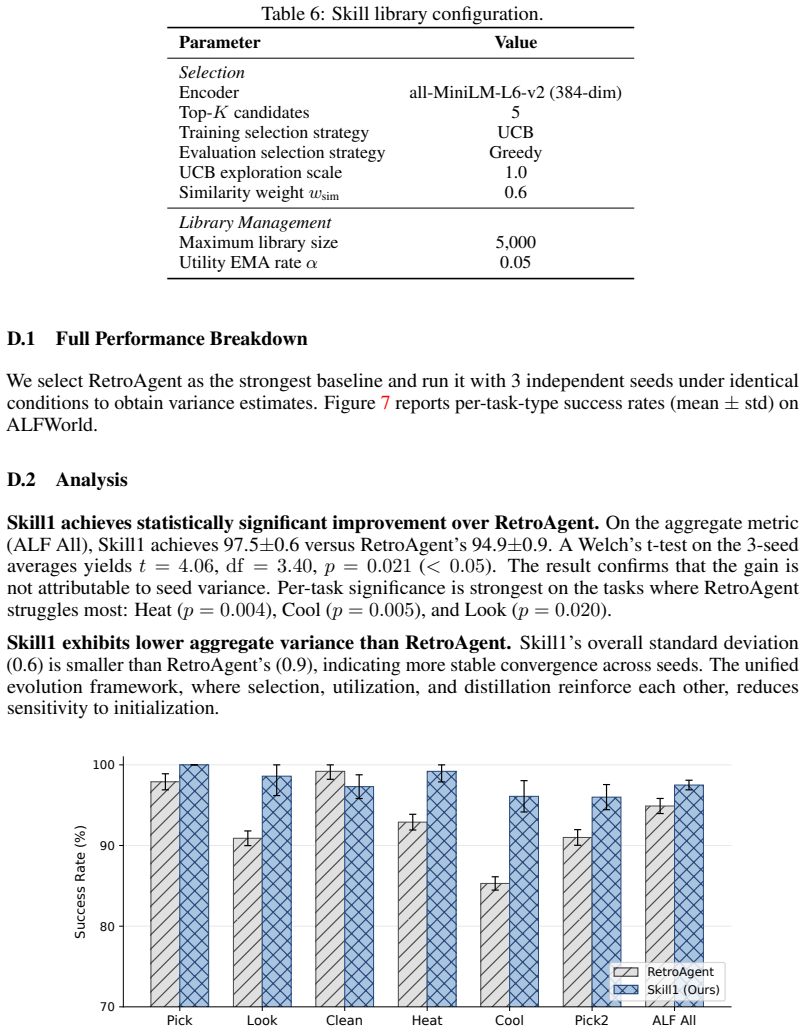
Recognition: no theorem link
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
Pith reviewed 2026-05-13 07:13 UTC · model grok-4.3
The pith
A single policy can co-evolve skill selection, utilization, and distillation from one task-outcome signal by separating its low-frequency trend and high-frequency variation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Skill1 is a framework in which one policy generates a query to search the skill library, re-ranks candidates to select one, solves the task conditioned on the chosen skill, and distills a new skill from the trajectory, with every update driven by a single task-outcome signal whose low-frequency trend supplies credit for selection and whose high-frequency variation supplies credit for distillation.
What carries the argument
The single RL policy that integrates query generation for skill retrieval, candidate re-ranking for selection, conditioned task execution, and trajectory-based distillation, with credit assignment performed by frequency decomposition of the shared outcome reward.
If this is right
- The three capabilities of selection, utilization, and distillation improve simultaneously during training under the shared objective.
- Skill1 outperforms prior skill-based methods and standard reinforcement-learning baselines on the ALFWorld and WebShop benchmarks.
- Removing the low-frequency credit signal or the high-frequency credit signal each degrades the co-evolution of the three capabilities.
- All learning, including skill library growth, derives from the single task-outcome signal without auxiliary rewards.
Where Pith is reading between the lines
- Skill libraries could expand more coherently across open-ended task sequences because selection and creation remain coupled through the same policy.
- The frequency-separation idea for credit assignment might transfer to other agent settings that require learning at multiple timescales.
- Less hand-designed reward engineering may be needed for long-term skill management if one outcome signal suffices for all three functions.
Load-bearing premise
The low-frequency trend and high-frequency variation of one task-outcome signal can be cleanly separated to supply non-conflicting credits for skill selection versus distillation.
What would settle it
An experiment in which the low- and high-frequency components of the outcome signal overlap strongly, so that ablating either component produces no performance drop relative to training selection and distillation with separate rewards.
Figures







read the original abstract
A persistent skill library allows language model agents to reuse successful strategies across tasks. Maintaining such a library requires three coupled capabilities. The agent selects a relevant skill, utilizes it during execution, and distills new skills from experience. Existing methods optimize these capabilities in isolation or with separate reward sources, resulting in partial and conflicting evolution. We propose Skill1, a framework that trains a single policy to co-evolve skill selection, utilization, and distillation toward a shared task-outcome objective. The policy generates a query to search the skill library, re-ranks candidates to select one, solves the task conditioned on it, and distills a new skill from the trajectory. All learning derives from a single task-outcome signal. Its low-frequency trend credits selection and its high-frequency variation credits distillation. Experiments on ALFWorld and WebShop show that Skill1 outperforms prior skill-based and reinforcement learning baselines. Training dynamics confirm the co-evolution of the three capabilities, and ablations show that removing any credit signal degrades the evolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Skill1, a unified RL framework in which a single policy co-evolves three capabilities—skill selection (via query generation and re-ranking), utilization, and distillation—by deriving all credit from one scalar task-outcome signal. Low-frequency trends of this signal are used to credit selection while high-frequency variations credit distillation; the policy is trained end-to-end on ALFWorld and WebShop, outperforming prior skill-based and RL baselines, with ablations confirming degradation when either frequency component is removed.
Significance. If the frequency-based credit separation can be shown to remain non-conflicting under the joint optimization and sparse-reward conditions of the target domains, the work would offer a parameter-free mechanism for maintaining coherent skill libraries without separate reward engineering. The reported outperformance and co-evolution dynamics would then constitute a concrete advance over methods that optimize the three capabilities in isolation.
major comments (3)
- [Abstract and §3] Abstract and §3 (Method): the claim that low-frequency trends cleanly credit selection while high-frequency variations credit distillation is load-bearing for the central contribution, yet no concrete filter (moving average, spectral cutoff, etc.), stationarity assumptions, or gradient-flow analysis is provided. In sparse-reward settings such as ALFWorld, any practical decomposition risks mixing selection and distillation gradients once utilization updates alter the trajectory distribution.
- [§4] §4 (Experiments): the ablation results that remove credit signals are reported without error bars, statistical significance tests, or exact implementation details of the frequency extraction. This prevents verification that the observed degradation is attributable to loss of the claimed credit separation rather than implementation artifacts.
- [§3.2] §3.2 (Policy architecture): the joint optimization over query-generation, re-ranking, utilization, and distillation heads creates an entanglement risk that is not analyzed; updates to the utilization head necessarily change the distribution of trajectories whose outcome signal is then decomposed for the other heads.
minor comments (2)
- [§3] Notation for the frequency decomposition (e.g., symbols for low- and high-pass components) should be introduced once and used consistently throughout the method and analysis sections.
- [§3] The manuscript would benefit from a short pseudocode listing the exact sequence of query generation, skill retrieval, execution, outcome extraction, and frequency-based credit assignment.
Simulated Author's Rebuttal
We thank the referee for the detailed and insightful comments on our manuscript. We address each major comment below and have made revisions to strengthen the paper accordingly.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): the claim that low-frequency trends cleanly credit selection while high-frequency variations credit distillation is load-bearing for the central contribution, yet no concrete filter (moving average, spectral cutoff, etc.), stationarity assumptions, or gradient-flow analysis is provided. In sparse-reward settings such as ALFWorld, any practical decomposition risks mixing selection and distillation gradients once utilization updates alter the trajectory distribution.
Authors: We agree that providing concrete implementation details is essential for reproducibility and to substantiate the central claim. In the revised manuscript, we specify the frequency decomposition method as an exponential moving average with a smoothing factor of 0.9 for the low-frequency trend, with the high-frequency component derived as the residual. We include a brief analysis of the gradient flow, demonstrating that selection gradients are computed at the episode level using the low-frequency signal, while distillation uses per-step high-frequency variations, minimizing interference in sparse-reward environments. Stationarity is assumed over short task horizons, which holds in our experimental setups. We have added this to §3. revision: yes
-
Referee: [§4] §4 (Experiments): the ablation results that remove credit signals are reported without error bars, statistical significance tests, or exact implementation details of the frequency extraction. This prevents verification that the observed degradation is attributable to loss of the claimed credit separation rather than implementation artifacts.
Authors: We acknowledge the need for rigorous statistical reporting. In the revision, we have added error bars representing standard deviation over 5 random seeds for all ablation results. We performed paired t-tests to confirm statistical significance of the performance drops (p < 0.05). Additionally, we provide the exact hyperparameters for the frequency extraction in the appendix, including the moving average parameters and how residuals are computed. revision: yes
-
Referee: [§3.2] §3.2 (Policy architecture): the joint optimization over query-generation, re-ranking, utilization, and distillation heads creates an entanglement risk that is not analyzed; updates to the utilization head necessarily change the distribution of trajectories whose outcome signal is then decomposed for the other heads.
Authors: This is a valid concern regarding potential distribution shift during joint training. We have added a new subsection in §3.2 analyzing this entanglement risk. We show that by alternating updates or using a replay buffer for trajectory sampling, the distribution changes are mitigated. Additional experiments in the revision demonstrate that the co-evolution remains coherent, with skill selection accuracy improving steadily despite utilization updates. revision: yes
Circularity Check
No significant circularity in Skill1 derivation chain
full rationale
The paper's central mechanism extracts credit signals for skill selection and distillation by frequency decomposition of an external task-outcome reward. This is a direct methodological assignment applied to an observed scalar signal rather than a quantity defined in terms of itself or a fitted parameter relabeled as a prediction. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the provided derivation. The co-evolution claim rests on the joint policy optimization under the shared signal, which remains falsifiable against external benchmarks such as ALFWorld and WebShop performance.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A single policy can simultaneously optimize skill selection, utilization, and distillation when credit is assigned via low-frequency trends for selection and high-frequency variation for distillation from one task-outcome signal.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Qwen2.5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Journal of artificial intelligence research , volume=
Reinforcement learning: A survey , author=. Journal of artificial intelligence research , volume=
-
[7]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[9]
International Conference on Machine Learning , pages=
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training , author=. International Conference on Machine Learning , pages=. 2025 , organization=
work page 2025
-
[10]
IEEE Transactions on Robotics , volume=
Partially observable markov decision processes in robotics: A survey , author=. IEEE Transactions on Robotics , volume=. 2022 , publisher=
work page 2022
-
[11]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Group-in-Group Policy Optimization for LLM Agent Training , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[14]
arXiv preprint arXiv:2512.16848 , year=
Meta-RL Induces Exploration in Language Agents , author=. arXiv preprint arXiv:2512.16848 , year=
-
[15]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[17]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models , author=. arXiv preprint arXiv:2501.03262 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Skillrl: Evolving agents via recursive skill-augmented reinforcement learning , author=. arXiv preprint arXiv:2602.08234 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Yu Li, Rui Miao, Zhengling Qi, and Tian Lan
Arise: Agent reasoning with intrinsic skill evolution in hierarchical reinforcement learning , author=. arXiv preprint arXiv:2603.16060 , year=
-
[20]
Complementary reinforcement learning.arXiv preprint arXiv:2603.17621, 2026
Complementary Reinforcement Learning , author=. arXiv preprint arXiv:2603.17621 , year=
-
[21]
arXiv preprint arXiv:2603.08561 , year=
RetroAgent: From Solving to Evolving via Retrospective Dual Intrinsic Feedback , author=. arXiv preprint arXiv:2603.08561 , year=
-
[22]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory , author=. arXiv preprint arXiv:2511.20857 , year=
work page internal anchor Pith review arXiv
-
[23]
Exgrpo: Learning to reason from experience
Exgrpo: Learning to reason from experience , author=. arXiv preprint arXiv:2510.02245 , year=
-
[24]
arXiv preprint arXiv:2603.16856 , year=
Online Experiential Learning for Language Models , author=. arXiv preprint arXiv:2603.16856 , year=
-
[25]
Memory Intelligence Agent , author=. arXiv preprint arXiv:2604.04503 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
arXiv preprint arXiv:2603.08068 , year=
In-Context Reinforcement Learning for Tool Use in Large Language Models , author=. arXiv preprint arXiv:2603.08068 , year=
-
[27]
arXiv preprint arXiv:2603.01145 , year=
AutoSkill: Experience-Driven Lifelong Learning via Skill Self-Evolution , author=. arXiv preprint arXiv:2603.01145 , year=
-
[28]
XSkill: Continual Learning from Experience and Skills in Multimodal Agents , author=. arXiv preprint arXiv:2603.12056 , year=
-
[29]
arXiv preprint arXiv:2603.28088 , year=
GEMS: Agent-Native Multimodal Generation with Memory and Skills , author=. arXiv preprint arXiv:2603.28088 , year=
-
[30]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
SkillsBench: Benchmarking how well agent skills work across diverse tasks , author=. arXiv preprint arXiv:2602.12670 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
arXiv preprint arXiv:2602.19672 , year=
SkillOrchestra: Learning to Route Agents via Skill Transfer , author=. arXiv preprint arXiv:2602.19672 , year=
-
[32]
SoK: Agentic Skills -- Beyond Tool Use in LLM Agents
SoK: Agentic Skills--Beyond Tool Use in LLM Agents , author=. arXiv preprint arXiv:2602.20867 , year=
work page internal anchor Pith review arXiv
-
[33]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
Agent skills for large language models: Architecture, acquisition, security, and the path forward , author=. arXiv preprint arXiv:2602.12430 , year=
work page internal anchor Pith review arXiv
-
[34]
arXiv preprint arXiv:2603.18718 , year=
MemMA: Coordinating the Memory Cycle through Multi-Agent Reasoning and In-Situ Self-Evolution , author=. arXiv preprint arXiv:2603.18718 , year=
-
[35]
arXiv preprint arXiv:2604.01599 , year=
ByteRover: Agent-Native Memory Through LLM-Curated Hierarchical Context , author=. arXiv preprint arXiv:2604.01599 , year=
-
[36]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[37]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Expel: Llm agents are experiential learners , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[39]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0: Building production-ready ai agents with scalable long-term memory , author=. arXiv preprint arXiv:2504.19413 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning , booktitle =
Mohit Shridhar and Xingdi Yuan and Marc. ALFWorld: Aligning Text and Embodied Environments for Interactive Learning , booktitle =
-
[41]
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , volume =
Yao, Shunyu and Chen, Howard and Yang, John and Narasimhan, Karthik , booktitle =. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , volume =
-
[42]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Text embeddings by weakly-supervised contrastive pre-training , author=. arXiv preprint arXiv:2212.03533 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [43]
-
[44]
Reinforcement learning for self-improving agent with skill library , author=. arXiv preprint arXiv:2512.17102 , year=
-
[45]
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization , author=. arXiv preprint arXiv:2604.02268 , year=
-
[46]
Intrinsically-Motivated and Open-Ended Learning Workshop@ NeurIPS2023 , year=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. Intrinsically-Motivated and Open-Ended Learning Workshop@ NeurIPS2023 , year=
-
[47]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents , author=. arXiv preprint arXiv:2602.02474 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Evolver: Self-evolving llm agents through an experience-driven lifecycle , author=. arXiv preprint arXiv:2510.16079 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Memrl: Self-evolving agents via runtime reinforcement learning on episodic memory , author=. arXiv preprint arXiv:2601.03192 , year=
-
[50]
arXiv preprint arXiv:2601.02553 , year=
SimpleMem: Efficient Lifelong Memory for LLM Agents , author=. arXiv preprint arXiv:2601.02553 , year=
-
[51]
Retroformer: Retrospective large language agents with policy gradient optimization
Retroformer: Retrospective large language agents with policy gradient optimization , author=. arXiv preprint arXiv:2308.02151 , year=
-
[52]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[53]
arXiv preprint arXiv:2601.12538 , year=
Agentic reasoning for large language models , author=. arXiv preprint arXiv:2601.12538 , year=
-
[54]
Advances in neural information processing systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in neural information processing systems , volume=
-
[55]
Forty-second International Conference on Machine Learning Position Paper Track , year=
Position: Truly Self-Improving Agents Require Intrinsic Metacognitive Learning , author=. Forty-second International Conference on Machine Learning Position Paper Track , year=
-
[56]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[58]
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
work page 1992
- [59]
-
[60]
International Conference on Machine Learning , pages=
ArCHer: Training Language Model Agents via Hierarchical Multi-Turn RL , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[61]
Agent q: Advanced reasoning and learning for autonomous ai agents , author=. arXiv preprint arXiv:2408.07199 , year=
-
[62]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , pages=
Trial and Error: Exploration-Based Trajectory Optimization of LLM Agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , pages=
-
[63]
Skillnet: Create, evaluate, and connect ai skills.arXiv preprint arXiv:2603.04448,
SkillNet: Create, Evaluate, and Connect AI Skills , author=. arXiv preprint arXiv:2603.04448 , year=
-
[64]
Organizing, orchestrating, and benchmarking agent skills at ecosystem scale, 2026
Organizing, Orchestrating, and Benchmarking Agent Skills at Ecosystem Scale , author=. arXiv preprint arXiv:2603.02176 , year=
-
[65]
arXiv preprint arXiv:2509.25123 , year=
From f (x) and g (x) to f (g (x)) : LLMs Learn New Skills in RL by Composing Old Ones , author=. arXiv preprint arXiv:2509.25123 , year=
-
[66]
Agentic Proposing: Enhancing Large Language Model Reasoning via Compositional Skill Synthesis , author=. arXiv preprint arXiv:2602.03279 , year=
-
[67]
Memento: Fine-tuning LLM agents without fine-tuning LLMs.arXiv, 2025
Memento: Fine-tuning llm agents without fine-tuning llms , author=. arXiv preprint arXiv:2508.16153 , year=
-
[68]
Memp: Exploring Agent Procedural Memory
MemP: Exploring Agent Procedural Memory , author=. arXiv preprint arXiv:2508.06433 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive NLP tasks , author=. Advances in neural information processing systems , volume=
-
[70]
International Conference on Machine Learning , pages=
Retrieval-augmented reinforcement learning , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[71]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[72]
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
The landscape of agentic reinforcement learning for LLMs: A survey , author=. arXiv preprint arXiv:2509.02547 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [73]
-
[74]
Finite-time analysis of the multiarmed bandit problem , author=. Machine learning , volume=. 2002 , publisher=
work page 2002
-
[75]
Psychological review , volume=
Acquisition of cognitive skill , author=. Psychological review , volume=. 1982 , publisher=
work page 1982
-
[76]
Transactions on Machine Learning Research , year=
Emergent Abilities of Large Language Models , author=. Transactions on Machine Learning Research , year=
-
[77]
Advances in Neural Information Processing Systems , volume=
A definition of continual reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
The Twelfth International Conference on Learning Representations , year=
Understanding the Effects of RLHF on LLM Generalisation and Diversity , author=. The Twelfth International Conference on Learning Representations , year=
-
[79]
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
work page 2024
-
[80]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Search and Refine During Think: Facilitating Knowledge Refinement for Improved Retrieval-Augmented Reasoning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.