World Models for Robotic Manipulation: A Survey
Pith reviewed 2026-06-29 12:22 UTC · model grok-4.3
The pith
World models are evolving from task-specific dynamics predictors into predictive infrastructure for robot learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By defining world models as action-conditioned predictive systems and classifying existing work into five representation families with a functional taxonomy, the survey establishes that these models are shifting from specialized task-specific dynamics predictors to general predictive infrastructure that supports synthetic experience, planning, verification, and adaptation in robotic manipulation, while exposing persistent gaps in contact-rich modeling, hallucination mitigation, action alignment, and reliable closed-loop evaluation.
What carries the argument
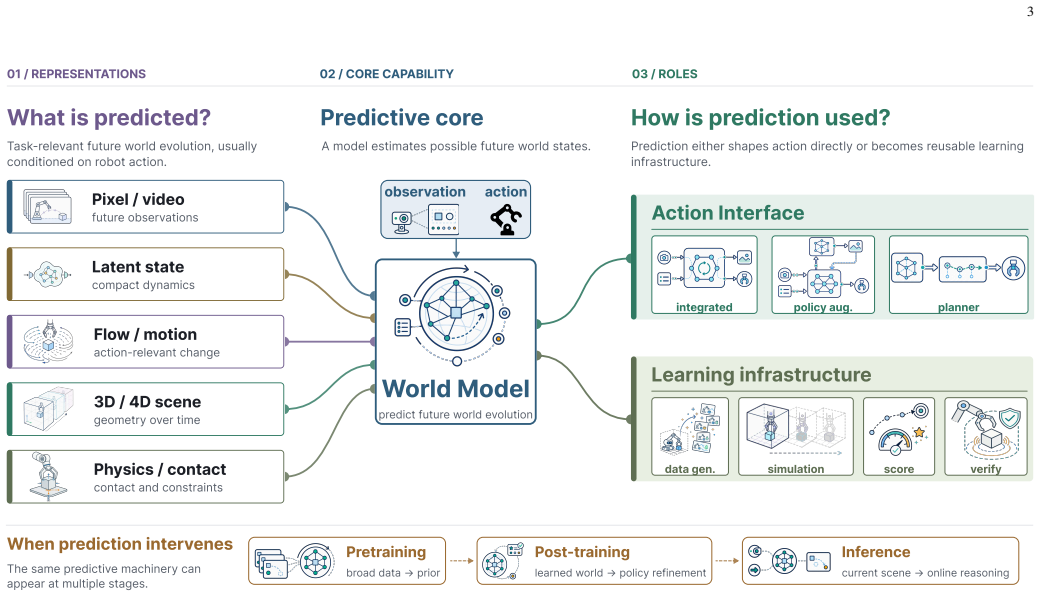
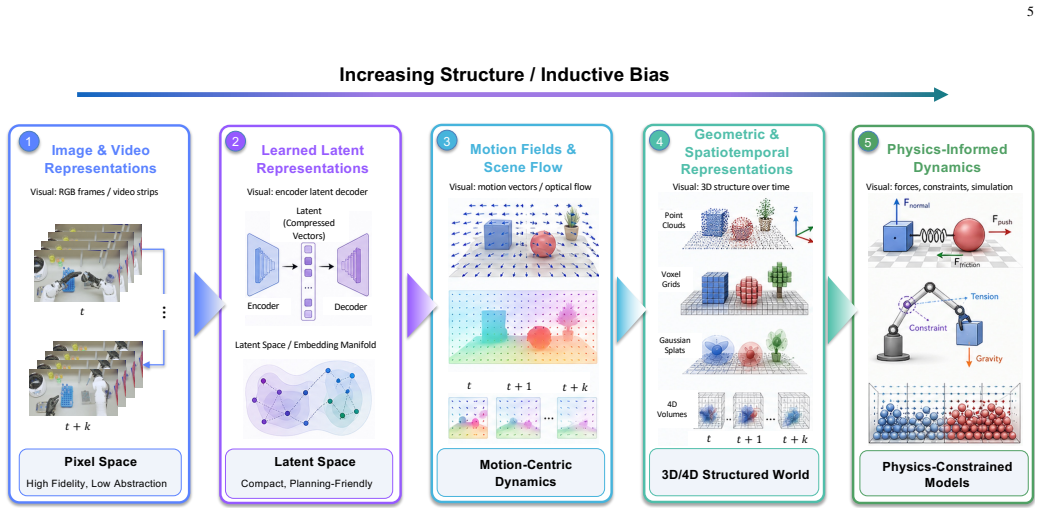
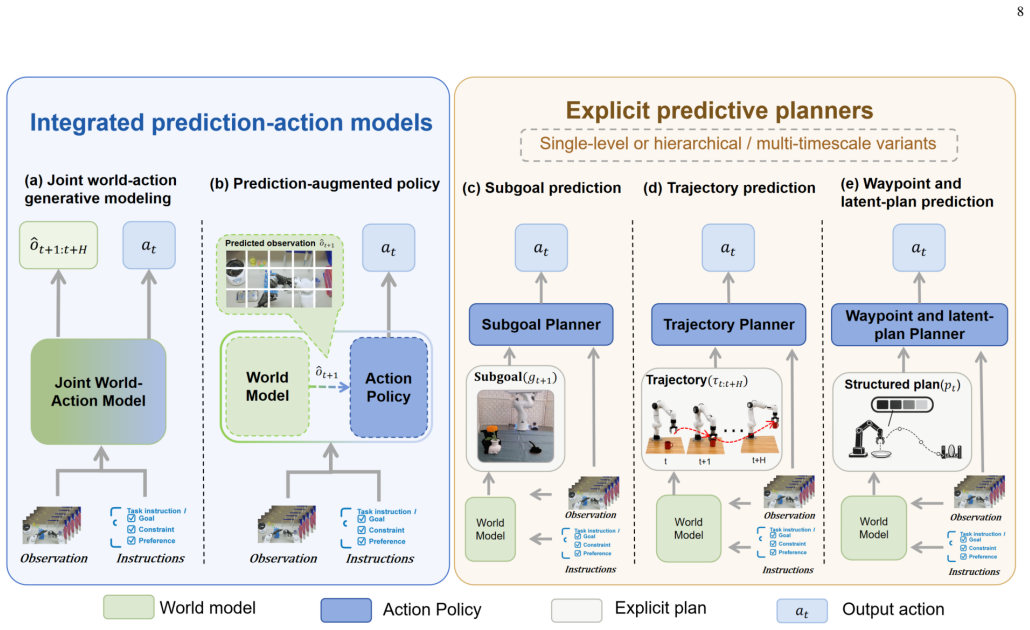
The operational definition of a world model as an action-conditioned predictive system, combined with the five representation families and the functional taxonomy that distinguishes integrated prediction-action models from explicit predictive planners.
If this is right
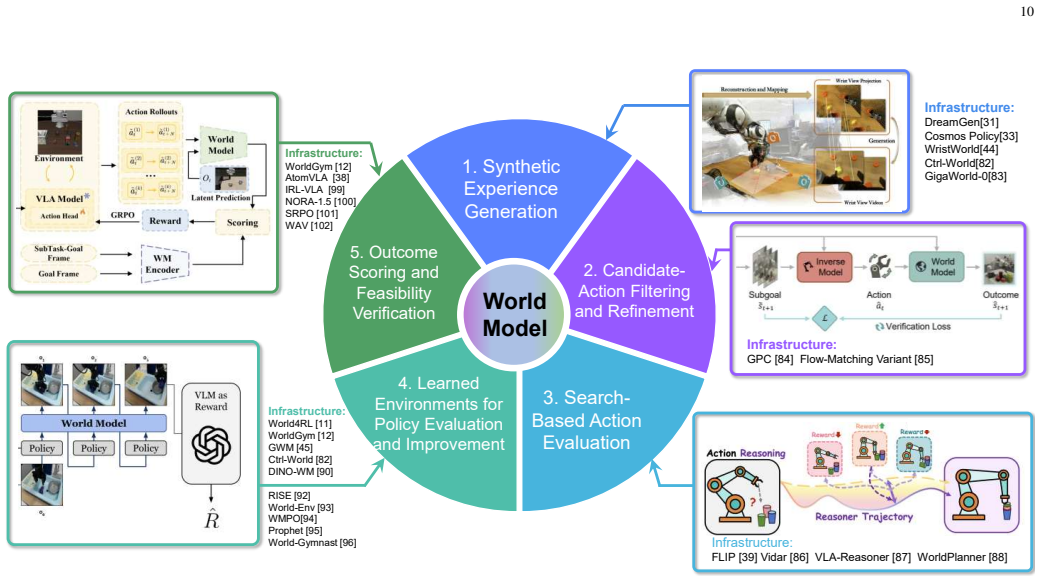
- World models support synthetic experience generation, candidate filtering, search-based evaluation, learned environments, and outcome verification in manipulation pipelines.
- These roles apply across pretraining, post-training, and inference adaptation stages.
- Evaluation protocols must jointly assess predictive fidelity, task performance, and simulator reliability.
- Open challenges remain in contact modeling, hallucination control, action alignment, and closed-loop benchmarking.
Where Pith is reading between the lines
- The infrastructure framing implies world models could reduce dependence on physical data collection by enabling more reliable simulation-based training.
- Persistent contact modeling gaps point to potential value in hybrid physics-informed and learned predictors for manipulation.
- The taxonomy may serve as a guide for integrating predictive components into emerging vision-language-action architectures.
Load-bearing premise
The assumption that the operational definition cleanly separates world models from perception modules, inverse models, policies, rewards, and value functions, and that the five representation families plus functional taxonomy provide exhaustive coverage of the literature without significant omissions or overlaps.
What would settle it
Identification of a substantial body of manipulation literature containing predictive modules that cannot be classified into any of the five representation families or that blur the separation from policies and rewards would falsify the taxonomy's claimed exhaustiveness.
Figures
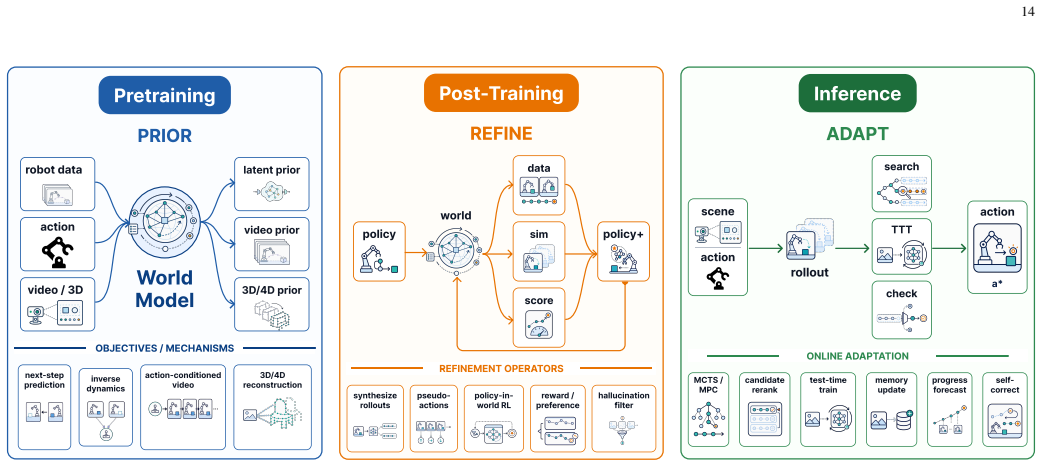
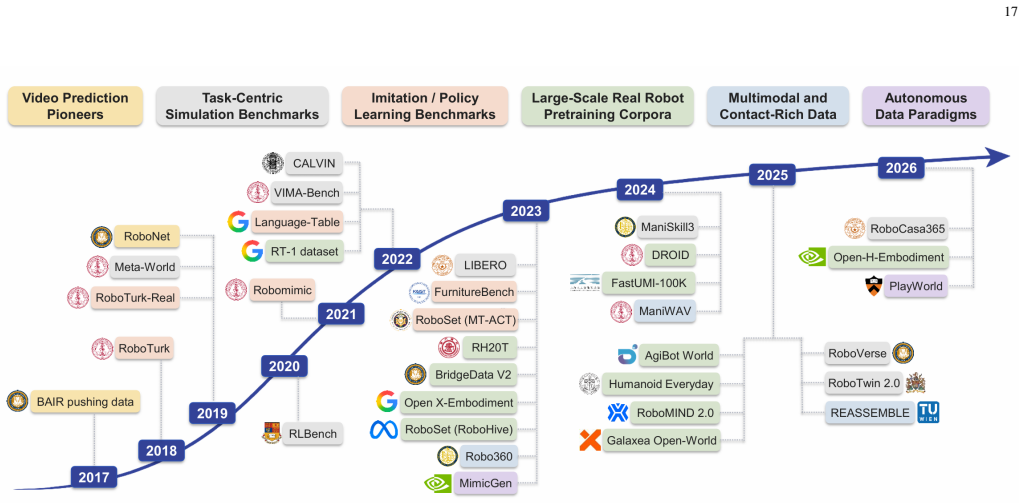
read the original abstract
Robotic manipulation depends on the ability to anticipate how actions reshape objects, contacts, and scene geometry before execution. Learned world models provide this capability by predicting task-relevant future evolution under robot intervention, yet the term now spans latent dynamics models, action-conditioned video generators, three- and four-dimensional scene predictors, physics-informed simulators, and predictive modules inside vision-language-action systems. This breadth has fragmented the literature and obscured the design choices that matter for manipulation. We survey world models for robotic manipulation through three questions: what future representation is predicted, how prediction is connected to action, and when prediction is used in the robot-learning pipeline. We operationally define a world model as an action-conditioned predictive system and distinguish it from perception modules, inverse models, policies, rewards, and value functions. We then organize existing work into five representation families, develop a functional taxonomy that separates integrated prediction-action models from explicit predictive planners, and characterize infrastructure roles including synthetic experience generation, candidate filtering, search-based evaluation, learned environments, and outcome verification. We further map these roles across pretraining, post-training, and inference adaptation, review 34 manipulation datasets, and synthesize evaluation protocols for predictive fidelity, task performance, and simulator reliability. This survey shows that world models are evolving from task-specific dynamics predictors into predictive infrastructure for robot learning, while exposing open challenges in contact modeling, hallucination control, action alignment, and benchmarking under closed-loop use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey organizes the literature on world models for robotic manipulation around three questions (what is predicted, how it connects to action, and when it is used in the learning pipeline). It proposes an operational definition of a world model as an action-conditioned predictive system that excludes perception modules, inverse models, policies, rewards, and value functions; classifies existing work into five representation families; introduces a functional taxonomy separating integrated prediction-action models from explicit predictive planners; maps infrastructure roles (synthetic experience, filtering, search, learned environments, verification) across pretraining/post-training/inference; reviews 34 manipulation datasets; and synthesizes evaluation protocols. The central claim is that world models are evolving from task-specific dynamics predictors into predictive infrastructure, while surfacing open challenges in contact modeling, hallucination control, action alignment, and closed-loop benchmarking.
Significance. If the operational definition and five-family taxonomy prove exhaustive and non-overlapping, the paper would supply a much-needed organizing framework for a fragmented subfield, enabling clearer comparisons of design choices and highlighting concrete research gaps. The dataset review and role-mapping could directly inform benchmark construction and system architecture decisions in robot learning.
major comments (2)
- [Abstract / §2] Abstract and §2 (operational definition): the claim that the definition cleanly separates world models from policies and value functions is load-bearing for the 'predictive infrastructure' narrative, yet the manuscript provides no concrete counter-examples or boundary cases from integrated VLA architectures (e.g., where the predictive head is jointly trained with the policy head). Without such disambiguation, the taxonomy risks artificial separation that does not reflect current practice.
- [§3] §3 (five representation families and functional taxonomy): the exhaustiveness of the partition is asserted but not demonstrated via an explicit coverage table or omission analysis; hybrid 3D+latent or physics-informed video models that straddle multiple families are not addressed, which directly affects the completeness of the infrastructure-role mapping and the listed open challenges.
minor comments (1)
- [Dataset review section] The abstract states that 34 datasets are reviewed, but the manuscript should include an explicit summary table (dataset name, size, manipulation tasks covered, world-model usage) to allow readers to assess coverage without reading every citation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and indicate planned revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract / §2] Abstract and §2 (operational definition): the claim that the definition cleanly separates world models from policies and value functions is load-bearing for the 'predictive infrastructure' narrative, yet the manuscript provides no concrete counter-examples or boundary cases from integrated VLA architectures (e.g., where the predictive head is jointly trained with the policy head). Without such disambiguation, the taxonomy risks artificial separation that does not reflect current practice.
Authors: We agree that explicit boundary cases would strengthen the operational definition. In the revised manuscript we will expand §2 with concrete examples drawn from integrated VLA architectures (e.g., models in which a predictive head is jointly trained with a policy head), showing how the world-model component remains the action-conditioned predictive subsystem even under joint optimization. This addition will directly support the separation from policies and value functions while preserving the predictive-infrastructure framing. revision: yes
-
Referee: [§3] §3 (five representation families and functional taxonomy): the exhaustiveness of the partition is asserted but not demonstrated via an explicit coverage table or omission analysis; hybrid 3D+latent or physics-informed video models that straddle multiple families are not addressed, which directly affects the completeness of the infrastructure-role mapping and the listed open challenges.
Authors: We accept that an explicit demonstration of coverage is required. The revised §3 will include a coverage table mapping all surveyed works to the five families together with an omission analysis. We will also add a dedicated paragraph on hybrid models (3D+latent and physics-informed video predictors), revise the functional taxonomy and infrastructure-role mapping to accommodate them, and update the open-challenges section accordingly. revision: yes
Circularity Check
No circularity: survey paper with external-citation foundation
full rationale
This is a literature survey whose central claims rest on classification of external papers rather than any internal derivation, fitted parameter, or self-referential prediction. The operational definition and taxonomy are presented as organizing choices, not as results derived from prior equations or self-citations within the manuscript. No equations, uniqueness theorems, or ansatzes appear; all substantive statements are supported by citations to independent works. The paper is therefore self-contained against external benchmarks and receives the default non-finding for a review article.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An operational definition of world model as an action-conditioned predictive system cleanly distinguishes it from perception, inverse models, policies, rewards, and value functions.
Reference graph
Works this paper leans on
-
[1]
Internal world models and supervised learning,
M. I. Jordan and D. E. Rumelhart, “Internal world models and supervised learning,” inMachine Learning Proceedings 1991. Elsevier, 1991, pp. 70–74. [Online]. Available: https://doi.org/10.1016/ B978-1-55860-200-7.50018-0
1991
-
[2]
An internal model for sensorimotor integration,
D. M. Wolpert, Z. Ghahramani, and M. I. Jordan, “An internal model for sensorimotor integration,”Science, vol. 269, no. 5232, pp. 1880–1882,
-
[3]
Available: https://doi.org/10.1126/science.7569931
[Online]. Available: https://doi.org/10.1126/science.7569931
-
[4]
Dyna, an integrated architecture for learning, planning, and reacting,
R. S. Sutton, “Dyna, an integrated architecture for learning, planning, and reacting,”ACM SIGART Bulletin, vol. 2, no. 4, pp. 160–163, 1991. [Online]. Available: https://doi.org/10.1145/122344.122377
-
[5]
Learning to control a low-cost manipulator using data-efficient reinforcement learning,
M. Deisenroth, C. Rasmussen, and D. Fox, “Learning to control a low-cost manipulator using data-efficient reinforcement learning,” inRobotics: Science and Systems VII, 2011. [Online]. Available: https://doi.org/10.15607/RSS.2011.VII.008
-
[6]
Recurrent world models facilitate policy evolution,
D. Ha and J. Schmidhuber, “Recurrent world models facilitate policy evolution,” inAdvances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds., vol. 31. Curran Associates, Inc., 2018. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/ 2018/file/2de5d16682c3c3...
2018
-
[7]
Learning latent dynamics for planning from pixels,
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson, “Learning latent dynamics for planning from pixels,” inInternational Conference on Machine Learning, 2019. [Online]. Available: https://proceedings.mlr.press/v97/hafner19a.html
2019
-
[8]
Dream to control: Learning behaviors by latent imagination,
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi, “Dream to control: Learning behaviors by latent imagination,” inInternational Conference on Learning Representations, 2020. [Online]. Available: https://openreview.net/forum?id=S1lOTC4tDS
2020
-
[9]
Mastering diverse control tasks through world models,
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap, “Mastering diverse control tasks through world models,”Nature, 2025. [Online]. Available: https://doi.org/10.1038/s41586-025-08744-2
-
[10]
Predictive Inverse Dynamics Models are Scalable Learners for Robotic Manipulation
Y . Tian, S. Yang, J. Zeng, P. Wang, D. Lin, H. Dong, and J. Pang, “Predictive inverse dynamics models are scalable learners for robotic manipulation,” 2024. [Online]. Available: https://arxiv.org/abs/2412.15109
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
WorldVLA: Towards Autoregressive Action World Model
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, D. Zhao, and H. Chen, “WorldVLA: Towards autoregressive action world model,” 2025. [Online]. Available: https://arxiv.org/abs/2506.21539
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Z. Jiang, K. Liu, Y . Qin, S. Tian, Y . Zheng, M. Zhou, C. Yu, H. Li, and D. Zhao, “World4RL: Diffusion world models for policy refinement with reinforcement learning for robotic manipulation,” 2025. [Online]. Available: https://arxiv.org/abs/2509.19080
-
[13]
Worldgym: World model as an environment for policy evaluation,
J. Quevedo, A. K. Sharma, Y . Sun, V . Suryavanshi, P. Liang, and S. Yang, “Worldgym: World model as an environment for policy evaluation,” 2025. [Online]. Available: https://arxiv.org/abs/2506.00613
-
[14]
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
Y . Liao, P. Zhou, S. Huang, D. Yang, S. Chen, Y . Jiang, Y . Hu, J. Cai, S. Liu, J. Luo, L. Chen, S. Yan, M. Yao, and G. Ren, “Genie envisioner: A unified world foundation platform for robotic manipulation,” 2025. [Online]. Available: https://arxiv.org/abs/2508.05635
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Tesseract: Learning 4d embodied world models.arXiv preprint arXiv:2504.20995, 2025
H. Zhen, Q. Sun, H. Zhang, J. Li, S. Zhou, Y . Du, and C. Gan, “TesserAct: Learning 4d embodied world models,” 2025. [Online]. Available: https://arxiv.org/abs/2504.20995
-
[16]
Pointworld: Scaling 3d world models for in-the-wild robotic manipulation,
W. Huang, Y .-W. Chao, A. Mousavian, M.-Y . Liu, D. Fox, K. Mo, and L. Fei-Fei, “Pointworld: Scaling 3d world models for in-the-wild robotic manipulation,” 2026. [Online]. Available: https://arxiv.org/abs/2601.03782
-
[17]
Is Sora a world simulator? A comprehensive survey on general world models and beyond,
Z. Zhu, X. Wang, W. Zhao, C. Min, B. Li, N. Deng, M. Dou, Y . Wang, B. Shi, K. Wang, C. Zhang, Y . You, Z. Zhang, D. Zhao, L. Xiao, J. Zhao, J. Lu, and G. Huang, “Is Sora a world simulator? A comprehensive survey on general world models and beyond,” 2024
2024
-
[18]
A survey: Learning embodied intelligence from physical simulators and world models,
X. Long, Q. Zhao, K. Zhang, Z. Zhang, D. Wang, Y . Liu, Z. Shu, Y . Lu, S. Wang, X. Wei, W. Li, W. Yin, Y . Yao, J. Pan, Q. Shen, R. Yang, X. Cao, and Q. Dai, “A survey: Learning embodied intelligence from physical simulators and world models,” 2025. 22
2025
-
[19]
3D and 4D world modeling: A survey,
L. Kong, W. Yang, J. Mei, Y . Liu, A. Liang, D. Zhu, D. Lu, W. Yin, X. Hu, M. Jia, J. Deng, K. Zhang, Y . Wu, T. Yan, S. Gao, S. Wang, L. Li, L. Pan, Y . Liu, J. Zhu, W. T. Ooi, S. C. H. Hoi, and Z. Liu, “3D and 4D world modeling: A survey,” 2025
2025
-
[20]
A step toward world models: A survey on robotic manipulation,
P.-F. Zhang, Y . Cheng, X. Sun, S. Wang, F. Li, L. Zhu, and H. T. Shen, “A step toward world models: A survey on robotic manipulation,” 2025
2025
-
[21]
Towards generalist embodied ai: A survey on world models for vla agents,
W. Tan, L. Zhu, B. Wang, E. Xie, B. Ji, Z. Lin, W. Yang, J. Li, and H. T. Shen, “Towards generalist embodied ai: A survey on world models for vla agents,” 2026, techRxiv preprint. [Online]. Available: https: //www.techrxiv.org/doi/full/10.36227/techrxiv.176948355.54623875/v1
-
[22]
Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
R. Shao, W. Li, L. Zhang, R. Zhang, Z. Liu, R. Chen, and L. Nie, “Large vlm-based vision-language-action models for robotic manipulation: A survey,” 2025. [Online]. Available: https://arxiv.org/abs/2508.13073
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
A Survey on Vision-Language-Action Models for Embodied AI
Y . Ma, Z. Song, Y . Zhuang, J. Hao, and I. King, “A survey on vision- language-action models for embodied AI,”IEEE Transactions on Neural Networks and Learning Systems, 2026, early Access; arXiv:2405.14093
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Forward models: Supervised learning with a distal teacher,
M. I. Jordan and D. E. Rumelhart, “Forward models: Supervised learning with a distal teacher,”Cognitive Science, vol. 16, no. 3, pp. 307–354,
-
[25]
Available: https://doi.org/10.1207/s15516709cog1603_1
[Online]. Available: https://doi.org/10.1207/s15516709cog1603_1
-
[26]
R. C. Miall and D. M. Wolpert, “Forward models for physiological motor control,”Neural Networks, vol. 9, no. 8, pp. 1265–1279, 1996. [Online]. Available: https://doi.org/10.1016/S0893-6080(96)00035-4
-
[27]
Multiple paired forward and inverse models for motor control,
D. M. Wolpert and M. Kawato, “Multiple paired forward and inverse models for motor control,”Neural Networks, vol. 11, no. 7–8, pp. 1317–1329, 1998. [Online]. Available: https://doi.org/10.1016/ S0893-6080(98)00066-5
1998
-
[28]
Learning universal policies via text- guided video generation,
Y . Du, M. Yang, B. Dai, H. Dai, O. Nachum, J. B. Tenenbaum, D. Schuurmans, and P. Abbeel, “Learning universal policies via text- guided video generation,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[29]
Zero-shot robotic manipulation with pretrained image- editing diffusion models,
K. Black, M. Nakamoto, P. Atreya, H. Walke, C. Finn, A. Kumar, and S. Levine, “Zero-shot robotic manipulation with pretrained image- editing diffusion models,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[30]
Video language planning,
Y . Du, M. Yang, P. Florence, F. Xia, A. Wahid, B. Ichter, P. Sermanet, T. Yu, P. Abbeel, J. B. Tenenbaum, L. Kaelbling, A. Zeng, and J. Tompson, “Video language planning,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[31]
Unleashing large-scale video generative pre-training for visual robot manipulation,
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong, “Unleashing large-scale video generative pre-training for visual robot manipulation,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 10 641–10 662
2024
-
[32]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
C.-L. Cheang, G. Chen, Y . Jing, T. Kong, H. Li, Y . Li, Y . Liu, H. Wu, J. Xu, Y . Yang, H. Zhang, and M. Zhu, “GR-2: A generative video-language-action model with web-scale knowledge for robot manipulation,” 2024. [Online]. Available: https://arxiv.org/abs/2410.06158
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
DreamGen: Unlocking Generalization in Robot Learning through Video World Models
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Linet al., “Dreamgen: Unlocking generaliza- tion in robot learning through video world models,”arXiv preprint arXiv:2505.12705, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Learning real-world action- video dynamics with heterogeneous masked autoregression,
L. Wang, K. Zhao, C. Liu, and X. Chen, “Learning real-world action- video dynamics with heterogeneous masked autoregression,”arXiv preprint arXiv:2502.04296, 2025
-
[35]
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finnet al., “Cosmos policy: Fine-tuning video models for visuomotor control and planning,”arXiv preprint arXiv:2601.16163, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, Mojtaba, Komeili, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, S. Arnaud, A. Gejji, A. Martin, F. R. Hogan, D. Dugas, P. Bojanowski, V . Khalidov, P. Labatut, F. Massa, M. Szafraniec, K. Krishnakumar, Y . Li, X. Ma, S. Chandar, F. Meier, Y . LeCun, M. Rabbat, and N. Ballas, “V-jepa 2: Self-supe...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
T. Yuan, Z. Dong, Y . Liu, and H. Zhao, “Fast-wam: Do world action models need test-time future imagination?” 2026. [Online]. Available: https://arxiv.org/abs/2603.16666
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Y . Luo, F. Li, S. Xu, Y . Ji, Z. Zhang, B. Wang, Y . Shen, J. Cui, L. Chen, G. Chen, H. Ye, Z.-X. Yang, and F. Wen, “Last-vla: Thinking in latent spatio-temporal space for vision-language-action in autonomous driving,” 2026. [Online]. Available: https://arxiv.org/abs/2603.01928
-
[39]
Chain of world: World model thinking in latent motion,
F. Yang, D. Di, L. Tang, X. Zhang, L. Fan, H. Li, C. Wei, T. Su, and B. Ma, “Chain of world: World model thinking in latent motion,”
-
[40]
Available: https://arxiv.org/abs/2603.03195
[Online]. Available: https://arxiv.org/abs/2603.03195
-
[41]
X. Sun, Z. Xu, C. Cao, Z. Liu, Y . Sun, J. Pang, R. Zhang, Z. Yang, K. Pang, D. He, M. Yuan, and J. Chen, “Atomvla: Scalable post-training for robotic manipulation via predictive latent world models,” 2026. [Online]. Available: https://arxiv.org/abs/2603.08519
-
[42]
Flip: Flow-centric generative planning as general-purpose manipulation world model,
C. Gao, H. Zhang, Z. Xu, C. Zhehao, and L. Shao, “Flip: Flow-centric generative planning as general-purpose manipulation world model,” in International Conference on Learning Representations, vol. 2025, 2025, pp. 21 927–21 948
2025
-
[43]
FlowVLA: Visual chain of thought-based motion reasoning for vision-language-action models,
Z. Zhong, H. Yan, J. Li, X. Liu, X. Gong, T. Zhang, W. Song, J. Chen, X. Zheng, H. Wang, and H. Li, “FlowVLA: Visual chain of thought-based motion reasoning for vision-language-action models,”
-
[44]
[Online]. Available: https://arxiv.org/abs/2508.18269
-
[45]
3d-vla: a 3d vision-language-action generative world model,
H. Zhen, X. Qiu, P. Chen, J. Yang, X. Yan, Y . Du, Y . Hong, and C. Gan, “3d-vla: a 3d vision-language-action generative world model,” in Proceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[46]
OG-VLA: Orthographic image generation for 3d- aware vision-language action model,
I. Singh, A. Goyal, S. Birchfield, D. Fox, A. Garg, and V . Blukis, “OG-VLA: Orthographic image generation for 3d- aware vision-language action model,” 2025. [Online]. Available: https://arxiv.org/abs/2506.01196
-
[47]
V . Bhat, Y .-H. Lan, P. Krishnamurthy, R. Karri, and F. Khorrami, “3D-CA VLA: Leveraging depth and 3d context to generalize vision language action models for unseen tasks,” 2025. [Online]. Available: https://arxiv.org/abs/2505.05800
-
[48]
Wristworld: Generating wrist-views via 4d world models for robotic manipulation,
Z. Qian, X. Chi, Y . Li, S. Wang, Z. Qin, X. Ju, S. Han, and S. Zhang, “Wristworld: Generating wrist-views via 4d world models for robotic manipulation,” 2025. [Online]. Available: https://arxiv.org/abs/2510.07313
-
[49]
Gwm: Towards scalable gaussian world models for robotic manipulation,
G. Lu, B. Jia, P. Li, Y . Chen, Z. Wang, Y . Tang, and S. Huang, “Gwm: Towards scalable gaussian world models for robotic manipulation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 9263–9274
2025
-
[50]
PIN- WM: Learning physics-informed world models for non-prehensile manipulation,
W. Li, H. Zhao, Z. Yu, Y . Du, Q. Zou, R. Hu, and K. Xu, “PIN- WM: Learning physics-informed world models for non-prehensile manipulation,” inProceedings of Robotics: Science and Systems (RSS), Los Angeles, CA, USA, 2025
2025
-
[51]
Showui: One vision-language- action model for GUI visual agent
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, A. Handa, M.-Y . Liu, D. Xiang, G. Wetzstein, and T.-Y . Lin, “CoT-VLA: Visual chain-of-thought reasoning for vision- language-action models,” in2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 1715–1726. [Online]. Available: https://do...
-
[52]
RynnVLA-002: A Unified Vision-Language-Action and World Model
J. Cen, S. Huang, Y . Yuan, K. Li, H. Yuan, C. Yu, Y . Jiang, J. Guo, X. Li, H. Luo, F. Wang, D. Zhao, and H. Chen, “RynnVLA-002: A unified vision-language-action and world model,” 2025. [Online]. Available: https://arxiv.org/abs/2511.17502
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Physical autoregressive model for robotic manipulation without action pretraining,
Z. Song, S. Qin, T. Chen, L. Lin, and G. Wang, “Physical autoregressive model for robotic manipulation without action pretraining,” 2025. [Online]. Available: https://arxiv.org/abs/2508.09822
-
[54]
Dual-Stream Diffusion for World-Model Augmented Vision-Language-Action Model
J. Won, K. Lee, H. Jang, D. Kim, and J. Shin, “Dual-stream diffusion for world-model augmented vision-language-action model,” 2025. [Online]. Available: https://arxiv.org/abs/2510.27607
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
World Action Models are Zero-shot Policies
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, A. Malik, K. Lee, W. Liang, N. Ranawaka, J. Gu, Y . Xu, G. Wang, F. Hu, A. Narayan, J. Bjorck, J. Wang, G. Kim, D. Niu, R. Zheng, Y . Xie, J. Wu, Q. Wang, R. Julian, D. Xu, Y . Du, Y . Chebotar, S. Reed, J. Kautz, Y . Zhu, L. J. Fan, and J. Jang, “World action mo...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
Do World Action Models Generalize Better than VLAs? A Robustness Study
Z. Zhang, Z. Li, B. Rahmati, R. H. Yang, Y . Ma, A. Rasouli, S. Pakdamansavoji, Y . Wu, L. Zhang, T. Cao, F. Wen, X. Wang, X. Quan, and Y . Zhang, “Do world action models generalize better than VLAs? a robustness study,” 2026. [Online]. Available: https://arxiv.org/abs/2603.22078
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
Flare: Robot learning with implicit world modeling,
R. Zheng, J. Wang, S. Reed, J. Bjorck, Y . Fang, F. Hu, J. Jang, K. Kundalia, Z. Lin, L. Magne, A. Narayan, Y . L. Tan, G. Wang, Q. Wang, J. Xiang, Y . Xu, S. Ye, J. Kautz, F. Huang, Y . Zhu, and L. Fan, “Flare: Robot learning with implicit world modeling,” in Proceedings of The 9th Conference on Robot Learning, ser. Proceedings of Machine Learning Resear...
2025
-
[58]
Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge,
W. Zhang, H. Liu, Z. Qi, Y . Wang, X. Yu, J. Zhang, R. Dong, J. He, H. Wang, Z. Zhanget al., “Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge,”Advances in Neural Information Processing Systems, vol. 38, pp. 24 195–24 228, 2026
2026
-
[59]
arXiv preprint arXiv:2602.10098 (2026)
J. Sun, W. Zhang, Z. Qi, S. Ren, Z. Liu, H. Zhu, G. Sun, X. Jin, and Z. Chen, “VLA-JEPA: Enhancing vision-language- 23 action model with latent world model,” 2026. [Online]. Available: https://arxiv.org/abs/2602.10098
-
[60]
DIAL: Decoupling Intent and Action via Latent World Modeling for End-to-End VLA
Y . Chen, Y . Ge, H. Zhou, M. Ding, Y . Ge, and X. Liu, “DIAL: Decoupling intent and action via latent world modeling for end-to-end vla,” 2026. [Online]. Available: https://arxiv.org/abs/2603.29844
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
UP-VLA: A unified understanding and prediction model for embodied agent,
J. Zhang, Y . Guo, Y . Hu, X. Chen, X. Zhu, and J. Chen, “UP-VLA: A unified understanding and prediction model for embodied agent,” in Forty-second International Conference on Machine Learning, 2025. [Online]. Available: https://openreview.net/forum?id=V7JPraxi5j
2025
-
[62]
Daydreamer: World models for physical robot learning,
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and K. Goldberg, “Daydreamer: World models for physical robot learning,” inProceedings of The 6th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, K. Liu, D. Kulic, and J. Ichnowski, Eds., vol
-
[63]
2226–2240
PMLR, 14–18 Dec 2023, pp. 2226–2240. [Online]. Available: https://proceedings.mlr.press/v205/wu23c.html
2023
-
[64]
Multi-view masked world models for visual robotic manipulation,
Y . Seo, J. Kim, S. James, K. Lee, J. Shin, and P. Abbeel, “Multi-view masked world models for visual robotic manipulation,” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, Eds., vol. 202. PMLR, 23–29 Jul 2023,...
2023
-
[65]
Learning view-invariant world models for visual robotic manipulation,
J.-C. Pang, N. Tang, K. Li, Y . Tang, X.-Q. Cai, Z.-Y . Zhang, G. Niu, M. Sugiyama, and Y . Yu, “Learning view-invariant world models for visual robotic manipulation,” inInternational Conference on Learning Representations, Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, Eds., vol. 2025, 2025, pp. 54 853–54 876. [Online]. Available: https://proceedings.iclr...
2025
-
[66]
Ladi-WM: A latent diffusion-based world model for predictive manipulation,
Y . Huang, J. Zhang, S. Zou, X. Liu, R. Hu, and K. Xu, “Ladi-WM: A latent diffusion-based world model for predictive manipulation,” in 9th Annual Conference on Robot Learning, 2025. [Online]. Available: https://openreview.net/forum?id=o2w2iiMyEU
2025
-
[67]
Lumos: Language-conditioned imitation learning with world models,
I. Nematollahi, B. DeMoss, A. L. Chandra, N. Hawes, W. Burgard, and I. Posner, “Lumos: Language-conditioned imitation learning with world models,” in2025 IEEE International Conference on Robotics and Automation (ICRA), 2025, pp. 8219–8225
2025
-
[68]
Reward-free world models for online imitation learning,
S. Li, Z. Huang, and H. Su, “Reward-free world models for online imitation learning,” inForty-second International Conference on Machine Learning, 2025. [Online]. Available: https://openreview.net/ forum?id=owEhpoKBKC
2025
-
[69]
Focus: object-centric world models for robotic manipulation,
S. Ferraro, P. Mazzaglia, T. Verbelen, and B. Dhoedt, “Focus: object-centric world models for robotic manipulation,”Frontiers in Neurorobotics, vol. V olume 19 - 2025, 2025. [Online]. Available: https://www.frontiersin.org/journals/neurorobotics/articles/10. 3389/fnbot.2025.1585386
-
[70]
Leveraging separated world model for exploration in visually distracted environments,
K. Huang, S. Wan, M. Shao, H.-H. Sun, L. Gan, S. Feng, and D.-C. Zhan, “Leveraging separated world model for exploration in visually distracted environments,” inAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Curran Associates, Inc., 2024, pp. 82 350–82 37...
2024
-
[71]
Gr-mg: Leveraging partially-annotated data via multi-modal goal-conditioned policy,
P. Li, H. Wu, Y . Huang, C. Cheang, L. Wang, and T. Kong, “Gr-mg: Leveraging partially-annotated data via multi-modal goal-conditioned policy,”IEEE Robotics and Automation Letters, vol. 10, no. 2, pp. 1912–1919, 2025
1912
-
[72]
L. Heng, J. Xu, Y . Wang, X. Li, M. Cai, Y . Shen, J. Zhu, G. Ren, and H. Dong, “Imagine2act: Leveraging object-action motion consistency from imagined goals for robotic manipulation,” 2025. [Online]. Available: https://arxiv.org/abs/2509.17125
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
Mind: Learning a dual-system world model for real-time planning and implicit risk analysis,
X. Chi, K. Ge, J. Liu, S. Zhou, P. Jia, Z. He, Y . Liu, T. Li, L. Han, S. Han, S. Zhang, and Y . Guo, “Mind: Learning a dual-system world model for real-time planning and implicit risk analysis,” 2025. [Online]. Available: https://arxiv.org/abs/2506.18897
-
[74]
Closed-loop visuomotor control with generative expectation for robotic manipulation,
Q. Bu, J. Zeng, L. Chen, Y . Yang, G. Zhou, J. Yan, P. Luo, H. Cui, Y . Ma, and H. Li, “Closed-loop visuomotor control with generative expectation for robotic manipulation,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id=1ptdkwZbMG
2024
-
[75]
Eva: Aligning video world models with executable robot actions via inverse dynamics rewards,
R. Wang, Q. Liu, Y . Deng, G. Liu, Z. Liu, and K. Jia, “Eva: Aligning video world models with executable robot actions via inverse dynamics rewards,” 2026. [Online]. Available: https://arxiv.org/abs/2603.17808
-
[76]
Video prediction policy: A generalist robot policy with predictive visual representations,
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen, “Video prediction policy: A generalist robot policy with predictive visual representations,” in Forty-second International Conference on Machine Learning, 2025. [Online]. Available: https://openreview.net/forum?id=c0dhw1du33
2025
-
[77]
TD-MPC2: Scalable, robust world models for continuous control,
N. Hansen, H. Su, and X. Wang, “TD-MPC2: Scalable, robust world models for continuous control,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=Oxh5CstDJU
2024
-
[78]
Modem: Accelerating visual model-based reinforcement learning with demonstrations,
N. Hansen, Y . Lin, H. Su, X. Wang, V . Kumar, and A. Rajeswaran, “Modem: Accelerating visual model-based reinforcement learning with demonstrations,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https: //openreview.net/forum?id=JdTnc9gjVfJ
2023
-
[79]
Modem-v2: Visuo-motor world models for real-world robot manipulation,
P. Lancaster, N. Hansen, A. Rajeswaran, and V . Kumar, “Modem-v2: Visuo-motor world models for real-world robot manipulation,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 7530–7537
2024
-
[80]
Multi-stage manipulation with demonstration-augmented reward, policy, and world model learning,
A. L. Escoriza, N. Hansen, S. Tao, T. Mu, and H. Su, “Multi-stage manipulation with demonstration-augmented reward, policy, and world model learning,” inForty-second International Conference on Machine Learning, 2025. [Online]. Available: https://openreview.net/forum?id=Bv7LUUYOiq
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.