Training Vision-Language-Action Models with Dense Embodied Chain-of-Thought Supervision
Pith reviewed 2026-06-30 05:07 UTC · model grok-4.3
The pith
A dual-stream VLA model aligns high-level reasoning across robot embodiments with dense chain-of-thought supervision during training only.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
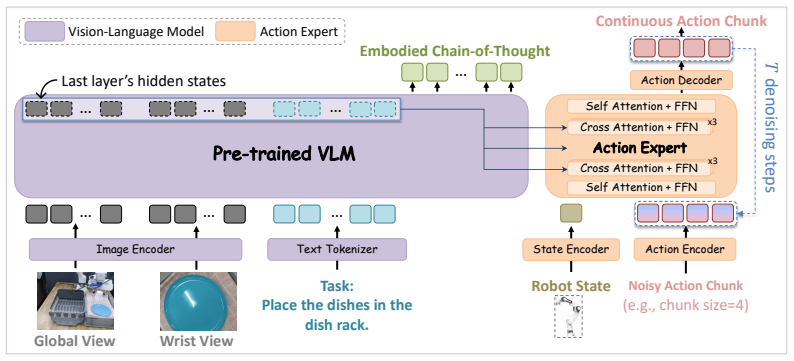
ZR-0 is an end-to-end VLA model that uses dense Embodied Chain-of-Thought supervision inside a dual-stream architecture to align cross-embodiment representations. A pre-trained VLM generates structured ECoT reasoning during training while a Diffusion Transformer-based action expert produces continuous action chunks via flow matching; the two are coupled by cross-attention with a mask that restricts the action expert to input prompt features only. This enables ECoT generation to be skipped entirely at inference without performance loss. The model is pre-trained on ProcCorpus-60M containing roughly 60 million frames from over 400K trajectories with dense annotations on 96.8 percent of frames a
What carries the argument
Dual-stream architecture with cross-attention and an attention mask that restricts the action expert to input prompt features only, allowing ECoT to be skipped at inference.
If this is right
- ECoT generation can be skipped at inference with no performance loss due to the attention mask.
- The model achieves strong performance on single-arm tasks in LIBERO, bimanual tasks in RoboTwin 2.0 and humanoid tasks in RoboCasa GR-1.
- Real-world experiments on the xArm platform confirm transfer beyond simulation.
- Pre-training on 60 million frames with dense ECoT annotations on 96.8 percent of the data supports the cross-embodiment alignment.
Where Pith is reading between the lines
- The separation of high-level alignment from low-level action generation could lower inference compute on new robot platforms.
- The same supervision pattern might transfer to other domains where cognitive structure is shared but motor spaces differ.
- Scaling the number of embodiments in the training set beyond the current four could test how far the shared-reasoning assumption holds.
Load-bearing premise
The high-level cognitive process underlying manipulation, including scene perception, object identification, task planning, and sub-task decomposition, is largely shared across embodiments.
What would settle it
Training an otherwise identical model without the dense ECoT supervision on the same ProcCorpus-60M data and measuring whether cross-embodiment success rates on LIBERO, RoboTwin 2.0 and RoboCasa benchmarks remain equal to the reported ZR-0 results.
Figures

read the original abstract
Cross-embodiment transfer in vision-language-action (VLA) models remains challenging because low-level state and action spaces differ fundamentally across robot platforms. We observe that the high-level cognitive process underlying manipulation, including scene perception, object identification, task planning, and sub-task decomposition, is largely shared across embodiments. Based on this observation, we present ZR-0, a 2.6 billion parameter end-to-end VLA model that uses dense Embodied Chain-of-Thought (ECoT) supervision to align cross-embodiment representations within the vision-language model (VLM). ZR-0 adopts a dual-stream architecture: a pre-trained VLM (System 2) generates structured ECoT reasoning during training, while a Diffusion Transformer-based action expert (System 1) produces continuous action chunks via flow matching. The two components are coupled through cross-attention, with an attention mask that restricts the action expert to input prompt features only, enabling ECoT generation to be entirely skipped at inference without any performance loss. ZR-0 is pre-trained on ProcCorpus-60M, a large-scale dataset comprising approximately 60 million frames (approximately 1,000 hours) from over 400K trajectories, with dense ECoT annotations covering 96.8% of all frames. We evaluate ZR-0 on three simulation benchmarks spanning single-arm (LIBERO), bimanual (RoboTwin 2.0), and humanoid (RoboCasa GR-1 Tabletop) embodiments, as well as real-world experiments on the xArm platform, demonstrating strong performance across all settings. Code and model checkpoints are available at https://github.com/RUCKBReasoning/ZR-0.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ZR-0, a 2.6B-parameter VLA model trained with dense Embodied Chain-of-Thought (ECoT) supervision on ProcCorpus-60M (~60M frames). It uses a dual-stream architecture: a pre-trained VLM (System 2) produces structured ECoT during training while a Diffusion Transformer action expert (System 1) generates continuous actions via flow matching; the streams are coupled by cross-attention with a mask that restricts the action expert to prompt features only. This design is claimed to allow complete removal of ECoT generation at inference with no performance loss. The model is evaluated on LIBERO, RoboTwin 2.0, RoboCasa GR-1, and real xArm experiments, with code and checkpoints released.
Significance. If the central architectural claim holds, the work would provide a practical route to efficient inference in cross-embodiment VLA models by decoupling high-level reasoning from low-level control. The release of code, model checkpoints, and a large annotated dataset constitutes a concrete contribution to reproducibility and follow-on research.
major comments (3)
- [Abstract] Abstract: the claim that the attention mask 'enables ECoT generation to be entirely skipped at inference without any performance loss' is presented without any supporting success rates, ablation tables, or statistical comparisons between masked training with ECoT versus inference without ECoT tokens.
- [Method and Results] Method and Results sections: no ablation is reported that isolates the effect of the cross-attention mask (e.g., masked vs. unmasked training, or inference with vs. without ECoT tokens) on the three simulation benchmarks or the xArm experiments; without these data it is impossible to verify that the streams are decoupled as asserted.
- [Evaluation] Evaluation: the abstract states 'strong performance across all settings' yet supplies no quantitative numbers, error bars, or baseline comparisons, preventing assessment of whether gains survive controls for dataset size and model scale.
minor comments (1)
- [Introduction] The high-level cognitive-process assumption is invoked to motivate the architecture but receives no direct empirical test; a brief discussion of how this assumption could be falsified would strengthen the motivation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical support of our architectural claims. We address each major comment below and will revise the manuscript to incorporate the requested evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the attention mask 'enables ECoT generation to be entirely skipped at inference without any performance loss' is presented without any supporting success rates, ablation tables, or statistical comparisons between masked training with ECoT versus inference without ECoT tokens.
Authors: We agree the abstract claim requires direct supporting data. While Section 4 reports overall benchmark results, we will revise the abstract to include key success rates and add an explicit ablation table comparing performance with ECoT tokens versus inference without ECoT generation across the evaluated settings. revision: yes
-
Referee: [Method and Results] Method and Results sections: no ablation is reported that isolates the effect of the cross-attention mask (e.g., masked vs. unmasked training, or inference with vs. without ECoT tokens) on the three simulation benchmarks or the xArm experiments; without these data it is impossible to verify that the streams are decoupled as asserted.
Authors: The method section details the cross-attention mask design, but we acknowledge the lack of a dedicated ablation isolating its contribution. In the revision we will add results for masked versus unmasked training and inference with versus without ECoT tokens on LIBERO, RoboTwin 2.0, RoboCasa GR-1, and the xArm experiments. revision: yes
-
Referee: [Evaluation] Evaluation: the abstract states 'strong performance across all settings' yet supplies no quantitative numbers, error bars, or baseline comparisons, preventing assessment of whether gains survive controls for dataset size and model scale.
Authors: We agree the abstract can be strengthened with quantitative highlights. We will update it to include representative success rates and baseline comparisons. Detailed tables with numbers, error bars, and scale-controlled baselines already appear in Section 4; we will ensure these are clearly cross-referenced. revision: partial
Circularity Check
No significant circularity detected
full rationale
The manuscript describes an empirical training procedure for ZR-0 using a dual-stream VLM + Diffusion Transformer architecture with an attention mask, pre-training on ProcCorpus-60M, and evaluation on external simulation and real-robot benchmarks. No mathematical derivation, prediction, or first-principles result is presented that reduces by construction to an internal fit, self-definition, or self-citation chain. The shared high-level cognitive process is invoked as an observation motivating the design rather than as a derived claim. The architecture choices (cross-attention mask, ECoT skipping at inference) are design decisions whose validity is asserted to rest on external performance metrics, not on identities internal to the paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-level cognitive process underlying manipulation is largely shared across embodiments
Reference graph
Works this paper leans on
-
[2]
AgiBot-World-Contributors, Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.CoRR, abs/2503.06669,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Motus: A unified latent action world model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, et al. Motus: A unified latent action world model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, pages 35101–35113, 2026
2026
-
[8]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
RT-1: robotics transformer for real-world control at scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alexander Herzog, Jasmine Hsu, et al. RT-1: robotics transformer for real-world control at scale. InRobotics: Science and Systems XIX, Daegu, Republic of Korea, July 10-14, 2023, 2023. doi: 10.15607/RSS.2023.XIX.025. URL http...
-
[13]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Training strategies for efficient embodied reasoning.CoRR, abs/2505.08243,
William Chen, Suneel Belkhale, Suvir Mirchandani, Oier Mees, Danny Driess, Karl Pertsch, and Sergey Levine. Training strategies for efficient embodied reasoning.CoRR, abs/2505.08243,
-
[16]
StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing
StarVLA Community. Starvla: A lego-like codebase for vision-language-action model develop- ing.arXiv preprint arXiv:2604.05014, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
The EPIC-KITCHENS dataset: Collection, challenges and baselines.IEEE Trans
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. The EPIC-KITCHENS dataset: Collection, challenges and baselines.IEEE Trans. Pattern Anal. Mach. Intell., 43(11):4125–4141, 2021. doi: 10.1109/TPAMI.2020.2991965. URL https: //doi.org/10...
-
[18]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum? id=mZn2Xyh9Ec
2024
-
[19]
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 20...
-
[20]
Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, et al
Danny Driess, Jost Tobias Springenberg, Brian Ichter, Lili Yu, Adrian Li-Bell, Karl Pertsch, Allen Z. Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, et al. Knowledge insulating vision-language-action models: Train fast, run fast, generalize better.CoRR, abs/2505.23705,
-
[23]
MolmoAct2: Action Reasoning Models for Real-world Deployment
Haoquan Fang, Jiafei Duan, Donovan Clay, Sam Wang, Shuo Liu, Weikai Huang, Xiang Fan, Wei-Chuan Tsai, Shirui Chen, Yi Ru Wang, et al. Molmoact2: Action reasoning models for real-world deployment.arXiv preprint arXiv:2605.02881, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Haoshu Fang, Hongjie Fang, Zhenyu Tang, Jirong Liu, Chenxi Wang, Junbo Wang, Haoyi Zhu, and Cewu Lu. RH20T: A comprehensive robotic dataset for learning diverse skills in one-shot. InIEEE International Conference on Robotics and Automation, ICRA 2024, Yokohama, Japan, May 13-17, 2024, pages 653–660. IEEE, 2024. doi: 10.1109/ICRA57147.2024.10611615. URL ht...
-
[25]
ProcVLM: Learning Procedure-Grounded Progress Rewards for Robotic Manipulation
Youhe Feng, Hansen Shi, Haoyang Li, Xinlei Guo, Yang Wang, Chengyang Zhang, Jinkai Zhang, Xiaohan Zhang, Jie Tang, and Jing Zhang. Procvlm: Learning procedure-grounded progress rewards for robotic manipulation.CoRR, abs/2605.08774, 2026. doi: 10.48550/ ARXIV .2605.08774. URLhttps://doi.org/10.48550/arXiv.2605.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.08774 2026
-
[26]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3, 000 hours of egocentric video. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 18973–18990. IEEE...
-
[27]
Chia-Yu Hung, Navonil Majumder, Haoyuan Deng, Liu Renhang, Yankang Ang, Amir Zadeh, Chuan Li, Dorien Herremans, Ziwei Wang, and Soujanya Poria. Nora-1.5: A vision-language- action model trained using world model-and action-based preference rewards.arXiv preprint arXiv:2511.14659, 2025. 13
-
[30]
Robobrain: A unified brain model for robotic manipulation from abstract to concrete
Yuheng Ji, Huajie Tan, Jiayu Shi, Xiaoshuai Hao, Yuan Zhang, Hengyuan Zhang, Pengwei Wang, Mengdi Zhao, Yao Mu, Pengju An, et al. Robobrain: A unified brain model for robotic manipulation from abstract to concrete. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1724–1734, 2025
2025
-
[31]
DROID: A large-scale in-the-wild robot manipulation dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. DROID: A large-scale in-the-wild robot manipulation dataset. InRobotics: Science and Systems XX, Delft, The Netherlands, July 15-19, 2024, 2024. doi: 10.15607/RSS.2024....
-
[32]
Sanketi, Quan Vuong, et al
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Paul Foster, Pannag R. Sanketi, Quan Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning, 6-9 November 2024, Munich, Germany, volume 270 ofProceedings of Machine Learning Research, pages 2679–2713...
2024
-
[34]
Onetwovla: A unified vision-language-action model with adaptive reasoning.CoRR, abs/2505.11917,
Fanqi Lin, Ruiqian Nai, Yingdong Hu, Jiacheng You, Junming Zhao, and Yang Gao. Onetwovla: A unified vision-language-action model with adaptive reasoning.CoRR, abs/2505.11917,
-
[37]
Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll \' a r, and C
Tsung-Yi Lin, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO: common objects in context. In Computer Vision - ECCV 2014 - 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V, volume 8693 ofLecture Notes in Computer Science, pages 740–755....
-
[38]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. URL http://papers.nips.cc/paper_files/paper/2023/hash/ 6dcf277ea32ce3288914faf369fe6de...
2023
-
[40]
RDT-1B: a diffusion foundation model for bimanual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. RDT-1B: a diffusion foundation model for bimanual manipulation. In 14 The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL https://openreview.net/forum?id= yAzN4tz7oI
2025
-
[41]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019. URLhttps://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[42]
Robocasa: Large-scale simulation of everyday tasks for generalist robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots. InRobotics: Science and Systems (RSS), 2024
2024
-
[43]
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and RT-X models : Open x-embodiment collaboration. InIEEE International Conference on Robotics and Automation, ICRA 2024, Yokohama, Japan, May 13-17, 20...
-
[44]
InProceedings of the SIGGRAPH Asia 2025 Conference Papers (SA Conference Papers ’25)
William Peebles and Saining Xie. Scalable diffusion models with transformers. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 4172–4182. IEEE, 2023. doi: 10.1109/ICCV51070.2023.00387. URL https://doi. org/10.1109/ICCV51070.2023.00387
-
[47]
Improving language understanding by generative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018
2018
-
[48]
Generalized Slow Roll for Tensors
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: memory op- timizations toward training trillion parameter models. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC 2020, Virtual Event / Atlanta, Georgia, USA, November 9-19, 2020, page 20. IEEE/ACM, 2020. doi: 10.1109/...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41405.2020.00024 2020
-
[50]
Gemini Robotics Team, Abbas Abdolmaleki, Saminda Abeyruwan, Joshua Ainslie, Jean- Baptiste Alayrac, Montserrat Gonzalez Arenas, Ashwin Balakrishna, Nathan Batchelor, Alex Bewley, Jeffrey T. Bingham, et al. Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer.CoRR, abs/2510.03342,
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Cambrian- 1: A fully open, vision-centric exploration of multimodal llms
Peter Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Adithya Iyer, Sai Charitha Akula, Shusheng Yang, Jihan Yang, Manoj Middepogu, Ziteng Wang, et al. Cambrian- 1: A fully open, vision-centric exploration of multimodal llms. InAdvances in Neural Information Processing Systems 37: Annual Conference on Neural Informa- tion Processing Systems 2024, NeurIPS 202...
2024
-
[53]
Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen- Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al
Homer Rich Walke, Kevin Black, Tony Z. Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen- Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. Bridgedata V2: A dataset for robot learning at scale. InConference on Robot Learning, CoRL 2023, 6-9 November 2023, Atlanta, GA, USA, volume 229 ofProceedings of Machine Learning Research, pages 1723–173...
2023
-
[54]
VP-VLA: Visual Prompting as an Interface for Vision-Language-Action Models
Zixuan Wang, Yuxin Chen, Yuqi Liu, Jinhui Ye, Pengguang Chen, Changsheng Lu, Shu Liu, Bei Yu, and Jiaya Jia. Vp-vla: Visual prompting as an interface for vision-language-action models.arXiv preprint arXiv:2603.22003, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
A Pragmatic VLA Foundation Model
Wei Wu, Fan Lu, Yunnan Wang, Shuai Yang, Shi Liu, Fangjing Wang, Qian Zhu, He Sun, Yong Wang, Shuailei Ma, et al. A pragmatic vla foundation model.arXiv preprint arXiv:2601.18692, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
Yandan Yang, Shuang Zeng, Tong Lin, Xinyuan Chang, Dekang Qi, Junjin Xiao, Haoyun Liu, Ronghan Chen, Yuzhi Chen, Dongjie Huo, et al. Abot-m0: Vla foundation model for robotic manipulation with action manifold learning.arXiv preprint arXiv:2602.11236, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
DeepThinkVLA: Enhancing Reasoning Capability of Vision-Language-Action Models
Cheng Yin, Yankai Lin, Wang Xu, Sikyuen Tam, Xiangrui Zeng, Zhiyuan Liu, and Zhouping Yin. Deepthinkvla: Enhancing reasoning capability of vision-language-action models.arXiv preprint arXiv:2511.15669, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Maskplan: Masked generative layout planning from partial input
Qiying Yu, Quan Sun, Xiaosong Zhang, Yufeng Cui, Fan Zhang, Yue Cao, Xinlong Wang, and Jingjing Liu. Capsfusion: Rethinking image-text data at scale. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 14022–14032. IEEE, 2024. doi: 10.1109/CVPR52733.2024.01330. URL https: //doi.org/10.1109...
-
[61]
Qwen-RobotManip Technical Report: Alignment Unlocks Scale for Robotic Manipulation Foundation Models
Haoqi Yuan, Zhixuan Liang, Anzhe Chen, Ye Wang, Haoyang Li, Pei Lin, Yiyang Huang, Zixing Lei, Tong Zhang, Jiazhao Zhang, et al. Qwen-robotmanip technical report: Alignment unlocks scale for robotic manipulation foundation models, 2026. URL https://arxiv.org/ abs/2606.17846
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[62]
Robopoint: A vision-language model for spatial affordance prediction in robotics
Wentao Yuan, Jiafei Duan, Valts Blukis, Wilbert Pumacay, Ranjay Krishna, Adithyavairavan Murali, Arsalan Mousavian, and Dieter Fox. Robopoint: A vision-language model for spatial affordance prediction in robotics. InConference on Robot Learning, 6-9 November 2024, Munich, Germany, volume 270 ofProceedings of Machine Learning Research, pages 4005–
2024
-
[63]
URLhttps://proceedings.mlr.press/v270/yuan25c.html
PMLR, 2024. URLhttps://proceedings.mlr.press/v270/yuan25c.html
2024
-
[64]
Robotic control via embodied chain-of-thought reasoning
Michal Zawalski, William Chen, Karl Pertsch, Oier Mees, Chelsea Finn, and Sergey Levine. Robotic control via embodied chain-of-thought reasoning. InConference on Robot Learning, 6-9 November 2024, Munich, Germany, volume 270 ofProceedings of Machine Learning Research, pages 3157–3181. PMLR, 2024. URL https://proceedings.mlr.press/v270/ zawalski25a.html
2024
-
[65]
Igniting vlms toward the embodied space.CoRR, abs/2509.11766,
Andy Zhai, Brae Liu, Bruno Fang, Chalse Cai, Ellie Ma, Ethan Yin, Hao Wang, Hugo Zhou, James Wang, Lights Shi, et al. Igniting vlms toward the embodied space.CoRR, abs/2509.11766,
-
[67]
JoyAI-RA 0.1: A Foundation Model for Robotic Autonomy
Tianle Zhang, Zhihao Yuan, Dafeng Chi, Peidong Liu, Dongwei Li, Kejun Hu, Likui Zhang, Junnan Nie, Ziming Wei, Zengjue Chen, et al. Joyai-ra 0.1: A foundation model for robotic autonomy.arXiv preprint arXiv:2604.20100, 2026. 16
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[68]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
-
[69]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-VLA: soft-prompted transformer as scalable cross-embodiment vision-language-action model.CoRR, abs/2510.10274, 2025. doi: 10.48550/ ARXIV .2510.10274. URLhttps://doi.org/10.48550/arXiv.2510.10274
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.10274 2025
-
[70]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
arXiv (2023) https://doi.org/10.48550/arXiv
Zhongyi Zhou, Yichen Zhu, Junjie Wen, Chaomin Shen, and Yi Xu. Chatvla-2: Vision- language-action model with open-world embodied reasoning from pretrained knowledge.CoRR, abs/2505.21906, 2025. doi: 10.48550/ARXIV .2505.21906. URL https://doi.org/10. 48550/arXiv.2505.21906
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[72]
RT-2: vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. RT-2: vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, CoRL 2023, 6-9 November 2023, Atlanta, GA, USA, volume 229 ofProceedings of Machine Learning Research, pages 2165–2...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.