CaptchaMind: Training CAPTCHA Solvers via Reinforcement Learning with Explicit Reasoning Supervision
Pith reviewed 2026-05-20 06:10 UTC · model grok-4.3
The pith
Reinforcement learning with explicit reasoning supervision solves CAPTCHAs at 82.9 percent average success on a new benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
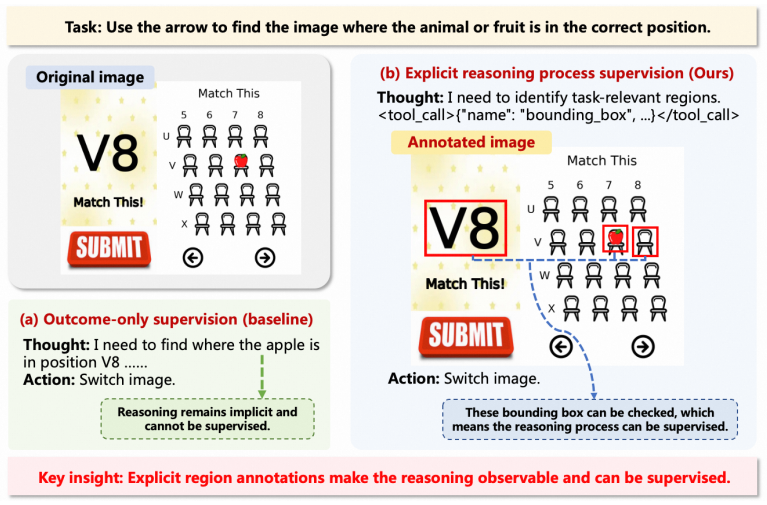
CaptchaMind is an RL-based solver trained with explicit reasoning process supervision on CaptchaBench, which contains 16,000 programmatically generated samples across eight task categories with region and process-level annotations, and it achieves an 82.9 percent average success rate across the eight tasks and 71.0 percent on real-world instances, substantially outperforming all existing methods that do not use closed-source APIs.
What carries the argument
CaptchaMind, the reinforcement learning solver trained with explicit reasoning process supervision that learns multi-step visual reasoning and interaction from process-level annotations.
Load-bearing premise
The programmatically generated samples and annotations in CaptchaBench sufficiently capture the distribution and difficulty of real-world CAPTCHAs so that benchmark performance predicts real-world success.
What would settle it
A significant drop in success rate when the same model is evaluated on a fresh collection of diverse human-created real-world CAPTCHAs drawn from many different websites and not seen during training or benchmark evaluation.
Figures










read the original abstract
CAPTCHAs are widely deployed as human verification mechanisms and frequently block intelligent agents from completing end-to-end automation in real-world web environments. Solving modern CAPTCHAs requires robust multi-step visual reasoning and interaction capabilities, yet training-based approaches have remained absent due to the lack of large-scale training data and process-level annotations. We introduce CaptchaBench, the first CAPTCHA benchmark designed to support large-scale training, comprising 16,000 programmatically generated samples across eight task categories with detailed region and process-level annotations. Systematic evaluation on CaptchaBench reveals that existing methods fail consistently on tasks requiring fine-grained visual detail capture and region-level comparison. We therefore present CaptchaMind, an RL-based solver trained with explicit reasoning process supervision, achieving 82.9% average success rate across eight tasks and 71.0% on real-world instances, substantially outperforming all existing methods without closed-source APIs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CaptchaBench, a benchmark of 16,000 programmatically generated CAPTCHA samples across eight task categories equipped with region- and process-level annotations to enable large-scale training. It proposes CaptchaMind, an RL-based solver that incorporates explicit reasoning-process supervision, and reports that this model attains an 82.9% average success rate on the benchmark and 71.0% on real-world instances while outperforming prior methods that do not rely on closed-source APIs.
Significance. If the reported performance gains prove robust and the synthetic benchmark is shown to be representative, the work would supply the first large-scale, annotation-rich training resource for multi-step visual reasoning in CAPTCHA solving and demonstrate that RL with process-level supervision can be effective in this domain. The provision of both benchmark and training methodology addresses a clear data gap noted in the abstract.
major comments (2)
- [Abstract] Abstract: headline success rates (82.9% on CaptchaBench, 71.0% real-world) are stated without any accompanying experimental protocol, baseline tables, error bars, or ablation results, so the claim of substantial outperformance cannot be evaluated from the provided information.
- [Benchmark section] Benchmark construction (presumably §3 or §4): the assertion that the 16k programmatically generated samples capture the visual statistics, noise patterns, and reasoning demands of production CAPTCHAs is load-bearing for both the benchmark scores and the real-world transfer result, yet no quantitative validation (distribution distances, human difficulty correlation, or adversarial robustness tests) is supplied.
minor comments (1)
- [Abstract] Abstract: the eight task categories are named only in aggregate; a brief enumeration would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential significance. We address each major comment below with honest responses and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: headline success rates (82.9% on CaptchaBench, 71.0% real-world) are stated without any accompanying experimental protocol, baseline tables, error bars, or ablation results, so the claim of substantial outperformance cannot be evaluated from the provided information.
Authors: We agree that the abstract's brevity limits inclusion of full experimental details. The complete manuscript details the protocol, baselines, ablations, and statistical results in Sections 5 and 6 (including Table 2 for comparisons and Table 3 for ablations). In revision, we will expand the abstract to reference the evaluation protocol and main result tables while preserving conciseness. revision: yes
-
Referee: [Benchmark section] Benchmark construction (presumably §3 or §4): the assertion that the 16k programmatically generated samples capture the visual statistics, noise patterns, and reasoning demands of production CAPTCHAs is load-bearing for both the benchmark scores and the real-world transfer result, yet no quantitative validation (distribution distances, human difficulty correlation, or adversarial robustness tests) is supplied.
Authors: This concern is valid and the lack of explicit quantitative validation is a limitation in the current version. The generation pipeline was constructed to replicate observed real-world CAPTCHA characteristics, with the 71% real-world transfer providing supporting evidence. We will add a dedicated subsection with quantitative analyses, including feature distribution comparisons and human difficulty correlations on sampled instances. revision: yes
Circularity Check
No circularity in empirical training and evaluation pipeline
full rationale
The paper introduces CaptchaBench as an external programmatically generated dataset with annotations and reports CaptchaMind performance as measured empirical success rates on that benchmark plus separate real-world instances. No equations, derivations, fitted parameters renamed as predictions, or self-referential definitions appear. The central results are experimental outcomes from RL training and testing rather than any reduction of claims to inputs by construction. The benchmark-to-real-world transfer assumption is a standard empirical validity concern, not a circularity issue.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CaptchaMind... RL-based solver trained with explicit reasoning process supervision... R = R_process + R_feedback + R_outcome
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CaptchaBench... 16,000 programmatically generated samples... automated data generation pipeline
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume =
Yaxin Luo and Zhaoyi Li and Jiacheng Liu and Jiacheng Cui and Xiaohan Zhao and Zhiqiang Shen , title =. Advances in Neural Information Processing Systems , volume =. 2025 , address =
work page 2025
-
[2]
Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security , series =
Gelei Deng and Haoran Ou and Yi Liu and Jie Zhang and Tianwei Zhang and Yang Liu , title =. Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security , series =. 2025 , doi =
work page 2025
-
[3]
Proceedings of the 34th USENIX Security Symposium (USENIX Security 25) , year =
Xiwen Teoh and Yun Lin and Siqi Li and Ruofan Liu and Avi Sollomoni and Yaniv Harel and Jin Song Dong , title =. Proceedings of the 34th USENIX Security Symposium (USENIX Security 25) , year =
-
[4]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng and Michael Yang and Jack Hong and Chenxiao Zhao and Guohai Xu and Le Yang and Chao Shen and Xing Yu , title =. Preprint, arXiv:2505.14362 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Meng Cao and Haoze Zhao and Can Zhang and Xiaojun Chang and Ian Reid and Xiaodan Liang , title =. arXiv preprint arXiv:2505.20272 , year =
-
[6]
arXiv preprint arXiv:2505.21457 , year =
Muzhi Zhu and Hao Zhong and Canyu Zhao and Zongze Du and Zheng Huang and Mingyu Liu and Hao Chen and Cheng Zou and Jingdong Chen and Ming Yang and Chunhua Shen , title =. arXiv preprint arXiv:2505.21457 , year =
-
[7]
Adaptive Chain-of-Focus Reasoning via Dynamic Visual Search and Zooming for Efficient VLMs
Xintong Zhang and Zhi Gao and Bofei Zhang and Pengxiang Li and Xiaowen Zhang and Yang Liu and Tao Yuan and Yuwei Wu and Yunde Jia and Song-Chun Zhu and Qing Li , title =. arXiv preprint arXiv:2505.15436 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
Xin Lai and Junyi Li and Wei Li and Tao Liu and Tianjian Li and Hengshuang Zhao , title =. arXiv preprint arXiv:2509.07969 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
Zhaochen Su and Linjie Li and Mingyang Song and Yunzhuo Hao and Zhengyuan Yang and Jun Zhang and Guanjie Chen and Jiawei Gu and Juntao Li and Xiaoye Qu and Yu Cheng , title =. arXiv preprint arXiv:2505.08617 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Yi-Fan Zhang and Xingyu Lu and Shukang Yin and Chaoyou Fu and Wei Chen and Xiao Hu and Bin Wen and Kaiyu Jiang and Changyi Liu and Tianke Zhang and Haonan Fan and Kaibing Chen and Jiankang Chen and Haojie Ding and Kaiyu Tang and Zhang Zhang and Liang Wang and Fan Yang and Tingting Gao and Guorui Zhou , title =. arXiv preprint arXiv:2508.11630 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
UI-R1: Enhancing Efficient Action Prediction of GUI Agents by Reinforcement Learning
Zhengxi Lu and Yuxiang Chai and Yaxuan Guo and Xi Yin and Liang Liu and Hao Wang and Han Xiao and Shuai Ren and Guanjing Xiong and Hongsheng Li , title =. arXiv preprint arXiv:2503.21620 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Run Luo and Lu Wang and Wanwei He and Longze Chen and Jiaming Li and Xiaobo Xia , title =. arXiv preprint arXiv:2504.10458 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
Yuhang Liu and Pengxiang Li and Congkai Xie and Xavier Hu and Xiaotian Han and Shengyu Zhang and Hongxia Yang and Fei Wu , title =. arXiv preprint arXiv:2504.14239 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction
Yiheng Xu and Zekun Wang and Junli Wang and Dunjie Lu and Tianchang Xie and Amrita Saha and Doyen Sahoo and Tao Yu and Caiming Xiong , title =. arXiv preprint arXiv:2412.04454 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
arXiv preprint arXiv:2501.04575 , year =
Yuhang Liu and Pengxiang Li and Zishu Wei and Congkai Xie and Xueyu Hu and Xinchen Xu and Shengyu Zhang and Xiaotian Han and Hongxia Yang and Fei Wu , title =. arXiv preprint arXiv:2501.04575 , year =
-
[16]
arXiv preprint arXiv:2505.23762 , year =
Chenyu Yang and Su Shiqian and Shi Liu and Xuan Dong and Yue Yu and Weijie Su and Xuehui Wang and Zhaoyang Liu and Jinguo Zhu and Hao Li and Wenhai Wang and Yu Qiao and Xizhou Zhu and Jifeng Dai , title =. arXiv preprint arXiv:2505.23762 , year =
-
[17]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin and Yining Ye and Junjie Fang and Haoming Wang and Shihao Liang and Shizuo Tian and Junda Zhang and Jiahao Li and Yunxin Li and Shijue Huang and Wanjun Zhong and Kuanye Li and Jiale Yang and Yu Miao and Woyu Lin and Longxiang Liu and Xu Jiang and Qianli Ma and Jingyu Li and Xiaojun Xiao and Kai Cai and Chuang Li and Yaowei Zheng and Chaolin Jin ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang and Haoyang Zou and Huatong Song and Jiazhan Feng and Junjie Fang and Junda Lu and Longxiang Liu and Qihao Luo and Shihao Liang and Shujue Huang and Wanjun Zhong and others , title =. arXiv preprint arXiv:2509.02544 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y.K. Li and Y. Wu and Daya Guo , title =. arXiv preprint arXiv:2402.03300 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Shuai Bai and Keqin Chen and Xuejing Liu and Jialin Wang and Wenbin Ge and Sibo Song and Kai Dang and Peng Wang and Shijie Wang and Jun Tang and Humen Zhong and Yuanzhi Zhu and Mingkun Yang and Zhaohai Li and Jianqiang Wan and Pengfei Wang and Wei Ding and Zheren Fu and Yiheng Xu and Jiabo Ye and Xi Zhang and Tianbao Xie and Zesen Cheng and Hang Zhang and...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo and Dejian Yang and Haowei Zhang and Junxiao Song and Ruoyu Zhang and Runxin Xu and Qihao Zhu and Shirong Ma and Peiyi Wang and Xiao Bi and others , title =. arXiv preprint arXiv:2501.12948 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Gemini 3: Our Most Intelligent AI Model , howpublished =
-
[23]
Aaron Hurst and Adam Lerer and Adam P. Goucher and others , title =. arXiv preprint arXiv:2410.21276 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
OpenAI , title =. arXiv preprint arXiv:2601.03267 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Zhiyong Wu and Zhenyu Wu and Fangzhi Xu and Yian Wang and Qiushi Sun and Chengyou Jia and Kanzhi Cheng and Zichen Ding and Liheng Chen and Paul Pu Liang and Yu Qiao , title =. arXiv preprint arXiv:2410.23218 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages =
Haipeng Wang and Feng Zheng and Zhuoming Chen and Yi Lu and Jing Gao and Renjia Wei , title =. 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages =. 2018 , organization =
work page 2018
-
[27]
Hopper and John Langford , title =
Luis Von Ahn and Manuel Blum and Nicholas J. Hopper and John Langford , title =. Advances in Cryptology—EUROCRYPT 2003 , pages =. 2003 , publisher =
work page 2003
-
[28]
30th USENIX Security Symposium (USENIX Security 21) , pages =
Yipeng Gao and Haichang Gao and Sainan Luo and Yang Zi and Shudong Zhang and Wenjie Mao and Ping Wang and Yulong Shen and Jeff Yan , title =. 30th USENIX Security Symposium (USENIX Security 21) , pages =. 2021 , address =
work page 2021
-
[29]
OpenAI , title =. arXiv preprint arXiv:2303.08774 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron and Thibaut Lavril and Gautier Izacard and Xavier Martinet and Marie-Anne Lachaux and Timothée Lacroix and Baptiste Rozière and Naman Goyal and Eric Hambro and Faisal Azhar and Aurelien Rodriguez and Armand Joulin and Edouard Grave and Guillaume Lample , title =. arXiv preprint arXiv:2302.13971 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
PaLM: Scaling Language Modeling with Pathways
Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and others , title =. arXiv preprint arXiv:2204.02311 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Training Compute-Optimal Large Language Models
Jordan Hoffmann and Sebastian Borgeaud and Arthur Mensch and Elena Buchatskaya and Trevor Cai and Eliza Rutherford and Diego de Las Casas and Lisa Anne Hendricks and Johannes Welbl and Aidan Clark and Tom Hennigan and Eric Noland and Katie Millican and George van den Driessche and Bogdan Damoc and Aurelia Guy and Simon Osindero and Karen Simonyan and Eric...
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai and Shuai Bai and Shusheng Yang and Shijie Wang and Sinan Tan and Peng Wang and Junyang Lin and Chang Zhou and Jingren Zhou , title =. arXiv preprint arXiv:2308.12966 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Haoran Yang and Yumeng Zhang and Jiaqi Xu and Hongyuan Lu and Pheng-Ann Heng and Wai Lam , title =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , year =
work page 2024
-
[35]
Advances in Neural Information Processing Systems , volume=
Mind2web: Towards a generalist agent for the web , author =. Advances in Neural Information Processing Systems , volume=
-
[36]
Hongliang He and Wenlin Yao and Kaixin Ma and Wenhao Yu and Yong Dai and Hongming Zhang and Zhenzhong Lan and Dong Yu , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =
work page 2024
-
[37]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Showui: One vision-language-action model for gui visual agent , author =. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=. 2025 , address =
work page 2025
-
[38]
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks , author =. arXiv preprint arXiv:2401.13649 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Advances in Neural Information Processing Systems , volume=
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments , author =. Advances in Neural Information Processing Systems , volume=
-
[40]
International Conference on Learning Representations (ICLR) , year=
React: Synergizing reasoning and acting in language models , author=. International Conference on Learning Representations (ICLR) , year=
-
[41]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author =. Advances in Neural Information Processing Systems , volume=
-
[42]
ViperGPT: Visual Inference via Python Execution for Reasoning , author=. ICCV , year=
-
[43]
Visual Programming: Compositional visual reasoning without training , author=. CVPR , year=
-
[44]
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
VisualPRM: An effective process reward model for multimodal reasoning,
Visualprm: An effective process reward model for multimodal reasoning , author =. arXiv preprint arXiv:2503.10291 , year=
-
[46]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[47]
Artificial Intelligence , volume=
Planning and acting in partially observable stochastic domains , author=. Artificial Intelligence , volume=
- [48]
-
[49]
Kanzhi Cheng and Qiushi Sun and Yougang Chu and Fangzhi Xu and Li YanTao and Jianbing Zhang and Zhiyong Wu , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.