Harnessing Agent Skills: Architectural Patterns and a Reference Architecture for Skill-Mediated LLM Agents
Pith reviewed 2026-06-28 22:38 UTC · model grok-4.3
The pith
Ten architectural patterns and a four-layer reference architecture organize skill harnessing responsibilities in LLM agent systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
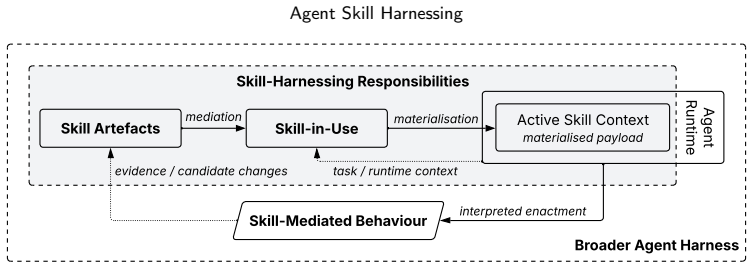
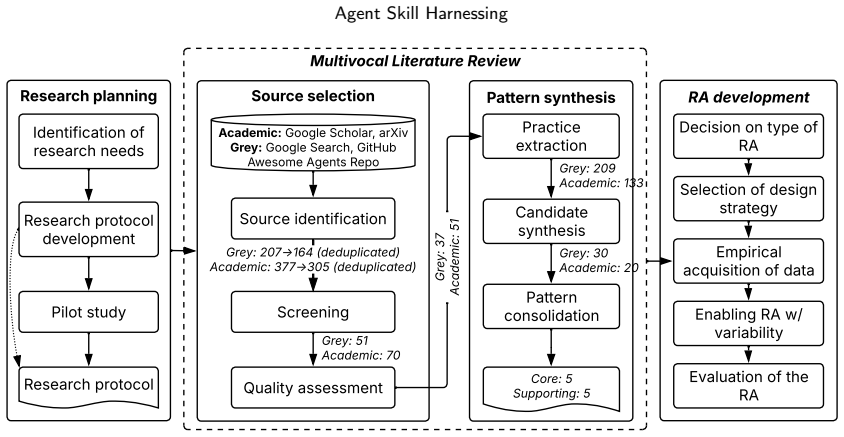
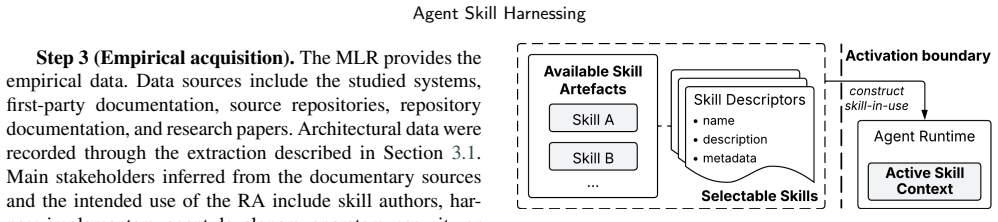
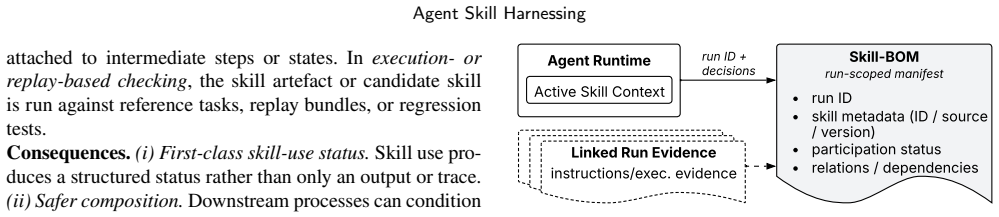
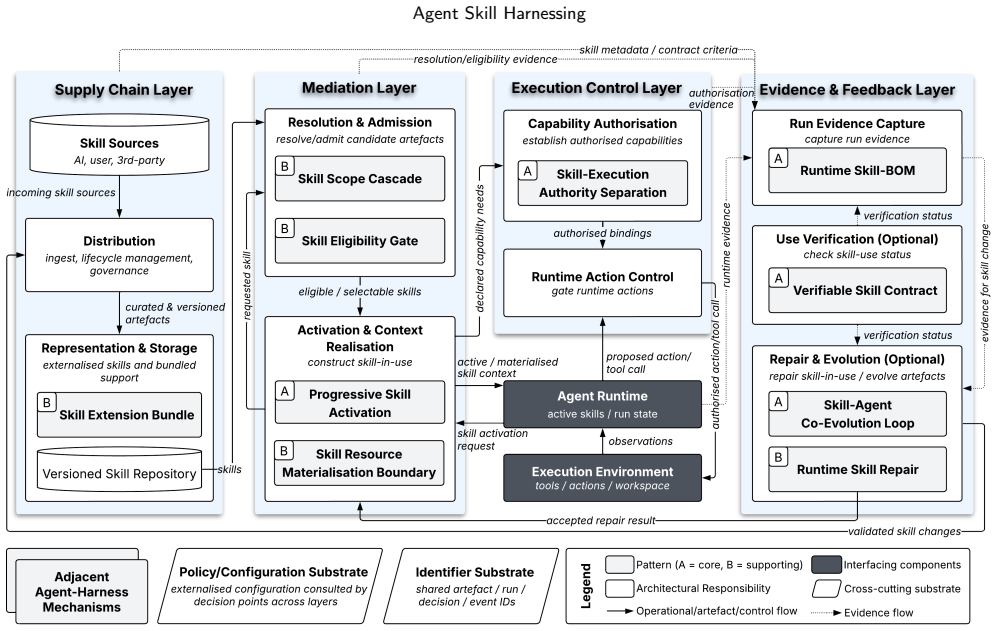
Agent skill harnessing consists of the architectural responsibilities that govern the transition from persistent skill artefacts to skill-in-use, bound the executable consequences, and capture evidence for attribution, verification, repair, and evolution. The paper presents a catalogue of ten empirically grounded architectural patterns and synthesises them into a reference architecture with four responsibility layers that together provide a vocabulary and diagnostic frame for analysing skill-harnessing responsibilities across agent systems.
What carries the argument
The skill-in-use relation together with the ten architectural patterns (five core, five supporting) that structure responsibilities for selection, binding, constraint enforcement, interpretation, and evidence recording.
If this is right
- Agent systems can be diagnosed for completeness across the four responsibility layers.
- The patterns supply reusable solutions for common challenges in skill discovery, activation, and constraint binding.
- Cross-system comparison and analysis become possible using a shared reference structure.
- Structured evidence recording supports attribution, verification, and iterative improvement of skills.
Where Pith is reading between the lines
- The four layers could be used as an audit checklist when reviewing codebases of existing LLM agent frameworks.
- Similar pattern catalogues might be developed for other reusable artefacts such as memory modules or planning templates.
- Interoperable skill repositories could emerge if multiple platforms adopt the same reference layers.
Load-bearing premise
The ten patterns identified from the eight selected systems generalize as a diagnostic frame for skill-harnessing responsibilities in arbitrary LLM agent architectures.
What would settle it
An LLM agent system that uses reusable skill artefacts but whose responsibilities for selection, binding, execution control, and evidence recording do not map onto the ten patterns or four layers.
Figures

read the original abstract
Agent skills externalise reusable agent-facing behavioural knowledge and guidance as persistent artefacts that can be discovered, activated, and interpreted by LLM agents. Although a skill artefact is static at rest, its architectural responsibilities arise in use, when the artefact is selected for a run, bound to context and authority constraints, interpreted by a stochastic agent, and recorded as run evidence. We call this run-specific relation skill-in-use. This paper studies agent skill harnessing: the architectural responsibilities that govern the transition from skill artefacts to skill-in-use, bound the executable consequences associated with skill-in-use, and capture evidence for attribution, verification, repair, and evolution. This paper provides a catalogue of ten empirically grounded architectural patterns (five core, five supporting) for skill harnessing and synthesises them into a reference architecture with four responsibility layers: Supply Chain, Mediation, Execution Control, and Evidence & Feedback. We evaluate the architecture through cross-instantiation across 8 selected systems. The resulting patterns and reference architecture provide a vocabulary and diagnostic frame for analysing skill-harnessing responsibilities across agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that agent skills are static artefacts whose run-specific responsibilities (selection, binding, interpretation, evidence capture) constitute 'skill-in-use'; from analysis of eight selected LLM agent systems it derives ten empirically grounded architectural patterns (five core, five supporting), synthesises them into a four-layer reference architecture (Supply Chain, Mediation, Execution Control, Evidence & Feedback), evaluates the architecture by cross-instantiation on the same eight systems, and concludes that the patterns and architecture supply a reusable vocabulary and diagnostic frame for skill-harnessing responsibilities across agent systems.
Significance. If the patterns prove generalisable, the work supplies a structured diagnostic lens for comparing how existing and future skill-mediated agents manage the transition from static artefacts to executable, attributable runs. The empirical derivation from multiple concrete systems and the explicit layering of responsibilities are constructive contributions that could aid both analysis and design.
major comments (1)
- [Evaluation] Evaluation section (cross-instantiation on the eight systems): the mapping back onto the source systems demonstrates internal consistency within the sample but supplies no external test that the four layers are exhaustive or that responsibilities in architectures employing different skill-binding mechanisms, authority models, or execution semantics map without gaps or emergent patterns; this directly undercuts the claim that the architecture constitutes a reusable diagnostic frame for arbitrary LLM agent systems.
minor comments (1)
- [Abstract] Abstract: the phrasing 'empirically grounded architectural patterns' and 'reference architecture' could be separated more explicitly so readers immediately see which elements are observed versus synthesised.
Simulated Author's Rebuttal
We thank the referee for the constructive summary and for highlighting the significance of the work. We address the single major comment on evaluation below, agreeing that the current evaluation is limited to internal consistency and will revise accordingly.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (cross-instantiation on the eight systems): the mapping back onto the source systems demonstrates internal consistency within the sample but supplies no external test that the four layers are exhaustive or that responsibilities in architectures employing different skill-binding mechanisms, authority models, or execution semantics map without gaps or emergent patterns; this directly undercuts the claim that the architecture constitutes a reusable diagnostic frame for arbitrary LLM agent systems.
Authors: We agree that the cross-instantiation on the eight source systems demonstrates only internal consistency and does not provide an external test of exhaustiveness or gap-free mapping for systems with different binding mechanisms, authority models, or execution semantics. This is a genuine limitation of the current evaluation. In the revised manuscript we will (1) add an explicit 'Limitations' subsection that states the evaluation scope is confined to the sampled systems, (2) qualify the abstract and conclusion claims to describe the architecture as 'an empirically derived diagnostic frame validated on the studied systems and offered as a reusable vocabulary for further application' rather than asserting it is already proven for arbitrary systems, and (3) outline concrete directions for future external validation. These changes directly address the concern without altering the core empirical contribution. revision: yes
Circularity Check
No circularity: purely descriptive synthesis with no derivations or self-referential reductions
full rationale
The paper is a descriptive catalogue of ten patterns identified from eight selected systems, synthesized into a four-layer reference architecture and evaluated only via cross-instantiation on the same sample. No equations, fitted parameters, predictions, or derivation chains appear in the provided text. The central claim (patterns and architecture as a diagnostic vocabulary) does not reduce to any input by construction, self-definition, or self-citation load-bearing step. This is the expected outcome for architecture synthesis work that makes no mathematical or predictive claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 , eprint =
Skill Retrieval Augmentation for Agentic AI , author =. 2026 , eprint =
2026
-
[2]
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver , author=. arXiv preprint arXiv:2604.08377 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
Skill0: In-context agentic reinforcement learning for skill internalization , author=. arXiv preprint arXiv:2604.02268 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2603.04448 , year=
Skillnet: Create, evaluate, and connect ai skills , author=. arXiv preprint arXiv:2603.04448 , year=
-
[5]
Reinforcement Learning for Self-Improving Agent with Skill Library
Reinforcement learning for self-improving agent with skill library , author=. arXiv preprint arXiv:2512.17102 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=
An empirical study on software bill of materials: Where we stand and the road ahead , author=. 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=. 2023 , organization=
2023
-
[7]
Empirically-grounded reference architectures: a proposal , author=. Proceedings of the joint ACM SIGSOFT conference--QoSA and ACM SIGSOFT symposium--ISARCS on Quality of software architectures--QoSA and architecting critical systems--ISARCS , pages=
-
[8]
Information and software technology , volume=
Guidelines for including grey literature and conducting multivocal literature reviews in software engineering , author=. Information and software technology , volume=. 2019 , publisher=
2019
-
[9]
2007 , publisher=
Guidelines for performing systematic literature reviews in software engineering , author=. 2007 , publisher=
2007
-
[10]
Thinking with Reasoning Skills: Fewer Tokens, More Accuracy
Thinking with Reasoning Skills: Fewer Tokens, More Accuracy , author=. arXiv preprint arXiv:2604.21764 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses
Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses , author=. arXiv preprint arXiv:2604.25850 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering
Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering , author=. arXiv preprint arXiv:2604.08224 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Toward Scalable Terminal Task Synthesis via Skill Graphs
Toward Scalable Terminal Task Synthesis via Skill Graphs , author=. arXiv preprint arXiv:2604.25727 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
2026 , month = mar, day =
The Anatomy of an Agent Harness , author =. 2026 , month = mar, day =
2026
-
[15]
2026 , month = feb, day =
Harness Engineering: Leveraging Codex in an Agent-First World , author =. 2026 , month = feb, day =
2026
-
[16]
2026 , month = mar, day =
Harness Design for Long-Running Application Development , author =. 2026 , month = mar, day =
2026
-
[17]
Agent Skills Overview , author =
-
[18]
"Do Not Mention This to the User": Detecting and Understanding Malicious Agent Skills in the Wild
Malicious agent skills in the wild: A large-scale security empirical study , author=. arXiv preprint arXiv:2602.06547 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
21st USENIX Security Symposium (USENIX Security 12) , pages=
An evaluation of the google chrome extension security architecture , author=. 21st USENIX Security Symposium (USENIX Security 12) , pages=
-
[20]
2003 , institution=
Capability myths demolished , author=. 2003 , institution=
2003
-
[21]
ACM Transactions on Software Engineering and Methodology , volume=
Research directions in software supply chain security , author=. ACM Transactions on Software Engineering and Methodology , volume=. 2025 , publisher=
2025
-
[22]
IEEE software , volume=
Package management systems , author=. IEEE software , volume=. 2012 , publisher=
2012
-
[23]
Architectural patterns revisited-a pattern language , author=
-
[24]
Systems Engineering , volume=
The concept of reference architectures , author=. Systems Engineering , volume=. 2010 , publisher=
2010
-
[25]
2025 , note =
Equipping Agents for the Real World with Agent Skills , howpublished =. 2025 , note =
2025
-
[26]
2026 , note =
Awesome Agents , howpublished =. 2026 , note =
2026
-
[27]
2009 Joint Working IEEE/IFIP Conference on Software Architecture & European Conference on Software Architecture , pages=
A classification of software reference architectures: Analyzing their success and effectiveness , author=. 2009 Joint Working IEEE/IFIP Conference on Software Architecture & European Conference on Software Architecture , pages=. 2009 , organization=
2009
-
[28]
2022 , month = nov, number =
2022
-
[29]
Wu, Xiyang and Li, Zongxia and Shi, Guangyao and Duffy, Alexander and Marques, Tyler and Olson, Matthew Lyle and Zhou, Tianyi and Manocha, Dinesh , year = 2026, month = apr, number =. Co-. 2604.20987 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
From Skill Text to Skill Structure: The Scheduling-Structural-Logical Representation for Agent Skills , author=. arXiv preprint arXiv:2604.24026 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Wang, Jianing and Guo, Linsen and Chen, Zhengyu and Guo, Qi and Zang, Hongyu and Shi, Wenjie and Ma, Haoxiang and Xi, Xiangyu and Li, Xiaoyu and Wang, Wei and Cai, Xunliang , year = 2026, publisher =
2026
-
[32]
Skills as
Metere, Alfredo , year = 2026, publisher =. Skills as
2026
-
[33]
arXiv preprint arXiv:2601.21123 , year=
Cua-skill: Develop skills for computer using agent , author=. arXiv preprint arXiv:2601.21123 , year=
-
[34]
SkCC: Portable and Secure Skill Compilation for Cross-Framework LLM Agents
SkCC: Portable and Secure Skill Compilation for Cross-Framework LLM Agents , author=. arXiv preprint arXiv:2605.03353 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
ContractSkill: Repairable Contract-Based Skills for Multimodal Web Agents
ContractSkill: Repairable Contract-Based Skills for Multimodal Web Agents , author=. arXiv preprint arXiv:2603.20340 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
arXiv preprint arXiv:2504.06821 , year=
Inducing programmatic skills for agentic tasks , author=. arXiv preprint arXiv:2504.06821 , year=
-
[37]
FlowEvo: Self-Evolving Agents through the Co-Evolution of Workflows and Executable Skills , author=
-
[38]
Design Principles, and Architectural Patterns for Scalable Verification (January 07, 2026) , year=
Verifiability-First AI Engineering in the Era of AIware: A Conceptual Framework, Design Principles, and Architectural Patterns for Scalable Verification , author=. Design Principles, and Architectural Patterns for Scalable Verification (January 07, 2026) , year=
2026
-
[39]
Sealing the Audit-Runtime Gap for LLM Skills
Sealing the Audit-Runtime Gap for LLM Skills , author=. arXiv preprint arXiv:2605.05274 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
oxo-call: Documentation-grounded Skill Augmentation for Accurate Bioinformatics Command-line Generation with Large Language Models , author=. arXiv preprint arXiv:2604.12387 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
arXiv preprint arXiv:2512.23760 , year=
Audited Skill-Graph Self-Improvement for Agentic LLMs via Verifiable Rewards, Experience Synthesis, and Continual Memory , author=. arXiv preprint arXiv:2512.23760 , year=
-
[42]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Skillweaver: Web agents can self-improve by discovering and honing skills , author=. arXiv preprint arXiv:2504.07079 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Lifting Traces to Logic: Programmatic Skill Induction with Neuro-Symbolic Learning for Long-Horizon Agentic Tasks , author=. arXiv preprint arXiv:2605.01293 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
SkillOS: Learning Skill Curation for Self-Evolving Agents
SkillOS: Learning Skill Curation for Self-Evolving Agents , author=. arXiv preprint arXiv:2605.06614 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents , author=. arXiv preprint arXiv:2602.02474 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
SkillForge: Forging Domain-Specific, Self-Evolving Agent Skills in Cloud Technical Support
SkillForge: Forging Domain-Specific, Self-Evolving Agent Skills in Cloud Technical Support , author=. arXiv preprint arXiv:2604.08618 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning , author=. arXiv preprint arXiv:2605.06130 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
Trace2skill: Distill trajectory-local lessons into transferable agent skills , author=. arXiv preprint arXiv:2603.25158 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
arXiv preprint arXiv:2603.12056 , year=
Xskill: Continual learning from experience and skills in multimodal agents , author=. arXiv preprint arXiv:2603.12056 , year=
-
[50]
GraSP: Graph-Structured Skill Compositions for LLM Agents
GraSP: Graph-Structured Skill Compositions for LLM Agents , author=. arXiv preprint arXiv:2604.17870 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
2026 , month = may, day =
Designing, Refining, and Maintaining Agent Skills at Perplexity , author =. 2026 , month = may, day =
2026
-
[52]
Workshop on Multi-Agent Learning and Its Opportunities in the Era of Generative AI , year=
SkillTracer: Structural Failure Attribution and Refinement of Agentic Skills in Long-Horizon Web Tasks , author=. Workshop on Multi-Agent Learning and Its Opportunities in the Era of Generative AI , year=
-
[53]
Xiang, Keyi and Tang, Tianyi and Shao, Jie-Jing and Lyu, Yueming and Tsang, Ivor and Ong, Yew-Soon and Yin, Haiyan , booktitle =
-
[54]
Empirical software engineering , volume=
Guidelines for conducting and reporting case study research in software engineering , author=. Empirical software engineering , volume=. 2009 , publisher=
2009
-
[55]
Uncertainty Propagation in LLM-Based Systems
Uncertainty Propagation in LLM-Based Systems , author=. arXiv preprint arXiv:2604.23505 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
2024 , month = dec, url =
Building Effective Agents , author =. 2024 , month = dec, url =
2024
-
[57]
2026 , howpublished =
Skill Authoring Best Practices , author =. 2026 , howpublished =
2026
-
[58]
Progent: Securing AI Agents with Privilege Control
Progent: Programmable privilege control for llm agents , author=. arXiv preprint arXiv:2504.11703 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
International Conference on Learning Representations , volume=
Openhands: An open platform for ai software developers as generalist agents , author=. International Conference on Learning Representations , volume=
-
[61]
arXiv preprint arXiv:2411.05285 , year=
Agentops: Enabling observability of llm agents , author=. arXiv preprint arXiv:2411.05285 , year=
-
[62]
Understanding Automated Program Repair Agents Through the Lens of Traceability: An Empirical Study
Understanding Software Engineering Agents Through the Lens of Traceability: An Empirical Study , author=. arXiv preprint arXiv:2506.08311 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Natural-Language Agent Harnesses
Natural-language agent harnesses , author=. arXiv preprint arXiv:2603.25723 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
arXiv preprint arXiv:2603.02176 , year=
Organizing, orchestrating, and benchmarking agent skills at ecosystem scale , author=. arXiv preprint arXiv:2603.02176 , year=
-
[65]
Guanzhi Wang and Yuqi Xie and Yunfan Jiang and Ajay Mandlekar and Chaowei Xiao and Yuke Zhu and Linxi Fan and Anima Anandkumar , title =. Trans. Mach. Learn. Res. , volume =. 2024 , url =
2024
-
[66]
Agent Workflow Memory , booktitle =
Zora Zhiruo Wang and Jiayuan Mao and Daniel Fried and Graham Neubig , editor =. Agent Workflow Memory , booktitle =. 2025 , url =
2025
-
[67]
CoEvoSkills: Self-Evolving Agent Skills via Co-Evolutionary Verification
Coevoskills: Self-evolving agent skills via co-evolutionary verification , author=. arXiv preprint arXiv:2604.01687 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
EvoSkill: Automated Skill Discovery for Multi-Agent Systems
Evoskill: Automated skill discovery for multi-agent systems , author=. arXiv preprint arXiv:2603.02766 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution , author=. arXiv preprint arXiv:2605.18401 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
Harnessing LLM Agents with Skill Programs
Harnessing LLM Agents with Skill Programs , author=. arXiv preprint arXiv:2605.17734 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications , author=. arXiv preprint arXiv:2605.07358 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
SkillsBench: Benchmarking how well agent skills work across diverse tasks , author=. arXiv preprint arXiv:2602.12670 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
How Well Do Agentic Skills Work in the Wild: Benchmarking LLM Skill Usage in Realistic Settings
How well do agentic skills work in the wild: Benchmarking llm skill usage in realistic settings , author=. arXiv preprint arXiv:2604.04323 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
Counterfactual Trace Auditing of LLM Agent Skills
Counterfactual Trace Auditing of LLM Agent Skills , author=. arXiv preprint arXiv:2605.11946 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
Skill-Inject: Measuring Agent Vulnerability to Skill File Attacks
Skill-inject: Measuring agent vulnerability to skill file attacks , author=. arXiv preprint arXiv:2602.20156 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
How Your Credentials Are Leaked by LLM Agent Skills: An Empirical Study
Credential leakage in llm agent skills: A large-scale empirical study , author=. arXiv preprint arXiv:2604.03070 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.