Recognition: no theorem link
RoboAgent: Chaining Basic Capabilities for Embodied Task Planning
Pith reviewed 2026-05-10 18:10 UTC · model grok-4.3
The pith
RoboAgent decomposes long-horizon embodied planning into chained basic vision-language sub-problems solved by one VLM through a scheduler that invokes separate capabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RoboAgent implements embodied task planning as a capability-driven pipeline in which a scheduler invokes distinct sub-capabilities inside a single VLM. Each capability solves a narrow vision-language problem, keeps its own context, and either returns intermediate results or issues atomic actions. The entire system is trained with a multi-stage regimen that first clones expert plans, then applies DAgger on self-generated trajectories, and finally optimizes via reinforcement learning; simulator internals supply dense supervision at every stage, augmented by synthetic data for broader coverage.
What carries the argument
The scheduler that selects and activates sub-capabilities, each maintaining independent context inside the single VLM.
If this is right
- Reasoning steps become inspectable because each capability produces explicit intermediate outputs.
- No external planners or tools are required since the scheduler and all capabilities live inside one VLM.
- Multi-stage training with simulator supervision yields policies that succeed on existing embodied planning benchmarks.
- Augmented and synthetic data improve robustness across varied task scenarios.
Where Pith is reading between the lines
- The same decomposition might let VLMs handle other sequential decision domains such as dialogue or software agents without separate modules.
- Real-robot deployment would still require bridging the sim-to-real gap that simulator-only supervision leaves untested.
- Hierarchical planners outside VLMs could adopt the same scheduler-plus-context pattern for better transparency.
Load-bearing premise
That any complex embodied plan can be broken into a sequence of basic vision-language sub-problems that one VLM, trained on simulator-derived data, can reliably chain without external tools or loss of long-horizon coherence.
What would settle it
Performance drop on an embodied benchmark when task horizons exceed the length of training trajectories or when objects and layouts differ from the augmented simulator data.
Figures
















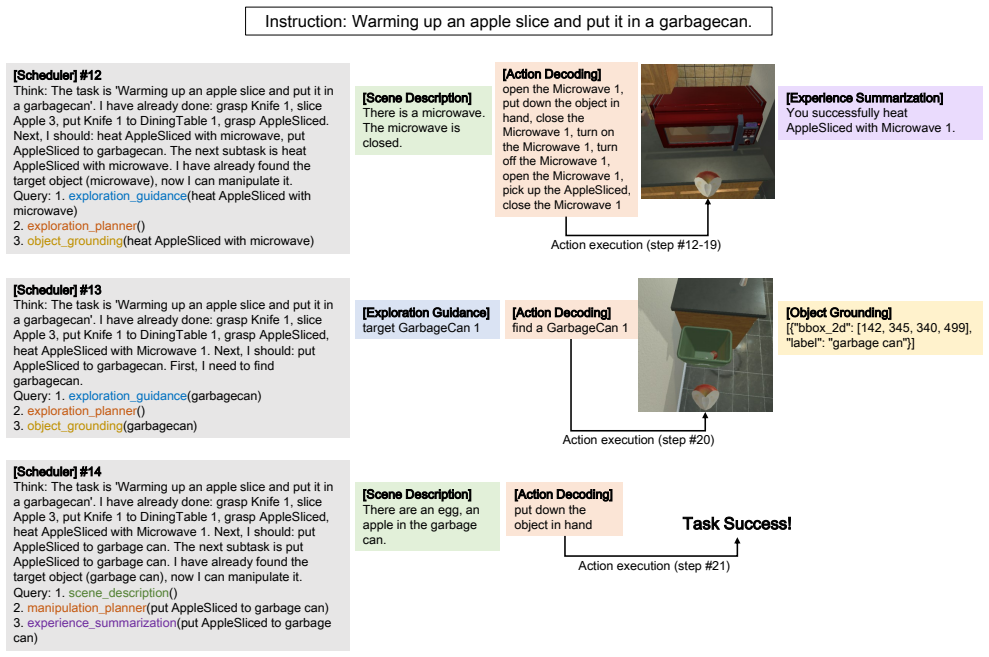


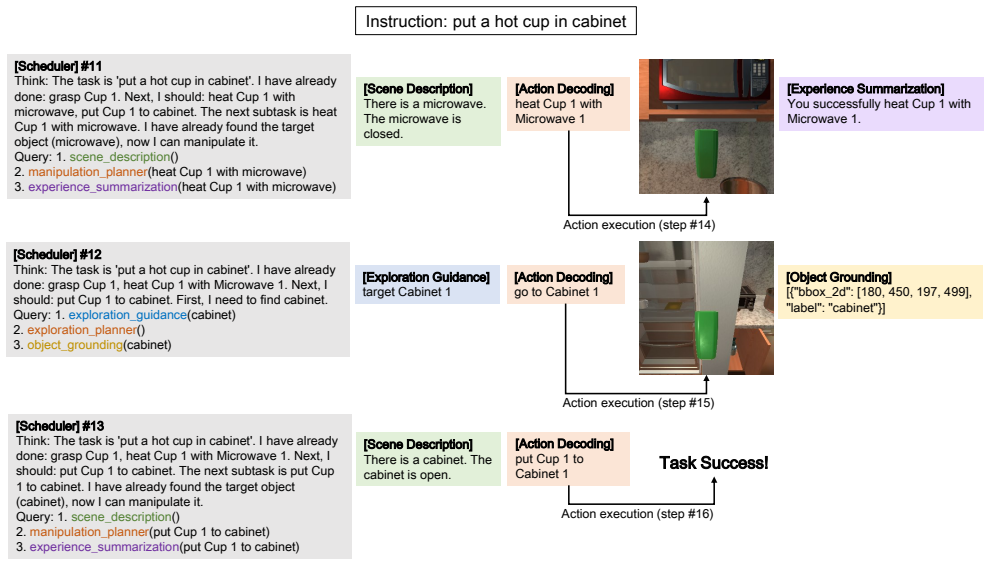

read the original abstract
This paper focuses on embodied task planning, where an agent acquires visual observations from the environment and executes atomic actions to accomplish a given task. Although recent Vision-Language Models (VLMs) have achieved impressive results in multimodal understanding and reasoning, their performance remains limited when applied to embodied planning that involves multi-turn interaction, long-horizon reasoning, and extended context analysis. To bridge this gap, we propose RoboAgent, a capability-driven planning pipeline in which the model actively invokes different sub-capabilities. Each capability maintains its own context, and produces intermediate reasoning results or interacts with the environment according to the query given by a scheduler. This framework decomposes complex planning into a sequence of basic vision-language problems that VLMs can better address, enabling a more transparent and controllable reasoning process. The scheduler and all capabilities are implemented with a single VLM, without relying on external tools. To train this VLM, we adopt a multi-stage paradigm that consists of: (1) behavior cloning with expert plans, (2) DAgger training using trajectories collected by the model, and (3) reinforcement learning guided by an expert policy. Across these stages, we exploit the internal information of the environment simulator to construct high-quality supervision for each capability, and we further introduce augmented and synthetic data to enhance the model's performance in more diverse scenarios. Extensive experiments on widely used embodied task planning benchmarks validate the effectiveness of the proposed approach. Our codes will be available at https://github.com/woyut/RoboAgent_CVPR26.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RoboAgent, a capability-driven planning pipeline for embodied task planning in which a single VLM implements both a scheduler and multiple sub-capabilities. Complex tasks are decomposed into sequences of basic vision-language sub-problems, each maintaining its own context; the model is trained via a three-stage process (behavior cloning on expert plans, DAgger on model-generated trajectories, and RL guided by an expert policy) that exploits simulator internal state to generate supervision, augmented by synthetic data. The authors claim this yields more transparent, controllable reasoning than direct VLM application and validate the approach through extensive experiments on standard embodied task planning benchmarks.
Significance. If the performance claims hold under scrutiny, the work would offer a practical, tool-free route to modular VLM-based planning that could improve transparency and reduce compounding errors in long-horizon robotic tasks. The multi-stage training regimen that derives high-quality per-capability supervision directly from simulator state is a concrete methodological contribution that other embodied VLM efforts could adopt.
major comments (2)
- [§3] §3 (Method), multi-stage training description: the RL stage is described as using simulator-derived rewards and expert-policy guidance, yet no explicit formulation is given for how rewards are computed per capability or how the single-VLM context maintenance prevents drift across chained invocations; this is load-bearing for the claim that decomposition plus training yields reliable long-horizon behavior.
- [§4] §4 (Experiments): the reported results are confined to standard in-distribution benchmarks; no OOD splits (new object layouts, longer task horizons, or unseen environments) or metrics quantifying compounding error across capability chains are presented, leaving the generalization assumption untested despite being central to the abstract's claim of effectiveness on long-horizon embodied planning.
minor comments (2)
- [Abstract / §3] The abstract and method sections use the term 'capability' without a concise definition or enumeration of the exact sub-capabilities implemented; a short table listing them would improve clarity.
- [§4] Figure captions and axis labels in the experimental plots should explicitly state whether error bars represent standard deviation across seeds or across tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions have been made to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method), multi-stage training description: the RL stage is described as using simulator-derived rewards and expert-policy guidance, yet no explicit formulation is given for how rewards are computed per capability or how the single-VLM context maintenance prevents drift across chained invocations; this is load-bearing for the claim that decomposition plus training yields reliable long-horizon behavior.
Authors: We agree that the original description of the RL stage in Section 3 was insufficiently precise. In the revised manuscript we have added explicit per-capability reward formulations that are computed directly from simulator state (binary success indicators for goal-reaching capabilities and continuous distance or contact metrics for manipulation capabilities). We have also clarified the context-maintenance mechanism: the scheduler maintains a per-capability context buffer that is reset at each invocation to contain only the sub-task query, the current visual observation, and the immediately preceding scheduler decision; this design is now formalized with pseudocode and a diagram in the updated Section 3.3. These additions make the long-horizon reliability claim more transparent. revision: yes
-
Referee: [§4] §4 (Experiments): the reported results are confined to standard in-distribution benchmarks; no OOD splits (new object layouts, longer task horizons, or unseen environments) or metrics quantifying compounding error across capability chains are presented, leaving the generalization assumption untested despite being central to the abstract's claim of effectiveness on long-horizon embodied planning.
Authors: We acknowledge that the primary reported results use standard benchmarks. These benchmarks already contain substantial variation in object layouts and task lengths, which we argue provides evidence of robustness within the evaluated domain. To directly respond to the request for compounding-error quantification, the revised experiments section now includes an additional analysis that plots success rate against the number of capability invocations in a chain and reports the rate of error accumulation. We have also added results on extended-horizon variants of the existing tasks. Full OOD splits on entirely novel environments remain outside the scope of the current work and are listed as future work; the multi-stage training procedure is intended to mitigate compounding errors, as supported by the new chain-length analysis. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
This paper presents an empirical systems contribution: a capability-driven planning pipeline implemented via a single VLM, trained in three stages (behavior cloning, DAgger, RL) with simulator-derived supervision and augmented data, then validated on embodied benchmarks. No mathematical derivation, first-principles result, or prediction is claimed that reduces by construction to its inputs. The decomposition into scheduler + capabilities is an architectural design choice, not a self-definitional or fitted-input equivalence. No load-bearing self-citations, uniqueness theorems, or ansatzes smuggled via prior work appear in the abstract or described pipeline. Claims rest on experimental outcomes rather than any closed logical loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- multi-stage training hyperparameters
axioms (1)
- domain assumption Decomposition of embodied planning into basic vision-language sub-problems is sufficient for long-horizon tasks
Forward citations
Cited by 1 Pith paper
-
RoboEvolve: Co-Evolving Planner-Simulator for Robotic Manipulation with Limited Data
A co-evolutionary VLM-VGM loop on 500 unlabeled images raises planner success by 30 points and simulator success by 48 percent while beating fully supervised baselines.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.03342 (2025)
Abbas Abdolmaleki, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas, Ash- win Balakrishna, Nathan Batchelor, Alex Bewley, Jeff Bingham, Michael Bloesch, et al. Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced em- bodied reasoning, thinking, and motion transfer.arXiv preprint arXiv:2510.03342,...
-
[2]
Pddl— the planning domain definition language.Technical Report, Tech
Constructions Aeronautiques, Adele Howe, Craig Knoblock, ISI Drew McDermott, Ashwin Ram, Manuela Veloso, Daniel Weld, David Wilkins Sri, Anthony Barrett, Dave Christianson, et al. Pddl— the planning domain definition language.Technical Report, Tech. Rep., 1998. 2
1998
-
[3]
Mohamed Salim Aissi, Cl ´emence Grislain, Mohamed Chetouani, Olivier Sigaud, Laure Soulier, and Nicolas Thome. Viper: Visual perception and explainable rea- soning for sequential decision-making.arXiv preprint arXiv:2503.15108, 2025. 2
-
[4]
Alisson Azzolini, Junjie Bai, Hannah Brandon, Jiaxin Cao, Prithvijit Chattopadhyay, Huayu Chen, Jinju Chu, Yin Cui, Jenna Diamond, Yifan Ding, et al. Cosmos-reason1: From physical common sense to embodied reasoning.arXiv preprint arXiv:2503.15558, 2025. 3
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Zitong Bo, Yue Hu, Jinming Ma, Mingliang Zhou, Junhui Yin, Yachen Kang, Yuqi Liu, Tong Wu, Diyun Xiang, and Hao Chen. Reinforced embodied planning with verifiable reward for real-world robotic manipulation.arXiv preprint arXiv:2509.25852, 2025. 2
-
[7]
Meghan Booker, Grayson Byrd, Bethany Kemp, Aurora Schmidt, and Corban Rivera. Embodiedrag: Dynamic 3d scene graph retrieval for efficient and scalable robot task planning.arXiv preprint arXiv:2410.23968, 2024. 2
-
[8]
George Bredis, Stanislav Dereka, Viacheslav Sinii, Rus- lan Rakhimov, and Daniil Gavrilov. Enhancing vision- language model training with reinforcement learning in synthetic worlds for real-world success.arXiv preprint arXiv:2508.04280, 2025. 2
-
[9]
Do as i can, not as i say: Grounding language in robotic affordances
Anthony Brohan, Yevgen Chebotar, Chelsea Finn, Karol Hausman, Alexander Herzog, Daniel Ho, Julian Ibarz, Alex Irpan, Eric Jang, Ryan Julian, et al. Do as i can, not as i say: Grounding language in robotic affordances. InConference on robot learning, pages 287–318. PMLR, 2023. 1
2023
-
[10]
Cookbench: A long-horizon embodied planning benchmark for complex cooking scenarios,
Muzhen Cai, Xiubo Chen, Yining An, Jiaxin Zhang, Xuesong Wang, Wang Xu, Weinan Zhang, and Ting Liu. Cookbench: A long-horizon embodied planning bench- mark for complex cooking scenarios.arXiv preprint arXiv:2508.03232, 2025. 3
-
[11]
Partnr: A benchmark for planning and rea- soning in embodied multi-agent tasks
Matthew Chang, Gunjan Chhablani, Alexander Clegg, Mikael Dallaire Cote, Ruta Desai, Michal Hlavac, Vladimir Karashchuk, Jacob Krantz, Roozbeh Mottaghi, Priyam Parashar, et al. Partnr: A benchmark for planning and rea- soning in embodied multi-agent tasks. InThe Thirteenth International Conference on Learning Representations. 3
-
[12]
arXiv preprint arXiv:2510.12693 , year=
Hanyang Chen, Mark Zhao, Rui Yang, Qinwei Ma, Ke Yang, Jiarui Yao, Kangrui Wang, Hao Bai, Zhenhailong Wang, Rui Pan, et al. Era: Transforming vlms into embod- ied agents via embodied prior learning and online reinforce- ment learning.arXiv preprint arXiv:2510.12693, 2025. 2
-
[13]
Self- questioning language models.arXiv preprint arXiv:2508.03682,
Lili Chen, Mihir Prabhudesai, Katerina Fragkiadaki, Hao Liu, and Deepak Pathak. Self-questioning language mod- els.arXiv preprint arXiv:2508.03682, 2025. 3
-
[14]
Scaling autonomous agents via automatic re- ward modeling and planning
Zhenfang Chen, Delin Chen, Rui Sun, Wenjun Liu, and Chuang Gan. Scaling autonomous agents via automatic re- ward modeling and planning. InInternational Conference on Learning Representations, 2025. 3
2025
-
[15]
EmbodiedEval: Evaluate Multimodal LLMs as Embodied Agents.arXiv preprint arXiv:2501.11858, 2025
Zhili Cheng, Yuge Tu, Ran Li, Shiqi Dai, Jinyi Hu, Shengding Hu, Jiahao Li, Yang Shi, Tianyu Yu, Weize Chen, et al. Embodiedeval: Evaluate multimodal llms as embodied agents.arXiv preprint arXiv:2501.11858, 2025. 3
-
[16]
Instructflow: Adaptive symbolic constraint-guided code generation for long-horizon plan- ning
Haotian Chi, Zeyu Feng, Yueming Lyu, Chengqi Zheng, Linbo Luo, Yew-Soon Ong, Ivor Tsang, Hechang Chen, Yi Chang, and Haiyan Yin. Instructflow: Adaptive symbolic constraint-guided code generation for long-horizon plan- ning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 3
2025
-
[17]
Lota-bench: Benchmarking language-oriented task planners for embodied agents
Jae-Woo Choi, Youngwoo Yoon, Hyobin Ong, Jaehong Kim, and Minsu Jang. Lota-bench: Benchmarking language-oriented task planners for embodied agents. In The Twelfth International Conference on Learning Repre- sentations, 2024. 6, 8, 7
2024
-
[18]
Reactree: Hierar- chical task planning with dynamic tree expansion using llm agent nodes
Jae-Woo Choi, Hyungmin Kim, Hyobin Ong, Youngwoo Yoon, Minsu Jang, Jaehong Kim, et al. Reactree: Hierar- chical task planning with dynamic tree expansion using llm agent nodes. 2025. 3
2025
-
[19]
Textworld: A learning environment for text-based games
Marc-Alexandre C ˆot´e, ´Akos K ´ad´ar, Xingdi Yuan, Ben Kybartas, Tavian Barnes, Emery Fine, James Moore, Matthew Hausknecht, Layla El Asri, Mahmoud Adada, et al. Textworld: A learning environment for text-based games. InWorkshop on Computer Games, pages 41–75. Springer, 2018. 6
2018
-
[20]
Enhanc- ing decision-making of large language models via actor- critic
Heng Dong, Kefei Duan, and Chongjie Zhang. Enhanc- ing decision-making of large language models via actor- critic. InForty-second International Conference on Ma- chine Learning, 2025. 3, 7
2025
-
[21]
Plan-and-act: Improving planning of agents for long-horizon tasks
Lutfi Eren Erdogan, Hiroki Furuta, Sehoon Kim, Nicholas Lee, Suhong Moon, Gopala Anumanchipalli, Kurt Keutzer, and Amir Gholami. Plan-and-act: Improving planning of agents for long-horizon tasks. InForty-second Interna- tional Conference on Machine Learning. 3
-
[22]
Robix: A unified model for robot interaction, reasoning and planning
Huang Fang, Mengxi Zhang, Heng Dong, Wei Li, Zixuan Wang, Qifeng Zhang, Xueyun Tian, Yucheng Hu, and Hang Li. Robix: A unified model for robot interaction, reasoning and planning.arXiv preprint arXiv:2509.01106, 2025. 3
-
[23]
arXiv preprint arXiv:2506.23127 (2025)
Zhaoye Fei, Li Ji, Siyin Wang, Junhao Shi, Jingjing Gong, and Xipeng Qiu. Unleashing embodied task planning abil- ity in llms via reinforcement learning.arXiv preprint arXiv:2506.23127, 2025. 3
-
[24]
Towards efficient online tuning of VLM agents via counterfactual soft reinforcement learning
Lang Feng, Weihao Tan, Zhiyi Lyu, Longtao Zheng, Haiyang Xu, Ming Yan, Fei Huang, and Bo An. Towards efficient online tuning of VLM agents via counterfactual soft reinforcement learning. InForty-second International Conference on Machine Learning, 2025. 7
2025
-
[25]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training. arXiv preprint arXiv:2505.10978, 2025. 3, 7, 9, 10
work page internal anchor Pith review arXiv 2025
-
[26]
Maria Fox and Derek Long. Pddl2. 1: An extension to pddl for expressing temporal planning domains.Journal of arti- ficial intelligence research, 20:61–124, 2003. 2
2003
-
[27]
What can VLMs do for zero-shot embodied task planning? InICML 2024 Work- shop on LLMs and Cognition, 2024
Xian Fu, Min Zhang, Jianye HAO, Peilong Han, Hao Zhang, Lei Shi, and Hongyao Tang. What can VLMs do for zero-shot embodied task planning? InICML 2024 Work- shop on LLMs and Cognition, 2024. 3
2024
-
[28]
Visual program- ming: Compositional visual reasoning without training
Tanmay Gupta and Aniruddha Kembhavi. Visual program- ming: Compositional visual reasoning without training. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 14953–14962, 2023. 2
2023
-
[29]
The ff planning sys- tem: Fast plan generation through heuristic search.Journal of Artificial Intelligence Research, 14:253–302, 2001
J ¨org Hoffmann and Bernhard Nebel. The ff planning sys- tem: Fast plan generation through heuristic search.Journal of Artificial Intelligence Research, 14:253–302, 2001. 2
2001
-
[30]
Yining Hong, Rui Sun, Bingxuan Li, Xingcheng Yao, Maxine Wu, Alexander Chien, Da Yin, Ying Nian Wu, Zhecan James Wang, and Kai-Wei Chang. Embodied web agents: Bridging physical-digital realms for integrated agent intelligence.arXiv preprint arXiv:2506.15677, 2025. 2
-
[31]
Tree-planner: Efficient close-loop task planning with large language models
Mengkang Hu, Yao Mu, Xinmiao Chelsey Yu, Mingyu Ding, Shiguang Wu, Wenqi Shao, Qiguang Chen, Bin Wang, Yu Qiao, and Ping Luo. Tree-planner: Efficient close-loop task planning with large language models. In The Twelfth International Conference on Learning Repre- sentations. 2
-
[32]
Look before you leap: Unveiling the power of gpt-4v in robotic vision-language planning,
Yingdong Hu, Fanqi Lin, Tong Zhang, Li Yi, and Yang Gao. Look before you leap: Unveiling the power of gpt- 4v in robotic vision-language planning.arXiv preprint arXiv:2311.17842, 2023. 2
-
[33]
ESCA: Contextualizing embodied agents via scene-graph generation
Jiani Huang, Amish Sethi, Matthew Kuo, Mayank Keoliya, Neelay Velingker, JungHo Jung, Ser-Nam Lim, Ziyang Li, and Mayur Naik. ESCA: Contextualizing embodied agents via scene-graph generation. InThe Thirty-ninth An- nual Conference on Neural Information Processing Sys- tems, 2025. 2
2025
-
[34]
Language models as zero-shot planners: Ex- tracting actionable knowledge for embodied agents
Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Ex- tracting actionable knowledge for embodied agents. InIn- ternational conference on machine learning, pages 9118–
-
[35]
Fine- tuning with rag for improving llm learning of new skills
Humaid Ibrahim, Nikolai Rozanov, and Marek Rei. Fine- tuning with rag for improving llm learning of new skills. arXiv preprint arXiv:2510.01375, 2025. 3
-
[36]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mo- hith Mothukuri, Suraj Nair, Karl Pert...
2025
-
[37]
Robobrain: A unified brain model for robotic manipulation from abstract to concrete
Yuheng Ji, Huajie Tan, Jiayu Shi, Xiaoshuai Hao, Yuan Zhang, Hengyuan Zhang, Pengwei Wang, Mengdi Zhao, Yao Mu, Pengju An, et al. Robobrain: A unified brain model for robotic manipulation from abstract to concrete. InProceedings of the Computer Vision and Pattern Recog- nition Conference, pages 1724–1734, 2025. 3
2025
-
[38]
Tcpo: Thought-centric preference optimization for effective embodied decision-making
Kechen Jiao, Zhirui Fang, Jiahao Liu, Bei Li, Qifan Wang, Xinyu Liu, Junhao Ruan, Zhongjian Qiao, Yifan Zhu, Yaxin Xu, et al. Tcpo: Thought-centric preference optimization for effective embodied decision-making. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9585–9599, 2025. 3, 7
2025
-
[39]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search- r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
-
[40]
Lm2: A simple society of language models solves complex reasoning
Gurusha Juneja, Subhabrata Dutta, and Tanmoy Chakraborty. Lm2: A simple society of language models solves complex reasoning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 16473–16484, 2024. 3
2024
-
[41]
Hierar- chical task and motion planning in the now
Leslie Pack Kaelbling and Tom ´as Lozano-P ´erez. Hierar- chical task and motion planning in the now. In2011 IEEE international conference on robotics and automation, pages 1470–1477. IEEE, 2011. 2
2011
-
[42]
Approximately optimal approximate reinforcement learning
Sham Kakade and John Langford. Approximately optimal approximate reinforcement learning. InProceedings of the nineteenth international conference on machine learning, pages 267–274, 2002. 5, 8
2002
-
[43]
Gflowvlm: Enhancing multi-step reasoning in vision-language models with generative flow networks
Haoqiang Kang, Enna Sachdeva, Piyush Gupta, Sangjae Bae, and Kwonjoon Lee. Gflowvlm: Enhancing multi-step reasoning in vision-language models with generative flow networks. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 3815–3825, 2025. 7
2025
-
[44]
Viki-r: Multi-agent cooperation via rl,
Li Kang, Xiufeng Song, Heng Zhou, Yiran Qin, Jie Yang, Xiaohong Liu, Philip Torr, Lei Bai, and Zhenfei Yin. Viki- r: Coordinating embodied multi-agent cooperation via re- inforcement learning.arXiv preprint arXiv:2506.09049,
-
[45]
Probabilistic roadmaps for path planning in high-dimensional configuration spaces.IEEE transactions on Robotics and Automation, 12(4):566–580, 2002
Lydia E Kavraki, Petr Svestka, J-C Latombe, and Mark H Overmars. Probabilistic roadmaps for path planning in high-dimensional configuration spaces.IEEE transactions on Robotics and Automation, 12(4):566–580, 2002. 2
2002
-
[46]
Bosung Kim and Prithviraj Ammanabrolu. Beyond nee- dle (s) in the embodied haystack: Environment, architec- ture, and training considerations for long context reasoning. arXiv preprint arXiv:2505.16928, 2025. 3
-
[47]
Context-aware planning and environment-aware memory for instruction following em- bodied agents
Byeonghwi Kim, Jinyeon Kim, Yuyeong Kim, Cheolhong Min, and Jonghyun Choi. Context-aware planning and environment-aware memory for instruction following em- bodied agents. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 10936– 10946, 2023. 6
2023
-
[48]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli Vander- Bilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474, 2017. 6, 1
work page internal anchor Pith review arXiv 2017
-
[49]
Rapidly-exploring random trees: A new tool for path planning.Research Report 9811, 1998
Steven LaValle. Rapidly-exploring random trees: A new tool for path planning.Research Report 9811, 1998. 2
1998
-
[50]
Robomemory: A brain-inspired multi-memory agentic framework for life- long learning in physical embodied systems.arXiv e-prints, pages arXiv–2508, 2025
Mingcong Lei, Honghao Cai, Binbin Que, Zezhou Cui, Liangchen Tan, Junkun Hong, Gehan Hu, Shuangyu Zhu, Yimou Wu, Shaohan Jiang, et al. Robomemory: A brain-inspired multi-memory agentic framework for life- long learning in physical embodied systems.arXiv e-prints, pages arXiv–2508, 2025. 2
2025
-
[51]
Mingcong Lei, Ge Wang, Yiming Zhao, Zhixin Mai, Qing Zhao, Yao Guo, Zhen Li, Shuguang Cui, Yatong Han, and Jinke Ren. Clea: Closed-loop embodied agent for enhanc- ing task execution in dynamic environments.arXiv preprint arXiv:2503.00729, 2025. 2
-
[52]
Closed-loop long-horizon robotic planning via equilibrium sequence modeling
Jinghan Li, Zhicheng Sun, et al. Closed-loop long-horizon robotic planning via equilibrium sequence modeling. In Forty-second International Conference on Machine Learn- ing. 2
-
[53]
Muep: a multimodal benchmark for em- bodied planning with foundation models
Kanxue Li, Baosheng Yu, Qi Zheng, Yibing Zhan, Yuhui Zhang, Tianle Zhang, Yijun Yang, Yue Chen, Lei Sun, Qiong Cao, et al. Muep: a multimodal benchmark for em- bodied planning with foundation models. InProceedings of the Thirty-Third International Joint Conference on Arti- ficial Intelligence, pages 129–138, 2024. 3, 6
2024
-
[54]
Pre-trained language models for interactive decision-making
Shuang Li, Xavier Puig, Chris Paxton, Yilun Du, Clinton Wang, Linxi Fan, Tao Chen, De-An Huang, Ekin Aky¨urek, Anima Anandkumar, et al. Pre-trained language models for interactive decision-making. pages 31199–31212, 2022. 2
2022
-
[55]
Xinran Li, Chenjia Bai, Zijian Li, Jiakun Zheng, Ting Xiao, and Jun Zhang. Learn as individuals, evolve as a team: Multi-agent llms adaptation in embodied environ- ments.arXiv preprint arXiv:2506.07232, 2025. 2
-
[56]
arXiv preprint arXiv:2510.21618 , year=
Xiaoxi Li, Wenxiang Jiao, Jiarui Jin, Guanting Dong, Jia- jie Jin, Yinuo Wang, Hao Wang, Yutao Zhu, Ji-Rong Wen, Yuan Lu, et al. Deepagent: A general reasoning agent with scalable toolsets.arXiv preprint arXiv:2510.21618, 2025. 3
-
[57]
Ziyue Li, Yuan Chang, Gaihong Yu, and Xiaoqiu Le. Hiplan: Hierarchical planning for llm-based agents with adaptive global-local guidance.arXiv preprint arXiv:2508.19076, 2025. 3
-
[58]
Xiwen Liang, Min Lin, Weiqi Ruan, Rongtao Xu, Yuecheng Liu, Jiaqi Chen, Bingqian Lin, Yuzheng Zhuang, and Xiaodan Liang. Structured preference optimization for vision-language long-horizon task planning.arXiv preprint arXiv:2502.20742, 2025. 3
-
[59]
arXiv preprint arXiv:2510.14828 , year=
Jinrui Liu, Bingyan Nie, Boyu Li, Yaran Chen, Yuze Wang, Shunsen He, and Haoran Li. Robogpt-r1: Enhancing robot planning with reinforcement learning.arXiv preprint arXiv:2510.14828, 2025. 7, 8
-
[60]
Jie Liu, Pan Zhou, Yingjun Du, Ah-Hwee Tan, Cees G. M. Snoek, Jan-Jakob Sonke, and Efstratios Gavves. Capo: Co- operative plan optimization for efficient embodied multi- agent cooperation. InThe Thirteenth International Confer- ence on Learning Representations, 2025. 2
2025
-
[61]
Visualagentbench: Towards large multimodal models as visual foundation agents
Xiao Liu, Tianjie Zhang, Yu Gu, Iat Long Iong, Song XiXuan, Yifan Xu, Shudan Zhang, Hanyu Lai, Jiadai Sun, Xinyue Yang, Yu Yang, Zehan Qi, Shuntian Yao, Xueqiao Sun, Siyi Cheng, Qinkai Zheng, Hao Yu, Hanchen Zhang, Wenyi Hong, Ming Ding, Lihang Pan, Xiaotao Gu, Aohan Zeng, Zhengxiao Du, Chan Hee Song, Yu Su, Yuxiao Dong, and Jie Tang. Visualagentbench: To...
2025
-
[62]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025. 8
work page internal anchor Pith review arXiv 2025
-
[63]
Zhichen Lou, Kechun Xu, Zhongxiang Zhou, and Rong Xiong. Explorevlm: Closed-loop robot exploration task planning with vision-language models.arXiv preprint arXiv:2508.11918, 2025. 2, 3
-
[64]
Keer Lu, Chong Chen, Bin Cui, Huang Leng, and Wentao Zhang. Pilotrl: Training language model agents via global planning-guided progressive reinforcement learning.arXiv preprint arXiv:2508.00344, 2025. 3
-
[65]
Yulin Luo, Chun-Kai Fan, Menghang Dong, Jiayu Shi, Mengdi Zhao, Bo-Wen Zhang, Cheng Chi, Jiaming Liu, Gaole Dai, Rongyu Zhang, et al. Robobench: A com- prehensive evaluation benchmark for multimodal large language models as embodied brain.arXiv preprint arXiv:2510.17801, 2025. 3
-
[66]
FILM: Following instructions in language with modular methods
So Yeon Min, Devendra Singh Chaplot, Pradeep Ku- mar Ravikumar, Yonatan Bisk, and Ruslan Salakhutdinov. FILM: Following instructions in language with modular methods. InInternational Conference on Learning Rep- resentations, 2022. 6
2022
-
[67]
Embodiedgpt: Vision-language pre-training via embodied chain of thought.Advances in Neural Informa- tion Processing Systems, 36:25081–25094, 2023
Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, and Ping Luo. Embodiedgpt: Vision-language pre-training via embodied chain of thought.Advances in Neural Informa- tion Processing Systems, 36:25081–25094, 2023. 3
2023
-
[68]
Embodied arena: A comprehensive, unified, and evolving evaluation platform for embodied ai
Fei Ni, Min Zhang, Pengyi Li, Yifu Yuan, Lingfeng Zhang, Yuecheng Liu, Peilong Han, Longxin Kou, Shaojin Ma, Jin- bin Qiao, et al. Embodied arena: A comprehensive, unified, and evolving evaluation platform for embodied ai.arXiv preprint arXiv:2509.15273, 2025. 3
-
[69]
Maithili Patel, Xavier Puig, Ruta Desai, Roozbeh Mottaghi, Sonia Chernova, Joanne Truong, and Akshara Rai. Adapt: Actively discovering and adapting to preferences for any task.arXiv preprint arXiv:2504.04040, 2025. 3
-
[70]
Virtualhome: Simulating household activities via programs
Xavier Puig, Kevin Ra, Marko Boben, Jiaman Li, Tingwu Wang, Sanja Fidler, and Antonio Torralba. Virtualhome: Simulating household activities via programs. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 8494–8502, 2018. 6, 7
2018
-
[71]
Watch-and-help: A challenge for social per- ception and human-ai collaboration
Xavier Puig, Tianmin Shu, Shuang Li, Zilin Wang, Yuan- Hong Liao, Joshua B Tenenbaum, Sanja Fidler, and Anto- nio Torralba. Watch-and-help: A challenge for social per- ception and human-ai collaboration. InInternational Con- ference on Learning Representations, 2021. 6
2021
-
[72]
Pranav Putta, Edmund Mills, Naman Garg, Sumeet Mot- wani, Chelsea Finn, Divyansh Garg, and Rafael Rafailov. Agent q: Advanced reasoning and learning for autonomous ai agents.arXiv preprint arXiv:2408.07199, 2024. 3
-
[73]
Bear: Benchmarking and enhancing mul- timodal language models for atomic embodied capabilities
Yu Qi, Haibo Zhao, Ziyu Guo, Siyuan Ma, Ziyan Chen, Yaokun Han, Renrui Zhang, Zitiantao Lin, Shiji Xin, Yi- jian Huang, et al. Bear: Benchmarking and enhancing mul- timodal language models for atomic embodied capabilities. arXiv preprint arXiv:2510.08759, 2025. 3
-
[74]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023. 3
2023
-
[75]
Planning with large language models via corrective re-prompting
Shreyas Sundara Raman, Vanya Cohen, Eric Rosen, Ifrah Idrees, David Paulius, and Stefanie Tellex. Planning with large language models via corrective re-prompting. In NeurIPS 2022 Foundation Models for Decision Making Workshop, 2022. 2
2022
-
[76]
Cape: Corrective actions from precondition er- rors using large language models
Shreyas Sundara Raman, Vanya Cohen, Ifrah Idrees, Eric Rosen, Raymond Mooney, Stefanie Tellex, and David Paulius. Cape: Corrective actions from precondition er- rors using large language models. In2024 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 14070–14077. IEEE, 2024. 2
2024
-
[77]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Lin- guistics, 2019. 7
2019
-
[78]
A reduction of imitation learning and structured prediction to no-regret online learning
St ´ephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the four- teenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Con- ference Proceedings, 2011. 2, 5
2011
-
[79]
Vlm agents generate their own memories: Distilling experience into embodied programs of thought.Advances in Neural Information Processing Systems, 37:75942–75985, 2024
Gabriel Sarch, Lawrence Jang, Michael Tarr, William W Cohen, Kenneth Marino, and Katerina Fragkiadaki. Vlm agents generate their own memories: Distilling experience into embodied programs of thought.Advances in Neural Information Processing Systems, 37:75942–75985, 2024. 2
2024
-
[80]
Toolformer: Lan- guage models can teach themselves to use tools.Ad- vances in Neural Information Processing Systems, 36: 68539–68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dess `ı, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Lan- guage models can teach themselves to use tools.Ad- vances in Neural Information Processing Systems, 36: 68539–68551, 2023. 2
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.