changing the core training objective.
- If the merging step proves robust, explicit memory modules could be replaced by implicit learned banks in related robot control systems.
Load-bearing premise
Similarity-based merging across independent memory banks together with a progress-supervision objective will encode both completed events and remaining task implications without adding noise or requiring task-specific tuning.
What would settle it
Applying the model without further tuning to a new long-horizon manipulation task where its success rate drops below the explicit-memory baseline would falsify the reliability of the memory mechanism.
Figures


read the original abstract
World-action models have shown promising robot-manipulation performance by jointly predicting future visual states and actions. However, existing methods mainly rely on short-term history and short-horizon future prediction, which is insufficient for long-horizon tasks whose correct execution depends on earlier observations and task progress. Such temporally dependent tasks require effective use of complementary temporal information, including recent local context, cross-stage historical events, immediate future dynamics, and global task progress. To address long-term forgetting and poor awareness of the global task state, we introduce DiM-WAM, a memory-augmented world-action model that integrates multi-scale historical context, local future dynamics, and global task progress. The memory extracts compact visual event information from real observations, updates multiple memory banks through independent similarity-based merging, and then reads the bank-identity- and time-embedded long-term context to condition video and action denoising. A progress-supervision objective further encourages memory tokens to encode not only completed historical events but also the current task stage and its implications for the remaining task. On RMBench, DiM-WAM raises average success from 28.4% with LingBot-VA to 69.8%, exceeding the explicit-memory Mem-0 baseline at 42.0%. On four real-world Franka tasks, it improves average stage success from 70.7% to 91.5% and full-task success from 52.5% to 80.0%. Project page: https://wangkai-casia.github.io/dim-wam/{\texttt{https://wangkai-casia.github.io/dim-wam/}}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiM-WAM, a memory-augmented world-action model for long-horizon robot manipulation. It extracts compact visual events, maintains multiple independent memory banks updated via similarity-based merging, reads bank-identity- and time-embedded context to condition video/action denoising, and adds a progress-supervision objective so that memory tokens encode both completed events and remaining task implications. On RMBench it reports raising average success from 28.4% (LingBot-VA) to 69.8% (exceeding Mem-0 at 42.0%); on four real-world Franka tasks it reports stage success rising from 70.7% to 91.5% and full-task success from 52.5% to 80.0%.
Significance. If the empirical gains are robust, the work would demonstrate a practical way to mitigate long-term forgetting and improve global task-state awareness in world-action models, which is a recognized bottleneck for temporally extended manipulation. The combination of multi-bank merging and progress supervision is a concrete, testable design choice whose value is directly measured on both simulated and physical benchmarks.
major comments (2)
- [Experiments] Experiments section (and any supplementary material): the reported success rates on RMBench and the four Franka tasks are the central claim, yet the manuscript provides no information on the number of evaluation episodes per task, variance across runs, statistical significance tests, or exact implementation details of the LingBot-VA and Mem-0 baselines. Without these, it is impossible to determine whether the 41.4-point and 27.5-point gains are reliable or could be explained by differences in training regime or evaluation protocol.
- [Method] Method section describing memory-bank merging: the claim that independent similarity-based merging across banks plus progress supervision reliably encodes both completed events and remaining task implications rests on an untested modeling assumption. The paper should include an ablation that isolates the contribution of the progress-supervision loss versus the multi-bank architecture alone, and should report whether performance degrades when the similarity threshold or bank count is varied.
minor comments (2)
- [Abstract] The abstract and introduction should explicitly state the number of trials and any statistical tests used for the RMBench and Franka results so that readers can immediately gauge the strength of the empirical evidence.
- [Method] Notation for the memory-bank update rule and the progress-supervision loss should be introduced with a single equation block rather than scattered prose descriptions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental reporting and the need for targeted ablations. We address each major comment below.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and any supplementary material): the reported success rates on RMBench and the four Franka tasks are the central claim, yet the manuscript provides no information on the number of evaluation episodes per task, variance across runs, statistical significance tests, or exact implementation details of the LingBot-VA and Mem-0 baselines. Without these, it is impossible to determine whether the 41.4-point and 27.5-point gains are reliable or could be explained by differences in training regime or evaluation protocol.
Authors: We agree that the manuscript currently lacks these details, which are necessary for evaluating result reliability. In the revised version we will expand the Experiments section (and supplementary material if needed) to report the number of evaluation episodes per task, variance or standard deviation across runs, results of statistical significance tests, and precise implementation details for LingBot-VA and Mem-0 including any differences in training or evaluation protocols. revision: yes
-
Referee: [Method] Method section describing memory-bank merging: the claim that independent similarity-based merging across banks plus progress supervision reliably encodes both completed events and remaining task implications rests on an untested modeling assumption. The paper should include an ablation that isolates the contribution of the progress-supervision loss versus the multi-bank architecture alone, and should report whether performance degrades when the similarity threshold or bank count is varied.
Authors: We acknowledge that an explicit ablation isolating the progress-supervision objective from the multi-bank design would strengthen the claims. We will add this ablation to the revised manuscript, along with results showing performance under varied similarity thresholds and different numbers of memory banks. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical description of a memory-augmented neural architecture for robotics, with no equations, derivations, or first-principles claims present. It defines DiM-WAM via concrete components (independent similarity-based merging of memory banks, progress-supervision objective) and reports direct benchmark results on RMBench and Franka tasks against named baselines. No step reduces a prediction or result to its own fitted inputs or self-citations by construction; the work is self-contained empirical evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-scale historical context (recent local, cross-stage events, immediate future, global progress) is necessary and sufficient to overcome long-term forgetting in world-action models.
invented entities (1)
-
Multiple independent memory banks with similarity-based merging
no independent evidence
Reference graph
Works this paper leans on
-
[1]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
“Rt-2: Vision-language-action models transfer web knowledge to robotic control,” 2023. [Online]. Available: https://arxiv.org/abs/2307.15818
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
OpenVLA: An Open-Source Vision-Language-Action Model
“Openvla: An open-source vision-language-action model,” 2024. [Online]. Available: https://arxiv.org/abs/2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
pi0: A vision-language-action flow model for general robot control,
“pi0: A vision-language-action flow model for general robot control,”
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
[Online]. Available: https://arxiv.org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Rdt-1b: A diffusion foundation model for bimanual manipulation,
“Rdt-1b: A diffusion foundation model for bimanual manipulation,”
-
[6]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
[Online]. Available: https://arxiv.org/abs/2410.07864
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Gr00t n1: An open foundation model for generalist humanoid robots,
“Gr00t n1: An open foundation model for generalist humanoid robots,”
-
[8]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
[Online]. Available: https://arxiv.org/abs/2503.14734
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Gigaworld-policy: An efficient action-centered world-action model,
“Gigaworld-policy: An efficient action-centered world-action model,”
-
[10]
Available: https://arxiv.org/abs/2603.17240
[Online]. Available: https://arxiv.org/abs/2603.17240
-
[11]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
“Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation,” 2024. [Online]. Available: https: //arxiv.org/abs/2410.06158
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Causal World Modeling for Robot Control
“Causal world modeling for robot control (lingbot-va),” 2026. [Online]. Available: https://arxiv.org/abs/2601.21998
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
World Action Models are Zero-shot Policies
“World action models are zero-shot policies (dreamzero),” 2026. [Online]. Available: https://arxiv.org/abs/2602.15922
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation,
“Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation,” 2025. [Online]. Available: https://arxiv.org/abs/2501.18564
-
[15]
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
“Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation,” 2025. [Online]. Available: https: //arxiv.org/abs/2508.19236
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Mem: Multi-scale embodied memory for vision language action models,
“Mem: Multi-scale embodied memory for vision language action models,” 2026. [Online]. Available: https://arxiv.org/abs/2603.03596
-
[17]
Remem-vla: Empowering vision-language-action model with memory via dual-level recurrent queries,
“Remem-vla: Empowering vision-language-action model with memory via dual-level recurrent queries,” 2026. [Online]. Available: https: //arxiv.org/abs/2603.12942
-
[18]
RMBench: Memory- dependent robotic manipulation benchmark with insights into policy design,
T. Chen, Y . Wang, M. Li, Y . Qin, H. Shi, Z. Li, Y . Hu, Y . Zhang, K. Wang, Y . Chenet al., “RMBench: Memory- dependent robotic manipulation benchmark with insights into policy design,”arXiv preprint arXiv:2603.01229, 2026. [Online]. Available: https://arxiv.org/abs/2603.01229
-
[19]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
“Spatialvla: Exploring spatial representations for visual-language-action model,” 2025. [Online]. Available: https://arxiv.org/abs/2501.15830
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
“Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models,” 2025. [Online]. Available: https://arxiv.org/abs/2506.07961
-
[21]
EventVLA: Event-Driven Visual Evidence Memory for Long-Horizon Vision-Language-Action Policies
“Eventvla: Event-driven visual evidence memory for long-horizon vision-language-action policies,” 2026. [Online]. Available: https: //arxiv.org/abs/2606.20092
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
MemoryVLA++: Temporal Modeling via Memory and Imagination in Vision-Language-Action Models
“Memoryvla++: Temporal modeling via memory and imagination in vision-language-action models,” 2026. [Online]. Available: https: //arxiv.org/abs/2606.09827
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Learning universal policies via text-guided video generation,
“Learning universal policies via text-guided video generation,” 2023. [Online]. Available: https://arxiv.org/abs/2302.00111
-
[24]
Robodreamer: Learning compositional world models for robot imagination,
“Robodreamer: Learning compositional world models for robot imagination,” 2024. [Online]. Available: https://arxiv.org/abs/2404. 12377
2024
-
[25]
Gen2Act: Human Video Generation in Novel Scenarios enables Generalizable Robot Manipulation
“Gen2act: Human video generation in novel scenarios enables generalizable robot manipulation,” 2024. [Online]. Available: https: //arxiv.org/abs/2409.16283
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
“Video prediction policy: A generalist robot policy with predictive visual representations,” 2024. [Online]. Available: https://arxiv.org/abs/ 2412.14803
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Predictive inverse dynamics models are scalable learners for robotic manipulation,
“Predictive inverse dynamics models are scalable learners for robotic manipulation,” 2024. [Online]. Available: https://arxiv.org/abs/2412. 15109
2024
-
[28]
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
“Cosmos policy: Fine-tuning video models for visuomotor control and planning,” 2026. [Online]. Available: https://arxiv.org/abs/2601.16163
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Dit4dit: Jointly modeling video dynamics and actions for generalizable robot control,
“Dit4dit: Jointly modeling video dynamics and actions for generalizable robot control,” 2026. [Online]. Available: https://arxiv.org/abs/2603. 10448
2026
-
[30]
World guidance: World modeling in condition space for action generation,
“World guidance: World modeling in condition space for action generation,” 2026. [Online]. Available: https://arxiv.org/abs/2602.22010
-
[31]
Fast-wam: Do world action models need test-time future imagination?
“Fast-wam: Do world action models need test-time future imagination?”
-
[32]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
[Online]. Available: https://arxiv.org/abs/2603.16666
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Streamingt2v: Consistent, dynamic, and extendable long video generation from text,
“Streamingt2v: Consistent, dynamic, and extendable long video generation from text,” 2024. [Online]. Available: https://arxiv.org/abs/ 2403.14773
-
[34]
Ssm meets video diffusion models: Efficient long-term video generation with selective state spaces,
“Ssm meets video diffusion models: Efficient long-term video generation with selective state spaces,” 2024. [Online]. Available: https://arxiv.org/abs/2403.07711
work page internal anchor Pith review arXiv 2024
-
[35]
Long context state space video world models,
“Long context state space video world models,” 2025. [Online]. Available: https://arxiv.org/abs/2505.20171
-
[36]
Sana-video: Efficient video generation with block linear diffusion transformer, 2025
“Sana-video: Efficient video generation with block linear diffusion transformer,” 2025. [Online]. Available: https://arxiv.org/abs/2509.24695
-
[37]
Malt diffusion: Memory-augmented latent transformers for any-length video generation,
“Malt diffusion: Memory-augmented latent transformers for any-length video generation,” 2025. [Online]. Available: https://arxiv.org/abs/2502. 12632
2025
-
[38]
Memorize-and-generate: Towards long-term consistency in real-time video generation,
“Memorize-and-generate: Towards long-term consistency in real-time video generation,” 2025. [Online]. Available: https://arxiv.org/abs/2512. 18741
2025
-
[39]
Videossm: Autoregressive long video generation with hybrid state- space memory,
“Videossm: Autoregressive long video generation with hybrid state- space memory,” 2025. [Online]. Available: https://arxiv.org/abs/2512. 04519
2025
-
[40]
Context forcing: Consistent autoregressive video generation with long context,
“Context forcing: Consistent autoregressive video generation with long context,” 2026. [Online]. Available: https://arxiv.org/abs/2602.06028
-
[41]
Relax forcing: Relaxed kv-memory for consistent long video generation,
“Relax forcing: Relaxed kv-memory for consistent long video generation,” 2026. [Online]. Available: https://arxiv.org/abs/2603.21366
-
[42]
Memflow: Flowing adaptive memory for consistent and efficient long video narratives,
“Memflow: Flowing adaptive memory for consistent and efficient long video narratives,” 2025. [Online]. Available: https://arxiv.org/abs/2512. 14699
2025
-
[43]
Videomemory: Toward consistent video generation via memory integration,
“Videomemory: Toward consistent video generation via memory integration,” 2026. [Online]. Available: https://arxiv.org/abs/2601.03655
-
[44]
SlotMemory: Object-Centric KV Memory for Streaming Long-Video Generation
“Slotmemory: Object-centric kv memory for streaming long-video generation,” 2026. [Online]. Available: https://arxiv.org/abs/2605.31033
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Diffusion policy: Visuomotor policy learning via action diffusion,
“Diffusion policy: Visuomotor policy learning via action diffusion,”
-
[46]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
[Online]. Available: https://arxiv.org/abs/2303.04137
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Learning fine-grained bimanual manipulation with low-cost hardware,
“Learning fine-grained bimanual manipulation with low-cost hardware,”
-
[48]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
[Online]. Available: https://arxiv.org/abs/2304.13705
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
“X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model,” 2025. [Online]. Available: https: //arxiv.org/abs/2510.10274
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.