E³C: Video Generation with 3D Environmental Memory and Ego-Exo Human Pose Control
Pith reviewed 2026-06-29 22:22 UTC · model grok-4.3
The pith
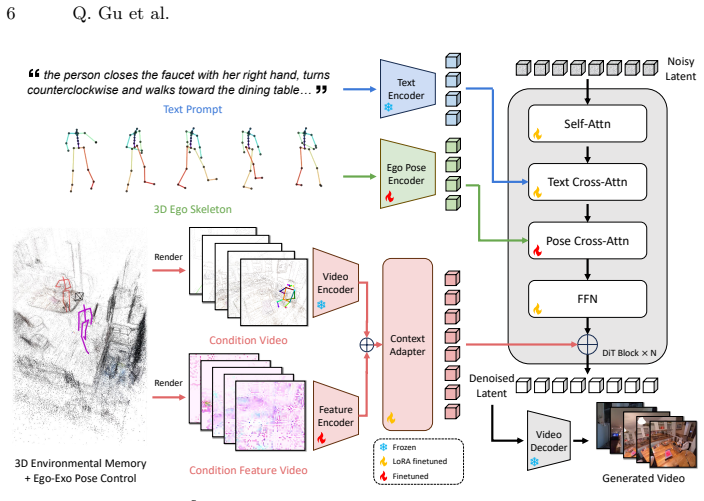
E³C generates egocentric videos by conditioning a diffusion model on rendered 3D point cloud memory while controlling ego and exo human poses separately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
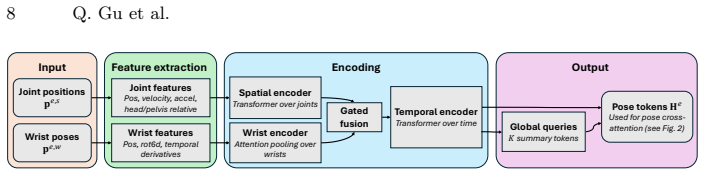
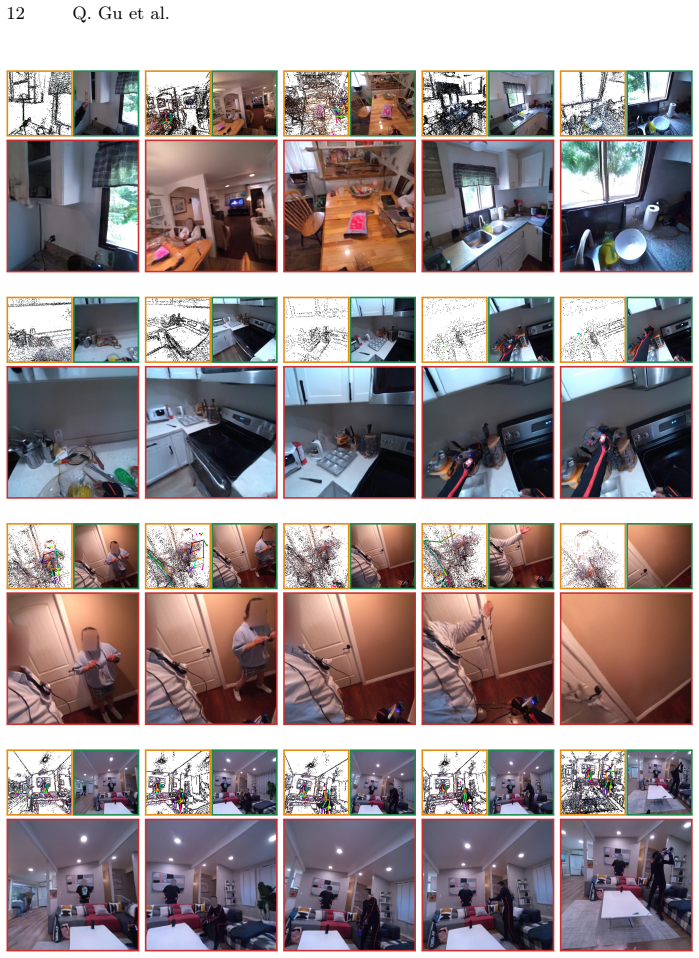
E³C constructs a semi-dense point cloud-based 3D memory from context frames, with each point augmented by appearance descriptors from video-VAE features. Rendering this memory into target viewpoints supplies conditioning signals aligned with the desired frames. Ego human control is specified through 3D body joints and wrist motion, with an ego motion encoder creating persistent tokens to maintain control during occlusions, while exo human control uses skeleton renderings. This separation of persistent scene structure from human-driven dynamics produces higher visual fidelity, more accurate camera motion and object consistency, stronger ego and exo pose control, and intuitive scene editing on
What carries the argument
The semi-dense point cloud-based 3D memory, rendered into target viewpoints to provide conditioning that disentangles persistent scene structure from human dynamics.
If this is right
- Generated videos exhibit improved object consistency and visual fidelity across frames with large viewpoint shifts.
- Camera motion accuracy and both ego and exo human pose control increase relative to baselines that lack separate memory and control pathways.
- Scene editing becomes feasible by direct modification of the underlying 3D memory points before rendering.
- Ego control remains effective even when the camera wearer's body parts leave the visible frame.
Where Pith is reading between the lines
- Incremental updates to the point cloud memory could support generation of video sequences longer than the initial context window.
- The same memory-plus-pose separation might transfer to predicting future views for navigation or planning in robotic systems.
- Multiple independent ego and exo control signals could extend the method to multi-person interaction videos.
Load-bearing premise
The semi-dense point cloud 3D memory built from context frames, when rendered to new viewpoints, supplies conditioning signals that preserve persistent scene structure despite rapid viewpoint changes, self-occlusions, and subtle articulated actions.
What would settle it
Generated video sequences that display drifting object locations or mismatched appearances in regions of rapid camera motion around self-occluded body parts, when compared frame-by-frame against ground-truth Nymeria recordings.
Figures



read the original abstract
Controllable and physically grounded egocentric video generation is essential for embodied agents to reason about how their own and others' actions manifest and change the world. Compared to generic video synthesis, egocentric generation is especially challenging: the camera is tightly coupled to the actor, leading to rapid viewpoint changes and frequent self-occlusions; the underlying actions are subtle, articulated, and often only partially visible; and both the people and the scene state must evolve consistently with the specified controls. We present E$^3$C, a controllable video diffusion framework for egocentric generation that builds structured and compact conditions disentangling persistent scene structure from human-driven dynamics. From context frames, E$^3$C constructs a semi-dense point cloud-based 3D memory and augments each point with appearance descriptors from video-VAE features. Rendering this memory into target viewpoints produces conditioning aligned with the target frames. Human dynamics are modeled separately. The observed people in the scene are controlled by skeleton renderings (exo human control), while the camera wearer is specified by their 3D body joints and 6DoF wrist motion (ego human control). To preserve ego human control when the wearer's body parts are invisible, we introduce an ego motion encoder that produces persistent cross-attention tokens. Experiments on Nymeria show that E$^3$C improves visual fidelity, camera-motion accuracy, object consistency, and ego & exo human control over strong baselines, while also enabling intuitive scene editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents E³C, a controllable video diffusion framework for egocentric video generation. From context frames it constructs a semi-dense point cloud-based 3D memory augmented with video-VAE appearance descriptors; this memory is rendered into target viewpoints to supply conditioning signals. Human dynamics are handled separately via skeleton renderings (exo control) and 3D body joints plus 6DoF wrist motion (ego control), with an additional ego motion encoder producing persistent cross-attention tokens for cases where the wearer's body is occluded. Experiments on the Nymeria dataset are reported to show gains in visual fidelity, camera-motion accuracy, object consistency, and ego/exo human control relative to strong baselines, together with the ability to perform intuitive scene editing.
Significance. If the empirical claims hold, the work offers a practical disentanglement of persistent 3D scene structure from articulated human dynamics, directly addressing the rapid viewpoint changes, self-occlusions, and partial visibility that characterize egocentric video. The combination of rendered 3D memory with separate pose controls and the editing capability would be a useful contribution to controllable video synthesis for embodied agents.
major comments (1)
- [Abstract] Abstract: the central empirical claim—that E³C improves visual fidelity, camera-motion accuracy, object consistency, and ego/exo human control on Nymeria—is stated without any quantitative numbers, metric definitions, baseline descriptions, error bars, dataset statistics, or implementation details. This absence prevents verification that the reported gains are supported by the method or data.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract and for the positive overall assessment of the work. We address the point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim—that E³C improves visual fidelity, camera-motion accuracy, object consistency, and ego/exo human control on Nymeria—is stated without any quantitative numbers, metric definitions, baseline descriptions, error bars, dataset statistics, or implementation details. This absence prevents verification that the reported gains are supported by the method or data.
Authors: We agree that the abstract would be strengthened by including quantitative support for the claims. In the revised version we will expand the final sentence of the abstract to report the key numerical improvements (e.g., relative gains in FID, camera-motion error, object-consistency metrics, and control accuracy) together with the names of the primary baselines, the main evaluation metrics, and a brief note on the Nymeria split used. Error bars and full implementation details will remain in the experimental section, as is conventional, but the abstract will now contain enough concrete numbers to allow immediate verification of the stated gains. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a video diffusion model that builds a semi-dense 3D point-cloud memory from context frames, renders it for target views, and applies separate skeleton-based controls for exo and ego human motion. No equations, fitted parameters, or predictions are presented that reduce by construction to the inputs themselves. The central claims rest on empirical results on the Nymeria dataset rather than any self-referential derivation or self-citation chain. The provided text contains no load-bearing self-citations, uniqueness theorems, or ansatzes that collapse the method onto its own definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gated Multimodal Units for Information Fusion
Arevalo, J., Solorio, T., Montes-y Gómez, M., González, F.A.: Gated multimodal units for information fusion. arXiv preprint arXiv:1702.01992 (2017) 8, 24
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv preprint arXiv:1607.06450 (2016) 23
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Bahmani, S., Skorokhodov, I., Qian, G., Siarohin, A., Menapace, W., Tagliasacchi, A., Lindell, D.B., Tulyakov, S.: Ac3d: Analyzing and improving 3d camera con- trol in video diffusion transformers. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22875–22889 (2025) 4
2025
-
[4]
Bahmani, S., Skorokhodov, I., Siarohin, A., Menapace, W., Qian, G., Vasilkovsky, M., Lee, H.Y., Wang, C., Zou, J., Tagliasacchi, A., Lindell, D.B., Tulyakov, S.: Vd3d: Taming large video diffusion transformers for 3d camera control. Proc. ICLR (2025) 4
2025
-
[5]
arXiv preprint arXiv:2506.21552 (2025) 2, 4, 9, 11, 13, 26
Bai, Y., Tran, D., Bar, A., LeCun, Y., Darrell, T., Malik, J.: Whole-body condi- tioned egocentric video prediction. arXiv preprint arXiv:2506.21552 (2025) 2, 4, 9, 11, 13, 26
-
[6]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Bar, A., Zhou, G., Tran, D., Darrell, T., LeCun, Y.: Navigation world models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15791–15801 (2025) 26 16 Q. Gu et al
2025
-
[7]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Cao, C., Zhou, J., Li, S., Liang, J., Yu, C., Wang, F., Xue, X., Fu, Y.: Uni3c: Unifying precisely 3d-enhanced camera and human motion controls for video gen- eration. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–12 (2025) 2, 4, 7, 8
2025
-
[8]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025) 10, 27
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020) 8, 24
2020
-
[10]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chou, G., Zhang, K., Bi, S., Tan, H., Xu, Z., Luan, F., Hariharan, B., Snavely, N.: Generating 3d-consistent videos from unposed internet photos. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 27934–27945 (2025) 4
2025
-
[11]
arXiv preprint arXiv:2511.18991 (2025) 4
Danier, D., Gao, G., McDonagh, S., Li, C., Bilen, H., Mac Aodha, O.: View- consistent diffusion representations for 3d-consistent video generation. arXiv preprint arXiv:2511.18991 (2025) 4
-
[12]
VideoGPA: Distilling Geometry Priors for 3D-Consistent Video Generation
Du, H., Ye, J., Cong, X., Li, R., Ni, J., Agarwal, A., Zhou, Z., Li, Z., Balestriero, R., Wang, Y.: Videogpa: Distilling geometry priors for 3d-consistent video generation. arXiv preprint arXiv:2601.23286 (2026) 4
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Project Aria: A New Tool for Egocentric Multi-Modal AI Research
Engel, J., Somasundaram, K., Goesele, M., Sun, A., Gamino, A., Turner, A., Ta- lattof, A., Yuan, A., Souti, B., Meredith, B., Peng, C., Sweeney, C., Wilson, C., Barnes, D., DeTone, D., Caruso, D., Valleroy, D., Ginjupalli, D., Frost, D., Miller, E., Mueggler, E., Oleinik, E., Zhang, F., Somasundaram, G., Solaira, G., Lanaras, H., Howard-Jenkins, H., Tang,...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Escobar, M., Puentes, J., Forigua, C., Pont-Tuset, J., Maninis, K.K., Arbelaez, P.: Egocast: Forecasting egocentric human pose in the wild. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 5831–5841. IEEE (2025) 2
2025
-
[15]
In: Forty-first international conference on machine learning (2024) 5
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024) 5
2024
-
[16]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Fang, I., Chen, Y., Wang, Y., Zhang, J., Zhang, Q., Xu, J., He, X., Gao, W., Su, H., Li, Y., et al.: Egopat3dv2: Predicting 3d action target from 2d egocentric vision for human-robot interaction. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 3036–3043. IEEE (2024) 2
2024
-
[17]
In: 2017 IEEE international conference on robotics and automation (ICRA)
Finn, C., Levine, S.: Deep visual foresight for planning robot motion. In: 2017 IEEE international conference on robotics and automation (ICRA). pp. 2786–2793. IEEE (2017) 2
2017
-
[18]
E³C: Video Generation with 3D Environmental Memory 17 In: Advances in Neural Information Processing Systems
Fu, S., Tamir, N., Sundaram, S., Chai, L., Zhang, R., Dekel, T., Isola, P.: Dream- sim: Learning new dimensions of human visual similarity using synthetic data. E³C: Video Generation with 3D Environmental Memory 17 In: Advances in Neural Information Processing Systems. vol. 36, pp. 50742–50768 (2023) 13
2023
-
[19]
YOLOX: Exceeding YOLO Series in 2021
Ge, Z., Liu, S., Wang, F., Li, Z., Sun, J.: Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430 (2021) 9, 10
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
In: European Conference on Computer Vision
Gu, Q., Lv, Z., Frost, D., Green, S., Straub, J., Sweeney, C.: Egolifter: Open-world 3d segmentation for egocentric perception. In: European Conference on Computer Vision. pp. 382–400. Springer (2024) 9
2024
-
[21]
In: 2025 International Conference on 3D Vision (3DV)
Guzov, V., Jiang, Y., Hong, F., Pons-Moll, G., Newcombe, R., Liu, C.K., Ye, Y., Ma, L.: Hmd 2: Environment-aware motion generation from single egocentric head-mounted device. In: 2025 International Conference on 3D Vision (3DV). pp. 1394–1405. IEEE (2025) 9
2025
-
[22]
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: En- ablingcameracontrolfortext-to-videogeneration.arXivpreprintarXiv:2404.02101 (2024) 2, 4, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Advances in neural information processing systems30(2017) 13
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017) 13
2017
- [24]
-
[25]
ICLR1(2), 3 (2022) 10
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR1(2), 3 (2022) 10
2022
-
[26]
ViPE: Video Pose Engine for 3D Geometric Perception
Huang, J., Zhou, Q., Rabeti, H., Korovko, A., Ling, H., Ren, X., Shen, T., Gao, J., Slepichev, D., Lin, C.H., Ren, J., Xie, K., Biswas, J., Leal-Taixe, L., Fidler, S.: Vipe: Video pose engine for 3d geometric perception. In: NVIDIA Research Whitepapers arXiv:2508.10934 (2025) 10, 24, 27
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
ACM Transactions on Graphics (TOG)44(6), 1–15 (2025) 2, 4
Huang, T., Zheng, W., Wang, T., Liu, Y., Wang, Z., Wu, J., Jiang, J., Li, H., Lau, R., Zuo, W., et al.: Voyager: Long-range and world-consistent video diffusion for explorable 3d scene generation. ACM Transactions on Graphics (TOG)44(6), 1–15 (2025) 2, 4
2025
-
[28]
VACE: All-in-One Video Creation and Editing
Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y., Liu, Y.: Vace: All-in-one video creation and editing. arXiv preprint arXiv:2503.07598 (2025) 3, 5, 6, 7, 8, 9, 10, 11, 21, 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
arXiv preprint arXiv:2512.08269 (2025) 5
Kang, T., Kim, K., Kim, D., Park, M., Hyung, J., Choo, J.: Egox: Egocentric video generation from a single exocentric video. arXiv preprint arXiv:2512.08269 (2025) 5
-
[30]
ACM Transactions on Graphics (ToG)42(4), 1–14 (2023) 26
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics (ToG)42(4), 1–14 (2023) 26
2023
-
[31]
In: Interna- tional Conference on Learning Representations (2015) 10
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: Interna- tional Conference on Learning Representations (2015) 10
2015
-
[32]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
Koh, J.Y., Lee, H., Yang, Y., Baldridge, J., Anderson, P.: Pathdreamer: A world model for indoor navigation. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 14738–14748 (2021) 2
2021
-
[33]
Naval research logistics quarterly2(1-2), 83–97 (1955) 10
Kuhn, H.W.: The hungarian method for the assignment problem. Naval research logistics quarterly2(1-2), 83–97 (1955) 10
1955
-
[34]
arXiv preprint arXiv:2510.14945 (2025) 4 18 Q
Lee, J., Jung, J., Han, J., Narihira, T., Fukuda, K., Seo, J., Hong, S., Mitsufuji, Y., Kim, S.: 3d scene prompting for scene-consistent camera-controllable video generation. arXiv preprint arXiv:2510.14945 (2025) 4 18 Q. Gu et al
-
[35]
In: Interna- tional conference on machine learning
Lee, J., Lee, Y., Kim, J., Kosiorek, A., Choi, S., Teh, Y.W.: Set transformer: A framework for attention-based permutation-invariant neural networks. In: Interna- tional conference on machine learning. pp. 3744–3753. PMLR (2019) 8, 24
2019
-
[36]
arXiv preprint arXiv:2506.18903 (2025) 2, 4, 9, 10, 11, 21, 25
Li, R., Torr, P., Vedaldi, A., Jakab, T.: Vmem: Consistent interactive video scene generation with surfel-indexed view memory. arXiv preprint arXiv:2506.18903 (2025) 2, 4, 9, 10, 11, 21, 25
-
[37]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, T., Zheng, G., Jiang, R., Zhan, S., Wu, T., Lu, Y., Lin, Y., Deng, C., Xiong, Y., Chen, M., et al.: Realcam-i2v: Real-world image-to-video generation with in- teractive complex camera control. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 28785–28796 (2025) 4
2025
-
[38]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) 5, 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Liu, J.W., Mao, W., Xu, Z., Keppo, J., Shou, M.Z.: Exocentric-to-egocentric video generation.AdvancesinNeuralInformationProcessingSystems37,136149–136172 (2024) 5
2024
-
[40]
arXiv preprint arXiv:2403.09194 (2024) 5
Luo, H., Zhu, K., Zhai, W., Cao, Y.: Intention-driven ego-to-exo video generation. arXiv preprint arXiv:2403.09194 (2024) 5
-
[41]
In: European Conference on Computer Vision
Luo, M., Xue, Z., Dimakis, A., Grauman, K.: Put myself in your shoes: Lifting the egocentric perspective from exocentric videos. In: European Conference on Computer Vision. pp. 407–425. Springer (2024) 5
2024
-
[42]
In: European Conference on Computer Vision
Ma, L., Ye, Y., Hong, F., Guzov, V., Jiang, Y., Postyeni, R., Pesqueira, L., Gamino, A., Baiyya, V., Kim, H.J., et al.: Nymeria: A massive collection of multimodal egocentric daily motion in the wild. In: European Conference on Computer Vision. pp. 445–465. Springer (2024) 3, 9
2024
-
[43]
arXiv preprint arXiv:2511.20186 (2025) 5
Mahdi, M., Fu, Y., Savov, N., Pan, J., Paudel, D.P., Van Gool, L.: Exo2egosyn: Unlocking foundation video generation models for exocentric-to-egocentric video synthesis. arXiv preprint arXiv:2511.20186 (2025) 5
-
[44]
Meta Reality Labs Research: Project aria machine perception services.https: //facebookresearch.github.io/projectaria_tools/docs/ARK/mps(2023), ac- cessed: 2026-01-27 9, 10, 21, 24, 26
2023
-
[45]
Advances in Neural Information Processing Systems36, 72983–73007 (2023) 10, 27
Minderer, M., Gritsenko, A., Houlsby, N.: Scaling open-vocabulary object detec- tion. Advances in Neural Information Processing Systems36, 72983–73007 (2023) 10, 27
2023
-
[46]
movella.com/products/motion-capture/xsens-mvn-link(2023), accessed: 2026- 01-27 9
Movella: Movella Xsens MVN Link Motion Capture System.https : / / www . movella.com/products/motion-capture/xsens-mvn-link(2023), accessed: 2026- 01-27 9
2023
-
[47]
nerf.studio/en/latest/nerfology/methods/splatfacto.html(2023), part of the Nerfstudio framework 9, 10, 11, 21, 26
Nerfstudio Team: Splatfacto: Splatting for fast radiance fields.https://docs. nerf.studio/en/latest/nerfology/methods/splatfacto.html(2023), part of the Nerfstudio framework 9, 10, 11, 21, 26
2023
-
[48]
arXiv preprint arXiv:2511.18173 (2025) 2, 4, 9, 10, 11, 13, 26
Pallotta, E., Azar, S.M., Doorenbos, L., Ozsoy, S., Iqbal, U., Gall, J.: Egocontrol: Controllable egocentric video generation via 3d full-body poses. arXiv preprint arXiv:2511.18173 (2025) 2, 4, 9, 10, 11, 13, 26
-
[49]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023) 5, 6
2023
-
[50]
arXiv preprint arXiv:2506.09042 (2025) 2 E³C: Video Generation with 3D Environmental Memory 19
Ren, X., Lu, Y., Cao, T., Gao, R., Huang, S., Sabour, A., Shen, T., Pfaff, T., Wu, J.Z., Chen, R., et al.: Cosmos-drive-dreams: Scalable synthetic driving data generation with world foundation models. arXiv preprint arXiv:2506.09042 (2025) 2 E³C: Video Generation with 3D Environmental Memory 19
-
[51]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ren, X., Shen, T., Huang, J., Ling, H., Lu, Y., Nimier-David, M., Müller, T., Keller, A., Fidler, S., Gao, J.: Gen3c: 3d-informed world-consistent video gener- ation with precise camera control. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6121–6132 (2025) 2, 4, 7, 9, 10, 11, 21, 24
2025
-
[52]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Shuai, X., Ding, H., Qin, Z., Luo, H., Ma, X., Tao, D.: Free-form motion control: Controlling the 6d poses of camera and objects in video generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12449–12458 (2025) 4
2025
-
[53]
Srivastava, R.K., Greff, K., Schmidhuber, J.: Highway networks. arXiv preprint arXiv:1505.00387 (2015) 8, 24
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[54]
arXiv preprint arXiv:2506.09995 (2025)
Tu, Y., Luo, H., Chen, X., Bai, X., Wang, F., Zhao, H.: Playerone: Egocentric world simulator. arXiv preprint arXiv:2506.09995 (2025) 2
-
[55]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner, T., van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717 (2018) 10
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[56]
Advances in neural information pro- cessing systems30(2017) 8, 23, 24
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017) 8, 23, 24
2017
-
[57]
In: European Conference on Computer Vision
Voleti, V., Yao, C.H., Boss, M., Letts, A., Pankratz, D., Tochilkin, D., Laforte, C., Rombach, R., Jampani, V.: Sv3d: Novel multi-view synthesis and 3d genera- tion from a single image using latent video diffusion. In: European Conference on Computer Vision. pp. 439–457. Springer (2024) 4
2024
-
[58]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025) 3, 5, 10, 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
arXiv preprint arXiv:2510.01183 (2025) 4
Wang, J., Ye, L., Lu, T., Xiao, J., Zhang, J., Guo, Y., Liu, X., Chellappa, R., Peng, C., Yuille, A., et al.: Evoworld: Evolving panoramic world generation with explicit 3d memory. arXiv preprint arXiv:2510.01183 (2025) 4
-
[60]
arXiv preprint arXiv:2411.08380 (2024) 4
Wang,X.,Zhao,K.,Liu,F.,Wang,J.,Zhao,G.,Bao,X.,Zhu,Z.,Zhang,Y.,Wang, X.: Egovid-5m: A large-scale video-action dataset for egocentric video generation. arXiv preprint arXiv:2411.08380 (2024) 4
-
[61]
IEEE TIP13(4), 600–612 (2004) 10
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE TIP13(4), 600–612 (2004) 10
2004
-
[62]
In: ACM SIGGRAPH 2024 Conference Papers
Wang, Z., Yuan, Z., Wang, X., Li, Y., Chen, T., Xia, M., Luo, P., Shan, Y.: Mo- tionctrl: A unified and flexible motion controller for video generation. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–11 (2024) 2, 4
2024
-
[63]
In: The Thirteenth International Conference on Learn- ing Representations, ICLR 2025, Singapore, April 24-28, 2025
Watson, D., Saxena, S., Li, L., Tagliasacchi, A., Fleet, D.J.: Controlling space and time with diffusion models. In: The Thirteenth International Conference on Learn- ing Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net (2025),https://openreview.net/forum?id=d2UrCGtntF2
2025
-
[64]
arXiv preprint arXiv:2506.05284 (2025) 2, 4, 7
Wu, T., Yang, S., Po, R., Xu, Y., Liu, Z., Lin, D., Wetzstein, G.: Video world models with long-term spatial memory. arXiv preprint arXiv:2506.05284 (2025) 2, 4, 7
-
[65]
arXiv preprint arXiv:2407.17470 (2024) 4
Xie, Y., Yao, C.H., Voleti, V., Jiang, H., Jampani, V.: Sv4d: Dynamic 3d con- tent generation with multi-frame and multi-view consistency. arXiv preprint arXiv:2407.17470 (2024) 4
-
[66]
arXiv preprint arXiv:2508.13013 (2025) 2, 4, 9, 10, 11, 13 20 Q
Xiu, J., Hong, F., Li, Y., Li, M., Wang, W., Han, S., Pan, L., Liu, Z.: Egotwin: Dreaming body and view in first person. arXiv preprint arXiv:2508.13013 (2025) 2, 4, 9, 10, 11, 13 20 Q. Gu et al
-
[67]
CamCo: Camera-Controllable 3D-Consistent Image-to-Video Generation
Xu, D., Nie, W., Liu, C., Liu, S., Kautz, J., Wang, Z., Vahdat, A.: Camco: Camera-controllable 3d-consistent image-to-video generation. arXiv preprint arXiv:2406.02509 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
arXiv preprint arXiv:2504.11732 (2025) 5
Xu, J., Huang, Y., Pei, B., Hou, J., Li, Q., Chen, G., Zhang, Y., Feng, R., Xie, W.: Egoexo-gen: Ego-centric video prediction by watching exo-centric videos. arXiv preprint arXiv:2504.11732 (2025) 5
-
[69]
In: Advances in Neural Information Processing Systems (2022) 9, 10
Xu,Y.,Zhang,J.,Zhang,Q.,Tao,D.:ViTPose:Simplevisiontransformerbaselines for human pose estimation. In: Advances in Neural Information Processing Systems (2022) 9, 10
2022
-
[70]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yang, J., Liu, S., Guo, H., Dong, Y., Zhang, X., Zhang, S., Wang, P., Zhou, Z., Xie, B., Wang, Z., et al.: Egolife: Towards egocentric life assistant. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 28885–28900 (2025) 2
2025
-
[71]
In: ACM SIGGRAPH 2024 Conference Papers
Yang, S., Hou, L., Huang, H., Ma, C., Wan, P., Zhang, D., Chen, X., Liao, J.: Direct-a-video: Customized video generation with user-directed camera movement and object motion. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–12 (2024) 2, 4
2024
-
[72]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Yu, J., Bai, J., Qin, Y., Liu, Q., Wang, X., Wan, P., Zhang, D., Liu, X.: Context as memory: Scene-consistent interactive long video generation with memory retrieval. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–11 (2025) 2
2025
-
[73]
In: The Thirteenth International Conference on Learning Representations (2025) 2
Yu, W., Yin, S., Easterbrook, S., Garg, A.: Egosim: Egocentric exploration in virtual worlds with multi-modal conditioning. In: The Thirteenth International Conference on Learning Representations (2025) 2
2025
-
[74]
Zhang, H., Chen, X., Wang, Y., Liu, X., Wang, Y., Qiao, Y.: 4diffusion: Multi-view videodiffusionmodelfor4dgeneration.AdvancesinNeuralInformationProcessing Systems37, 15272–15295 (2024) 4
2024
-
[75]
arXiv preprint arXiv:2512.04515 (2025) 4
Zhang, L., Ye, J., Wang, Y., Zhong, M., Cao, M., Xia, W., Zeng, B., Zhang, Z., Tang, H.: Egolcd: Egocentric video generation with long context diffusion. arXiv preprint arXiv:2512.04515 (2025) 4
-
[76]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023) 8
2023
-
[77]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, Q., Zhai, S., Martin, M.A.B., Miao, K., Toshev, A., Susskind, J., Gu, J.: World-consistent video diffusion with explicit 3d modeling. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21685–21695 (2025) 4
2025
-
[78]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018) 10, 13
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018) 10, 13
2018
-
[79]
arXiv preprint arXiv:2512.15716 (2025) 4
Zhao, J., Wei, F., Liu, Z., Zhang, H., Xu, C., Lu, Y.: Spatia: Video generation with updatable spatial memory. arXiv preprint arXiv:2512.15716 (2025) 4
-
[80]
arXiv preprint arXiv:2410.15957 (2024) 4
Zheng, G., Li, T., Jiang, R., Lu, Y., Wu, T., Li, X.: Cami2v: Camera-controlled image-to-video diffusion model. arXiv preprint arXiv:2410.15957 (2024) 4
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.