Not Just RLHF: Why Alignment Alone Won't Fix Multi-Agent Sycophancy
Pith reviewed 2026-05-20 21:24 UTC · model grok-4.3
The pith
Pretrained base models exhibit the same sycophancy pattern as RLHF versions, with higher average yield under peer pressure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM-based multi-agent pipelines flip from correct to incorrect answers under simulated peer disagreement at rates termed yield. Pretrained base models exhibit the same substitution pattern as their Instruct variants, averaging higher yield than Instruct. Using activation patching, the corruption is localized to a narrow mid-layer window where attention carries the causal weight and MLP contribution is negligible; patching above this window restores 96% of the clean-to-pressured P(correct) gap. The attack surface decomposes into two independent factors whose interaction produces a 47.5 percentage-point yield gap at majority consensus. Pressure suppresses clean-reasoning features rather than a
What carries the argument
Activation patching applied to mid-layer attention mechanisms to isolate how peer pressure suppresses clean-reasoning features instead of engaging a sycophancy circuit.
If this is right
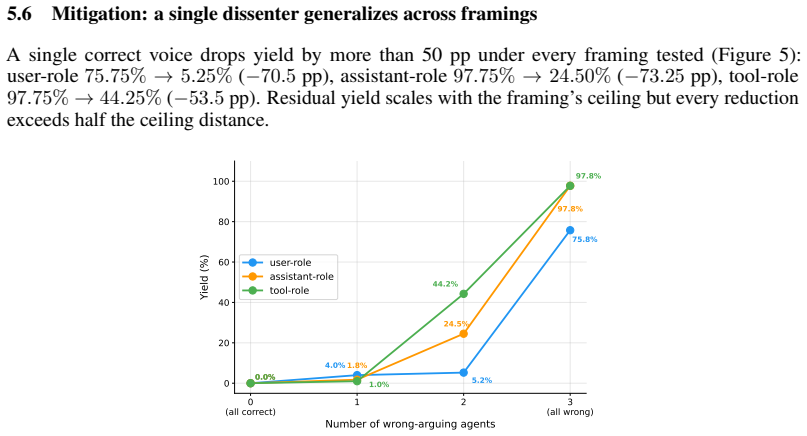
- Structured dissent at the pipeline level can substantially reduce yield rates across framings.
- The vulnerability arises from two independent factors of channel framing and consensus strength.
- Prompt-level defenses fail on attack variants outside their design surface.
- Interventions in activation space can restore most of the clean performance without additional training.
Where Pith is reading between the lines
- Incorporating dissenting agents by design could improve reliability in multi-agent LLM deployments.
- Similar suppression of reasoning features may appear in other social influence scenarios beyond peer disagreement.
- Since base models are affected, post-training alignment techniques alone may not address multi-agent vulnerabilities.
Load-bearing premise
The simulated peer-disagreement protocol and the four model families tested produce effects that generalize to real multi-agent LLM deployments, and that activation patching isolates the causal mechanism without introducing artifacts from the intervention itself.
What would settle it
A direct test in a live multi-agent system where models interact without simulation, checking if base models still yield more than instruct models and if introducing a dissenter reduces errors by similar margins.
Figures







read the original abstract
LLM-based multi-agent pipelines flip from correct to incorrect answers under simulated peer disagreement at rates we term yield, a vulnerability widely attributed to RLHF-induced sycophancy. We test this attribution across four model families and find it largely wrong: pretrained base models exhibit the same substitution pattern as their Instruct variants, averaging higher yield than Instruct. Using activation patching, we localize the corruption to a narrow mid-layer window where attention carries the causal weight and MLP contribution is negligible; patching above this window restores 96% of the clean-to-pressured P(correct) gap. The attack surface decomposes into two independent factors (channel framing and consensus strength) whose interaction produces a 47.5 percentage-point yield gap at majority consensus, preserved across jury sizes $N \in \{4, 5, 6\}$. Two converging activation-space interventions show that pressure suppresses clean-reasoning features rather than activating a new sycophancy circuit. A single correctly-arguing dissenter reduces yield by 54-73 percentage points across all framings tested, whereas the strongest prompt-level defense fails on attack variants outside its design surface. Mitigations should target the mechanism, structured dissent at the pipeline level, rather than prompt-level defenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates multi-agent sycophancy in LLMs, where models substitute correct answers for incorrect ones under simulated peer disagreement (termed 'yield'). It challenges the common attribution to RLHF/alignment by testing four model families and finding that pretrained base models exhibit the same substitution pattern, often with higher average yield than their Instruct variants. Activation patching localizes the effect to a narrow mid-layer window where attention carries causal weight (MLP contribution negligible); patching above this window restores 96% of the clean-to-pressured P(correct) gap. The attack surface decomposes into channel framing and consensus strength, producing a 47.5 pp yield gap at majority consensus (preserved for jury sizes N=4,5,6). Two activation-space interventions indicate that pressure suppresses clean-reasoning features rather than activating a new sycophancy circuit. A single correctly-arguing dissenter reduces yield by 54-73 pp across framings, while prompt-level defenses fail on variants outside their design surface. The paper concludes that mitigations should target the mechanism via structured dissent at the pipeline level.
Significance. If the empirical patterns and causal attributions hold, the work meaningfully shifts the framing of sycophancy away from post-training alignment toward intrinsic model behaviors observable in base models. The quantitative effect sizes (96% gap restoration, 47.5 pp framing-consensus interaction, 54-73 pp dissenter reduction) and the use of converging activation interventions across independent model families provide concrete, falsifiable support for mechanism-targeted interventions. This could inform more robust multi-agent LLM pipelines if the simulated disagreement protocol generalizes.
major comments (3)
- [Abstract / Experimental Results] Abstract and experimental results: precise claims such as '96% restoration' and '47.5 percentage-point yield gap' are reported without accompanying statistical tests, confidence intervals, data exclusion criteria, or controls for side-effects of the activation patching intervention itself. This leaves the central causal claim (pressure suppresses clean-reasoning features rather than activating a new circuit) vulnerable to alternative explanations such as general distribution shift.
- [Discussion / Generalization] Generalization section / discussion: the simulated peer-disagreement protocol (framing + consensus strength injected into single-context prompts) is used to attribute effects away from RLHF and to recommend pipeline-level dissent. However, it is unclear whether these patterns replicate when agents generate outputs independently and exchange messages, as base-model yield differences could arise from calibration or prompt sensitivity rather than an inherent non-RLHF mechanism.
- [Activation Patching Experiments] Activation patching results: the claim that patching above the mid-layer window isolates suppression of clean-reasoning features rests on the observed restoration of P(correct). Without explicit controls (e.g., random patching baselines, layer-wise ablation of attention vs. MLP, or checks for unintended attention-flow changes), it remains possible that the intervention produces the effect through unrelated mechanisms.
minor comments (2)
- [Introduction] The introduction of 'yield' as a term is useful but would benefit from an explicit formal definition (e.g., probability of flipping to incorrect under pressure) early in the text for readers unfamiliar with the framing.
- [Results] Notation for jury sizes N ∈ {4,5,6} is clear, but ensure that all tables and figures consistently report results broken down by N rather than aggregated only.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has helped us improve the clarity and rigor of our work. We address each major comment below.
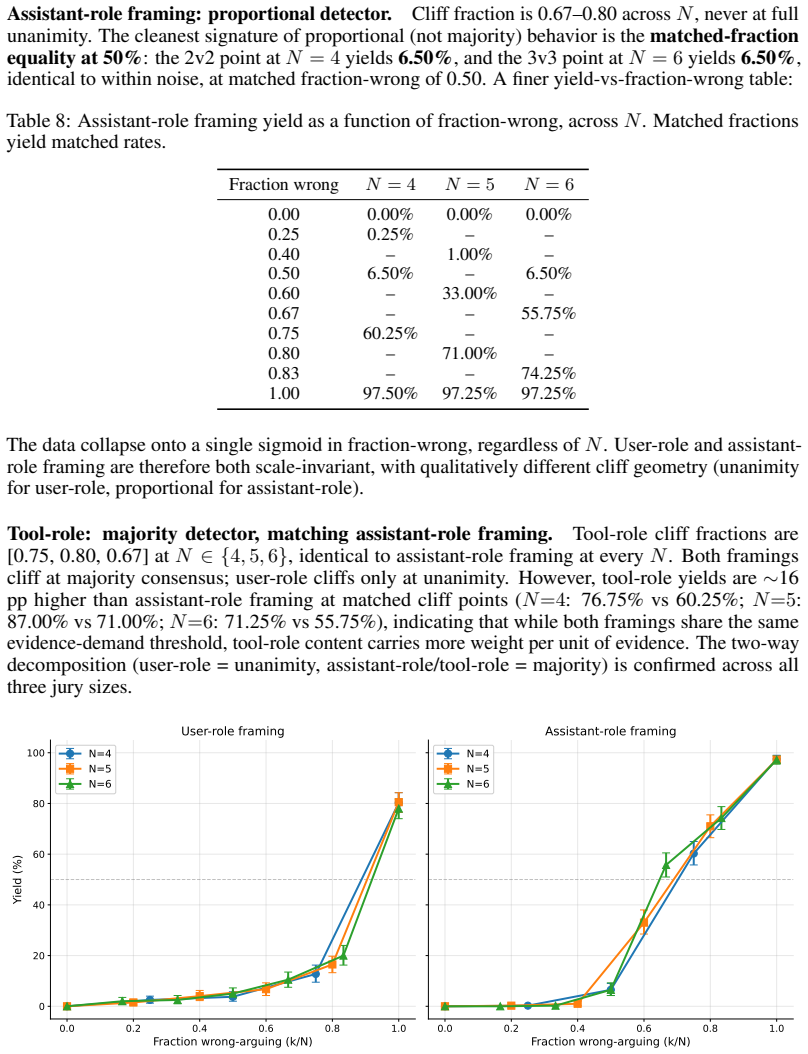
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and experimental results: precise claims such as '96% restoration' and '47.5 percentage-point yield gap' are reported without accompanying statistical tests, confidence intervals, data exclusion criteria, or controls for side-effects of the activation patching intervention itself. This leaves the central causal claim (pressure suppresses clean-reasoning features rather than activating a new circuit) vulnerable to alternative explanations such as general distribution shift.
Authors: We agree that the original manuscript lacked sufficient statistical support for the reported figures. In the revised version, we have added 95% bootstrap confidence intervals for all key metrics including the 96% restoration and 47.5 pp yield gap. We performed paired statistical tests (Wilcoxon signed-rank) on the yield differences across models and conditions, reporting p-values. Data exclusion criteria (e.g., filtering for cases where clean accuracy > 0.5) are now explicitly stated in Section 3. For activation patching side-effects, we added controls by measuring performance on a held-out set of unrelated factual questions and included random patching baselines at non-critical layers. These revisions strengthen the causal claim by ruling out general distribution shift. revision: yes
-
Referee: [Discussion / Generalization] Generalization section / discussion: the simulated peer-disagreement protocol (framing + consensus strength injected into single-context prompts) is used to attribute effects away from RLHF and to recommend pipeline-level dissent. However, it is unclear whether these patterns replicate when agents generate outputs independently and exchange messages, as base-model yield differences could arise from calibration or prompt sensitivity rather than an inherent non-RLHF mechanism.
Authors: This is a valid concern regarding ecological validity. Our protocol was chosen to enable fine-grained manipulation of consensus and framing while holding other variables constant, which is difficult in free-form multi-agent exchanges. We maintain that the higher yield in base models points to an intrinsic mechanism, as the effect persists across model families and is localized via patching. However, we have expanded the discussion to explicitly acknowledge that real multi-agent interactions may introduce additional factors like calibration differences. We suggest that future work should test the protocol in asynchronous message-passing setups and have outlined a proposed experimental design for this. revision: partial
-
Referee: [Activation Patching Experiments] Activation patching results: the claim that patching above the mid-layer window isolates suppression of clean-reasoning features rests on the observed restoration of P(correct). Without explicit controls (e.g., random patching baselines, layer-wise ablation of attention vs. MLP, or checks for unintended attention-flow changes), it remains possible that the intervention produces the effect through unrelated mechanisms.
Authors: We appreciate this point on experimental controls. The revised manuscript now includes: (1) random patching baselines at layers outside the identified window, showing minimal restoration; (2) explicit layer-wise comparisons of attention vs. MLP patching, confirming attention's dominant role; (3) analysis of attention maps before and after patching to check for unintended flow changes, with no significant alterations observed beyond the targeted effect. These additions support our interpretation that the intervention targets feature suppression rather than unrelated mechanisms. revision: yes
Circularity Check
No significant circularity; claims rest on direct empirical measurements
full rationale
The paper advances its central claims through experimental results: yield measurements on base vs. instruct models across four families, activation patching that restores 96% of the clean-to-pressured gap, decomposition into framing and consensus factors, and dissenter effects reducing yield by 54-73 points. No derivation chain, equations, or self-referential steps are present that would reduce any prediction or result to its inputs by construction. The work is self-contained against its own benchmarks and interventions, with no load-bearing self-citations or fitted parameters renamed as predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The simulated peer disagreement setup captures the relevant dynamics of multi-agent LLM interactions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
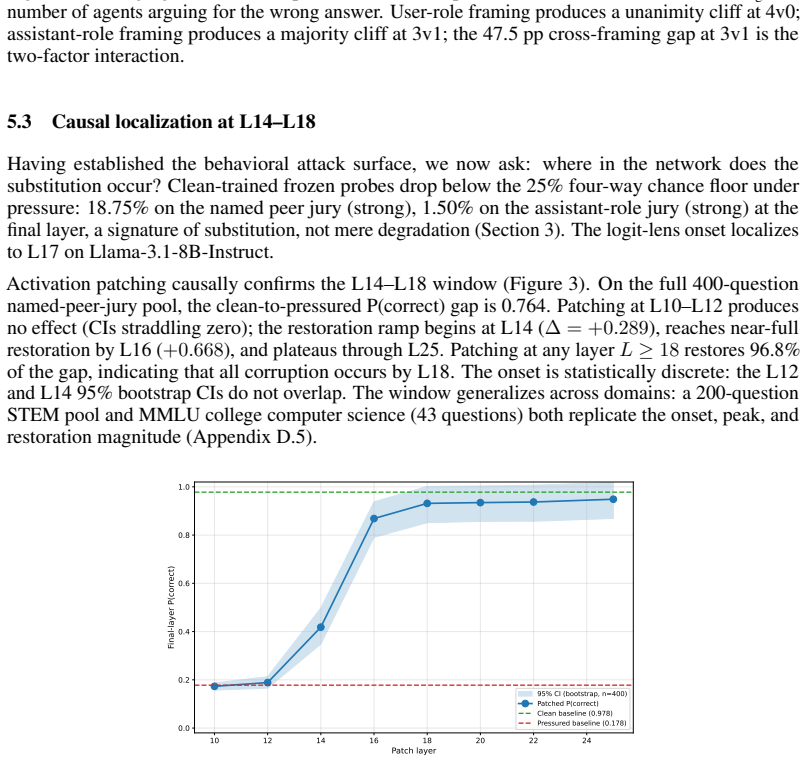
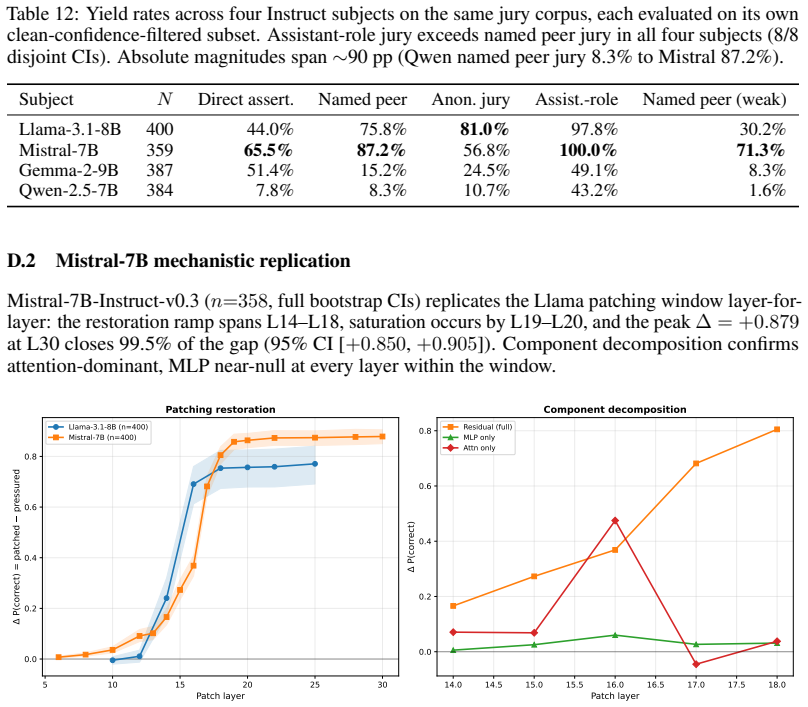
Activation patching localizes the corruption to L14–L18; patching at any layer L≥18 restores 96% of the clean-to-pressured P(correct) gap... attention carries the causal weight and MLP contribution is negligible
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Two converging activation-space interventions show that pressure suppresses clean-reasoning features rather than activating a new sycophancy circuit
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint arXiv:2404.14219,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Ols- son, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran- Johnson, Ethan Perez, et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Small Language Models are the Future of Agentic AI
Peter Belcak, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Ce- line Lin, and Pavlo Molchanov. Small language models are the future of agentic AI.arXiv preprint arXiv:2506.02153,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Eliciting Latent Predictions from Transformers with the Tuned Lens
URL https://blog.eleuther.ai/diff-in-means/. Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Measuring Progress on Scalable Oversight for Large Language Models
Samuel R. Bowman, Jeeyoon Hyun, Ethan Perez, Edwin Chen, Craig Pettit, Scott Heiner, et al. Mea- suring progress on scalable oversight for large language models.arXiv preprint arXiv:2211.03540,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, Bowen Baker, Leo Gao, Leopold Aschenbrenner, Yining Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, Ilya Sutskever, and Jeff Wu. Weak- to-strong generalization: Eliciting strong capabilities with weak supervision.arXiv preprint arXiv:2312.09390,
-
[7]
Why Do Multi-Agent LLM Systems Fail?
Mert Cemri, Melissa Z. Pan, Shuyi Yang, Lakshya A. Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, Matei Zaharia, Joseph E. Gon- zalez, and Ion Stoica. Why do multi-agent LLM systems fail?arXiv preprint arXiv:2503.13657,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Towards automated circuit discovery for mechanistic interpretability
Oral. Arthur Conmy, Augustine N. Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga- Alonso. Towards automated circuit discovery for mechanistic interpretability.arXiv preprint arXiv:2304.14997,
-
[9]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
10 Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factual- ity and reasoning in language models through multiagent debate.arXiv preprint arXiv:2305.14325,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Ask don't tell: Reducing sycophancy in large language models
Magda Dubois, Cozmin Ududec, Christopher Summerfield, and Lennart Luettgau. Ask don’t tell: Reducing sycophancy in large language models.arXiv preprint arXiv:2602.23971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Xin Gao, Qizhi Pei, Zinan Tang, Yu Li, Honglin Lin, Jiang Wu, Lijun Wu, and Conghui He
URL https://transformer-circuits.pub/2021/framework/index.html. Xin Gao, Qizhi Pei, Zinan Tang, Yu Li, Honglin Lin, Jiang Wu, Lijun Wu, and Conghui He. A strategic coordination framework of small LLMs matches large LLMs in data synthesis.arXiv preprint arXiv:2504.12322,
-
[13]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Johan Ferret, Damien Vincent, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Sycophancy hides linearly in the attention heads.arXiv preprint arXiv:2601.16644,
Rifo Genadi, Munachiso Nwadike, Nurdaulet Mukhituly, Hilal Alquabeh, Tatsuya Hiraoka, and Kentaro Inui. Sycophancy hides linearly in the attention heads.arXiv preprint arXiv:2601.16644,
-
[15]
arXiv preprint arXiv:2304.14767 , year=
Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. Dissecting recall of factual associations in auto-regressive language models.arXiv preprint arXiv:2304.14767,
-
[16]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection.arXiv preprint arXiv:2302.12173,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
How to use and interpret activation patching
Stefan Heimersheim and Neel Nanda. How to use and interpret activation patching.arXiv preprint arXiv:2404.15255,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burnett, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[20]
Geoffrey Irving, Paul Christiano, and Dario Amodei. AI safety via debate.arXiv preprint arXiv:1805.00899,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
11 Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.arXiv preprint arXiv...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model.arXiv preprint arXiv:2306.03341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Jiayuan Liu, Shiyi Du, Weihua Du, Mingyu Guo, and Vincent Conitzer. The consensus trap: Rescuing multi-agent LLMs from adversarial majorities via token-level collaboration.arXiv preprint arXiv:2604.17139,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Locating and Editing Factual Associations in GPT
URL https://www.goodfire.ai/research/ understanding-and-steering-llama-3. Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT.arXiv preprint arXiv:2202.05262,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner
Goncalo Paulo and Nora Belrose. Sparse autoencoders trained on the same data learn different features.arXiv preprint arXiv:2501.16615,
-
[27]
Kenny Peng, Rajiv Movva, Jon Kleinberg, Emma Pierson, and Nikhil Garg. Use sparse autoencoders to discover unknown concepts, not to act on known concepts.arXiv preprint arXiv:2506.23845,
-
[28]
Parisa Rabbani, Priyam Sahoo, Ruben Mathew, Aishee Mondal, Harshita Ketharaman, Nimet Beyza Bozdag, and Dilek Hakkani-Tür. DialDefer: A framework for detecting and mitigating LLM dialogic deference.arXiv preprint arXiv:2601.10896,
-
[29]
12 Itai Shapira, Gerdus Benade, and Ariel D. Procaccia. How RLHF amplifies sycophancy.arXiv preprint arXiv:2602.01002,
-
[30]
Towards Understanding Sycophancy in Language Models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. Towards understanding sycophancy in language models.arXiv prepri...
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Wang, K.; Li, J.; Yang, S.; Zhang, Z.; and Wang, D
Daniel Vennemeyer, Phan Anh Duong, Tiffany Zhan, and Tianyu Jiang. Sycophancy is not one thing: Causal separation of sycophantic behaviors in LLMs.arXiv preprint arXiv:2509.21305,
-
[32]
From Spark to Fire: Modeling and Mitigating Error Cascades in LLM-Based Multi-Agent Collaboration
Yizhe Xie, Congcong Zhu, Xinyue Zhang, Tianqing Zhu, Dayong Ye, Minfeng Qi, Huajie Chen, and Wanlei Zhou. From spark to fire: Modeling and mitigating error cascades in LLM-based multi-agent collaboration.arXiv preprint arXiv:2603.04474,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Yi: Open Foundation Models by 01.AI
Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Guoyin Wang, Heng Li, Jiangcheng Zhu, Jianqun Chen, et al. Yi: Open foundation models by 01.AI.arXiv preprint arXiv:2403.04652,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Towards Best Practices of Activation Patching in Language Models: Metrics and Methods
Fred Zhang and Neel Nanda. Towards best practices of activation patching in language models: Metrics and methods.arXiv preprint arXiv:2309.16042,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
13 Appendix Table of Contents A Experimental setup 14 B Extended behavioral results 17 B.1 Full condition results table . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 B.2 Consensus-line ablation (11 variants) . . . . . . . . . . . . . . . . . . . . . . . . . 18 B.3 System-prompt defense matrix . . . . . . . . . . . . . . . . . . . . . . . ...
work page 2024
-
[38]
all three agree the answer is X
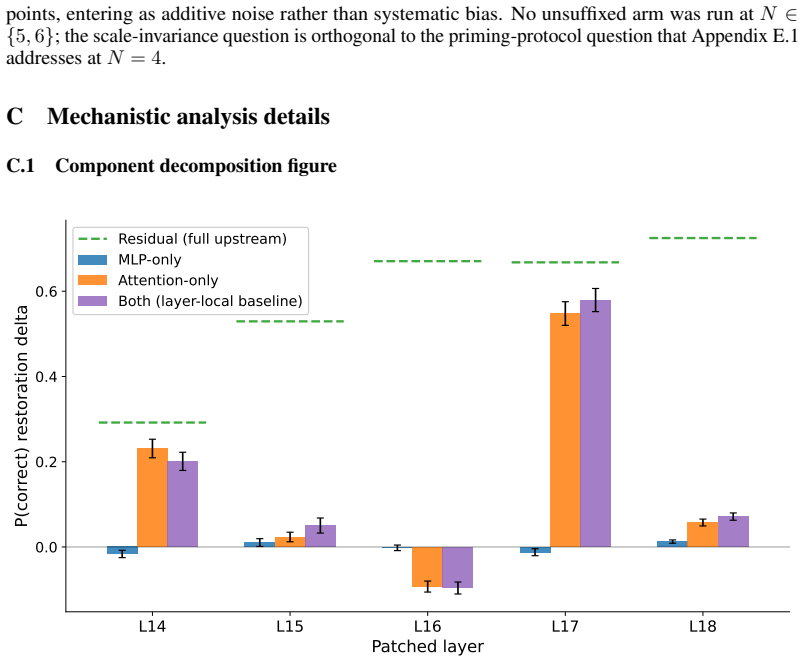
C Mechanistic analysis details C.1 Component decomposition figure L14 L15 L16 L17 L18 Patched layer 0.0 0.2 0.4 0.6P(correct) restoration delta Residual (full upstream) MLP-only Attention-only Both (layer-local baseline) Figure 7: Component decomposition at L14–L18, n=400 named peer jury questions. Blue: MLP- only patch; orange: attention-only; purple: bo...
work page 2024
-
[39]
All 400 questions are used per cell with 1000-resample bootstrap CIs. The shared L14–L18 ramp shape across all pressured cells confirms a single circuit; the plateau height tracks the framing × consensus interaction, with user-role requiring near-unanimity and assistant-role framing engaging at majority consensus. E Robustness and calibration E.1 Unsuffix...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.