SimScale: Learning to Drive via Real-World Simulation at Scale
Pith reviewed 2026-05-17 04:29 UTC · model grok-4.3
The pith
Co-training on real driving logs and simulated states from perturbed trajectories improves planning robustness and scales with more simulation data alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
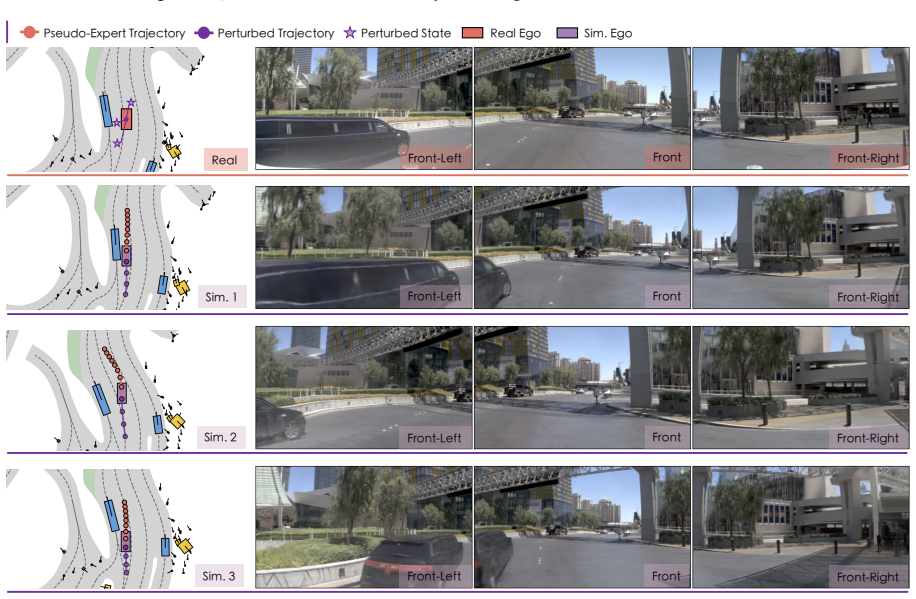
The SimScale framework synthesizes high-fidelity multi-view observations for perturbed ego trajectories using advanced neural rendering in a reactive environment and supplies action supervision through a pseudo-expert trajectory generation mechanism for these new states. A simple co-training strategy on both real-world and simulated samples produces significant improvements in robustness and generalization for various planning methods on challenging real-world benchmarks, up to +8.6 EPDMS on navhard and +2.9 on navtest. These policy gains scale smoothly when simulation data volume is increased, even without additional real-world data.
What carries the argument
The simulation pipeline that creates unseen states from real logs via neural rendering on perturbed trajectories, together with the pseudo-expert trajectory generation that supplies action supervision for co-training.
If this is right
- Planning methods gain robustness in safety-critical and out-of-distribution scenarios.
- Generalization on real-world benchmarks improves without collecting additional real data.
- Policy performance continues to rise smoothly as simulation data volume increases.
- Different policy architectures exhibit distinct scaling behaviors with added simulation data.
- The quality of pseudo-expert design directly affects the usefulness of the synthesized supervision.
Where Pith is reading between the lines
- Continuous model improvement could occur in deployed systems by generating fresh simulated states from newly collected logs.
- Similar synthesis and co-training methods could address data scarcity in other robotics decision tasks.
- The reactive environment component may capture interaction dynamics that static log replay misses.
Load-bearing premise
The pseudo-expert trajectory generation produces sufficiently accurate action supervision for the newly simulated states that do not appear in the original logs.
What would settle it
Performance on navhard and navtest stops improving or declines once simulation data volume exceeds a certain scale, or the gains vanish when the pseudo-expert labels are replaced by noisier supervision.
Figures








read the original abstract
Achieving fully autonomous driving systems requires learning rational decisions in a wide span of scenarios, including safety-critical and out-of-distribution ones. However, such cases are underrepresented in real-world corpus collected by human experts. To complement for the lack of data diversity, we introduce a novel and scalable simulation framework capable of synthesizing massive unseen states upon existing driving logs. Our pipeline utilizes advanced neural rendering with a reactive environment to generate high-fidelity multi-view observations controlled by the perturbed ego trajectory. Furthermore, we develop a pseudo-expert trajectory generation mechanism for these newly simulated states to provide action supervision. Upon the synthesized data, we find that a simple co-training strategy on both real-world and simulated samples can lead to significant improvements in both robustness and generalization for various planning methods on challenging real-world benchmarks, up to +8.6 EPDMS on navhard and +2.9 on navtest. More importantly, such policy improvement scales smoothly by increasing simulation data only, even without extra real-world data streaming in. We further reveal several crucial findings of such a sim-real learning system, which we term SimScale, including the design of pseudo-experts and the scaling properties for different policy architectures. Simulation data and code have been released at https://github.com/OpenDriveLab/SimScale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SimScale, a scalable simulation framework that synthesizes large volumes of unseen driving states from real-world logs. It perturbs ego trajectories, applies neural rendering to produce high-fidelity multi-view observations, and uses a pseudo-expert mechanism to generate action labels for the new states. A simple co-training strategy on real and simulated data is shown to improve planning robustness and generalization on challenging real-world benchmarks (up to +8.6 EPDMS on navhard and +2.9 on navtest), with performance scaling smoothly as simulation data volume increases even without additional real data.
Significance. If the pseudo-expert labels prove reliable for the generated out-of-distribution states, the work provides a practical, data-efficient path to augment real-world corpora for autonomous driving, addressing under-representation of rare and safety-critical scenarios. The reported empirical scaling behavior and public release of simulation data and code are notable strengths that support reproducibility and further research.
major comments (2)
- [§3.2] §3.2 (Pseudo-expert trajectory generation): The headline result and the claim of smooth scaling with simulation data alone rest on the assumption that the pseudo-expert supplies accurate action supervision for states produced by trajectory perturbation and neural rendering. The manuscript provides no independent validation (e.g., label error rates against held-out real trajectories or an oracle policy on rendered views) for these novel states, leaving open the possibility that observed EPDMS gains reflect data volume or regularization rather than genuine robustness improvements.
- [§5] §5 (Scaling experiments): The cross-architecture scaling results would be more convincing with a control experiment that adds equivalent volumes of data with deliberately noisy or random labels; without it, it remains unclear whether the smooth improvement curve is driven by the quality of the pseudo-expert supervision or simply by increased training data quantity.
minor comments (3)
- [Abstract] Abstract: the phrase 'pseudo-expert quality is validated' is referenced but not elaborated; a single sentence summarizing the validation approach used in the paper would improve clarity for readers.
- [Figure 3] Figure 3 and associated caption: the distinction between real and rendered views is visually subtle; adding explicit arrows or annotations highlighting distribution-shift examples would aid interpretation.
- [§4] Notation: EPDMS is used throughout without an explicit expansion on first use in the main text (though defined in the abstract); adding the expansion at first appearance would help.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our work. We provide detailed responses to each major comment below and outline the revisions we intend to make to address the concerns raised.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Pseudo-expert trajectory generation): The headline result and the claim of smooth scaling with simulation data alone rest on the assumption that the pseudo-expert supplies accurate action supervision for states produced by trajectory perturbation and neural rendering. The manuscript provides no independent validation (e.g., label error rates against held-out real trajectories or an oracle policy on rendered views) for these novel states, leaving open the possibility that observed EPDMS gains reflect data volume or regularization rather than genuine robustness improvements.
Authors: We appreciate the referee pointing out the need for validation of the pseudo-expert labels on out-of-distribution states. Obtaining direct ground truth for these synthesized states is challenging since they are generated by perturbing real trajectories. However, the pseudo-expert is constructed by optimizing trajectories in the reactive environment to match expert-like behavior, and we have included ablations in the paper showing the importance of the pseudo-expert design. To further address this, we will add a new section discussing the reliability of the pseudo-expert and include any available indirect validations, such as consistency checks with the original expert policy on unperturbed states. We acknowledge that this is a limitation and will clarify it in the revised manuscript. revision: partial
-
Referee: [§5] §5 (Scaling experiments): The cross-architecture scaling results would be more convincing with a control experiment that adds equivalent volumes of data with deliberately noisy or random labels; without it, it remains unclear whether the smooth improvement curve is driven by the quality of the pseudo-expert supervision or simply by increased training data quantity.
Authors: We agree that including a control experiment with noisy labels would provide stronger evidence for the role of pseudo-expert quality. We will conduct this experiment by training with random action labels at the same data volumes and include the results in the revised paper. This will demonstrate that the scaling improvements are indeed attributable to the quality of the generated supervision rather than mere data volume. revision: yes
Circularity Check
No circularity: empirical augmentation evaluated on external benchmarks
full rationale
The paper presents a practical pipeline that perturbs real driving logs, renders new observations via neural rendering, labels them with a pseudo-expert, and co-trains policies on the combined real+simulated data. All reported gains (+8.6 EPDMS on navhard, +2.9 on navtest) and the scaling-with-simulation-volume observation are measured directly on held-out real-world test sets. No equations, uniqueness theorems, or first-principles derivations are offered that could reduce to fitted parameters or self-referential definitions by construction. The pseudo-expert mechanism is a methodological choice whose quality is assessed only through downstream empirical performance on independent benchmarks, rendering the work self-contained without circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Neural rendering produces observations whose distribution is close enough to real sensor data for policy training to transfer.
- domain assumption Pseudo-expert trajectories generated for unseen states provide valid action supervision.
Forward citations
Cited by 6 Pith papers
-
DriveFuture: Future-Aware Latent World Models for Autonomous Driving
DriveFuture achieves SOTA results on NAVSIM by conditioning latent world model states on future predictions to directly inform trajectory planning.
-
Xiaomi OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
OneVL is the first latent CoT method to exceed explicit CoT accuracy on four driving benchmarks while running at answer-only speed, by supervising latent tokens with a visual world model decoder.
-
Xiaomi OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
OneVL achieves superior accuracy to explicit chain-of-thought reasoning at answer-only latency by supervising latent tokens with a visual world model decoder that predicts future frames.
-
SIM1: Physics-Aligned Simulator as Zero-Shot Data Scaler in Deformable Worlds
SIM1 converts sparse real demonstrations into high-fidelity synthetic data through physics-aligned simulation, yielding policies that match real-data performance at a 1:15 ratio with 90% zero-shot success on deformabl...
-
Optimization-Guided Diffusion for Interactive Scene Generation
OMEGA guides diffusion sampling with per-step constrained optimization and game-theoretic adversarial modeling to generate physically valid and interactive driving scenes, raising valid scene ratios from 32% to 72% an...
-
EponaV2: Driving World Model with Comprehensive Future Reasoning
EponaV2 advances perception-free driving world models by forecasting comprehensive future 3D geometry and semantic representations, achieving SOTA planning performance on NAVSIM benchmarks.
Reference graph
Works this paper leans on
-
[1]
Adam: A Method for Stochastic Optimization
Kingma DP Ba J Adam et al. A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980, 2014. 2
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[2]
Hassan Abu Alhaija, Jose Alvarez, Maciej Bala, Tiffany Cai, Tianshi Cao, Liz Cha, Joshua Chen, Mike Chen, Francesco Ferroni, Sanja Fidler, et al. Cosmos-transfer1: Conditional world generation with adaptive multimodal control.arXiv preprint arXiv:2503.14492, 2025. 1, 4
-
[3]
Scaling laws of motion forecasting and planning–a technical report.arXiv preprint arXiv:2506.08228,
Mustafa Baniodeh, Kratarth Goel, Scott Ettinger, Carlos Fuertes, Ari Seff, Tim Shen, Cole Gulino, Chenjie Yang, Ghassen Jerfel, Dokook Choe, et al. Scaling laws of motion forecasting and planning–a technical report.arXiv preprint arXiv:2506.08228, 2025. 1
-
[4]
Pdm-lite: A rule-based planner for carla leaderboard 2.0.Univ
Jens Beißwenger. Pdm-lite: A rule-based planner for carla leaderboard 2.0.Univ. T ¨ubingen, 2024. 4
work page 2024
-
[5]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakr- ishnan, Kehang Han, Karol Hausman, Alex Herzog, Jas- mine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov,...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Lan- guage models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Lan- guage models are few-shot learners. InNeurIPS, 2020. 2
work page 2020
-
[7]
Pseudo- simulation for autonomous driving
Wei Cao, Marcel Hallgarten, Tianyu Li, Daniel Dauner, Xunjiang Gu, Caojun Wang, Yakov Miron, Marco Aiello, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, Andreas Geiger, and Kashyap Chitta. Pseudo- simulation for autonomous driving. InCoRL, 2025. 2, 5, 1
work page 2025
-
[8]
Mp3: A unified model to map, perceive, predict and plan
Sergio Casas, Abbas Sadat, and Raquel Urtasun. Mp3: A unified model to map, perceive, predict and plan. InCVPR,
-
[9]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction
David Charatan, Sizhe Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InCVPR, 2024. 4
work page 2024
-
[10]
End-to-end autonomous driving: Challenges and frontiers.TPAMI, 2024
Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, An- dreas Geiger, and Hongyang Li. End-to-end autonomous driving: Challenges and frontiers.TPAMI, 2024. 2, 7, 1
work page 2024
-
[11]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning.arXiv preprint arXiv:2402.13243,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Omnire: Omni urban scene reconstruction
Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo de Lutio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Go- jcic, Sanja Fidler, Marco Pavone, Li Song, and Yue Wang. Omnire: Omni urban scene reconstruction. InICLR, 2025. 1
work page 2025
-
[13]
Diffusion policy: Visuomotor policy learning via action dif- fusion.RSS, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action dif- fusion.RSS, 2025. 8
work page 2025
-
[14]
Transfuser: Imitation with transformer-based sensor fusion for autonomous driv- ing.TPAMI, 2022
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driv- ing.TPAMI, 2022. 2, 4, 5, 6, 1, 3
work page 2022
-
[15]
OpenScene Contributors. OpenScene: The largest up-to- date 3d occupancy prediction benchmark in autonomous driving.https://github.com/OpenDriveLab/ OpenScene, 2023. 5
work page 2023
-
[16]
Building reliable sim driving agents by scaling self-play, 2025
Daphne Cornelisse, Aarav Pandya, Kevin Joseph, Joseph Su´arez, and Eugene Vinitsky. Building reliable sim driving agents by scaling self-play, 2025. 1, 4
work page 2025
-
[17]
Robust autonomy emerges from self-play.arXiv preprint arXiv:2502.03349, 2025
Marco Cusumano-Towner, David Hafner, Alex Hertzberg, Brody Huval, Aleksei Petrenko, Eugene Vinitsky, Erik Wi- jmans, Taylor Killian, Stuart Bowers, Ozan Sener, et al. Robust autonomy emerges from self-play.arXiv preprint arXiv:2502.03349, 2025. 8, 1, 4
-
[18]
Parting with misconceptions about learning- based vehicle motion planning
Daniel Dauner, Marcel Hallgarten, Andreas Geiger, and Kashyap Chitta. Parting with misconceptions about learning- based vehicle motion planning. InCoRL, 2023. 2, 5, 6, 3 9
work page 2023
-
[19]
Navsim: Data-driven non- reactive autonomous vehicle simulation and benchmarking
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, Andreas Geiger, and Kashyap Chitta. Navsim: Data-driven non- reactive autonomous vehicle simulation and benchmarking. InNeurIPS, 2024. 2, 5
work page 2024
-
[20]
CARLA: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. CARLA: An open urban driving simulator. InCoRL, 2017. 1
work page 2017
-
[21]
Rap: 3d rasterization augmented end-to-end planning.arXiv preprint arXiv:2510.04333, 2025
Lan Feng, Yang Gao, Eloi Zablocki, Quanyi Li, Wuyang Li, Sichao Liu, Matthieu Cord, and Alexandre Alahi. Rap: 3d rasterization augmented end-to-end planning.arXiv preprint arXiv:2510.04333, 2025. 1
-
[22]
Rad: Training an end-to-end driving pol- icy via large-scale 3dgs-based reinforcement learning
Hao Gao, Shaoyu Chen, Bo Jiang, Bencheng Liao, Yiang Shi, Xiaoyang Guo, Yuechuan Pu, Haoran Yin, Xiangyu Li, Xinbang Zhang, Ying Zhang, Wenyu Liu, Qian Zhang, and Xinggang Wang. Rad: Training an end-to-end driving pol- icy via large-scale 3dgs-based reinforcement learning. In NeurIPS, 2025. 2, 1, 4
work page 2025
-
[23]
Learning to drive from a world model
Mitchell Goff, Greg Hogan, George Hotz, Armand du Parc Locmaria, Kacper Raczy, Harald Sch ¨afer, Adeeb Shi- hadeh, Weixing Zhang, and Yassine Yousfi. Learning to drive from a world model. InCVPR, 2025. 2
work page 2025
-
[24]
Ke Guo, Haochen Liu, Xiaojun Wu, Jia Pan, and Chen Lv. ipad: Iterative proposal-centric end-to-end autonomous driv- ing.arXiv preprint arXiv:2505.15111, 2025. 1
-
[25]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InCVPR,
-
[26]
St-p3: End-to-end vision-based au- tonomous driving via spatial-temporal feature learning
Shengchao Hu, Li Chen, Penghao Wu, Hongyang Li, Junchi Yan, and Dacheng Tao. St-p3: End-to-end vision-based au- tonomous driving via spatial-temporal feature learning. In ECCV, 2022. 1
work page 2022
-
[27]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. In CVPR, 2023. 4, 1
work page 2023
-
[28]
Drivegpt: Scaling autoregressive behavior models for driving.arXiv preprint arXiv:2412.14415, 2024
Xin Huang, Eric M Wolff, Paul Vernaza, Tung Phan-Minh, Hongge Chen, David S Hayden, Mark Edmonds, Brian Pierce, Xinxin Chen, Pratik Elias Jacob, et al. Drivegpt: Scaling autoregressive behavior models for driving.arXiv preprint arXiv:2412.14415, 2024. 1
-
[29]
EMMA: End-to-End Multimodal Model for Autonomous Driving
Jyh-Jing Hwang, Runsheng Xu, Hubert Lin, Wei-Chih Hung, Jingwei Ji, Kristy Choi, Di Huang, Tong He, Paul Covington, Benjamin Sapp, et al. Emma: End-to-end multimodal model for autonomous driving.arXiv preprint arXiv:2410.23262,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Carl: Learning scalable planning policies with simple rewards
Bernhard Jaeger, Daniel Dauner, Jens Beißwenger, Simon Gerstenecker, Kashyap Chitta, and Andreas Geiger. Carl: Learning scalable planning policies with simple rewards. In CoRL, 2025. 4
work page 2025
-
[31]
Think twice before driv- ing: Towards scalable decoders for end-to-end autonomous driving
Xiaosong Jia, Penghao Wu, Li Chen, Jiangwei Xie, Conghui He, Junchi Yan, and Hongyang Li. Think twice before driv- ing: Towards scalable decoders for end-to-end autonomous driving. InCVPR, 2023. 1
work page 2023
-
[32]
Drivetransformer: Unified transformer for scalable end-to- end autonomous driving
Xiaosong Jia, Junqi You, Zhiyuan Zhang, and Junchi Yan. Drivetransformer: Unified transformer for scalable end-to- end autonomous driving. InICLR, 2025. 1
work page 2025
-
[33]
Vad: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. InICCV, 2023. 1
work page 2023
-
[34]
Junzhe Jiang, Nan Song, Jingyu Li, Xiatian Zhu, and Li Zhang. Realengine: Simulating autonomous driving in re- alistic context.arXiv preprint arXiv:2505.16902, 2025. 1
-
[35]
Scenediffuser: Efficient and controllable driving simulation initialization and rollout
Max Jiang, Yijing Bai, Andre Cornman, Christopher Davis, Xiukun Huang, Hong Jeon, Sakshum Kulshrestha, John Lambert, Shuangyu Li, Xuanyu Zhou, et al. Scenediffuser: Efficient and controllable driving simulation initialization and rollout. InNeurIPS, 2024. 1, 4
work page 2024
-
[36]
Siwen Jiao, Kangan Qian, Hao Ye, Yang Zhong, Ziang Luo, Sicong Jiang, Zilin Huang, Yangyi Fang, Jinyu Miao, Zheng Fu, et al. Evadrive: Evolutionary adversarial policy opti- mization for end-to-end autonomous driving.arXiv preprint arXiv:2508.09158, 2025. 1
-
[37]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[38]
Towards learning-based planning: The nuplan benchmark for real-world autonomous driving
Napat Karnchanachari, Dimitris Geromichalos, Kok Seang Tan, Nanxiang Li, Christopher Eriksen, Shakiba Yaghoubi, Noushin Mehdipour, Gianmarco Bernasconi, Whye Kit Fong, Yiluan Guo, et al. Towards learning-based planning: The nuplan benchmark for real-world autonomous driving. InICRA, 2024. 5, 2
work page 2024
-
[39]
3d gaussian splatting for real-time radiance field rendering.TOG, 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.TOG, 2023. 2, 3
work page 2023
-
[40]
Centermask: Real-time anchor-free instance segmentation
Youngwan Lee and Jongyoul Park. Centermask: Real-time anchor-free instance segmentation. InCVPR, 2020. 6, 2
work page 2020
-
[41]
Robustness results in linear-quadratic gaussian based mul- tivariable control designs.TAC, 2003
Norman Lehtomaki, NJAM Sandell, and Michael Athans. Robustness results in linear-quadratic gaussian based mul- tivariable control designs.TAC, 2003. 3
work page 2003
-
[42]
Uniscene: Unified occupancy-centric driving scene generation
Bohan Li, Jiazhe Guo, Hongsi Liu, Yingshuang Zou, Yikang Ding, Xiwu Chen, Hu Zhu, Feiyang Tan, Chi Zhang, Tiancai Wang, et al. Uniscene: Unified occupancy-centric driving scene generation. InCVPR, 2025. 4
work page 2025
-
[43]
Derun Li, Jianwei Ren, Yue Wang, Xin Wen, Pengxiang Li, Leimeng Xu, Kun Zhan, Zhongpu Xia, Peng Jia, Xianpeng Lang, et al. Finetuning generative trajectory model with re- inforcement learning from human feedback.arXiv preprint arXiv:2503.10434, 2025. 1
-
[44]
Kailin Li, Zhenxin Li, Shiyi Lan, Yuan Xie, Zhizhong Zhang, Jiayi Liu, Zuxuan Wu, Zhiding Yu, and Jose M Alvarez. Hydra-mdp++: Advancing end-to-end driv- ing via expert-guided hydra-distillation.arXiv preprint arXiv:2503.12820, 2025. 5
-
[45]
Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning.TPAMI, 2022
Quanyi Li, Zhenghao Peng, Lan Feng, Qihang Zhang, Zhenghai Xue, and Bolei Zhou. Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning.TPAMI, 2022. 1
work page 2022
-
[46]
Qifeng Li, Xiaosong Jia, Shaobo Wang, and Junchi Yan. Think2drive: Efficient reinforcement learning by thinking with latent world model for autonomous driving (in carla- v2). InECCV, 2024. 4 10
work page 2024
-
[47]
Mtgs: Multi-traversal gaussian splatting.arXiv preprint arXiv:2503.12552, 2025
Tianyu Li, Yihang Qiu, Zhenhua Wu, Carl Lind- str¨om, Peng Su, Matthias Nießner, and Hongyang Li. Mtgs: Multi-traversal gaussian splatting.arXiv preprint arXiv:2503.12552, 2025. 3, 5
-
[48]
Xiaofan Li, Yifu Zhang, and Xiaoqing Ye. Drivingdiffusion: layout-guided multi-view driving scenarios video generation with latent diffusion model. InECCV, 2024. 1
work page 2024
-
[49]
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Yingyan Li, Shuyao Shang, Weisong Liu, Bing Zhan, Haochen Wang, Yuqi Wang, Yuntao Chen, Xiaoman Wang, Yasong An, Chufeng Tang, et al. Drivevla-w0: World mod- els amplify data scaling law in autonomous driving.arXiv preprint arXiv:2510.12796, 2025. 1
work page internal anchor Pith review arXiv 2025
-
[50]
Yingyan Li, Yuqi Wang, Yang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end driving with online tra- jectory evaluation via bev world model.arXiv preprint arXiv:2504.01941, 2025. 1
-
[51]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing Wang, et al. Recogdrive: A reinforced cognitive frame- work for end-to-end autonomous driving.arXiv preprint arXiv:2506.08052, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, et al. Hydra-mdp: End-to-end multimodal planning with multi- target hydra-distillation.arXiv preprint arXiv:2406.06978,
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Hydra-next: Robust closed-loop driving with open-loop training.arXiv preprint arXiv:2503.12030, 2025
Zhenxin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Zux- uan Wu, and Jose M Alvarez. Hydra-next: Robust closed-loop driving with open-loop training.arXiv preprint arXiv:2503.12030, 2025. 1
-
[54]
Zhenxin Li, Wenhao Yao, Zi Wang, Xinglong Sun, Jingde Chen, Nadine Chang, Maying Shen, Jingyu Song, Zuxuan Wu, Shiyi Lan, et al. Ztrs: Zero-imitation end-to-end au- tonomous driving with trajectory scoring.arXiv preprint arXiv:2510.24108, 2025. 1
-
[55]
Zhenxin Li, Wenhao Yao, Zi Wang, Xinglong Sun, Joshua Chen, Nadine Chang, Maying Shen, Zuxuan Wu, Shiyi Lan, and Jose M Alvarez. Generalized trajectory scor- ing for end-to-end multimodal planning.arXiv preprint arXiv:2506.06664, 2025. 2, 5, 6, 1, 3
-
[56]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InCVPR, 2025. 2, 4, 5, 6, 1, 3
work page 2025
-
[57]
Hybrid-prediction integrated plan- ning for autonomous driving.TPAMI, 2025
Haochen Liu, Zhiyu Huang, Wenhui Huang, Haohan Yang, Xiaoyu Mo, and Chen Lv. Hybrid-prediction integrated plan- ning for autonomous driving.TPAMI, 2025. 1
work page 2025
-
[58]
Haochen Liu, Tianyu Li, Haohan Yang, Li Chen, Caojun Wang, Ke Guo, Haochen Tian, Hongchen Li, Hongyang Li, and Chen Lv. Reinforced refinement with self-aware ex- pansion for end-to-end autonomous driving.arXiv preprint arXiv:2506.09800, 2025. 2, 7, 1
-
[59]
Novel view extrapolation with video diffusion priors.arXiv preprint arXiv:2411.14208, 2024
Kunhao Liu, Ling Shao, and Shijian Lu. Novel view extrapolation with video diffusion priors.arXiv preprint arXiv:2411.14208, 2024. 4
-
[60]
3dgs-enhancer: Enhancing unbounded 3d gaussian splatting with view- consistent 2d diffusion priors
Xi Liu, Chaoyi Zhou, and Siyu Huang. 3dgs-enhancer: Enhancing unbounded 3d gaussian splatting with view- consistent 2d diffusion priors. InNeurIPS, 2024. 4
work page 2024
-
[61]
Neuroncap: Photorealistic closed- loop safety testing for autonomous driving
William Ljungbergh, Adam Tonderski, Joakim Johnan- der, Holger Caesar, Kalle ˚Astr¨om, Michael Felsberg, and Christoffer Petersson. Neuroncap: Photorealistic closed- loop safety testing for autonomous driving. InECCV, 2024. 1
work page 2024
-
[62]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[63]
Sim-and-real co-training: A simple recipe for vision-based robotic manipulation
Abhiram Maddukuri, Zhenyu Jiang, Lawrence Yunliang Chen, Soroush Nasiriany, Yuqi Xie, Yu Fang, Wenqi Huang, Zu Wang, Zhenjia Xu, Nikita Chernyadev, Scott Reed, Ken Goldberg, Ajay Mandlekar, Linxi Fan, and Yuke Zhu. Sim-and-real co-training: A simple recipe for vision-based robotic manipulation. InRSS, 2025. 2, 4
work page 2025
-
[64]
Data scaling laws for end-to-end autonomous driving
Alexander Naumann, Xunjiang Gu, Tolga Dimlioglu, Mar- iusz Bojarski, Alperen Degirmenci, Alexander Popov, De- vansh Bisla, Marco Pavone, Urs Muller, and Boris Ivanovic. Data scaling laws for end-to-end autonomous driving. In CVPR, 2025. 2, 1
work page 2025
-
[65]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, Nikita Cherniadev Johan Bjorck andFernando Casta˜neda, Xingye Da, Runyu Ding, Linxi ”Jim” Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llon- top, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Alexander Popov, Alperen Degirmenci, David Wehr, Shashank Hegde, Ryan Oldja, Alexey Kamenev, Bertrand Douillard, David Nist ´er, Urs Muller, Ruchi Bhargava, et al. Mitigating covariate shift in imitation learning for au- tonomous vehicles using latent space generative world mod- els.arXiv preprint arXiv:2409.16663, 2024. 2
-
[67]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, 2021. 2, 1
work page 2021
-
[68]
Sparsedrive: End-to-end au- tonomous driving via sparse scene representation
Wenchao Sun, Xuewu Lin, Yining Shi, Chuang Zhang, Hao- ran Wu, and Sifa Zheng. Sparsedrive: End-to-end au- tonomous driving via sparse scene representation. InICRA,
-
[69]
Flow matching-based autonomous driving planning with advanced interactive behavior modeling
Tianyi Tan, Yinan Zheng, Ruiming Liang, Zexu Wang, Kexin Zheng, Jinliang Zheng, Jianxiong Li, Xianyuan Zhan, and Jingjing Liu. Flow matching-based autonomous driving planning with advanced interactive behavior modeling. In NeurIPS, 2025. 4
work page 2025
-
[70]
Martin Treiber, Ansgar Hennecke, and Dirk Helbing. Con- gested traffic states in empirical observations and micro- scopic simulations.Physical review E, 2000. 2, 3, 1, 4 11
work page 2000
-
[71]
Drivedreamer: Towards real-world- drive world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jia- gang Zhu, and Jiwen Lu. Drivedreamer: Towards real-world- drive world models for autonomous driving. InECCV, 2024. 1
work page 2024
-
[72]
Para-drive: Parallelized architecture for real- time autonomous driving
Xinshuo Weng, Boris Ivanovic, Yan Wang, Yue Wang, and Marco Pavone. Para-drive: Parallelized architecture for real- time autonomous driving. InCVPR, 2024. 1
work page 2024
-
[73]
Penghao Wu, Xiaosong Jia, Li Chen, Junchi Yan, Hongyang Li, and Yu Qiao. Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong base- line. InNeurIPS, 2022. 1
work page 2022
-
[74]
Generating multimodal driving scenes via next-scene predic- tion
Yanhao Wu, Haoyang Zhang, Tianwei Lin, Lichao Huang, Shujie Luo, Rui Wu, Congpei Qiu, Wei Ke, and Tong Zhang. Generating multimodal driving scenes via next-scene predic- tion. InCVPR, 2025. 4
work page 2025
-
[75]
Vid2sim: Realistic and interactive simulation from video for urban navigation
Ziyang Xie, Zhizheng Liu, Zhenghao Peng, Wayne Wu, and Bolei Zhou. Vid2sim: Realistic and interactive simulation from video for urban navigation. InCVPR, 2025. 1
work page 2025
-
[76]
Zebin Xing, Xingyu Zhang, Yang Hu, Bo Jiang, Tong He, Qian Zhang, Xiaoxiao Long, and Wei Yin. Goalflow: Goal- driven flow matching for multimodal trajectories generation in end-to-end autonomous driving. InCVPR, 2025. 4, 1
work page 2025
-
[77]
Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios
Runsheng Xu, Hubert Lin, Wonseok Jeon, Hao Feng, Yu- liang Zou, Liting Sun, John Gorman, Kate Tolstaya, Sarah Tang, Brandyn White, et al. Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios. arXiv preprint arXiv:2510.26125, 2025. 2
-
[78]
Challenger: Affordable adversarial driving video generation.arXiv preprint arXiv:2505.15880, 2025
Zhiyuan Xu, Bohan Li, Huan-ang Gao, Mingju Gao, Yong Chen, Ming Liu, Chenxu Yan, Hang Zhao, Shuo Feng, and Hao Zhao. Challenger: Affordable adversarial driving video generation.arXiv preprint arXiv:2505.15880, 2025. 1
-
[79]
Street gaussians: Modeling dynamic urban scenes with gaussian splatting
Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, and Sida Peng. Street gaussians: Modeling dynamic urban scenes with gaussian splatting. InECCV, 2024. 3, 1
work page 2024
-
[80]
Jiawei Yang, Jiahui Huang, Yuxiao Chen, Yan Wang, Boyi Li, Yurong You, Apoorva Sharma, Maximilian Igl, Peter Karkus, Danfei Xu, et al. Storm: Spatio-temporal re- construction model for large-scale outdoor scenes.arXiv preprint arXiv:2501.00602, 2024. 4
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.