Recognition: 2 theorem links
· Lean TheoremLinMU: Multimodal Understanding Made Linear
Pith reviewed 2026-05-16 18:29 UTC · model grok-4.3
The pith
LinMU replaces self-attention in vision-language models with a linear dual-branch module that matches teacher performance on multimodal benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
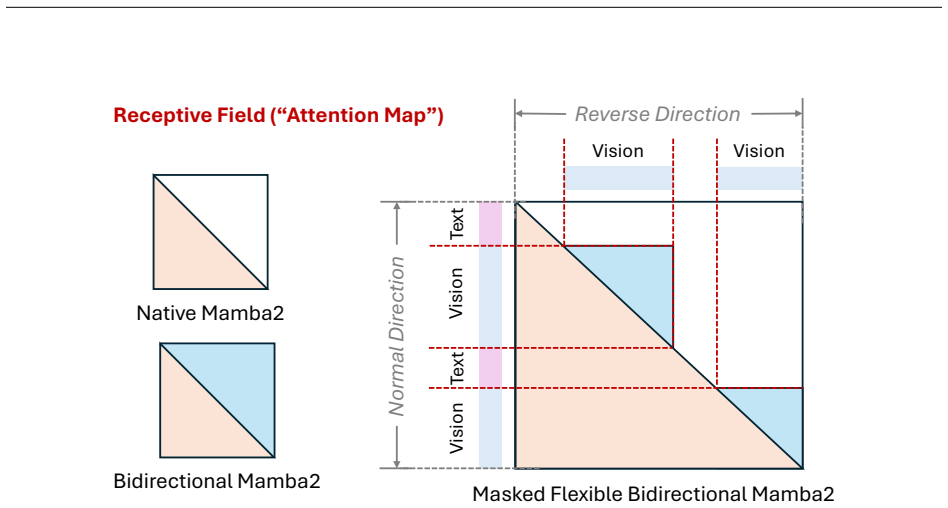
LinMU replaces every self-attention layer in the language model decoder with an M-MATE block: a dual-branch module that combines a bidirectional state-space model branch (Flex-MA) for global context with a localized Swin-style window attention branch (Local-Swin) for adjacent correlations. A three-stage distillation framework converts a pre-trained VLM into this architecture by first training the Flex-MA branch alone from self-attention weights, then jointly fine-tuning both branches, and finally adapting the remaining blocks with LoRA adapters while regressing on the teacher’s hidden states and token logits. On MMMU, TextVQA, LongVideoBench, Video-MME and similar benchmarks, the resulting模型
What carries the argument
M-MATE block: dual-branch replacement for self-attention consisting of a bidirectional state-space model for global context and localized Swin-style window attention for adjacent correlations.
Load-bearing premise
The combination of a bidirectional state-space model branch and localized window attention can fully substitute for global self-attention across multimodal reasoning tasks without measurable degradation after the three-stage distillation.
What would settle it
Accuracy measurements on a long-video or high-resolution image benchmark where LinMU falls measurably below the teacher model on tasks that require full global context.
Figures







read the original abstract
Modern Vision-Language Models (VLMs) achieve impressive performance but are limited by the quadratic complexity of self-attention, which prevents their deployment on edge devices and makes their understanding of high-resolution images and long-context videos prohibitively expensive. To address this challenge, we introduce LinMU (Linear-complexity Multimodal Understanding), a VLM design that achieves linear complexity for the language model decoder without using any quadratic-complexity modules while maintaining the performance of global-attention-based VLMs. LinMU replaces every self-attention layer in the language model decoder with an M-MATE block: a dual-branch module that combines a bidirectional state-space model for global context (Flex-MA branch) with localized Swin-style window attention (Local-Swin branch) for adjacent correlations. To transform a pre-trained VLM into the LinMU architecture, we propose a three-stage distillation framework that (i) initializes both branches with self-attention weights and trains the Flex-MA branch alone, (ii) unfreezes the Local-Swin branch and fine-tunes it jointly with the Flex-MA branch, and (iii) unfreezes the remaining blocks and fine-tunes them using LoRA adapters, while regressing on hidden states and token-level logits of the frozen VLM teacher. On MMMU, TextVQA, LongVideoBench, Video-MME, and other benchmarks, LinMU matches the performance of teacher models, yet reduces Time-To-First-Token (TTFT) by up to 2.7$\times$ and improves token throughput by up to 9.0$\times$ on minute-length videos. Ablations confirm the importance of each distillation stage and the necessity of the two branches of the M-MATE block. The proposed framework demonstrates that state-of-the-art multimodal reasoning can be achieved without quadratic attention, thus opening up avenues for long-context VLMs that can deal with high-resolution images and long videos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LinMU, a VLM architecture that replaces all self-attention layers in the language decoder with M-MATE blocks. Each block combines a bidirectional state-space model branch (Flex-MA) for global context with a localized Swin-style window attention branch (Local-Swin) for adjacent correlations, achieving linear complexity. A three-stage distillation process initializes the branches from a frozen teacher VLM, jointly tunes them, and applies LoRA while regressing on hidden states and logits. The authors report that LinMU matches teacher performance on MMMU, TextVQA, LongVideoBench, Video-MME and related benchmarks while delivering up to 2.7× lower TTFT and 9.0× higher token throughput on minute-length videos.
Significance. If the performance equivalence and robustness claims hold, the work would be significant for enabling efficient long-context and high-resolution multimodal models on edge devices. The dual-branch linear design and staged distillation offer a concrete route to remove quadratic attention without sacrificing multimodal reasoning, with potential impact on deployment of VLMs for video understanding.
major comments (3)
- [Benchmark results] Benchmark results section: the claim of matching teacher performance on MMMU, TextVQA, LongVideoBench, and Video-MME is presented without error bars, standard deviations across runs, or explicit data-exclusion criteria; this weakens the equivalence assertion because the central efficiency claim rests on summarized point estimates whose statistical reliability cannot be assessed.
- [§3] Three-stage distillation framework (described in §3): no quantitative metrics are supplied on how faithfully the Flex-MA bidirectional SSM recovers the teacher's long-range cross-modal token interactions after stages (i)–(iii); hidden-state cosine similarity or logit KL divergence broken down by token distance on minute-length videos would directly test whether the linear recurrence approximates the quadratic mixing that the headline claim requires.
- [Ablation studies] Ablation studies: while the necessity of both branches and all three stages is asserted, the paper does not report the performance drop on global-reasoning subsets when the Local-Swin window size is reduced or when Flex-MA is replaced by a unidirectional SSM; such controls are needed to substantiate that the combination fully substitutes for global self-attention without measurable degradation.
minor comments (2)
- [§3.1] Clarify in §3.1 the precise fusion mechanism inside the M-MATE block (e.g., how Flex-MA and Local-Swin outputs are combined before the feed-forward layer) and whether any additional parameters are introduced beyond the stated LoRA adapters.
- [Supplementary material] Add full training curves and per-stage loss trajectories to the supplementary material to allow readers to verify convergence behavior of the distillation objectives.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and will incorporate revisions to strengthen the statistical rigor and design validation of the manuscript.
read point-by-point responses
-
Referee: Benchmark results section: the claim of matching teacher performance on MMMU, TextVQA, LongVideoBench, and Video-MME is presented without error bars, standard deviations across runs, or explicit data-exclusion criteria; this weakens the equivalence assertion because the central efficiency claim rests on summarized point estimates whose statistical reliability cannot be assessed.
Authors: We agree that error bars and standard deviations are important for assessing statistical reliability. In the revised manuscript we will report mean performance and standard deviations across multiple independent runs for all benchmarks. We will also add an explicit statement confirming that all results use standard benchmark splits with no data exclusion. revision: yes
-
Referee: Three-stage distillation framework (described in §3): no quantitative metrics are supplied on how faithfully the Flex-MA bidirectional SSM recovers the teacher's long-range cross-modal token interactions after stages (i)–(iii); hidden-state cosine similarity or logit KL divergence broken down by token distance on minute-length videos would directly test whether the linear recurrence approximates the quadratic mixing that the headline claim requires.
Authors: We thank the referee for this valuable suggestion. We will add quantitative analysis in the revised paper, including hidden-state cosine similarity and logit KL divergence metrics broken down by token distance on minute-length videos, to directly demonstrate that the Flex-MA branch recovers the teacher's long-range interactions after each distillation stage. revision: yes
-
Referee: Ablation studies: while the necessity of both branches and all three stages is asserted, the paper does not report the performance drop on global-reasoning subsets when the Local-Swin window size is reduced or when Flex-MA is replaced by a unidirectional SSM; such controls are needed to substantiate that the combination fully substitutes for global self-attention without measurable degradation.
Authors: We agree these targeted controls would better substantiate the design. In the revised manuscript we will include additional ablation results on global-reasoning subsets, reporting performance when the Local-Swin window size is reduced and when Flex-MA is replaced by a unidirectional SSM variant, to confirm the necessity of the bidirectional global branch and chosen window size. revision: yes
Circularity Check
No significant circularity; architecture and distillation are independent of target metrics
full rationale
The paper defines the M-MATE block (Flex-MA bidirectional SSM + Local-Swin window attention) as a direct architectural replacement for self-attention, with linear complexity arising from the SSM recurrence and fixed-window design rather than any fitted quantity. The three-stage distillation explicitly regresses on hidden states and logits from a frozen external teacher VLM, so benchmark matching is an empirical outcome of that objective rather than a prediction forced by construction. No equations reduce a claimed result to its inputs, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled via prior work by the same authors. The efficiency gains (TTFT and throughput) follow directly from the linear modules once the weights are obtained. This is a standard distillation setup with independent architectural choices; the derivation chain does not collapse.
Axiom & Free-Parameter Ledger
free parameters (1)
- LoRA rank and scaling factors
axioms (2)
- domain assumption Bidirectional state-space models can represent global context at linear cost
- domain assumption Localized window attention suffices for adjacent token correlations
invented entities (3)
-
M-MATE block
no independent evidence
-
Flex-MA branch
no independent evidence
-
Local-Swin branch
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LinMU replaces every self-attention layer ... with an M-MATE block: a dual-branch module that combines a bidirectional state-space model ... with localized Swin-style window attention
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-stage distillation framework that (i) initializes both branches with self-attention weights and trains the Flex-MA branch alone
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Efficient hybrid mamba- transformer reasoning model.arXiv preprint arXiv:2508.14444, 2025
Aarti Basant, Abhijit Khairnar, Abhijit Paithankar, Abhinav Khattar, Adithya Renduchintala, Aditya Malte, Akhiad Bercovich, Akshay Hazare, Alejandra Rico, Aleksander Ficek, et al. NVIDIA Nemotron Nano 2: An accurate and efficient hybrid Mamba-Transformer reasoning model.arXiv preprint arXiv:2508.14444,
-
[3]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer.arXiv preprint arXiv:2004.05150,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[4]
Jieneng Chen, Luoxin Ye, Ju He, Zhao-Yang Wang, Daniel Khashabi, and Alan Yuille. Efficient large multi- modal models via visual context compression.Advances in Neural Information Processing Systems, 37: 73986–74007, 2024a. Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
NVIDIA Nemotron Nano V2 VL.arXiv preprint arXiv:2511.03929,
Amala Sanjay Deshmukh, Kateryna Chumachenko, Tuomas Rintamaki, Matthieu Le, Tyler Poon, Da- nial Mohseni Taheri, Ilia Karmanov, Guilin Liu, Jarno Seppanen, Guo Chen, et al. NVIDIA Nemotron Nano V2 VL.arXiv preprint arXiv:2511.03929,
-
[6]
Shangzhe Di, Zhelun Yu, Guanghao Zhang, Haoyuan Li, Tao Zhong, Hao Cheng, Bolin Li, Wanggui He, Fangxun Shu, and Hao Jiang. Streaming video question-answering with in-context video KV-cache re- trieval.arXiv preprint arXiv:2503.00540,
-
[7]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
PruneVid: Visual token pruning for efficient video large language models
Xiaohu Huang, Hao Zhou, and Kai Han. PruneVid: Visual token pruning for efficient video large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 19959–19973,
work page 2025
-
[9]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. GPT-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
A survey on vision-language-action models for autonomous driving
Sicong Jiang, Zilin Huang, Kangan Qian, Ziang Luo, Tianze Zhu, Yang Zhong, Yihong Tang, Menglin Kong, Yunlong Wang, Siwen Jiao, et al. A survey on vision-language-action models for autonomous driving. arXiv preprint arXiv:2506.24044,
-
[11]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. OpenVLA: An open-source vision-language- action model.arXiv preprint arXiv:2406.09246,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. LlaVA-OneVision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 26296–26306, 2024a. HaotianLiu, ChunyuanLi, YuhengLi, BoLi, YuanhanZhang, ShengShen, andYongJaeLee. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge, January 2024b. URLhttps...
work page 2024
-
[14]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. MathVista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
RWKV: Reinventing RNNs for the Transformer Era
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, et al. RWKV: Reinventing rnns for the transformer era.arXiv preprint arXiv:2305.13048,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
VL-Mamba: Exploring state space models for multimodal learning.arXiv preprint arXiv:2403.13600,
21 Yanyuan Qiao, Zheng Yu, Longteng Guo, Sihan Chen, Zijia Zhao, Mingzhen Sun, Qi Wu, and Jing Liu. VL-Mamba: Exploring state space models for multimodal learning.arXiv preprint arXiv:2403.13600,
-
[17]
Boyuan Sun, Jiaxing Zhao, Xihan Wei, and Qibin Hou. LLaVA-Scissor: Token compression with semantic connected components for video LLMs.arXiv preprint arXiv:2506.21862,
-
[18]
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive Network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Yi-Lin Sung, Jaehong Yoon, and Mohit Bansal. ECoFLaP: Efficient coarse-to-fine layer-wise pruning for vision-language models.arXiv preprint arXiv:2310.02998,
-
[20]
CoViPAL: Layer-wise contextualized visual token pruning for large vision-language models
Zicong Tang, Ziyang Ma, Suqing Wang, Zuchao Li, Lefei Zhang, Hai Zhao, Yun Li, and Qianren Wang. CoViPAL: Layer-wise contextualized visual token pruning for large vision-language models. InFindings of the Association for Computational Linguistics: EMNLP 2025, pp. 20701–20714,
work page 2025
-
[21]
Hongjie Wang, Chih-Yao Ma, Yen-Cheng Liu, Ji Hou, Tao Xu, Jialiang Wang, Felix Juefei-Xu, Yaqiao Luo, Peizhao Zhang, Tingbo Hou, Peter Vajda, Xiaoliang Dai, and Niraj K. Jha. LinGen-Uni: A universal linear-complexity framework for high-resolution minute-length text-to-video generation.Research Square Preprint, 2025a. Hongjie Wang, Chih-Yao Ma, Yen-Cheng L...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. SparseVLM: Visual token sparsification for efficient vision-language model inference.arXiv preprint arXiv:2410.04417, 2024a. Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video in...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. MiniGPT-4: Enhancing vision- language understanding with advanced large language models.arXiv preprint arXiv:2304.10592,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.