IntentVLA: Short-Horizon Intent Modeling for Aliased Robot Manipulation
Pith reviewed 2026-06-30 20:53 UTC · model grok-4.3
The pith
Encoding recent visual observations into a short-horizon intent representation allows visual-language-action policies to generate consistent action chunks under observation aliasing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
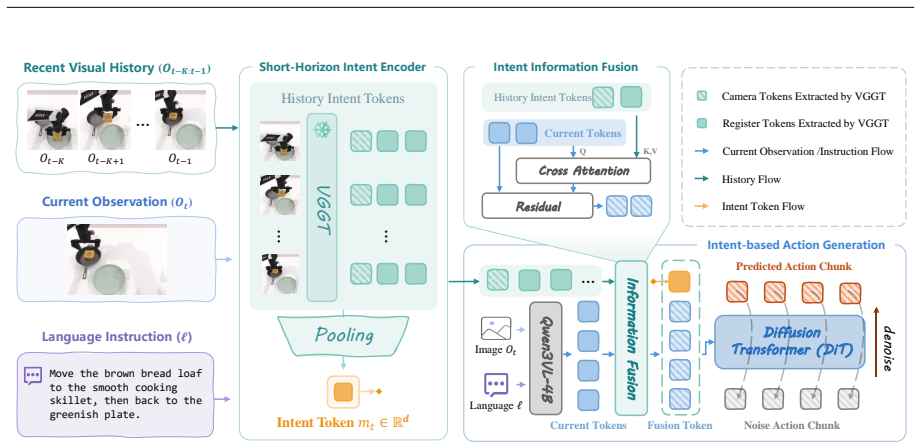
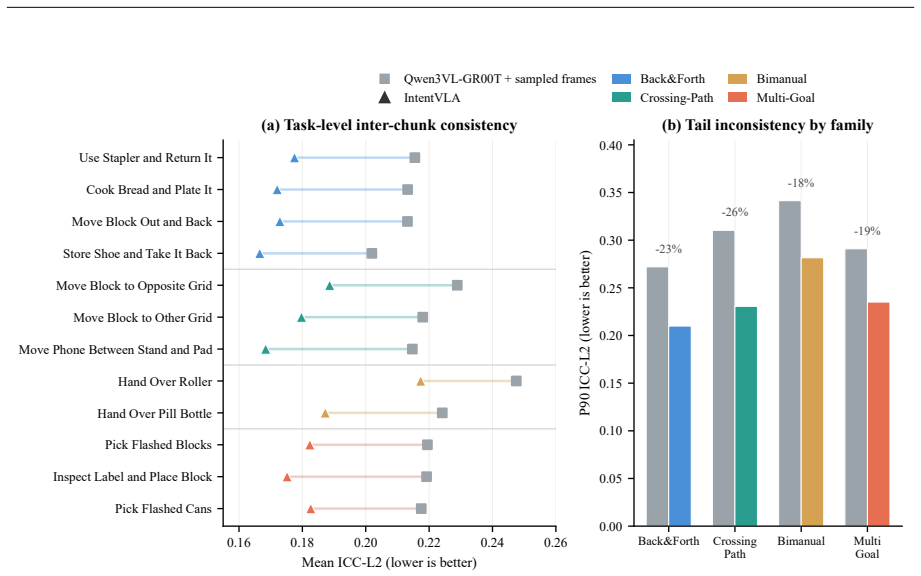
IntentVLA is a history-conditioned VLA framework that encodes recent visual observations into a compact short-horizon intent representation and conditions chunk generation on this representation, which improves rollout stability and outperforms baselines on AliasBench, SimplerEnv, LIBERO, and RoboCasa.
What carries the argument
The short-horizon intent representation, a compact encoding of recent visual observations that disambiguates the current task phase or intent for conditioning action generation.
If this is right
- Policies achieve more stable rollouts by avoiding inter-chunk intent conflicts.
- Performance gains hold across multiple simulation environments and benchmarks designed for aliasing.
- The framework can be applied to existing VLA architectures by adding the history encoder and conditioning.
- Training remains feasible without introducing new inconsistencies.
Where Pith is reading between the lines
- Similar history-based intent modeling could help in partially observable real-world settings where visual aliasing is common.
- The method might reduce the need for high-frequency replanning if intent consistency is maintained.
- Extending the intent representation to include language or proprioceptive history could further improve disambiguation.
Load-bearing premise
The multimodal nature of imitation data stems mainly from different short-horizon intents that recent observations can summarize compactly enough for conditioning to resolve conflicts.
What would settle it
A controlled experiment where the intent-conditioned model is compared to the baseline on tasks with known intent switches, measuring if the frequency of action chunk conflicts decreases significantly.
Figures

read the original abstract
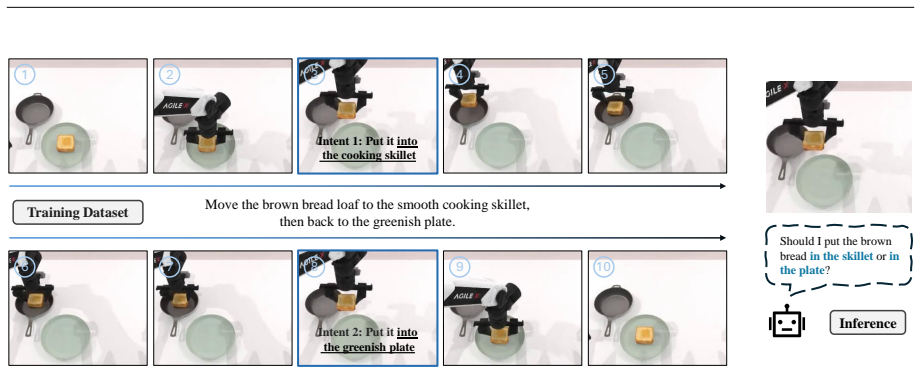
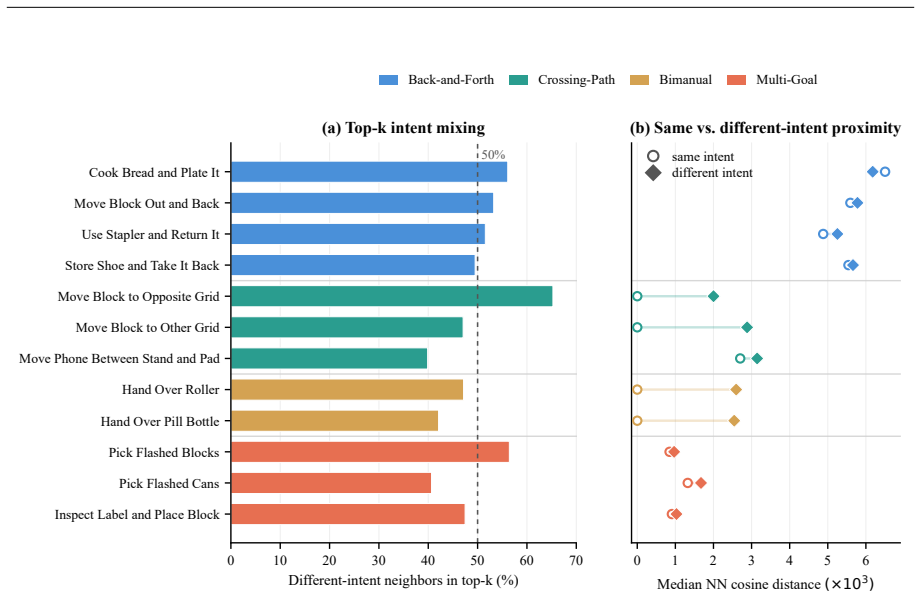
Robot imitation data are often multimodal: similar visual-language observations may be followed by different action chunks because human demonstrators act with different short-horizon intents, task phases, or recent context. Existing frame-conditioned VLA policies infer each chunk from the current observation and instruction alone, so under partial observability they may resample different intents across adjacent replanning steps, leading to inter-chunk conflict and unstable execution. We introduce IntentVLA, a history-conditioned VLA framework that encodes recent visual observations into a compact short-horizon intent representation and uses it to condition chunk generation. We further introduce AliasBench, a 12-task ambiguity-aware benchmark on RoboTwin2 with matched training data and evaluation environments that isolate short-horizon observation aliasing. Across AliasBench, SimplerEnv, LIBERO, and RoboCasa, IntentVLA improves rollout stability and outperforms strong VLA baselines
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IntentVLA, a history-conditioned VLA policy that encodes recent visual observations into a compact short-horizon intent representation used to condition action chunk generation. The goal is to reduce inter-chunk conflicts caused by multimodal aliasing in imitation data under partial observability. The authors also present AliasBench, a 12-task benchmark on RoboTwin2 designed to isolate short-horizon observation aliasing with matched training and evaluation data. Empirical results are reported showing improved rollout stability and outperformance versus strong VLA baselines across AliasBench, SimplerEnv, LIBERO, and RoboCasa.
Significance. If the reported gains hold under the full experimental protocol, the work supplies a practical mechanism for stabilizing chunk-based VLA execution without requiring full history or additional sensors. AliasBench provides a controlled testbed for aliasing phenomena that are otherwise difficult to isolate, which could support follow-on research. The approach is incremental on existing VLA architectures yet directly targets a load-bearing source of execution instability in real-robot deployment.
minor comments (2)
- [Abstract] The abstract states performance improvements but supplies no numerical values, metrics, or effect sizes; adding one or two headline numbers (e.g., success-rate deltas on AliasBench) would improve immediate readability.
- [Methods] The description of the intent encoder architecture and its training objective is referenced but not expanded in the provided excerpt; ensure the methods section supplies the precise input window length, embedding dimension, and loss formulation so that the compactness claim can be verified.
Simulated Author's Rebuttal
We thank the referee for the positive review, the recognition of IntentVLA's practical contribution to stabilizing chunk-based VLA policies under aliasing, and the recommendation for minor revision. We appreciate the note on AliasBench as a controlled testbed and will incorporate any minor suggestions in the revised manuscript.
Circularity Check
No significant circularity; empirical method without derivation chain
full rationale
The provided manuscript text consists of an empirical proposal for a history-conditioned VLA policy and an associated benchmark (AliasBench). No equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the abstract or described structure. The central claim is that conditioning on a short-horizon intent encoder improves stability; this is evaluated via rollout metrics on external suites rather than reducing to a self-definition or renamed input. The paper is self-contained against its benchmarks with no visible reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, and 1 others. 2025. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, and 5 others. 2024.π 0: A vision- language-action flow model for general robot cont...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xu Huang, Shu Jiang, and 1 others. 2025. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. 2025. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, and 1 others. 2025. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [7]
-
[8]
Yi Chen, Yuying Ge, Hui Zhou, Mingyu Ding, Yixiao Ge, and Xihui Liu. 2026. Dial: Decoupling intent and action via latent world modeling for end-to-end vla.arXiv preprint arXiv:2603.29844
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
StarVLA Community. 2026. Starvla: A lego-like codebase for vision-language-action model developing.arXiv preprint arXiv:2604.05014
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
GEAR-Team, Allison Azzolini, Johan Bjorck, Valts Blukis, Fernando Castañeda, Rahul Chand, and 1 others
-
[11]
nvidia.com/labs/gear/gr00t-n1_6/
Gr00t n1.6: An improved open foundation model for generalist humanoid robots.https://research. nvidia.com/labs/gear/gr00t-n1_6/
- [12]
-
[13]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, and 17 others. 2025.π0.5: a vision-language-action model with open-world...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, and 1 others. 2024. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Moo Jin Kim, Chelsea Finn, and Percy Liang. 2025. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. 2024. OpenVLA: An open-source vision-language- action model. InConference on Robot Learning (CoRL)
2024
-
[17]
Chengmeng Li, Junjie Wen, Yaxin Peng, Yan Peng, and Yichen Zhu. 2026. Pointvla: Injecting the 3d world into vision-language-action models.IEEE Robotics and Automation Letters, 11(3):2506–2513
2026
- [18]
-
[19]
Peiyan Li, Yixiang Chen, Hongtao Wu, Xiao Ma, Xiangnan Wu, Yan Huang, Liang Wang, Tao Kong, and Tie- niu Tan. 2025. Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models. InAdvances in neural information processing systems (NeurIPS)
2025
-
[20]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, and 1 others. 2024. CogACT: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Xinghang Li, Peiyan Li, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Tao Kong, Hanbo Zhang, and Huaping Liu. 2024. Towards generalist robot policies: What matters in building vision-language- action models.arXiv preprint arXiv:2412.14058
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Oier Mees, Karl Pertsch, Homer Rich Walke, Chuyuan Fu, Ishikaa Lu- nawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. 2024. SimplerEnv: Evaluating real-world robot manipulation policies in simulation. InConference on Robot Learning (CoRL)
2024
-
[23]
Shijie Lian, Bin Yu, Xiaopeng Lin, Laurence T Yang, Zhaolong Shen, Changti Wu, Yuzhuo Miao, Cong Huang, and Kai Chen. 2026. Langforce: Bayesian decomposition of vision language action models via latent action queries.arXiv e-prints, pages arXiv–2601
2026
- [24]
- [25]
-
[26]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. 2023. LIBERO: Benchmarking knowledge transfer for lifelong robot learning.Advances in neural information processing sys- tems (NeurIPS), 36:44776–44791
2023
-
[27]
Songming Liu, Bangguo Li, Kai Ma, Lingxuan Wu, Hengkai Tan, Xiao Ouyang, Hang Su, and Jun Zhu
- [28]
-
[29]
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. 2025. RDT-1b: a diffusion foundation model for bimanual manipulation. InInternational Conference on Learning Representations (ICLR)
2025
-
[30]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. InInternational Conference on Learning Representations (ICLR)
2017
- [31]
-
[32]
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Man- dlekar, and Yuke Zhu. 2024. RoboCasa: Large-scale simulation of everyday tasks for generalist robots. In Robotics: Science and Systems
2024
-
[33]
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, and 1 others. 2024. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE
2024
-
[34]
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. 2025. FAST: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, and 1 others. 2025. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. Deepspeed: System optimiza- tions enable training deep learning models with over 100 billion parameters. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 3505–3506. 14
2020
-
[37]
Yichao Shen, Fangyun Wei, Zhiying Du, Yaobo Liang, Yan Lu, Jiaolong Yang, Nanning Zheng, and Baining Guo. 2025. VideoVLA: Video generators can be generalizable robot manipulators. InAdvances in neural information processing systems (NeurIPS)
2025
-
[38]
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xiangyu Zhang, and Gao Huang. 2026. Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation. InInternational Conference on Learning Representations (ICLR)
2026
- [39]
-
[40]
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, and 1 others. 2024. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen-Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, and 1 others. 2023. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning (CoRL), pages 1723–1736. PMLR
2023
-
[42]
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny
-
[43]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
-
[44]
Jianwei Yang, Reuben Tan, Qianhui Wu, Ruijie Zheng, Baolin Peng, Yongyuan Liang, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, and 1 others. 2025. Magma: A foundation model for multimodal ai agents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14203– 14214
2025
-
[45]
Bin Yu, Shijie Lian, Xiaopeng Lin, Zhaolong Shen, Yuliang Wei, Haishan Liu, Changti Wu, Hang Yuan, Bailing Wang, Cong Huang, and 1 others. 2026. 3d-mix for vla: A plug-and-play module for integrating vggt- based 3d information into vision-language-action models.arXiv preprint arXiv:2603.24393
-
[46]
Bin Yu, Shijie Lian, Xiaopeng Lin, Yuliang Wei, Zhaolong Shen, Changti Wu, Yuzhuo Miao, Xinming Wang, Bailing Wang, Cong Huang, and 1 others. 2026. Twinbrainvla: Unleashing the potential of generalist vlms for embodied tasks via asymmetric mixture-of-transformers.arXiv preprint arXiv:2601.14133
- [48]
-
[49]
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan
-
[50]
InInternational conference on machine learning (ICML), pages 61229–61245
3D-VLA: A 3D vision-language-action generative world model. InInternational conference on machine learning (ICML), pages 61229–61245
-
[51]
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, and 1 others. 2025. X-VLA: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daumé III, Andrey Kolobov, Furong Huang, and Jianwei Yang. 2025. TraceVLA: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies.arXiv preprint arXiv:2412.10345
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [53]
-
[54]
Zheyuan Zhou, Liang Du, Zixun Sun, Xiaoyu Zhou, Ruimin Ye, Qihao Chen, Yinda Chen, and Lemiao Qiu
- [55]
-
[56]
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, and 1 others. 2023. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning (CoRL), pages 2165–2183. 15 A Additional Analysis on Intent Consistency and Mode Switching A.1 Mode Swi...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.