Recognition: no theorem link
OmniCamera: A Unified Framework for Multi-task Video Generation with Arbitrary Camera Control
Pith reviewed 2026-05-10 20:05 UTC · model grok-4.3
The pith
OmniCamera separates video content from camera motion for independent control in generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
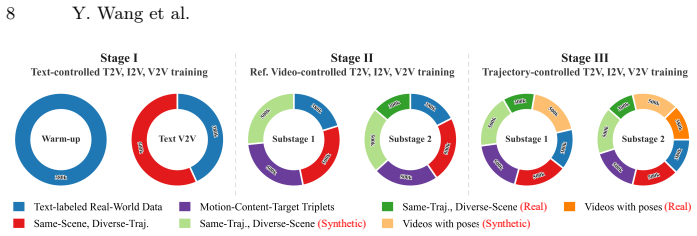
OmniCamera is a unified framework that explicitly disentangles the dynamic content of a scene from the camera motion used to observe it. The approach rests on the OmniCAM hybrid dataset of curated real videos paired with synthetic examples that supply diverse ground-truth camera trajectories, together with a Dual-level Curriculum Co-Training procedure that first teaches basic control on easier conditions and synthetic data before adapting to real footage for photorealism.
What carries the argument
The Dual-level Curriculum Co-Training strategy, which introduces control modalities progressively by difficulty at the condition level and shifts from synthetic to real data at the data level to reduce modality interference.
If this is right
- Any camera trajectory can be combined with arbitrary scene content to produce generated videos.
- Complex camera movements become controllable while visual quality remains high across tasks.
- A single model handles multiple video generation scenarios without separate specialized training.
- Photorealistic results are obtained by first learning control on synthetic data then adapting to real data.
Where Pith is reading between the lines
- The same staged training pattern could be tested on other factor-disentanglement problems such as separating lighting from geometry in image synthesis.
- Extending the framework to longer sequences would show whether camera control remains stable beyond the lengths used in the current experiments.
- If the hybrid data construction generalizes, similar mixing of real and synthetic sources might reduce data needs in related multimodal generation settings.
Load-bearing premise
The curriculum co-training approach resolves conflicts between different control signals and data sources without causing performance drops or biases when moving from synthetic to real videos.
What would settle it
A test in which the model is asked to follow camera trajectories more extreme or longer than those present in the hybrid dataset and the resulting videos are checked for loss of visual consistency or control accuracy compared with simpler paths.
Figures












read the original abstract
Video fundamentally intertwines two crucial axes: the dynamic content of a scene and the camera motion through which it is observed. However, existing generation models often entangle these factors, limiting independent control. In this work, we introduce OmniCamera, a unified framework designed to explicitly disentangle and command these two dimensions. This compositional approach enables flexible video generation by allowing arbitrary pairings of camera and content conditions, unlocking unprecedented creative control. To overcome the fundamental challenges of modality conflict and data scarcity inherent in such a system, we present two key innovations. First, we construct OmniCAM, a novel hybrid dataset combining curated real-world videos with synthetic data that provides diverse paired examples for robust multi-task learning. Second, we propose a Dual-level Curriculum Co-Training strategy that mitigates modality interference and synergistically learns from diverse data sources. This strategy operates on two levels: first, it progressively introduces control modalities by difficulties (condition-level), and second, trains for precise control on synthetic data before adapting to real data for photorealism (data-level). As a result, OmniCamera achieves state-of-the-art performance, enabling flexible control for complex camera movements while maintaining superior visual quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OmniCamera, a unified framework for multi-task video generation that explicitly disentangles dynamic scene content from camera motion to enable arbitrary, independent control over both. It proposes the OmniCAM hybrid dataset (curated real-world videos paired with synthetic data) and a Dual-level Curriculum Co-Training strategy—operating at condition level via progressive modality introduction by difficulty and at data level via synthetic pre-training before real-data adaptation—to address modality conflict and data scarcity, claiming state-of-the-art performance in flexible complex camera control while preserving superior visual quality.
Significance. If the empirical results validate that the curriculum strategy and hybrid dataset achieve the claimed disentanglement without trade-offs or domain-shift artifacts, the work would advance controllable video synthesis by providing a compositional conditioning approach that existing models lack. This could enable new applications in creative video production and simulation, with the dual-level training representing a practical solution to common data and interference issues in multi-modal generation.
major comments (2)
- [Abstract] Abstract: The central claim of state-of-the-art performance with effective mitigation of modality conflict is unsupported by any quantitative metrics, baselines, ablation studies, control-error curves, or quality scores. Without these, it is impossible to verify whether the Dual-level Curriculum Co-Training avoids the synthetic-to-real biases or interference risks highlighted in the stress-test note.
- [Abstract] Abstract: The description of the Dual-level Curriculum Co-Training (condition-level progressive introduction plus data-level synthetic pre-training before real adaptation) is too high-level to assess load-bearing details such as the exact scheduling of modality difficulty, loss weighting between levels, or how adaptation prevents domination of learned dynamics by synthetic trajectories.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly enumerated the specific multi-task learning objectives (e.g., which generation subtasks are jointly trained) rather than referring to them generically.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and have prepared revisions to the abstract to better support our claims with references to the empirical evidence and methodological details provided in the full paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of state-of-the-art performance with effective mitigation of modality conflict is unsupported by any quantitative metrics, baselines, ablation studies, control-error curves, or quality scores. Without these, it is impossible to verify whether the Dual-level Curriculum Co-Training avoids the synthetic-to-real biases or interference risks highlighted in the stress-test note.
Authors: The abstract is a concise summary; the full manuscript (Sections 4 and 5) contains the requested quantitative support, including baseline comparisons, ablation studies on the curriculum components, control-error curves, and perceptual quality metrics that demonstrate SOTA performance and effective mitigation of modality conflict. These results indicate that the Dual-level Curriculum Co-Training successfully avoids synthetic-to-real biases and interference, as the progressive training and adaptation steps preserve control accuracy while improving photorealism. To address the concern directly in the abstract, we will revise it to include brief references to these key empirical findings. revision: yes
-
Referee: [Abstract] Abstract: The description of the Dual-level Curriculum Co-Training (condition-level progressive introduction plus data-level synthetic pre-training before real adaptation) is too high-level to assess load-bearing details such as the exact scheduling of modality difficulty, loss weighting between levels, or how adaptation prevents domination of learned dynamics by synthetic trajectories.
Authors: We agree the abstract description is high-level by design. The manuscript (Section 3.2) specifies the condition-level scheduling (starting with single-modality basic camera control and progressively adding complex multi-modal conditions), loss weighting (balanced coefficients between condition-level and data-level objectives), and adaptation mechanism (synthetic pre-training followed by real-data fine-tuning with control modules partially frozen to retain learned dynamics). We will revise the abstract to incorporate these load-bearing details at a summary level while remaining within length limits. revision: yes
Circularity Check
No circularity: empirical framework with independent dataset and training innovations
full rationale
The paper presents a new architecture, hybrid dataset (OmniCAM), and Dual-level Curriculum Co-Training strategy as engineering contributions. No equations, first-principles derivations, or predictions appear that reduce claimed performance to fitted inputs or self-definitions by construction. SOTA claims rest on experimental benchmarks against external baselines, not on renaming or self-referential fitting. The training strategy is a proposed heuristic whose effectiveness is asserted via results rather than tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic data can be used to train precise camera control that transfers to real-world videos after adaptation.
invented entities (2)
-
OmniCAM hybrid dataset
no independent evidence
-
Dual-level Curriculum Co-Training strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025) 6 Y
Bahmani, S., Skorokhodov, I., Qian, G., Siarohin, A., Menapace, W., Tagliasacchi, A., Lindell, D.B., Tulyakov, S.: Ac3d: Analyzing and improving 3d camera con- trol in video diffusion transformers. In: Proceedings of the Computer Vision and Pattern Recognition Conference (2025) 6 Y. Wang et al
2025
-
[2]
ICCV (2025)
Bai,J., Xia, M., Fu, X.,Wang, X.,Mu, L., Cao, J.,Liu, Z., Hu, H., Bai, X., Wan, P., et al.: Recammaster: Camera-controlled generative rendering from a single video. ICCV (2025)
2025
-
[3]
Bai, J., Xia, M., Wang, X., Yuan, Z., Fu, X., Liu, Z., Hu, H., Wan, P., Zhang, D.: Syncammaster: Synchronizing multi-camera video generation from diverse view- points. arXiv preprint arXiv:2412.07760 (2024)
-
[4]
In: Thirty-fifth Con- ference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1) (2021),https://openreview.net/forum?id=tjZjv_qh_CE
Baruch,G.,Chen,Z.,Dehghan,A.,Dimry,T.,Feigin,Y.,Fu,P.,Gebauer,T.,Joffe, B., Kurz, D., Schwartz, A., Shulman, E.: ARKitscenes - a diverse real-world dataset for 3d indoor scene understanding using mobile RGB-d data. In: Thirty-fifth Con- ference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1) (2021),https://openreview.net/f...
2021
-
[5]
Bian, W., Huang, Z., Shi, X., Li, Y., Wang, F.Y., Li, H.: Gs-dit: Advancing video generation with pseudo 4d gaussian fields through efficient dense 3d point tracking. arXiv preprint arXiv:2501.02690 (2025)
-
[6]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review arXiv 2023
-
[7]
OpenAI Blog1(8), 1 (2024)
Brooks, T., Peebles, B., Holmes, C., DePue, W., Guo, Y., Jing, L., Schnurr, D., Taylor, J., Luhman, T., Luhman, E., et al.: Video generation models as world simulators. OpenAI Blog1(8), 1 (2024)
2024
-
[8]
arXiv preprint arXiv:2506.23361 (2025)
Cai,Y.,Zhang,H.,Chen,X.,Xing,J.,Hu,Y.,Zhou,Y.,Zhang,K.,Zhang,Z.,Kim, S.Y., Wang, T., et al.: Omnivcus: Feedforward subject-driven video customization with multimodal control conditions. arXiv preprint arXiv:2506.23361 (2025)
-
[9]
International Conference on 3D Vision (3DV) (2017)
Chang, A., Dai, A., Funkhouser, T., Halber, M., Niessner, M., Savva, M., Song, S., Zeng, A., Zhang, Y.: Matterport3d: Learning from rgb-d data in indoor envi- ronments. International Conference on 3D Vision (3DV) (2017)
2017
-
[10]
In: CVPR (2017)
Dai,A.,Chang,A.X.,Savva,M.,Halber,M.,Funkhouser,T.,Nießner,M.:Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: CVPR (2017)
2017
-
[11]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[12]
arXiv preprint arXiv:2411.06525 , year=
Feng, W., Liu, J., Tu, P., Qi, T., Sun, M., Ma, T., Zhao, S., Zhou, S., He, Q.: I2vcontrol-camera: Precise video camera control with adjustable motion strength. arXiv preprint arXiv:2411.06525 (2024)
-
[13]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Gao, Y., Guo, H., Hoang, T., Huang, W., Jiang, L., Kong, F., Li, H., Li, J., Li, L., Li, X., et al.: Seedance 1.0: Exploring the boundaries of video generation models. arXiv preprint arXiv:2506.09113 (2025)
work page internal anchor Pith review arXiv 2025
-
[14]
In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (2025)
Gu, Z., Yan, R., Lu, J., Li, P., Dou, Z., Si, C., Dong, Z., Liu, Q., Lin, C., Liu, Z., et al.: Diffusion as shader: 3d-aware video diffusion for versatile video generation control. In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (2025)
2025
-
[15]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Guo, Y., Yang, C., Rao, A., Liang, Z., Wang, Y., Qiao, Y., Agrawala, M., Lin, D., Dai, B.: Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725 (2023)
work page internal anchor Pith review arXiv 2023
-
[16]
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: En- ablingcameracontrolfortext-to-videogeneration.arXivpreprintarXiv:2404.02101 (2024) Abbreviated paper title 7
work page internal anchor Pith review arXiv 2024
-
[17]
He, H., Yang, C., Lin, S., Xu, Y., Wei, M., Gui, L., Zhao, Q., Wetzstein, G., Jiang, L., Li, H.: Cameractrl ii: Dynamic scene exploration via camera-controlled video diffusion models. arXiv preprint arXiv:2503.10592 (2025)
-
[18]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Hong, W., Ding, M., Zheng, W., Liu, X., Tang, J.: Cogvideo: Large-scale pretrain- ing for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868 (2022)
work page internal anchor Pith review arXiv 2022
- [19]
-
[20]
In: CVPR (2025)
Jin, W., Dai, Q., Luo, C., Baek, S.H., Cho, S.: Flovd: Optical flow meets video diffusion model for enhanced camera-controlled video synthesis. In: CVPR (2025)
2025
-
[21]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024)
2024
-
[22]
Li, T., Zheng, G., Jiang, R., Zhan, S., Wu, T., Lu, Y., Lin, Y., Deng, C., Xiong, Y., Chen, M., et al.: Realcam-i2v: Real-world image-to-video generation with in- teractive complex camera control. arXiv preprint arXiv:2502.10059 (2025)
-
[23]
In: CVPR (2025)
Li, Z., Tucker, R., Cole, F., Wang, Q., Jin, L., Ye, V., Kanazawa, A., Holynski, A., Snavely, N.: MegaSaM: Accurate, fast and robust structure and motion from casual dynamic videos. In: CVPR (2025)
2025
-
[24]
In: CVPR (2024)
Ling, L., Sheng, Y., Tu, Z., Zhao, W., Xin, C., Wan, K., Yu, L., Guo, Q., Yu, Z., Lu, Y., et al.: Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. In: CVPR (2024)
2024
-
[25]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Luo, Y., Bai, J., Shi, X., Xia, M., Wang, X., Wan, P., Zhang, D., Gai, K., Xue, T.: Camclonemaster: Enabling reference-based camera control for video generation. arXiv preprint arXiv:2506.03140 (2025)
-
[27]
Transactions on Machine Learn- ing Research (2025)
Ma, X., Wang, Y., Chen, X., Jia, G., Liu, Z., Li, Y.F., Chen, C., Qiao, Y.: Latte: Latent diffusion transformer for video generation. Transactions on Machine Learn- ing Research (2025)
2025
-
[28]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[29]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ren, X., Shen, T., Huang, J., Ling, H., Lu, Y., Nimier-David, M., Müller, T., Keller, A., Fidler, S., Gao, J.: Gen3c: 3d-informed world-consistent video gener- ation with precise camera control. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6121–6132 (2025)
2025
-
[30]
In: 2012 IEEE/RSJ international conference on intelligent robots and systems
Sturm, J., Engelhard, N., Endres, F., Burgard, W., Cremers, D.: A benchmark for the evaluation of rgb-d slam systems. In: 2012 IEEE/RSJ international conference on intelligent robots and systems. pp. 573–580. IEEE (2012)
2012
-
[31]
IEEE Transactions on pattern analysis and machine intelligence 13(4), 376–380 (2002)
Umeyama, S.: Least-squares estimation of transformation parameters between two point patterns. IEEE Transactions on pattern analysis and machine intelligence 13(4), 376–380 (2002)
2002
-
[32]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner, T., van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717 (2018)
work page internal anchor Pith review arXiv 2018
-
[33]
In: ECCV
Van Hoorick, B., Wu, R., Ozguroglu, E., Sargent, K., Liu, R., Tokmakov, P., Dave, A., Zheng, C., Vondrick, C.: Generative camera dolly: Extreme monocular dynamic novel view synthesis. In: ECCV. pp. 313–331. Springer (2024)
2024
-
[34]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025) 8 Y. Wang et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Xie, Y., Yao, C.H., Voleti, V., Jiang, H., Jampani, V.: Sv4d: Dynamic 3d con- tent generation with multi-frame and multi-view consistency. arXiv preprint arXiv:2407.17470 (2024)
-
[36]
In: ECCV
Xing,J.,Xia,M.,Zhang,Y.,Chen,H.,Yu,W.,Liu,H.,Liu,G.,Wang,X.,Shan,Y., Wong, T.T.: Dynamicrafter: Animating open-domain images with video diffusion priors. In: ECCV. pp. 399–417. Springer (2024)
2024
-
[37]
Xu, D., Nie, W., Liu, C., Liu, S., Kautz, J., Wang, Z., Vahdat, A.: Camco: Camera-controllable 3d-consistent image-to-video generation. arXiv preprint arXiv:2406.02509 (2024)
-
[38]
Yan, W., Zhang, Y., Abbeel, P., Srinivas, A.: Videogpt: Video generation using vq-vae and transformers (2021)
2021
-
[39]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, L., Kang, B., Huang, Z., Xu, X., Feng, J., Zhao, H.: Depth anything: Un- leashing the power of large-scale unlabeled data. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10371–10381 (2024)
2024
-
[40]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Unic: Unified in-context video editing.arXiv preprint arXiv:2506.04216, 2025
Ye, Z., He, X., Liu, Q., Wang, Q., Wang, X., Wan, P., Zhang, D., Gai, K., Chen, Q., Luo, W.: Unic: Unified in-context video editing. arXiv preprint arXiv:2506.04216 (2025)
-
[42]
arXiv preprint arXiv:2503.05638 (2025) 18 Liu et al
YU, M., Hu, W., Xing, J., Shan, Y.: Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models. arXiv preprint arXiv:2503.05638 (2025)
-
[43]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Yu, W., Xing, J., Yuan, L., Hu, W., Li, X., Huang, Z., Gao, X., Wong, T.T., Shan, Y., Tian, Y.: Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis. arXiv preprint arXiv:2409.02048 (2024)
work page internal anchor Pith review arXiv 2024
-
[44]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, D.J., Paiss, R., Zada, S., Karnad, N., Jacobs, D.E., Pritch, Y., Mosseri, I., Shou, M.Z., Wadhwa, N., Ruiz, N.: Recapture: Generative video camera controls for user-provided videos using masked video fine-tuning. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2050–2062 (2025)
2050
-
[45]
Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N.: Stereo magnification: Learn- ingviewsynthesisusingmultiplaneimages.arXivpreprintarXiv:1805.09817(2018)
work page internal anchor Pith review arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.