Understanding Goal Generalisation in Sequential Reinforcement Learning
Pith reviewed 2026-05-25 04:47 UTC · model grok-4.3
The pith
Latent policy gradients simulate low-dimensional variables to predict how sequentially trained RL agents will generalize goals to new environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Latent policy gradients predicts what out-of-distribution behaviour a training pipeline will likely induce by simulating the evolution of low-dimensional latent variables during training according to what would achieve high reward on the training objective with respect to a simple model of how the latent variables map to behaviour.
What carries the argument
Latent policy gradients, which simulates the evolution of low-dimensional latent variables to maximize training rewards under a simple behavior-mapping model.
If this is right
- Out-of-distribution agent behavior depends on the entire sequential training pipeline rather than only the final task.
- Goals learned early can persist and continue to influence goals acquired later.
- Salient environmental features determine which behaviors generalize to novel settings.
- The dependence of generalization on training history has an underlying structure that latent policy gradients can capture.
- A developmental perspective on goal generalization becomes feasible once training pipelines are modeled explicitly.
Where Pith is reading between the lines
- Training pipelines could be designed deliberately to suppress or encourage particular forms of goal generalization.
- The same latent-variable simulation approach might extend to studying generalization in other sequential learning domains.
- If the simple mapping model remains adequate, extensive empirical testing of each new pipeline may become unnecessary.
- The persistence of early goals suggests parallels with developmental processes where initial experiences constrain later learning.
Load-bearing premise
A simple model of how low-dimensional latent variables map to behavior is sufficient to simulate the actual evolution of an agent's policy during sequential training.
What would settle it
Running agents on new sequential training pipelines and finding that their actual out-of-distribution behaviors diverge systematically from the predictions made by latent policy gradients.
Figures









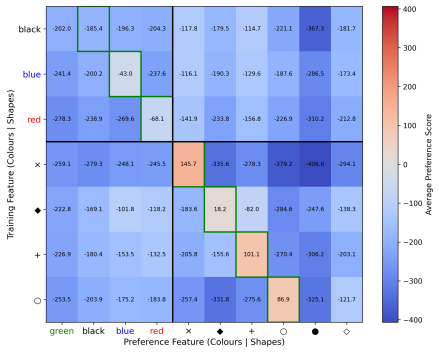

















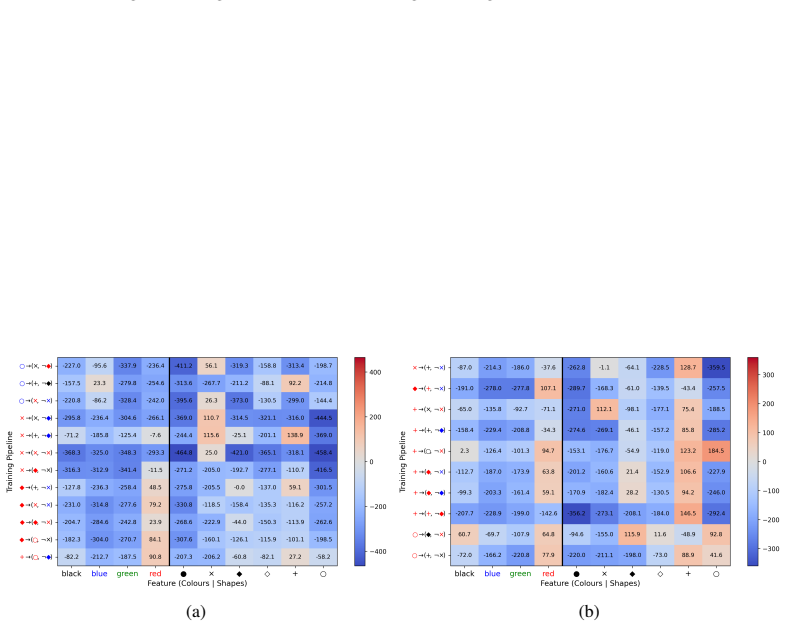
read the original abstract
Reinforcement learning agents often exhibit unintended goal-directed behaviour outside their training distribution, but we currently lack a principled understanding of how such agents will generalise to novel environments based on their training history. We address this gap for agents trained sequentially on one or more tasks. We study over 100 sequential training pipelines, evaluating behaviour across over 250 out-of-distribution environments. We find that salient features drive generalisation, and that goals learnt early in training can persist and influence those acquired later. To explain these phenomena, we introduce latent policy gradients, a method that predicts what out-of-distribution behaviour a training pipeline will likely induce. Our method simulates the evolution of low-dimensional latent variables during training according to what would achieve high reward on the training objective with respect to a simple model of how the latent variables map to behaviour. It achieves strong predictive accuracy, generalises to unseen types of training pipeline, and is interpretable. Our findings demonstrate that while out-of-distribution RL agent behaviour is dependent on the whole training pipeline, this dependence has an underlying structure we can capture, laying groundwork for understanding goal generalisation from a developmental perspective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines goal generalisation in sequential reinforcement learning agents by studying over 100 training pipelines across more than 250 out-of-distribution environments. It reports that salient features drive generalisation and that goals acquired early in training can persist and influence later ones. To explain these observations, the authors introduce latent policy gradients: a forward simulation that evolves low-dimensional latent variables during training by maximising reward on the training objective under a simple model of how those latents map to behaviour. The method is claimed to achieve strong predictive accuracy for OOD behaviour, to generalise to unseen pipeline types, and to remain interpretable.
Significance. If the central claims hold, the work offers a structured, developmental account of how training history shapes out-of-distribution goal-directed behaviour in RL, which is relevant to AI safety and reliability. The scale of the empirical study (100+ pipelines, 250+ environments) and the emphasis on interpretability are strengths. A method that predicts OOD outcomes from training dynamics without being directly fitted to those outcomes would constitute a useful contribution if the underlying modelling assumptions are shown to be sufficient.
major comments (2)
- [latent policy gradients method description] The predictive claims rest on the assumption that a simple model of latent-to-behaviour mapping is sufficient to simulate actual policy evolution under sequential training. This assumption is load-bearing for both the reported accuracy and the generalisation to unseen pipelines, yet the manuscript provides no ablations against full high-dimensional policy-gradient baselines, no analysis of identifiability of the chosen latents, and no quantification of omitted non-linear or history-dependent effects.
- [Abstract] The abstract asserts 'strong predictive accuracy' and generalisation to unseen pipeline types, but the provided text contains no quantitative metrics, error bars, baseline comparisons, or cross-validation details that would allow assessment of these claims. Without such evidence the central empirical result cannot be evaluated.
minor comments (2)
- Notation for the latent variables and the simple mapping function should be introduced with explicit equations and a clear statement of what is assumed versus what is learned.
- The manuscript would benefit from a dedicated limitations section that discusses the scope of the simple mapping model and the conditions under which the simulation may diverge from true policy updates.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We respond to each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [latent policy gradients method description] The predictive claims rest on the assumption that a simple model of latent-to-behaviour mapping is sufficient to simulate actual policy evolution under sequential training. This assumption is load-bearing for both the reported accuracy and the generalisation to unseen pipelines, yet the manuscript provides no ablations against full high-dimensional policy-gradient baselines, no analysis of identifiability of the chosen latents, and no quantification of omitted non-linear or history-dependent effects.
Authors: We acknowledge that the manuscript does not contain ablations against full high-dimensional policy-gradient baselines, formal identifiability analysis of the latents, or explicit quantification of omitted non-linear or history-dependent effects. The low-dimensional latent representation was selected to enable interpretability while capturing the dominant dynamics observed across the 100+ pipelines. The reported predictive accuracy is measured on held-out pipelines and environments, but we agree that direct comparisons to higher-dimensional alternatives would better substantiate the sufficiency of the simple mapping. In revision we will add an ablation section comparing the latent model to a full-dimensional simulation where computationally feasible, include a discussion of modeling assumptions and potential omitted effects, and qualify the generalisation claims accordingly. revision: yes
-
Referee: [Abstract] The abstract asserts 'strong predictive accuracy' and generalisation to unseen pipeline types, but the provided text contains no quantitative metrics, error bars, baseline comparisons, or cross-validation details that would allow assessment of these claims. Without such evidence the central empirical result cannot be evaluated.
Authors: The abstract is a high-level summary; the quantitative metrics (predictive accuracy with error bars, baseline comparisons, and cross-validation across pipeline types) appear in the experimental results sections of the full manuscript. To address the concern, we will revise the abstract to include a brief reference to the evaluation scale and the nature of the reported accuracy while ensuring all claims remain fully supported by the main text. revision: partial
Circularity Check
No significant circularity; derivation is a forward simulation independent of target OOD outcomes
full rationale
The paper's central method (latent policy gradients) is presented as a simulation of low-dimensional latent evolution driven by reward maximization on the training objective, using an explicit simple model of latent-to-behavior mapping. This construction is not equivalent by definition to the OOD predictions it generates, nor does the provided text rely on self-citations, fitted parameters renamed as predictions, or ansatzes imported from prior work. The derivation chain remains self-contained as a modeling approach whose validity rests on empirical predictive accuracy rather than tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pieter Abbeel and Andrew Y. Ng. Apprenticeship learning via inverse reinforcement learning. In Twenty-first international conference on Machine learning - ICML '04 , page 1, Banff, Alberta, Canada, 2004. ACM Press. doi:10.1145/1015330.1015430. URL http://portal.acm.org/citation.cfm?doid=1015330.1015430
-
[2]
Stephen Adams, Tyler Cody, and Peter A. Beling. A survey of inverse reinforcement learning. Artificial Intelligence Review, 55 0 (6): 0 4307--4346, August 2022. ISSN 0269-2821, 1573-7462. doi:10.1007/s10462-021-10108-x. URL https://link.springer.com/10.1007/s10462-021-10108-x
-
[3]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete Problems in AI Safety , July 2016. URL http://arxiv.org/abs/1606.06565. arXiv:1606.06565 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, Eric Winsor, Jerome Wynne, Yarin Gal, and Xander Davies. AgentHarm : A Benchmark for Measuring Harmfulness of LLM Agents , April 2025. URL http://arxiv.org/abs/2410.09024. arXiv:2410.09024 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Claude’s Character , August 2024
Anthropic. Claude’s Character , August 2024. URL https://www.anthropic.com/research/claude-character
work page 2024
-
[6]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, K...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Mechanistic Interpretability for AI Safety -- A Review
Leonard Bereska and Efstratios Gavves. Mechanistic Interpretability for AI Safety -- A Review , August 2024. URL http://arxiv.org/abs/2404.14082. arXiv:2404.14082 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Weird generalization and inductive backdoors: New ways to corrupt llms
Jan Betley, Jorio Cocola, Dylan Feng, James Chua, Andy Arditi, Anna Sztyber-Betley, and Owain Evans. Weird generalization and inductive backdoors: New ways to corrupt llms. arXiv preprint arXiv:2512.09742, 2025
-
[10]
Emergent Misalignment : Narrow finetuning can produce broadly misaligned LLMs
Jan Betley, Daniel Tan, Niels Warncke, Anna Sztyber-Betley, Xuchan Bao, Martín Soto, Nathan Labenz, and Owain Evans. Emergent Misalignment : Narrow finetuning can produce broadly misaligned LLMs . Nature, 649 0 (8097): 0 584--589, January 2026. ISSN 0028-0836, 1476-4687. doi:10.1038/s41586-025-09937-5. URL http://arxiv.org/abs/2502.17424. arXiv:2502.17424 [cs]
-
[11]
Ralph Allan Bradley and Milton E. Terry. Rank Analysis of Incomplete Block Designs : I . The Method of Paired Comparisons . Biometrika, 39 0 (3/4): 0 324, December 1952. ISSN 00063444. doi:10.2307/2334029. URL https://www.jstor.org/stable/2334029?origin=crossref
-
[12]
Brown, Carl Henrik Ek, and Robert D
Jason R. Brown, Carl Henrik Ek, and Robert D. Mullins. Learning from Preferences and Mixed Demonstrations in General Settings , August 2025. URL http://arxiv.org/abs/2508.14027. arXiv:2508.14027 [cs]
-
[13]
Deep Reinforcement Learning from Human Preferences
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep Reinforcement Learning from Human Preferences . In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems , volume 30. Curran Associates, Inc., 2017. URL https://proceed...
work page 2017
-
[14]
Quantifying Generalization in Reinforcement Learning
Karl Cobbe, Oleg Klimov, Chris Hesse, Taehoon Kim, and John Schulman. Quantifying Generalization in Reinforcement Learning , July 2019. URL http://arxiv.org/abs/1812.02341. arXiv:1812.02341 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[15]
Leveraging Procedural Generation to Benchmark Reinforcement Learning , July 2020
Karl Cobbe, Christopher Hesse, Jacob Hilton, and John Schulman. Leveraging Procedural Generation to Benchmark Reinforcement Learning , July 2020. URL http://arxiv.org/abs/1912.01588. arXiv:1912.01588 [cs]
-
[16]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-09422-z 2025
-
[17]
Loss of plasticity in deep continual learning
Shibhansh Dohare, J Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A Rupam Mahmood, and Richard S Sutton. Loss of plasticity in deep continual learning. Nature, 632 0 (8026): 0 768--774, 2024. ISSN 0028-0836
work page 2024
-
[18]
Jan Dubiński, Jan Betley, Anna Sztyber-Betley, Daniel Tan, and Owain Evans. Conditional misalignment: common interventions can hide emergent misalignment behind contextual triggers, 2026. URL https://arxiv.org/abs/2604.25891. \_eprint: 2604.25891
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Arpad E. Elo. The rating of chessplayers, past and present. Ishi Press International, Bronx, NY, 2. print edition, 2008. ISBN 978-0-923891-27-5
work page 2008
-
[20]
Reuben Feinman and Brenden M. Lake. Learning Inductive Biases with Simple Neural Networks , June 2018. URL http://arxiv.org/abs/1802.02745. arXiv:1802.02745 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
Foundation models in robotics: Applications , challenges, and the future
Roya Firoozi, Johnathan Tucker, Stephen Tian, Anirudha Majumdar, Jiankai Sun, Weiyu Liu, Yuke Zhu, Shuran Song, Ashish Kapoor, Karol Hausman, Brian Ichter, Danny Driess, Jiajun Wu, Cewu Lu, and Mac Schwager. Foundation models in robotics: Applications , challenges, and the future. The International Journal of Robotics Research, 44 0 (5): 0 701--739, April...
-
[22]
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2 0 (11): 0 665--673, November 2020. ISSN 2522-5839. doi:10.1038/s42256-020-00257-z. URL https://www.nature.com/articles/s42256-020-00257-z
-
[23]
Melody Y. Guan, Manas Joglekar, Eric Wallace, Saachi Jain, Boaz Barak, Alec Helyar, Rachel Dias, Andrea Vallone, Hongyu Ren, Jason Wei, Hyung Won Chung, Sam Toyer, Johannes Heidecke, Alex Beutel, and Amelia Glaese. Deliberative Alignment : Reasoning Enables Safer Language Models , January 2025. URL http://arxiv.org/abs/2412.16339. arXiv:2412.16339 [cs]
-
[24]
Causal Confusion in Imitation Learning , November 2019
Pim de Haan, Dinesh Jayaraman, and Sergey Levine. Causal Confusion in Imitation Learning , November 2019. URL http://arxiv.org/abs/1905.11979. arXiv:1905.11979 [cs]
-
[25]
Reinforcement Learning with Deep Energy-Based Policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement Learning with Deep Energy - Based Policies , July 2017. URL http://arxiv.org/abs/1702.08165. arXiv:1702.08165 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Soft Actor-Critic Algorithms and Applications
Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, and Sergey Levine. Soft Actor - Critic Algorithms and Applications , January 2019. URL http://arxiv.org/abs/1812.05905. arXiv:1812.05905 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[27]
Cooperative Inverse Reinforcement Learning
Dylan Hadfield-Menell, Stuart J Russell, Pieter Abbeel, and Anca Dragan. Cooperative Inverse Reinforcement Learning . In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems , volume 29. Curran Associates, Inc., 2016. URL https://proceedings.neurips.cc/paper_files/paper/2016/file/c3395dd46c3...
work page 2016
-
[28]
An Overview of Catastrophic AI Risks
Dan Hendrycks, Mantas Mazeika, and Thomas Woodside. An Overview of Catastrophic AI Risks , October 2023. URL http://arxiv.org/abs/2306.12001. arXiv:2306.12001 [cs]
work page internal anchor Pith review arXiv 2023
-
[29]
Risks from Learned Optimization in Advanced Machine Learning Systems
Evan Hubinger, Chris van Merwijk, Vladimir Mikulik, Joar Skalse, and Scott Garrabrant. Risks from Learned Optimization in Advanced Machine Learning Systems , December 2021. URL http://arxiv.org/abs/1906.01820. arXiv:1906.01820 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
A Review of Deep Transfer Learning and Recent Advancements
Mohammadreza Iman, Hamid Reza Arabnia, and Khaled Rasheed. A Review of Deep Transfer Learning and Recent Advancements . Technologies, 11 0 (2): 0 40, March 2023. ISSN 2227-7080. doi:10.3390/technologies11020040. URL https://www.mdpi.com/2227-7080/11/2/40
-
[31]
Towards Continual Reinforcement Learning : A Review and Perspectives , November 2022
Khimya Khetarpal, Matthew Riemer, Irina Rish, and Doina Precup. Towards Continual Reinforcement Learning : A Review and Perspectives , November 2022. URL http://arxiv.org/abs/2012.13490. arXiv:2012.13490 [cs]
-
[32]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[33]
A Survey of Zero -shot Generalisation in Deep Reinforcement Learning
Robert Kirk, Amy Zhang, Edward Grefenstette, and Tim Rocktäschel. A Survey of Zero -shot Generalisation in Deep Reinforcement Learning . Journal of Artificial Intelligence Research, 76: 0 201--264, January 2023. ISSN 1076-9757. doi:10.1613/jair.1.14174. URL http://jair.org/index.php/jair/article/view/14174
-
[34]
Goal Misgeneralization in Deep Reinforcement Learning , January 2023
Lauro Langosco, Jack Koch, Lee Sharkey, Jacob Pfau, Laurent Orseau, and David Krueger. Goal Misgeneralization in Deep Reinforcement Learning , January 2023. URL http://arxiv.org/abs/2105.14111. arXiv:2105.14111 [cs]
-
[35]
Disentangling the Causes of Plasticity Loss in Neural Networks , February 2024
Clare Lyle, Zeyu Zheng, Khimya Khetarpal, Hado van Hasselt, Razvan Pascanu, James Martens, and Will Dabney. Disentangling the Causes of Plasticity Loss in Neural Networks , February 2024. URL http://arxiv.org/abs/2402.18762. arXiv:2402.18762 [cs]
-
[36]
Ritchie, Soren Mindermann, Evan Hubinger, Ethan Perez, and Kevin Troy
Aengus Lynch, Benjamin Wright, Caleb Larson, Stuart J. Ritchie, Soren Mindermann, Evan Hubinger, Ethan Perez, and Kevin Troy. Agentic Misalignment : How LLMs Could Be Insider Threats , October 2025. URL http://arxiv.org/abs/2510.05179. arXiv:2510.05179 [cs]
-
[37]
Natural Emergent Misalignment from Reward Hacking in Production RL , 2025
Monte MacDiarmid, Benjamin Wright, Jonathan Uesato, Joe Benton, Jon Kutasov, Sara Price, Naia Bouscal, Sam Bowman, Trenton Bricken, Alex Cloud, Carson Denison, Johannes Gasteiger, Ryan Greenblatt, Jan Leike, Jack Lindsey, Vlad Mikulik, Ethan Perez, Alex Rodrigues, Drake Thomas, Albert Webson, Daniel Ziegler, and Evan Hubinger. Natural Emergent Misalignmen...
-
[38]
Sharan Maiya, Henning Bartsch, Nathan Lambert, and Evan Hubinger. Open Character Training : Shaping the Persona of AI Assistants through Constitutional AI , November 2025. URL http://arxiv.org/abs/2511.01689. arXiv:2511.01689 [cs]
-
[39]
Lee, Richard Ren, Long Phan, Norman Mu, Adam Khoja, Oliver Zhang, and Dan Hendrycks
Mantas Mazeika, Xuwang Yin, Rishub Tamirisa, Jaehyuk Lim, Bruce W. Lee, Richard Ren, Long Phan, Norman Mu, Adam Khoja, Oliver Zhang, and Dan Hendrycks. Utility Engineering : Analyzing and Controlling Emergent Value Systems in AIs , February 2025. URL http://arxiv.org/abs/2502.08640. arXiv:2502.08640 [cs]
-
[40]
Associative learning and elemental representation: II
IPL McLaren and NJ Mackintosh. Associative learning and elemental representation: II . Generalization and discrimination. Animal learning & behavior, 30 0 (3): 0 177--200, 2002. ISSN 0090-4996
work page 2002
-
[41]
Understanding and Controlling a Maze - Solving Policy Network , October 2023
Ulisse Mini, Peli Grietzer, Mrinank Sharma, Austin Meek, Monte MacDiarmid, and Alexander Matt Turner. Understanding and Controlling a Maze - Solving Policy Network , October 2023. URL http://arxiv.org/abs/2310.08043. arXiv:2310.08043 [cs]
-
[42]
Playing Atari with Deep Reinforcement Learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing Atari with Deep Reinforcement Learning , December 2013. URL http://arxiv.org/abs/1312.5602. arXiv:1312.5602 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[43]
Human-level control through deep reinforcement learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcement l...
-
[44]
Akshat Naik, Patrick Quinn, Guillermo Bosch, Emma Gouné, Francisco Javier Campos Zabala, Jason Ross Brown, and Edward James Young. AgentMisalignment : Measuring the Propensity for Misaligned Behaviour in LLM - Based Agents , October 2025. URL http://arxiv.org/abs/2506.04018. arXiv:2506.04018 [cs]
-
[45]
Deep double descent: where bigger models and more data hurt*
Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. Deep double descent: where bigger models and more data hurt*. Journal of Statistical Mechanics: Theory and Experiment, 2021 0 (12): 0 124003, December 2021. ISSN 1742-5468. doi:10.1088/1742-5468/ac3a74. URL https://iopscience.iop.org/article/10.1088/1742-5468/ac3a74
-
[46]
The Alignment Problem from a Deep Learning Perspective , May 2025
Richard Ngo, Lawrence Chan, and Sören Mindermann. The Alignment Problem from a Deep Learning Perspective , May 2025. URL http://arxiv.org/abs/2209.00626. arXiv:2209.00626 [cs]
-
[47]
The Primacy Bias in Deep Reinforcement Learning , May 2022
Evgenii Nikishin, Max Schwarzer, Pierluca D'Oro, Pierre-Luc Bacon, and Aaron Courville. The Primacy Bias in Deep Reinforcement Learning , May 2022. URL http://arxiv.org/abs/2205.07802. arXiv:2205.07802 [cs]
-
[48]
Deep reinforcement learning with plasticity injection
Evgenii Nikishin, Junhyuk Oh, Georg Ostrovski, Clare Lyle, Razvan Pascanu, Will Dabney, and André Barreto. Deep reinforcement learning with plasticity injection. Advances in Neural Information Processing Systems, 36: 0 37142--37159, 2023
work page 2023
-
[49]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[50]
A model for stimulus generalization in Pavlovian conditioning
John M Pearce. A model for stimulus generalization in Pavlovian conditioning. Psychological review, 94 0 (1): 0 61, 1987. ISSN 1939-1471
work page 1987
-
[51]
Courville, Doina Precup, and Guillaume Lajoie
Mohammad Pezeshki, Oumar Kaba, Yoshua Bengio, Aaron C. Courville, Doina Precup, and Guillaume Lajoie. Gradient starvation: A learning proclivity in neural networks. Advances in Neural Information Processing Systems, 34: 0 1256--1272, 2021
work page 2021
-
[52]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets , January 2022. URL http://arxiv.org/abs/2201.02177. arXiv:2201.02177 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
Direct Preference Optimization : Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct Preference Optimization : Your Language Model is Secretly a Reward Model . In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems , volume 36, pages 53728--53741. Curran A...
work page 2023
-
[54]
Stable- Baselines3 : Reliable Reinforcement Learning Implementations
Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. Stable- Baselines3 : Reliable Reinforcement Learning Implementations . Journal of Machine Learning Research, 22 0 (268): 0 1--8, 2021. URL http://jmlr.org/papers/v22/20-1364.html
work page 2021
-
[55]
Bayesian Inverse Reinforcement Learning
Deepak Ramachandran and Eyal Amir. Bayesian Inverse Reinforcement Learning
-
[56]
Robert A Rescorla. A theory of Pavlovian conditioning: Variations in the effectiveness of reinforcement and non-reinforcement. Classical conditioning, Current research and theory, 2: 0 64--69, 1972
work page 1972
- [57]
-
[58]
Andrei A. Rusu, Neil C. Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive Neural Networks , October 2022. URL http://arxiv.org/abs/1606.04671. arXiv:1606.04671 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[59]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal Policy Optimization Algorithms , August 2017. URL http://arxiv.org/abs/1707.06347. arXiv:1707.06347 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[60]
Goal misgeneralization: Why correct specifications aren't enough for correct goals
Rohin Shah, Vikrant Varma, Ramana Kumar, Mary Phuong, Victoria Krakovna, Jonathan Uesato, and Zac Kenton. Goal misgeneralization: Why correct specifications aren't enough for correct goals. arXiv preprint arXiv:2210.01790, 2022
-
[61]
Toward a universal law of generalization for psychological science
Roger N Shepard. Toward a universal law of generalization for psychological science. Science, 237 0 (4820): 0 1317--1323, 1987. ISSN 0036-8075
work page 1987
-
[62]
Misspecification in Inverse Reinforcement Learning
Joar Skalse and Alessandro Abate. Misspecification in Inverse Reinforcement Learning . Proceedings of the AAAI Conference on Artificial Intelligence, 37 0 (12): 0 15136--15143, June 2023. ISSN 2374-3468, 2159-5399. doi:10.1609/aaai.v37i12.26766. URL https://ojs.aaai.org/index.php/AAAI/article/view/26766
-
[63]
Invariance in policy optimisation and partial identifiability in reward learning
Joar Max Viktor Skalse, Matthew Farrugia-Roberts, Stuart Russell, Alessandro Abate, and Adam Gleave. Invariance in policy optimisation and partial identifiability in reward learning. In International Conference on Machine Learning , pages 32033--32058. PMLR, 2023. ISBN 2640-3498
work page 2023
-
[64]
The Dormant Neuron Phenomenon in Deep Reinforcement Learning , June 2023
Ghada Sokar, Rishabh Agarwal, Pablo Samuel Castro, and Utku Evci. The Dormant Neuron Phenomenon in Deep Reinforcement Learning , June 2023. URL http://arxiv.org/abs/2302.12902. arXiv:2302.12902 [cs]
-
[65]
Mia Taylor, James Chua, Jan Betley, Johannes Treutlein, and Owain Evans. School of Reward Hacks : Hacking harmless tasks generalizes to misaligned behavior in LLMs , August 2025. URL http://arxiv.org/abs/2508.17511. arXiv:2508.17511 [cs]
-
[66]
Alignment Pretraining : AI Discourse Causes Self - Fulfilling ( Mis )alignment, January 2026
Cameron Tice, Puria Radmard, Samuel Ratnam, Andy Kim, David Africa, and Kyle O'Brien. Alignment Pretraining : AI Discourse Causes Self - Fulfilling ( Mis )alignment, January 2026. URL http://arxiv.org/abs/2601.10160. arXiv:2601.10160 [cs]
-
[67]
Theory of games and economic behavior, 2nd rev
John Von Neumann and Oskar Morgenstern. Theory of games and economic behavior, 2nd rev. 1947
work page 1947
-
[68]
Maximum Entropy Deep Inverse Reinforcement Learning
Markus Wulfmeier, Peter Ondruska, and Ingmar Posner. Maximum Entropy Deep Inverse Reinforcement Learning , March 2016. URL http://arxiv.org/abs/1507.04888. arXiv:1507.04888 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[69]
Jailbreak Attacks and Defenses Against Large Language Models: A Survey
Sibo Yi, Yule Liu, Zhen Sun, Tianshuo Cong, Xinlei He, Jiaxing Song, Ke Xu, and Qi Li. Jailbreak Attacks and Defenses Against Large Language Models : A Survey , August 2024. URL http://arxiv.org/abs/2407.04295. arXiv:2407.04295 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Investigating Generalisation in Continuous Deep Reinforcement Learning
Chenyang Zhao, Olivier Sigaud, Freek Stulp, and Timothy M. Hospedales. Investigating Generalisation in Continuous Deep Reinforcement Learning , February 2019. URL http://arxiv.org/abs/1902.07015. arXiv:1902.07015 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[71]
Maximum entropy inverse reinforcement learning
Brian D Ziebart, J Andrew Bagnell, and Anind K Dey. Maximum entropy inverse reinforcement learning. 2008
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.