Error-Conditioned Neural Solvers
Pith reviewed 2026-06-26 04:52 UTC · model grok-4.3
The pith
Neural PDE solvers improve accuracy by reading their residual fields as input instead of minimizing those residuals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
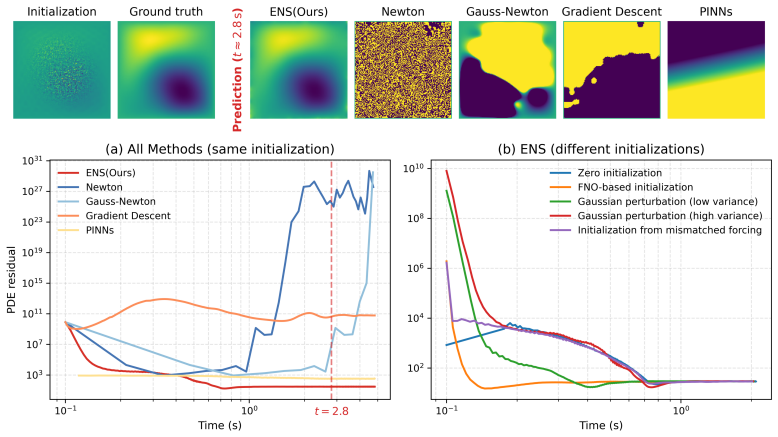
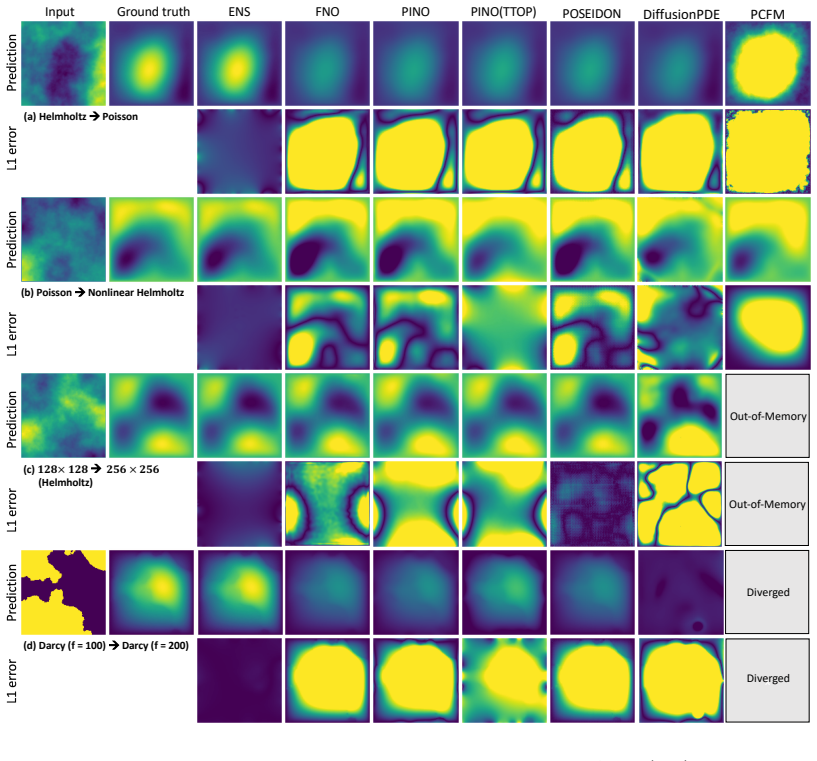
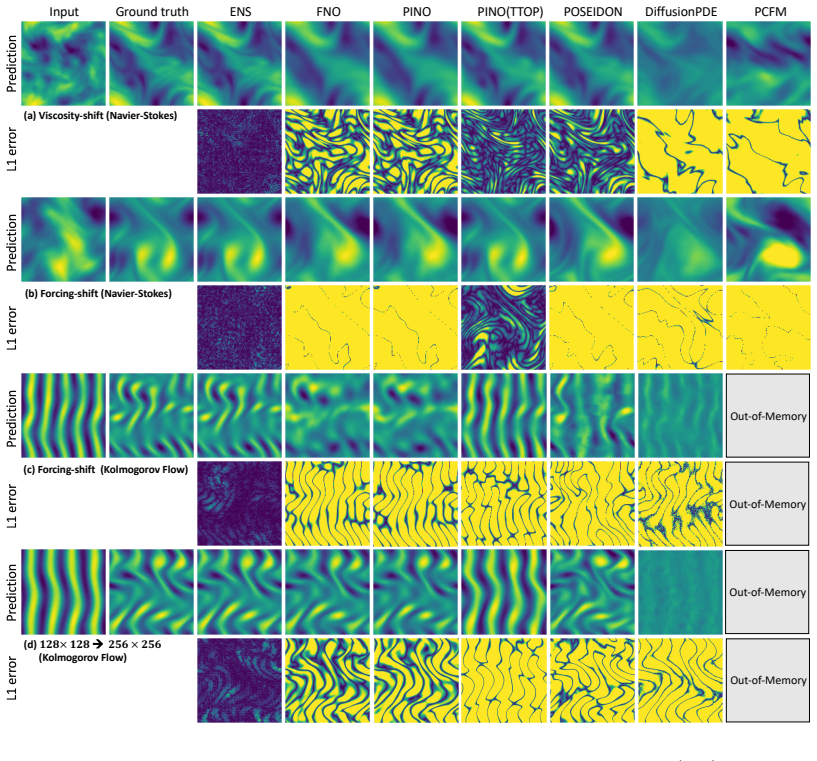
We show theoretically and empirically that minimizing the PDE residual is an unreliable proxy for solution accuracy in ill-conditioned regimes. Error-conditioned Neural Solvers instead feed the residual field directly to the network at each step, enabling it to learn a correction policy that attains the highest accuracy across four PDE families, with gains up to 10× on turbulent Kolmogorov flow, and that generalizes under distribution shift where residual minimization is least reliable.
What carries the argument
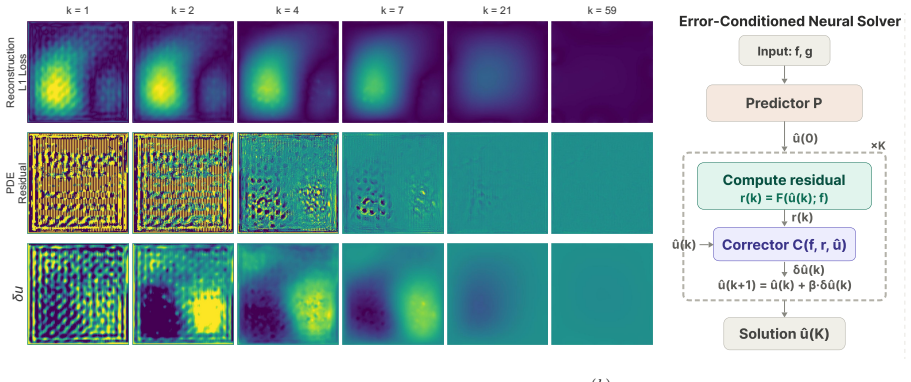
Error-conditioned Neural Solvers (ENS), a network that receives the PDE residual field as direct input to learn an iterative update policy.
If this is right
- ENS reaches highest prediction accuracy in the large majority of tested settings.
- Gains reach 10× on turbulent Kolmogorov flow while using less compute than hybrid methods.
- The learned correction policy generalizes to zero-shot parameter changes and cross-equation transfer.
- Relative advantage is largest precisely in the ill-conditioned regimes where residual minimization performs worst.
Where Pith is reading between the lines
- The same conditioning idea could be applied to iterative refinement in other domains such as optimization or control where error fields are observable.
- If the correction policy proves stable, it may reduce reliance on expensive physics-informed fine-tuning loops in surrogate modeling.
- The approach suggests testing whether residual conditioning also improves long-horizon rollouts in time-dependent PDEs beyond the single-step corrections shown.
Load-bearing premise
Supplying the PDE residual field as direct input lets the network learn a correction policy that is more reliable than residual minimization, especially in ill-conditioned systems.
What would settle it
A controlled test on an ill-conditioned PDE where an ENS model produces lower residuals than a residual-minimization baseline yet higher pointwise error on held-out solutions.
Figures

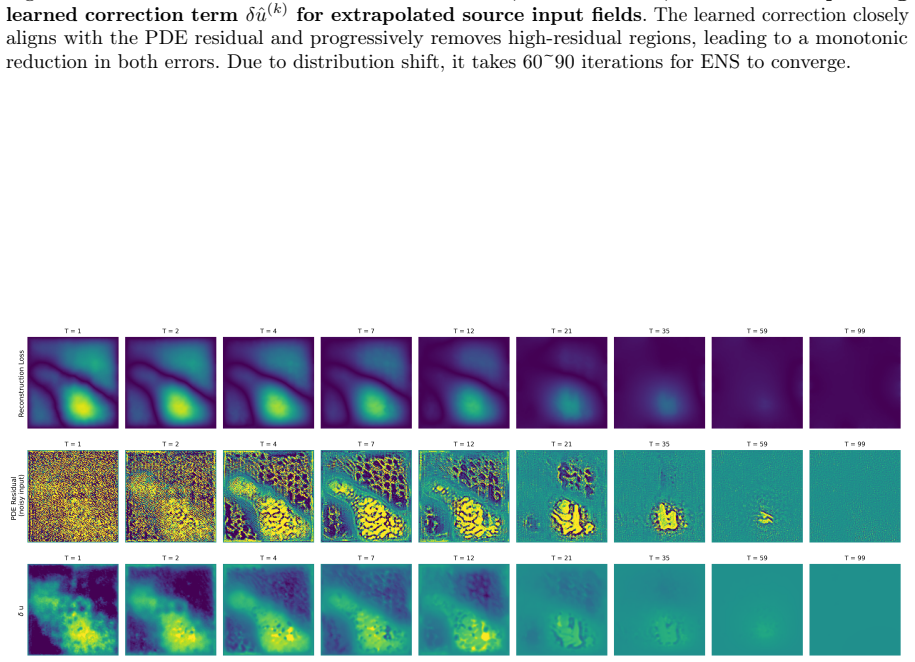
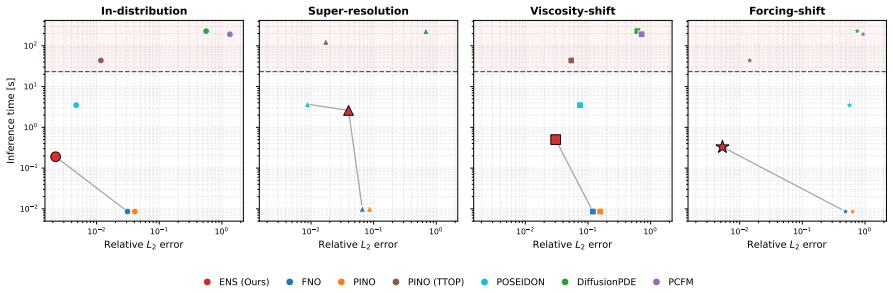
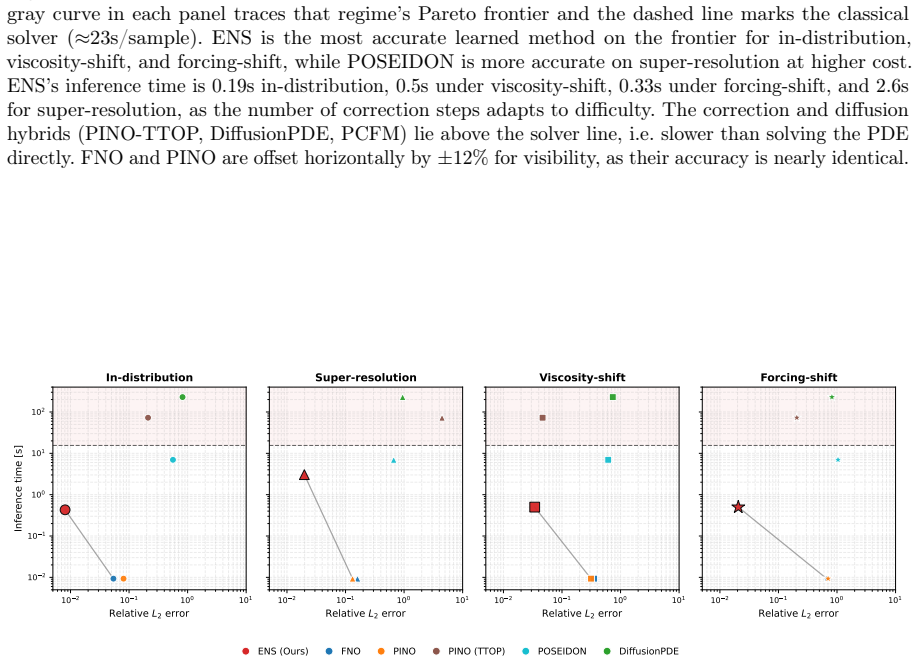
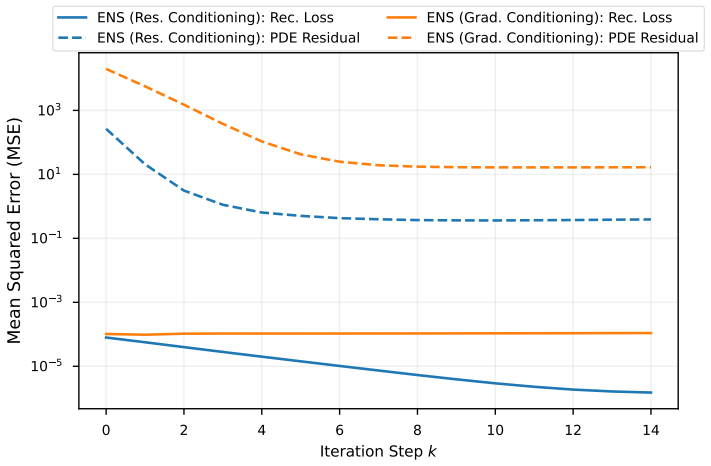
read the original abstract
Neural surrogate models offer fast approximate mappings from PDE parameters to solutions, but they typically treat solving as a purely statistical task: once trained, they struggle to correct their own constraint violations and extrapolate beyond the training distribution. Recent hybrid methods promote physical correctness by targeting the PDE residual via gradient descent or Gauss--Newton steps, but inherit the compute cost and instability of the underlying classical optimizers. We show, theoretically and empirically, that numerically minimizing the PDE residual can be an unreliable proxy for reconstruction accuracy in ill-conditioned systems, explaining why these methods often do not make accurate predictions despite achieving low residuals. We propose error-conditioned Neural Solvers (ENS), built on a different principle: rather than an optimization target, the PDE residual field is passed as a direct input to the network at each iteration, enabling it to read the spatial structure of its own errors and learn an update policy to iteratively correct its predictions. Across four PDE families, ENS attains the highest prediction accuracy in the large majority of settings, with gains reaching $10\times$ on turbulent Kolmogorov flow, while avoiding the expensive compute cost of hybrid methods. ENS's learned correction policy generalizes under distribution shift, including zero-shot parameter changes and cross-equation transfer, where its relative advantage is largest in the ill-conditioned regimes where residual minimization is least reliable. Project website: https://neuralsolver.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Error-Conditioned Neural Solvers (ENS) for neural PDE approximation. It argues theoretically that residual minimization is an unreliable proxy for reconstruction accuracy in ill-conditioned regimes, then proposes feeding the residual field directly as network input to learn an iterative correction policy. Experiments across four PDE families (including turbulent Kolmogorov flow) report that ENS achieves highest accuracy in most settings, with up to 10× gains over baselines, lower compute than hybrid optimizers, and improved generalization under parameter shifts and cross-equation transfer.
Significance. If the theoretical distinction and empirical gains hold under the reported controls, the work offers a practical advance over both pure neural surrogates and residual-minimization hybrids by demonstrating a learned correction mechanism that is both more accurate and cheaper at inference. The zero-shot transfer results in ill-conditioned regimes are a particular strength, as they suggest the approach may scale to settings where classical residual methods degrade.
major comments (2)
- [§3.1] §3.1, Eq. (7): the claim that residual minimization is 'unreliable' rests on the condition-number argument, but the derivation assumes the error operator is exactly the inverse of the linearized residual operator; this equivalence should be stated explicitly or relaxed with a counter-example when the discretization is nonlinear.
- [§5.3] §5.3, Table 4: the cross-equation transfer results show ENS advantage largest on ill-conditioned cases, yet the table does not report the condition numbers of the target equations or the precise distribution-shift magnitude; without these, it is difficult to confirm that the relative gain scales with ill-conditioning as asserted.
minor comments (3)
- [§4.2] §4.2: the description of the residual encoder architecture is terse; adding the precise channel count and activation after the residual concatenation would aid reproducibility.
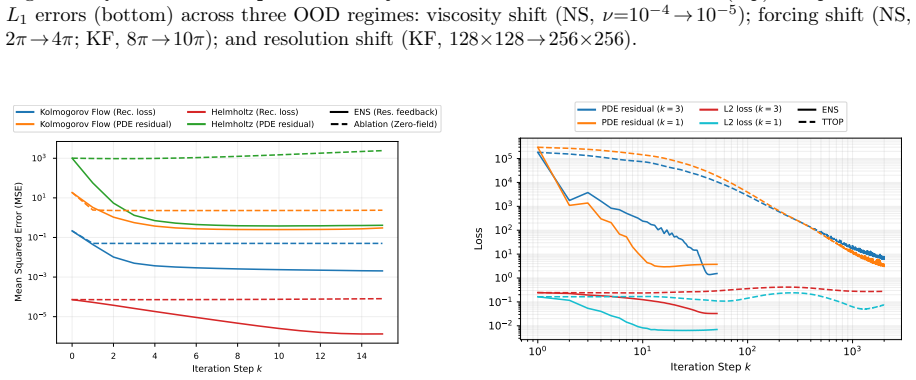
- [Figure 5] Figure 5: the error-vs-iteration curves for ENS and the hybrid baseline use different y-axis scales; uniform scaling would make the 10× claim visually clearer.
- The project website link is given but the repository does not yet contain the exact training seeds or the Kolmogorov-flow mesh files used for the 10× result.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation of minor revision. We address each major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.1] §3.1, Eq. (7): the claim that residual minimization is 'unreliable' rests on the condition-number argument, but the derivation assumes the error operator is exactly the inverse of the linearized residual operator; this equivalence should be stated explicitly or relaxed with a counter-example when the discretization is nonlinear.
Authors: We agree that the derivation in Section 3.1 and Equation (7) is presented for the linear operator case, where the reconstruction error is exactly the inverse of the residual operator scaled by the condition number. For nonlinear discretizations the relationship holds only locally. We will revise the text to state this assumption explicitly and note that the argument applies approximately for the mildly nonlinear regimes examined in our experiments (e.g., the Navier–Stokes cases). No counter-example is required because the central claim concerns ill-conditioned linear or locally linear operators; the clarification will make the scope precise. revision: yes
-
Referee: [§5.3] §5.3, Table 4: the cross-equation transfer results show ENS advantage largest on ill-conditioned cases, yet the table does not report the condition numbers of the target equations or the precise distribution-shift magnitude; without these, it is difficult to confirm that the relative gain scales with ill-conditioning as asserted.
Authors: We concur that reporting the condition numbers and quantifying the distribution-shift magnitudes would improve interpretability. In the revised manuscript we will augment Table 4 with the condition numbers of each target equation and add a sentence in the table caption (or §5.3) describing the precise parameter ranges used for the shifts. revision: yes
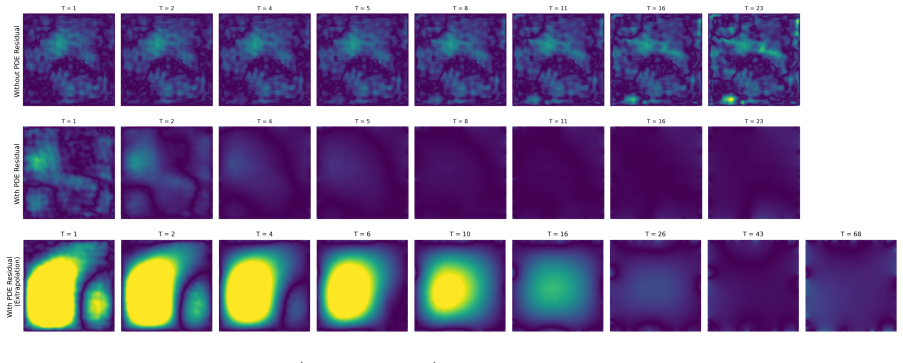
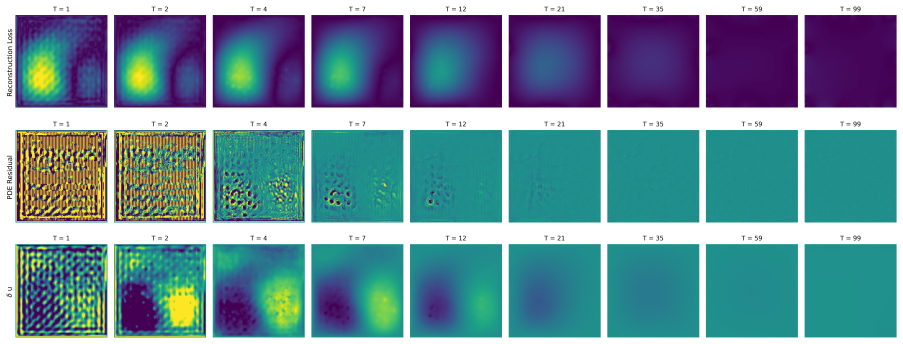
Circularity Check
No significant circularity detected
full rationale
The paper proposes ENS by passing the PDE residual field directly as network input to learn an iterative correction policy, contrasting it with residual-minimization hybrids. No load-bearing step reduces by the paper's own equations or self-citations to a fitted input renamed as prediction, a self-definitional loop, or an ansatz smuggled via prior work by the same authors. The claimed theoretical demonstration that residual minimization is unreliable in ill-conditioned regimes is presented as an independent argument supported by experiments across PDE families, without equations that equate the ENS update rule to its own training objective by construction. The generalization claims under distribution shift are framed as empirical outcomes rather than tautological renamings. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Science , volume=
Hydrodynamic stability without eigenvalues , author=. Science , volume=. 1993 , publisher=
1993
-
[2]
Advances in Neural Information Processing Systems , volume=
Pde-refiner: Achieving accurate long rollouts with neural pde solvers , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Advances in neural information processing systems , volume=
Deep equilibrium models , author=. Advances in neural information processing systems , volume=
-
[4]
Advances in neural information processing systems , volume=
Learning to learn by gradient descent by gradient descent , author=. Advances in neural information processing systems , volume=
-
[5]
arXiv preprint arXiv:2312.15796 , year=
Gencast: Diffusion-based ensemble forecasting for medium-range weather , author=. arXiv preprint arXiv:2312.15796 , year=
-
[6]
arXiv preprint arXiv:2110.06197 , year=
Crystal diffusion variational autoencoder for periodic material generation , author=. arXiv preprint arXiv:2110.06197 , year=
-
[7]
International conference on machine learning , pages=
Equivariant diffusion for molecule generation in 3d , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[8]
Journal of Computational Physics , volume=
Residual-based error correction for neural operator accelerated infinite-dimensional Bayesian inverse problems , author=. Journal of Computational Physics , volume=. 2023 , publisher=
2023
-
[9]
2006 , publisher =
Numerical Optimization , author =. 2006 , publisher =
2006
-
[10]
2022 , eprint=
Palette: Image-to-Image Diffusion Models , author=. 2022 , eprint=
2022
-
[11]
2011 , publisher =
Newton Methods for Nonlinear Problems: Affine Invariance and Adaptive Algorithms , author =. 2011 , publisher =
2011
-
[12]
arXiv preprint arXiv:2512.01370 , year=
Beyond Loss Guidance: Using PDE Residuals as Spectral Attention in Diffusion Neural Operators , author=. arXiv preprint arXiv:2512.01370 , year=
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Physicscorrect: A training-free approach for stable neural pde simulations , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
INC: An Indirect Neural Corrector for Auto-Regressive Hybrid PDE Solvers , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Computer Methods in Applied Mechanics and Engineering , volume=
Residual-based error corrector operator to enhance accuracy and reliability of neural operator surrogates of nonlinear variational boundary-value problems , author=. Computer Methods in Applied Mechanics and Engineering , volume=. 2024 , publisher=
2024
-
[16]
Nature Computational Science , volume=
Structure-based drug design with equivariant diffusion models , author=. Nature Computational Science , volume=. 2024 , publisher=
2024
-
[17]
International Conference on Learning Representations , volume=
Gradient-free generation for hard-constrained systems , author=. International Conference on Learning Representations , volume=
-
[18]
Nature , volume=
De novo design of protein structure and function with RFdiffusion , author=. Nature , volume=. 2023 , publisher=
2023
-
[19]
Advances in neural information processing systems , volume=
Elucidating the design space of diffusion-based generative models , author=. Advances in neural information processing systems , volume=
-
[20]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[21]
2003 , publisher=
Iterative methods for sparse linear systems , author=. 2003 , publisher=
2003
-
[22]
Advances in Neural Information Processing Systems , volume=
Constrained synthesis with projected diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Fourier Neural Operator for Parametric Partial Differential Equations
Fourier neural operator for parametric partial differential equations , author=. arXiv preprint arXiv:2010.08895 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[24]
SIAM Journal on Scientific Computing , volume=
Cocogen: Physically consistent and conditioned score-based generative models for forward and inverse problems , author=. SIAM Journal on Scientific Computing , volume=. 2025 , publisher=
2025
-
[25]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[26]
Deeponet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators , author=. arXiv preprint arXiv:1910.03193 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[27]
Denoising Diffusion Implicit Models
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[28]
Nature machine intelligence , volume=
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators , author=. Nature machine intelligence , volume=. 2021 , publisher=
2021
-
[29]
Journal of Computational physics , volume=
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations , author=. Journal of Computational physics , volume=. 2019 , publisher=
2019
-
[30]
Encyclopedia of continuum mechanics , pages=
Boundary element methods , author=. Encyclopedia of continuum mechanics , pages=. 2020 , publisher=
2020
-
[31]
2005 , publisher=
Partial differential equations and the finite element method , author=. 2005 , publisher=
2005
-
[32]
arXiv preprint arXiv:2506.13754 , year=
Videopde: Unified generative pde solving via video inpainting diffusion models , author=. arXiv preprint arXiv:2506.13754 , year=
-
[33]
ACM/IMS Journal of Data Science , volume=
Physics-informed neural operator for learning partial differential equations , author=. ACM/IMS Journal of Data Science , volume=. 2024 , publisher=
2024
-
[34]
arXiv preprint arXiv:2506.04171 , year=
Physics-constrained flow matching: Sampling generative models with hard constraints , author=. arXiv preprint arXiv:2506.04171 , year=
-
[35]
Advances in Neural Information Processing Systems , volume=
Poseidon: Efficient foundation models for pdes , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Advances in Neural Information Processing Systems , volume=
DiffusionPDE: Generative PDE-solving under partial observation , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Zoedepth: Zero-shot transfer by combining relative and metric depth , author=. arXiv preprint arXiv:2302.12288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Advances in Neural Information Processing Systems , volume=
Diffusion forcing: Next-token prediction meets full-sequence diffusion , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Advances in Neural Information Processing Systems , year=
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks , author=. Advances in Neural Information Processing Systems , year=
-
[40]
arXiv preprint arXiv:2409.18124 , year=
Lotus: Diffusion-based visual foundation model for high-quality dense prediction , author=. arXiv preprint arXiv:2409.18124 , year=
-
[41]
Communications of the ACM , volume=
Nerf: Representing scenes as neural radiance fields for view synthesis , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[42]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Putting nerf on a diet: Semantically consistent few-shot view synthesis , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[43]
Stereo Magnification: Learning View Synthesis using Multiplane Images
Stereo magnification: Learning view synthesis using multiplane images , author=. arXiv preprint arXiv:1805.09817 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[45]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Mvimgnet: A large-scale dataset of multi-view images , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[46]
2014 IEEE Conference on Computer Vision and Pattern Recognition , pages=
Large scale multi-view stereopsis evaluation , author=. 2014 IEEE Conference on Computer Vision and Pattern Recognition , pages=. 2014 , organization=
2014
-
[47]
arXiv , year=
ReconFusion: 3D Reconstruction with Diffusion Priors , author=. arXiv , year=
-
[48]
ICCV , year=
Zip-NeRF: Anti-Aliased Grid-Based Neural Radiance Fields , author=. ICCV , year=
-
[49]
arXiv preprint arXiv:2310.17994 , year=
Sargent, Kyle and Li, Zizhang and Shah, Tanmay and Herrmann, Charles and Yu, Hong-Xing and Zhang, Yunzhi and Chan, Eric Ryan and Lagun, Dmitry and Fei-Fei, Li and Sun, Deqing and Wu, Jiajun , title =. arXiv preprint arXiv:2310.17994 , year=
-
[50]
ACM Transactions on Graphics (TOG) , year=
Local Light Field Fusion: Practical View Synthesis with Prescriptive Sampling Guidelines , author=. ACM Transactions on Graphics (TOG) , year=
-
[51]
arXiv preprint arXiv:2410.24207 , year=
No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images , author=. arXiv preprint arXiv:2410.24207 , year=
-
[52]
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
Splatt3r: Zero-shot gaussian splatting from uncalibrated image pairs , author=. arXiv preprint arXiv:2408.13912 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Learning to Render Novel Views from Wide-Baseline Stereo Pairs , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[54]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[55]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[56]
arXiv preprint arXiv:2312.07246 , year=
Unifying correspondence, pose and nerf for pose-free novel view synthesis from stereo pairs , author=. arXiv preprint arXiv:2312.07246 , year=
-
[57]
European Conference on Computer Vision , pages=
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[58]
European Conference on Computer Vision , pages=
Sv3d: Novel multi-view synthesis and 3d generation from a single image using latent video diffusion , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[59]
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
Cat3d: Create anything in 3d with multi-view diffusion models , author=. arXiv preprint arXiv:2405.10314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
MVDream: Multi-view Diffusion for 3D Generation
Mvdream: Multi-view diffusion for 3d generation , author=. arXiv preprint arXiv:2308.16512 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Zero-1-to-3: Zero-shot one image to 3d object , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[62]
European Conference on Computer Vision , pages=
Grounding image matching in 3d with mast3r , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[63]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
pixelnerf: Neural radiance fields from one or few images , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[64]
, author=
3d gaussian splatting for real-time radiance field rendering. , author=. ACM Trans. Graph. , volume=
-
[65]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Regnerf: Regularizing neural radiance fields for view synthesis from sparse inputs , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[66]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Infonerf: Ray entropy minimization for few-shot neural volume rendering , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[67]
arXiv preprint arXiv:2301.10941 , year=
Geconerf: Few-shot neural radiance fields via geometric consistency , author=. arXiv preprint arXiv:2301.10941 , year=
-
[68]
and Mittleman, J
Bernardini, F. and Mittleman, J. and Rushmeier, H. and Silva, C. and Taubin, G. , journal=. The ball-pivoting algorithm for surface reconstruction , year=
-
[69]
Proceedings of EMNLP , year=
LXMERT: Learning Cross-Modality Encoder Representations from Transformers , author=. Proceedings of EMNLP , year=
-
[70]
ECCV , year=
UNITER: UNiversal Image-Text Representation Learning , author=. ECCV , year=
-
[71]
ICML , year=
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision , author=. ICML , year=
-
[72]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Repaint: Inpainting using denoising diffusion probabilistic models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[73]
CVPR , year =
DUSt3R: Geometric 3D Vision Made Easy , author=. CVPR , year =
-
[74]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Repurposing diffusion-based image generators for monocular depth estimation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[75]
arXiv preprint arXiv:2311.13384 , year=
LucidDreamer: Domain-free Generation of 3D Gaussian Splatting Scenes , author=. arXiv preprint arXiv:2311.13384 , year=
-
[76]
arXiv preprint arXiv:2311.17117 , website=
Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation , author=. arXiv preprint arXiv:2311.17117 , website=
-
[77]
arXiv preprint arXiv:2405.17251 , year=
GenWarp: Single Image to Novel Views with Semantic-Preserving Generative Warping , author=. arXiv preprint arXiv:2405.17251 , year=
-
[78]
Full Author Name , title =
-
[79]
arXiv preprint arXiv:2503.11651 , year=
Vggt: Visual geometry grounded transformer , author=. arXiv preprint arXiv:2503.11651 , year=
-
[80]
CVPR , year=
Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields , author=. CVPR , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.